Unit – 5
J2SE
The operating system allocates memory and determines what can be put in reserved memory based on the data type of a variable. As a result, you can store integers, decimals, or characters in variables by assigning multiple data types to them.
In Java, there are two data types to choose from.
● Primitive Data Types
● Reference/Object Data Types
Primitive Data Types
Java supports a total of eight primitive data types. The language defines primitive data types and names them with keywords.
Let's take a closer look at each of the eight primitive data types.
boolean
Only two potential values are stored in the Boolean data type: true and false. Simple flags that track true/false circumstances are stored in this data type.
The Boolean data type specifies a single bit of data, but its "size" cannot be precisely defined.
byte
The primitive data type byte is an example of this. It's an 8-bit two-s complement signed integer. It has a value range of -128 to 127. (inclusive). It has a minimum of -128 and a high of 127. It has a value of 0 by default.
The byte data type is used to preserve memory in huge arrays where space is at a premium. Because a byte is four times smaller than an integer, it saves space. It can also be used in place of "int" data type.
short
A 16-bit signed two's complement integer is the short data type. It has a value range of -32,768 to 32,767. (inclusive). It has a minimum of -32,768 and a maximum of 32,767. It has a value of 0 by default.
The short data type, like the byte data type, can be used to save memory. A short data type is twice the size of an integer.
int
A 32-bit signed two's complement integer is represented by the int data type. Its range of values is - 2,147,483,648 (-231 -1) to 2,147,483,647 (231 -1). (inclusive). It has a minimum of 2,147,483,648 and a maximum of 2,147,483,647. It has a value of 0 by default.
Unless there is a memory constraint, the int data type is usually chosen as the default data type for integral values.
long
A 64-bit two's complement integer is the long data type. It has a value range of -9,223,372,036,854,775,808(-263 -1) to 9,223,372,036,854,775,807(263 -1). (inclusive). Its lowest and maximum values are 9,223,372,036,854,775,808 and 9,223,372,036,854,775,807. It has a value of 0 by default. When you need a larger range of values than int can supply, you should utilize the long data type.
float
The float data type is a 32-bit IEEE 754 floating point with single precision. It has an infinite value range. If you need to preserve memory in big arrays of floating point integers, use a float (rather than a double). For precise numbers, such as currency, the float data type should never be used. 0.0F is the default value.
double
A double data type is a 64-bit IEEE 754 floating point with double precision. It has an infinite value range. Like float, the double data type is commonly used for decimal values. For precise values, such as currency, the double data type should never be utilized. 0.0d is the default value.
Reference Data Types
● The constructors of the classes are used to create reference variables. They're used to getting things. These variables have been declared to be of a particular type that cannot be modified. For instance, employees, Puppy, and so on.
● The reference data type encompasses class objects and several types of array variables.
● Any reference variable's default value is null.
● Any object of the defined type or a compatible type can be referred to by a reference variable.
● for example: Animal animal = new Animal("giraffe");
Array
The array is a Java data structure that contains a fixed-size sequential collection of elements of the same type in a fixed-size sequential order. Although an array is used to hold data, it is often more beneficial to conceive of it as a collection of variables of the same type.
An array in Java is an object that includes components of the same data type. Furthermore, the items of an array are kept in a single memory address. It's a data structure where we save items that are comparable. In a Java array, we can only store a fixed number of elements.
Instead of declaring individual variables like number0, number1,..., and number99, you declare a single array variable called numbers and use numbers[0], numbers[1],..., numbers[99] to represent individual variables.
The first element of an array is stored at the 0th index, the second element is stored at the 1st index, and so on.
Declaring array variable
To use an array in a program, you must first define a variable that will refer to the array, as well as the kind of array that the variable can refer to. The syntax for declaring an array variable is as follows:
dataType[] arrayRefVar; // preferred way.
or
dataType arrayRefVar[]; // works but not preferred way.
Dynamic Arrays
The dynamic array is a list data structure with a configurable size. It expands automatically when we try to introduce an element and there isn't enough room for it. It gives us the ability to add and remove items. It uses the heap to allocate memory at runtime. It has the ability to modify its size while running.
ArrayList is a resizable implementation in Java. It contains all methods related to list operations and implements the List interface. The dynamic array's strength is:
● Quick lookup
● Variable size
● Cache-friendly
Working of Dynamic Array
The elements in a dynamic array are stored consecutively from the beginning of the array, and the remaining space is left empty. We can continue to add items until all of the designated space is filled. When the designated space is filled and additional items are necessary. The fixed-sized array must be enlarged in size in this scenario. Note that we allocate a larger array, copy the components from the array, and return the newly constructed array before attaching the element.
Create a method that produces a new array of double size, copies all the elements from the old array, and returns the new array as another way to add an element.
Features of Dynamic array
The dynamic array in Java has three main characteristics: Add element, delete an element, and resize an array.
Add elements in a dynamic array
If we need to add more elements to the array, we can use the dynamic array to construct a fixed-size array. It usually builds a new double-sized array. The elements are then copied into the freshly generated array.
The following is how we go about it:
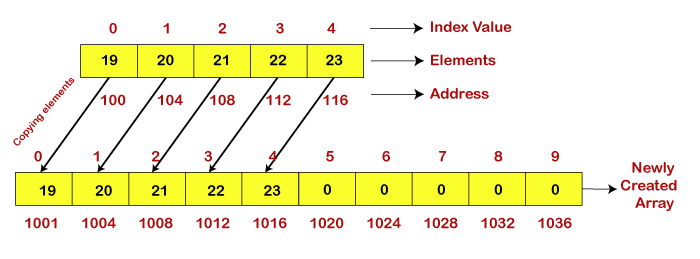
Fig 1: Add elements
Delete an Element from a Dynamic Array
The removeAt(i) method is used to remove an element from an array at the provided index. The procedure parses the element's index number to determine which one we want to remove. It shifts the remaining elements (elements to the right of the deleted element) to the left from the supplied index number after deleting the element.
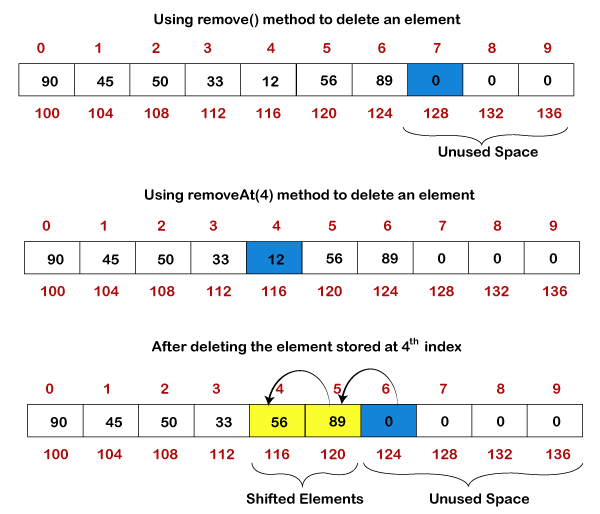
Fig 2: Delete an element
Resizing a Dynamic Array in Java
In two cases, we must resize an array:
● The array consumes more memory than is necessary.
● We need to add elements to the array because it has consumed all of the memory.
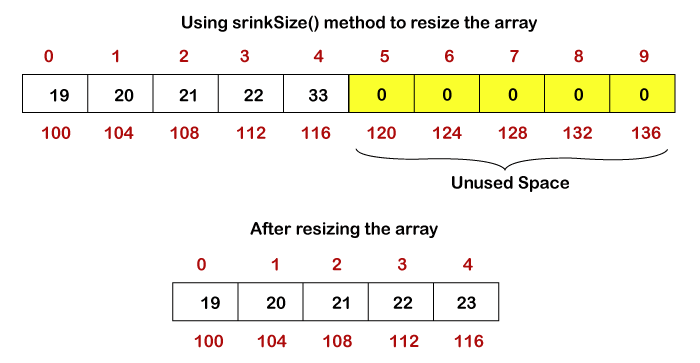
To shrink the array in the first case, we utilize the shrinkSize() method. The array's size is reduced as a result. It frees up any unused or excess RAM. To resize the array in the second scenario, we use the growSize() method. It increases the array's size.
It's a pricey operation because it takes a larger array and then duplicates all of the elements from the previous array before returning the new one.
Let's say you need to add six more elements to the aforementioned array, but you don't have any more memory to store them in. In such cases, we use the growSize() method to expand the array.
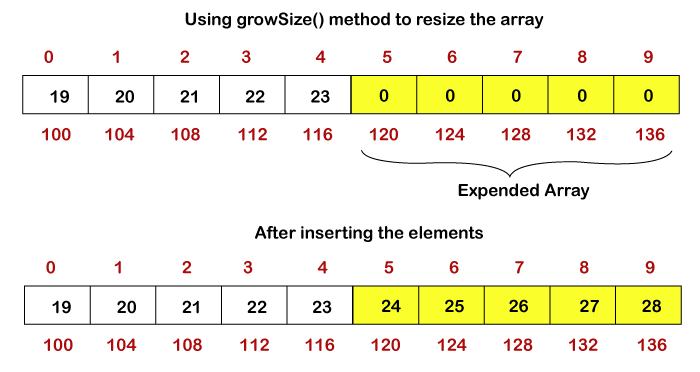
Fig 3: Resizing
Key takeaway
In Java, type casting is a method or procedure for manually and automatically converting one data type into another. The compiler performs the automatic conversion, whereas the programmer performs the manual conversion.
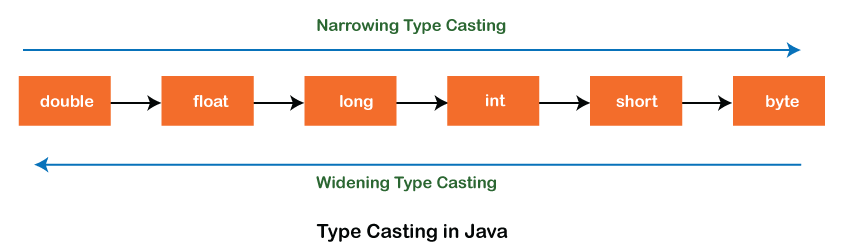
Fig 4: Type casting
The act of allocating a value from one primitive data type to another is known as type casting. When you assign the value of one data type to another, you should consider the data type's compatibility. If they are compatible, Java will convert them automatically (Automatic Type Conversion), but if they aren't, they must be cast or converted directly.
In Java, there are two different methods of casting:
When two data types are automatically converted, this type of casting occurs. Implicit Conversion is another name for it. This occurs when the two data types are compatible, as well as when a smaller data type's value is assigned to a larger data type.
This entails converting a smaller data type to a larger data type.
byte -> short -> char -> int -> long -> float -> double
Example: The numeric data types are interchangeable, however there is no automatic translation from numeric to char or boolean. Furthermore, char and boolean are not interchangeable. To better understand how Implicit type casting works, let's construct a reasoning for it.
public class Conversion{
public static void main(String[] args)
{
int i = 200;
//automatic type conversion
long l = i;
//automatic type conversion
float f = l;
System.out.println("Int value "+i);
System.out.println("Long value "+l);
System.out.println("Float value "+f);
}
}
Output
Int value 200
Long value 200
Float value 200.0
2. Narrowing Casting
Narrowing type casting is the process of converting a higher data type to a lower one. It's also known as casting up or explicit conversion. The programmer performs this task manually. The compiler will raise a compile-time error if we do not perform casting.
Converting a larger data type to a smaller data type is what this entails.
double -> float -> long -> int -> char -> short -> byte
Example
//Java program to illustrate explicit type conversion
public class Narrowing
{
public static void main(String[] args)
{
double d = 200.06;
//explicit type casting
long l = (long)d;
//explicit type casting
int i = (int)l;
System.out.println("Double Data type value "+d);
//fractional part lost
System.out.println("Long Data type value "+l);
//fractional part lost
System.out.println("Int Data type value "+i);
}
}
Output
Double Data type value 200.06
Long Data type value 200
Int Data type value 200
Key takeaway
A class is a template/blueprint that outlines the behavior/state that objects of that kind support.
Individual objects are formed from a blueprint called a class.
Here's an example of a class.
public class Dog {
String breed;
int age;
String color;
void barking() {
}
void hungry() {
}
void sleeping() {
}
}
Any of the following variable kinds can be found in a class.
Local variables – Local variables are variables specified within methods, constructors, or blocks. The variable will be declared and initialized within the method, and then removed once the method is finished.
Instance variables – Instance variables are variables that exist within a class but are not associated with any methods. When the class is created, these variables are set to their default values. Instance variables can be accessed from within any of the class's methods, constructors, or blocks.
Class variables – Class variables are variables declared with the static keyword within a class, outside of any methods.
A class can have as many methods as it wants to retrieve the value of different types of methods. Barking(), hungry(), and sleeping() are methods in the sample above.
Objects
Objects have states and behaviors that they exhibit. A dog, for example, has states such as color, name, and breed, as well as behaviors such as waving the tail, barking, and eating. A class's instance is an object.
Let's take a closer look at what objects are. Many objects, such as vehicles, pets, humans, and other living things, can be found in the actual world. There is a state and a behavior for each of these things.
If we consider a dog, its state includes its name, breed, and color, as well as its activity, which includes barking, wagging the tail, and running.
When you compare a software object to a real-world thing, you'll see that they have a lot in common.
Object and Class Example: main within the class
We've developed a Student class in this example, which has two data members: id and name. The object of the Student class is created using the new keyword, and the object's value is printed.
Inside the class, we're going to create a main() method.
//Java Program to illustrate how to define a class and fields
//Defining a Student class.
class Student{
//defining fields
int id;//field or data member or instance variable
String name;
//creating main method inside the Student class
public static void main(String args[]){
//Creating an object or instance
Student s1=new Student();//creating an object of Student
//Printing values of the object
System.out.println(s1.id);//accessing member through reference variable
System.out.println(s1.name);
}
}
Output
0
null
Key takeaway
The process through which one class inherits the properties (methods and fields) of another is known as inheritance. The use of inheritance allows for the management of information in a hierarchical way.
A subclass (derived class, child class) is a class that inherits the properties of another, while a superclass is a class that inherits the properties of another (base class, parent class).
Extends keywords
The keyword extends is used to inherit a class's properties. The syntax for the extends keyword is as follows.
class Super {
.....
.....
}
class Sub extends Super {
.....
.....
}
When you use the extends keyword, it means you're creating a new class that inherits from an existing one. The word "extends" means "to improve functionality."
In Java, an inherited class is referred to as a parent or superclass, while the new class is referred to as a child or subclass.
Terminology used in inheritance
Class - A class is a collection of objects with similar attributes. It's a blueprint or template from which items are made.
Sub class / child class - A subclass is a class that inherits the properties of another class. A derived class, extended class, or kid class is another name for it.
Superclass / parent class - The features of a subclass are inherited from the superclass. It's also known as a parent class or a base class.
Reusability - Reusability, as the name implies, is a feature that allows you to reuse the fields and methods of an existing class while creating a new one. The fields and methods defined in the preceding class can be reused.
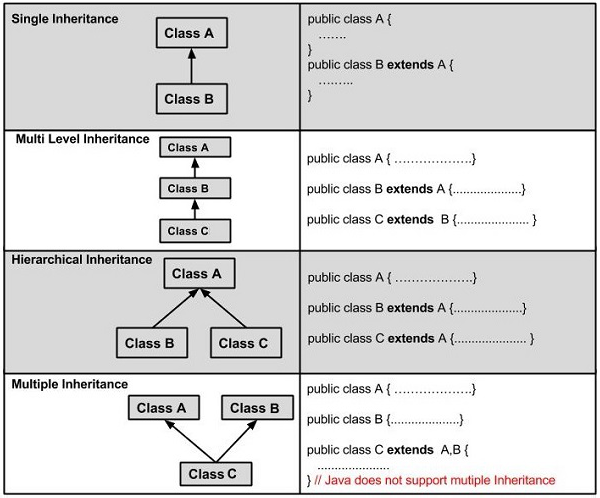
Fig 5: Types of inheritance
Key takeaway
In Java, an interface is a reference type. It's comparable to a class. It consists of a set of abstract methods. When a class implements an interface, it inherits the interface's abstract methods.
An interface may also have constants, default methods, static methods, and nested types in addition to abstract methods. Method bodies are only available for default and static methods.
The process of creating an interface is identical to that of creating a class. A class, on the other hand, describes an object's features and behaviors. An interface, on the other hand, contains the behaviors that a class implements.
Unless the interface's implementation class is abstract, all of the interface's methods must be declared in the class.
In the following ways, an interface is analogous to a class:
● Any number of methods can be included in an interface.
● An interface is written in a file with the extension.java, with the interface's name matching the file's name.
● A.class file contains the byte code for an interface.
● Packages have interfaces, and the bytecode file for each must be in the same directory structure as the package name.
Why do we use interfaces?
There are three primary reasons to utilize an interface. Below is a list of them.
● It's a technique for achieving abstraction.
● We can offer various inheritance functionality via an interface.
● It's useful for achieving loose coupling.
Declaration
The interface keyword is used to declare an interface. All methods in an interface are declared with an empty body, and all fields are public, static, and final by default. A class that implements an interface is required to implement all of the interface's functions.
Syntax
interface <interface_name>{
// declare constant fields
// declare methods that abstract
// by default.
}
Key takeaway
Exception Handling in Java is a strong technique for handling runtime failures so that the application's normal flow may be maintained.
We'll learn about Java exceptions, their types, and the difference between checked and unchecked exceptions on this page.
Exception: An exception in Java is an event that causes the program's usual flow to be disrupted. It's a type of object that's thrown at runtime.
Exception Handling: Exception Handling is a framework for dealing with runtime issues like ClassNotFoundException, IOException, SQLException, and RemoteException, among others.
Types of Exception
Checked and unchecked exceptions are the two most common forms. An error is referred to as an uncontrolled exception in this context. There are three sorts of exceptions, according to Oracle:
Exception keywords
In Java, there are five keywords that are used to handle exceptions.
try- The "try" keyword is used to designate a block where exception code should be placed. Either catch or finally must come after the try block. This means that we can't just utilize the try block.
catch- To handle the exception, the "catch" block is utilized. It must be preceded by a try block, thus we can't just use catch block. It can be followed by a later finally block.
finally- The "finally" block is used to run the program's most critical code. Whether or not an exception is handled, it is run.
throw- To throw an exception, use the "throw" keyword.
throws- Exceptions are declared with the "throws" keyword. There isn't any exception thrown. It specifies that an exception may occur in the method. It's usually used in conjunction with a method signature.
Key takeaway
In Java, multithreading is the process of running several threads at the same time.
A thread is the smallest unit of processing and is a lightweight sub-process. Multitasking is accomplished through the use of multiprocessing and multithreading.
Because threads share memory, we employ multithreading rather than multiprocessing. They conserve memory by not allocating a separate memory space, and context-switching between threads takes less time than processing.
Multithreading in Java is typically utilized in gaming, animation, and other similar applications.
Because Java is a multi-threaded programming language, we can use it to create multi-threaded programs. A multi-threaded program is made up of two or more portions that can operate in parallel, each of which can tackle a distinct task at the same time, maximizing the use of available resources, especially when your computer has several CPUs.
Multitasking is defined as the sharing of common processing resources, such as a CPU, by many processes. Multi-threading extends the concept of multitasking into programs by allowing you to divide certain operations within a single app into several threads. Each thread can execute in its own thread. Not only does the operating system split processing time among distinct apps, but it also divides it among each thread within an application.
Multi-threading allows you to write software in which multiple activities can run at the same time.
Life cycle of a Thread
In its life cycle, a thread travels through several stages. A thread, for example, gets born, starts, runs, and eventually dies. The graphic below depicts a thread's whole life cycle.
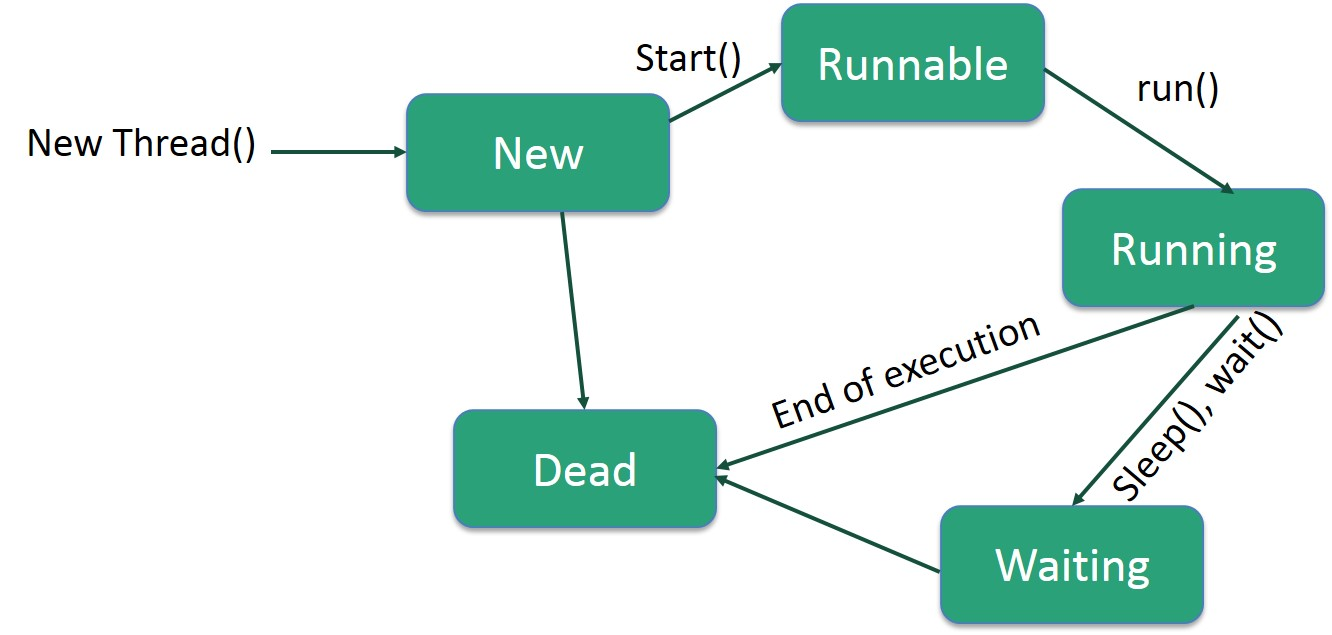
Fig 6: Life cycle of a thread
The stages of the life cycle are listed below.
New – In the new state, a new thread begins its life cycle. It will stay in this state until the thread is started by the program. A born thread is another name for it.
Runnable – When a freshly created thread is initiated, it becomes runnable. When a thread is in this position, it is regarded to be doing its job.
Waiting – When a thread is waiting for another thread to complete a job, it may shift to the waiting state. Only when another thread signals the waiting thread to continue executing does a thread transition back to the runnable state.
Timed waiting – A runnable thread can go into a timed waiting state for a set amount of time. When the time period expires or the event it is waiting for occurs, a thread in this state moves back to the runnable state.
Terminated (Dead) – When a runnable thread completes its task or otherwise terminates, it enters the terminated state.
Advantages of multithreading
● Because threads are autonomous and many operations can be performed at the same time, it does not cause the user to be blocked.
● It saves time by allowing you to do multiple procedures at once.
● Because threads are self-contained, an exception in one thread has no impact on other threads.
Key takeaway
Oracle owns the Java 2 Platform, Enterprise Edition (J2EE), which is a Java API collection. It's what programmers use to make server-side apps. Java EE applications are hosted on a variety of application servers, including IBM's WebSphere, Oracle's GlassFish, Red Hat's WildFly server, and others, which all run on the cloud or in the corporate data center. Some clients, such as IoT devices, ordinary web apps, smartphones, web sockets, RESTful web services, or micro services, run in a Docker container, despite the fact that these applications are hosted on a server.
Why do we need the J2EE Framework?
Now, we might wonder why this framework is needed when there are so many technologies.
One of the main reasons for the Java EE framework's popularity is that it provides services that make typical problems for developers easier to solve. APIs, in other words, make it easier to use established design patterns and industry-accepted practices when designing applications. Assume that managing requests from web-based customers presents a problem for enterprise developers. This framework provides Server and JSP APIs, which provide methods for determining what a user typed in a form's text field or saving a cookie in the browser.
Another task is to figure out how information is stored in databases and retrieved from them. To do this, Java EE provides JPA, also known as Java Persistence API, which makes data mapping within the program to information in database tables and rows simple. Furthermore, the EJB (Enterprise JavaBeans) specification simplifies the design of web services and high-scalability logic components. The benefit of these APIs is that they have been well tested and made simple for developers.
How does the J2EE framework work?
The server-side development of the Java program entails the following steps:
● Write code that makes use of Java EE's fundamental technologies.
● Compile the code you've written into bytecode.
● In an EAR, or Enterprise Archive file, package the produced bytecode as well as the resources connected with it.
● Use an application server to deploy the Enterprise Archive file.
All we need is a text editor and the usual Java compiler with JDK installed to finish this operation. However, we should be aware that there is a robust ecosystem of IDE (integrated development environment) tools that contribute to the rapid creation of Java EE applications.
In terms of open source IDEs, Eclipse and NetBeans are the most popular in Java EE development. In addition to the large plug-in ecosystem that allows users to create components that add extra functionality to the integrated development environment, both include project organization, syntax checking, and source code formatting. Plug-ins are typically used to develop, deploy, and execute continuous integration for Java EE applications.
Key takeaway
The client-server paradigm is a distributed application structure that divides tasks or labor between servers, who supply a resource or service, and clients, who request that service. When a client computer submits a data request to the server over the internet, the server accepts the request and returns the data packets requested to the client. Clients do not share any of their assets with one another. Email, the World Wide Web, and other client-server models are examples.
How does the Client-Server Model work?
In this, we'll look at the Client-Server concept and how the Internet operates using web browsers. This essay will assist us in establishing a solid web foundation and dealing with web technologies with ease.
● Client – When we refer to a client, we're talking about a person or an organization who uses a specific service. A Client is a computer (Host) in the digital world, capable of receiving information or using a specific service from the service providers (Servers).
A client is a computer or application used by a single user that does certain processing on its own. It also sends and receives requests for other processing and/or data to and from one or more servers.
● Server – When we talk about servers, we're talking about a person or a media who serves things. A server is a distant computer that offers information (data) or access to certain services in the digital world.
One or more computers make up a server, which receives and processes requests from one or more client machines. In terms of power, network, computation, and file storage, a server is usually designed with some redundancy.
So, the Client requests something, and the Server fulfills the request as long as it is stored in the database.
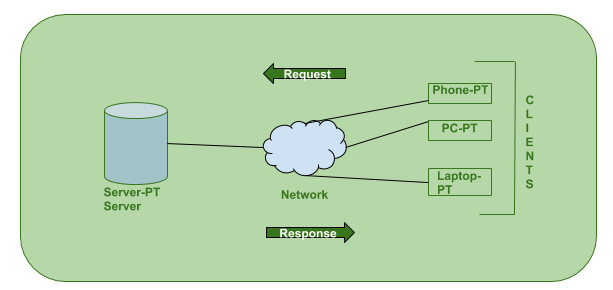
Fig 7: Client - server model
Advantages
● All data is in one place thanks to a centralized system.
● Data recovery is possible, and cost-effectiveness necessitates lower maintenance costs.
● The Client and Server capacities can be modified independently.
Disadvantages
● Viruses, Trojans, and worms can infect clients if they are present on the server or are uploaded to the server.
● Denial of Service (DoS) attacks are common on servers.
● During transmission, data packets might be faked or manipulated.
● Phishing, or collecting a user's login credentials or other relevant information, is prevalent, as are MITM (Man in the Middle) assaults.
Key takeaway
2 – tier Architecture
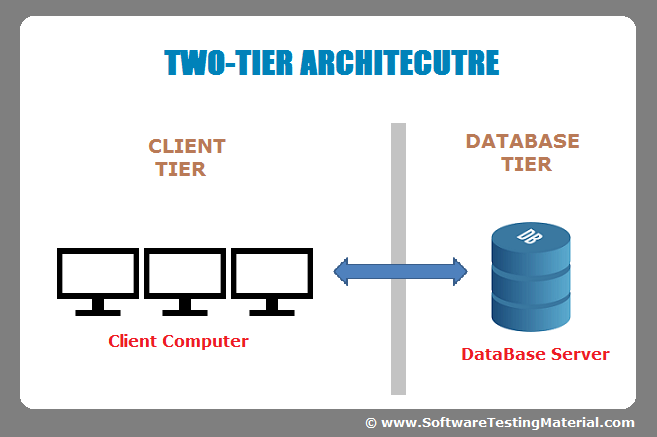
Fig 8: 2 Tier Architecture
There are two parts to the two-tier architecture:
1. Client Software (Client Tier)
2. Informational database (Data Tier)
The Presentation and Application levels are handled by the client system, while the Database layer is handled by the server system. It's also referred to as a client-server application. The Client and the Server communicate with one another. The Client System transmits the request to the Server System, which processes it and provides the data back to the Client System.
3 – tier Architecture
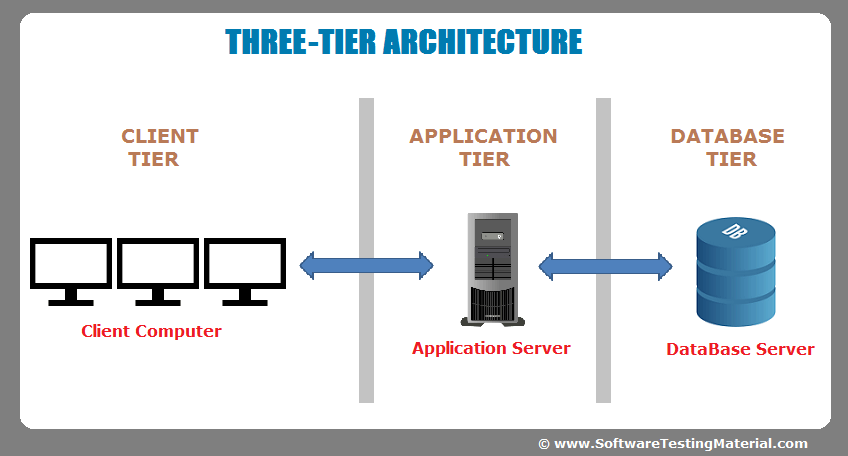
Fig 9: 3 Tier Architecture
Three sections make up the three-tier architecture:
1. The layer of presentation (Client Tier)
2. The layer of application (Business Tier)
3. Layer 2: Database (Data Tier)
Presentation layer is handled by the client system, Application layer is handled by the application server, and Database layer is handled by the server system.
N-tier applications are another layer. N-tier application is a type of application that has multiple levels. It is comparable to a three-tier design, except that the number of application servers is expanded and represented in individual tiers in order to disperse business logic.
N – tier Architecture
Because the processing, data management, and display functions are physically and logically separated, N-tier architecture is also known as multi-tier architecture. That is, these various functions are housed on multiple servers or clusters, guaranteeing that services are offered without sharing resources and, as a result, are given at maximum capacity. The “N” in n-tier architecture refers to any number between 1 and 10.
An application would be divided into three tiers in an N-tier design. These are the ones.
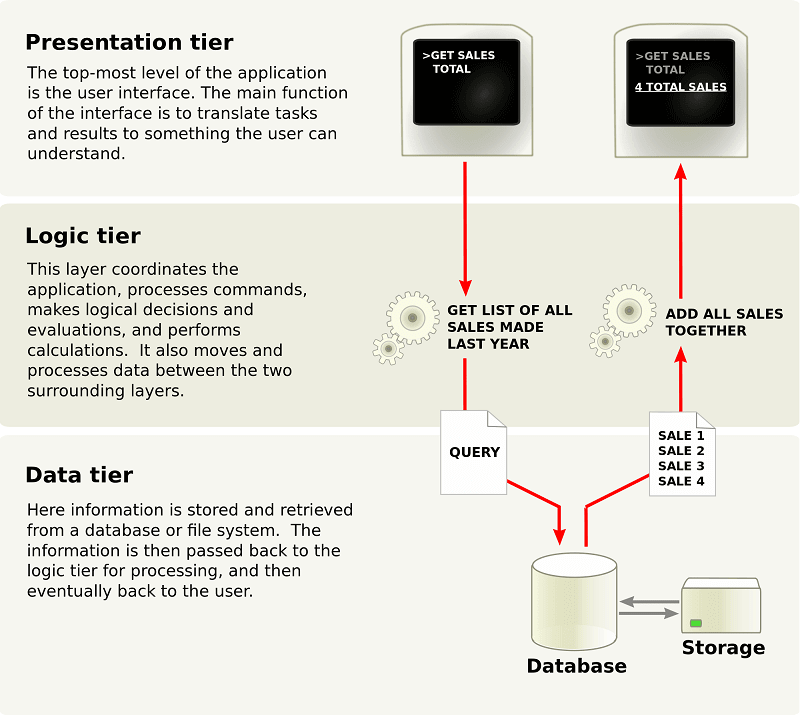
Fig 10: N tier architecture
The separation of these tiers in terms of physical location distinguishes n-tier architecture from the model-view-controller structure, which merely divides the presentation, logic, and data tiers conceptually. The N-tier design differs from the MVC framework in that it features a central layer, or logic tier, that facilitates all communication between the various tiers.
The interaction is triangular when using the MVC framework; rather than traveling through the logic tier, the control layer accesses the model and view layers, while the model layer accesses the view layer. In addition, the control layer creates a model based on the requirements, which it then sends to the view layer.
Key takeaway
A thin client is a computer that runs in a server-based environment. They operate by connecting to a distant server-based environment, which stores the majority of apps and data. The majority of the tasks, such as computations and calculations, are handled by the server. When it comes to security threats, they are more secure than thick client systems. Because there are centralized servers in thin clients, system management is considerably easier. With the help of centralization, hardware may be optimized, and software maintenance is significantly easy.
Thick clients
A thick client is a system that can connect to the server even if it is not connected to the internet. Clients who are overweight are referred to as "heavy" or "fat." Thick clients aren't reliant on the server's apps. They have their own software programs and operating systems. They have a lot of flexibility as well as a lot of server capacity. Thick clients are more vulnerable to security risks than thin clients.
Difference between thin and thick clients
Factors | Thin clients | Thick clients |
Installation | The installation of thin clients is done through a web browser. | Locally, thick clients are installed. |
Types of devices | Handheld devices make use of thin clients. | Thick clients are used in customization systems. |
Processing type | The server handles all of the processing in thin clients. | Thick clients consume more computer resources than thin clients. |
Deployability | When compared to thick clients, thin clients are much easier to deploy. | Deploying thick clients is more expensive. |
Data validation | From the server's perspective, data verification is required. | Client-side data verification is performed. |
Communication | Thin clients necessitate constant communication with the server. | Thick clients communicate with the server at predetermined intervals. |
Security | It poses less security risks. | When compared to thin clients, it poses a greater security risk. |
Interfacing | It can't be connected to anything else. | It is more durable than thin clients and can be connected to other devices. |
Key takeaway
References:




