UNIT-2
Data Link Layer and Medium Access Sub Layer
Error Correction codes are used to detect and correct the errors when data is transmitted from the sender to the receiver. Error Correction can be handled in two ways:
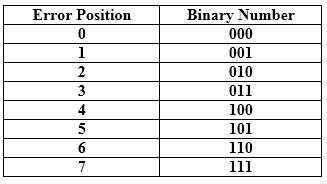
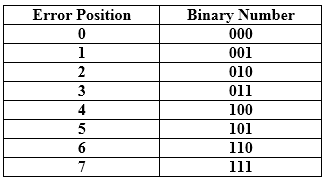
A single additional bit can detect the error, but cannot correct it. For correcting the errors, one has to know the exact position of the error. For example, If we want to calculate a single-bit error, the error correction code will determine which one of seven bits is in error. To achieve this, we have to add some additional redundant bits. Suppose r is the number of redundant bits and d is the total number of the data bits. The number of redundant bits r can be calculated by using the formula: 2r>=d+r+1 The value of r is calculated by using the above formula. For example, if the value of d is 4, then the possible smallest value that satisfies the above relation would be 3. To determine the position of the bit which is in error, a technique developed by R.W Hamming is Hamming code which can be applied to any length of the data unit and uses the relationship between data units and redundant units. Parity bits: The bit which is appended to the original data of binary bits so that the total number of 1s is even or odd. Even parity: To check for even parity, if the total number of 1s is even, then the value of the parity bit is 0. If the total number of 1s occurrences is odd, then the value of the parity bit is 1. Odd Parity: To check for odd parity, if the total number of 1s is even, then the value of parity bit is 1. If the total number of 1s is odd, then the value of parity bit is 0.
Relationship b/w Error position & binary number.
Let's understand the concept of Hamming code through an example: Suppose the original data is 1010 which is to be sent. Total number of data bits 'd' = 4 Number of redundant bits r : 2r >= d+r+1 2r>= 4+r+1 Therefore, the value of r is 3 that satisfies the above relation. Total number of bits = d+r = 4+3 = 7; Determining the position of the redundant bits The number of redundant bits is 3. The three bits are represented by r1, r2, r4. The position of the redundant bits is calculated with corresponds to the raised power of 2. Therefore, their corresponding positions are 1, 21, 22.
Representation of Data on the addition of parity bits:
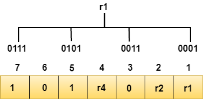
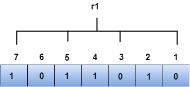
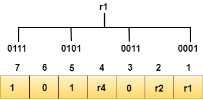
The r1 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the first position.
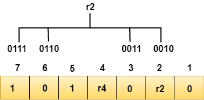
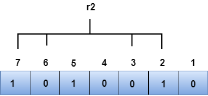
We observe from the above figure that the bit positions that includes 1 in the first position are 1, 3, 5, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r1 is even, therefore, the value of the r1 bit is 0. The r2 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the second position.
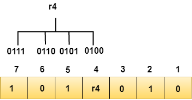
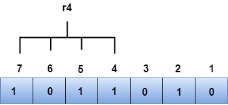
We observe from the above figure that the bit positions that includes 1 in the second position are 2, 3, 6, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r2 is odd, therefore, the value of the r2 bit is 1. The r4 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the third position.
We observe from the above figure that the bit positions that includes 1 in the third position are 4, 5, 6, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r4 is even, therefore, the value of the r4 bit is 0. Data transferred is given below:
Suppose the 4th bit is changed from 0 to 1 at the receiving end, then parity bits are recalculated. The bit positions of the r1 bit are 1,3,5,7
We observe from the above figure that the binary representation of r1 is 1100. Now, we perform the even-parity check, the total number of 1s appearing in the r1 bit is an even number. Therefore, the value of r1 is 0. The bit positions of r2 bit are 2,3,6,7.
We observe from the above figure that the binary representation of r2 is 1001. Now, we perform the even-parity check, the total number of 1s appearing in the r2 bit is an even number. Therefore, the value of r2 is 0. The bit positions of r4 bit are 4,5,6,7.
We observe from the above figure that the binary representation of r4 is 1011. Now, we perform the even-parity check, the total number of 1s appearing in the r4 bit is an odd number. Therefore, the value of r4 is 1.
When data is transmitted from one device to another device, the system does not guarantee whether the data received by the device is identical to the data transmitted by another device. An Error is a situation when the message received at the receiver end is not identical to the message transmitted.
Fig 1 – Types of errors Errors can be classified into two categories:
The only one bit of a given data unit is changed from 1 to 0 or from 0 to 1.
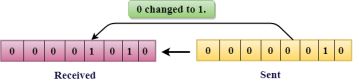
Fig 2 – Single bit error In the above figure, the message which is sent is corrupted as single-bit, i.e., 0 bit is changed to 1. Single-Bit Error does not appear more likely in Serial Data Transmission. For example, Sender sends the data at 10 Mbps, this means that the bit lasts only for 1 ?s and for a single-bit error to occurred, a noise must be more than 1 ?s. Single-Bit Error mainly occurs in Parallel Data Transmission. For example, if eight wires are used to send the eight bits of a byte, if one of the wire is noisy, then single-bit is corrupted per byte. The two or more bits are changed from 0 to 1 or from 1 to 0 is known as Burst Error. The Burst Error is determined from the first corrupted bit to the last corrupted bit.
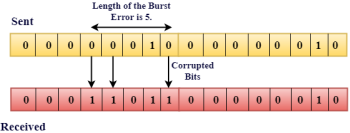
Fig 3 - Burst Error The duration of noise in Burst Error is more than the duration of noise in Single-Bit. Burst Errors are most likely to occurr in Serial Data Transmission. The number of affected bits depends on the duration of the noise and data rate. The most popular Error Detecting Techniques are:
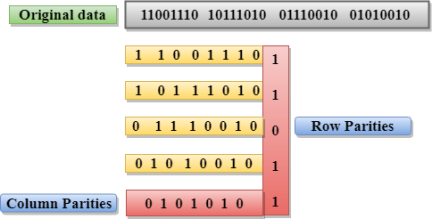
Drawbacks Of Single Parity Checking
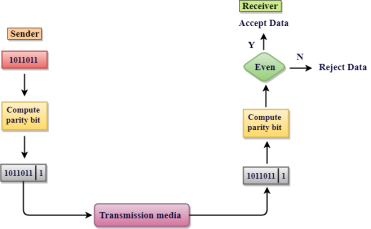
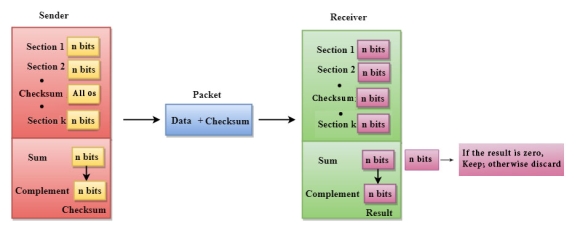
A Checksum is an error detection technique based on the concept of redundancy. It is divided into two parts: A Checksum is generated at the sending side. Checksum generator subdivides the data into equal segments of n bits each, and all these segments are added together by using one's complement arithmetic. The sum is complemented and appended to the original data, known as checksum field. The extended data is transmitted across the network. Suppose L is the total sum of the data segments, then the checksum would be ?L
Fig 6 - Checksum
A Checksum is verified at the receiving side. The receiver subdivides the incoming data into equal segments of n bits each, and all these segments are added together, and then this sum is complemented. If the complement of the sum is zero, then the data is accepted otherwise data is rejected.
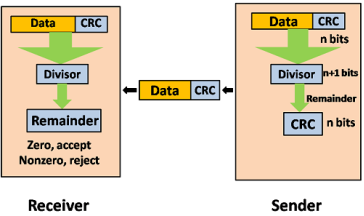
CRC is a redundancy error technique used to determine the error. Following are the steps used in CRC for error detection:
If the resultant of this division is zero which means that it has no error, and the data is accepted. If the resultant of this division is not zero which means that the data consists of an error. Therefore, the data is discarded.
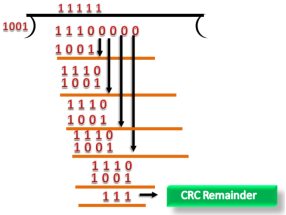
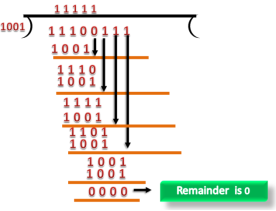
Fig 7 – Data CRC Let's understand this concept through an example: Suppose the original data is 11100 and divisor is 1001.
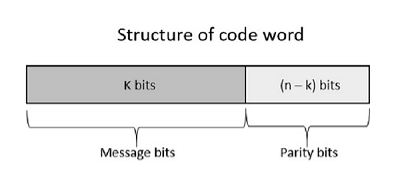
Noise or Error is the main problem in the signal, which disturbs the reliability of the communication system. Error control coding is the coding procedure done to control the occurrences of errors. These techniques help in Error Detection and Error Correction. There are many different error correcting codes depending upon the mathematical principles applied to them. But, historically, these codes have been classified into Linear block codes and Convolution codes. In the linear block codes, the parity bits and message bits have a linear combination, which means that the resultant code word is the linear combination of any two code words. Let us consider some blocks of data, which contains k bits in each block. These bits are mapped with the blocks which has n bits in each block. Here n is greater than k. The transmitter adds redundant bits which are n−k bits. The ratio k/n is the code rate. It is denoted by r and the value of r is r < 1. The n−k bits added here, are parity bits. Parity bits help in error detection and error correction, and also in locating the data. In the data being transmitted, the left most bits of the code word correspond to the message bits, and the right most bits of the code word correspond to the parity bits. Any linear block code can be a systematic code, until it is altered. Hence, an unaltered block code is called as a systematic code. Following is the representation of the structure of code word, according to their allocation.
Fig 8 – Structure of code word If the message is not altered, then it is called as systematic code. It means, the encryption of the data should not change the data. So far, in the linear codes, we have discussed that systematic unaltered code is preferred. Here, the data of total n bits if transmitted, k bits are message bits and n−k bits are parity bits. In the process of encoding, the parity bits are subtracted from the whole data and the message bits are encoded. Now, the parity bits are again added and the whole data is again encoded. The following figure quotes an example for blocks of data and stream of data, used for transmission of information.
The whole process, stated above is tedious which has drawbacks. The allotment of buffer is a main problem here, when the system is busy. This drawback is cleared in convolution codes. Where the whole stream of data is assigned symbols and then transmitted. As the data is a stream of bits, there is no need of buffer for storage. The linearity property of the code word is that the sum of two code words is also a code word. Hamming codes are the type of linear error correcting codes, which can detect up to two bit errors or they can correct one bit errors without the detection of uncorrected errors. While using the hamming codes, extra parity bits are used to identify a single bit error. To get from one-bit pattern to the other, few bits are to be changed in the data. Such number of bits can be termed as Hamming distance. If the parity has a distance of 2, one-bit flip can be detected. But this can't be corrected. Also, any two bit flips cannot be detected. However, Hamming code is a better procedure than the previously discussed ones in error detection and correction. BCH codes are named after the inventors Bose, Chaudari and Hocquenghem. During the BCH code design, there is control on the number of symbols to be corrected and hence multiple bit correction is possible. BCH codes is a powerful technique in error correcting codes. For any positive integers m ≥ 3 and t < 2m-1 there exists a BCH binary code. Following are the parameters of such code. Block length n = 2m-1 Number of parity-check digits n - k ≤ mt Minimum distance dmin ≥ 2t + 1 This code can be called as t-error-correcting BCH code. The cyclic property of code words is that any cyclic-shift of a code word is also a code word. Cyclic codes follow this cyclic property. For a linear code C, if every code word i.e., C = C1,C2,......Cn from C has a cyclic right shift of components, it becomes a code word. This shift of right is equal to n-1 cyclic left shifts. Hence, it is invariant under any shift. So, the linear code C, as it is invariant under any shift, can be called as a Cyclic code. Cyclic codes are used for error correction. They are mainly used to correct double errors and burst errors. Hence, these are a few error correcting codes, which are to be detected at the receiver. These codes prevent the errors from getting introduced and disturb the communication. They also prevent the signal from getting tapped by unwanted receivers. |



Key takeaways
- Error Correction codes are used to detect and correct the errors when data is transmitted from the sender to the receiver.
- Error Correction can be handled in two ways:
- Backward error correction: Once the error is discovered, the receiver requests the sender to retransmit the entire data unit.
- Forward error correction: In this case, the receiver uses the error-correcting code which automatically corrects the errors.
3. A single additional bit can detect the error, but cannot correct it.
4. For correcting the errors, one has to know the exact position of the error. For example, If we want to calculate a single-bit error, the error correction code will determine which one of seven bits is in error. To achieve this, we have to add some additional redundant bits.
5. Suppose r is the number of redundant bits and d is the total number of the data bits. The number of redundant bits r can be calculated by using the formula:
2r>=d+r+1
6. The value of r is calculated by using the above formula. For example, if the value of d is 4, then the possible smallest value that satisfies the above relation would be 3.
7. To determine the position of the bit which is in error, a technique developed by R.W Hamming is Hamming code which can be applied to any length of the data unit and uses the relationship between data units and redundant units.
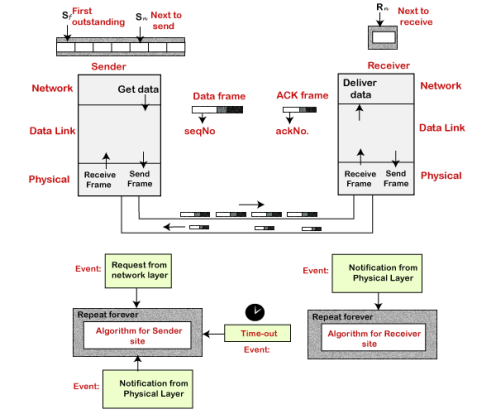
Before understanding the stop and Wait protocol, we first know about the error control mechanism. The error control mechanism is used so that the received data should be exactly same whatever sender has sent the data. The error control mechanism is divided into two categories, i.e., Stop and Wait ARQ and sliding window. The sliding window is further divided into two categories, i.e., Go Back N, and Selective Repeat. Based on the usage, the people select the error control mechanism whether it is stop and wait or sliding window. What is Stop and Wait protocol? Here stop and wait means, whatever the data that sender wants to send, he sends the data to the receiver. After sending the data, he stops and waits until he receives the acknowledgment from the receiver. The stop and wait protocol is a flow control protocol where flow control is one of the services of the data link layer. It is a data-link layer protocol which is used for transmitting the data over the noiseless channels. It provides unidirectional data transmission which means that either sending or receiving of data will take place at a time. It provides flow-control mechanism but does not provide any error control mechanism. The idea behind the usage of this frame is that when the sender sends the frame then he waits for the acknowledgment before sending the next frame. Primitives of Stop and Wait Protocol The primitives of stop and wait protocol are: Sender side Rule 1: Sender sends one data packet at a time. Rule 2: Sender sends the next packet only when it receives the acknowledgment of the previous packet. Therefore, the idea of stop and wait protocol in the sender's side is very simple, i.e., send one packet at a time, and do not send another packet before receiving the acknowledgment. Rule 1: Receive and then consume the data packet. Rule 2: When the data packet is consumed, receiver sends the acknowledgment to the sender. Therefore, the idea of stop and wait protocol in the receiver's side is also very simple, i.e., consume the packet, and once the packet is consumed, the acknowledgment is sent. This is known as a flow control mechanism. Working of Stop and Wait protocol
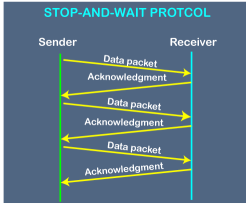
Fig 9 - Working of Stop and Wait protocol The above figure shows the working of the stop and wait protocol. If there is a sender and receiver, then sender sends the packet and that packet is known as a data packet. The sender will not send the second packet without receiving the acknowledgment of the first packet. The receiver sends the acknowledgment for the data packet that it has received. Once the acknowledgment is received, the sender sends the next packet. This process continues until all the packet are not sent. The main advantage of this protocol is its simplicity but it has some disadvantages also. For example, if there are 1000 data packets to be sent, then all the 1000 packets cannot be sent at a time as in Stop and Wait protocol, one packet is sent at a time. Disadvantages of Stop and Wait protocol The following are the problems associated with a stop and wait protocol: 1. Problems occur due to lost data
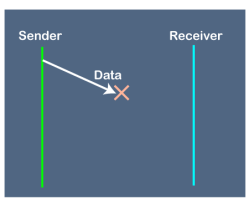
Fig 10 - Problems occur due to lost data Suppose the sender sends the data and the data is lost. The receiver is waiting for the data for a long time. Since the data is not received by the receiver, so it does not send any acknowledgment. Since the sender does not receive any acknowledgment so it will not send the next packet. This problem occurs due to the lost data. In this case, two problems occur:
2. Problems occur due to lost acknowledgment
Suppose the sender sends the data and it has also been received by the receiver. On receiving the packet, the receiver sends the acknowledgment. In this case, the acknowledgment is lost in a network, so there is no chance for the sender to receive the acknowledgment. There is also no chance for the sender to send the next packet as in stop and wait protocol, the next packet cannot be sent until the acknowledgment of the previous packet is received. In this case, one problem occurs:
3. Problem due to the delayed data or acknowledgment
Suppose the sender sends the data and it has also been received by the receiver. The receiver then sends the acknowledgment but the acknowledgment is received after the timeout period on the sender's side. As the acknowledgment is received late, so acknowledgment can be wrongly considered as the acknowledgment of some other data packet. Before understanding the working of Go-Back-N ARQ, we first look at the sliding window protocol. As we know that the sliding window protocol is different from the stop-and-wait protocol. In the stop-and-wait protocol, the sender can send only one frame at a time and cannot send the next frame without receiving the acknowledgment of the previously sent frame, whereas, in the case of sliding window protocol, the multiple frames can be sent at a time. The variations of sliding window protocol are Go-Back-N ARQ and Selective Repeat ARQ. Let's understand 'what is Go-Back-N ARQ'. In Go-Back-N ARQ, N is the sender's window size. Suppose we say that Go-Back-3, which means that the three frames can be sent at a time before expecting the acknowledgment from the receiver. It uses the principle of protocol pipelining in which the multiple frames can be sent before receiving the acknowledgment of the first frame. If we have five frames and the concept is Go-Back-3, which means that the three frames can be sent, i.e., frame no 1, frame no 2, frame no 3 can be sent before expecting the acknowledgment of frame no 1. In Go-Back-N ARQ, the frames are numbered sequentially as Go-Back-N ARQ sends the multiple frames at a time that requires the numbering approach to distinguish the frame from another frame, and these numbers are known as the sequential numbers. The number of frames that can be sent at a time totally depends on the size of the sender's window. So, we can say that 'N' is the number of frames that can be sent at a time before receiving the acknowledgment from the receiver. If the acknowledgment of a frame is not received within an agreed-upon time period, then all the frames available in the current window will be retransmitted. Suppose we have sent the frame no 5, but we didn't receive the acknowledgment of frame no 5, and the current window is holding three frames, then these three frames will be retransmitted. The sequence number of the outbound frames depends upon the size of the sender's window. Suppose the sender's window size is 2, and we have ten frames to send, then the sequence numbers will not be 1,2,3,4,5,6,7,8,9,10. Let's understand through an example.
The number of bits in the sequence number is 2 to generate the binary sequence 00,01,10,11. Suppose there are a sender and a receiver, and let's assume that there are 11 frames to be sent. These frames are represented as 0,1,2,3,4,5,6,7,8,9,10, and these are the sequence numbers of the frames. Mainly, the sequence number is decided by the sender's window size. But, for the better understanding, we took the running sequence numbers, i.e., 0,1,2,3,4,5,6,7,8,9,10. Let's consider the window size as 4, which means that the four frames can be sent at a time before expecting the acknowledgment of the first frame. Step 1: Firstly, the sender will send the first four frames to the receiver, i.e., 0,1,2,3, and now the sender is expected to receive the acknowledgment of the 0th frame.
Let's assume that the receiver has sent the acknowledgment for the 0 frame, and the receiver has successfully received it.
The sender will then send the next frame, i.e., 4, and the window slides containing four frames (1,2,3,4).
The receiver will then send the acknowledgment for the frame no 1. After receiving the acknowledgment, the sender will send the next frame, i.e., frame no 5, and the window will slide having four frames (2,3,4,5).
Now, let's assume that the receiver is not acknowledging the frame no 2, either the frame is lost, or the acknowledgment is lost. Instead of sending the frame no 6, the sender Go-Back to 2, which is the first frame of the current window, retransmits all the frames in the current window, i.e., 2,3,4,5.
Important points related to Go-Back-N ARQ:
Let's understand the Go-Back-N ARQ through an example. Example 1: In GB4, if every 6th packet being transmitted is lost and if we have to spend 10 packets then how many transmissions are required? Solution: Here, GB4 means that N is equal to 4. The size of the sender's window is 4. Step 1: As the window size is 4, so four packets are transferred at a time, i.e., packet no 1, packet no 2, packet no 3, and packet no 4.
Step 2: Once the transfer of window size is completed, the sender receives the acknowledgment of the first frame, i.e., packet no1. As the acknowledgment receives, the sender sends the next packet, i.e., packet no 5. In this case, the window slides having four packets, i.e., 2,3,4,5 and excluded the packet 1 as the acknowledgment of the packet 1 has been received successfully.
Step 3: Now, the sender receives the acknowledgment of packet 2. After receiving the acknowledgment for packet 2, the sender sends the next packet, i.e., packet no 6. As mentioned in the question that every 6th is being lost, so this 6th packet is lost, but the sender does not know that the 6th packet has been lost.
Step 4: The sender receives the acknowledgment for the packet no 3. After receiving the acknowledgment of 3rd packet, the sender sends the next packet, i.e., 7th packet. The window will slide having four packets, i.e., 4, 5, 6, 7.
Step 5: When the packet 7 has been sent, then the sender receives the acknowledgment for the packet no 4. When the sender has received the acknowledgment, then the sender sends the next packet, i.e., the 8th packet. The window will slide having four packets, i.e., 5, 6, 7, 8.
Step 6: When the packet 8 is sent, then the sender receives the acknowledgment of packet 5. On receiving the acknowledgment of packet 5, the sender sends the next packet, i.e., 9th packet. The window will slide having four packets, i.e., 6, 7, 8, 9.
Step 7: The current window is holding four packets, i.e., 6, 7, 8, 9, where the 6th packet is the first packet in the window. As we know, the 6th packet has been lost, so the sender receives the negative acknowledgment NAK(6). As we know that every 6th packet is being lost, so the counter will be restarted from 1. So, the counter values 1, 2, 3 are given to the 7th packet, 8th packet, 9th packet respectively.
Step 8: As it is Go-BACK, so it retransmits all the packets of the current window. It will resend 6, 7, 8, 9. The counter values of 6, 7, 8, 9 are 4, 5, 6, 1, respectively. In this case, the 8th packet is lost as it has a 6-counter value, so the counter variable will again be restarted from 1.
Step 9: After the retransmission, the sender receives the acknowledgment of packet 6. On receiving the acknowledgment of packet 6, the sender sends the 10th packet. Now, the current window is holding four packets, i.e., 7, 8, 9, 10.
Step 10: When the 10th packet is sent, the sender receives the acknowledgment of packet 7. Now the current window is holding three packets, 8, 9 and 10. The counter values of 8, 9, 10 are 6, 1, 2.
Step 11: As the 8th packet has 6 counter value which means that 8th packet has been lost, and the sender receives NAK (8). Step 12: Since the sender has received the negative acknowledgment for the 8th packet, it resends all the packets of the current window, i.e., 8, 9, 10.
Step 13: The counter values of 8, 9, 10 are 3, 4, 5, respectively, so their acknowledgments have been received successfully. We conclude from the above figure that total 17 transmissions are required. A Protocol Using Selective Repeat Selective repeat protocol, also called Selective Repeat ARQ (Automatic Repeat reQuest), is a data link layer protocol that uses sliding window method for reliable delivery of data frames. Here, only the erroneous or lost frames are retransmitted, while the good frames are received and buffered. It uses two windows of equal size: a sending window that stores the frames to be sent and a receiving window that stores the frames receive by the receiver. The size is half the maximum sequence number of the frame. For example, if the sequence number is from 0 – 15, the window size will be 8. Selective Repeat protocol provides for sending multiple frames depending upon the availability of frames in the sending window, even if it does not receive acknowledgement for any frame in the interim. The maximum number of frames that can be sent depends upon the size of the sending window. The receiver records the sequence number of the earliest incorrect or un-received frame. It then fills the receiving window with the subsequent frames that it has received. It sends the sequence number of the missing frame along with every acknowledgement frame. The sender continues to send frames that are in its sending window. Once, it has sent all the frames in the window, it retransmits the frame whose sequence number is given by the acknowledgements. It then continues sending the other frames. Sender Site Algorithm of Selective Repeat Protocol begin frame s; //s denotes frame to be sent frame t; //t is temporary frame S_window = power(2,m-1); //Assign maximum window size SeqFirst = 0; // Sequence number of first frame in window SeqN = 0; // Sequence number of Nth frame window while (true) //check repeatedly do Wait_For_Event(); //wait for availability of packet if ( Event(Request_For_Transfer)) then //check if window is full if (SeqN–SeqFirst >= S_window) then doNothing(); end if; Get_Data_From_Network_Layer(); s = Make_Frame(); s.seq = SeqN; Store_Copy_Frame(s); Send_Frame(s); Start_Timer(s); SeqN = SeqN + 1; end if; if ( Event(Frame_Arrival) then r = Receive_Acknowledgement(); //Resend frame whose sequence number is with ACK if ( r.type = NAK) then if ( NAK_No > SeqFirst && NAK_No < SeqN ) then Retransmit( s.seq(NAK_No)); Start_Timer(s); end if //Remove frames from sending window with positive ACK else if ( r.type = ACK ) then Remove_Frame(s.seq(SeqFirst)); Stop_Timer(s); SeqFirst = SeqFirst + 1; end if end if // Resend frame if acknowledgement haven’t been received if ( Event(Time_Out)) then Start_Timer(s); Retransmit_Frame(s); end if end Receiver Site Algorithm of Selective Repeat Protocol Begin frame f; RSeqNo = 0; // Initialise sequence number of expected frame NAKsent = false; ACK = false; For each slot in receive_window Mark(slot)=false; while (true) //check repeatedly do Wait_For_Event(); //wait for arrival of frame if ( Event(Frame_Arrival) then Receive_Frame_From_Physical_Layer(); if ( Corrupted ( f.SeqNo ) AND NAKsent = false) then SendNAK(f.SeqNo); NAKsent = true; end if if ( f.SeqNo != RSeqNo AND NAKsent = false ) then SendNAK(f.SeqNo); NAKsent = true; if ( f.SeqNo is in receive_window ) then if ( Mark(RSeqNo) = false ) then Store_frame(f.SeqNo); Mark(RSeqNo) = true; end if end if else while ( Mark(RSeqNo)) Extract_Data(RSeqNo); Deliver_Data_To_Network_Layer(); RSeqNo = RSeqNo + 1; Send_ACK(RSeqNo); end while end if end if end while end
The sliding window is a technique for sending multiple frames at a time. It controls the data packets between the two devices where reliable and gradual delivery of data frames is needed. It is also used in TCP (Transmission Control Protocol). In this technique, each frame has sent from the sequence number. The sequence numbers are used to find the missing data in the receiver end. The purpose of the sliding window technique is to avoid duplicate data, so it uses the sequence number. Types of Sliding Window Protocol Sliding window protocol has two types:
Go-Back-N ARQ protocol is also known as Go-Back-N Automatic Repeat Request. It is a data link layer protocol that uses a sliding window method. In this, if any frame is corrupted or lost, all subsequent frames have to be sent again. The size of the sender window is N in this protocol. For example, Go-Back-8, the size of the sender window, will be 8. The receiver window size is always 1. If the receiver receives a corrupted frame, it cancels it. The receiver does not accept a corrupted frame. When the timer expires, the sender sends the correct frame again. The design of the Go-Back-N ARQ protocol is shown below.
The example of Go-Back-N ARQ is shown below in the figure.
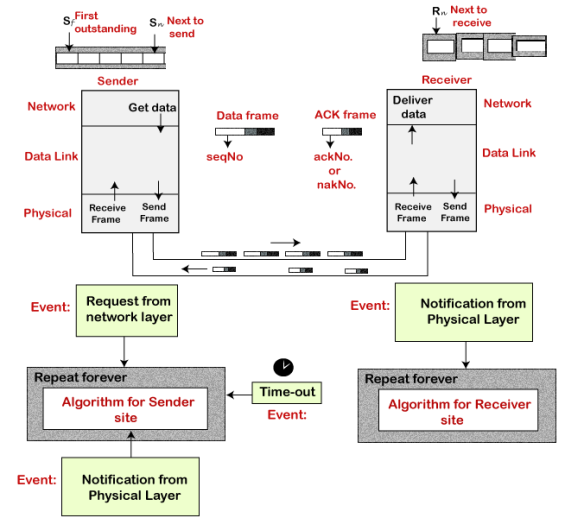
Selective Repeat ARQ is also known as the Selective Repeat Automatic Repeat Request. It is a data link layer protocol that uses a sliding window method. The Go-back-N ARQ protocol works well if it has fewer errors. But if there is a lot of error in the frame, lots of bandwidth loss in sending the frames again. So, we use the Selective Repeat ARQ protocol. In this protocol, the size of the sender window is always equal to the size of the receiver window. The size of the sliding window is always greater than 1. If the receiver receives a corrupt frame, it does not directly discard it. It sends a negative acknowledgment to the sender. The sender sends that frame again as soon as on the receiving negative acknowledgment. There is no waiting for any time-out to send that frame. The design of the Selective Repeat ARQ protocol is shown below.
The example of the Selective Repeat ARQ protocol is shown below in the figure.
Difference between the Go-Back-N ARQ and Selective Repeat ARQ?
Communications are mostly full – duplex in nature, i.e. data transmission occurs in both directions. A method to achieve full – duplex communication is to consider both the communication as a pair of simplex communication. Each link comprises a forward channel for sending data and a reverse channel for sending acknowledgments. However, in the above arrangement, traffic load doubles for each data unit that is transmitted. Half of all data transmission comprise of transmission of acknowledgments. So, a solution that provides better utilization of bandwidth is piggybacking. Here, sending of acknowledgment is delayed until the next data frame is available for transmission. The acknowledgment is then hooked onto the outgoing data frame. The data frame consists of an ack field. The size of the ack field is only a few bits, while an acknowledgment frame comprises of several bytes. Thus, a substantial gain is obtained in reducing bandwidth requirement. Suppose that there are two communication stations X and Y. The data frames transmitted have an acknowledgment field, ack field that is of a few bits length. Additionally, there are frames for sending acknowledgments, ACK frames. The purpose is to minimize the ACK frames. The three principles governing piggybacking when the station X wants to communicate with station Y are −
The following diagram illustrates the three scenario −
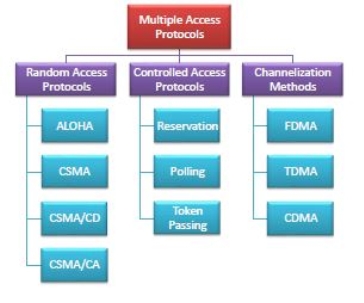
Multiple Access Protocols in Computer Networks Multiple access protocols are a set of protocols operating in the Medium Access Control sublayer (MAC sublayer) of the Open Systems Interconnection (OSI) model. These protocols allow a number of nodes or users to access a shared network channel. Several data streams originating from several nodes are transferred through the multi-point transmission channel. The objectives of multiple access protocols are optimization of transmission time, minimization of collisions and avoidance of crosstalks. Categories of Multiple Access Protocols Multiple access protocols can be broadly classified into three categories - random access protocols, controlled access protocols and channelization protocols.
Fig 11 – Multiple Access Protocols Random access protocols assign uniform priority to all connected nodes. Any node can send data if the transmission channel is idle. No fixed time or fixed sequence is given for data transmission. The four random access protocols are−
Controlled access protocols allow only one node to send data at a given time.Before initiating transmission, a node seeks information from other nodes to determine which station has the right to send. This avoids collision of messages on the shared channel. The station can be assigned the right to send by the following three methods−
Channelization are a set of methods by which the available bandwidth is divided among the different nodes for simultaneous data transfer. The three channelization methods are−
|
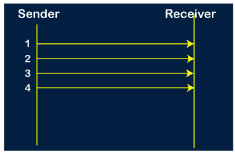
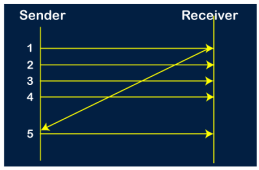
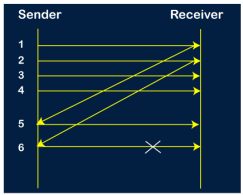
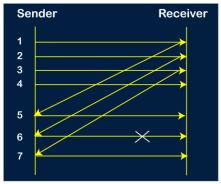
Key takeaways
- Before understanding the stop and Wait protocol, we first know about the error control mechanism. The error control mechanism is used so that the received data should be exactly same whatever sender has sent the data. The error control mechanism is divided into two categories, i.e., Stop and Wait ARQ and sliding window. The sliding window is further divided into two categories, i.e., Go Back N, and Selective Repeat. Based on the usage, the people select the error control mechanism whether it is stop and wait or sliding window.
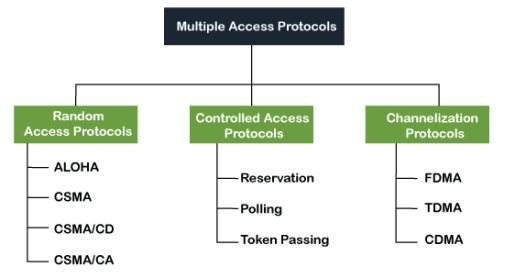
The data link layer is used in a computer network to transmit the data between two devices or nodes. It divides the layer into parts such as data link control and the multiple access resolution/protocol. The upper layer has the responsibility to flow control and the error control in the data link layer, and hence it is termed as logical of data link control. Whereas the lower sub-layer is used to handle and reduce the collision or multiple access on a channel. Hence it is termed as media access control or the multiple access resolutions. A data link control is a reliable channel for transmitting data over a dedicated link using various techniques such as framing, error control and flow control of data packets in the computer network. What is a multiple access protocol? When a sender and receiver have a dedicated link to transmit data packets, the data link control is enough to handle the channel. Suppose there is no dedicated path to communicate or transfer the data between two devices. In that case, multiple stations access the channel and simultaneously transmits the data over the channel. It may create collision and cross talk. Hence, the multiple access protocol is required to reduce the collision and avoid crosstalk between the channels. For example, suppose that there is a classroom full of students. When a teacher asks a question, all the students (small channels) in the class start answering the question at the same time (transferring the data simultaneously). All the students respond at the same time due to which data is overlap or data lost. Therefore it is the responsibility of a teacher (multiple access protocol) to manage the students and make them one answer. Following are the types of multiple access protocol that is subdivided into the different process as:
Fig 12 - Types of multiple access protocol In this protocol, all the station has the equal priority to send the data over a channel. In random access protocol, one or more stations cannot depend on another station nor any station control another station. Depending on the channel's state (idle or busy), each station transmits the data frame. However, if more than one station sends the data over a channel, there may be a collision or data conflict. Due to the collision, the data frame packets may be lost or changed. And hence, it does not receive by the receiver end. Following are the different methods of random-access protocols for broadcasting frames on the channel.
It is designed for wireless LAN (Local Area Network) but can also be used in a shared medium to transmit data. Using this method, any station can transmit data across a network simultaneously when a data frameset is available for transmission. Aloha Rules
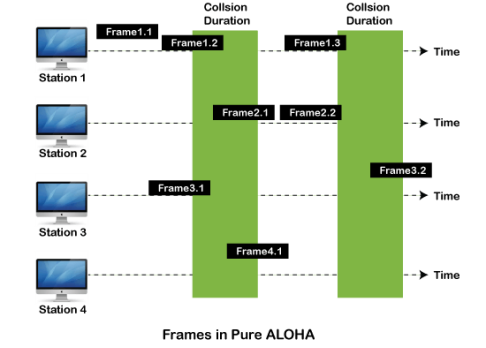
Fig 13 – Types of ALOHA Pure Aloha Whenever data is available for sending over a channel at stations, we use Pure Aloha. In pure Aloha, when each station transmits data to a channel without checking whether the channel is idle or not, the chances of collision may occur, and the data frame can be lost. When any station transmits the data frame to a channel, the pure Aloha waits for the receiver's acknowledgment. If it does not acknowledge the receiver end within the specified time, the station waits for a random amount of time, called the backoff time (Tb). And the station may assume the frame has been lost or destroyed. Therefore, it retransmits the frame until all the data are successfully transmitted to the receiver.
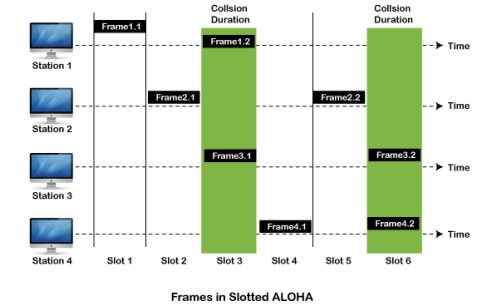
As we can see in the figure above, there are four stations for accessing a shared channel and transmitting data frames. Some frames collide because most stations send their frames at the same time. Only two frames, frame 1.1 and frame 2.2, are successfully transmitted to the receiver end. At the same time, other frames are lost or destroyed. Whenever two frames fall on a shared channel simultaneously, collisions can occur, and both will suffer damage. If the new frame's first bit enters the channel before finishing the last bit of the second frame. Both frames are completely finished, and both stations must retransmit the data frame. Slotted Aloha The slotted Aloha is designed to overcome the pure Aloha's efficiency because pure Aloha has a very high possibility of frame hitting. In slotted Aloha, the shared channel is divided into a fixed time interval called slots. So that, if a station wants to send a frame to a shared channel, the frame can only be sent at the beginning of the slot, and only one frame is allowed to be sent to each slot. And if the stations are unable to send data to the beginning of the slot, the station will have to wait until the beginning of the slot for the next time. However, the possibility of a collision remains when trying to send a frame at the beginning of two or more station time slot.
CSMA (Carrier Sense Multiple Access) It is a carrier sense multiple access based on media access protocol to sense the traffic on a channel (idle or busy) before transmitting the data. It means that if the channel is idle, the station can send data to the channel. Otherwise, it must wait until the channel becomes idle. Hence, it reduces the chances of a collision on a transmission medium.
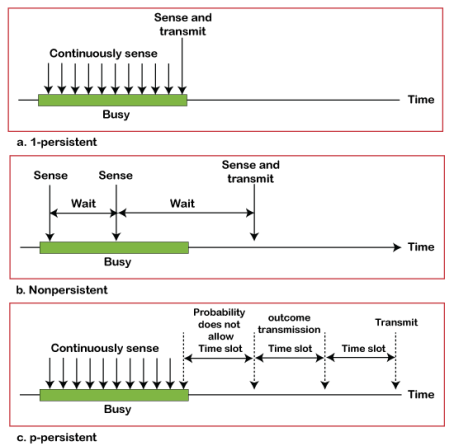
CSMA Access Modes 1-Persistent: In the 1-Persistent mode of CSMA that defines each node, first sense the shared channel and if the channel is idle, it immediately sends the data. Else it must wait and keep track of the status of the channel to be idle and broadcast the frame unconditionally as soon as the channel is idle. Non-Persistent: It is the access mode of CSMA that defines before transmitting the data, each node must sense the channel, and if the channel is inactive, it immediately sends the data. Otherwise, the station must wait for a random time (not continuously), and when the channel is found to be idle, it transmits the frames. P-Persistent: It is the combination of 1-Persistent and Non-persistent modes. The P-Persistent mode defines that each node senses the channel, and if the channel is inactive, it sends a frame with a P probability. If the data is not transmitted, it waits for a (q = 1-p probability) random time and resumes the frame with the next time slot. O- Persistent: It is an O-persistent method that defines the superiority of the station before the transmission of the frame on the shared channel. If it is found that the channel is inactive, each station waits for its turn to retransmit the data.
It is a carrier sense multiple access/ collision detection network protocol to transmit data frames. The CSMA/CD protocol works with a medium access control layer. Therefore, it first senses the shared channel before broadcasting the frames, and if the channel is idle, it transmits a frame to check whether the transmission was successful. If the frame is successfully received, the station sends another frame. If any collision is detected in the CSMA/CD, the station sends a jam/ stop signal to the shared channel to terminate data transmission. After that, it waits for a random time before sending a frame to a channel. It is a carrier sense multiple access/collision avoidance network protocol for carrier transmission of data frames. It is a protocol that works with a medium access control layer. When a data frame is sent to a channel, it receives an acknowledgment to check whether the channel is clear. If the station receives only a single (own) acknowledgment, that means the data frame has been successfully transmitted to the receiver. But if it gets two signals (its own and one more in which the collision of frames), a collision of the frame occurs in the shared channel. Detects the collision of the frame when a sender receives an acknowledgment signal. Following are the methods used in the CSMA/ CA to avoid the collision: Interframe space: In this method, the station waits for the channel to become idle, and if it gets the channel is idle, it does not immediately send the data. Instead of this, it waits for some time, and this time period is called the Interframe space or IFS. However, the IFS time is often used to define the priority of the station. Contention window: In the Contention window, the total time is divided into different slots. When the station/ sender is ready to transmit the data frame, it chooses a random slot number of slots as wait time. If the channel is still busy, it does not restart the entire process, except that it restarts the timer only to send data packets when the channel is inactive. Acknowledgment: In the acknowledgment method, the sender station sends the data frame to the shared channel if the acknowledgment is not received ahead of time. It is a method of reducing data frame collision on a shared channel. In the controlled access method, each station interacts and decides to send a data frame by a particular station approved by all other stations. It means that a single station cannot send the data frames unless all other stations are not approved. It has three types of controlled access: Reservation, Polling, and Token Passing. It is a channelization protocol that allows the total usable bandwidth in a shared channel to be shared across multiple stations based on their time, distance and codes. It can access all the stations at the same time to send the data frames to the channel. Following are the various methods to access the channel based on their time, distance and codes:
FDMA It is a frequency division multiple access (FDMA) method used to divide the available bandwidth into equal bands so that multiple users can send data through a different frequency to the subchannel. Each station is reserved with a particular band to prevent the crosstalk between the channels and interferences of stations.
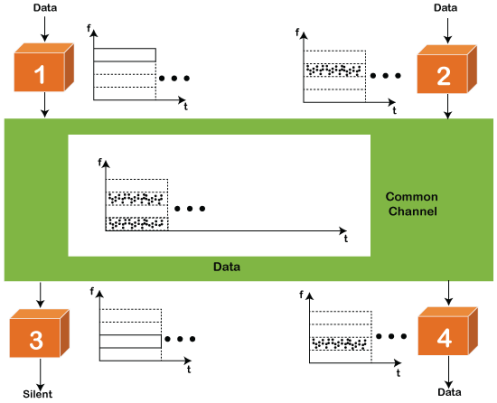
TDMA Time Division Multiple Access (TDMA) is a channel access method. It allows the same frequency bandwidth to be shared across multiple stations. And to avoid collisions in the shared channel, it divides the channel into different frequency slots that allocate stations to transmit the data frames. The same frequency bandwidth into the shared channel by dividing the signal into various time slots to transmit it. However, TDMA has an overhead of synchronization that specifies each station's time slot by adding synchronization bits to each slot. CDMA The code division multiple access (CDMA) is a channel access method. In CDMA, all stations can simultaneously send the data over the same channel. It means that it allows each station to transmit the data frames with full frequency on the shared channel at all times. It does not require the division of bandwidth on a shared channel based on time slots. If multiple stations send data to a channel simultaneously, their data frames are separated by a unique code sequence. Each station has a different unique code for transmitting the data over a shared channel. For example, there are multiple users in a room that are continuously speaking. Data is received by the users if only two-person interact with each other using the same language. Similarly, in the network, if different stations communicate with each other simultaneously with different code language. |

Key takeaways
- When a sender and receiver have a dedicated link to transmit data packets, the data link control is enough to handle the channel. Suppose there is no dedicated path to communicate or transfer the data between two devices. In that case, multiple stations access the channel and simultaneously transmits the data over the channel. It may create collision and cross talk. Hence, the multiple access protocol is required to reduce the collision and avoid crosstalk between the channels.
- For example, suppose that there is a classroom full of students. When a teacher asks a question, all the students (small channels) in the class start answering the question at the same time (transferring the data simultaneously). All the students respond at the same time due to which data is overlap or data lost. Therefore it is the responsibility of a teacher (multiple access protocol) to manage the students and make them one answer.
Referencs
1. Computer Networks, 8th Edition, Andrew S. Tanenbaum, Pearson New International Edition.
2. Internetworking with TCP/IP, Volume 1, 6th Edition Douglas Comer, Prentice Hall of India.
3. TCP/IP Illustrated, Volume 1, W. Richard Stevens, Addison-Wesley, United States of America.
UNIT-2
Data Link Layer and Medium Access Sub Layer
Error Correction codes are used to detect and correct the errors when data is transmitted from the sender to the receiver. Error Correction can be handled in two ways:
A single additional bit can detect the error, but cannot correct it. For correcting the errors, one has to know the exact position of the error. For example, If we want to calculate a single-bit error, the error correction code will determine which one of seven bits is in error. To achieve this, we have to add some additional redundant bits. Suppose r is the number of redundant bits and d is the total number of the data bits. The number of redundant bits r can be calculated by using the formula: 2r>=d+r+1 The value of r is calculated by using the above formula. For example, if the value of d is 4, then the possible smallest value that satisfies the above relation would be 3. To determine the position of the bit which is in error, a technique developed by R.W Hamming is Hamming code which can be applied to any length of the data unit and uses the relationship between data units and redundant units. Parity bits: The bit which is appended to the original data of binary bits so that the total number of 1s is even or odd. Even parity: To check for even parity, if the total number of 1s is even, then the value of the parity bit is 0. If the total number of 1s occurrences is odd, then the value of the parity bit is 1. Odd Parity: To check for odd parity, if the total number of 1s is even, then the value of parity bit is 1. If the total number of 1s is odd, then the value of parity bit is 0.
Relationship b/w Error position & binary number.
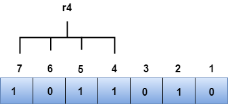
Let's understand the concept of Hamming code through an example: Suppose the original data is 1010 which is to be sent. Total number of data bits 'd' = 4 Number of redundant bits r : 2r >= d+r+1 2r>= 4+r+1 Therefore, the value of r is 3 that satisfies the above relation. Total number of bits = d+r = 4+3 = 7; Determining the position of the redundant bits The number of redundant bits is 3. The three bits are represented by r1, r2, r4. The position of the redundant bits is calculated with corresponds to the raised power of 2. Therefore, their corresponding positions are 1, 21, 22.
Representation of Data on the addition of parity bits:
The r1 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the first position.
We observe from the above figure that the bit positions that includes 1 in the first position are 1, 3, 5, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r1 is even, therefore, the value of the r1 bit is 0. The r2 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the second position.
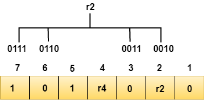
We observe from the above figure that the bit positions that includes 1 in the second position are 2, 3, 6, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r2 is odd, therefore, the value of the r2 bit is 1. The r4 bit is calculated by performing a parity check on the bit positions whose binary representation includes 1 in the third position.
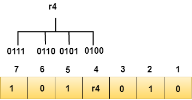
We observe from the above figure that the bit positions that includes 1 in the third position are 4, 5, 6, 7. Now, we perform the even-parity check at these bit positions. The total number of 1 at these bit positions corresponding to r4 is even, therefore, the value of the r4 bit is 0. Data transferred is given below:
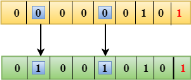
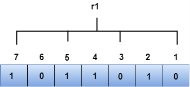
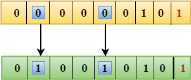
Suppose the 4th bit is changed from 0 to 1 at the receiving end, then parity bits are recalculated. The bit positions of the r1 bit are 1,3,5,7
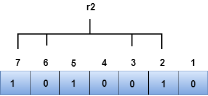
We observe from the above figure that the binary representation of r1 is 1100. Now, we perform the even-parity check, the total number of 1s appearing in the r1 bit is an even number. Therefore, the value of r1 is 0. The bit positions of r2 bit are 2,3,6,7.
We observe from the above figure that the binary representation of r2 is 1001. Now, we perform the even-parity check, the total number of 1s appearing in the r2 bit is an even number. Therefore, the value of r2 is 0. The bit positions of r4 bit are 4,5,6,7.
We observe from the above figure that the binary representation of r4 is 1011. Now, we perform the even-parity check, the total number of 1s appearing in the r4 bit is an odd number. Therefore, the value of r4 is 1.
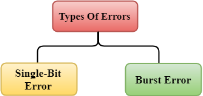
When data is transmitted from one device to another device, the system does not guarantee whether the data received by the device is identical to the data transmitted by another device. An Error is a situation when the message received at the receiver end is not identical to the message transmitted.
Fig 1 – Types of errors Errors can be classified into two categories:
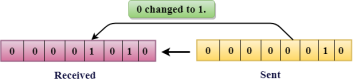
The only one bit of a given data unit is changed from 1 to 0 or from 0 to 1.
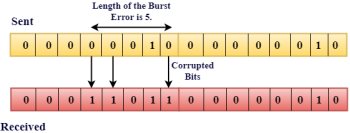
Fig 2 – Single bit error In the above figure, the message which is sent is corrupted as single-bit, i.e., 0 bit is changed to 1. Single-Bit Error does not appear more likely in Serial Data Transmission. For example, Sender sends the data at 10 Mbps, this means that the bit lasts only for 1 ?s and for a single-bit error to occurred, a noise must be more than 1 ?s. Single-Bit Error mainly occurs in Parallel Data Transmission. For example, if eight wires are used to send the eight bits of a byte, if one of the wire is noisy, then single-bit is corrupted per byte. The two or more bits are changed from 0 to 1 or from 1 to 0 is known as Burst Error. The Burst Error is determined from the first corrupted bit to the last corrupted bit.
Fig 3 - Burst Error The duration of noise in Burst Error is more than the duration of noise in Single-Bit. Burst Errors are most likely to occurr in Serial Data Transmission. The number of affected bits depends on the duration of the noise and data rate. The most popular Error Detecting Techniques are:
Drawbacks Of Single Parity Checking
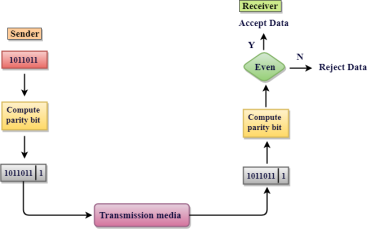
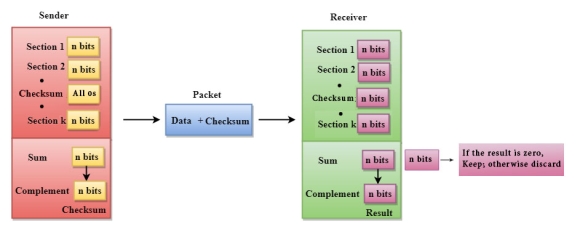
A Checksum is an error detection technique based on the concept of redundancy. It is divided into two parts: A Checksum is generated at the sending side. Checksum generator subdivides the data into equal segments of n bits each, and all these segments are added together by using one's complement arithmetic. The sum is complemented and appended to the original data, known as checksum field. The extended data is transmitted across the network. Suppose L is the total sum of the data segments, then the checksum would be ?L
Fig 6 - Checksum
A Checksum is verified at the receiving side. The receiver subdivides the incoming data into equal segments of n bits each, and all these segments are added together, and then this sum is complemented. If the complement of the sum is zero, then the data is accepted otherwise data is rejected.
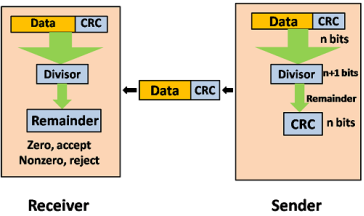
CRC is a redundancy error technique used to determine the error. Following are the steps used in CRC for error detection:
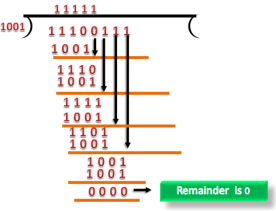
If the resultant of this division is zero which means that it has no error, and the data is accepted. If the resultant of this division is not zero which means that the data consists of an error. Therefore, the data is discarded.
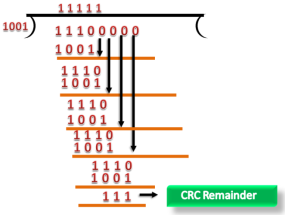
Fig 7 – Data CRC Let's understand this concept through an example: Suppose the original data is 11100 and divisor is 1001.
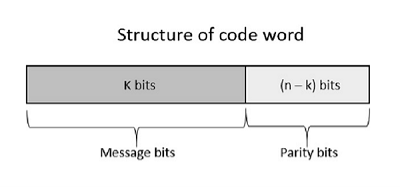
Noise or Error is the main problem in the signal, which disturbs the reliability of the communication system. Error control coding is the coding procedure done to control the occurrences of errors. These techniques help in Error Detection and Error Correction. There are many different error correcting codes depending upon the mathematical principles applied to them. But, historically, these codes have been classified into Linear block codes and Convolution codes. In the linear block codes, the parity bits and message bits have a linear combination, which means that the resultant code word is the linear combination of any two code words. Let us consider some blocks of data, which contains k bits in each block. These bits are mapped with the blocks which has n bits in each block. Here n is greater than k. The transmitter adds redundant bits which are n−k bits. The ratio k/n is the code rate. It is denoted by r and the value of r is r < 1. The n−k bits added here, are parity bits. Parity bits help in error detection and error correction, and also in locating the data. In the data being transmitted, the left most bits of the code word correspond to the message bits, and the right most bits of the code word correspond to the parity bits. Any linear block code can be a systematic code, until it is altered. Hence, an unaltered block code is called as a systematic code. Following is the representation of the structure of code word, according to their allocation.
Fig 8 – Structure of code word If the message is not altered, then it is called as systematic code. It means, the encryption of the data should not change the data. So far, in the linear codes, we have discussed that systematic unaltered code is preferred. Here, the data of total n bits if transmitted, k bits are message bits and n−k bits are parity bits. In the process of encoding, the parity bits are subtracted from the whole data and the message bits are encoded. Now, the parity bits are again added and the whole data is again encoded. The following figure quotes an example for blocks of data and stream of data, used for transmission of information.
The whole process, stated above is tedious which has drawbacks. The allotment of buffer is a main problem here, when the system is busy. This drawback is cleared in convolution codes. Where the whole stream of data is assigned symbols and then transmitted. As the data is a stream of bits, there is no need of buffer for storage. The linearity property of the code word is that the sum of two code words is also a code word. Hamming codes are the type of linear error correcting codes, which can detect up to two bit errors or they can correct one bit errors without the detection of uncorrected errors. While using the hamming codes, extra parity bits are used to identify a single bit error. To get from one-bit pattern to the other, few bits are to be changed in the data. Such number of bits can be termed as Hamming distance. If the parity has a distance of 2, one-bit flip can be detected. But this can't be corrected. Also, any two bit flips cannot be detected. However, Hamming code is a better procedure than the previously discussed ones in error detection and correction. BCH codes are named after the inventors Bose, Chaudari and Hocquenghem. During the BCH code design, there is control on the number of symbols to be corrected and hence multiple bit correction is possible. BCH codes is a powerful technique in error correcting codes. For any positive integers m ≥ 3 and t < 2m-1 there exists a BCH binary code. Following are the parameters of such code. Block length n = 2m-1 Number of parity-check digits n - k ≤ mt Minimum distance dmin ≥ 2t + 1 This code can be called as t-error-correcting BCH code. The cyclic property of code words is that any cyclic-shift of a code word is also a code word. Cyclic codes follow this cyclic property. For a linear code C, if every code word i.e., C = C1,C2,......Cn from C has a cyclic right shift of components, it becomes a code word. This shift of right is equal to n-1 cyclic left shifts. Hence, it is invariant under any shift. So, the linear code C, as it is invariant under any shift, can be called as a Cyclic code. Cyclic codes are used for error correction. They are mainly used to correct double errors and burst errors. Hence, these are a few error correcting codes, which are to be detected at the receiver. These codes prevent the errors from getting introduced and disturb the communication. They also prevent the signal from getting tapped by unwanted receivers. |



Key takeaways
- Error Correction codes are used to detect and correct the errors when data is transmitted from the sender to the receiver.
- Error Correction can be handled in two ways:
- Backward error correction: Once the error is discovered, the receiver requests the sender to retransmit the entire data unit.
- Forward error correction: In this case, the receiver uses the error-correcting code which automatically corrects the errors.
3. A single additional bit can detect the error, but cannot correct it.
4. For correcting the errors, one has to know the exact position of the error. For example, If we want to calculate a single-bit error, the error correction code will determine which one of seven bits is in error. To achieve this, we have to add some additional redundant bits.
5. Suppose r is the number of redundant bits and d is the total number of the data bits. The number of redundant bits r can be calculated by using the formula:
2r>=d+r+1
6. The value of r is calculated by using the above formula. For example, if the value of d is 4, then the possible smallest value that satisfies the above relation would be 3.
7. To determine the position of the bit which is in error, a technique developed by R.W Hamming is Hamming code which can be applied to any length of the data unit and uses the relationship between data units and redundant units.
Before understanding the stop and Wait protocol, we first know about the error control mechanism. The error control mechanism is used so that the received data should be exactly same whatever sender has sent the data. The error control mechanism is divided into two categories, i.e., Stop and Wait ARQ and sliding window. The sliding window is further divided into two categories, i.e., Go Back N, and Selective Repeat. Based on the usage, the people select the error control mechanism whether it is stop and wait or sliding window. What is Stop and Wait protocol? Here stop and wait means, whatever the data that sender wants to send, he sends the data to the receiver. After sending the data, he stops and waits until he receives the acknowledgment from the receiver. The stop and wait protocol is a flow control protocol where flow control is one of the services of the data link layer. It is a data-link layer protocol which is used for transmitting the data over the noiseless channels. It provides unidirectional data transmission which means that either sending or receiving of data will take place at a time. It provides flow-control mechanism but does not provide any error control mechanism. The idea behind the usage of this frame is that when the sender sends the frame then he waits for the acknowledgment before sending the next frame. Primitives of Stop and Wait Protocol The primitives of stop and wait protocol are: Sender side Rule 1: Sender sends one data packet at a time. Rule 2: Sender sends the next packet only when it receives the acknowledgment of the previous packet. Therefore, the idea of stop and wait protocol in the sender's side is very simple, i.e., send one packet at a time, and do not send another packet before receiving the acknowledgment. Rule 1: Receive and then consume the data packet. Rule 2: When the data packet is consumed, receiver sends the acknowledgment to the sender. Therefore, the idea of stop and wait protocol in the receiver's side is also very simple, i.e., consume the packet, and once the packet is consumed, the acknowledgment is sent. This is known as a flow control mechanism. Working of Stop and Wait protocol
Fig 9 - Working of Stop and Wait protocol The above figure shows the working of the stop and wait protocol. If there is a sender and receiver, then sender sends the packet and that packet is known as a data packet. The sender will not send the second packet without receiving the acknowledgment of the first packet. The receiver sends the acknowledgment for the data packet that it has received. Once the acknowledgment is received, the sender sends the next packet. This process continues until all the packet are not sent. The main advantage of this protocol is its simplicity but it has some disadvantages also. For example, if there are 1000 data packets to be sent, then all the 1000 packets cannot be sent at a time as in Stop and Wait protocol, one packet is sent at a time. Disadvantages of Stop and Wait protocol The following are the problems associated with a stop and wait protocol: 1. Problems occur due to lost data
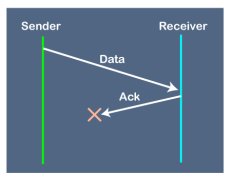
Fig 10 - Problems occur due to lost data Suppose the sender sends the data and the data is lost. The receiver is waiting for the data for a long time. Since the data is not received by the receiver, so it does not send any acknowledgment. Since the sender does not receive any acknowledgment so it will not send the next packet. This problem occurs due to the lost data. In this case, two problems occur:
2. Problems occur due to lost acknowledgment
Suppose the sender sends the data and it has also been received by the receiver. On receiving the packet, the receiver sends the acknowledgment. In this case, the acknowledgment is lost in a network, so there is no chance for the sender to receive the acknowledgment. There is also no chance for the sender to send the next packet as in stop and wait protocol, the next packet cannot be sent until the acknowledgment of the previous packet is received. In this case, one problem occurs:
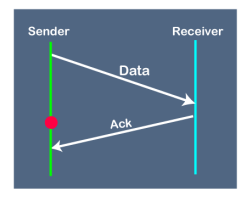
3. Problem due to the delayed data or acknowledgment
Suppose the sender sends the data and it has also been received by the receiver. The receiver then sends the acknowledgment but the acknowledgment is received after the timeout period on the sender's side. As the acknowledgment is received late, so acknowledgment can be wrongly considered as the acknowledgment of some other data packet. Before understanding the working of Go-Back-N ARQ, we first look at the sliding window protocol. As we know that the sliding window protocol is different from the stop-and-wait protocol. In the stop-and-wait protocol, the sender can send only one frame at a time and cannot send the next frame without receiving the acknowledgment of the previously sent frame, whereas, in the case of sliding window protocol, the multiple frames can be sent at a time. The variations of sliding window protocol are Go-Back-N ARQ and Selective Repeat ARQ. Let's understand 'what is Go-Back-N ARQ'. In Go-Back-N ARQ, N is the sender's window size. Suppose we say that Go-Back-3, which means that the three frames can be sent at a time before expecting the acknowledgment from the receiver. It uses the principle of protocol pipelining in which the multiple frames can be sent before receiving the acknowledgment of the first frame. If we have five frames and the concept is Go-Back-3, which means that the three frames can be sent, i.e., frame no 1, frame no 2, frame no 3 can be sent before expecting the acknowledgment of frame no 1. In Go-Back-N ARQ, the frames are numbered sequentially as Go-Back-N ARQ sends the multiple frames at a time that requires the numbering approach to distinguish the frame from another frame, and these numbers are known as the sequential numbers. The number of frames that can be sent at a time totally depends on the size of the sender's window. So, we can say that 'N' is the number of frames that can be sent at a time before receiving the acknowledgment from the receiver. If the acknowledgment of a frame is not received within an agreed-upon time period, then all the frames available in the current window will be retransmitted. Suppose we have sent the frame no 5, but we didn't receive the acknowledgment of frame no 5, and the current window is holding three frames, then these three frames will be retransmitted. The sequence number of the outbound frames depends upon the size of the sender's window. Suppose the sender's window size is 2, and we have ten frames to send, then the sequence numbers will not be 1,2,3,4,5,6,7,8,9,10. Let's understand through an example.
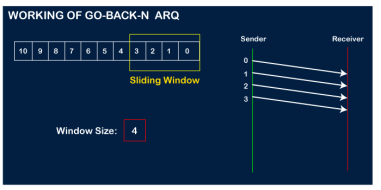
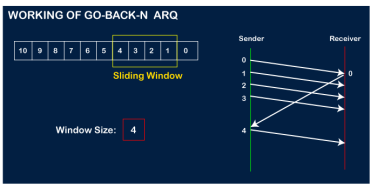
The number of bits in the sequence number is 2 to generate the binary sequence 00,01,10,11. Suppose there are a sender and a receiver, and let's assume that there are 11 frames to be sent. These frames are represented as 0,1,2,3,4,5,6,7,8,9,10, and these are the sequence numbers of the frames. Mainly, the sequence number is decided by the sender's window size. But, for the better understanding, we took the running sequence numbers, i.e., 0,1,2,3,4,5,6,7,8,9,10. Let's consider the window size as 4, which means that the four frames can be sent at a time before expecting the acknowledgment of the first frame. Step 1: Firstly, the sender will send the first four frames to the receiver, i.e., 0,1,2,3, and now the sender is expected to receive the acknowledgment of the 0th frame.
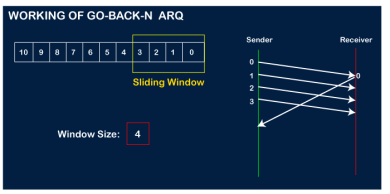
Let's assume that the receiver has sent the acknowledgment for the 0 frame, and the receiver has successfully received it.
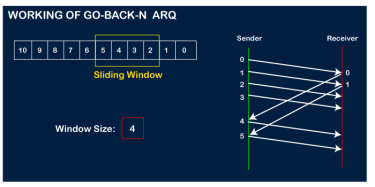
The sender will then send the next frame, i.e., 4, and the window slides containing four frames (1,2,3,4).
The receiver will then send the acknowledgment for the frame no 1. After receiving the acknowledgment, the sender will send the next frame, i.e., frame no 5, and the window will slide having four frames (2,3,4,5).
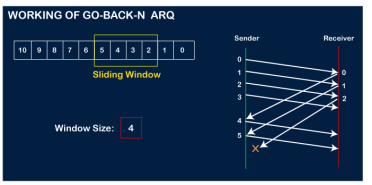
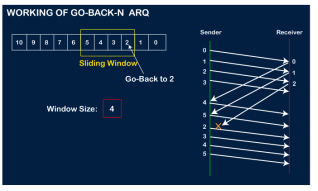
Now, let's assume that the receiver is not acknowledging the frame no 2, either the frame is lost, or the acknowledgment is lost. Instead of sending the frame no 6, the sender Go-Back to 2, which is the first frame of the current window, retransmits all the frames in the current window, i.e., 2,3,4,5.
Important points related to Go-Back-N ARQ:
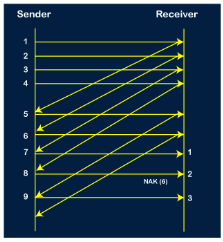
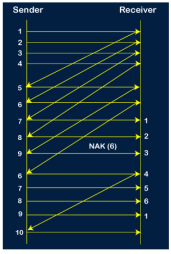
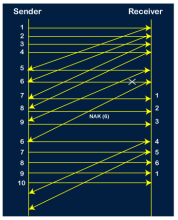
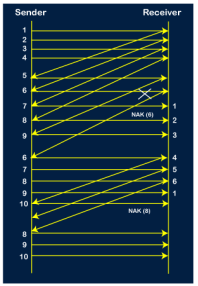
Let's understand the Go-Back-N ARQ through an example. Example 1: In GB4, if every 6th packet being transmitted is lost and if we have to spend 10 packets then how many transmissions are required? Solution: Here, GB4 means that N is equal to 4. The size of the sender's window is 4. Step 1: As the window size is 4, so four packets are transferred at a time, i.e., packet no 1, packet no 2, packet no 3, and packet no 4.
Step 2: Once the transfer of window size is completed, the sender receives the acknowledgment of the first frame, i.e., packet no1. As the acknowledgment receives, the sender sends the next packet, i.e., packet no 5. In this case, the window slides having four packets, i.e., 2,3,4,5 and excluded the packet 1 as the acknowledgment of the packet 1 has been received successfully.
Step 3: Now, the sender receives the acknowledgment of packet 2. After receiving the acknowledgment for packet 2, the sender sends the next packet, i.e., packet no 6. As mentioned in the question that every 6th is being lost, so this 6th packet is lost, but the sender does not know that the 6th packet has been lost.
Step 4: The sender receives the acknowledgment for the packet no 3. After receiving the acknowledgment of 3rd packet, the sender sends the next packet, i.e., 7th packet. The window will slide having four packets, i.e., 4, 5, 6, 7.
Step 5: When the packet 7 has been sent, then the sender receives the acknowledgment for the packet no 4. When the sender has received the acknowledgment, then the sender sends the next packet, i.e., the 8th packet. The window will slide having four packets, i.e., 5, 6, 7, 8.
Step 6: When the packet 8 is sent, then the sender receives the acknowledgment of packet 5. On receiving the acknowledgment of packet 5, the sender sends the next packet, i.e., 9th packet. The window will slide having four packets, i.e., 6, 7, 8, 9.
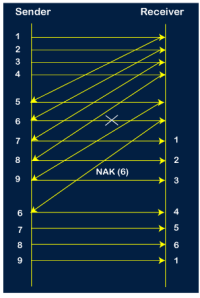
Step 7: The current window is holding four packets, i.e., 6, 7, 8, 9, where the 6th packet is the first packet in the window. As we know, the 6th packet has been lost, so the sender receives the negative acknowledgment NAK(6). As we know that every 6th packet is being lost, so the counter will be restarted from 1. So, the counter values 1, 2, 3 are given to the 7th packet, 8th packet, 9th packet respectively.
Step 8: As it is Go-BACK, so it retransmits all the packets of the current window. It will resend 6, 7, 8, 9. The counter values of 6, 7, 8, 9 are 4, 5, 6, 1, respectively. In this case, the 8th packet is lost as it has a 6-counter value, so the counter variable will again be restarted from 1.
Step 9: After the retransmission, the sender receives the acknowledgment of packet 6. On receiving the acknowledgment of packet 6, the sender sends the 10th packet. Now, the current window is holding four packets, i.e., 7, 8, 9, 10.
Step 10: When the 10th packet is sent, the sender receives the acknowledgment of packet 7. Now the current window is holding three packets, 8, 9 and 10. The counter values of 8, 9, 10 are 6, 1, 2.
Step 11: As the 8th packet has 6 counter value which means that 8th packet has been lost, and the sender receives NAK (8). Step 12: Since the sender has received the negative acknowledgment for the 8th packet, it resends all the packets of the current window, i.e., 8, 9, 10.
Step 13: The counter values of 8, 9, 10 are 3, 4, 5, respectively, so their acknowledgments have been received successfully. We conclude from the above figure that total 17 transmissions are required. A Protocol Using Selective Repeat Selective repeat protocol, also called Selective Repeat ARQ (Automatic Repeat reQuest), is a data link layer protocol that uses sliding window method for reliable delivery of data frames. Here, only the erroneous or lost frames are retransmitted, while the good frames are received and buffered. It uses two windows of equal size: a sending window that stores the frames to be sent and a receiving window that stores the frames receive by the receiver. The size is half the maximum sequence number of the frame. For example, if the sequence number is from 0 – 15, the window size will be 8. Selective Repeat protocol provides for sending multiple frames depending upon the availability of frames in the sending window, even if it does not receive acknowledgement for any frame in the interim. The maximum number of frames that can be sent depends upon the size of the sending window. The receiver records the sequence number of the earliest incorrect or un-received frame. It then fills the receiving window with the subsequent frames that it has received. It sends the sequence number of the missing frame along with every acknowledgement frame. The sender continues to send frames that are in its sending window. Once, it has sent all the frames in the window, it retransmits the frame whose sequence number is given by the acknowledgements. It then continues sending the other frames. Sender Site Algorithm of Selective Repeat Protocol begin frame s; //s denotes frame to be sent frame t; //t is temporary frame S_window = power(2,m-1); //Assign maximum window size SeqFirst = 0; // Sequence number of first frame in window SeqN = 0; // Sequence number of Nth frame window while (true) //check repeatedly do Wait_For_Event(); //wait for availability of packet if ( Event(Request_For_Transfer)) then //check if window is full if (SeqN–SeqFirst >= S_window) then doNothing(); end if; Get_Data_From_Network_Layer(); s = Make_Frame(); s.seq = SeqN; Store_Copy_Frame(s); Send_Frame(s); Start_Timer(s); SeqN = SeqN + 1; end if; if ( Event(Frame_Arrival) then r = Receive_Acknowledgement(); //Resend frame whose sequence number is with ACK if ( r.type = NAK) then if ( NAK_No > SeqFirst && NAK_No < SeqN ) then Retransmit( s.seq(NAK_No)); Start_Timer(s); end if //Remove frames from sending window with positive ACK else if ( r.type = ACK ) then Remove_Frame(s.seq(SeqFirst)); Stop_Timer(s); SeqFirst = SeqFirst + 1; end if end if // Resend frame if acknowledgement haven’t been received if ( Event(Time_Out)) then Start_Timer(s); Retransmit_Frame(s); end if end Receiver Site Algorithm of Selective Repeat Protocol Begin frame f; RSeqNo = 0; // Initialise sequence number of expected frame NAKsent = false; ACK = false; For each slot in receive_window Mark(slot)=false; while (true) //check repeatedly do Wait_For_Event(); //wait for arrival of frame if ( Event(Frame_Arrival) then Receive_Frame_From_Physical_Layer(); if ( Corrupted ( f.SeqNo ) AND NAKsent = false) then SendNAK(f.SeqNo); NAKsent = true; end if if ( f.SeqNo != RSeqNo AND NAKsent = false ) then SendNAK(f.SeqNo); NAKsent = true; if ( f.SeqNo is in receive_window ) then if ( Mark(RSeqNo) = false ) then Store_frame(f.SeqNo); Mark(RSeqNo) = true; end if end if else while ( Mark(RSeqNo)) Extract_Data(RSeqNo); Deliver_Data_To_Network_Layer(); RSeqNo = RSeqNo + 1; Send_ACK(RSeqNo); end while end if end if end while end
The sliding window is a technique for sending multiple frames at a time. It controls the data packets between the two devices where reliable and gradual delivery of data frames is needed. It is also used in TCP (Transmission Control Protocol). In this technique, each frame has sent from the sequence number. The sequence numbers are used to find the missing data in the receiver end. The purpose of the sliding window technique is to avoid duplicate data, so it uses the sequence number. Types of Sliding Window Protocol Sliding window protocol has two types:
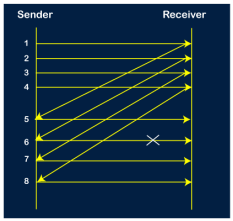
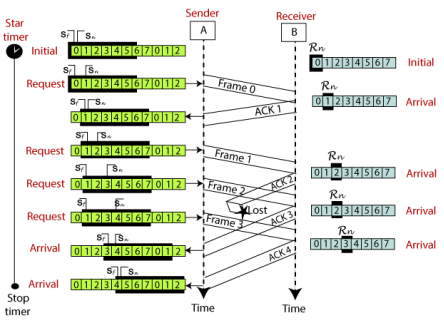
Go-Back-N ARQ protocol is also known as Go-Back-N Automatic Repeat Request. It is a data link layer protocol that uses a sliding window method. In this, if any frame is corrupted or lost, all subsequent frames have to be sent again. The size of the sender window is N in this protocol. For example, Go-Back-8, the size of the sender window, will be 8. The receiver window size is always 1. If the receiver receives a corrupted frame, it cancels it. The receiver does not accept a corrupted frame. When the timer expires, the sender sends the correct frame again. The design of the Go-Back-N ARQ protocol is shown below.
The example of Go-Back-N ARQ is shown below in the figure.
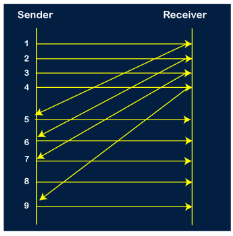
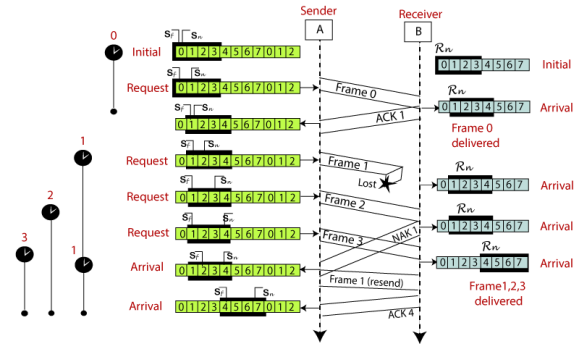
Selective Repeat ARQ is also known as the Selective Repeat Automatic Repeat Request. It is a data link layer protocol that uses a sliding window method. The Go-back-N ARQ protocol works well if it has fewer errors. But if there is a lot of error in the frame, lots of bandwidth loss in sending the frames again. So, we use the Selective Repeat ARQ protocol. In this protocol, the size of the sender window is always equal to the size of the receiver window. The size of the sliding window is always greater than 1. If the receiver receives a corrupt frame, it does not directly discard it. It sends a negative acknowledgment to the sender. The sender sends that frame again as soon as on the receiving negative acknowledgment. There is no waiting for any time-out to send that frame. The design of the Selective Repeat ARQ protocol is shown below.
The example of the Selective Repeat ARQ protocol is shown below in the figure.
Difference between the Go-Back-N ARQ and Selective Repeat ARQ?
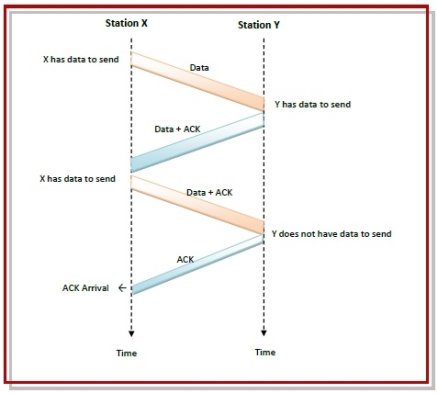
Communications are mostly full – duplex in nature, i.e. data transmission occurs in both directions. A method to achieve full – duplex communication is to consider both the communication as a pair of simplex communication. Each link comprises a forward channel for sending data and a reverse channel for sending acknowledgments. However, in the above arrangement, traffic load doubles for each data unit that is transmitted. Half of all data transmission comprise of transmission of acknowledgments. So, a solution that provides better utilization of bandwidth is piggybacking. Here, sending of acknowledgment is delayed until the next data frame is available for transmission. The acknowledgment is then hooked onto the outgoing data frame. The data frame consists of an ack field. The size of the ack field is only a few bits, while an acknowledgment frame comprises of several bytes. Thus, a substantial gain is obtained in reducing bandwidth requirement. Suppose that there are two communication stations X and Y. The data frames transmitted have an acknowledgment field, ack field that is of a few bits length. Additionally, there are frames for sending acknowledgments, ACK frames. The purpose is to minimize the ACK frames. The three principles governing piggybacking when the station X wants to communicate with station Y are −
The following diagram illustrates the three scenario −
Multiple Access Protocols in Computer Networks Multiple access protocols are a set of protocols operating in the Medium Access Control sublayer (MAC sublayer) of the Open Systems Interconnection (OSI) model. These protocols allow a number of nodes or users to access a shared network channel. Several data streams originating from several nodes are transferred through the multi-point transmission channel. The objectives of multiple access protocols are optimization of transmission time, minimization of collisions and avoidance of crosstalks. Categories of Multiple Access Protocols Multiple access protocols can be broadly classified into three categories - random access protocols, controlled access protocols and channelization protocols.
Fig 11 – Multiple Access Protocols Random access protocols assign uniform priority to all connected nodes. Any node can send data if the transmission channel is idle. No fixed time or fixed sequence is given for data transmission. The four random access protocols are−
Controlled access protocols allow only one node to send data at a given time.Before initiating transmission, a node seeks information from other nodes to determine which station has the right to send. This avoids collision of messages on the shared channel. The station can be assigned the right to send by the following three methods−
Channelization are a set of methods by which the available bandwidth is divided among the different nodes for simultaneous data transfer. The three channelization methods are−
|
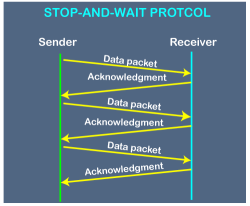
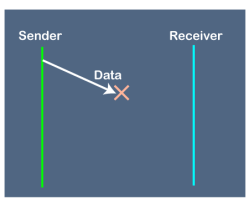
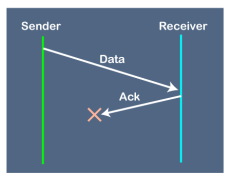
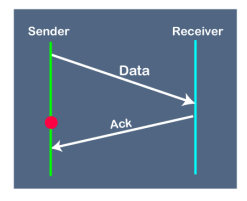
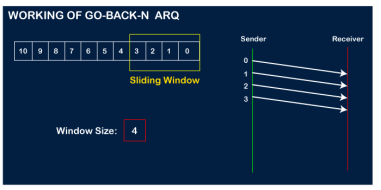
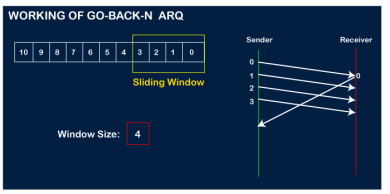
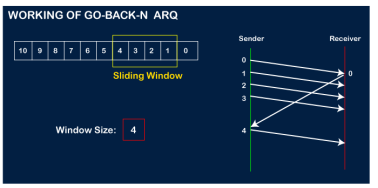
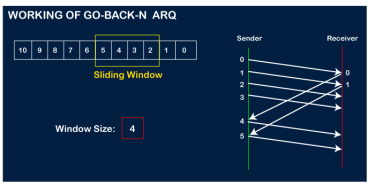
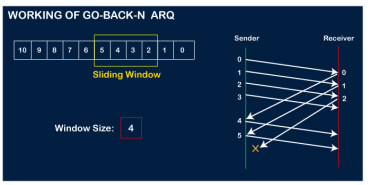
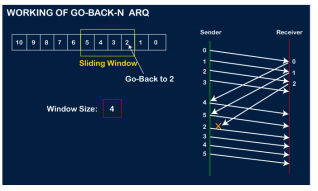
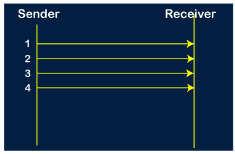
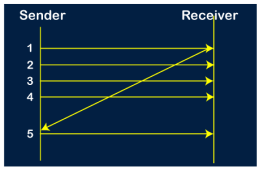
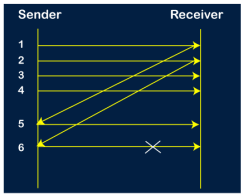
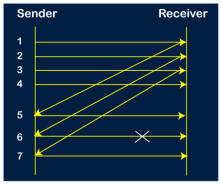
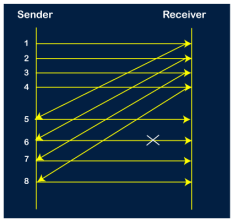
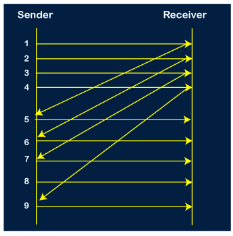
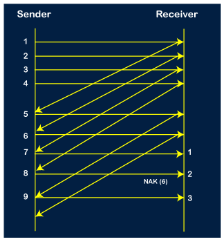
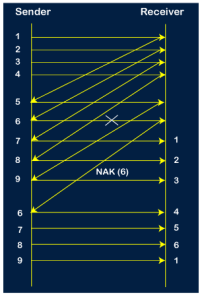
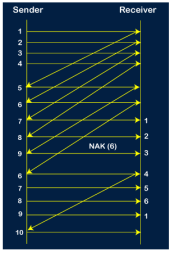
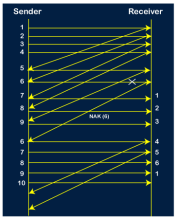
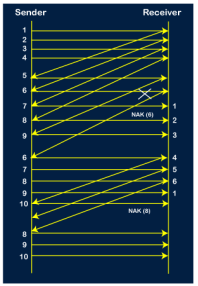
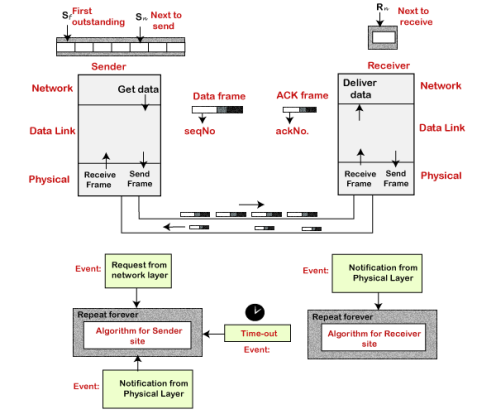
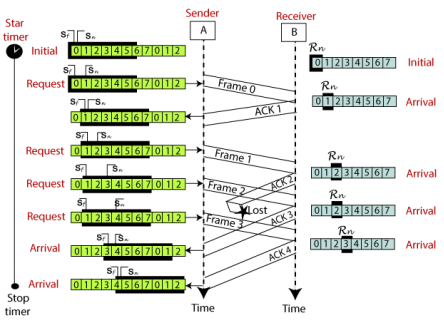
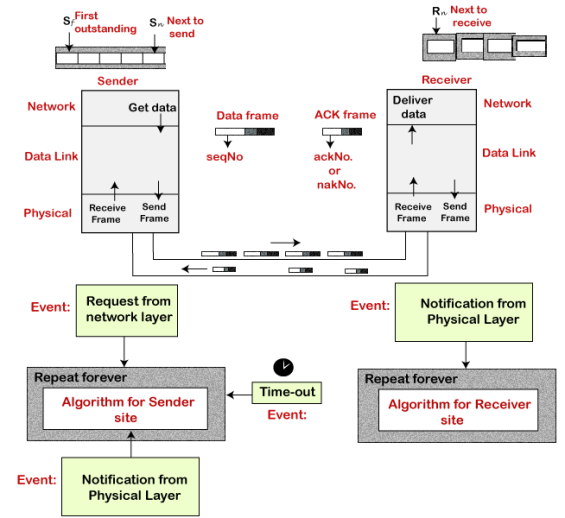
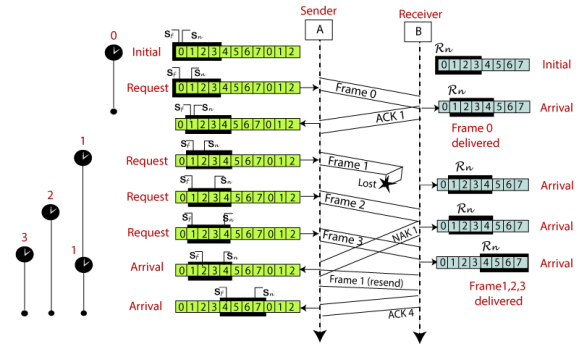
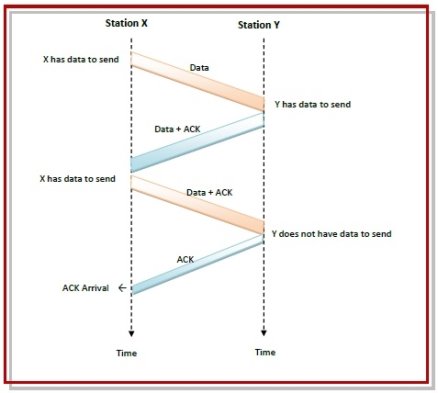
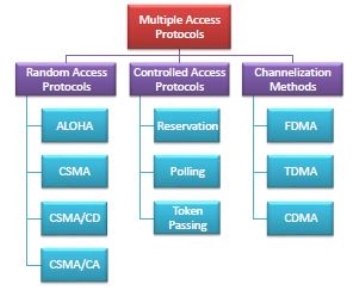
Key takeaways
- Before understanding the stop and Wait protocol, we first know about the error control mechanism. The error control mechanism is used so that the received data should be exactly same whatever sender has sent the data. The error control mechanism is divided into two categories, i.e., Stop and Wait ARQ and sliding window. The sliding window is further divided into two categories, i.e., Go Back N, and Selective Repeat. Based on the usage, the people select the error control mechanism whether it is stop and wait or sliding window.
The data link layer is used in a computer network to transmit the data between two devices or nodes. It divides the layer into parts such as data link control and the multiple access resolution/protocol. The upper layer has the responsibility to flow control and the error control in the data link layer, and hence it is termed as logical of data link control. Whereas the lower sub-layer is used to handle and reduce the collision or multiple access on a channel. Hence it is termed as media access control or the multiple access resolutions. A data link control is a reliable channel for transmitting data over a dedicated link using various techniques such as framing, error control and flow control of data packets in the computer network. What is a multiple access protocol? When a sender and receiver have a dedicated link to transmit data packets, the data link control is enough to handle the channel. Suppose there is no dedicated path to communicate or transfer the data between two devices. In that case, multiple stations access the channel and simultaneously transmits the data over the channel. It may create collision and cross talk. Hence, the multiple access protocol is required to reduce the collision and avoid crosstalk between the channels. For example, suppose that there is a classroom full of students. When a teacher asks a question, all the students (small channels) in the class start answering the question at the same time (transferring the data simultaneously). All the students respond at the same time due to which data is overlap or data lost. Therefore it is the responsibility of a teacher (multiple access protocol) to manage the students and make them one answer. Following are the types of multiple access protocol that is subdivided into the different process as:
Fig 12 - Types of multiple access protocol In this protocol, all the station has the equal priority to send the data over a channel. In random access protocol, one or more stations cannot depend on another station nor any station control another station. Depending on the channel's state (idle or busy), each station transmits the data frame. However, if more than one station sends the data over a channel, there may be a collision or data conflict. Due to the collision, the data frame packets may be lost or changed. And hence, it does not receive by the receiver end. Following are the different methods of random-access protocols for broadcasting frames on the channel.
It is designed for wireless LAN (Local Area Network) but can also be used in a shared medium to transmit data. Using this method, any station can transmit data across a network simultaneously when a data frameset is available for transmission. Aloha Rules
Fig 13 – Types of ALOHA Pure Aloha Whenever data is available for sending over a channel at stations, we use Pure Aloha. In pure Aloha, when each station transmits data to a channel without checking whether the channel is idle or not, the chances of collision may occur, and the data frame can be lost. When any station transmits the data frame to a channel, the pure Aloha waits for the receiver's acknowledgment. If it does not acknowledge the receiver end within the specified time, the station waits for a random amount of time, called the backoff time (Tb). And the station may assume the frame has been lost or destroyed. Therefore, it retransmits the frame until all the data are successfully transmitted to the receiver.
As we can see in the figure above, there are four stations for accessing a shared channel and transmitting data frames. Some frames collide because most stations send their frames at the same time. Only two frames, frame 1.1 and frame 2.2, are successfully transmitted to the receiver end. At the same time, other frames are lost or destroyed. Whenever two frames fall on a shared channel simultaneously, collisions can occur, and both will suffer damage. If the new frame's first bit enters the channel before finishing the last bit of the second frame. Both frames are completely finished, and both stations must retransmit the data frame. Slotted Aloha The slotted Aloha is designed to overcome the pure Aloha's efficiency because pure Aloha has a very high possibility of frame hitting. In slotted Aloha, the shared channel is divided into a fixed time interval called slots. So that, if a station wants to send a frame to a shared channel, the frame can only be sent at the beginning of the slot, and only one frame is allowed to be sent to each slot. And if the stations are unable to send data to the beginning of the slot, the station will have to wait until the beginning of the slot for the next time. However, the possibility of a collision remains when trying to send a frame at the beginning of two or more station time slot.
CSMA (Carrier Sense Multiple Access) It is a carrier sense multiple access based on media access protocol to sense the traffic on a channel (idle or busy) before transmitting the data. It means that if the channel is idle, the station can send data to the channel. Otherwise, it must wait until the channel becomes idle. Hence, it reduces the chances of a collision on a transmission medium.
CSMA Access Modes 1-Persistent: In the 1-Persistent mode of CSMA that defines each node, first sense the shared channel and if the channel is idle, it immediately sends the data. Else it must wait and keep track of the status of the channel to be idle and broadcast the frame unconditionally as soon as the channel is idle. Non-Persistent: It is the access mode of CSMA that defines before transmitting the data, each node must sense the channel, and if the channel is inactive, it immediately sends the data. Otherwise, the station must wait for a random time (not continuously), and when the channel is found to be idle, it transmits the frames. P-Persistent: It is the combination of 1-Persistent and Non-persistent modes. The P-Persistent mode defines that each node senses the channel, and if the channel is inactive, it sends a frame with a P probability. If the data is not transmitted, it waits for a (q = 1-p probability) random time and resumes the frame with the next time slot. O- Persistent: It is an O-persistent method that defines the superiority of the station before the transmission of the frame on the shared channel. If it is found that the channel is inactive, each station waits for its turn to retransmit the data.
It is a carrier sense multiple access/ collision detection network protocol to transmit data frames. The CSMA/CD protocol works with a medium access control layer. Therefore, it first senses the shared channel before broadcasting the frames, and if the channel is idle, it transmits a frame to check whether the transmission was successful. If the frame is successfully received, the station sends another frame. If any collision is detected in the CSMA/CD, the station sends a jam/ stop signal to the shared channel to terminate data transmission. After that, it waits for a random time before sending a frame to a channel. It is a carrier sense multiple access/collision avoidance network protocol for carrier transmission of data frames. It is a protocol that works with a medium access control layer. When a data frame is sent to a channel, it receives an acknowledgment to check whether the channel is clear. If the station receives only a single (own) acknowledgment, that means the data frame has been successfully transmitted to the receiver. But if it gets two signals (its own and one more in which the collision of frames), a collision of the frame occurs in the shared channel. Detects the collision of the frame when a sender receives an acknowledgment signal. Following are the methods used in the CSMA/ CA to avoid the collision: Interframe space: In this method, the station waits for the channel to become idle, and if it gets the channel is idle, it does not immediately send the data. Instead of this, it waits for some time, and this time period is called the Interframe space or IFS. However, the IFS time is often used to define the priority of the station. Contention window: In the Contention window, the total time is divided into different slots. When the station/ sender is ready to transmit the data frame, it chooses a random slot number of slots as wait time. If the channel is still busy, it does not restart the entire process, except that it restarts the timer only to send data packets when the channel is inactive. Acknowledgment: In the acknowledgment method, the sender station sends the data frame to the shared channel if the acknowledgment is not received ahead of time. It is a method of reducing data frame collision on a shared channel. In the controlled access method, each station interacts and decides to send a data frame by a particular station approved by all other stations. It means that a single station cannot send the data frames unless all other stations are not approved. It has three types of controlled access: Reservation, Polling, and Token Passing. It is a channelization protocol that allows the total usable bandwidth in a shared channel to be shared across multiple stations based on their time, distance and codes. It can access all the stations at the same time to send the data frames to the channel. Following are the various methods to access the channel based on their time, distance and codes:
FDMA It is a frequency division multiple access (FDMA) method used to divide the available bandwidth into equal bands so that multiple users can send data through a different frequency to the subchannel. Each station is reserved with a particular band to prevent the crosstalk between the channels and interferences of stations.
TDMA Time Division Multiple Access (TDMA) is a channel access method. It allows the same frequency bandwidth to be shared across multiple stations. And to avoid collisions in the shared channel, it divides the channel into different frequency slots that allocate stations to transmit the data frames. The same frequency bandwidth into the shared channel by dividing the signal into various time slots to transmit it. However, TDMA has an overhead of synchronization that specifies each station's time slot by adding synchronization bits to each slot. CDMA The code division multiple access (CDMA) is a channel access method. In CDMA, all stations can simultaneously send the data over the same channel. It means that it allows each station to transmit the data frames with full frequency on the shared channel at all times. It does not require the division of bandwidth on a shared channel based on time slots. If multiple stations send data to a channel simultaneously, their data frames are separated by a unique code sequence. Each station has a different unique code for transmitting the data over a shared channel. For example, there are multiple users in a room that are continuously speaking. Data is received by the users if only two-person interact with each other using the same language. Similarly, in the network, if different stations communicate with each other simultaneously with different code language. |
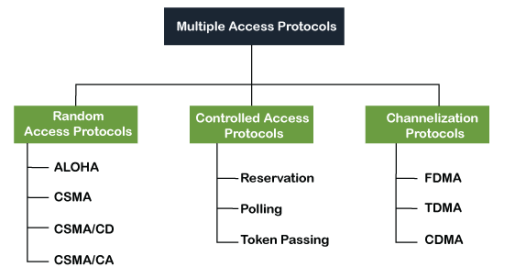

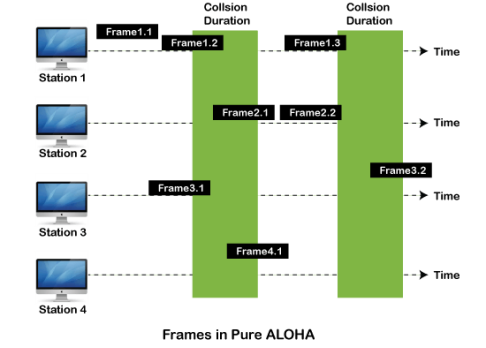
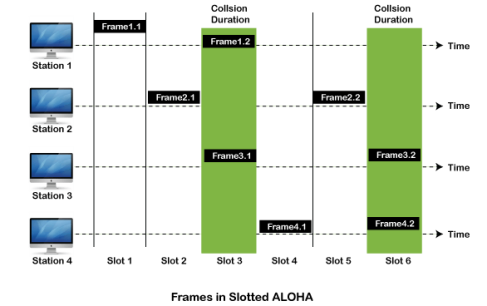
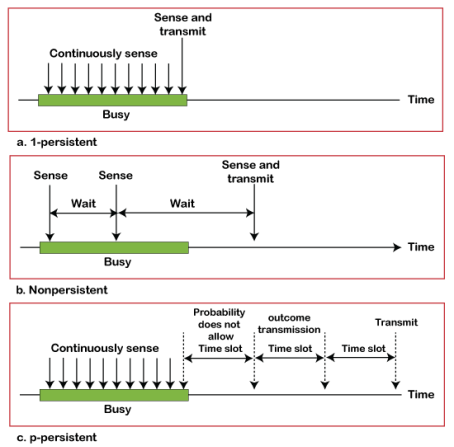
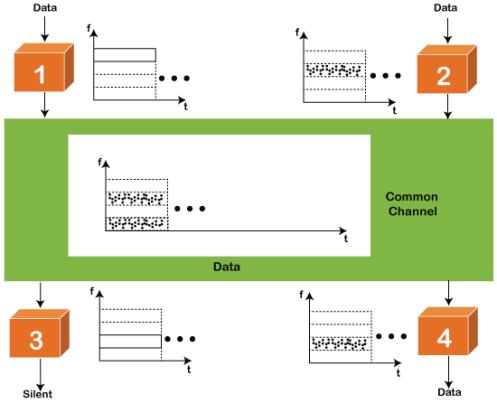
Key takeaways
- When a sender and receiver have a dedicated link to transmit data packets, the data link control is enough to handle the channel. Suppose there is no dedicated path to communicate or transfer the data between two devices. In that case, multiple stations access the channel and simultaneously transmits the data over the channel. It may create collision and cross talk. Hence, the multiple access protocol is required to reduce the collision and avoid crosstalk between the channels.
- For example, suppose that there is a classroom full of students. When a teacher asks a question, all the students (small channels) in the class start answering the question at the same time (transferring the data simultaneously). All the students respond at the same time due to which data is overlap or data lost. Therefore it is the responsibility of a teacher (multiple access protocol) to manage the students and make them one answer.
Referencs
1. Computer Networks, 8th Edition, Andrew S. Tanenbaum, Pearson New International Edition.
2. Internetworking with TCP/IP, Volume 1, 6th Edition Douglas Comer, Prentice Hall of India.
3. TCP/IP Illustrated, Volume 1, W. Richard Stevens, Addison-Wesley, United States of America.




