UNIT 3
Learning
Machine Learning (ML) is an automated learning with little or no human intervention. It involves programming computers so that they learn from the available inputs. The main purpose of machine learning is to explore and construct algorithms that can learn from the previous data and make predictions on new input data.
The input to a learning algorithm is training data, representing experience, and the output is any expertise, which usually takes the form of another algorithm that can perform a task. The input data to a machine learning system can be numerical, textual, audio, visual, or multimedia. The corresponding output data of the system can be a floating-point number, for instance, the velocity of a rocket, an integer representing a category or a class, for example, a pigeon or a sunflower from image recognition.
In this chapter, we will learn about the training data our programs will access and how learning process is automated and how the success and performance of such machine learning algorithms is evaluated.
Concepts of Learning
Learning is the process of converting experience into expertise or knowledge.
Learning can be broadly classified into three categories, as mentioned below, based on the nature of the learning data and interaction between the learner and the environment.
- Supervised Learning
- Unsupervised Learning
- Semi-supervised Learning
Similarly, there are four categories of machine learning algorithms as shown below −
- Supervised learning algorithm
- Unsupervised learning algorithm
- Semi-supervised learning algorithm
- Reinforcement learning algorithm
However, the most commonly used ones are supervised and unsupervised learning.
Supervised Learning
Supervised learning is commonly used in real world applications, such as face and speech recognition, products or movie recommendations, and sales forecasting. Supervised learning can be further classified into two types - Regression and Classification.
Regression trains on and predicts a continuous-valued response, for example predicting real estate prices.
Classification attempts to find the appropriate class label, such as analyzing positive/negative sentiment, male and female persons, benign and malignant tumors, secure and unsecure loans etc.
In supervised learning, learning data comes with description, labels, targets or desired outputs and the objective is to find a general rule that maps inputs to outputs. This kind of learning data is called labeled data. The learned rule is then used to label new data with unknown outputs.
Supervised learning involves building a machine learning model that is based on labeled samples. For example, if we build a system to estimate the price of a plot of land or a house based on various features, such as size, location, and so on, we first need to create a database and label it. We need to teach the algorithm what features correspond to what prices. Based on this data, the algorithm will learn how to calculate the price of real estate using the values of the input features.
Supervised learning deals with learning a function from available training data. Here, a learning algorithm analyzes the training data and produces a derived function that can be used for mapping new examples. There are many supervised learning algorithms such as Logistic Regression, Neural networks, Support Vector Machines (SVMs), and Naive Bayes classifiers.
Common examples of supervised learning include classifying e-mails into spam and not-spam categories, labeling webpages based on their content, and voice recognition.
Unsupervised Learning
Unsupervised learning is used to detect anomalies, outliers, such as fraud or defective equipment, or to group customers with similar behaviors for a sales campaign. It is the opposite of supervised learning. There is no labeled data here.
When learning data contains only some indications without any description or labels, it is up to the coder or to the algorithm to find the structure of the underlying data, to discover hidden patterns, or to determine how to describe the data. This kind of learning data is called unlabeled data.
Suppose that we have a number of data points, and we want to classify them into several groups. We may not exactly know what the criteria of classification would be. So, an unsupervised learning algorithm tries to classify the given dataset into a certain number of groups in an optimum way.
Unsupervised learning algorithms are extremely powerful tools for analyzing data and for identifying patterns and trends. They are most commonly used for clustering similar input into logical groups. Unsupervised learning algorithms include Kmeans, Random Forests, Hierarchical clustering and so on.
Semi-supervised Learning
If some learning samples are labeled, but some other are not labeled, then it is semi-supervised learning. It makes use of a large amount of unlabeled data for training and a small amount of labeled data for testing. Semi-supervised learning is applied in cases where it is expensive to acquire a fully labeled dataset while more practical to label a small subset. For example, it often requires skilled experts to label certain remote sensing images, and lots of field experiments to locate oil at a particular location, while acquiring unlabeled data is relatively easy.
Reinforcement Learning
Here learning data gives feedback so that the system adjusts to dynamic conditions in order to achieve a certain objective. The system evaluates its performance based on the feedback responses and reacts accordingly. The best known instances include self-driving cars and chess master algorithm AlphaGo.
Purpose of Machine Learning
Machine learning can be seen as a branch of AI or Artificial Intelligence, since, the ability to change experience into expertise or to detect patterns in complex data is a mark of human or animal intelligence.
As a field of science, machine learning shares common concepts with other disciplines such as statistics, information theory, game theory, and optimization.
As a subfield of information technology, its objective is to program machines so that they will learn.
However, it is to be seen that, the purpose of machine learning is not building an automated duplication of intelligent behavior, but using the power of computers to complement and supplement human intelligence. For example, machine learning programs can scan and process huge databases detecting patterns that are beyond the scope of human perception.
Introduction to K-Means Algorithm
K-means clustering algorithm computes the centroids and iterates until we it finds optimal centroid. It assumes that the number of clusters are already known. It is also called flat clustering algorithm. The number of clusters identified from data by algorithm is represented by ‘K’ in K-means.
In this algorithm, the data points are assigned to a cluster in such a manner that the sum of the squared distance between the data points and centroid would be minimum. It is to be understood that less variation within the clusters will lead to more similar data points within same cluster.
Working of K-Means Algorithm
We can understand the working of K-Means clustering algorithm with the help of following steps −
Step 1 − First, we need to specify the number of clusters, K, need to be generated by this algorithm.
Step 2 − Next, randomly select K data points and assign each data point to a cluster. In simple words, classify the data based on the number of data points.
Step 3 − Now it will compute the cluster centroids.
Step 4 − Next, keep iterating the following until we find optimal centroid which is the assignment of data points to the clusters that are not changing any more
- 4.1 − First, the sum of squared distance between data points and centroids would be computed.
- 4.2 − Now, we have to assign each data point to the cluster that is closer than other cluster (centroid).
- 4.3 − At last compute the centroids for the clusters by taking the average of all data points of that cluster.
K-means follows Expectation-Maximization approach to solve the problem. The Expectation-step is used for assigning the data points to the closest cluster and the Maximization-step is used for computing the centroid of each cluster.
While working with K-means algorithm we need to take care of the following things −
- While working with clustering algorithms including K-Means, it is recommended to standardize the data because such algorithms use distance-based measurement to determine the similarity between data points.
- Due to the iterative nature of K-Means and random initialization of centroids, K-Means may stick in a local optimum and may not converge to global optimum. That is why it is recommended to use different initializations of centroids.
Implementation in Python
The following two examples of implementing K-Means clustering algorithm will help us in its better understanding −
Example 1
It is a simple example to understand how k-means works. In this example, we are going to first generate 2D dataset containing 4 different blobs and after that will apply k-means algorithm to see the result.
First, we will start by importing the necessary packages −
%matplotlib inline
Import matplotlib.pyplot as plt
Import seaborn as sns; sns.set()
Import numpy as np
From sklearn.cluster import KMeans
The following code will generate the 2D, containing four blobs −
From sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Next, the following code will help us to visualize the dataset −
Plt.scatter(X[:, 0], X[:, 1], s = 20);
Plt.show()
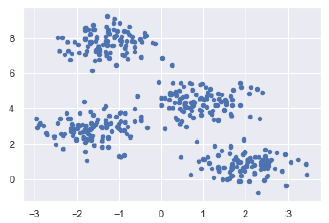
Next, make an object of KMeans along with providing number of clusters, train the model and do the prediction as follows −
Kmeans = KMeans(n_clusters = 4)
Kmeans.fit(X)
y_kmeans = kmeans.predict(X)
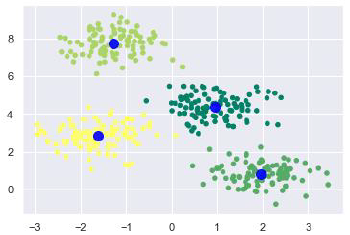
Now, with the help of following code we can plot and visualize the cluster’s centers picked by k-means Python estimator −
From sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Next, the following code will help us to visualize the dataset −
Plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 20, cmap = 'summer')
Centers = kmeans.cluster_centers_
Plt.scatter(centers[:, 0], centers[:, 1], c = 'blue', s = 100, alpha = 0.9);
Plt.show()
Example 2
Let us move to another example in which we are going to apply K-means clustering on simple digits dataset. K-means will try to identify similar digits without using the original label information.
First, we will start by importing the necessary packages −
%matplotlib inline
Import matplotlib.pyplot as plt
Import seaborn as sns; sns.set()
Import numpy as np
From sklearn.cluster import KMeans
Next, load the digit dataset from sklearn and make an object of it. We can also find number of rows and columns in this dataset as follows −
From sklearn.datasets import load_digits
Digits = load_digits()
Digits.data.shape
Output
(1797, 64)
The above output shows that this dataset is having 1797 samples with 64 features.
We can perform the clustering as we did in Example 1 above −
Kmeans = KMeans(n_clusters = 10, random_state = 0)
Clusters = kmeans.fit_predict(digits.data)
Kmeans.cluster_centers_.shape
Output
(10, 64)
The above output shows that K-means created 10 clusters with 64 features.
Fig, ax = plt.subplots(2, 5, figsize=(8, 3))
Centers = kmeans.cluster_centers_.reshape(10, 8, 8)
For axi, center in zip(ax.flat, centers):
Axi.set(xticks=[], yticks=[])
Axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
Output
As output, we will get following image showing clusters centers learned by k-means.
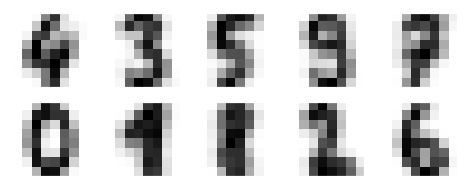
The following lines of code will match the learned cluster labels with the true labels found in them −
From scipy.stats import mode
Labels = np.zeros_like(clusters)
For i in range(10):
Mask = (clusters == i)
Labels[mask] = mode(digits.target[mask])[0]
Next, we can check the accuracy as follows −
From sklearn.metrics import accuracy_score
Accuracy_score(digits.target, labels)
Output
0.7935447968836951
The above output shows that the accuracy is around 80%.
Advantages and Disadvantages
Advantages
The following are some advantages of K-Means clustering algorithms −
- It is very easy to understand and implement.
- If we have large number of variables then, K-means would be faster than Hierarchical clustering.
- On re-computation of centroids, an instance can change the cluster.
- Tighter clusters are formed with K-means as compared to Hierarchical clustering.
Disadvantages
The following are some disadvantages of K-Means clustering algorithms −
- It is a bit difficult to predict the number of clusters i.e. the value of k.
- Output is strongly impacted by initial inputs like number of clusters (value of k)
- Order of data will have strong impact on the final output.
- It is very sensitive to rescaling. If we will rescale our data by means of normalization or standardization, then the output will completely change.
- It is not good in doing clustering job if the clusters have a complicated geometric shape.
Applications of K-Means Clustering Algorithm
The main goals of cluster analysis are −
- To get a meaningful intuition from the data we are working with.
- Cluster-then-predict where different models will be built for different subgroups.
To fulfill the above-mentioned goals, K-means clustering is performing well enough. It can be used in following applications −
- Market segmentation
- Document Clustering
- Image segmentation
- Image compression
- Customer segmentation
- Analyzing the trend on dynamic data
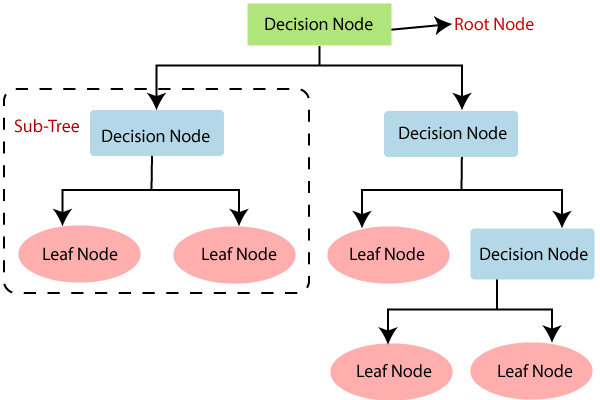
- Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems. It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome.
- In a Decision tree, there are two nodes, which are the Decision Node and Leaf Node. Decision nodes are used to make any decision and have multiple branches, whereas Leaf nodes are the output of those decisions and do not contain any further branches.
- The decisions or the test are performed on the basis of features of the given dataset.
- It is a graphical representation for getting all the possible solutions to a problem/decision based on given conditions.
- It is called a decision tree because, similar to a tree, it starts with the root node, which expands on further branches and constructs a tree-like structure.
- In order to build a tree, we use the CART algorithm, which stands for Classification and Regression Tree algorithm.
- A decision tree simply asks a question, and based on the answer (Yes/No), it further split the tree into subtrees.
- Below diagram explains the general structure of a decision tree:
Note: A decision tree can contain categorical data (YES/NO) as well as numeric data.
Why use Decision Trees?
There are various algorithms in Machine learning, so choosing the best algorithm for the given dataset and problem is the main point to remember while creating a machine learning model. Below are the two reasons for using the Decision tree:
- Decision Trees usually mimic human thinking ability while making a decision, so it is easy to understand.
- The logic behind the decision tree can be easily understood because it shows a tree-like structure.
Decision Tree Terminologies
Root Node: Root node is from where the decision tree starts. It represents the entire dataset, which further gets divided into two or more homogeneous sets.
Leaf Node: Leaf nodes are the final output node, and the tree cannot be segregated further after getting a leaf node.
Splitting: Splitting is the process of dividing the decision node/root node into sub-nodes according to the given conditions.
Branch/Sub Tree: A tree formed by splitting the tree.
Pruning: Pruning is the process of removing the unwanted branches from the tree.
Parent/Child node: The root node of the tree is called the parent node, and other nodes are called the child nodes.
How does the Decision Tree algorithm Work?
In a decision tree, for predicting the class of the given dataset, the algorithm starts from the root node of the tree. This algorithm compares the values of root attribute with the record (real dataset) attribute and, based on the comparison, follows the branch and jumps to the next node.
For the next node, the algorithm again compares the attribute value with the other sub-nodes and move further. It continues the process until it reaches the leaf node of the tree. The complete process can be better understood using the below algorithm:
- Step-1: Begin the tree with the root node, says S, which contains the complete dataset.
- Step-2: Find the best attribute in the dataset using Attribute Selection Measure (ASM).
- Step-3: Divide the S into subsets that contains possible values for the best attributes.
- Step-4: Generate the decision tree node, which contains the best attribute.
- Step-5: Recursively make new decision trees using the subsets of the dataset created in step -3. Continue this process until a stage is reached where you cannot further classify the nodes and called the final node as a leaf node.
Example: Suppose there is a candidate who has a job offer and wants to decide whether he should accept the offer or Not. So, to solve this problem, the decision tree starts with the root node (Salary attribute by ASM). The root node splits further into the next decision node (distance from the office) and one leaf node based on the corresponding labels. The next decision node further gets split into one decision node (Cab facility) and one leaf node. Finally, the decision node splits into two leaf nodes (Accepted offers and Declined offer). Consider the below diagram:
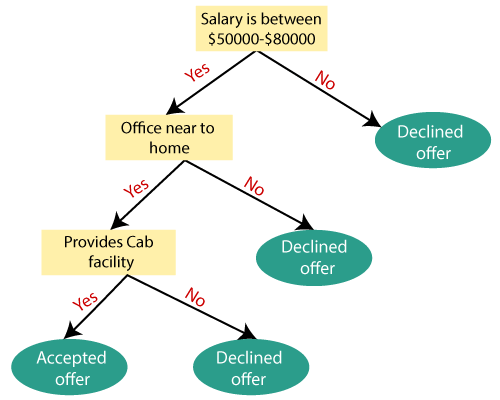
Attribute Selection Measures
While implementing a Decision tree, the main issue arises that how to select the best attribute for the root node and for sub-nodes. So, to solve such problems there is a technique which is called as Attribute selection measure or ASM. By this measurement, we can easily select the best attribute for the nodes of the tree. There are two popular techniques for ASM, which are:
- Information Gain
- Gini Index
1. Information Gain:
- Information gain is the measurement of changes in entropy after the segmentation of a dataset based on an attribute.
- It calculates how much information a feature provides us about a class.
- According to the value of information gain, we split the node and build the decision tree.
- A decision tree algorithm always tries to maximize the value of information gain, and a node/attribute having the highest information gain is split first. It can be calculated using the below formula:
- Information Gain= Entropy(S)- [(Weighted Avg) *Entropy(each feature)
Entropy: Entropy is a metric to measure the impurity in a given attribute. It specifies randomness in data. Entropy can be calculated as:
Entropy(s)= -P(yes)log2 P(yes)- P(no) log2 P(no)
Where,
- S= Total number of samples
- P(yes)= probability of yes
- P(no)= probability of no
2. Gini Index:
- Gini index is a measure of impurity or purity used while creating a decision tree in the CART(Classification and Regression Tree) algorithm.
- An attribute with the low Gini index should be preferred as compared to the high Gini index.
- It only creates binary splits, and the CART algorithm uses the Gini index to create binary splits.
- Gini index can be calculated using the below formula:
Gini Index= 1- ∑jPj2
Pruning: Getting an Optimal Decision tree
Pruning is a process of deleting the unnecessary nodes from a tree in order to get the optimal decision tree.
A too-large tree increases the risk of overfitting, and a small tree may not capture all the important features of the dataset. Therefore, a technique that decreases the size of the learning tree without reducing accuracy is known as Pruning. There are mainly two types of tree pruning technology used:
- Cost Complexity Pruning
- Reduced Error Pruning.
Advantages of the Decision Tree
- It is simple to understand as it follows the same process which a human follow while making any decision in real-life.
- It can be very useful for solving decision-related problems.
- It helps to think about all the possible outcomes for a problem.
- There is less requirement of data cleaning compared to other algorithms.
Disadvantages of the Decision Tree
- The decision tree contains lots of layers, which makes it complex.
- It may have an overfitting issue, which can be resolved using the Random Forest algorithm.
- For more class labels, the computational complexity of the decision tree may increase.
Python Implementation of Decision Tree
Now we will implement the Decision tree using Python. For this, we will use the dataset "user_data.csv," which we have used in previous classification models. By using the same dataset, we can compare the Decision tree classifier with other classification models such as KNN SVM, LogisticRegression, etc.
Steps will also remain the same, which are given below:
- Data Pre-processing step
- Fitting a Decision-Tree algorithm to the Training set
- Predicting the test result
- Test accuracy of the result(Creation of Confusion matrix)
- Visualizing the test set result.
1. Data Pre-Processing Step:
Below is the code for the pre-processing step:
- # importing libraries
- Import numpy as nm
- Import matplotlib.pyplot as mtp
- Import pandas as pd
- #importing datasets
- Data_set= pd.read_csv('user_data.csv')
- #Extracting Independent and dependent Variable
- x= data_set.iloc[:, [2,3]].values
- y= data_set.iloc[:, 4].values
- # Splitting the dataset into training and test set.
- From sklearn.model_selection import train_test_split
- x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.25, random_state=0)
- #feature Scaling
- From sklearn.preprocessing import StandardScaler
- St_x= StandardScaler()
- x_train= st_x.fit_transform(x_train)
- x_test= st_x.transform(x_test)
In the above code, we have pre-processed the data. Where we have loaded the dataset, which is given as:
2. Fitting a Decision-Tree algorithm to the Training set
Now we will fit the model to the training set. For this, we will import the DecisionTreeClassifier class from sklearn.tree library. Below is the code for it:
- #Fitting Decision Tree classifier to the training set
- From sklearn.tree import DecisionTreeClassifier
- Classifier= DecisionTreeClassifier(criterion='entropy', random_state=0)
- Classifier.fit(x_train, y_train)
In the above code, we have created a classifier object, in which we have passed two main parameters;
- "criterion='entropy': Criterion is used to measure the quality of split, which is calculated by information gain given by entropy.
- Random_state=0": For generating the random states.
Below is the output for this:
Out[8]:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
Max_features=None, max_leaf_nodes=None,
Min_impurity_decrease=0.0, min_impurity_split=None,
Min_samples_leaf=1, min_samples_split=2,
Min_weight_fraction_leaf=0.0, presort=False,
Random_state=0, splitter='best')
3. Predicting the test result
Now we will predict the test set result. We will create a new prediction vector y_pred. Below is the code for it:
- #Predicting the test set result
- y_pred= classifier.predict(x_test)
Output:
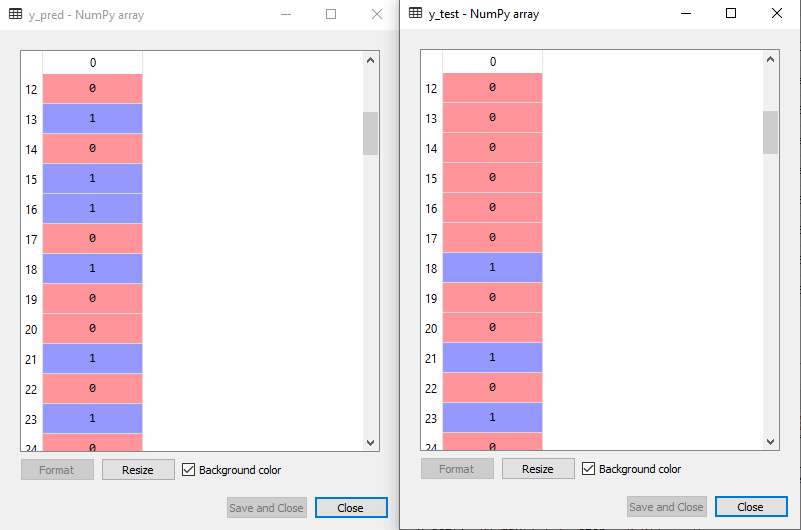
In the below output image, the predicted output and real test output are given. We can clearly see that there are some values in the prediction vector, which are different from the real vector values. These are prediction errors.
4. Test accuracy of the result (Creation of Confusion matrix)
In the above output, we have seen that there were some incorrect predictions, so if we want to know the number of correct and incorrect predictions, we need to use the confusion matrix. Below is the code for it:
- #Creating the Confusion matrix
- From sklearn.metrics import confusion_matrix
- Cm= confusion_matrix(y_test, y_pred)
Output:
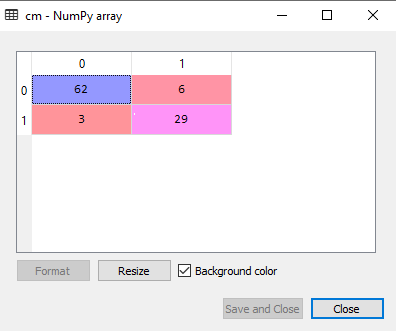
In the above output image, we can see the confusion matrix, which has 6+3= 9 incorrect predictions and62+29=91 correct predictions. Therefore, we can say that compared to other classification models, the Decision Tree classifier made a good prediction.
5. Visualizing the training set result:
Here we will visualize the training set result. To visualize the training set result we will plot a graph for the decision tree classifier. The classifier will predict yes or No for the users who have either Purchased or Not purchased the SUV car as we did in Logistic Regression. Below is the code for it:
- #Visulaizing the trianing set result
- From matplotlib.colors import ListedColormap
- x_set, y_set = x_train, y_train
- x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
- Nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
- Mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
- Alpha = 0.75, cmap = ListedColormap(('purple','green' )))
- Mtp.xlim(x1.min(), x1.max())
- Mtp.ylim(x2.min(), x2.max())
- Fori, j in enumerate(nm.unique(y_set)):
- Mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
- c = ListedColormap(('purple', 'green'))(i), label = j)
- Mtp.title('Decision Tree Algorithm (Training set)')
- Mtp.xlabel('Age')
- Mtp.ylabel('Estimated Salary')
- Mtp.legend()
- Mtp.show()
Output:
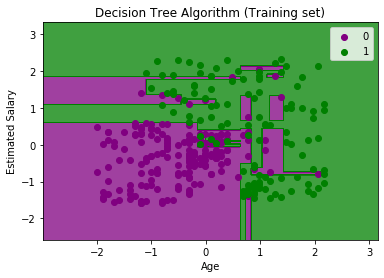
The above output is completely different from the rest classification models. It has both vertical and horizontal lines that are splitting the dataset according to the age and estimated salary variable.
As we can see, the tree is trying to capture each dataset, which is the case of overfitting.
6. Visualizing the test set result:
Visualization of test set result will be similar to the visualization of the training set except that the training set will be replaced with the test set.
- #Visulaizing the test set result
- From matplotlib.colors import ListedColormap
- x_set, y_set = x_test, y_test
- x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
- Nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
- Mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
- Alpha = 0.75, cmap = ListedColormap(('purple','green' )))
- Mtp.xlim(x1.min(), x1.max())
- Mtp.ylim(x2.min(), x2.max())
- Fori, j in enumerate(nm.unique(y_set)):
- Mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
- c = ListedColormap(('purple', 'green'))(i), label = j)
- Mtp.title('Decision Tree Algorithm(Test set)')
- Mtp.xlabel('Age')
- Mtp.ylabel('Estimated Salary')
- Mtp.legend()
- Mtp.show()
Output:
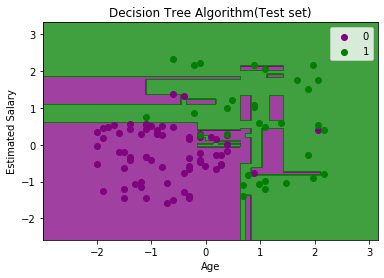
As we can see in the above image that there are some green data points within the purple region and vice versa. So, these are the incorrect predictions which we have discussed in the confusion matrix.
Yet another research area in AI, neural networks, is inspired from the natural neural network of human nervous system.
What are Artificial Neural Networks (ANNs)?
The inventor of the first neurocomputer, Dr. Robert Hecht-Nielsen, defines a neural network as −
"...a computing system made up of a number of simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs.”
Basic Structure of ANNs
The idea of ANNs is based on the belief that working of human brain by making the right connections, can be imitated using silicon and wires as living neurons and dendrites.
The human brain is composed of 86 billion nerve cells called neurons. They are connected to other thousand cells by Axons. Stimuli from external environment or inputs from sensory organs are accepted by dendrites. These inputs create electric impulses, which quickly travel through the neural network. A neuron can then send the message to other neuron to handle the issue or does not send it forward.
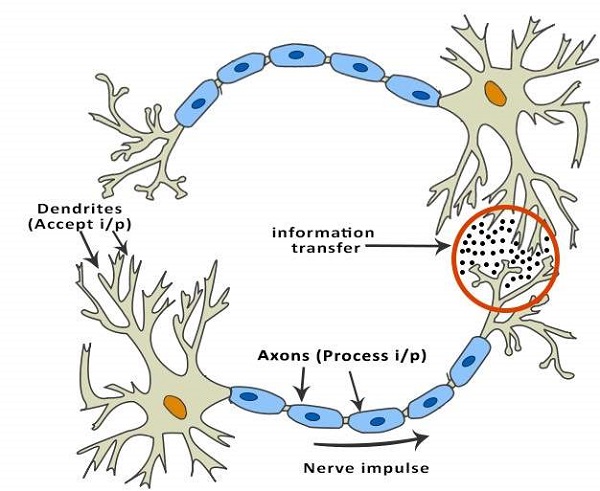
ANNs are composed of multiple nodes, which imitate biological neurons of human brain. The neurons are connected by links and they interact with each other. The nodes can take input data and perform simple operations on the data. The result of these operations is passed to other neurons. The output at each node is called its activation or node value.
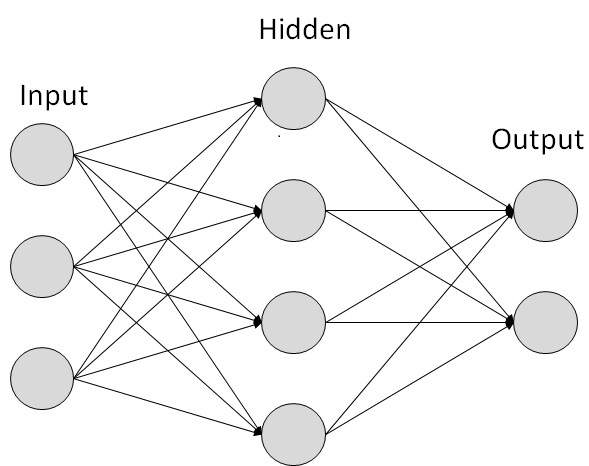
Each link is associated with weight. ANNs are capable of learning, which takes place by altering weight values. The following illustration shows a simple ANN −
Types of Artificial Neural Networks
There are two Artificial Neural Network topologies − FeedForward and Feedback.
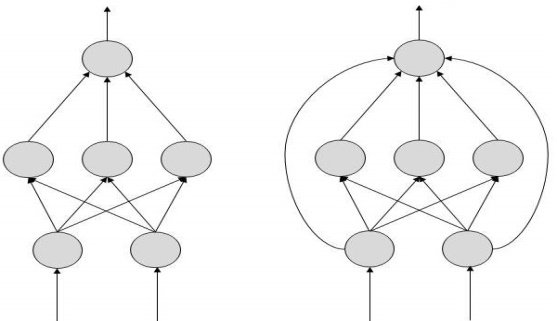
FeedForward ANN
In this ANN, the information flow is unidirectional. A unit sends information to other unit from which it does not receive any information. There are no feedback loops. They are used in pattern generation/recognition/classification. They have fixed inputs and outputs.
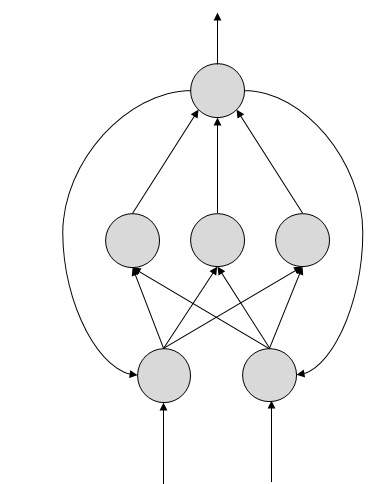
FeedBack ANN
Here, feedback loops are allowed. They are used in content addressable memories.
Working of ANNs
In the topology diagrams shown, each arrow represents a connection between two neurons and indicates the pathway for the flow of information. Each connection has a weight, an integer number that controls the signal between the two neurons.
If the network generates a “good or desired” output, there is no need to adjust the weights. However, if the network generates a “poor or undesired” output or an error, then the system alters the weights in order to improve subsequent results.
Machine Learning in ANNs
ANNs are capable of learning and they need to be trained. There are several learning strategies −
- Supervised Learning − It involves a teacher that is scholar than the ANN itself. For example, the teacher feeds some example data about which the teacher already knows the answers.
For example, pattern recognizing. The ANN comes up with guesses while recognizing. Then the teacher provides the ANN with the answers. The network then compares it guesses with the teacher’s “correct” answers and makes adjustments according to errors.
- Unsupervised Learning − It is required when there is no example data set with known answers. For example, searching for a hidden pattern. In this case, clustering i.e. dividing a set of elements into groups according to some unknown pattern is carried out based on the existing data sets present.
- Reinforcement Learning − This strategy built on observation. The ANN makes a decision by observing its environment. If the observation is negative, the network adjusts its weights to be able to make a different required decision the next time.
Back Propagation Algorithm
It is the training or learning algorithm. It learns by example. If you submit to the algorithm the example of what you want the network to do, it changes the network’s weights so that it can produce desired output for a particular input on finishing the training.
Back Propagation networks are ideal for simple Pattern Recognition and Mapping Tasks.
Bayesian Networks (BN)
These are the graphical structures used to represent the probabilistic relationship among a set of random variables. Bayesian networks are also called Belief Networks or Bayes Nets. BNs reason about uncertain domain.
In these networks, each node represents a random variable with specific propositions. For example, in a medical diagnosis domain, the node Cancer represents the proposition that a patient has cancer.
The edges connecting the nodes represent probabilistic dependencies among those random variables. If out of two nodes, one is affecting the other then they must be directly connected in the directions of the effect. The strength of the relationship between variables is quantified by the probability associated with each node.
There is an only constraint on the arcs in a BN that you cannot return to a node simply by following directed arcs. Hence the BNs are called Directed Acyclic Graphs (DAGs).
BNs are capable of handling multivalued variables simultaneously. The BN variables are composed of two dimensions −
- Range of prepositions
- Probability assigned to each of the prepositions.
Consider a finite set X = {X1, X2, …,Xn} of discrete random variables, where each variable Xi may take values from a finite set, denoted by Val(Xi). If there is a directed link from variable Xi to variable, Xj, then variable Xi will be a parent of variable Xj showing direct dependencies between the variables.
The structure of BN is ideal for combining prior knowledge and observed data. BN can be used to learn the causal relationships and understand various problem domains and to predict future events, even in case of missing data.
Building a Bayesian Network
A knowledge engineer can build a Bayesian network. There are a number of steps the knowledge engineer needs to take while building it.
Example problem − Lung cancer. A patient has been suffering from breathlessness. He visits the doctor, suspecting he has lung cancer. The doctor knows that barring lung cancer, there are various other possible diseases the patient might have such as tuberculosis and bronchitis.
Gather Relevant Information of Problem
- Is the patient a smoker? If yes, then high chances of cancer and bronchitis.
- Is the patient exposed to air pollution? If yes, what sort of air pollution?
- Take an X-Ray positive X-ray would indicate either TB or lung cancer.
Identify Interesting Variables
The knowledge engineer tries to answer the questions −
- Which nodes to represent?
- What values can they take? In which state can they be?
For now let us consider nodes, with only discrete values. The variable must take on exactly one of these values at a time.
Common types of discrete nodes are −
- Boolean nodes − They represent propositions, taking binary values TRUE (T) and FALSE (F).
- Ordered values − A node Pollution might represent and take values from {low, medium, high} describing degree of a patient’s exposure to pollution.
- Integral values − A node called Age might represent patient’s age with possible values from 1 to 120. Even at this early stage, modeling choices are being made.
Possible nodes and values for the lung cancer example −
Node Name | Type | Value | Nodes Creation |
Polution | Binary | {LOW, HIGH, MEDIUM} |  |
Smoker | Boolean | {TRUE, FASLE} | |
Lung-Cancer | Boolean | {TRUE, FASLE} | |
X-Ray | Binary | {Positive, Negative} |
Create Arcs between Nodes
Topology of the network should capture qualitative relationships between variables.
For example, what causes a patient to have lung cancer? - Pollution and smoking. Then add arcs from node Pollution and node Smoker to node Lung-Cancer.
Similarly if patient has lung cancer, then X-ray result will be positive. Then add arcs from node Lung-Cancer to node X-Ray.
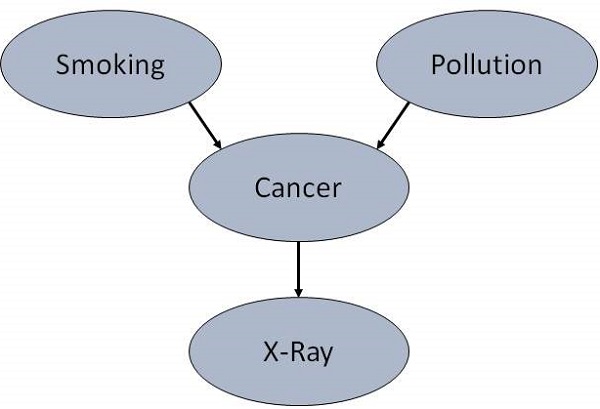
Specify Topology
Conventionally, BNs are laid out so that the arcs point from top to bottom. The set of parent nodes of a node X is given by Parents(X).
The Lung-Cancer node has two parents (reasons or causes): Pollution and Smoker, while node Smoker is an ancestor of node X-Ray. Similarly, X-Ray is a child (consequence or effects) of node Lung-Cancer and successor of nodes Smoker and Pollution.
Conditional Probabilities
Now quantify the relationships between connected nodes: this is done by specifying a conditional probability distribution for each node. As only discrete variables are considered here, this takes the form of a Conditional Probability Table (CPT).
First, for each node we need to look at all the possible combinations of values of those parent nodes. Each such combination is called an instantiation of the parent set. For each distinct instantiation of parent node values, we need to specify the probability that the child will take.
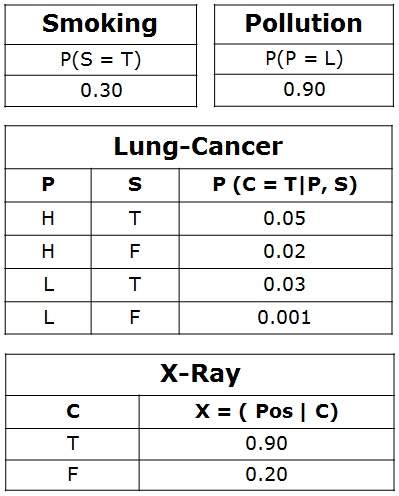
For example, the Lung-Cancer node’s parents are Pollution and Smoking. They take the possible values = { (H,T), ( H,F), (L,T), (L,F)}. The CPT specifies the probability of cancer for each of these cases as <0.05, 0.02, 0.03, 0.001> respectively.
Each node will have conditional probability associated as follows −
Applications of Neural Networks
They can perform tasks that are easy for a human but difficult for a machine −
- Aerospace − Autopilot aircrafts, aircraft fault detection.
- Automotive − Automobile guidance systems.
- Military − Weapon orientation and steering, target tracking, object discrimination, facial recognition, signal/image identification.
- Electronics − Code sequence prediction, IC chip layout, chip failure analysis, machine vision, voice synthesis.
- Financial − Real estate appraisal, loan advisor, mortgage screening, corporate bond rating, portfolio trading program, corporate financial analysis, currency value prediction, document readers, credit application evaluators.
- Industrial − Manufacturing process control, product design and analysis, quality inspection systems, welding quality analysis, paper quality prediction, chemical product design analysis, dynamic modeling of chemical process systems, machine maintenance analysis, project bidding, planning, and management.
- Medical − Cancer cell analysis, EEG and ECG analysis, prosthetic design, transplant time optimizer.
- Speech − Speech recognition, speech classification, text to speech conversion.
- Telecommunications − Image and data compression, automated information services, real-time spoken language translation.
- Transportation − Truck Brake system diagnosis, vehicle scheduling, routing systems.
- Software − Pattern Recognition in facial recognition, optical character recognition, etc.
- Time Series Prediction − ANNs are used to make predictions on stocks and natural calamities.
- Signal Processing − Neural networks can be trained to process an audio signal and filter it appropriately in the hearing aids.
- Control − ANNs are often used to make steering decisions of physical vehicles.
- Anomaly Detection − As ANNs are expert at recognizing patterns, they can also be trained to generate an output when something unusual occurs that misfits the pattern.
Deep learning is based on the branch of machine learning, which is a subset of artificial intelligence. Since neural networks imitate the human brain and so deep learning will do. In deep learning, nothing is programmed explicitly. Basically, it is a machine learning class that makes use of numerous nonlinear processing units so as to perform feature extraction as well as transformation. The output from each preceding layer is taken as input by each one of the successive layers.
Deep learning models are capable enough to focus on the accurate features themselves by requiring a little guidance from the programmer and are very helpful in solving out the problem of dimensionality. Deep learning algorithms are used, especially when we have a huge no of inputs and outputs.
Since deep learning has been evolved by the machine learning, which itself is a subset of artificial intelligence and as the idea behind the artificial intelligence is to mimic the human behavior, so same is "the idea of deep learning to build such algorithm that can mimic the brain".
Deep learning is implemented with the help of Neural Networks, and the idea behind the motivation of Neural network is the biological neurons, which is nothing but a brain cell.
Deep learning is a collection of statistical techniques of machine learning for learning feature hierarchies that are actually based on artificial neural networks.
So basically, deep learning is implemented by the help of deep networks, which are nothing but neural networks with multiple hidden layers.
Example of Deep Learning
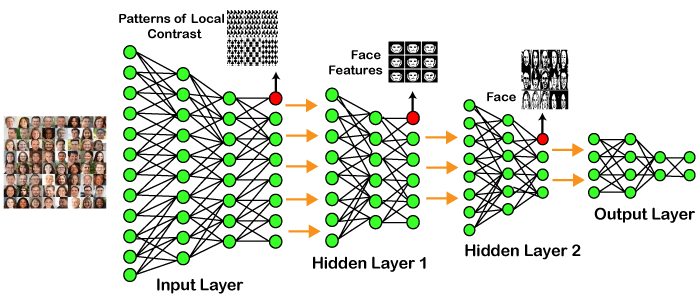
In the example given above, we provide the raw data of images to the first layer of the input layer. After then, these input layer will determine the patterns of local contrast that means it will differentiate on the basis of colors, luminosity, etc. Then the 1st hidden layer will determine the face feature, i.e., it will fixate on eyes, nose, and lips, etc. And then, it will fixate those face features on the correct face template. So, in the 2nd hidden layer, it will actually determine the correct face here as it can be seen in the above image, after which it will be sent to the output layer. Likewise, more hidden layers can be added to solve more complex problems, for example, if you want to find out a particular kind of face having large or light complexions. So, as and when the hidden layers increase, we are able to solve complex problems.
Architectures
- Deep Neural Networks
It is a neural network that incorporates the complexity of a certain level, which means several numbers of hidden layers are encompassed in between the input and output layers. They are highly proficient on model and process non-linear associations. - Deep Belief Networks
A deep belief network is a class of Deep Neural Network that comprises of multi-layer belief networks.
Steps to perform DBN:- With the help of the Contrastive Divergence algorithm, a layer of features is learned from perceptible units.
- Next, the formerly trained features are treated as visible units, which perform learning of features.
- Lastly, when the learning of the final hidden layer is accomplished, then the whole DBN is trained.
- Recurrent Neural Networks
It permits parallel as well as sequential computation, and it is exactly similar to that of the human brain (large feedback network of connected neurons). Since they are capable enough to reminisce all of the imperative things related to the input they have received, so they are more precise.
Deep learning applications
- Self-Driving Cars
In self-driven cars, it is able to capture the images around it by processing a huge amount of data, and then it will decide which actions should be incorporated to take a left or right or should it stop. So, accordingly, it will decide what actions it should take, which will further reduce the accidents that happen every year. - Voice Controlled Assistance
When we talk about voice control assistance, then Siri is the one thing that comes into our mind. So, you can tell Siri whatever you want it to do it for you, and it will search it for you and display it for you. - Automatic Image Caption Generation
Whatever image that you upload, the algorithm will work in such a way that it will generate caption accordingly. If you say blue colored eye, it will display a blue-colored eye with a caption at the bottom of the image. - Automatic Machine Translation
With the help of automatic machine translation, we are able to convert one language into another with the help of deep learning.
Limitations
- It only learns through the observations.
- It comprises of biases issues.
Advantages
- It lessens the need for feature engineering.
- It eradicates all those costs that are needless.
- It easily identifies difficult defects.
- It results in the best-in-class performance on problems.
Disadvantages
- It requires an ample amount of data.
- It is quite expensive to train.
- It does not have strong theoretical groundwork.
Text Books
1. S. Russell and P. Norvig, “Artificial Intelligence: A Modern Approach,” Prentice Hall
2. E. Rich, K. Knight and S. B. Nair, “Artificial Intelligence,” TMH
References
1. C. Bishop,“Pattern Recognition and Machine Learning," Springer
2. D. W. Patterson, “Introduction to artificial intelligence and expert systems,” Prentice Hall
3. A. C.Staugaard, Jr., “Robotics and AI: An Introduction to Applied Machine Intelligence,” Prentice Hall
4. I. Bratko, “Prolog Programming for Artificial Intelligence,” Addison-Wesley
5. S. O. Haykin, “Neural Networks and Learning Machines,” Prentice Hall
6. D.Jurafsky and J. H. Martin,“Speech and Language Processing,” Prentice Hall




