Attribute grammar is a special type of context-free grammar where certain additional information (attributes) are appended to one or more of its non-terminals in order to provide context-sensitive information. Each attribute has a well-defined domain of values, such as integer, float, character, string, and expressions.
Attribute grammar is a tool to provide semantics to the context-free grammar and it can help define the syntax and semantics of a programming language. Attribute grammar (when viewed as a parse-tree) can transfer values or information among the nodes of a tree.
Example :
E → E + T { E.value = E.value + T.value }
The right section of the CFG contains the semantic rules that determine how the grammar should be read. Here, the values of non-terminals E and T are applied together and the output is copied to the non-terminal E.
Semantic attributes can be assigned to their values from their domain at the time of parsing and evaluated at the time of assignment or conditions. Based on the way the attributes get their values, they can be narrowly divided into two groups : synthesised attributes and inherited attributes.
- Synthesized Attribute : These attributes get values from the attribute values of their child nodes. To demonstrate, assume the following production:
S → ABC
If S is taking values from its child nodes (A,B,C), then it is said to be a synthesised attribute, as the values of ABC are synthesised to S.
As in our previous example (E → E + T), the parent node E gets its value from its child node. Synthesized attributes never take values from their parent nodes or any sibling nodes.
2. Inherited Attributes : In comparison to synthesised attributes, inherited attributes may take values from parent and/or siblings. As in the following output,
S → ABC
A can get values from S, B and C. B will take values from S, A, and C. Likewise, C will take values from S, A, and B.
Key takeaway:
● Attribute grammar is a special type of context-free grammar where certain additional information are appended to one or more of its non-terminals in order to provide context-sensitive information.
● Attribute grammar is a tool to provide semantics to the context-free grammar and it can help define the syntax and semantics of a programming language.
A Syntax Driven Description (SSD) is a context-free grammar generalization in which each grammar symbol has an associated collection of attributes, divided into two subsets of that grammar symbol's synthesized and inherited attributes.
An attribute may represent a string, a number, a type, a position in the memory, or something. A semantic rule associated with the output used on that node determines the value of an attribute at a parse-tree node.
Types of Attributes : Attributes are grouped into two kinds:
1. Synthesized Attributes : These are the attributes that derive their values from their child nodes, i.e. the synthesised attribute value at the node is determined from the attribute values at the child nodes in the parse tree.
Example
E --> E1 + T { E.val = E1.val + T.val}
● Write the SDD using applicable semantic rules in the specified grammar for each production.
● The annotated parse tree is created and bottom-up attribute values are computed.
● The final output will be the value obtained at the root node.
Considering the above example:
S --> E
E --> E1 + T
E --> T
T --> T1 * F
T --> F
F --> digit
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> E | Print (E.val) |
E --> E1 + T | E.val = E1.val + T.val |
E --> T | E.val = T. val |
T --> T1 * F | T. val = T1.val * F. val |
T --> F | T. val = F. val |
F --> digit | F. val = digit.lexval |
For arithmetic expressions, let us consider the grammar. The Syntax Directed Description associates a synthesised attribute, called val, to each non-terminal. The semantic rule measures the value of the non-terminal attribute val on the left side of the non-terminal value on the right side of the attribute val.
2. Inherited Attributes : These are the attributes derived from their parent or sibling nodes by their values, i.e. the value of the inherited attributes is determined by the parent or sibling node value.
Example
A --> BCD { C.in = A.in, C.type = B.type }
● Using semantic behaviour, create the SDD.
● The annotated parse tree is created and the values of attributes are computed top-down.
Consider the grammar below
S --> T L
T --> int
T --> float
T --> double
L --> L1, id
L --> id
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> T L | L.in = T.type |
T --> int | T.type = int |
T --> float | T.type = float |
T --> double | T.type = double |
L --> L1, id | L1.in = L.in Enter_type(id.entry, L.in) |
L --> id | Entry _type(id.entry, L.in) |
Key takeaway:
● SSD is a context-free grammar generalisation in which each grammar symbol has an associated collection of attributes
● Attributes divided into two subsets of that grammar symbol's synthesised and inherited attributes.
● Synethesised are the attributes that derive their values from their child nodes,
● Inherited are the attributes derived from their parent or sibling nodes by their values
The abstract syntactic structure of source code written in a programming language is represented by a syntax tree. Rather than elements such as braces, semicolons that end sentences in some languages, it focuses on the laws.
It is also a hierarchy divided into many parts with the elements of programming statements. The tree nodes denote a construct that exists in the source code.
A form id + id * id will have the following tree of syntax:
It is possible to represent the Abstract Syntax Tree as:
Fig 1: Syntax tree
|
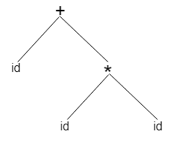
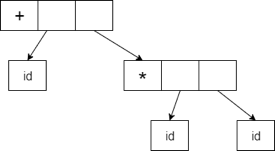
In a compiler, abstract syntax trees are significant data structures. It includes the least information that is redundant.
Key takeaway:
● Abstract syntax trees are more compact and can easily be used by a compiler than a parse tree.
● The syntax tree helps evaluate the compiler's accuracy.
● A parse forest is a collection of possible parse trees for a syntactically ambiguous word.
The Symbol Table is an essential data structure generated and maintained by the compiler to keep track of variable semantics, i.e. to store information about scope and binding information about names, information about instances of different entities, such as variable and function names, classes, objects, etc.
A table of symbols used for the following purposes:
● It is used to store the names of all individuals in one location in a standardised way.
● To check if a variable has been declared, it is used.
● It is used to evaluate a name's scope.
● It is used to enforce type checking by verifying the assignments and semantically correct expressions in the source code.
A table of symbols may either be linear or a table of hashes. Using the following format, the entry for each name is kept
<symbol name, type, attribute>
For reference, suppose that a variable stores information about the following declaration of a variable:
static int salary
Then, in the following format, it stores an entry:
<salary, int, static>
The attribute of the clause includes the name-related entries.
symbol attributes and management
Symbol Table entries –
Every entry in the symbol table is associated with attributes that the compiler supports at various stages.
Items contained in Table Symbols:
● Variable names and constants
● Procedure and function names
● Literal constants and strings
● Compiler generated temporaries
● Labels in source languages
Details from the Symbol table used by the compiler:
● Data type and name
● Declaring procedures
● Offset in storage
● If structure or record then, pointer to structure table.
● For parameters, whether parameter passing by value or by reference
● Number and type of arguments passed to function
● Base Address
Scope management
Two symbol table forms are included in the compiler: the global symbol table and the scope symbol table.
Global symbol table that can be reached by all the tables of procedures and scope symbols that are generated in the software for each scope.
Both procedures and the scope symbol table can be accessed via the Global Symbol Table.
In the hierarchy structure, the scope of a name and symbol table is organised as shown below.
int value=10;
void sum_num() { int num_1; int num_2;
{ int num_3; int num_4; }
int num_5;
{ int_num 6; int_num 7; } }
Void sum_id { int id_1; int id_2;
{ int id_3; int id_4; }
int num_5; }
|
In a hierarchical data structure of symbol tables, the grammar above can be represented:
|
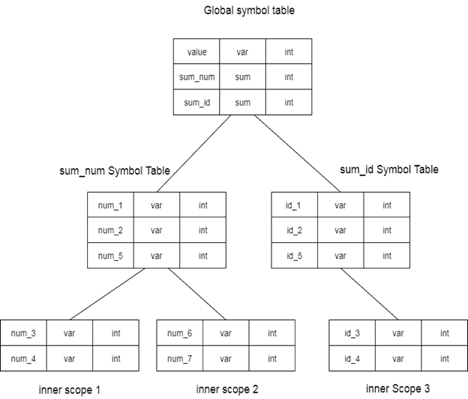
Fig 2: global symbol table
There is one global variable and two procedure names in the global symbol table. For sum id and its child tables, the name cited in the sum num table is not available.
The hierarchy of the symbol table's data structure is stored in the semantic analyzer. If you want to look for the name in the table of symbols, you can use the following algorithm to search for it:
● A symbol is first checked for in the current table of symbols.
● If the name is found, the search will be completed or the name will be checked in the parent symbol table until,
● Find a name or look for a global symbol.
Key takeaway :
● Both procedures and the scope symbol table can be accessed via the Global Symbol Table.
● Global symbol table that can be reached by all the tables of procedures
● scope symbols that are generated in the software for each scope.
Run - time Environments
As a source code, a programme is merely a set of text (code, statements etc.) and it needs actions to be performed on the target computer to make it alive. To execute instructions, a programme requires memory resources. A programme includes names for processes, identifiers, etc. that enable the actual memory position to be mapped at runtime.
By runtime, we mean the execution of a programme. The runtime environment is the state of the target machine that can provide services to the processes running in the system, including software libraries, environment variables, and so on.
A set, often created with the executable programme itself, is a runtime support system that enables the communication of the process between the process and the runtime environment. Memory allocation and deallocation are taken care of when the programme is being executed.
● Every time a process is run, it is referred to as an activation.
● The execution of a procedure P begins at the beginning of the procedure body, and when it is done, it restores power to the point immediately following the call to P.
● The sequence of steps between the first and last steps in the execution of P is called the lifetime of an activation of a procedure P. (including the other procedures called by P).
● The lifetimes of A and B are either non-overlapping or nested if they are procedure activations.
● A new activation of a recursive procedure will begin before an earlier activation of the same procedure has finished.
parameter passing and value return
The medium of communication between procedures is known as passing parameters. The values of the variables from a calling procedure are passed by some process to the called procedure. Go first through some simple terminologies relating to the principles in a programme before going on.
r-value : An expression's value is called its r-value. The value stored in a single variable, even if it occurs on the right-hand side of the assignment operator, becomes an r-value. It is always possible to assign r-values to any other variable.
l-value : The memory location (address) at which an expression is stored is referred to as the l-value of that expression. It often appears on the left side of an operator's task.
Example
day = 1;
week = day * 7;
month = 1;
year = month * 12;
We understand from this example that constant values, such as 1, 7, 12, and variables such as day, week, month and year, all have r-values. As they also represent the memory location assigned to them, only variables have l-values.
7 = x + y;
As constant 7 does not represent any memory location, this is a l-value error.
Formal Parameter :
The formal parameters are called variables that take the data passed by the caller procedure. In the description of the call function, certain variables are declared.
Actual Parameter :
The actual parameters are called variables whose values or addresses are transferred to the calling process. These variables are defined as arguments in the function call.
Example
fun_one()
{
int actual_parameter = 16;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}
Depending on the parameter passing technique used, formal parameters hold the actual parameter information. It may be an address or a value.
Different ways of passing the parameters to the procedure
● Call by Value
The calling procedure passes the r-value of actual parameters in the pass by value mechanism, and the compiler puts that into the activation record of the called procedure. The formal parameters will then hold the values that the calling procedure passes. If the values held by the formal parameters are modified, the real parameters should not be influenced by this.
● Call by References
The formal and real parameters in the reference call refer to the same memory location. The l-value of the individual parameters is copied to the call function's activation record. The named function therefore has the address of the actual parameters. If there is no l-value(eg-i+3) for the actual parameters, it is evaluated at a new temporary location and the location address is transmitted. Any formal parameter changes are expressed in the actual parameters (because changes are made at the address).
● Call by Copy Restore
In copy call restore, the compiler copies the value to formal parameters when the procedure is called and copies the value back to real parameters when the control returns to the method called. The r-values are transferred, and the r-value of formals is copied to the l-value of actuals upon return.
● Call by Name
The actual parameters are substituted for formals in the call by name in all places where formals occur in the process. It is also referred to as lazy assessment since evaluation is only conducted on criteria when appropriate.
Key takeaway :
● The medium of communication between procedures is known as passing parameters.
● The formal parameters are called variables that take the data passed by the caller procedure.
● The actual parameters are called variables whose values or addresses are transferred to the calling process.
The numerous ways that memory can be allocated are:
- Static storage allocation
- Stack storage allocation
- Heap storage allocation
Static storage allocation :
● Names are attached to storage locations in static allocation.
● If the memory is created at the time of compilation, the memory is created in a static region and only once.
● The dynamic data structure is assisted by static allocation, meaning that memory is only generated at compile time and redistributed after programme completion.
● The downside of static storage allocation is that it is important to know the size and position of data objects at compile time.
● The constraint of the recursion method is another downside.
Stack storage allocation :
● Space is structured as a stack of static storage allocation.
● When activation begins, an activation record is placed into the stack and it pops when the activation finishes.
● The activation record includes the locals of each activation record so that they are connected to fresh storage. When the activation stops, the value for locals is deleted.
● It operates on the basis of last-in-first-out (LIFO) and the recursion mechanism is supported by this allocation.
Heap storage allocation :
● The most versatile allocation scheme is heap allocation.
● Depending on the requirement of the user, memory allocation and deallocation can be performed at any time and at any venue.
● Heap allocation is used to dynamically assign memory to the variables and then regain it when the variables are no longer used.
● The recursion mechanism is assisted by heap capacity allocation.
Example :
fact (int n) { if (n<=1) return 1; else return (n * fact(n-1)); } fact (6)
dynamic allocation is given below:
|
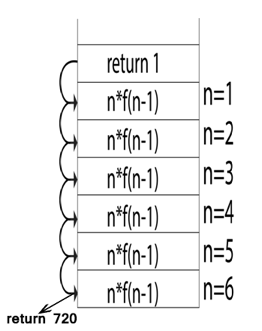
Fig 3: dynamic allocation
Key takeaway :
● If the memory is created at the time of compilation, the memory is created in a static region and only once, in static storage allocation.
● Space is structured as a stack of static storage allocation.
● The most versatile allocation scheme is heap allocation.
Scope
In the source software, every name has a validity area, called that name's scope.
The following are the rules in a block-structured language:
● If a name is declared within Block B, then only within B will it be valid.
● The name that is valid for block B2 is also valid for B1 if the B1 block is nested within B2, unless the name's identifier is re-declared in B1.
These scope rules require a more complicated symbol table organisation than a list of names and attribute associations.
The tables are arranged into stacks, and each table includes a list of names and attributes associated with them.
● A new table is entered into the stack whenever a new block is entered.
● The name that is declared as local to this block is included in the new table.
● The table will look for a name when the declaration is compiled.
● If the name of the table is not identified, a new name is added.
Example :
int x; void f(int m) { float x, y; { int i, j; int u, v; } } int g (int n) { bool t; }
|
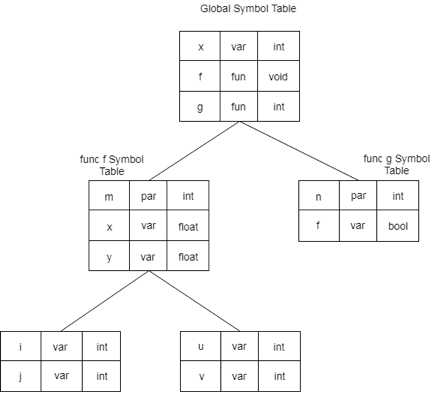
Fig 4: Symbol table organisation compliant with the principles of static scope information
Key takeaway :
● Every name has a validity area, called that name's scope.
● The tables are arranged into stacks, and each table includes a list of names and attributes associated with them.
● Storage is organized as a stack .
References :
- CompilersPrinciples.Techniques.AndToolsbyAlfredV.Aho.RaviSethiJefferyD.Ullman.PearsonEducation.
2. Compiler Design by Santanu Chattopadhyay. PHI
3. www.javatpoint.com




