Unit - 4
Symbol Tables
The Symbol Table is an essential data structure generated and maintained by the compiler to keep track of variable semantics, i.e. to store information about the scope and binding information about names, information about instances of different entities, such as variable and function names, classes, objects, etc.
A table of symbols used for the following purposes:
● It is used to store the names of all individuals in one location in a standardized way.
● To check if a variable has been declared, it is used.
● It is used to evaluate a name's scope.
● It is used to enforce type checking by verifying the assignments and semantically correct expressions in the source code.
A table of symbols may either be linear or a table of hashes. Using the following format, the entry for each name is kept
<symbol name, type, attribute>
For reference, suppose that a variable stores information about the following declaration of a variable:
static int salary
Then, in the following format, it stores an entry:
<salary, int, static>
The attribute of the clause includes the name-related entries.
Symbol Table entries –
Every entry in the symbol table is associated with attributes that the compiler supports at various stages.
Items contained in Table Symbols:
❏ Variable names and constants
❏ Procedure and function names
❏ Literal constants and strings
❏ Compiler generated temporaries
❏ Labels in source languages
Details from the Symbol table used by the compiler:
● Data type and name
● Declaring procedures
● Offset in storage
● If structure or record then, a pointer to structure table.
● For parameters, whether parameter passing by value or by reference
● Number and type of arguments passed to function
● Base Address
Operations of Symbol table –
The basic operations listed on the table of symbols include:
Operation | Functions |
insert | To insert a name into a table of symbols and return a pointer to its input.
|
lookup | To check for a name and return its input to the pointer
|
free | Removal of all entries and free symbol table storage.
|
allocate | To assign a new empty table of symbols. |
Implementation :
If the compiler is used to handle a small amount of data, the symbol table can be implemented in the unordered list.
In one of the following methods, a symbol table can be implemented:
● Linear list
● List
● Hash table
● Binary search tree
Key takeaway :
- The symbol table is implemented primarily as a hash table.
- A significant data structure used in a compiler is the Symbol table.
- A table of symbols may either be linear or a table of hashes
Two symbol table forms are included in the compiler: the global symbol table and the scope symbol table.
Global symbol table that can be reached by all the tables of procedures and scope symbols that are generated in the software for each scope.
Both procedures and the scope symbol table can be accessed via the Global Symbol Table.
In the hierarchy structure, the scope of a name and symbol table is organized as shown below.
int value=10;
void sum_num()
{
int num_1;
int num_2;
{
int num_3;
int num_4;
}
int num_5;
{
int_num 6;
int_num 7;
}
}
Void sum_id
{
int id_1;
int id_2;
{
int id_3;
int id_4;
}
int num_5;
}
In a hierarchical data structure of symbol tables, the grammar above can be represented:
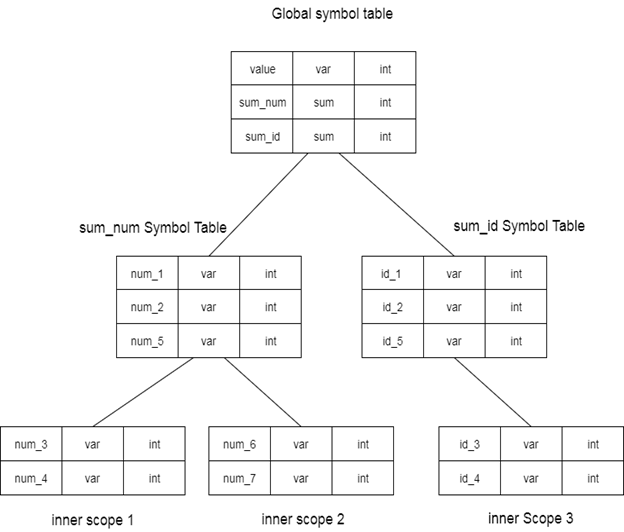
Fig 1: global symbol table
There are one global variable and two procedure names in the global symbol table. For sum id and its child tables, the name cited in the sum num table is not available.
The hierarchy of the symbol table's data structure is stored in the semantic analyzer. If you want to look for the name in the table of symbols, you can use the following algorithm to search for it:
● A symbol is first checked for in the current table of symbols.
● If the name is found, the search will be completed or the name will be checked in the parent symbol table until,
● Find a name or look for a global symbol.
Key takeaway :
- Both procedures and the scope symbol table can be accessed via the Global Symbol Table.
- Global symbol table that can be reached by all the tables of procedures
- scope symbols that are generated in the software for each scope.
Run - time environment
As a source code, a programme is merely a set of text (code, statements, etc.) and it needs actions to be performed on the target computer to make it alive. To execute instructions, a programme requires memory resources. A programme includes names for processes, identifiers, etc. that enable the actual memory position to be mapped at runtime.
By runtime, we mean the execution of a programme. The runtime environment is the state of the target machine that can provide services to the processes running in the system, including software libraries, environment variables, and so on.
A set, often created with the executable programme itself, is a runtime support system that enables the communication of the process between the process and the runtime environment. Memory allocation and deallocation are taken care of when the programme is being executed.
In the source software, every name has a validity area, called that name's scope.
The following are the rules in a block-structured language:
● If a name is declared within Block B, then only within B will it be valid.
● The name that is valid for block B2 is also valid for B1 if the B1 block is nested within B2 unless the name's identifier is re-declared in B1.
These scope rules require a more complicated symbol table organization than a list of names and attribute associations.
The tables are arranged into stacks, and each table includes a list of names and attributes associated with them.
● A new table is entered into the stack whenever a new block is entered.
● The name that is declared as local to this block is included in the new table.
● The table will look for a name when the declaration is compiled.
● If the name of the table is not identified, a new name is added.
Example :
int x;
void f(int m) {
float x, y;
{
int i, j;
int u, v;
}
}
int g (int n)
{
bool t;
}
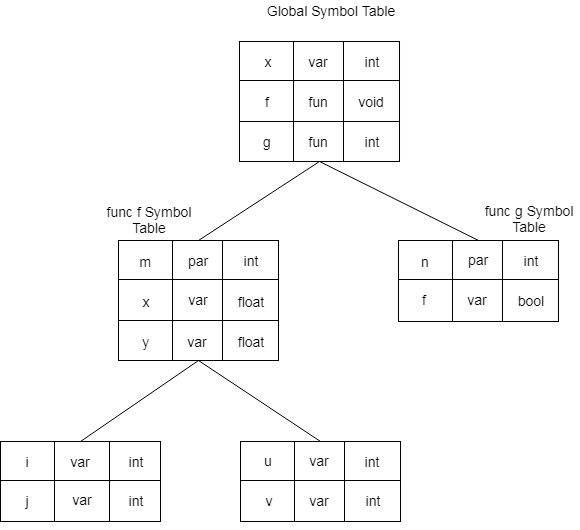
Fig 2: Symbol table organization compliant with the principles of static scope information
Key takeaway :
- Every name has a validity area, called that name's scope.
- The tables are arranged into stacks, and each table includes a list of names and attributes associated with them.
- Storage is organized as a stack.
The numerous ways that memory can be allocated are:
Static storage allocation :
➢ Names are attached to storage locations in static allocation.
➢ If the memory is created at the time of compilation, the memory is created in a static region and only once.
➢ The dynamic data structure is assisted by static allocation, meaning that memory is only generated at compile-time and redistributed after programme completion.
➢ The downside of static storage allocation is that it is important to know the size and position of data objects at compile time.
➢ The constraint of the recursion method is another downside.
Stack storage allocation :
➢ Space is structured as a stack of static storage allocation.
➢ When activation begins, an activation record is placed into the stack and it pops when the activation finishes.
➢ The activation record includes the locals of each activation record so that they are connected to fresh storage. When the activation stops, the value for locals is deleted.
➢ It operates based on last-in-first-out (LIFO) and the recursion mechanism is supported by this allocation.
Heap storage allocation :
➢ The most versatile allocation scheme is heap allocation.
➢ Depending on the requirement of the user, memory allocation and deallocation can be performed at any time and any venue.
➢ Heap allocation is used to dynamically assign memory to the variables and then regain it when the variables are no longer used.
➢ The recursion mechanism is assisted by heap capacity allocation.
Example :
fact (int n)
{
if (n<=1)
return 1;
else
return (n * fact(n-1));
}
fact (6)
dynamic allocation is given below:
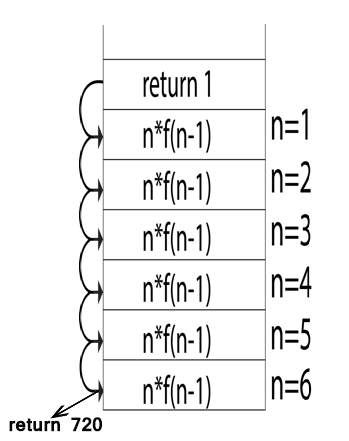
Fig 3: dynamic allocation
Key takeaway :
- If the memory is created at the time of compilation, the memory is created in a static region and only once, in static storage allocation.
- Space is structured as a stack of static storage allocation.
- The most versatile allocation scheme is heap allocation.
All potential errors made by the user are identified at this compilation stage and recorded to the user in the form of error messages. This method of finding errors and disclosing them to the user is called the process of Error Handling.
Functions of the Error handler
● Detection
● Reporting
● Recovery
Classification of Errors
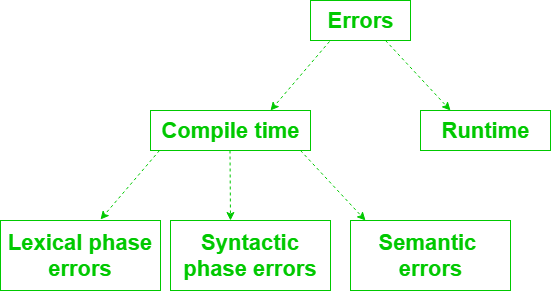
Fig 4: classification of error
Time errors in the compilation are of three kinds :
4.5.1 Lexical phase error
This type of error can be identified during the lexical analysis stage.
The lexical error is a character sequence that does not fit any token's pattern. During programme execution, a lexical step error is observed.
The lexical phase error is:
● Spelling error.
● Exceeding the length of an identifier or numeric constants.
● The appearance of illegal characters.
● To remove the character that should be present.
● To replace a character with an incorrect character.
● Transposition of two characters.
Example :
Void main()
{
int a=10, b=20;
char * x;
x= &a;
a= 1axy;
}
1axy is neither a number nor an identifier in this code. So the lexical error will be shown by this code.
Error recovery:
Panic Mode Recovery
➔ In this process, until a specified set of synchronizing tokens is identified, successive characters from the input are extracted one at a time. Tokens for synchronization are delimiters such as; or }
➔ The advantage is that it is quick to execute and means that there is no infinite loop.
➔ The disadvantage is that a large amount of input is missed without additional errors being tested.
Key takeaway :
- During the lexical analysis process, these errors are found.
- The lexical error is a character sequence that does not fit any token's pattern.
4.5.2 Syntactic phase error
This type of error occurs during the syntax analysis process. A syntax error is observed during programme execution.
There may be some syntax errors:
● Errors in structure
● Missing operator
● Misspelled keywords
● Unbalanced parenthesis
A syntax error can also occur when an incorrect formula is entered into a calculator. This can be activated by entering a number of decimal points or by opening brackets without closing them.
Example: Missing semicolon
int a = 5 // semicolon is missing
Compiler message:
ab.java:20: ';' expected
int a = 5
Error recovery:
❏ In this process, one at a time, successive characters are deleted from the input until a specified collection of synchronizing tokens is found. Tokens for synchronization are deli-meters such as; or }
❏ The advantage is that it is quick to implement and promises not to go to the infinite loop.
❏ The disadvantage is that, without testing for additional faults, a large amount of feedback is missed.
2. Statement Mode recovery
❏ In this process, when a parser detects an error, the remaining input is corrected to allow the parser to parse ahead of the rest of the input statement.
❏ You can remove extra semicolons, substitute a semicolon with a comma, or insert a missing semicolon for correction.
❏ When correcting, it is important to take the utmost care not to go in an endless loop.
❏ The drawback is that cases where the real error occurred before the detection point find it difficult to manage.
3. Error production
❏ If the consumer is aware of common errors that can then be found, these errors can be introduced by increasing the grammar by generating errors that produce erroneous constructs.
❏ If this is used, then suitable error messages can be produced during parsing and parsing can be continued.
❏ The drawback is that it's hard to hold.
4. Global Correction
❏ The parser analyses the entire programme and tries to figure out which error-free match is nearest to it.
❏ To recover from erroneous data, the closest match programme has fewer insertions, deletions, and token shifts.
❏ This technique is not practically applied due to elevated time and space complexity.
Key takeaway :
- A syntax error is observed during programme execution.
4.5.3 Semantic errors
This type of error occurs during the semantic analysis process. These error types are observed at the time of compilation.
Scope and declaration errors are often compiled time errors. E.g.: undeclared or multiple identifiers declared. Another compile-time error is Form Mismatched.
Using the wrong variable or using the incorrect operator or doing an operation in the wrong order, the semantic error can occur.
Typical semantic errors are as follows:
● Incompatible type of operands
● Undeclared variables
● Not matching of actual arguments with the formal one
Example :
Use of a non-initialized variable:
int a;
void x (int s)
{
s=t;
}
t is undeclared in this code, which is why the semantic error is seen.
Error recovery
❏ If an 'Undeclared Identifier' error is found, a symbol table entry is made for the corresponding identifier to recover from this.
❏ If two operand data types are incompatible, then the compiler performs an automatic type conversion.
Key takeaway :
- These error types are observed at the time of compilation.
References:
1. V Raghvan, “ Principles of Compiler Design”, TMH
2. Kenneth Louden,” Compiler Construction”, Cengage Learning.




