Unit – 2
Data Warehouse and OLAP Technology for Data Mining
It is process for collecting and managing data from varied sources to provide meaningful business insights. A Data warehouse is typically used to connect and analyse business data from heterogeneous sources. The data warehouse is the core of the BI system which is built for data analysis and reporting.
It is a blend of technologies and components which aids the strategic use of data. It is electronic storage of a large amount of information by a business which is designed for query and analysis instead of transaction processing. It is a process of transforming data into information and making it available to users in a timely manner to make a difference.
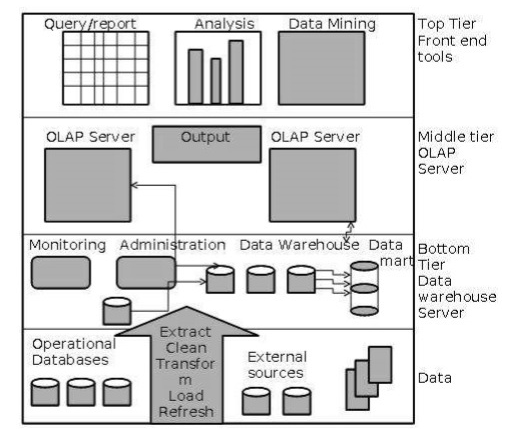
A data warehouses adopts a three-tier architecture. Following are the three tiers of the data warehouse architecture.
- Bottom Tier − The bottom tier of the architecture is the data warehouse database server. It is the relational database system. We use the back end tools and utilities to feed data into the bottom tier. These back end tools and utilities perform the Extract, Clean, Load, and refresh functions.
- Middle Tier − In the middle tier, we have the OLAP Server that can be implemented in either of the following ways.
- By Relational OLAP (ROLAP), which is an extended relational database management system? The ROLAP maps the operations on multidimensional data to standard relational operations.
- By Multidimensional OLAP (MOLAP) model, which directly implements the multidimensional data and operations?
- Top-Tier − This tier is the front-end client layer. This layer holds the query tools and reporting tools, analysis tools and data mining tools.
Data warehouse design is the process of building a solution to integrate data from multiple sources that support analytical reporting and data analysis. A poorly designed data warehouse can result in acquiring and using inaccurate source data that negatively affect the productivity and growth of your organization. The steps in data warehouse design process from requirements gathering to implementation are:
Requirements Gathering
Gathering requirements is step one of the data warehouse design process. The goal of the requirements gathering phase is to determine the criteria for a successful implementation of the data warehouse. An organization's long-term business strategy should be just as important as the current business and technical requirements. User analysis and reporting requirements must be identified as well as hardware, development, testing, implementation, and user training. Once the business and technical strategy has been decided the next step is to address how the organization will backup the data warehouse and how it will recover if the system fails. Developing a disaster recovery plan while gathering requirements, ensures that the organization is prepared to respond quickly to direct and indirect threats to the data warehouse.
Physical Environment Setup
Once the business requirements are set, the next step is to determine the physical environment for the data warehouse. At a minimum, there should be separate physical application and database servers as well as separate ETL/ELT, OLAP, cube, and reporting processes set up for development, testing, and production. Building separate physical environments ensure that all changes can be tested before moving them to production, development, and testing can occur without halting the production environment, and if data integrity becomes suspect, the IT staff can investigate the issue without negatively impacting the production environment.
Data Modelling
Once requirements gathering and physical environments have been defined, the next step is to define how data structures will be accessed, connected, processed, and stored in the data warehouse. This process is known as data modelling. During this phase of data warehouse design, is where data sources are identified. Knowing where the original data resides and just as importantly, the availability of that data, is crucial to the success of the project. Once the data sources have been identified, the data warehouse team can begin building the logical and physical structures based on established requirements.
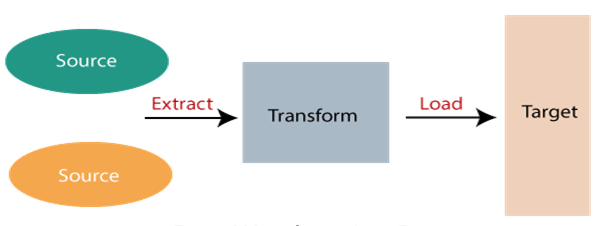
ETL
The ETL process takes the most time to develop and eats up the majority of implementation. Identifying data sources during the data modelling phase may help to reduce ETL development time. The goal of ETL is to provide optimized load speeds without sacrificing quality. Failure at this stage of the process can lead to poor performance of the ETL process and the entire data warehouse system.
OLAP
On-Line Analytical Processing (OLAP) is the answer engine that provides the infrastructure for ad-hoc user query and multi-dimensional analysis. OLAP design specification should come from those who will query the data. Documentation specifying the OLAP cube dimensions and measures should be obtained during the beginning of data warehouse design process. The three critical elements of OLAP design include:
- Grouping measures - numerical values you want to analyze such as revenue, number of customers, how many products customers purchase, or average purchase amount.
- Dimension - where measures are stored for analysis such as geographic region, month, or quarter.
- Granularity - the lowest level of detail that you want to include in the OLAP dataset.
During development, make sure the OLAP cube process is optimized. A data warehouse is usually not a nightly priority run, and once the data warehouse has been updated, there little time left to update the OLAP cube. Not updating either of them in a timely manner could lead to reduced system performance. Taking the time to explore the most efficient OLAP cube generation path can reduce or prevent performance problems after the data warehouse goes live.
Front End Development
At this point, business requirements have been captured, physical environment complete, data model decided, and ETL process has been documented. The next step is to work on how users will access the data warehouse. Front end development is how users will access the data for analysis and run reports. There are many options available, including building your front end in-house or purchasing an off the shelf product. Either way, there are a few considerations to keep in mind to ensure the best experience for end users.
Get your guide to Modern Data Management
Secure access to the data from any device - desktop, laptop, tablet, or phone should be the primary consideration. The tool should allow your development team to modify the backend structure as enterprise level reporting requirements change. It should also provide a Graphical User Interface (GUI) that enables users to customize their reports as needed. The OLAP engine and data can be the best in class, but if users are not able to use the data, the data warehouse becomes an expensive and useless data repository.
Report Development
For most end users, the only contact they have with the data warehouse is through the reports they generate. As mentioned in the front end development section, users’ ability to select their report criteria quickly and efficiently is an essential feature for data warehouse report generation. Delivery options are another consideration. Along with receiving reports through a secure web interface, users may want or need reports sent as an email attachment, or spreadsheet. Controlling the flow and visibility of data is another aspect of report development that must be addressed. Developing user groups with access to specific data segments should provide data security and control. Reporting will and should change well after the initial implementation. A well-designed data warehouse should be able to handle the new reporting requests with little to no data warehouse system modification.
Performance Tuning
Earlier in this post, the recommendation was to create separate development and testing environments. Doing so allows organizations to provide system performance tuning on ETL, query processing, and report delivery without interrupting the current production environment. Make sure the development and testing environments-hardware and applications mimic the production environment so that the performance enhancements created in development will work in the live production environment.
Once the data warehouse system has been developed according to business requirements, the next step is to test it. Testing, or quality assurance, is a step that should not be skipped because it will allow the data warehouse team to expose and address issues before the initial rollout. Failing to complete the testing phase could lead to implementation delays or termination of the data warehouse project.
Implementation
Time to go live. Deciding to make the system available to everyone at once or perform a staggered release, will depend on the number of end users and how they will access the data warehouse system. Another important aspect of any system implementation and one that is often skipped, is end-user training. No matter how "intuitive" the data warehouse team and developers think the GUI is, if the actual end users finds the tool difficult to use, or do not understand the benefits of using the data warehouse for reporting and analysis, they will not engage.
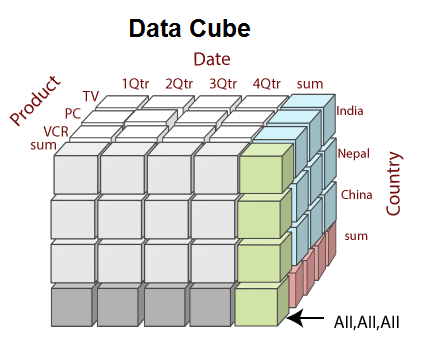
A data cube is created from a subset of attributes in the database. Specific attributes are chosen to be measure attributes, i.e., the attributes whose values are of interest. Another attributes are selected as dimensions or functional attributes. The measure attributes are aggregated according to the dimensions.
For example, XYZ may create a sales data warehouse to keep records of the store's sales for the dimensions time, item, branch, and location. These dimensions enable the store to keep track of things like monthly sales of items, and the branches and locations at which the items were sold. Each dimension may have a table identify with it, known as a dimensional table, which describes the dimensions. For example, a dimension table for items may contain the attributes item_name, brand, and type.
Data cube method is an interesting technique with many applications. Data cubes could be sparse in many cases because not every cell in each dimension may have corresponding data in the database.
Techniques should be developed to handle sparse cubes efficiently.
If a query contains constants at even lower levels than those provided in a data cube, it is not clear how to make the best use of the precomputed results stored in the data cube.
The model view data in the form of a data cube. OLAP tools are based on the multidimensional data model. Data cubes usually model n-dimensional data.
A data cube enables data to be modeled and viewed in multiple dimensions. A multidimensional data model is organized around a central theme, like sales and transactions. A fact table represents this theme. Facts are numerical measures. Thus, the fact table contains measure (such as Rs_sold) and keys to each of the related dimensional tables.
Dimensions are a fact that defines a data cube. Facts are generally quantities, which are used for analyzing the relationship between dimensions.
Reference Books
1 Data Mining : Next Generation Challenges and Future Direction by Kargupta, et al, PHI.
2 Data Warehousing, Data Mining & OLAP by Alex Berson Stephen J.Smith.




