UNIT - 4
Introduction to Parallel Processing
Reduced Instruction Set Computer (RISC) is a type or category of the processor, or Instruction Set Architecture (ISA). Speaking broadly, an ISA is a medium whereby a processor communicates with the human programmer (although there are several other formally identified layers in between the processor and the programmer). An instruction is a command given to the processor to perform an action. An instruction set is the entire collection of instructions for a given processor, and the term architecture implies a particular way of building the system that makes the processor.
RISC generally refers to a streamlined version of its predecessor, the Complex Instruction Set Computer (CISC). At the dawn of processors, there was no formal identification known as CISC, but the term has since been coined to identify them as different from the RISC architecture. Some examples of CISC microprocessor instruction set architectures (ISAs) include the Motorola 68000 (68K), the DEC VAX, PDP-11, several generations of the Intel x86, and 8051.
Examples of processors with the RISC architecture include MIPS, PowerPC, Atmel’s AVR, the Microchip PIC processors, Arm processors, RISC-V, and all modern microprocessors have at least some elements of RISC. The progression from 8- and 16-bit to 32-bit architectures essentially forced the need for RISC architectures. Nevertheless, it took a decade before RISC architectures began to take hold, mainly due to lack of software that would run on RISC architectures. Intel also made an impact, since it had the means to continue using the CISC architecture and found no need to redesign from the ground up. The MIPS architecture was one of the first RISC ISAs and has been used widely to teach the RISC architecture.
Some history
The first integrated chip was designed in 1958 by Jack Kilby. Microprocessors were introduced in the 1970s, the first commercial one coming from Intel Corporation. By the early 1980s, the RISC architecture had been introduced. The RISC design came about as a total redesign because the CISC architecture was becoming more complex. Most credit John Cocke of IBM as having come up with the RISC concept. History tells us that to get a faster computer, some major changes in the microprocessor architecture took place that became RISC, including a uniform format for instructions and easily pipelined instructions. (Pipelining means the processor starts to execute the next instruction before the present instruction is completed.) In the 1970s, memory was costly, so smaller programs were a focus.
What are the differences between RISC and CISC?
The short answer is that RISC is perceived by many as an improvement over CISC. There is no best architecture since different architectures can simply be better in some scenarios but less ideal in others. RISC-based machines execute one instruction per clock cycle. CISC machines can have special instructions as well as instructions that take more than one cycle to execute. This means that the same instruction executed on a CISC architecture might take several instructions to execute on a RISC machine. The RISC architecture will need more working (RAM) memory than CISC to hold values as it loads each instruction, acts upon it, then loads the next one.
The CISC architecture can execute one, albeit more complex instruction, that does the same operations, all at once, directly upon memory. Thus, RISC architecture requires more RAM but always executes one instruction per clock cycle for predictable processing, which is good for pipelining. One of the major differences between RISC and CISC is that RISC emphasizes efficiency in cycles per instruction and CISC emphasizes efficiency in instructions per program. A fast processor is dependent upon how much time it takes to execute each clock cycle, how many cycles it takes to execute instructions, and the number of instructions there are in each program. RISC has an emphasis on larger program code sizes (due to a smaller instruction set, so multiple steps done in succession may equate to one step in CISC).
The RISC ISA emphasizes software over hardware. The RISC instruction set requires one to write more efficient software (e.g., compilers or code) with fewer instructions. CISC ISAs use more transistors in the hardware to implement more instructions and more complex instructions as well.
RISC needs more RAM, whereas CISC has an emphasis on smaller code size and uses less RAM overall than RISC. Many microprocessors today hold a mix of RISC- and CISC-like attributes, however, such as a CISC-like ISA that treats instructions as if they are a string of RISC-type instructions.
Some major differences between CISC and RISC architectures are listed in Table
|
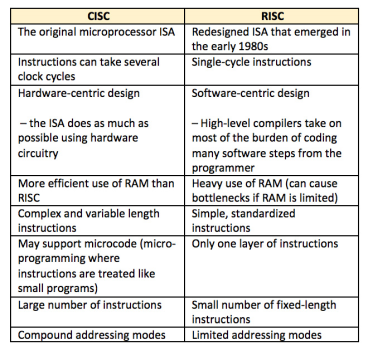
Table 1: Table of some of the differences between CISC and RISC Instruction Set Architectures (ISAs).
Key takeaways
- Reduced Instruction Set Computer (RISC) is a type or category of the processor, or Instruction Set Architecture (ISA). Speaking broadly, an ISA is a medium whereby a processor communicates with the human programmer (although there are several other formally identified layers in between the processor and the programmer). An instruction is a command given to the processor to perform an action. An instruction set is the entire collection of instructions for a given processor, and the term architecture implies a particular way of building the system that makes the processor.
- RISC generally refers to a streamlined version of its predecessor, the Complex Instruction Set Computer (CISC). At the dawn of processors, there was no formal identification known as CISC, but the term has since been coined to identify them as different from the RISC architecture. Some examples of CISC microprocessor instruction set architectures (ISAs) include the Motorola 68000 (68K), the DEC VAX, PDP-11, several generations of the Intel x86, and 8051.
Parallelism in Uniprocessor Systems
A typical uniprocessor computer consists of three major components: the main memory, the central processing unit (CPU), and the input-output (I/O) subsystem. The architectures of two commercially available uniprocessor computers are given below to show the possible interconnection of structures among the three subsystems. There are sixteen 32-bit general purpose registers, one of which serves as the program Counter (pc).there is also a special CPU status register containing information about the current state of the processor and of the program being executed. The CPU contains an arithmetic and logic unit (ALU) with an optional floating-point accelerator, and some local cache memory with an optional diagnostic memory.
Basic Uniprocessor Architecture
The CPU, the main memory and the I/O subsystems are all connected to a common bus, the synchronous backplane interconnect (SBI) through this bus, all I/O device scan communicate with each other, with the CPU, or with the memory. Peripheral storage or I/O devices can be connected directly to the SBI through the unibus and its controller or through a mass bus and its controller.
The CPU contains the instruction decoding and execution units as well as a cache. Main memory is divided into four units, referred to as logical storage units that are four-way interleaved. The storage controller provides mutltiport connections between the CPU and the four LSUs. Peripherals are connected to the system via high speed I/O channels which operate asynchronously with the CPU.
Central Processing Unit (CPU)
LOGICAL STORAGE UNITS
STORAGE CONTROLLER
LSU0 LSU1 LSU2 LSU3
I/O CHANNELS
I/O Sub System
1. Parallel Processing Mechanism
A number of parallel processing mechanisms have been developed in uniprocessor
computers.
We identify them in the following six categories:
- multiplicity of functional units
- parallelism and pipelining within the CPU
- overlapped CPU and I/O operations
- use of a hierarchical memory system
- multiprogramming and time sharing
- multiplicity of functional units
2. Multiplicity of Functional Units
The early computer has only one ALU in its CPU and hence performing a long sequence of ALU instructions takes more amount of time. The CDC-6600 has 10 functional units built into its CPU. These 10 units are independent of each other and may operate simultaneously.
A score board is used to keep track of the availability of the functional units and registers being demanded. With 10 functional units and 24 registers available, the instruction issue rate can be significantly increased. Another good example of a multifunction uniprocessor is the IBM 360/91 which has 2 parallel execution units. One for fixed point arithmetic and the other for floating point arithmetic. Within the floating point E-unit are two functional units: one for floating point add- subtract and other for floating point multiply – divide. IBM 360/91 is a highly pipelined, multifunction scientific uniprocessor.
Parallelism and Pipelining Within The Cpu
Parallel adders, using such techniques as carry-look ahead and carry –save, are now built into almost all ALUs. This is in contrast to the bit serial adders used in the first generation machines. High speed multiplier recording and convergence division are techniques for exploring parallelism and the sharing of hardware resources for the functions of multiply and
Divide. The use of multiple functional units is a form of parallelism with the CPU. Various phases of instructions executions are now pipelined, including instruction fetch, decode, operand fetch, arithmetic logic execution, and store result.
Overlapped CPU and I/O operations
I/O operations can be performed simultaneously with the CPU competitions by using separate I/O controllers, channels, or I/O processors. The direct memory access (DMA) channel can be used to provide direct information transfer between the I/O devices and the main memory. The DMA is conducted on a cycle stealing basis, which is apparent to the CPU.
Use of Hierarchical Memory System
The CPU is 1000 times faster than memory access. A hierarchical memory system can be used to close up the speed gap. The hierarchical order listed is
- Registers
- Cache
- Main Memory
- Magnetic Disk
- Magnetic Tape
The inner most level is the register files directly addressable by ALU.
Cache memory can be used to serve as a buffer between the CPU and the main memory. Virtual memory space can be established with the use of disks and tapes at the outer levels.
Balancing Of Subsystem Bandwidth
CPU is the fastest unit in computer. The bandwidth of a system is defined as the number of operations performed per unit time. In case of main memory the memory bandwidth is measured by the number of words that can be accessed per unit time.
Bandwidth Balancing Between CPU and Memory
The speed gap between the CPU and the main memory can be closed up by using fast cache memory between them. A block of memory words is moved from the main memory into the cache so that immediate instructions can be available most of the time from the cache.
Bandwidth Balancing Between Memory and I/O Devices
Input-output channels with different speeds can be used between the slow I/O devices and the main memory. The I/O channels perform buffering and multiplexing functions to transfer the data from multiple disks into the main memory by stealing cycles from the CPU.
Multiprogramming
Within the same interval of time, there may be multiple processes active in a computer, competing for memory, I/O and CPU resources. Some computers are I/O bound and some are
CPU bound. Various types of programs are mixed up to balance bandwidths among functional units.
Example Whenever a process P1 is tied up with I/O processor for performing input output operation at the same moment CPU can be tied up with an process P2. This allows simultaneous execution of programs. The interleaving of CPU and I/O operations among several programs is called as Multiprogramming.
Time-Sharing
The mainframes of the batch era were firmly established by the late 1960s when advances in semiconductor technology made the solid-state memory and integrated circuit feasible. Theseadvances in hardware technology spawned the minicomputer era. They were small, fast, and inexpensive enough to be spread throughout the company at the divisional level. Multiprogramming mainly deals with sharing of many programs by the CPU. Sometimes high priority programs may occupy the CPU for long time and other programs are put up in queue. This problem can be overcome by a concept called as Time sharing in which every process is allotted a time slice of CPU time and thereafter after its respective time slice is over CPU is allotted to the next program if the process is not completed it will be in queue waiting for the second chance to receive the CPU time
Key takeaways
1. A typical uniprocessor computer consists of three major components: the main memory, the central processing unit (CPU), and the input-output (I/O) subsystem. The architectures of two commercially available uniprocessor computers are given below to show the possible interconnection of structures among the three subsystems. There are sixteen 32-bit general purpose registers, one of which serves as the program Counter (pc).there is also a special CPU status register containing information about the current state of the processor and of the program being executed. The CPU contains an arithmetic and logic unit (ALU) with an optional floating-point accelerator, and some local cache memory with an optional diagnostic memory.
Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
Parallel systems are more difficult to program than computers with a single processor because the architecture of parallel computers varies accordingly and the processes of multiple CPUs must be coordinated and synchronized.
The crux of parallel processing is CPUs. Based on the number of instruction and data streams that can be processed simultaneously, computing systems are classified into four major categories:
|
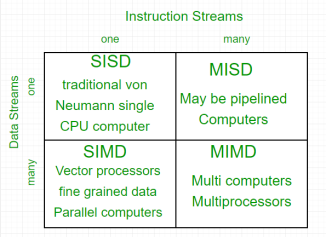
Figure 1 – Instruction Streams
Flynn’s classification –
Single-instruction, single-data (SISD) systems –
An SISD computing system is a uniprocessor machine which is capable of executing a single instruction, operating on a single data stream. In SISD, machine instructions are processed in a sequential manner and computers adopting this model are popularly called sequential computers. Most conventional computers have SISD architecture. All the instructions and data to be processed have to be stored in primary memory.
|
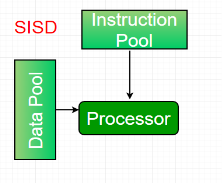
Figure 2 - SISD
The speed of the processing element in the SISD model is limited(dependent) by the rate at which the computer can transfer information internally. Dominant representative SISD systems are IBM PC, workstations.
Single-instruction, multiple-data (SIMD) systems –
An SIMD system is a multiprocessor machine capable of executing the same instruction on all the CPUs but operating on different data streams. Machines based on an SIMD model are well suited to scientific computing since they involve lots of vector and matrix operations. So that the information can be passed to all the processing elements (PEs) organized data elements of vectors can be divided into multiple sets(N-sets for N PE systems) and each PE can process one data set.
|
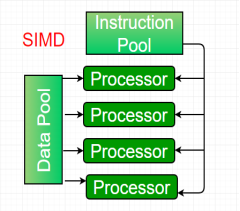
Figure 3 - SIMD
Dominant representative SIMD systems is Cray’s vector processing machine.
Multiple-instruction, single-data (MISD) systems –
An MISD computing system is a multiprocessor machine capable of executing different instructions on different PEs but all of them operating on the same dataset .
|
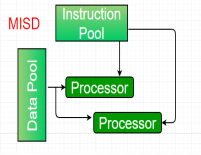
Figure 4 - MISD
Example Z = sin(x)+cos(x)+tan(x) |
The system performs different operations on the same data set. Machines built using the MISD model are not useful in most of the application, a few machines are built, but none of them are available commercially.
Multiple-instruction, multiple-data (MIMD) systems –
An MIMD system is a multiprocessor machine which is capable of executing multiple instructions on multiple data sets. Each PE in the MIMD model has separate instruction and data streams; therefore machines built using this model are capable to any kind of application. Unlike SIMD and MISD machines, PEs in MIMD machines work asynchronously.
|
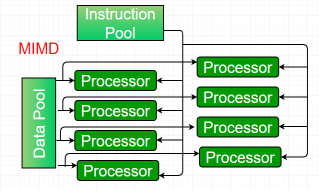
Figure 5 - MIMD
MIMD machines are broadly categorized into shared-memory MIMD and distributed-memory MIMD based on the way PEs are coupled to the main memory.
In the shared memory MIMD model (tightly coupled multiprocessor systems), all the PEs are connected to a single global memory and they all have access to it. The communication between PEs in this model takes place through the shared memory, modification of the data stored in the global memory by one PE is visible to all other PEs. Dominant representative shared memory MIMD systems are Silicon Graphics machines and Sun/IBM’s SMP (Symmetric Multi-Processing).
In Distributed memory MIMD machines (loosely coupled multiprocessor systems) all PEs have a local memory. The communication between PEs in this model takes place through the interconnection network (the inter process communication channel, or IPC). The network connecting PEs can be configured to tree, mesh or in accordance with the requirement.
The shared-memory MIMD architecture is easier to program but is less tolerant to failures and harder to extend with respect to the distributed memory MIMD model. Failures in a shared-memory MIMD affect the entire system, whereas this is not the case of the distributed model, in which each of the PEs can be easily isolated. Moreover, shared memory MIMD architectures are less likely to scale because the addition of more PEs leads to memory contention. This is a situation that does not happen in the case of distributed memory, in which each PE has its own memory. As a result of practical outcomes and user’s requirement , distributed memory MIMD architecture is superior to the other existing models.
Key takeaways
- Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
Parallel systems are more difficult to program than computers with a single processor because the architecture of parallel computers varies accordingly and the processes of multiple CPUs must be coordinated and synchronized.
References
1 Computer system architecture by M. Morris Mano
2 Computer Architecture and parallel processing by Kai Hwang, Briggs, McGraw
3 Hill
4 Computer Architecture by Carter, Tata McGraw Hill.
5 Computer System Organization and Architecture by John D. Carpinelli, Pearson Education
UNIT - 4
Introduction to Parallel Processing
Reduced Instruction Set Computer (RISC) is a type or category of the processor, or Instruction Set Architecture (ISA). Speaking broadly, an ISA is a medium whereby a processor communicates with the human programmer (although there are several other formally identified layers in between the processor and the programmer). An instruction is a command given to the processor to perform an action. An instruction set is the entire collection of instructions for a given processor, and the term architecture implies a particular way of building the system that makes the processor.
RISC generally refers to a streamlined version of its predecessor, the Complex Instruction Set Computer (CISC). At the dawn of processors, there was no formal identification known as CISC, but the term has since been coined to identify them as different from the RISC architecture. Some examples of CISC microprocessor instruction set architectures (ISAs) include the Motorola 68000 (68K), the DEC VAX, PDP-11, several generations of the Intel x86, and 8051.
Examples of processors with the RISC architecture include MIPS, PowerPC, Atmel’s AVR, the Microchip PIC processors, Arm processors, RISC-V, and all modern microprocessors have at least some elements of RISC. The progression from 8- and 16-bit to 32-bit architectures essentially forced the need for RISC architectures. Nevertheless, it took a decade before RISC architectures began to take hold, mainly due to lack of software that would run on RISC architectures. Intel also made an impact, since it had the means to continue using the CISC architecture and found no need to redesign from the ground up. The MIPS architecture was one of the first RISC ISAs and has been used widely to teach the RISC architecture.
Some history
The first integrated chip was designed in 1958 by Jack Kilby. Microprocessors were introduced in the 1970s, the first commercial one coming from Intel Corporation. By the early 1980s, the RISC architecture had been introduced. The RISC design came about as a total redesign because the CISC architecture was becoming more complex. Most credit John Cocke of IBM as having come up with the RISC concept. History tells us that to get a faster computer, some major changes in the microprocessor architecture took place that became RISC, including a uniform format for instructions and easily pipelined instructions. (Pipelining means the processor starts to execute the next instruction before the present instruction is completed.) In the 1970s, memory was costly, so smaller programs were a focus.
What are the differences between RISC and CISC?
The short answer is that RISC is perceived by many as an improvement over CISC. There is no best architecture since different architectures can simply be better in some scenarios but less ideal in others. RISC-based machines execute one instruction per clock cycle. CISC machines can have special instructions as well as instructions that take more than one cycle to execute. This means that the same instruction executed on a CISC architecture might take several instructions to execute on a RISC machine. The RISC architecture will need more working (RAM) memory than CISC to hold values as it loads each instruction, acts upon it, then loads the next one.
The CISC architecture can execute one, albeit more complex instruction, that does the same operations, all at once, directly upon memory. Thus, RISC architecture requires more RAM but always executes one instruction per clock cycle for predictable processing, which is good for pipelining. One of the major differences between RISC and CISC is that RISC emphasizes efficiency in cycles per instruction and CISC emphasizes efficiency in instructions per program. A fast processor is dependent upon how much time it takes to execute each clock cycle, how many cycles it takes to execute instructions, and the number of instructions there are in each program. RISC has an emphasis on larger program code sizes (due to a smaller instruction set, so multiple steps done in succession may equate to one step in CISC).
The RISC ISA emphasizes software over hardware. The RISC instruction set requires one to write more efficient software (e.g., compilers or code) with fewer instructions. CISC ISAs use more transistors in the hardware to implement more instructions and more complex instructions as well.
RISC needs more RAM, whereas CISC has an emphasis on smaller code size and uses less RAM overall than RISC. Many microprocessors today hold a mix of RISC- and CISC-like attributes, however, such as a CISC-like ISA that treats instructions as if they are a string of RISC-type instructions.
Some major differences between CISC and RISC architectures are listed in Table
|
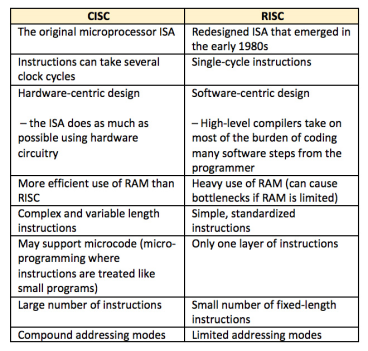
Table 1: Table of some of the differences between CISC and RISC Instruction Set Architectures (ISAs).
Key takeaways
- Reduced Instruction Set Computer (RISC) is a type or category of the processor, or Instruction Set Architecture (ISA). Speaking broadly, an ISA is a medium whereby a processor communicates with the human programmer (although there are several other formally identified layers in between the processor and the programmer). An instruction is a command given to the processor to perform an action. An instruction set is the entire collection of instructions for a given processor, and the term architecture implies a particular way of building the system that makes the processor.
- RISC generally refers to a streamlined version of its predecessor, the Complex Instruction Set Computer (CISC). At the dawn of processors, there was no formal identification known as CISC, but the term has since been coined to identify them as different from the RISC architecture. Some examples of CISC microprocessor instruction set architectures (ISAs) include the Motorola 68000 (68K), the DEC VAX, PDP-11, several generations of the Intel x86, and 8051.
Parallelism in Uniprocessor Systems
A typical uniprocessor computer consists of three major components: the main memory, the central processing unit (CPU), and the input-output (I/O) subsystem. The architectures of two commercially available uniprocessor computers are given below to show the possible interconnection of structures among the three subsystems. There are sixteen 32-bit general purpose registers, one of which serves as the program Counter (pc).there is also a special CPU status register containing information about the current state of the processor and of the program being executed. The CPU contains an arithmetic and logic unit (ALU) with an optional floating-point accelerator, and some local cache memory with an optional diagnostic memory.
Basic Uniprocessor Architecture
The CPU, the main memory and the I/O subsystems are all connected to a common bus, the synchronous backplane interconnect (SBI) through this bus, all I/O device scan communicate with each other, with the CPU, or with the memory. Peripheral storage or I/O devices can be connected directly to the SBI through the unibus and its controller or through a mass bus and its controller.
The CPU contains the instruction decoding and execution units as well as a cache. Main memory is divided into four units, referred to as logical storage units that are four-way interleaved. The storage controller provides mutltiport connections between the CPU and the four LSUs. Peripherals are connected to the system via high speed I/O channels which operate asynchronously with the CPU.
Central Processing Unit (CPU)
LOGICAL STORAGE UNITS
STORAGE CONTROLLER
LSU0 LSU1 LSU2 LSU3
I/O CHANNELS
I/O Sub System
1. Parallel Processing Mechanism
A number of parallel processing mechanisms have been developed in uniprocessor
computers.
We identify them in the following six categories:
- multiplicity of functional units
- parallelism and pipelining within the CPU
- overlapped CPU and I/O operations
- use of a hierarchical memory system
- multiprogramming and time sharing
- multiplicity of functional units
2. Multiplicity of Functional Units
The early computer has only one ALU in its CPU and hence performing a long sequence of ALU instructions takes more amount of time. The CDC-6600 has 10 functional units built into its CPU. These 10 units are independent of each other and may operate simultaneously.
A score board is used to keep track of the availability of the functional units and registers being demanded. With 10 functional units and 24 registers available, the instruction issue rate can be significantly increased. Another good example of a multifunction uniprocessor is the IBM 360/91 which has 2 parallel execution units. One for fixed point arithmetic and the other for floating point arithmetic. Within the floating point E-unit are two functional units: one for floating point add- subtract and other for floating point multiply – divide. IBM 360/91 is a highly pipelined, multifunction scientific uniprocessor.
Parallelism and Pipelining Within The Cpu
Parallel adders, using such techniques as carry-look ahead and carry –save, are now built into almost all ALUs. This is in contrast to the bit serial adders used in the first generation machines. High speed multiplier recording and convergence division are techniques for exploring parallelism and the sharing of hardware resources for the functions of multiply and
Divide. The use of multiple functional units is a form of parallelism with the CPU. Various phases of instructions executions are now pipelined, including instruction fetch, decode, operand fetch, arithmetic logic execution, and store result.
Overlapped CPU and I/O operations
I/O operations can be performed simultaneously with the CPU competitions by using separate I/O controllers, channels, or I/O processors. The direct memory access (DMA) channel can be used to provide direct information transfer between the I/O devices and the main memory. The DMA is conducted on a cycle stealing basis, which is apparent to the CPU.
Use of Hierarchical Memory System
The CPU is 1000 times faster than memory access. A hierarchical memory system can be used to close up the speed gap. The hierarchical order listed is
- Registers
- Cache
- Main Memory
- Magnetic Disk
- Magnetic Tape
The inner most level is the register files directly addressable by ALU.
Cache memory can be used to serve as a buffer between the CPU and the main memory. Virtual memory space can be established with the use of disks and tapes at the outer levels.
Balancing Of Subsystem Bandwidth
CPU is the fastest unit in computer. The bandwidth of a system is defined as the number of operations performed per unit time. In case of main memory the memory bandwidth is measured by the number of words that can be accessed per unit time.
Bandwidth Balancing Between CPU and Memory
The speed gap between the CPU and the main memory can be closed up by using fast cache memory between them. A block of memory words is moved from the main memory into the cache so that immediate instructions can be available most of the time from the cache.
Bandwidth Balancing Between Memory and I/O Devices
Input-output channels with different speeds can be used between the slow I/O devices and the main memory. The I/O channels perform buffering and multiplexing functions to transfer the data from multiple disks into the main memory by stealing cycles from the CPU.
Multiprogramming
Within the same interval of time, there may be multiple processes active in a computer, competing for memory, I/O and CPU resources. Some computers are I/O bound and some are
CPU bound. Various types of programs are mixed up to balance bandwidths among functional units.
Example Whenever a process P1 is tied up with I/O processor for performing input output operation at the same moment CPU can be tied up with an process P2. This allows simultaneous execution of programs. The interleaving of CPU and I/O operations among several programs is called as Multiprogramming.
Time-Sharing
The mainframes of the batch era were firmly established by the late 1960s when advances in semiconductor technology made the solid-state memory and integrated circuit feasible. Theseadvances in hardware technology spawned the minicomputer era. They were small, fast, and inexpensive enough to be spread throughout the company at the divisional level. Multiprogramming mainly deals with sharing of many programs by the CPU. Sometimes high priority programs may occupy the CPU for long time and other programs are put up in queue. This problem can be overcome by a concept called as Time sharing in which every process is allotted a time slice of CPU time and thereafter after its respective time slice is over CPU is allotted to the next program if the process is not completed it will be in queue waiting for the second chance to receive the CPU time
Key takeaways
1. A typical uniprocessor computer consists of three major components: the main memory, the central processing unit (CPU), and the input-output (I/O) subsystem. The architectures of two commercially available uniprocessor computers are given below to show the possible interconnection of structures among the three subsystems. There are sixteen 32-bit general purpose registers, one of which serves as the program Counter (pc).there is also a special CPU status register containing information about the current state of the processor and of the program being executed. The CPU contains an arithmetic and logic unit (ALU) with an optional floating-point accelerator, and some local cache memory with an optional diagnostic memory.
Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
Parallel systems are more difficult to program than computers with a single processor because the architecture of parallel computers varies accordingly and the processes of multiple CPUs must be coordinated and synchronized.
The crux of parallel processing is CPUs. Based on the number of instruction and data streams that can be processed simultaneously, computing systems are classified into four major categories:
|
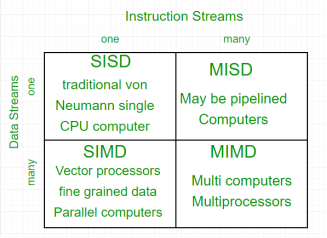
Figure 1 – Instruction Streams
Flynn’s classification –
Single-instruction, single-data (SISD) systems –
An SISD computing system is a uniprocessor machine which is capable of executing a single instruction, operating on a single data stream. In SISD, machine instructions are processed in a sequential manner and computers adopting this model are popularly called sequential computers. Most conventional computers have SISD architecture. All the instructions and data to be processed have to be stored in primary memory.
|
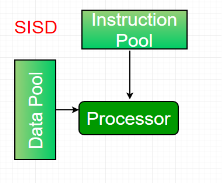
Figure 2 - SISD
The speed of the processing element in the SISD model is limited(dependent) by the rate at which the computer can transfer information internally. Dominant representative SISD systems are IBM PC, workstations.
Single-instruction, multiple-data (SIMD) systems –
An SIMD system is a multiprocessor machine capable of executing the same instruction on all the CPUs but operating on different data streams. Machines based on an SIMD model are well suited to scientific computing since they involve lots of vector and matrix operations. So that the information can be passed to all the processing elements (PEs) organized data elements of vectors can be divided into multiple sets(N-sets for N PE systems) and each PE can process one data set.
|
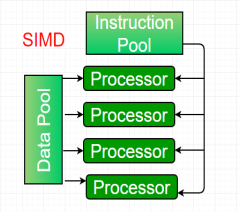
Figure 3 - SIMD
Dominant representative SIMD systems is Cray’s vector processing machine.
Multiple-instruction, single-data (MISD) systems –
An MISD computing system is a multiprocessor machine capable of executing different instructions on different PEs but all of them operating on the same dataset .
|
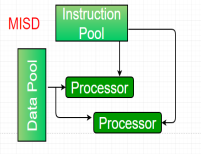
Figure 4 - MISD
Example Z = sin(x)+cos(x)+tan(x) |
The system performs different operations on the same data set. Machines built using the MISD model are not useful in most of the application, a few machines are built, but none of them are available commercially.
Multiple-instruction, multiple-data (MIMD) systems –
An MIMD system is a multiprocessor machine which is capable of executing multiple instructions on multiple data sets. Each PE in the MIMD model has separate instruction and data streams; therefore machines built using this model are capable to any kind of application. Unlike SIMD and MISD machines, PEs in MIMD machines work asynchronously.
|
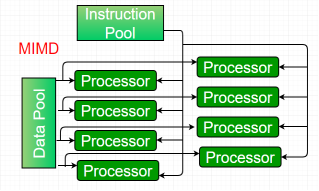
Figure 5 - MIMD
MIMD machines are broadly categorized into shared-memory MIMD and distributed-memory MIMD based on the way PEs are coupled to the main memory.
In the shared memory MIMD model (tightly coupled multiprocessor systems), all the PEs are connected to a single global memory and they all have access to it. The communication between PEs in this model takes place through the shared memory, modification of the data stored in the global memory by one PE is visible to all other PEs. Dominant representative shared memory MIMD systems are Silicon Graphics machines and Sun/IBM’s SMP (Symmetric Multi-Processing).
In Distributed memory MIMD machines (loosely coupled multiprocessor systems) all PEs have a local memory. The communication between PEs in this model takes place through the interconnection network (the inter process communication channel, or IPC). The network connecting PEs can be configured to tree, mesh or in accordance with the requirement.
The shared-memory MIMD architecture is easier to program but is less tolerant to failures and harder to extend with respect to the distributed memory MIMD model. Failures in a shared-memory MIMD affect the entire system, whereas this is not the case of the distributed model, in which each of the PEs can be easily isolated. Moreover, shared memory MIMD architectures are less likely to scale because the addition of more PEs leads to memory contention. This is a situation that does not happen in the case of distributed memory, in which each PE has its own memory. As a result of practical outcomes and user’s requirement , distributed memory MIMD architecture is superior to the other existing models.
Key takeaways
- Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
Parallel systems are more difficult to program than computers with a single processor because the architecture of parallel computers varies accordingly and the processes of multiple CPUs must be coordinated and synchronized.
References
1 Computer system architecture by M. Morris Mano
2 Computer Architecture and parallel processing by Kai Hwang, Briggs, McGraw
3 Hill
4 Computer Architecture by Carter, Tata McGraw Hill.
5 Computer System Organization and Architecture by John D. Carpinelli, Pearson Education




