1.1.1 Origins of NLP
NLP is essentially the way humans communicate with a machine to allow them to perform the tasks required. This means that the earliest traces of NLP should be found right at the time where computers were starting to be developed. However, language processing is not only limited to a computer but can also be used for other machines as well. Around 1950 the Turing Machine became famous (Developed by Alan Turing to interpret the encrypted signals being sent by the Germans). Turing built a machine that could use logic and various other key aspects to understand the logic behind each message and crack the code. The first use of NLP was seen right there while communicating with the Turing Machine.
Right after this invention researchers started to use machine intelligence to perform several tasks that could make life a lot easier for people. To ensure that the machine performed the tasks that were given to the people needed to feed in appropriate data. The 1960’s seen a lot of work that was led by Chomsky and other renowned researchers who worked on this language to develop a universal syntax that could be used by people around the world to communicate with machines.
Development in this field was not rapid but there was a growing interest in developing this field further to automate a lot of manual activities. People had a learning curve that was very slow which only allowed people to have a keen interest in this field around the year 1990. The 90’s seen a surge of people developing models using artificial intelligence. TO do the same they relied heavily on language processing which seen a boost around the time.
All of this gave an incentive for people to use NLP along with machine learning and artificial intelligence to develop probabilistic models that relied heavily on data. To let the machine read and interpret data NLP became key right up to the present time. A lot of data relied on speech recognition which allowed people to transfer audio files and store them in the form of data on the internet. Due to the Internet Age language processing is used in almost any area around you. Social media platforms rely heavily on language processing which forms a major part of recent generations. In short, without NLP we would not have achieved all the technological advancements that we have in recent times.
1.1.2 Challenges of NLP
NLP is one of the major ways in which a person can communicate with machines to solve problems does come with a plethora of advantages. However, as advanced as the technology may be there are always a few challenges that lie ahead of the following which needs to be conquered to solve them. A little about each of the challenges are given below.
- Text Summarization
This is simply a challenge that lies ahead for readers who are working on extracting data and going through a lot of data in a short time. They would prefer to have a summary of the same. AI uses NLP to interpret and structure a summary by using all of the important points. However, there are a lot of points that do get missed out. This is one of the challenges that could solve a lot of problems that use data inspection.
2. Chatbot’s and Other AI Answer Machines
These are so frequently used by people while surfing a website to navigate the site appropriately to find the thing that they would be needing most. Replies do get easy based on questions that are asked frequently. However, when we use this on a much higher level with more complex reasonings, not every chatbot implemented with AI would be able to provide reliable answers. AI intends to allow everyone to use this feature to solve their daily problems.
Key Takeaways
- NLP has definitely made advancements in the world but still faces many challenges that could eventually limit the use of it.
Language models (LM’s) are used to estimate the likelihood of different words or phrases relative to other phrases or words to improve other NLP applications. Most of the models that are based on language modelling use probabilistic inferences to calculate the probability of the next word that the user might be intending to note down. It can also be used to find the probability of a certain word or phrase in data that is already existing.

P(w) = P(w1, w2, w3, w4, ………wn) = ∏ P(wi|w1,w2.w3……..wi-1)
where ‘n’ is the total number of occurrences in the given data and i is the instance that we need to find out the occurrence of.
1.2.1 Grammar Based Language Modelling
As the name rightly suggests this model is based on the grammatical inferences that have been given out to the machine to make an appropriate prediction based on the probabilistic inferences that the sentence has occurred in a similar event as before.
We can be sure that the language that we need the user to interpret a certain event is based on the past happenings in terms of that data. Let us understand this model with the help of an example further.
E.g. Sentence: “This glass is transparent.”
P (“This glass is transparent.”) = P(wi)
To construct the above sentence or predict it we need to see all the possible combinations based on the rule that is given below.
- P(This ) = P(w1)
- P(glass | This ) = P(w2)
- P( is | This glass ) =P(w3)
- P(transparent | This glass is ) = P(w4)
If the model needs to calculate the probability of the above sentence it would have to follow the same formula as given above.
Therefore, P(w) = ∏ P(wi|w1,w2.w3……..wi-1)
This would give us the probability of the grammatically correct statement which would then be predicted and shown to the user. Based on this one could build a sentence or phrase completion model using NLP.
1.2.2 Statistical Based Language Modelling
As the name suggests this model is based on statistical inferences made from data that has been entered into the machine that is supposed to make the final inferences. This language model relies heavily on data and the input in a correct and appropriate form.
The probability distribution is given over required word sequences which are then used over the textual data to gain inferences based on the values given to them.
E.g. 1) -p(“Today is Monday”) = 0.001
2) -p(“Today Monday is”) = 0.00000001
Approximate values are given to the model to work on making inferences.
This model is also known to have a probabilistic mechanism that is used to generate text and is also known as a ‘generative model’. All of the values are sampled from the data that has been entered to gain appropriate context about the happenings that surround the entire probability distribution. Statistical LM also happens to be context-dependent. This simply means that the way a certain data is entered and interpreted also affects the outcome of the probabilistic outcome.
This model is extremely useful to quantify uncertainties that might be lurking around in the data that has been entered in the form of speech or simply computer language. This can be seen clearly in the example below.
E.g. 1) John feels _________. (happy, habit)
This is an example where the language model needs to predict the next word that the person is going to say or type to save time. 99 percent of the people would agree that “happy” would be the correct option. However, the language model does not have the same process of thinking as a normal English-speaking human has. LM’s simply use the probability density of the word in the option to predict the next word.
Hence the final answer would be “John feels happy.”
Key Takeaways
- Grammar based modelling uses the smallest syllable in order to construct the sentence.
Regular Expression is a language that has been developed to help the user specify a search string to be found in the data. The pattern needs to be specified to get the desired results.
E.g. If a person wishes to find 10 numbers from the data but does not know the exact numbers, he/she could simply specify the pattern that those numbers are following to find them.
We can divide the following regular expression into 2 parts which is the corpus and the pattern.
Corpus: A Corpus is essentially a paragraph that is being specified under which an entire search will be executed. This has the entire bulk of data that can be used.
Pattern: This is the required pattern that can be entered in the search to obtain the required search results. Basic expressions that are used for the following are given below.
There are a few basic properties of a regular expression that need to be understood to use ‘RegEx’ (Regular Expression) efficiently.
- Brackets (“[ ]”)
Brackets are used to specify a certain disjunction of characters. For instance, the bracket being used on a regular ‘s’ or ‘S’ can be used to return a capital or lower case ‘S’.
E.g. /[sS]mall = Small or small (any of the above combinations)
/[a b c] = ‘a’, ‘b’ or ‘c’ (any of the letters in the bracket)
/[0,1,2,3,4,5] = any digit from the bracket
2. Dash (“-”)
Dash is a regular expression that can specify the range for a particular search. If we put a dash between two letters it would match all the letters between them.
E.g. /[A-Z] = All upper-case letters between A and Z would match the search.
/[a-z] = All lower-case letters between a and z would match the search.
3. Caret (“^”)
As normal syntax, this sign is also used to indicate a negation in the search that is conducted using this regular expression. It could also simply be used as a ‘caret’ symbol.
E.g. /[^A-Z]mall = Not any upper-case would be selected
/[^Dd] = This would indicate the search is for neither ‘d’ nor ‘D’
/[e^] = Used as a simple caret simple as there is nothing to negate after ‘e’
4. Question Mark (“?”)
The question mark symbol is essentially used to display the optionality for the search that has been conducted in the previous search. Putting a “?” before a certain letter would indicate that the user would like to return the search with an option consisting of that letter and one without that letter.
E.g. /[malls?] = This would return either “mall” or “malls”
/[colou?r] = This would return either “color” or “colour”
5. Period(“*”)
The asterisk symbol “*” is used to match a certain character that is between an expression in the search. If the user has an expression that would make sense after entering another letter this period mark is very useful.
E.g. /[beg*n] = Will give out any word that makes sense like ‘begin’
6. Anchors
Anchors can be used to match a certain assertion in the text that has been searched.
E.g. Consider “^” and “$” as specified anchors. Then
- ^The = Matches a string that starts with ‘The’
- bye$ = Matches a string that ends with ‘bye’
7. Character Classes
- “\d”: Matches a single character which is a digit.
- “\w”: Matches a word character. This could be alphanumeric as well as with an underscore.
- “\s”: Matches a whitespace character. This includes line breaks as well as tabs.
- “.”: Matches any character.
Key Takeaways
- Regular Expression is a language that has been developed to mainly match different patterns in the data.
Finite State Automata is an abstract computing device that is designed to be a mathematical model of a system. This system has discrete inputs, outputs, transition sets, and different states that occur on input symbols. This can be represented in 3 forms namely:
- Graphical forms (Transition Diagram)
- Tabular forms (Transition Table)
- Mathematical forms (Mapping functions or Transition functions)
A finite Automata is made up of 5 tuples which are given in a set as:

M = { Q, ∑, ∂, q0, F }
- Q: It is a finite set known as states
- ∑: It is a finite set known as alphabets
- ∂: ( Q x ∑ ) This is a transition function
- qo: This is a state that is called the initial state and is part of Q
- F: This set is also known as the final state and is also a part of Q
|
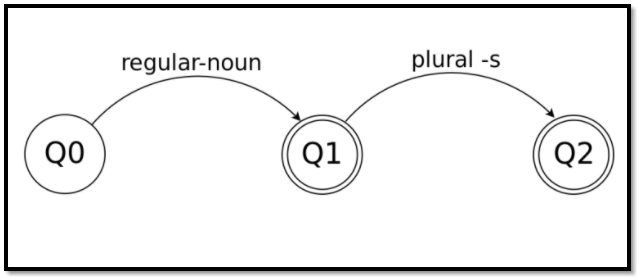
Fig. Description 1: These are 3 steps of the formation in the process of FSA
Key Takeaways
FSA can be represented in 3 forms namely:
- Graphical forms (Transition Diagram)
- Tabular forms (Transition Table)
- Mathematical forms (Mapping functions or Transition functions)
English Morphology is essentially the process of structuring the entire language to form new words from other base words that can be used further in the field of NLP. This type of morphology is also known as ‘derivational morphology’. We can achieve the following in so many different ways as follows:
We can use the stem (root word) to pair with different suffixes and affixes to make a new word that may have relevance based on our language processing. A derived word from on that is pre-existing is known as morphology. The English language has a lot of words that were made through morphology. English derivation, however, is complex. The reasons are:
- Different meanings: A lot of words do have the same root word but differ when it comes to the true meaning of the word. For example. Let us take the word “conform”. A person can add 2 suffixes to form the words “conformity” and “conformation”. However, both of the above words have completely different meanings despite stemming from the same root word.
- Non-uniform Effects: The words that are formed may not always have lasting effects on other words that are formed in the same manner. Take for example the word summarizes, if one adds the verb form – “ation” it forms another word with very similar meaning. The English language is vast but does not form the same throughout the entire plethora of the language.
E.g.
Category | Root | Affix | Derived word | New category |
Noun | character | -ize | characterize | Verb |
Verb | give
| -er | giver | Noun |
Adjective | real | -ize | realize | Verb |
Noun | colour | -ful | colourful | Adjective |
Key Takeaways
- English Morphology is used by the system in order to structure the entire language and make some sense of it.
A finite-state transducer is essentially a representation of a set of string pairs that are used to analyse outputs to get a better understanding of the same. They could be any type of string pairs such as input and output pairs of the data.
E.g. An FST can represent {(run, Run + Verb + PL), (run, run + Noun + SG), (ran, run + Verb + Past) …..}
A transducer function can be used to map input from zero and all the other outputs as well. A regular relation is not termed as a function in the above expression.
E.g. An FST can represent – transduce(run) {(run, Run + Verb + PL, run + Noun + SG)}
Finite-state transducers essentially have 2 tapes which are known as input and output. The pairs are made up of input and output variables. There is also a concept of transducer inversion that is important in switching pairs i.e. the input and the output labels. The inversion of a transducer T(T^-1) simply works to switch the input and output labels. T would help map the input I to the output O whereas the T^-1 maps the exact opposite of the above.
T = {(a,a1),(a,a2),(b,b1),(c,c1)}
T-1 = {(a1,a), (a2,a), (b1,b), (c1,c)}
We could have 2 lexical tapes placed as an example
- Lexical Tape: Output alphabet ( ∂ )
(dog + noun + plural)
- Surface Tape: Input alphabet ( ∑ )
(dogs)
A finite-state transducer T = P(in) X P(out) defines a certain relation that is between 2 languages which are in the terms of input and output. FST has a few applications which are given below as follows.
- Recognizer
The transducer plays an important role in taking a pair of strings and deciding whether to accept them or reject them based on a certain amount of criteria.
2. Generator
The transducer can also give a pair of strings (viz. L(input) and L(output)) as output for a certain language that is required.
3. Translator
This process involves reading a string that has been placed as input by the user. The FST then uses “Morphological parsing” to translate the input in the form of morphemes.
4. Relater
FST’s are key in being used as a medium that can help relationships between different types of sets being used around.
Lexicon
Every word in a language is made up of existing words that have meaning. This would essentially be from a base word while adding an affix to the same. The result would be a word that is formed through morphology. Most of these are governed by rules which are also known as “Orthographic rules”. They form the main basis on which Morphological Parsing takes place. This is done through the process of morphological parsing which is used to form or break a complex structured form of representation into ‘morphemes. These morphemes are further used to make words that have meaning and sense.
A “Lexicon” is essentially a list of words that can be used as the stem and affixes that would suit them to form a new word. A lexicon should constitute the list of words that have the base to form a structure to be converted to different types of words.
Key Takeaways
- A “Lexicon” is essentially a list of words that can be used as the stem and affixes that would suit them to form a new word.
Before a user happens to proceed with processing the language, the input text in any form needs to undergo a process of normalization. This ensures that the text is easily distinguished and easy to work on before any process goes through. The first process that is part of the entire normalization process is also known as Tokenization or ‘segmentation’ of words.
Word tokenization can be achieved very easily with the help of a UNIX command line for a text that is solely in the form of the English language. The process of breaking a given string into smaller parts (tokens) is known as tokenization. Some of the basic commands that are used to proceed with the following are as follows.
- “tr”: This command is used to make systematic changes to the characters that are already part of the input.
- “sort”: This command as the name suggests can help to sort the lines which are part of the input in alphabetical order for better understanding and inference.
- “uniq”: This command is simply used to analyse the identical lines input and allow them to collapse based on changes and modifications made to the system.
A simple method that can be used to initialize the process of tokenization is to split it o whitespace. In the Python programming language, one should simply split this through the NLTK library with the command raw.split(). Using regular expression makes it impossible to match new characters in the space to the string. We need to match tabs and lines while using this process.
Problems with tokenization:
Tokenization may be a great way to analyse and break down complex language structures but may pan out to be a difficult task while executing. A single solution may not always serve the purpose as efficiently as one would expect.
- Deciding what should be grouped as a token and what should not, is key to enabling users to work easily with the help of tokenization.
- Having raw manually tokenized data to compare with data that has been given back as output from the tokenizer helps to inspect the flaws and finally choose an appropriate token in the process.
- Contractions serve as a major problem e.g. “couldn’t”. While analysing a sentence meaning this would not pose too much of a problem and hence should be broken down into 2 separate tokens potentially.
Key Takeaways
- Tokenization is generally done using finite automata or by using expressions.
While typing text into the computer it is a must that people are able to type the words in correctly. Most of the times there is appropriate entry of words in the form of a corpus. However, if at a certain point of time people do not understand the word being dictated out to them. This would cause them to have an incorrect spelling attached to them. The computer would now have to work on this right there in order to allow the corpus to be examined for analysis further. This is one of the main reasons why the detection of spelling errors is essential to any corpus.
In order to get an idea about what errors could occur we need to make a list of them. These are all the errors that could occur in a corpus.
- Ignoring grammar rules
- Semantically similar components
- Phonetically similar components
There are also different errors that are important to know while typing. The machine has to get a good idea of the following before letting any of the data into the sorting algorithm.
- Deletion – This means that a letter is missing from the string
- Insertion – This means that a certain letter or letters need to be added
- Substitution – This means that a certain letter or letter in the string needs to be replaced by another letter or letters in the string
- Transposition – This means that all the letters are present but in a different order. The letters in the string could be swapped between each other to get a meaningful word.
In order to detect the issue with the spelling there are 2 models that can be employed based on the corpus that is in question. They are:
- Direct Detection
After working with a lot of corrections the system is trained to make a list of all the words that have been corrected before. By running the corpus against the list could get rid of many words that are commonly misspelled. If the words check out they will be considered eligible.
- Language Model Detection
This model is a little different from the previous one because there are many words that could be considered wrong even when they are correct. This is why the user builds a model which is essentially made just for the purpose of correction. The model is well trained in order to get a good look at the different words that could be suggested as alternatives to the misspelled word.
Key Takeaways
- Some of the basic operators that are used in regular expressions are Brackets, Dash, Caret, Question mark, Concatenation symbols, Anchors, etc.
Just as the name rightly suggests this phenomenon is about the comparison between two different types of strings. NLP constitutes a major part of measuring the similarities between two or more phrases (strings). An example of this can be seen in everyday life. While typing a message on your mobile you notice a certain autocorrect feature. In short, if the user types the word ‘kangaroo’ instead of ‘kangaroo’ the system would intend to know what exactly did the user mean. This would mean that the user has made a mistake and meant a word that was similar to this one. Based on simple NLP the system deciphers ‘kangaroo’ to be the appropriate spelling and consciously makes the change to save the user time and effort.
At times the spelling is not the only thing that is different about the string. Many a time people have two strings that differ by only a single word. E.g.
- “ Andrew is a football player.”
- “Andrew is a good football player.”
On closer observation, we notice that both the sentences are very similar to each other and differ by only a single letter. This tells us that both these strings might be referent. Now that we have an idea about the similarities that can occur between two strings we can move on to the definition of “Edit Distance” or simply “Minimum Edit Distance.”
Edit Distance is the distance between two strings in terms of their similarities and differences. It also refers to the minimum number of operations that the user would have to execute to make two or more strings alike (transform S1 into S2). The operations could include deletion and addition of words as well as the substitution in certain cases to achieve the end string product.
We can look at the following example to understand the case between the 2 words ‘execution’ and ‘intention’.
|


The alignment between the 2 words is something that has been depicted in the above figure. We can notice that there are a lot of letters that bear resemblance to each other in a very similar position as the word we intend to transform it to. We notice that the transformation can be made with the help of 3 distinct operations viz. deletion, insertion, and substitution. This is a visual depiction of how knowledge of the minimum distance can help in-text transformation and editing.
We now have a clear idea about exactly is the minimum distance in NLP. However, to calculate the same, we need to get familiar with an algorithm known as the “Minimum Edit Distance Algorithm”. We need to find the shortest path that can get us to the intended word with simple processes as mentioned above.
Key Takeaways
- The minimum Edit distance refers to the least number of actions that it takes to convert string 1 into string 2. We can achieve this through the minimum edit distance algorithm.
N-Gram as a term simply means the simplest bit the forms a sentence. It is essentially the number of bits that form a given string while we are reading data that has to be processed. For example:
- New Delhi – (2-gram word)
- Phir Hera Pheri – (3-gram word)
- He stood up quickly – (4-gram word)
It is very obvious that we have heard the first two examples much more frequently than we may have heard the last example which is “He stood up quickly.” This is an example of an instance where the N-gram is not observed as much. We then notice that assigning a certain probability to the occurrence of the N-bits in the model to predict the next word in the string, we could benefit from it for 3 of the main following reasons:
- Many of the 2-bit N-grams could be clubbed together to form a single word and in turn for a single bit that could be easier to read.
2. Predictions could be made very easily by doing the same. Users would benefit because the next word in completing the statement would be one that has appeared more time because of the appropriate probability density that has been assigned to the same. E.g. If we have a sentence, “Please submit your ______.” It is most likely that the next word would more likely be ‘assignment’ rather than ‘house’.
3. Spellings are something that needs to be changed from time to time depending on the typing speed of the person. Having a feature like autocorrect could be based more on the occurrence of the word after a certain one. E.g. If we have a sentence, “drink mlik” due to some error while typing, the machine will correct it to ‘milk’ and in turn change the spelling. This is done because the word ‘milk’ has a higher chance of coming after the word ‘drink’.
Now that we understand the use of an N-gram model let us move forward and get an idea about the formal understanding of an N-gram model. An N-gram model is essentially used to predict the occurrences of the previous (N-1) words. To understand this better we have a few terms introduced which help us understand the type of model we are going to be working with. This helps us figure out our next word by handpicking the required data from each of them.
- Bi-Gram Model – This means that there are 2 words (N=2) and we need to go back to (N-1) = (2-1) = 1 word to predict the next word accurately.
- Tri-Gram Model – This means that there are 3 words (N=3) and we need to go back to (N-1) = (3-1) = 2 words to predict the next word accurately.
To see how the model works further we need to work with assigning a certain probabilistic density to each of the following words in a model. Depending on the sentence the user can choose the model which could be bigram, trigram, or even further for more complex strings. To illustrate we need a ‘corpus’ or a large set of small sentences. Let us look at a few small sentences to illustrate this property.
- He went to New Delhi.
- New Delhi has nice weather.
- It is raining in the new city.
Let us assume one of the models that have been mentioned above. What if we take a bigram model? Probability is the [number of times the previous word (N-1) appears before the word that we require to predict] / [Number of time the previous word appears before the required word in the entire set of lines]
Let us find out the probability that the word ‘Delhi’ comes after the word ‘New’. So for this, we need to take the number of times ‘New Delhi’ appears divided by the number of times ‘New’ appears in the 3 lines on top.
= (number of times ‘New Delhi’ appears) / (the number of times ‘New’ appears)
= 2 / 3
= 0.67
Bigram models work very well with all the different types of corpus’ that are available from the model. Bigram may work better than trigram models even for more complex strings. However, when we have a lot of data for testing it is much more feasible to work with 4-gram and 5-gram models. One needs to analyse the right and left sides of the sentence as well before making any adjustments and assumptions about the same. Now we will look at the different unsmoothed N-gram models and their evaluation.
Key Takeaways
- The N-gram model uses probability to make assumptions based on the corpus that is used to train the function.
When we have a model like the N-gram model we must know how effective the model is in practice as well as hypothetical cases. If the application of the program improves after time and spatial expansion it is certain that the performance is improving. If we want to analyse and go through the model, we need to conduct something which is known as ‘extrinsic evaluation’.
Extrinsic evaluation is a method that works from one end of the model that is the start to the other end which is the output. We can simply run the model twice with a slight tweak in the model to get a whole description of the analysis that is going to be conducted by the model. Once we get both of the tests done we can simply compare them. However, the worst part about having to do a test like this is the cost. Running an NLP system twice just for testing could cost a lot.
Due to the cost and other factors that would cause the previous evaluation to be accurate but not every effective in the long run a new method was decided. This one simply decided a certain metric that would be constant for all of the models. Once the model works it would simply compare similar statistics even without having a certain application of the model. Such an application and testing of the model is known as ‘Intrinsic evaluation’.
Now while using the above ‘Intrinsic evaluation’ we need to train the corpus that we have and hence we need something which is known as a ‘test set’. Just as a lot of other tests that are present in the world of statistics the N-gram model also relies heavily on testing the model with the help of a corpus. So, this allows us to have a ‘training set’ and a ‘test set’ with data that is unseen by the system. This allows the user to train the data with other features not prevalent in the current dataset but might appear in future datasets.
Once we train our model with the help of the sets that are given above we notice that our algorithm gets tuned up explicitly to the features that are present in these sets. This causes it to become redundant with respect to a new feature that could appear in datasets in the future. This is why people have come up with something which is known as the ‘development test set’ or a ‘devset’ to solve this problem. A general distribution by users who work with the data is 80% which foes for the training data, 10% which goes for the test data, and the remaining 10% which goes for the development set.
Key Takeaways
- We can train our N-gram model with the help of an algorithm for the same.
A lot of times while testing our model we might come in contact with words that might be unknown to us or those which simply have meaning but have occurred in the dataset only once. Due to their single presence, the algorithm might assign them with simply a zero probability. If this happens it might cause our result set to be null and void due to the negligible importance given to those words. The process that allows us to assign some mass to the events is known as smoothing or discounting. There are a few ways to do this smoothing which are given below.
Laplace Smoothing
Before we complete the normalization of the probability densities, we can add the number 1 to every bigram count. We would notice that all the counts would be upped by a single value. E.g. 2 would be 1, 3 would be 4, etc. This is the simplest way of smoothing which may not be of great use in newer N-gram models but does a great job in getting one familiar with concepts that might be key in learning different types of smoothing.
Let us get an idea of this smoothing with the help of a unigram model
Where, w = word count
c = normalized count
N = number of words/tokens (after tokenization)
 Therefore, P(w) = c / N
Therefore, P(w) = c / N
Now as explained above, the process of Laplace smoothing allows each word count to be increased by the value 1. After making this increment, we need to also notice that an adjustment has to be made to the denominator to make up for the W words in the observation list.
w = word count
c = normalized count
N = number of words/tokens (after tokenization)
W = words in observation (left out)

Therefore, P(Laplace)(w) = c +1 / N +W
Key Takeaways
- P(Laplace)(w) = c +1 / N +W this is the formula for Laplace Smoothing.
We learned a lot about the smoothing that takes place to get rid of the problem that involves not assigning any probability to new words. However, different problems need to be taken care of which are shown below. Some of the problems that are solved by involving a trigram can be solved instead by using bigram. We can also solve a few bigram models by using unigram models.
We can use lesser context as a good example that allows the user to generalize the model. There are 2 different types of ways that we can use the following
1.13.1 Interpolation (Jelinek-Mercer Smoothing)
Interpolation which is also a type of smoothing is used in place of back off at times. The process of interpolation involves mixing the estimates of the probability of all the n-gram estimators available. This is done by consciously weighing all the word counts in the 3-gram, 2-gram, and unigram models.
When we look at simple interpolation there is a combination of different n-gram orders as mentioned above in the model. The mixing of all the models gives us a fair idea of all the probabilities with their weights assigned to them as P(wn|wn−2.wn−1). If λ is given as the weight coefficient then we get the following expression.

Pˆ(wn|wn−2wn−1) = λ1P(wn|wn−2wn−1) + λ2P(wn|wn−1) + λ3P(wn)
There is also a little more complex version of the same in which the λ is given as per the context in which it is issued. We have a little assumption made here that the word counts for the trigram model would be more accurate as compared to the bigram and unigram models. Hence, we get a new modified equation as shown below.
|
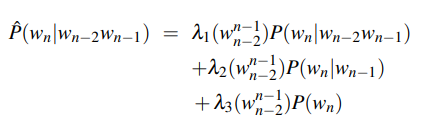
1.13.2 Back off (Katz Smoothing)
- Back off is the process where the user uses a trigram to provide a source of evidence to the NLP algorithm. If this does not train appropriately the user can switch to a bigram model as well as a unigram model thereafter. In short, the user “backs off” from using a higher gram model if there is 0 or no evidence of the same during discounting. This allows lower n-gram models to come into the big picture.
- In the algorithm, if we notice that the word count of the desired word in the corpus has zero counts, we allow the model to be reduced to one that has (N-1) grams. This process is simply continued until the model has enough evidence to be used as an appropriate model. Higher ordered grams save some probability density to get an appropriate discount for the same.
- We notice that the probability that is going to be added to the total discounted word counts in the string must have an assigned number that is greater than 1!. Katz back off is a type of back off that relies on the discounting that happens throughout a probability P*(P-star). We would also need a function α(alpha) to allow a fair distribution of the probability density throughout. This algorithm is mainly used with the Good Turing Algorithm that is used for smoothing. Collectively this is known as the Good-Turing back off method for providing an insight into the zero-gram word counts present in the corpus.
- The P(BO) which is the probability of the back off is given as:
|
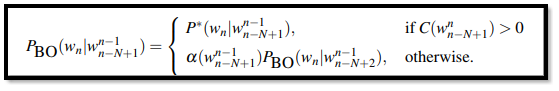
Comparison between back off and interpolation
- Both the models (interpolation and back off) deal with involving higher and lower gram models to compute the final result during smoothing.
2. In the case of having a certain non-zero word count the process of interpolation uses the data which is given by lower n-gram models.
3. In the case of having a certain non-zero word count the process of back off does not use the data which is given by lower n-gram models.
4. One can create an interpolated version of a back off algorithm and the same goes with creating a back off version of the interpolated algorithm.
1.13.3 Word Classes
When we look at the topic of word classes, we find a very simple understanding of the same in the English language. Having a good knowledge of the different word classes could help us understand the morphology and other lexical analysis’ happening in language processing. We can start with the simple examples of word classes which are given below and then move forward.
- Basic Word Classes
- Noun – N
- Verb – V
- Adjective – A
- Adverb – a
2. Closed Classes
- Determiners – the, an, a
- Pronouns – he, she, it, they, etc.
- Prepositions - over, from, with, under, around, etc.
1.13.4 Part of Speech (POS) Tagging
When we talk about the different word classes above, we get a clear idea about the English language that we are dealing with here. Below is a table that is made up of the tags given to the different parts of speech along with examples of the same to get you familiar with the following. In POS, each word class is tagged and then used as a token during the analysis process.
WORD CLASS | TAG | EXAMPLE |
Singular Noun | NN | House, school |
Plural Noun | NNS | Boys, girls |
Singular Proper Noun | NNP | APPLE, OPPO |
Plural Proper Noun | NNPS | Anands, Geetas |
Base Verb | VB | Work, play |
Verb past tense | VBD | Worked, played |
Verb Gerund
| VBG | Working, Playing |
Verb Past Participle | VBN | Driven |
Adjective | JJ | Beautiful, long |
Comparative Adjective | JJR | Bigger, Longer |
Superlative Adjective | JJS | Deadliest |
Adverb | RB | Easily, beautifully |
Preposition | IN | Under, around, near |
Conjunction | CC | And, or, neither, nor |
Determiner | DT | The, a, an |
Foreign Word | FW | Mea Culpa |
Existential | EX | (is) there |
Personal pronoun | PRP | You, He |
Possessive pronoun | PRP$ | Yours, Theirs |
List / Item Marker | LS | 3,4, three, four |
Modal | MD | Must, might |
Cardinal Number | CD | Nine, ten |
Interjection | UH | Ouch!, Alas! |
Dollar Sign | $ | $ |
Pound Sign | # | # |
Left Quote | “ | ‘, “ |
Right Quote | ” | ’, ” |
Left Parentheses | ( | (, [, {, > |
Right Parentheses | ) | ), ], }, < |
Comma | , | , |
1.13.5 Rule-Based Tagging
This type of tagging happens to be one of the most formerly known methods of tagging with the help of POS. These simply use tags for word classes that are present in the lexicon or the corpus. Sometimes there could be more than one possible tag. To deal with this problem there are a set of rules that have been made to deal with this.
Rule-based tagging is a process that goes through 2 stages entirely. The first stage and the second stage are given below.
- Stage One - In this stage, the language processing uses the dictionary that has been included to give each word a specific POS which can be used in the tagging process later.
2. Stage Two – There is a list of rules which are used to finalize every word to select and assign them with a particular POS.
Rules for Rule-Based tagging
- The taggers that are used are all driven by knowledge.
- The rules involved in finalizing the POS are all made manually.
- Rules are used to code the information.
- There are a limited number of rules.
- Rule-Based tags are the only rules used for smoothing and NLP.
1.13.6 Stochastic Tagging
There is another model that is made to complete the process of tagging. This is known as the Stochastic POS tagging. We only need to identify which of the model could be classified as a stochastic model and used for the same. The name comes from the feature of the model using a lot of statistics to get the desired results.
Word Frequency Approach
In the word frequency approach, the taggers that are assigned classify the words mainly based on the probability of occurrence. If the tag has been assigned the most it will show up after the training set and be used in the main assigning process. A lot of tags have different approaches and this is one of the common ones that are used for the same
The N-Gram approach is one that is very similar to the same because of the different probability densities given to the model. As explained above it depends on the previous words assigned to the entire sequence.
Properties
- The following type of tagging is based on all the statistical inferences that have been made to tag words that are part of the corpus.
- A training set needs to be assigned to the model to get an idea of the instances that have occurred in the past.
- A probability would also be assigned to the words that may not appear in the training corpus.
- The training and testing corpus are different from each other.
- It simply uses the tags which appear most frequently during the training process using a training corpus set.
1.13.7 Transformation Based Tagging
This type of tagging is also known by the name of ‘Brill Tagging’. This form of tagging does not use any sort of probability or statistical inferences to make tags. Instead, there are a set of rules used by the algorithm to allow POS tags on the corpus. It essentially transforms the text into a different state through the intervention of pre-defined rules.
The model is heavily based on the previous two models to understand the rules laid down by the algorithm for the tagging process. There is a fixed protocol that is followed by this tagging process to get an idea of the tagging process.
- The solution to begin – The program works with solutions that are very familiar to it based on past problems that occurred which take place in cycles.
- The most appropriate solution chosen - The most useful solution would be automatically adopted.
- Application – The solution is then implemented into the solution of the problem.
Key Takeaways
- POS is a feature that helps tag the different tokens that have been formed after the process of tokenization.
Rules for Rule-Based tagging
- The taggers that are used are all driven by knowledge.
- The rules involved in finalizing the POS are all made manually.
- Rules are used to code the information.
- There are a limited number of rules.
- Rule-Based tags are the only rules used for smoothing and NLP.
1.14.1 Hidden Markov Model
A Hidden Markov Model (HMM) is a model that is a modified stochastic tagging model with the main process being underlined throughout the main process. The result is simply the same if not more accurate. However, the processes that get done cannot be seen. The results of each sequence throughout the process are the only part that can be seen and comprehended.
To understand this a little better, we need to understand the term Markov chain. This is simply a model that gives us inferences about the sequences from the different probability densities occurring throughout the corpus. To make a prediction the Markov chain relies heavily on the current position of the tag or word count in the string. The Hidden Markov Model allows the user to dwell around both visible events (input strings) as well as hidden events (POS tagging).
Let us take an example to understand better the HMM process for a certain example. Say we have to build an HMM of the problem where coins are tossed in a certain sequence. To get a better understanding we can break this down into the 2 processes and factors
- Visible Events
These are the events that we know are happening and can physically or virtually picture them. In this case, it is the tossing of coins. We are sure that coins are being tossed with an option of either showing ‘heads’ or ‘tails’ as the outcome.
2. Hidden Events
These are the factors that are completely hidden from the user. In this case, they could be the number of coins that are used in the problem or the order in which the coins are tossed up in case they are different or weighted. One could conclude so many different models to understand this process better. One of the forms of the model is given below.
|
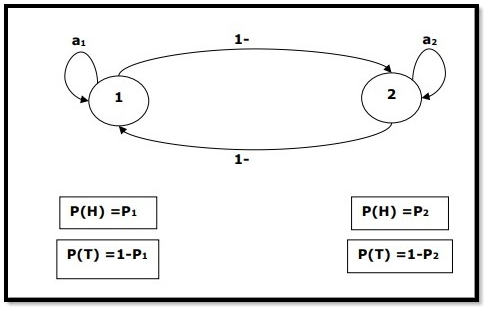
Fig. No. 2
Fig. Description 2: These are the hidden events during the transformation as shown in the diagram.
Tags in each of the following are sequences that generate tags for the outputs being given in the hidden states. These states have tags that could give an output that is observable to the user.
1.14.2 Maximum Entropy Markov Model (MEMM)
This model is used as an alternate form for the above Markov Model. In this model, the sequences which are taking place are replaced by a single function that we can define. This model can simply tell us about the happenings in the predicted state ‘s’ while knowing the past state ‘s’ as well as the current observation o. P (s | s’, o)
The main difference that we can get ourselves familiar with is the part where HMM’s are only dependent on the current state whereas the MEMM’s have their inferences which can be based on the current as well as the past states. This could involve a better form of accuracy while going through the entire tagging process. We can even see the difference in the diagram which is given below.
|
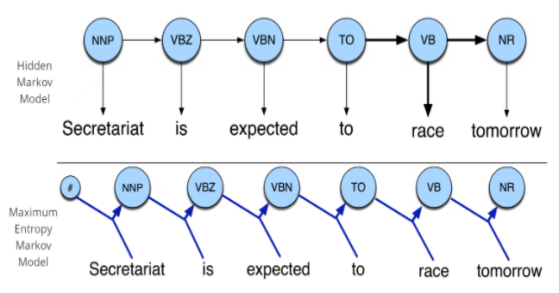
Fig. Description: Comparison between the Hidden Markov Model and the Maximum Entropy Markov Model
Disadvantages of MEMM’s
- MEMM models have a problem due to the label bias problem. Once the state has been selected, the observation which is going to succeed the current one will select all of the transitions that might be leaving the state.
2. There are a few examples in words such as “rib” and “rob” which when placed in the algorithm in their raw form have a little different path as compared to the other words. When we have “r_b” there is a path that goes through 0-1 and 0-4 to get the probability mass function. Both the paths would be equally likely not allowing the model to select one fixed word that could be predicted by the model correctly.
- HMM, and MEMM models are used to tag and have their pros and cons which can be decided based on the model that needs to be adapted.
Perplexity
One of the methods that are put to use to make sure that the evaluation of models is done correctly is the process of ‘perplexity’. We cannot use probabilities that are raw for a metric while evaluating languages. A variant in this is known as perplexity (PP). Perplexity of a certain NLP model on a set that is used for testing is normalized by the number of words and the probabilistic density assigned to it.
Let us say that for a set W = w1.w2.w3.w4……..wn
The following process is done by working on the probability expansion with the help of the chain rule. This is followed by the assumption that the model is a 2-gram ort a bigram model as given above. The result is perplexity which gives us a clear understanding while evaluating a model.
These are the different formulas as given below:
|
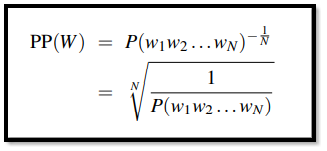
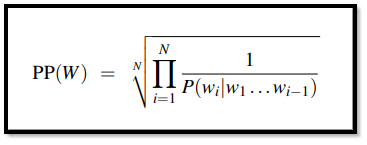
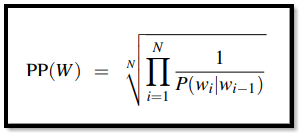
The final result that we can conclude is that because the probability is an inverse type of probability, the higher the conditional probability of W the lower if the perplexity (PP).
We could even try to understand the concept of perplexity with the help of a factor called the ‘weighted average branching factor’. This simply is a factor that tells the user about the number of words that may follow the given word. Let us take a simple example of the first 20 digits in the normal number system. Hence the set S = {1,2,3,4, ……..20}. The probability that any of the digits occurs is simply P = 1/20. However, if we consider the following as a language we notice something a little different about the measure of the perplexity. As mentioned before the perplexity is simply the inverse which is precisely why the answer would be inverted as shown below.
We know, Perplexity = PP(S) = P(s1.s2.s3…….sN) ^ (-1/N)
= { [ (1/20)^N ] ^ (-1/N) }
= ( 1/20 ) ^ -1
= 20
Key Takeaways
- A Hidden Markov Model (HMM) is a model that is a modified stochastic tagging model with the main process being underlined throughout the main process.
- They are based on 2 main factors viz. visible events and hidden events.
References
- Fundamentals of Speech Recognition by Lawrence Rabiner
- Speech and Language Processing by Daniel Jurafsky and James H. martin




