UNIT 7
Image and Video Database
Bitmap images
- A digital image showing how each pixel of a bitmap image can be represented in binary using 1 bit.
- Bitmap images are made up of individual pixels. The colour of each pixel is represented as a binary number so the whole image is therefore stored as a series of binary numbers.
- If memory bits are used to represent each pixel then more combinations of binary numbers are possible so more colours are possible in the image.
Vector images
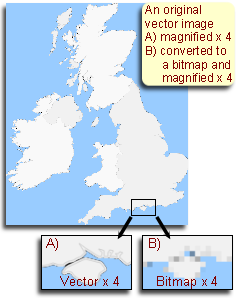
Vector images store information as mathematical instructions rather than as individual pixels.
For example, to save a vector image of a circle the software only needs to store:
- The coordinates of the circle centre
- The radius
- The line thickness
- The line style and colour
- The fill type and colour
- The image scale.
This information would be stored using binary codes for the instructions.
The result is that the file size of a vector image would be considerably smaller than the equivalent bitmap image which would need to store the colour information for every pixel.
Although vector images can have graduated fills these are mathematically defined and cannot represent the level of detail needed for photographic images.
A vector image was scaled-up and then saved then it would have the same file size as the original.
- Segmentation partitions an image into distinct regions containing each pixels with similar attributes.
- To be meaningful and useful for image analysis and interpretation, the regions should strongly relate to depicted objects or features of interest.
- Meaningful segmentation is the first step from low-level image processing transforming a greyscale or colour image into one or more other images to high-level image description in terms of features, objects, and scenes.
- Image analysis success depends on reliability of segmentation, but an accurate partitioning of an image is generally a very challenging problem.
- Segmentation techniques are either contextual or non-contextual.
- Non-contextual techniques take no account of spatial relationships between features in an image and group pixels together on the basis of some global attribute, e.g. Grey level or colour.
- Whereas Contextual techniques exploit these relationships, e.g. Group together pixels with similar grey levels and close spatial locations.

- Content-based image retrieval is also known as query by image content.
- A database of images with feature was the color and size.
- Primitive features used for restoration or could mean, but the extraction process must be predominantly automatic.
- Semantic extraction can be done automatically and correctly, but the image retrieval system cannot expect to find the exact images.
- Users can select the desired images to the most similar images should choose.
- A typical CBIR system consists of three major components used variations of them depending on the features.
- i. Extraction facility - the facility to check the raw image data to extract specific information.
- Ii. Feature storage - also help to improve the pace of discovery, offering efficient storage of the extracted information.
- Iii. Similarity measure - to determine the significance between the images to measure the difference between the images.
1. Colour
- Based on color similarity to retrieve the ratio of pixels within the image, holding images shows the exact values of each image is achieved by computing a color histogram .
- The spatial relationship between the area ratios is attempting to paint the block.
- Area - Having the same or similar color, region or counting the number of pixels.
- Color distance - The distance between colors in a perceptually uniform color space. Close match between colors.
- Spatial distribution - Such as the size of the texture and color combination with other features, while commonly used.
- Traditional color image retrieval system is used to color histogram approach.
- Histograms color will not miss out because of non-existence, however, histograms are restricted compactness of description and fixed feature space is a limitation.
2.1 Color
2.2 Texture
2. Texture
- The ability to retrieve images based on texture helps to make the difference between the similar colors.
- The technique that is used to retrieve image based on texture is wavelet trans-form technique.
- Wavelet change is a procedure of turning a signal to series of wavelets. It transforms the picture into multi scale representation with both spatial and frequency attributes.
- The main objective is to compute the pixel power of the pictures. In this technique the image is divided into 4-sub bands each of various frequency that is low-low, low-high, high-low, high-high.
2.3 Shape Retrieval
3. Shape
- Retrieving images based on the shape is basic requirement at the primitive level. Shape of the natural objects can be primitively recognized.
- The number of shapes present in the each image is recognized for all the images stored in the database.
- The images which are close to the shapes that are present in the query image are checked.
- The 2 types of shape features are global features and local features.
- Global features incorporate viewpoint proportion, circularity and minute invariants where as local features incorporate arrangements of sequential limit sections. The image segmentation is based on the brightness. They are: Mass, centroid and dispersion.
- For retrieving images the vectors of the pictures in the database and the query image are contrasted and the applicable pictures are acquired.
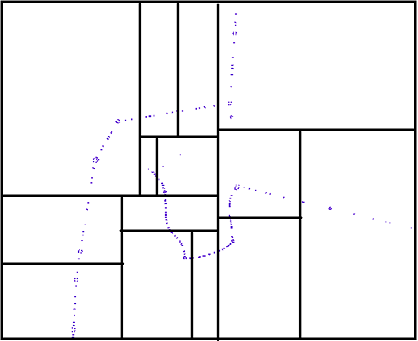
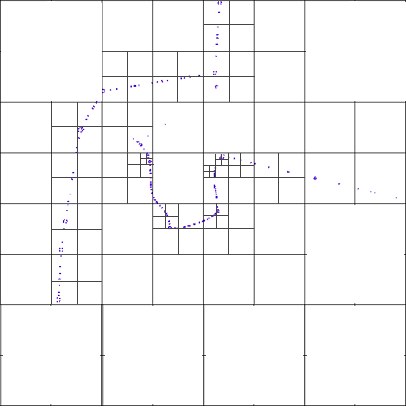
KD-Tree
In this, we divide an area if it has more than a threshold points in it and dividing is done using a (K-1) dimension geometry, for example in a 3D-Tree we need a plane to divide the space, and in a 2D-Tree we need a line to divide the area.
Dividing geometry is iterative and cyclic, for example in a 3D-Tree, the first splitting plane is a X axis aligned plane and the next dividing plane is Y axis aligned and the next is Z, the cycle continue for each space parts to become acceptable.
The following picture shows a balanced KD-Tree that each dividing line is a median, that divides an area into two sub-area with approximately equal number of points.
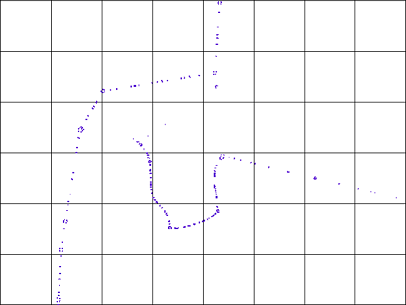
R-Tree
It is a grid-base spatial indexing method in which the study area is divided into tiles with fixed dimensions like chess board.
Using this, every point in a tile are tagged with that tile number, so the Index table could provide a tag for each point showing the tile which our number falls in.
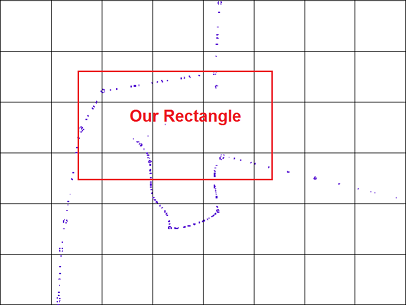
When the tiles are too big, then the first filter is practically useless, the whole processing load will be burden by the second filter. In this case the first filter is fast and the second filter is very slow.
If the tiles are very small, then the first filter is very slow and practically it generates the answer itself, and the second filter is fast.
Quad-Tree
It starts with a big tile that covers whole study area and divides it by two horizontal and vertical lines to have four equal area which are new tiles and then inspect each tile to see if it has more than a pre-defined threshold, points in it.
In this case the tile will be divided into four equal parts using a horizontal and a vertical dividing lines again. The process continues till there would be no more tile with number of points bigger than threshold, which is a recursive algorithm.
So in denser areas we have smaller tiles and big tiles when having spare points.
QBIC (Query by Image Content)
- Currently supported features: query by color, texture, simple shape, and keywords
- It is being used in IBM's Multimedia Manager in OS/2, and in DB2 Extenders
Query by example using color histograms
- Example image:

- One of the colour histograms for the example image is shown in Fig.
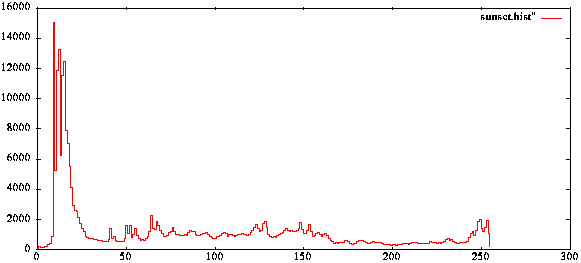
Colour Histogram of Image
- Store a histogram vector for each image in the database,
Compare images using mean squared difference,
Return images sorted by this metric.
- We'll find the images displayed in Fig.

Result of QBIC Search
- The method has the following advantages:
- Very, very fast
- Easily implemented
- Invariant to small changes in camera angle (and sometimes large ones!)
- The method has the following disadvantages:
- Sensitive to illumination changes.
- Sensitive to different levels of gamma correction.
- Doesn't account for location of colour. The images in Fig. are equivalent

Equivalent Colour in QBIC
Could use three additional colour edge images and their histograms to solve this problem.
Color constancy problems: two otherwise equivalent scenes will have different histograms depending on the colour of the incident light.
Possible variations on the theme
- Use other metrics: mean squared difference, mean absolute difference, cosine of angle, etc.
- Use dominant colours - k bins in the histogram that have larger counts
- Use other colour spaces, and/or uneven weights (e.g. 8 bits for green, 5 red, 3 blue) -> perceptual weighting
- Also, colour histogramming can be augmented by other simple statistical measures, e.g. mean brightness, moments, etc.
Other Queries in QBIC
- By texture: coarseness ("edgeness"), contrast, and edge directionality.
- By sketching: Sketch a shape and use it for a pattern match (the current demo version doesn't work well).
- By keywords: Often there's a set of keywords and other textual data associated with a picture.
References:
- Multimedia : Computing, Communications & Applications by Ralf Steinmetz and Klara Nahrstedt, Pearson Ed.
2. Multimedia Systems Design by Prabhat K. Andleigh & Kiran Thakrar, PHI.
3. Principles of Multimedia by Parekh, TMH.




