Unit -7
Cluster Analysis
Clustering is the grouping of specific objects based on their characteristics and their similarities. As for data mining, this methodology divides the data that are best suited to the desired analysis using a special join algorithm. This analysis allows an object not to be part or strictly part of a cluster, which is called the hard partitioning of this type. However, smooth partitions suggest that each object in the same degree belongs to a cluster. More specific divisions can be created like objects of multiple clusters, a single cluster can be forced to participate or even hierarchic trees can be constructed in group relations. This file system can be put into place in different ways based on various models. These Distinct Algorithms apply to each and every model, distinguishing their properties as well as their results. A good clustering algorithm is able to identify the cluster independent of cluster shape. There are 3 basic stages of clustering algorithm which are shown as below
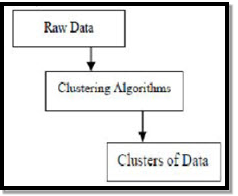
Clustering Algorithms in Data Mining
Depending on the cluster models recently described, many clusters can be used to partition information into a set of data. It should be said that each method has its own advantages and disadvantages. The selection of an algorithm depends on the properties and the nature of the data set.
Clustering Methods for Data Mining can be Shown as Below
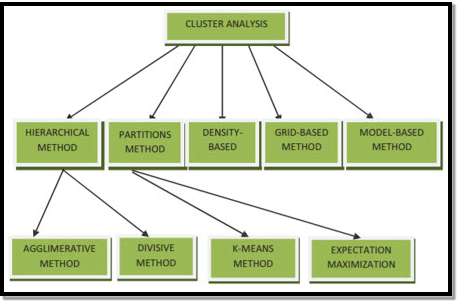
- Partitioning based Method
- Density-based Method
- Centroid-based Method
- Hierarchical Method
- Grid-Based Method
- Model-Based Method
1. Partitioning based Method
The partition algorithm divides data into many subsets.Let’s assume the partitioning algorithm builds partition of data as k and n is objects are present in the database. Hence each partition will be represented as k ≤ n.This gives an idea that the classification of the data is in k groups, which can be shown below .Figure shows original points in clustering

Figure shows Partition clustering after applying an algorithm
This indicates that each group has at least one object, as well as every object, must belong to exactly one group.
2. Density Based Method
These algorithms produce clusters in a determined location based on the high density of data set participants. It aggregates some range notion for group members in clusters to a density standard level. Such processes can perform less in detecting the group’s Surface areas.
3. Centroid-based Method
Almost every cluster is referenced by a vector of values in this type of os grouping technique. In comparison to other clusters, each object is part of the cluster with a minimum difference in value. The number of clusters should be predefined, and this is the biggest algorithm problem of this type. This methodology is the closest to the subject of identification and is widely used for problems of optimization.
4. Hierarchical Method
The method will create a hierarchical decomposition of a given set of data objects. Based on how the hierarchical decomposition is formed, we can classify hierarchical methods. This method is given as follows
- Agglomerative Approach
- Divisive Approach
Agglomerative Approach is also known as Button-up Approach. Here we begin with every object that constitutes a separate group. It continues to fuse objects or groups close together
Divisive Approach is also Known as the Top-Down Approach. We begin with all the objects in the same cluster. This method is rigid, i.e., it can never be undone once a fusion or division is completed
5. Grid-Based Method
Grid-based methods work in the object space instead of dividing the data into a grid. Grid is divided based on characteristics of the data. By using this method non-numeric data is easy to manage. Data order does not affect the partitioning of the grid. An important advantage of a grid-based model it provides faster execution speed.
Advantages of Hierarchical Clustering are as follows
- It is applicable to any attribute type.
- It provides flexibility related to the level of granularity.
6. Model-Based Method
This method uses a hypothesized model based on probability distribution. By clustering the density function, this method locates the clusters. It reflects the data points’ spatial distribution.
Clustering is a unsupervised learning technique to discover the inherent groupings in the data such as grouping customers by purchasing behavior. This helps to find the differences and similarities between the. Here no external label is attached to the object. For example, when you go out for grocery shopping, you easily distinguish between apples and oranges in a given set containing both of them. We can distinguish these both based on their color, texture and other sensory information that is processed by your brain. Clustering is an emulation of this process so that machines are able to distinguish between different objects. Clustering is a process that helps in determining intrinsic grouping among the unlabeled dataset. In clustering, there are no standard criteria.
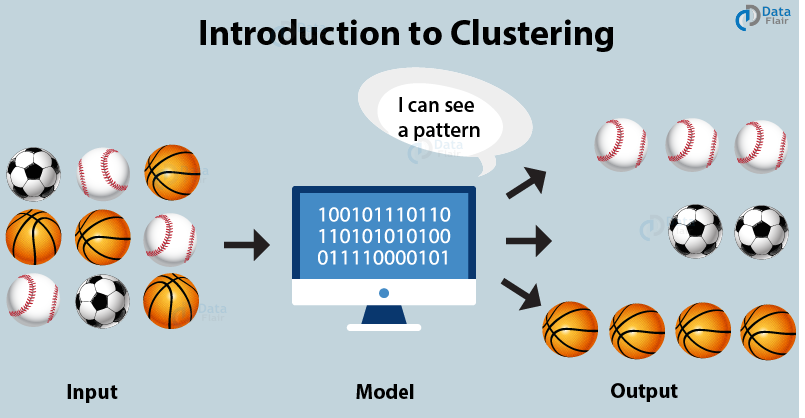
Types of Clustering Algorithms
In total, there are five distinct types of clustering algorithms. They are as follows –
- Partitioning Based Clustering
- Hierarchical Clustering
- Model-Based Clustering
- Density-Based Clustering
- Fuzzy Clustering
1. Partitioning Clustering
In this type of clustering, the algorithm subdivides the data into a subset of k groups. These k groups or clusters are to be pre-defined. It divides the data into clusters by satisfying these two requirements – Firstly, Each group should consist of at least one point. Secondly, each point must belong to exactly one group. K-Means Clustering is the most popular type of partitioning clustering method.
2. Hierarchical Clustering
The basic notion behind this type of clustering is to create a hierarchy of clusters. As opposed to Partitioning Clustering, it does not require pre-definition of clusters upon which the model is to be built. There are two ways to perform Hierarchical Clustering. The first approach is a bottom-up approach, also known as Agglomerative Approach and the second approach is the Divisive Approach which moves hierarchy of clusters in a top-down approach. As a result of this type of clustering, we obtain a tree-like representation known as a dendogram.
3. Density-Based Models
In these type of clusters, there are dense areas present in the data space that are separated from each other by sparser areas. These type of clustering algorithms play a crucial role in evaluating and finding non-linear shape structures based on density. The most popular density-based algorithm is DBSCAn which allows spatial clustering of data with noise. It makes use of two concepts – Data Reachability and Data Connectivity.
4. Model-Based Clustering
In this type of clustering technique, the data observed arises from a distribution consisting of a mixture of two or more cluster components. Furthermore, each component cluster has a density function having an associated probability or weight in this mixture.
5. Fuzzy Clustering
In this type of clustering, the data points can belong to more than one cluster. Each component present in the cluster has a membership coefficient that corresponds to a degree of being present in that cluster. Fuzzy Clustering method is also known as a soft method of clustering.
The clustering methods can be classified into following categories:
o Kmeans
o Partitioning Method
o Hierarchical Method
o Density-based Method
o Grid-Based Method
o Model-Based Method
o Constraint-based Method
Suppose we are given a database of n objects, the partitioning method construct k partition of data.
Each partition will represent a cluster and k≤n. It means that it will classify the data into k groups, which satisfy the following requirements:
o Each group contain at least one object.
o Each object must belong to exactly one group.
Typical methods:
K-means, k-medoids, CLARANS
This method creates the hierarchical decomposition of the given set of data objects.:
Agglomerative Approach
This approach is also known as bottom-up approach. In this we start with each object forming a separate group. It keeps on merging the objects or groups that are close to one another. It keep on doing so until all of the groups are merged into one or until the termination condition holds.
Divisive Approach
This approach is also known as top-down approach. In this we start with all of the objects in the same cluster. In the continuous iteration, a cluster is split up into smaller clusters. It is down until each object in one cluster or the termination condition holds.
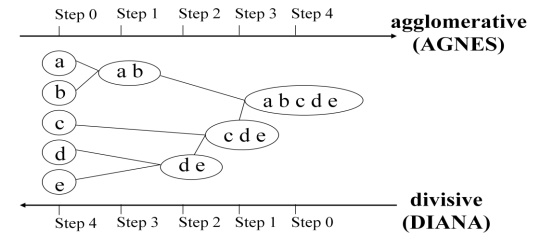
Disadvantage
This method is rigid i.e. once merge or split is done, It can never be undone.
Approaches to improve quality of Hierarchical clustering
Here is the two approaches that are used to improve quality of hierarchical clustering:
Perform careful analysis of object linkages at each hierarchical partitioning.
Integrate hierarchical agglomeration by first using a hierarchical agglomerative algorithm to group objects into microclusters, and then performing macroclustering on the microclusters. Typical methods: Diana, Agnes, BIRCH, ROCK, CAMELEON
Major features:
o Discover clusters of arbitrary shape
o Handle noise
o One scan
o Need density parameters as termination condition
Two parameters:
o Eps: Maximum radius of the neighbourhood
o MinPts: Minimum number of points in an Eps-neighbourhood of that point
Typical methods: DBSACN, OPTICS, DenClue
Using multi-resolution grid data structure
Advantage
o The major advantage of this method is fast processing time.
o It is dependent only on the number of cells in each dimension in the quantized space.
o Typical methods: STING, WaveCluster, CLIQUE
o STING: a STatistical INformation Grid approach
o The spatial area area is divided into rectangular cells
o There are several levels of cells corresponding to different levels of resolution
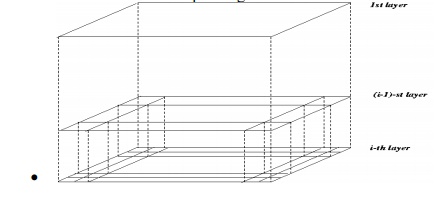
o Each cell at a high level is partitioned into a number of smaller cells in the next lower level
o Statistical info of each cell is calculated and stored beforehand and is used to answer queries
o Parameters of higher level cells can be easily calculated from parameters of lower level cell
Count, mean, s, min, max
Type of distribution—normal, uniform, etc.
o Use a top-down approach to answer spatial data queries
o Start from a pre-selected layer—typically with a small number of cells
o For each cell in the current level compute the confidence interval
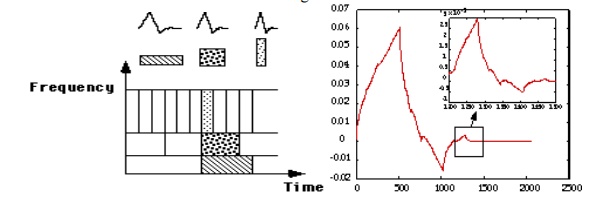
· WaveCluster: Clustering by Wavelet Analysis
· A multi-resolution clustering approach which applies wavelet transform to the feature space
· How to apply wavelet transform to find clusters
o Summarizes the data by imposing a multidimensional grid structure onto data space
o These multidimensional spatial data objects are represented in a n-dimensional feature space
o Apply wavelet transform on feature space to find the dense regions in the feature space
o Apply wavelet transform multiple times which result in clusters at different scales from fine to coarse
· Wavelet transform: A signal processing technique that decomposes a signal into different frequency sub-band (can be applied to n-dimensional signals)
· Data are transformed to preserve relative distance between objects at different levels of resolution
· Allows natural clusters to become more distinguishable
Attempt to optimize the fit between the given data and some mathematical model
Based on the assumption: Data are generated by a mixture of underlying probability distribution
o In this method a model is hypothesize for each cluster and find the best fit of data to the given model.
o This method also serve a way of automatically determining number of clusters based on standard statistics, taking outlier or noise into account. It therefore yields robust clustering methods.
o Typical methods: EM, SOM, COBWEB
o EM — A popular iterative refinement algorithm
o An extension to k-means
Assign each object to a cluster according to a weight (prob. Distribution)
New means are computed based on weighted measures
o General idea
Starts with an initial estimate of the parameter vector
Iteratively rescores the patterns against the mixture density produced by the parameter vector
The rescored patterns are used to update the parameter updates
Patterns belonging to the same cluster, if they are placed by their scores in a particular component
o Algorithm converges fast but may not be in global optima
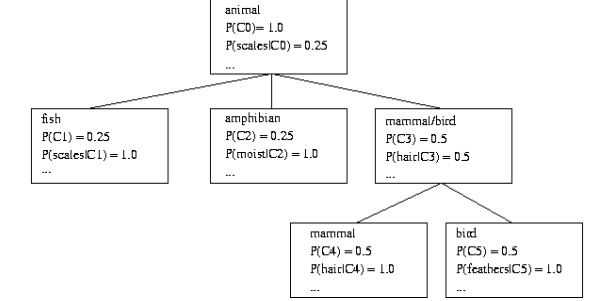
o COBWEB (Fisher’87)
A popular a simple method of incremental conceptual learning
Creates a hierarchical clustering in the form of a classification tree
Each node refers to a concept and contains a probabilistic description of that concept
o SOM (Soft-Organizing feature Map)
o Competitive learning
o Involves a hierarchical architecture of several units (neurons)
o Neurons compete in a ―winner-takes-all‖ fashion for the object currently being presented
o SOMs, also called topological ordered maps, or Kohonen Self-Organizing Feature Map (KSOMs)
o It maps all the points in a high-dimensional source space into a 2 to 3-d target space, s.t., the distance and proximity relationship (i.e., topology) are preserved as much as possible
o Similar to k-means: cluster centers tend to lie in a low-dimensional manifold in the feature space
o Clustering is performed by having several units competing for the current object
· The unit whose weight vector is closest to the current object wins
· The winner and its neighbors learn by having their weights adjusted
o SOMs are believed to resemble processing that can occur in the brain
o Useful for visualizing high-dimensional data in 2- or 3-D space
Reference Books
- Data Mining : Next Generation Challenges and Future Direction by Kargupta, et al, PHI.
2. Data Warehousing, Data Mining & OLAP by Alex Berson Stephen J.Smith.




