Unit – 1
Introduction
The nature of speech coding systems is heavily influenced by how the human auditory system functions. Understanding how sounds are heard allows resources in the coding system to be distributed more efficiently, resulting in cost savings. Many speech coding requirements are tailored to take advantage of the properties of the human auditory system.
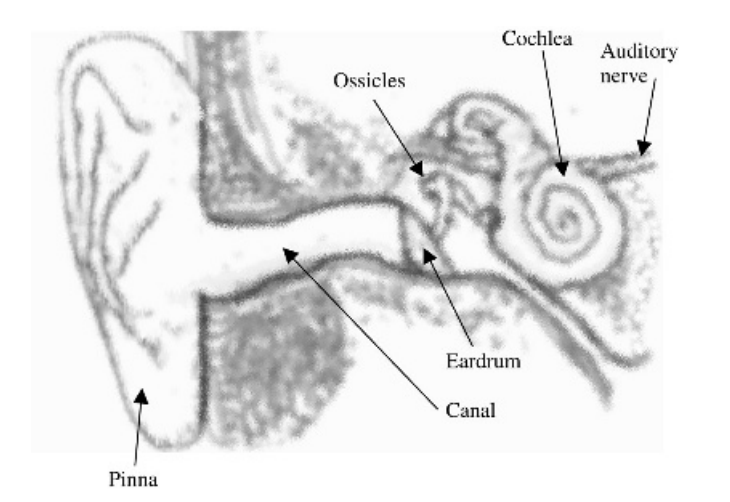
Fig 1: Diagram of the human auditory system
Figure depicts a simplified diagram of the human auditory system. The pinna (or ear informally) is the surface that surrounds the canal through which sound travels. The canal directs sound waves into the eardrum, a membrane that serves as an acoustic-to-mechanical transducer.
The sound waves are then converted into mechanical vibrations and transmitted to the cochlea through the ossicles, a collection of bones. The presence of the ossicles increases sound propagation by lowering the amount of reflection, which is achieved using the impedance matching principle.
The cochlea is a fluid-filled rigid snail-shaped organ. Mechanical oscillations impinge on the ossicles cause the basilar membrane, an internal membrane, to vibrate at different frequencies. A bank of filters can be used to model the activity of the basilar membrane, which is defined by a series of frequency responses at various points along the membrane. Inner hair cells detect movement along the basilar membrane and cause neural processes that are transmitted to the brain through the auditory nerve.
Depending on the frequencies of the incoming sound waves, various points along the basilar membrane respond differently. As a result, sounds of various frequencies excite hair cells at various locations along the membrane. The frequency specificity is maintained by the neurons that touch the hair cells and transmit the excitation to higher auditory centers.
The human auditory system acts very much like a frequency analyzer as a result of this arrangement, and system characterization in the frequency domain is much easier.
Key takeaway:
The generic block diagrams of a speech encoder and decoder are shown in Figure. The encoder processes and analyzes the input speech to derive a set of parameters that describe the frame. With the binary indices sent as the compressed bit-stream, these parameters are encoded or quantized.
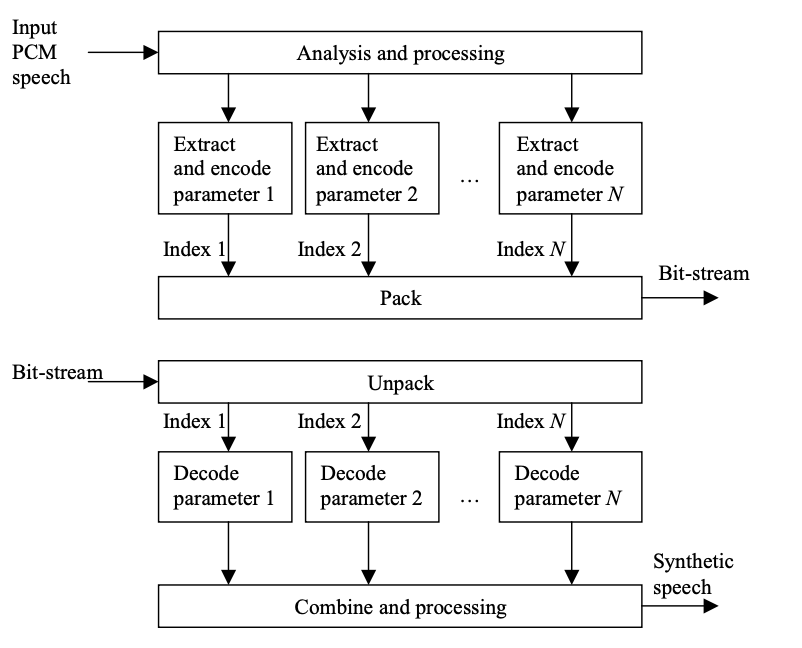
Fig 2: General structure of a speech coder. Top: Encoder. Bottom: Decoder
The indices are packed together to form the bit-stream; that is, they are arranged in a predetermined order and transmitted to the decoder, as we can see.
The speech decoder decodes the bitstream and sends the recovered binary indices to the corresponding parameter decoder to obtain quantized parameters. To create synthetic expression, these decoded parameters are combined and processed.
The functionality and features of the various processing, analysis, and quantization blocks are determined by the algorithm designer. Their choices can influence the speech coder's success and characteristics.
Key takeaway:
Parametric coders and Waveform approximating coders are the two most common types of speech coders.
Parametric coders use a number of model parameters to model the speech signal. The encoder quantizes the extracted parameters before sending them to the decoder. The decoder synthesizes speech based on the model defined.
The speech production model ignores quantization noise and does not attempt to maintain waveform consistency between synthesized and original speech signals. The estimation of model parameters may be an open loop method that receives no input from the quantization or speech synthesis.
Only the features used in the speech development model, such as the spectral envelope, pitch, and energy contour, are preserved by these coders. With improved quantization of model parameters, the speech quality of parametric coders does not converge towards the transparent quality of the original speech.
Because of the limitations of the speech development model used, this is the case. Furthermore, they do not maintain waveform similarity, and measuring the signal to noise ratio (SNR) is meaningless because the SNR sometimes becomes negative when expressed in dB (due to the lack of phase alignment between the input and output waveforms).
The SNR has no bearing on the content of synthesized expression, which should be judged subjectively (or perceptually).
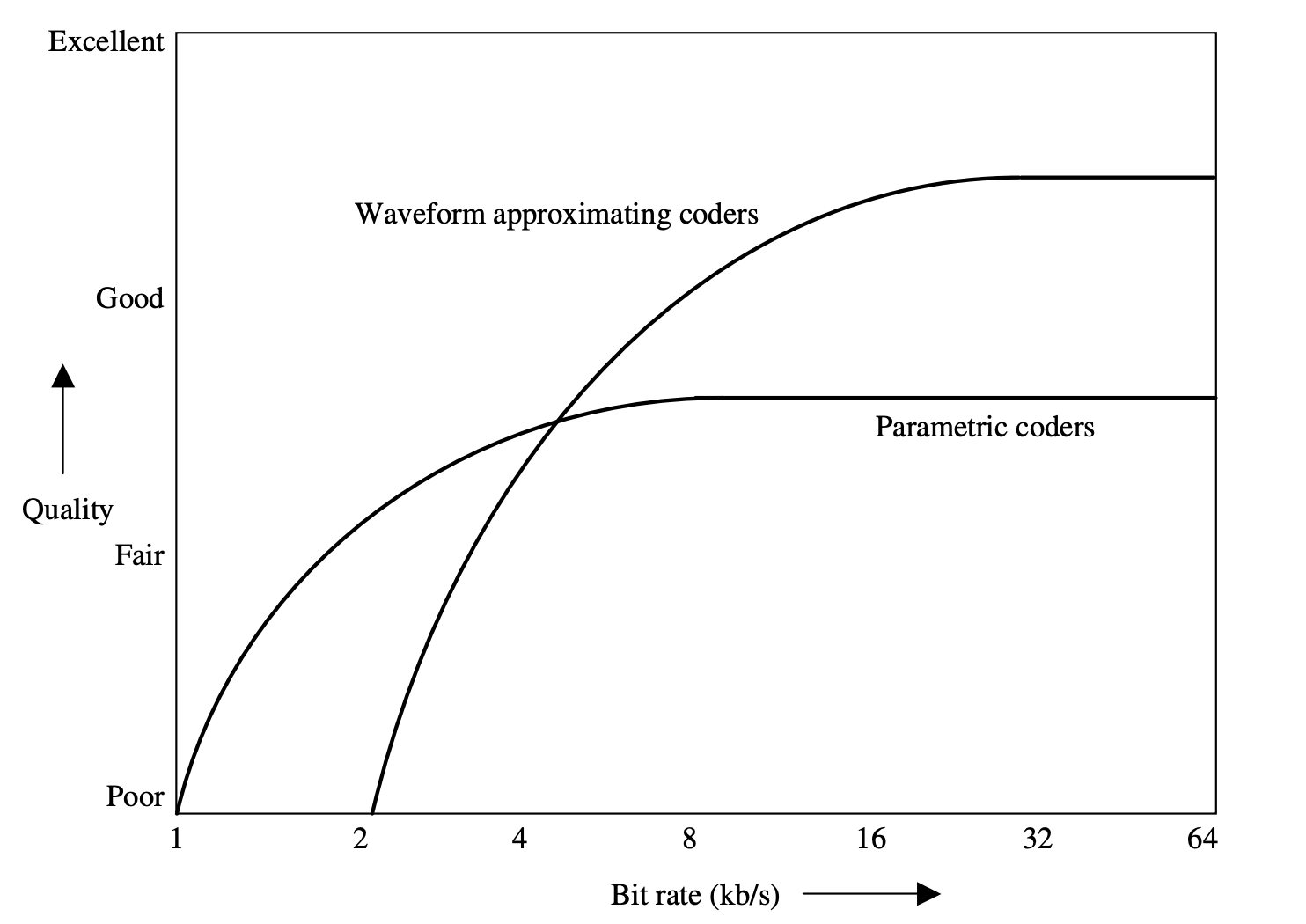
Fig 3: Quality vs bit rate for different speech coding techniques
Key takeaway:
The error between the synthesized and original speech waveforms is minimized by waveform coders. Early waveform coders including compressed Pulse Code Modulation (PCM) and Adaptive Differential Pulse Code Modulation (ADPCM) send a quantized value for each speech sample.
ADPCM, on the other hand, uses an adaptive pole zero predictor and quantizes the error signal with a variable phase scale adaptive quantizer. Backward adaptive ADPCM predictor coefficients and quantizer phase size are modified at the sampling rate.
The vocal tract model and long-term prediction are specifically used to model the associations present in the speech signal in recent waveform-approximating coders based on time domain analysis by synthesis, such as Code Excited Linear Prediction (CELP). CELP coders buffer the speech signal and conduct block-based analysis before transmitting the prediction filter coefficients and an excitation vector index. They often use perceptual weighting, which hides the quantization noise range behind the signal stage.
Hybrid coding
Regardless of the widely varying character of the speech signal, i.e. voiced, unvoiced, mixed, transitions, etc., almost all current speech coders use the same coding principle. ADPCM (Adaptive Differential Pulse Code Modulation), CELP (Code Excited Linear Prediction), and Improved Multi Band Excitation are some examples (IMBE).
The perceived quality of these coders degrades more for some speech segments when the bit rate is decreased, while remaining adequate for others. This demonstrates that the assumed coding theory is insufficient for all forms of expression. Hybrid coders, which combine different coding concepts to encode different types of speech segments, have been implemented to solve this issue.
A hybrid coder can choose from a number of different coding modes. As a result, they're also known as multimode coders. A hybrid coder is an adaptive coder that can adjust the coding technique or mode based on the source, choosing the best mode for the speech signal's local character. By adjusting the modes and bit rate, as well as modifying the relative bit allocation of the source and channel coding, a coder may adjust to network load or channel error output.
Key takeaway:
Speech quality and bit rate are two variables that are in direct dispute. Lowering the speech coder's bit rate, i.e. using higher signal compression, results in some output degradation (simple parametric vocoders). The quality standards for systems that link to the Public Switched Telephone Network (PSTN) and related systems are stringent, and they must adhere to the restrictions and guidelines placed by relevant regulatory bodies, such as the International Telecommunication Union (ITU).
Such systems necessitate the use of high-quality (toll-quality) coding. Closed systems, such as private commercial networks and military systems, can, on the other hand, jeopardize efficiency in order to reduce capacity requirements.
While absolute quality is frequently defined, it is frequently jeopardized when other variables are given a higher overall ranking. In a mobile radio system, for example, the overall average output is often the determining factor. This average quality takes both good and poor transmission conditions into account.
Key takeaway:
A speech transmission system's coding delay is a factor that is directly linked to the consistency requirements. Coding delays can be algorithmic (buffering speech for analysis), computational (processing the stored speech samples), or transmission - related.
Only the first two are related to the speech coding subsystem, though the coding scheme is often designed so that transmission can begin before the algorithm has finished processing all of the information in the analysis frame; for example, in the pan-European digital mobile radio system, the encoder transmits the spectral parameters as soon as they are visible.
Low delay is important for PSTN applications if the major problem of echo is to be minimized. Echo cancellation is used in mobile device applications and satellite communication systems because significant propagation delays already occur. However, if coders with long delays are implemented on the PSTN, where there is very little delay, additional echo cancellers will be needed. The strictly subjective frustration factor is the other issue with encoder/decoder delay.
As compared to a regular 64 kb/s PCM method, most low-rate algorithms introduce a significant coding delay. For example, the GSM system's initial upper limit for a back-to-back configuration was 65 milliseconds, while the 16 kbps G.728 specification had a maximum of 5 milliseconds with a target of 2 milliseconds.
Key takeaway:
The speech source coding rate normally consumes just a fraction of the total channel capacity for many applications, with the remaining capacity being used for forward error correction (FEC) and signaling. A coding scheme's built-in tolerance to channel errors is critical for an acceptable average overall efficiency, i.e. communication quality, on mobile connections, which suffer greatly from both random and burst errors.
Built-in robustness allows for less FEC to be used and more source coding capability to be usable, resulting in improved speech quality. This trade-off between speech quality and robustness is always a difficult one to strike, and it is a condition that must be taken into account right from the start of the speech coding algorithm design.
Other applications that use less extreme networks, such as fiber-optic connections, have less issues with channel errors, and robustness can be overlooked in favor of higher clean channel speech efficiency. This is a significant distinction between wireless mobile systems and fixed link systems. Coders can have to work in noisy background conditions in addition to channel noise.
Key takeawa :
References:
2. “Speech Coding Algorithms: Foundation and Evolution of Standardized Coders”, W.C. Chu, Wiley Inter science, 2003.




