UNIT 4
Advanced Topics
Computer vision is a field of study focused on the problem of helping computers to see.
At an abstract level, the goal of computer vision problems is to use the observed image data to infer something about the world.
It is a multidisciplinary field that could broadly be called a subfield of artificial intelligence and machine learning, which may involve the use of specialized methods and make use of general learning algorithms.
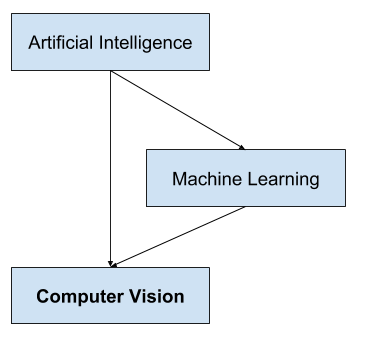
Overview of the Relationship of Artificial Intelligence and Computer Vision
As a multidisciplinary area of study, it can look messy, with techniques borrowed and reused from a range of disparate engineering and computer science fields.
One particular problem in vision may be easily addressed with a hand-crafted statistical method, whereas another may require a large and complex ensemble of generalized machine learning algorithms.
Computer vision as a field is an intellectual frontier. Like any frontier, it is exciting and disorganized, and there is often no reliable authority to appeal to. Many useful ideas have no theoretical grounding, and some theories are useless in practice; developed areas are widely scattered, and often one looks completely inaccessible from the other.
The goal of computer vision is to understand the content of digital images. Typically, this involves developing methods that attempt to reproduce the capability of human vision.
Understanding the content of digital images may involve extracting a description from the image, which may be an object, a text description, a three-dimensional model, and so on.
Computer vision is the automated extraction of information from images. Information can mean anything from 3D models, camera position, object detection and recognition to grouping and searching image content.
Computer Vision and Image Processing
Computer vision is distinct from image processing.
Image processing is the process of creating a new image from an existing image, typically simplifying or enhancing the content in some way. It is a type of digital signal processing and is not concerned with understanding the content of an image.
A given computer vision system may require image processing to be applied to raw input, e.g. Pre-processing images.
Examples of image processing include:
- Normalizing photometric properties of the image, such as brightness or color.
- Cropping the bounds of the image, such as centering an object in a photograph.
- Removing digital noise from an image, such as digital artifacts from low light levels.
Challenge of Computer Vision
Helping computers to see turns out to be very hard.
The goal of computer vision is to extract useful information from images. This has proved a surprisingly challenging task; it has occupied thousands of intelligent and creative minds over the last four decades, and despite this we are still far from being able to build a general-purpose “seeing machine.”
Computer vision seems easy, perhaps because it is so effortless for humans.
Initially, it was believed to be a trivially simple problem that could be solved by a student connecting a camera to a computer. After decades of research, “computer vision” remains unsolved, at least in terms of meeting the capabilities of human vision.
Making a computer see was something that leading experts in the field of Artificial Intelligence thought to be at the level of difficulty of a summer student’s project back in the sixties. Forty years later the task is still unsolved and seems formidable.
One reason is that we don’t have a strong grasp of how human vision works.
Studying biological vision requires an understanding of the perception organs like the eyes, as well as the interpretation of the perception within the brain. Much progress has been made, both in charting the process and in terms of discovering the tricks and shortcuts used by the system, although like any study that involves the brain, there is a long way to go.
Perceptual psychologists have spent decades trying to understand how the visual system works and, even though they can devise optical illusions to tease apart some of its principles, a complete solution to this puzzle remains elusive
Another reason why it is such a challenging problem is because of the complexity inherent in the visual world.
A given object may be seen from any orientation, in any lighting conditions, with any type of occlusion from other objects, and so on. A true vision system must be able to “see” in any of an infinite number of scenes and still extract something meaningful.
Computers work well for tightly constrained problems, not open unbounded problems like visual perception.
Tasks in Computer Vision
Nevertheless, there has been progress in the field, especially in recent years with commodity systems for optical character recognition and face detection in cameras and smartphones.
Computer vision is at an extraordinary point in its development. The subject itself has been around since the 1960s, but only recently has it been possible to build useful computer systems using ideas from computer vision.
- Optical character recognition (OCR)
- Machine inspection
- Retail (e.g. Automated checkouts)
- 3D model building (photogrammetry)
- Medical imaging
- Automotive safety
- Match move (e.g. Merging CGI with live actors in movies)
- Motion capture (mocap)
- Surveillance
- Fingerprint recognition and biometrics
It is a broad area of study with many specialized tasks and techniques, as well as specializations to target application domains.
Computer vision has a wide variety of applications, both old (e.g., mobile robot navigation, industrial inspection, and military intelligence) and new (e.g., human computer interaction, image retrieval in digital libraries, medical image analysis, and the realistic rendering of synthetic scenes in computer graphics).
It may be helpful to zoom in on some of the more simpler computer vision tasks that you are likely to encounter or be interested in solving given the vast number of publicly available digital photographs and videos available.
Many popular computer vision applications involve trying to recognize things in photographs; for example:
- Object Classification: What broad category of object is in this photograph?
- Object Identification: Which type of a given object is in this photograph?
- Object Verification: Is the object in the photograph?
- Object Detection: Where are the objects in the photograph?
- Object Landmark Detection: What are the key points for the object in the photograph?
- Object Segmentation: What pixels belong to the object in the image?
- Object Recognition: What objects are in this photograph and where are they?
Other common examples are related to information retrieval; for example: finding images like an image or images that contain an object.
Summary
In this post, you discovered a gentle introduction to the field of computer vision.
Specifically, you learned:
- The goal of the field of computer vision and its distinctness from image processing.
- What makes the problem of computer vision challenging.
- Typical problems or tasks pursued in computer vision.
Natural Language Processing (NLP) refers to AI method of communicating with an intelligent systems using a natural language such as English.
Processing of Natural Language is required when you want an intelligent system like robot to perform as per your instructions, when you want to hear decision from a dialogue based clinical expert system, etc.
The field of NLP involves making computers to perform useful tasks with the natural languages humans use. The input and output of an NLP system can be −
- Speech
- Written Text
Components of NLP
There are two components of NLP as given −
Natural Language Understanding (NLU)
Understanding involves the following tasks −
- Mapping the given input in natural language into useful representations.
- Analyzing different aspects of the language.
Natural Language Generation (NLG)
It is the process of producing meaningful phrases and sentences in the form of natural language from some internal representation.
It involves −
- Text planning − It includes retrieving the relevant content from knowledge base.
- Sentence planning − It includes choosing required words, forming meaningful phrases, setting tone of the sentence.
- Text Realization − It is mapping sentence plan into sentence structure.
The NLU is harder than NLG.
Difficulties in NLU
NL has an extremely rich form and structure.
It is very ambiguous. There can be different levels of ambiguity −
- Lexical ambiguity − It is at very primitive level such as word-level.
- For example, treating the word “board” as noun or verb?
- Syntax Level ambiguity − A sentence can be parsed in different ways.
- For example, “He lifted the beetle with red cap.” − Did he use cap to lift the beetle or he lifted a beetle that had red cap?
- Referential ambiguity − Referring to something using pronouns. For example, Rima went to Gauri. She said, “I am tired.” − Exactly who is tired?
- One input can mean different meanings.
- Many inputs can mean the same thing.
NLP Terminology
- Phonology − It is study of organizing sound systematically.
- Morphology − It is a study of construction of words from primitive meaningful units.
- Morpheme − It is primitive unit of meaning in a language.
- Syntax − It refers to arranging words to make a sentence. It also involves determining the structural role of words in the sentence and in phrases.
- Semantics − It is concerned with the meaning of words and how to combine words into meaningful phrases and sentences.
- Pragmatics − It deals with using and understanding sentences in different situations and how the interpretation of the sentence is affected.
- Discourse − It deals with how the immediately preceding sentence can affect the interpretation of the next sentence.
- World Knowledge − It includes the general knowledge about the world.
Steps in NLP
There are general five steps −
- Lexical Analysis − It involves identifying and analyzing the structure of words. Lexicon of a language means the collection of words and phrases in a language. Lexical analysis is dividing the whole chunk of txt into paragraphs, sentences, and words.
- Syntactic Analysis (Parsing) − It involves analysis of words in the sentence for grammar and arranging words in a manner that shows the relationship among the words. The sentence such as “The school goes to boy” is rejected by English syntactic analyzer.
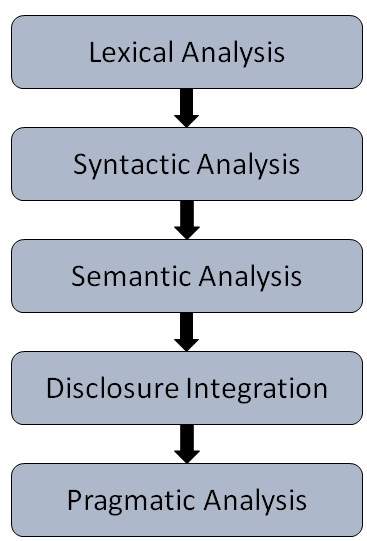
- Semantic Analysis − It draws the exact meaning or the dictionary meaning from the text. The text is checked for meaningfulness. It is done by mapping syntactic structures and objects in the task domain. The semantic analyzer disregards sentence such as “hot ice-cream”.
- Discourse Integration − The meaning of any sentence depends upon the meaning of the sentence just before it. In addition, it also brings about the meaning of immediately succeeding sentence.
- Pragmatic Analysis − During this, what was said is re-interpreted on what it actually meant. It involves deriving those aspects of language which require real world knowledge.
Implementation Aspects of Syntactic Analysis
There are a number of algorithms researchers have developed for syntactic analysis, but we consider only the following simple methods −
- Context-Free Grammar
- Top-Down Parser
Let us see them in detail −
Context-Free Grammar
It is the grammar that consists rules with a single symbol on the left-hand side of the rewrite rules. Let us create grammar to parse a sentence −
“The bird pecks the grains”
Articles (DET) − a | an | the
Nouns − bird | birds | grain | grains
Noun Phrase (NP) − Article + Noun | Article + Adjective + Noun
= DET N | DET ADJ N
Verbs − pecks | pecking | pecked
Verb Phrase (VP) − NP V | V NP
Adjectives (ADJ) − beautiful | small | chirping
The parse tree breaks down the sentence into structured parts so that the computer can easily understand and process it. In order for the parsing algorithm to construct this parse tree, a set of rewrite rules, which describe what tree structures are legal, need to be constructed.
These rules say that a certain symbol may be expanded in the tree by a sequence of other symbols. According to first order logic rule, if there are two strings Noun Phrase (NP) and Verb Phrase (VP), then the string combined by NP followed by VP is a sentence. The rewrite rules for the sentence are as follows −
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | the
ADJ → beautiful | perching
N → bird | birds | grain | grains
V → peck | pecks | pecking
The parse tree can be created as shown −
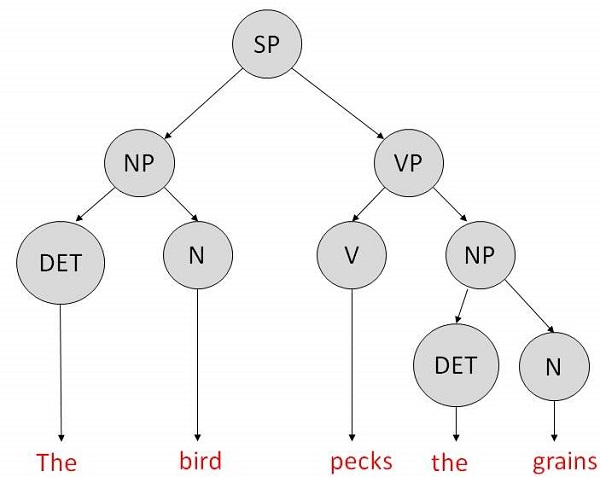
Now consider the above rewrite rules. Since V can be replaced by both, "peck" or "pecks", sentences such as "The bird peck the grains" can be wrongly permitted. i. e. The subject-verb agreement error is approved as correct.
Merit − The simplest style of grammar, therefore widely used one.
Demerits −
- They are not highly precise. For example, “The grains peck the bird”, is a syntactically correct according to parser, but even if it makes no sense, parser takes it as a correct sentence.
- To bring out high precision, multiple sets of grammar need to be prepared. It may require a completely different sets of rules for parsing singular and plural variations, passive sentences, etc., which can lead to creation of huge set of rules that are unmanageable.
Top-Down Parser
Here, the parser starts with the S symbol and attempts to rewrite it into a sequence of terminal symbols that matches the classes of the words in the input sentence until it consists entirely of terminal symbols.
These are then checked with the input sentence to see if it matched. If not, the process is started over again with a different set of rules. This is repeated until a specific rule is found which describes the structure of the sentence.
Merit − It is simple to implement.
Demerits −
- It is inefficient, as the search process has to be repeated if an error occurs.
- Slow speed of working.
An expert system is a computer program that is designed to solve complex problems and to provide decision-making ability like a human expert. It performs this by extracting knowledge from its knowledge base using the reasoning and inference rules according to the user queries.
The expert system is a part of AI, and the first ES was developed in the year 1970, which was the first successful approach of artificial intelligence. It solves the most complex issue as an expert by extracting the knowledge stored in its knowledge base. The system helps in decision making for compsex problems using both facts and heuristics like a human expert. It is called so because it contains the expert knowledge of a specific domain and can solve any complex problem of that particular domain. These systems are designed for a specific domain, such as medicine, science, etc.
The performance of an expert system is based on the expert's knowledge stored in its knowledge base. The more knowledge stored in the KB, the more that system improves its performance. One of the common examples of an ES is a suggestion of spelling errors while typing in the Google search box.
Below is the block diagram that represents the working of an expert system:
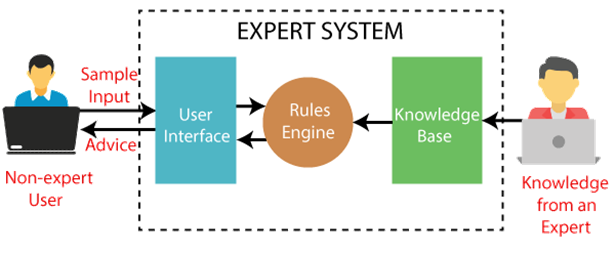
Note: It is important to remember that an expert system is not used to replace the human experts; instead, it is used to assist the human in making a complex decision. These systems do not have human capabilities of thinking and work on the basis of the knowledge base of the particular domain.
Below are some popular examples of the Expert System:
- DENDRAL: It was an artificial intelligence project that was made as a chemical analysis expert system. It was used in organic chemistry to detect unknown organic molecules with the help of their mass spectra and knowledge base of chemistry.
- MYCIN: It was one of the earliest backward chaining expert systems that was designed to find the bacteria causing infections like bacteraemia and meningitis. It was also used for the recommendation of antibiotics and the diagnosis of blood clotting diseases.
- PXDES: It is an expert system that is used to determine the type and level of lung cancer. To determine the disease, it takes a picture from the upper body, which looks like the shadow. This shadow identifies the type and degree of harm.
- CaDeT: The CaDet expert system is a diagnostic support system that can detect cancer at early stages.
Characteristics of Expert System
- High Performance: The expert system provides high performance for solving any type of complex problem of a specific domain with high efficiency and accuracy.
- Understandable: It responds in a way that can be easily understandable by the user. It can take input in human language and provides the output in the same way.
- Reliable: It is much reliable for generating an efficient and accurate output.
- Highly responsive: ES provides the result for any complex query within a very short period of time.
Components of Expert System
An expert system mainly consists of three components:
- User Interface
- Inference Engine
- Knowledge Base
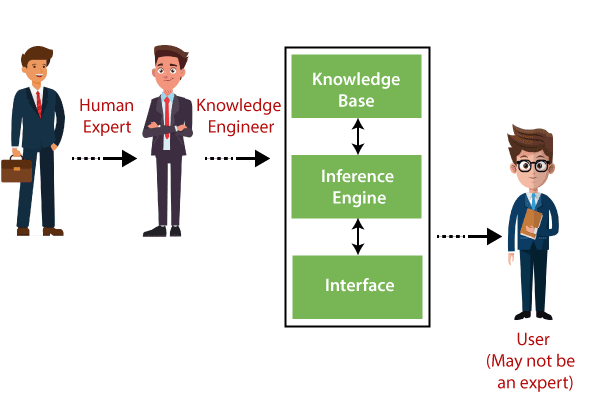
1. User Interface
With the help of a user interface, the expert system interacts with the user, takes queries as an input in a readable format, and passes it to the inference engine. After getting the response from the inference engine, it displays the output to the user. In other words, it is an interface that helps a non-expert user to communicate with the expert system to find a solution.
2. Inference Engine(Rules of Engine)
- The inference engine is known as the brain of the expert system as it is the main processing unit of the system. It applies inference rules to the knowledge base to derive a conclusion or deduce new information. It helps in deriving an error-free solution of queries asked by the user.
- With the help of an inference engine, the system extracts the knowledge from the knowledge base.
- There are two types of inference engine:
- Deterministic Inference engine: The conclusions drawn from this type of inference engine are assumed to be true. It is based on facts and rules.
- Probabilistic Inference engine: This type of inference engine contains uncertainty in conclusions, and based on the probability.
Inference engine uses the below modes to derive the solutions:
- Forward Chaining: It starts from the known facts and rules, and applies the inference rules to add their conclusion to the known facts.
- Backward Chaining: It is a backward reasoning method that starts from the goal and works backward to prove the known facts.
3. Knowledge Base
- The knowledgebase is a type of storage that stores knowledge acquired from the different experts of the particular domain. It is considered as big storage of knowledge. The more the knowledge base, the more precise will be the Expert System.
- It is similar to a database that contains information and rules of a particular domain or subject.
- One can also view the knowledge base as collections of objects and their attributes. Such as a Lion is an object and its attributes are it is a mammal, it is not a domestic animal, etc.
Components of Knowledge Base
- Factual Knowledge: The knowledge which is based on facts and accepted by knowledge engineers comes under factual knowledge.
- Heuristic Knowledge: This knowledge is based on practice, the ability to guess, evaluation, and experiences.
Knowledge Representation: It is used to formalize the knowledge stored in the knowledge base using the If-else rules.
Knowledge Acquisitions: It is the process of extracting, organizing, and structuring the domain knowledge, specifying the rules to acquire the knowledge from various experts, and store that knowledge into the knowledge base.
Development of Expert System
Here, we will explain the working of an expert system by taking an example of MYCIN ES. Below are some steps to build an MYCIN:
- Firstly, ES should be fed with expert knowledge. In the case of MYCIN, human experts specialized in the medical field of bacterial infection, provide information about the causes, symptoms, and other knowledge in that domain.
- The KB of the MYCIN is updated successfully. In order to test it, the doctor provides a new problem to it. The problem is to identify the presence of the bacteria by inputting the details of a patient, including the symptoms, current condition, and medical history.
- The ES will need a questionnaire to be filled by the patient to know the general information about the patient, such as gender, age, etc.
- Now the system has collected all the information, so it will find the solution for the problem by applying if-then rules using the inference engine and using the facts stored within the KB.
- In the end, it will provide a response to the patient by using the user interface.
Participants in the development of Expert System
There are three primary participants in the building of Expert System:
- Expert: The success of an ES much depends on the knowledge provided by human experts. These experts are those persons who are specialized in that specific domain.
- Knowledge Engineer: Knowledge engineer is the person who gathers the knowledge from the domain experts and then codifies that knowledge to the system according to the formalism.
- End-User: This is a particular person or a group of people who may not be experts, and working on the expert system needs the solution or advice for his queries, which are complex.
Why Expert System?

Before using any technology, we must have an idea about why to use that technology and hence the same for the ES. Although we have human experts in every field, then what is the need to develop a computer-based system. So below are the points that are describing the need of the ES:
- No memory Limitations: It can store as much data as required and can memorize it at the time of its application. But for human experts, there are some limitations to memorize all things at every time.
- High Efficiency: If the knowledge base is updated with the correct knowledge, then it provides a highly efficient output, which may not be possible for a human.
- Expertise in a domain: There are lots of human experts in each domain, and they all have different skills, different experiences, and different skills, so it is not easy to get a final output for the query. But if we put the knowledge gained from human experts into the expert system, then it provides an efficient output by mixing all the facts and knowledge
- Not affected by emotions: These systems are not affected by human emotions such as fatigue, anger, depression, anxiety, etc.. Hence the performance remains constant.
- High security: These systems provide high security to resolve any query.
- Considers all the facts: To respond to any query, it checks and considers all the available facts and provides the result accordingly. But it is possible that a human expert may not consider some facts due to any reason.
- Regular updates improve the performance: If there is an issue in the result provided by the expert systems, we can improve the performance of the system by updating the knowledge base.
Capabilities of the Expert System
Below are some capabilities of an Expert System:
- Advising: It is capable of advising the human being for the query of any domain from the particular ES.
- Provide decision-making capabilities: It provides the capability of decision making in any domain, such as for making any financial decision, decisions in medical science, etc.
- Demonstrate a device: It is capable of demonstrating any new products such as its features, specifications, how to use that product, etc.
- Problem-solving: It has problem-solving capabilities.
- Explaining a problem: It is also capable of providing a detailed description of an input problem.
- Interpreting the input: It is capable of interpreting the input given by the user.
- Predicting results: It can be used for the prediction of a result.
- Diagnosis: An ES designed for the medical field is capable of diagnosing a disease without using multiple components as it already contains various inbuilt medical tools.
Advantages of Expert System
- These systems are highly reproducible.
- They can be used for risky places where the human presence is not safe.
- Error possibilities are less if the KB contains correct knowledge.
- The performance of these systems remains steady as it is not affected by emotions, tension, or fatigue.
- They provide a very high speed to respond to a particular query.
Limitations of Expert System
- The response of the expert system may get wrong if the knowledge base contains the wrong information.
- Like a human being, it cannot produce a creative output for different scenarios.
- Its maintenance and development costs are very high.
- Knowledge acquisition for designing is much difficult.
- For each domain, we require a specific ES, which is one of the big limitations.
- It cannot learn from itself and hence requires manual updates.
Applications of Expert System
- In designing and manufacturing domain
It can be broadly used for designing and manufacturing physical devices such as camera lenses and automobiles. - In the knowledge domain
These systems are primarily used for publishing the relevant knowledge to the users. The two popular ES used for this domain is an advisor and a tax advisor. - In the finance domain
In the finance industries, it is used to detect any type of possible fraud, suspicious activity, and advise bankers that if they should provide loans for business or not. - In the diagnosis and troubleshooting of devices
In medical diagnosis, the ES system is used, and it was the first area where these systems were used. - Planning and Scheduling
The expert systems can also be used for planning and scheduling some particular tasks for achieving the goal of that task.
Robotics is a domain in artificial intelligence that deals with the study of creating intelligent and efficient robots.
What are Robots?
Robots are the artificial agents acting in real world environment.
Objective
Robots are aimed at manipulating the objects by perceiving, picking, moving, modifying the physical properties of object, destroying it, or to have an effect thereby freeing manpower from doing repetitive functions without getting bored, distracted, or exhausted.
What is Robotics?
Robotics is a branch of AI, which is composed of Electrical Engineering, Mechanical Engineering, and Computer Science for designing, construction, and application of robots.
Aspects of Robotics
- The robots have mechanical construction, form, or shape designed to accomplish a particular task.
- They have electrical components which power and control the machinery.
- They contain some level of computer program that determines what, when and how a robot does something.
Difference in Robot System and Other AI Program
Here is the difference between the two −
AI Programs | Robots |
They usually operate in computer-stimulated worlds. | They operate in real physical world |
The input to an AI program is in symbols and rules. | Inputs to robots is analog signal in the form of speech waveform or images |
They need general purpose computers to operate on. | They need special hardware with sensors and effectors. |
Robot Locomotion
Locomotion is the mechanism that makes a robot capable of moving in its environment. There are various types of locomotions −
- Legged
- Wheeled
- Combination of Legged and Wheeled Locomotion
- Tracked slip/skid
Legged Locomotion
- This type of locomotion consumes more power while demonstrating walk, jump, trot, hop, climb up or down, etc.
- It requires more number of motors to accomplish a movement. It is suited for rough as well as smooth terrain where irregular or too smooth surface makes it consume more power for a wheeled locomotion. It is little difficult to implement because of stability issues.
- It comes with the variety of one, two, four, and six legs. If a robot has multiple legs then leg coordination is necessary for locomotion.
The total number of possible gaits (a periodic sequence of lift and release events for each of the total legs) a robot can travel depends upon the number of its legs.
If a robot has k legs, then the number of possible events N = (2k-1)!.
In case of a two-legged robot (k=2), the number of possible events is N = (2k-1)! = (2*2-1)! = 3! = 6.
Hence there are six possible different events −
- Lifting the Left leg
- Releasing the Left leg
- Lifting the Right leg
- Releasing the Right leg
- Lifting both the legs together
- Releasing both the legs together
In case of k=6 legs, there are 39916800 possible events. Hence the complexity of robots is directly proportional to the number of legs.

Wheeled Locomotion
It requires fewer number of motors to accomplish a movement. It is little easy to implement as there are less stability issues in case of more number of wheels. It is power efficient as compared to legged locomotion.
- Standard wheel − Rotates around the wheel axle and around the contact
- Castor wheel − Rotates around the wheel axle and the offset steering joint.
- Swedish 45o and Swedish 90o wheels − Omni-wheel, rotates around the contact point, around the wheel axle, and around the rollers.
- Ball or spherical wheel − Omnidirectional wheel, technically difficult to implement.

Slip/Skid Locomotion
In this type, the vehicles use tracks as in a tank. The robot is steered by moving the tracks with different speeds in the same or opposite direction. It offers stability because of large contact area of track and ground.

Components of a Robot
Robots are constructed with the following −
- Power Supply − The robots are powered by batteries, solar power, hydraulic, or pneumatic power sources.
- Actuators − They convert energy into movement.
- Electric motors (AC/DC) − They are required for rotational movement.
- Pneumatic Air Muscles − They contract almost 40% when air is sucked in them.
- Muscle Wires − They contract by 5% when electric current is passed through them.
- Piezo Motors and Ultrasonic Motors − Best for industrial robots.
- Sensors − They provide knowledge of real time information on the task environment. Robots are equipped with vision sensors to be to compute the depth in the environment. A tactile sensor imitates the mechanical properties of touch receptors of human fingertips.
Computer Vision
This is a technology of AI with which the robots can see. The computer vision plays vital role in the domains of safety, security, health, access, and entertainment.
Computer vision automatically extracts, analyzes, and comprehends useful information from a single image or an array of images. This process involves development of algorithms to accomplish automatic visual comprehension.
Hardware of Computer Vision System
This involves −
- Power supply
- Image acquisition device such as camera
- A processor
- A software
- A display device for monitoring the system
- Accessories such as camera stands, cables, and connectors
Tasks of Computer Vision
- OCR − In the domain of computers, Optical Character Reader, a software to convert scanned documents into editable text, which accompanies a scanner.
- Face Detection − Many state-of-the-art cameras come with this feature, which enables to read the face and take the picture of that perfect expression. It is used to let a user access the software on correct match.
- Object Recognition − They are installed in supermarkets, cameras, high-end cars such as BMW, GM, and Volvo.
- Estimating Position − It is estimating position of an object with respect to camera as in position of tumor in human’s body.
Application Domains of Computer Vision
- Agriculture
- Autonomous vehicles
- Biometrics
- Character recognition
- Forensics, security, and surveillance
- Industrial quality inspection
- Face recognition
- Gesture analysis
- Geoscience
- Medical imagery
- Pollution monitoring
- Process control
- Remote sensing
- Robotics
- Transport
Applications of Robotics
The robotics has been instrumental in the various domains such as −
- Industries − Robots are used for handling material, cutting, welding, color coating, drilling, polishing, etc.
- Military − Autonomous robots can reach inaccessible and hazardous zones during war. A robot named Daksh, developed by Defense Research and Development Organization (DRDO), is in function to destroy life-threatening objects safely.
- Medicine − The robots are capable of carrying out hundreds of clinical tests simultaneously, rehabilitating permanently disabled people, and performing complex surgeries such as brain tumors.
- Exploration − The robot rock climbers used for space exploration, underwater drones used for ocean exploration are to name a few.
- Entertainment − Disney’s engineers have created hundreds of robots for movie making.
Genetic Algorithm (GA) is a search-based optimization technique based on the principles of Genetics and Natural Selection. It is frequently used to find optimal or near-optimal solutions to difficult problems which otherwise would take a lifetime to solve. It is frequently used to solve optimization problems, in research, and in machine learning.
Introduction to Optimization
Optimization is the process of making something better. In any process, we have a set of inputs and a set of outputs as shown in the following figure.
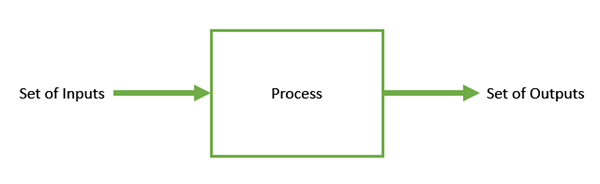
Optimization refers to finding the values of inputs in such a way that we get the “best” output values. The definition of “best” varies from problem to problem, but in mathematical terms, it refers to maximizing or minimizing one or more objective functions, by varying the input parameters.
The set of all possible solutions or values which the inputs can take make up the search space. In this search space, lies a point or a set of points which gives the optimal solution. The aim of optimization is to find that point or set of points in the search space.
What are Genetic Algorithms?
Nature has always been a great source of inspiration to all mankind. Genetic Algorithms (GAs) are search based algorithms based on the concepts of natural selection and genetics. GAs are a subset of a much larger branch of computation known as Evolutionary Computation.
GAs were developed by John Holland and his students and colleagues at the University of Michigan, most notably David E. Goldberg and has since been tried on various optimization problems with a high degree of success.
In GAs, we have a pool or a population of possible solutions to the given problem. These solutions then undergo recombination and mutation (like in natural genetics), producing new children, and the process is repeated over various generations. Each individual (or candidate solution) is assigned a fitness value (based on its objective function value) and the fitter individuals are given a higher chance to mate and yield more “fitter” individuals. This is in line with the Darwinian Theory of “Survival of the Fittest”.
In this way we keep “evolving” better individuals or solutions over generations, till we reach a stopping criterion.
Genetic Algorithms are sufficiently randomized in nature, but they perform much better than random local search (in which we just try various random solutions, keeping track of the best so far), as they exploit historical information as well.
Advantages of GAs
GAs have various advantages which have made them immensely popular. These include −
- Does not require any derivative information (which may not be available for many real-world problems).
- Is faster and more efficient as compared to the traditional methods.
- Has very good parallel capabilities.
- Optimizes both continuous and discrete functions and also multi-objective problems.
- Provides a list of “good” solutions and not just a single solution.
- Always gets an answer to the problem, which gets better over the time.
- Useful when the search space is very large and there are a large number of parameters involved.
Limitations of GAs
Like any technique, GAs also suffer from a few limitations. These include −
- GAs are not suited for all problems, especially problems which are simple and for which derivative information is available.
- Fitness value is calculated repeatedly which might be computationally expensive for some problems.
- Being stochastic, there are no guarantees on the optimality or the quality of the solution.
- If not implemented properly, the GA may not converge to the optimal solution.
GA – Motivation
Genetic Algorithms have the ability to deliver a “good-enough” solution “fast-enough”. This makes genetic algorithms attractive for use in solving optimization problems. The reasons why GAs are needed are as follows −
Solving Difficult Problems
In computer science, there is a large set of problems, which are NP-Hard. What this essentially means is that, even the most powerful computing systems take a very long time (even years!) to solve that problem. In such a scenario, GAs prove to be an efficient tool to provide usable near-optimal solutions in a short amount of time.
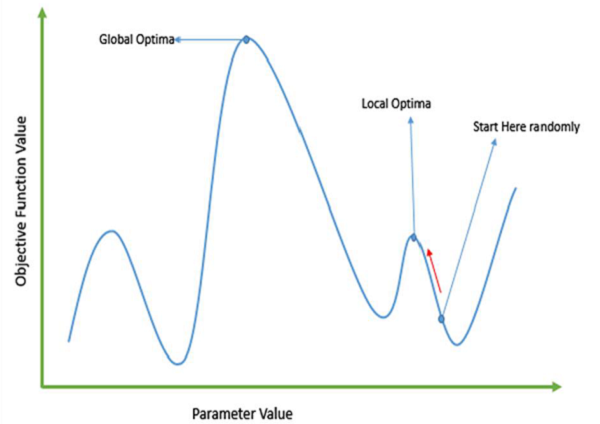
Failure of Gradient Based Methods
Traditional calculus based methods work by starting at a random point and by moving in the direction of the gradient, till we reach the top of the hill. This technique is efficient and works very well for single-peaked objective functions like the cost function in linear regression. But, in most real-world situations, we have a very complex problem called as landscapes, which are made of many peaks and many valleys, which causes such methods to fail, as they suffer from an inherent tendency of getting stuck at the local optima as shown in the following figure.
Getting a Good Solution Fast
Some difficult problems like the Travelling Salesperson Problem (TSP), have real-world applications like path finding and VLSI Design. Now imagine that you are using your GPS Navigation system, and it takes a few minutes (or even a few hours) to compute the “optimal” path from the source to destination. Delay in such real world applications is not acceptable and therefore a “good-enough” solution, which is delivered “fast” is what is required.
This section introduces the basic terminology required to understand GAs. Also, a generic structure of GAs is presented in both pseudo-code and graphical forms. The reader is advised to properly understand all the concepts introduced in this section and keep them in mind when reading other sections of this tutorial as well.
Basic Terminology
Before beginning a discussion on Genetic Algorithms, it is essential to be familiar with some basic terminology which will be used throughout this tutorial.
- Population − It is a subset of all the possible (encoded) solutions to the given problem. The population for a GA is analogous to the population for human beings except that instead of human beings, we have Candidate Solutions representing human beings.
- Chromosomes − A chromosome is one such solution to the given problem.
- Gene − A gene is one element position of a chromosome.
- Allele − It is the value a gene takes for a particular chromosome.
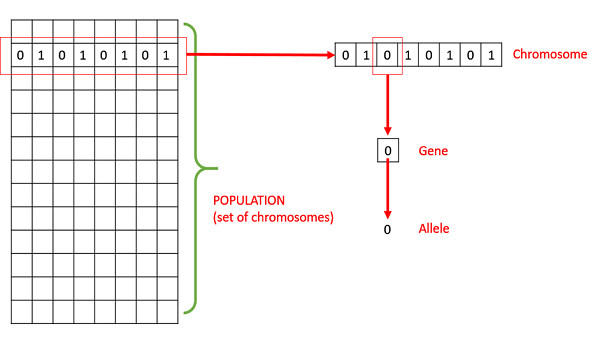
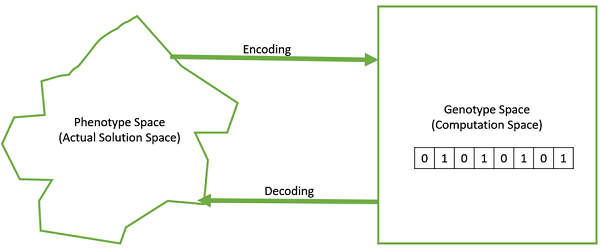
- Genotype − Genotype is the population in the computation space. In the computation space, the solutions are represented in a way which can be easily understood and manipulated using a computing system.
- Phenotype − Phenotype is the population in the actual real world solution space in which solutions are represented in a way they are represented in real world situations.
- Decoding and Encoding − For simple problems, the phenotype and genotype spaces are the same. However, in most of the cases, the phenotype and genotype spaces are different. Decoding is a process of transforming a solution from the genotype to the phenotype space, while encoding is a process of transforming from the phenotype to genotype space. Decoding should be fast as it is carried out repeatedly in a GA during the fitness value calculation.
For example, consider the 0/1 Knapsack Problem. The Phenotype space consists of solutions which just contain the item numbers of the items to be picked.
However, in the genotype space it can be represented as a binary string of length n (where n is the number of items). A 0 at position x represents that xth item is picked while a 1 represents the reverse. This is a case where genotype and phenotype spaces are different.
- Fitness Function − A fitness function simply defined is a function which takes the solution as input and produces the suitability of the solution as the output. In some cases, the fitness function and the objective function may be the same, while in others it might be different based on the problem.
- Genetic Operators − These alter the genetic composition of the offspring. These include crossover, mutation, selection, etc.
Basic Structure
The basic structure of a GA is as follows −
We start with an initial population (which may be generated at random or seeded by other heuristics), select parents from this population for mating. Apply crossover and mutation operators on the parents to generate new off-springs. And finally these off-springs replace the existing individuals in the population and the process repeats. In this way genetic algorithms actually try to mimic the human evolution to some extent.
Each of the following steps are covered as a separate chapter later in this tutorial.
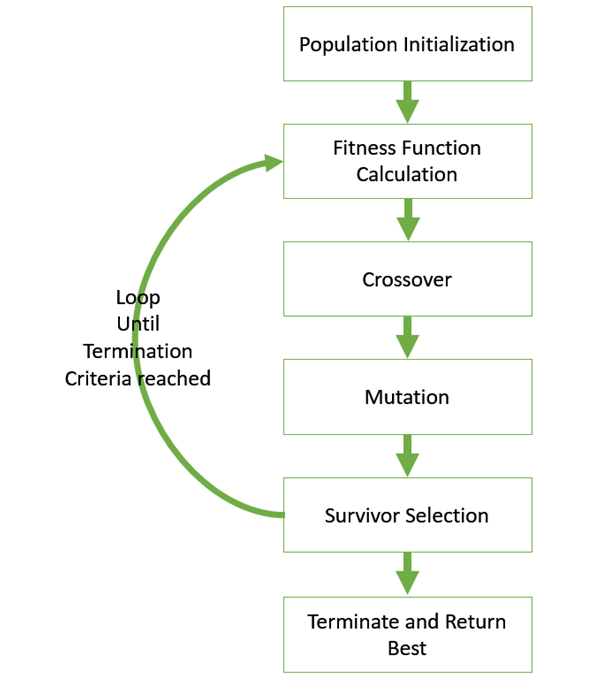
A generalized pseudo-code for a GA is explained in the following program −
GA()
Initialize population
Find fitness of population
While (termination criteria is reached) do
Parent selection
Crossover with probability pc
Mutation with probability pm
Decode and fitness calculation
Survivor selection
Find best
Return best
Text Books
1. S. Russell and P. Norvig, “Artificial Intelligence: A Modern Approach,” Prentice Hall
2. E. Rich, K. Knight and S. B. Nair, “Artificial Intelligence,” TMH
References
1. C. Bishop,“Pattern Recognition and Machine Learning," Springer
2. D. W. Patterson, “Introduction to artificial intelligence and expert systems,” Prentice Hall
3. A. C.Staugaard, Jr., “Robotics and AI: An Introduction to Applied Machine Intelligence,” Prentice Hall
4. I. Bratko, “Prolog Programming for Artificial Intelligence,” Addison-Wesley
5. S. O. Haykin, “Neural Networks and Learning Machines,” Prentice Hall
6. D.Jurafsky and J. H. Martin,“Speech and Language Processing,” Prentice Hall




