Unit – 5
Mining Association rules in large database
Association rule mining, at a basic level, involves the use of machine learning models to analyze data for patterns, or co-occurrence, in a database. It identifies frequent if-then associations, which are called association rules.
An association rule has two parts: an antecedent (if) and a consequent (then). An antecedent is an item found within the data. A consequent is an item found in combination with the antecedent.
Association rules are created by searching data for frequent if-then patterns and using the criteria support and confidence to identify the most important relationships. Support is an indication of how frequently the items appear in the data. Confidence indicates the number of times the if-then statements are found true. A third metric, called lift, can be used to compare confidence with expected confidence.
Association rules are calculated from itemsets, which are made up of two or more items. If rules are built from analyzing all the possible itemsets, there could be so many rules that the rules hold little meaning. With that, association rules are typically created from rules well-represented in data.
Mining, the extraction of hidden predictive information from large databases, is a powerful new technology with great potential to help companies focus on the most important information in their data warehouses. Data mining tools predict future trends and behaviors, allowing businesses to make proactive, knowledge-driven decisions.
Association rule induction is a powerful method for so-called market basket analysis, which aims at finding regularities in the shopping behavior of customers of supermarkets. With the induction of association rules one tries to find sets of products that are frequently bought together, so that from the presence of certain products in a shopping cart one can infer (with a high probability) that certain other products are present. Such information, expressed in the form of rules, can often be used to increase the number of items sold, for instance, by appropriately arranging the products in the shelves of a supermarket (they may, for example, be placed adjacent to each other in order to invite even more customers to buy them together) or by directly suggesting items to a customer, which may be of interest for him/her.
An association rule is a rule like "If a customer buys milk and bread, he often buys cheese, too." It expresses an association between (sets of) items, which may be products of a supermarket or special equipment options of a car, optional services offered by telecommunication companies etc., The standard measures to assess association rules are the support and the confidence of a rule.
Association rule mining finds patterns in data. In other words interesting associations and relationships among large sets of data items can be done using association rules. This rule shows how likely a item set occurs in a transaction. A typical example is Market Based Analysis.
Market Based Analysis allows retailers to identify relationships between the items that people buy together frequently .Through a given a set of transactions, we can find rules that will predict the frequency of an item based on the occurrences of other items in the transaction.
TID | ITEMS |
1 | Bread, Milk |
2 | Bread, Diaper, Beer, Eggs |
3 | Milk, Diaper, Beer, Coke |
4 | Bread, Milk, Diaper, Beer |
5 | Bread, Milk, Diaper, Coke |
Some of the basic definitions include:
Support Count (σ) – Frequency of occurrence of a item set.
Here σ ({Milk, Bread, Diaper}) =2
Frequent Item set – An item set whose support is greater than or equal to min sup threshold.
Association Rule – An implication expression of the form X -> Y, where X and Y are any 2 item sets.
Example: {Milk, Diaper} -> {Beer}
Rule Evaluation Metrics –
- Support(s) :
The number of transactions that include items in the {X} and {Y} parts of the rule as a percentage of the total number of transaction. It is a measure of how frequently the collection of items occur together as a percentage of all transactions.
- Support = σ (X+Y) ÷ total :
It is interpreted as fraction of transactions that contain both X and Y. - Confidence(c) :
It is the ratio of the no of transactions that includes all items in {B} as well as the no of transactions that includes all items in {A} to the no of transactions that includes all items in {A}.
- Conf(X=>Y) = Supp(X U Y) ÷ Supp(X) :
It measures how often each item in Y appears in transactions that contains items in X also. - Lift(l) :
The lift of the rule X=>Y is the confidence of the rule divided by the expected confidence, assuming that the itemsets X and Y are independent of each other.The expected confidence is the confidence divided by the frequency of {Y}. - Lift(X=>Y) = Conf(X=>Y) ÷ Supp(Y) :
Lift value near 1 indicates X and Y almost often appear together as expected, greater than 1 means they appear together more than expected and less than 1 means they appear less than expected. Greater lift values indicate stronger association.
Example – From the above table, {Milk, Diaper}=>{Beer}
s=  ({Milk, Diaper, Beer}) ÷ |T|
({Milk, Diaper, Beer}) ÷ |T|
= 2/5
= 0.4
c=  (Milk, Diaper, Beer) ÷ σ (Milk, Diaper)
(Milk, Diaper, Beer) ÷ σ (Milk, Diaper)
= 2/3
= 0.67
l= Supp({Milk, Diaper, Beer}) ÷ Supp({Milk, Diaper})*Supp({Beer})
= 0.4/(0.6*0.6)
= 1.11
Association rules generated from mining data at multiple levels of abstraction are called multiple-level or multilevel association rules.
It can be mined efficiently using concept hierarchies under a support-confidence framework.
Rules at high concept level may add to common sense while rules at low concept level may not be useful always.
Using uniform minimum support for all levels:
When a uniform minimum support threshold is used, the search procedure is simplified.
The method is also simple, in that users are required to specify only one minimum support threshold.
The same minimum support threshold is used when mining at each level of abstraction.
For example, in Figure, a minimum support threshold of 5% is used throughout.
(e.g. For mining from “computer” down to “laptop computer”).
Both “computer” and “laptop computer” are found to be frequent, while “desktop computer” is not.
Using reduced minimum support at lower levels:
Each level of abstraction has its own minimum support threshold.
The deeper the level of abstraction, the smaller the corresponding threshold is.
For example in Figure, the minimum support thresholds for levels 1 and 2 are 5% and 3%, respectively.
In this way, “computer,” “laptop computer,” and “desktop computer” are all considered frequent.
Multilevel Association rule consists of alternate search strategies and Controlled level cross filtering:
1.Alternate Search Strategies:
Level by level independent:
Full breadth search.
No background knowledge in pruning.
Leads to examine lot of infrequent items.
Level-cross filtering by single item:
Examine nodes at level i only if node at level (i-1) is frequent.
Misses frequent items at lower level abstractions (due to reduced support).
Level-cross filtering by k-item set:
Examine k-itemsets at level i only if k-itemsets at level (i-1) is frequent.
Misses frequent k-itemsets at lower level abstractions (due to reduced support).
Controlled Level-cross filtering by single item:
A modified level-cross filtering by single item.
Sets a level passage threshold for every level.
Allows the inspection of lower abstractions even if its ancestor fails to satisfy min_sup threshold.
MULTIDIMENSIONAL ASSOCIATION RULES:
1.In Multi dimensional association:
Attributes can be categorical or quantitative.
Quantitative attributes are numeric and incorporates hierarchy.
Numeric attributes must be discretized.
Multi dimensional association rule consists of more than one dimension:
Eg: buys(X,”IBM Laptop computer”)buys(X,”HP Inkjet Printer”)
2.Three approaches in mining multi dimensional association rules:
1.Using static discritization of quantitative attributes.
Discritization is static and occurs prior to mining.
Discritized attributes are treated as categorical.
Use apriori algorithm to find all k-frequent predicate sets(this requires k or k+1 table scans ).
Every subset of frequent predicate set must be frequent.
Eg: If in a data cube the 3D cuboid (age, income, buys) is frequent implies (age, income), (age, buys), (income, buys) are also frequent.
Data cubes are well suited for mining since they make mining faster.
The cells of an n-dimensional data cuboid correspond to the predicate cells.
2.Using dynamic discritization of quantitative attributes:
Known as mining Quantitative Association Rules.
Numeric attributes are dynamically discretized.
Eg: age(X,”20..25”) Λ income(X,”30K..41K”)buys (X,”Laptop Computer”)
GRID FOR TUPLES
GRID FOR TUPLES
3.Using distance based discritization with clustering.
This id dynamic discretization process that considers the distance between data points.
It involves a two step mining process:
Perform clustering to find the interval of attributes involved.
Obtain association rules by searching for groups of clusters that occur together.
The resultant rules may satisfy:
Clusters in the rule antecedent are strongly associated with clusters of rules in the consequent.
Clusters in the antecedent occur together.
Clusters in the consequent occur together.
Most association rule mining algorithms employ a support-confidence framework. Often, many interesting rules can be found using low support thresholds. Although minimum support and confidence thresholds help weed out or exclude the exploration of a good number of uninteresting rules, many rules so generated are still not interesting to the users
1)Strong Rules Are Not Necessarily Interesting: An Example
Whether or not a rule is interesting can be assessed either subjectively or objectively. Ultimately, only the user can judge if a given rule is interesting, and this judgment, being subjective, may differ from one user to another. However, objective interestingness measures, based on the statistics ―behind‖ the data, can be used as one step toward the goal of weeding out uninteresting rules from presentation to the user.
The support and confidence measures are insufficient at filtering out uninteresting association rules. To tackle this weakness, a correlation measure can be used to augment the support-confidence framework for association rules. This leads to correlation rules of the form
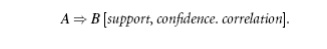
That is, a correlation rule is measured not only by its support and confidence but also by the correlation between item sets A and B. There are many different correlation measures from which to choose. In this section, we study various correlation measures to determine which would be good for mining large data sets.
- A data mining process may uncover thousands of rules from a given set of data, most of which end up being unrelated or uninteresting to the users.
- Often, users have a good sense of which “direction” of mining may lead to interesting patterns and the “form” of the patterns or rules they would like to find.
- Thus, a good heuristic is to have the users specify such intuition or expectations as constraints to confine the search space.
- This strategy is known as constraint-based mining.
- Constraint based mining provides
- User Flexibility: provides constraints on what to be mined.
- System Optimization: explores constraints to help efficient mining.
- The constraints can include the following:
- Knowledge type constraints: These specify the type of knowledge to be mined, such as association or correlation.
- Data constraints:These specify the set of task-relevant data.
- Dimension/level constraints: These specify the desired dimensions (or attributes) of the data, or levels of the concept hierarchies, to be used in mining.
- Interestingness constraints: These specify thresholds on statistical measures of rule interestingness, such as support, confidence, and correlation.
- Rule constraints: These specify the form of rules to be mined. Such constraints may be expressed as rule templates, as the maximum or minimum number of predicates that can occur in the rule antecedent or consequent, or as relationships among attributes, attribute values, and/or aggregates. The above constraints can be specified using a high-level declarative data mining query language and user interface.
Constraint based association rules: - In order to make the mining process more efficient rule based constraint mining : - allows users to describe the rules that they would like to uncover. - provides a sophisticated mining query optimizer that can be used to exploit the constraints specified by the user. - encourages interactive exploratory mining and analysis.
Constrained frequent pattern mining: Query optimization approach
- Given a frequent pattern mining query with a set of constraints C, the algorithm should be:
- Sound: it only finds frequent sets that satisfy the given constraints C.
- Complete: all frequent sets satisfying the given constraints are found .
- A naïve solution:
- Find all frequent sets and then test them for constraint satisfaction.
- More efficient approaches:
- Analyze the properties of constraints comprehensively.
- Push them as deeply as possible inside the frequent pattern computation.
Reference Books
- Data Mining : Next Generation Challenges and Future Direction by Kargupta, et al, PHI.
2. Data Warehousing, Data Mining & OLAP by Alex Berson Stephen J.Smith.




