Unit - 5
Concurrency Control Techniques
Concurrency Control in a Database Management System is a method of controlling multiple actions at the same time without their interfering. It ensures that Database transactions are completed in a timely and accurate manner to deliver accurate results without jeopardizing the database's data integrity.
When all users are doing is reading data, concurrent access is simple. There's no way they'll get in each other's way. Concurrency is an issue in any practical database because it will include a mix of READ and WRITE activities.
Concurrency control in DBMSs is used to resolve such conflicts, which are most common in multi-user systems. As a result, Concurrency Control is the most crucial component for a Database Management System's correct operation when two or more database transactions demand access to the same data at the same time.
Example
Assume that two customers visit electronic kiosks at the same time to purchase a movie ticket for the same film and show time.
However, there is just one seat left in that particular theatre for the movie screening. It's feasible that both moviegoers will buy a ticket if the DBMS doesn't provide concurrency control. However, the concurrency control approach prevents this from happening. Both moviegoers have access to the data stored in the cinema seating database. Concurrency control, on the other hand, only gives a ticket to the first buyer who completes the transaction process.
Key takeaway
- Concurrency Control is a management process for controlling the concurrent execution of database operations.
- However, we must first understand concurrent execution before we can understand concurrency control.
Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it. There are two types of locks.
Binary Locks - A data item's lock can be in one of two states: locked or unlocked.
Shared/exclusive - This sort of locking mechanism distinguishes the locks according to their intended usage. It is an exclusive lock when a lock is obtained on a data item in order to perform a write operation. Allowing many transactions to write to the same data item would cause the database to become incompatible. Because no data value is changed, read locks are shared.
There are four different types of lock procedures.
Simplistic Lock Protocol
Transactions can obtain a lock on every object before performing a 'write' operation using simple lock-based protocols. After performing the ‘write' procedure, transactions may unlock the data item.
Pre-claiming Lock Protocol
Pre-claiming protocols assess their activities and generate a list of data items for which locks are required. Before beginning an execution, the transaction requests all of the locks it will require from the system. If all of the locks are granted, the transaction runs and then releases all of the locks when it's finished. If none of the locks are granted, the transaction is aborted and the user must wait until all of the locks are granted.
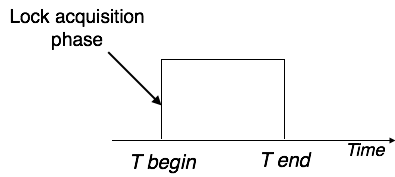
Fig 1: Pre claiming lock protocol
Two-Phase Locking 2PL
This locking protocol divides a transaction's execution phase into three segments. When the transaction first starts, it asks for permission to obtain the locks it requires. The transaction then obtains all of the locks in the second section. The third phase begins as soon as the transaction's first lock is released. The transaction can't demand any additional locks at this point; it can only release the ones it already possesses.
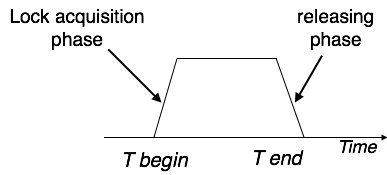
Fig 2: Two phase locking
Two-phase locking has two phases: one is growing, in which the transaction acquires all of the locks, and the other is shrinking, in which the transaction releases the locks it has gained.
A transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock in order to claim an exclusive (write) lock.
Strict Two-Phase Locking
Strict-2PL's initial phase is identical to 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase. However, unlike 2PL, Strict-2PL does not release a lock after it has been used. Strict-2PL keeps all locks until the commit point, then releases them all at once.
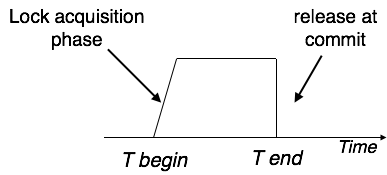
Fig 3: Strict two phase locking
Key takeaway
- Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it.
- Pre-claiming protocols assess their activities and generate a list of data items for which locks are required.
- This locking protocol divides a transaction's execution phase into three segments.
- Strict-2PL's initial phase is identical to 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase.
The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
At the moment of execution, lock-based protocols regulate the order between conflicting pairings among transactions, whereas timestamp-based protocols begin working as soon as a transaction is initiated.
Every transaction has a timestamp, and the order of the transactions is controlled by the transaction's age. All subsequent transactions would be older than a transaction started at 0002 clock time. For example, any transaction 'y' entering the system at 0004 is two seconds younger than the older one, and the older one will be prioritized.
In addition, the most recent read and write timestamps are assigned to each data item. This tells the system when the last ‘read and write' operation on the data item was done.
Timestamp ordering protocol
The Timestamp Ordering Protocol is used to place transactions in chronological order based on their timestamps. The transaction order is just the ascending sequence of transaction creation.
Because the older transaction has a greater priority, it runs first. This protocol employs system time or a logical counter to determine the transaction's timestamp.
At execution time, the lock-based protocol is utilized to govern the order between conflicting pairs of transactions. However, protocols based on timestamps begin working as soon as a transaction is created.
Assume T1 and T2 are two separate transactions. Assume that transaction T1 has been processed 007 times and transaction T2 has been processed 009 times. T1 has a higher priority, thus it runs first because it was the first to enter the system.
The timestamp ordering protocol also saves the timestamp of the most recent data 'read' and 'write' operations.
Timestamp ordering protocol works as follows −
● If a transaction Ti issues a read(X) operation −
○ If TS(Ti) < W-timestamp(X)
■ Operation rejected.
○ If TS(Ti) >= W-timestamp(X)
■ Operation executed.
○ All data-item timestamps updated.
● If a transaction Ti issues a write(X) operation −
○ If TS(Ti) < R-timestamp(X)
■ Operation rejected.
○ If TS(Ti) < W-timestamp(X)
■ Operation rejected and Ti rolled back.
○ Otherwise, operation executed.
Key takeaway
- The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
- The Timestamp Ordering Protocol is used to place transactions in chronological order based on their timestamps.
Optimistic concurrency control technique is another name for the validation phase. The transaction is carried out in three phases in the validation-based protocol:
Read phase -
The transaction T is read and executed in this step. It is used to read the value of various data elements and store them in local variables that are temporary. It is capable of performing all write operations on temporary variables without affecting the database.
Validation phase -
The temporary variable value will be checked against the actual data to see if it violates serializability in this phase.
Write phase -
If the transaction's validation is successful, the temporary results are saved to the database or system; otherwise, the transaction is rolled back.
The following are the different timestamps for each phase:
Start(Ti) - It contains the start time of Ti's execution.
Validation (Ti) - It specifies when Ti completes its read phase and begins its validation phase.
Finish (Ti) - It records the time Ti completes its write phase.
● This protocol is used to determine the transaction's time stamp for serialization by using the time stamp of the validation phase, as this is the phase that determines whether the transaction will commit or rollback.
● Hence TS(T) = validation(T).
● During the validation procedure, the serializability is determined. It's impossible to know ahead of time.
● It ensures a higher level of concurrency and fewer conflicts while processing the transaction.
● As a result, it contains transactions with fewer rollbacks.
Key takeaway
- Optimistic concurrency control technique is another name for the validation phase.
- The transaction is carried out in three phases in the validation-based protocol: read, validation and write phase.
It is defined as dividing the database into chunks that can be locked in a hierarchical manner.
Multiple Granularity improves concurrency while lowering lock overhead.
It keeps track of what needs to be locked and how it should be locked.
It makes it simple to choose whether to lock or unlock a data item. A tree can be used to graphically display this type of organization.
Example
Take a look at a tree with four tiers of nodes.
● The full database is displayed at the first level or higher level.
● A node of type area is represented at the second level. These are the areas that make up the higher-level database.
● The region is made up of files, which are child nodes. No file can exist in more than one location.
● Finally, each file contains records, which are child nodes. The file contains only the records that belong to its child nodes. There are no records in more than one file.
As a result, starting at the top, the tree's tiers are as follows:
● Database
● Area
● File
● Record
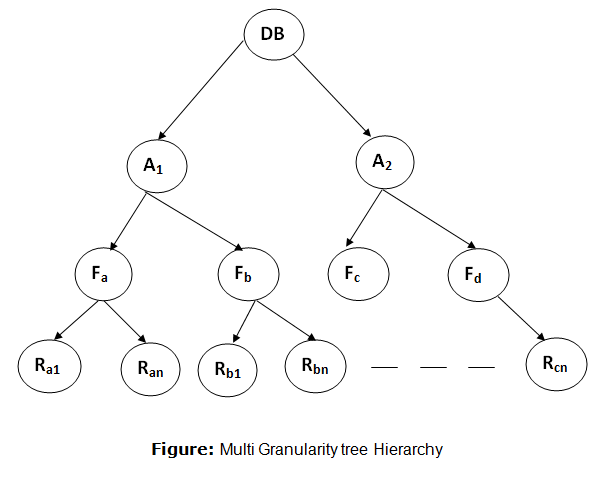
Fig 4: Multiple granularity hierarchy
The top level in this example displays the full database. File, record, and fields are the levels below.
There are three more lock modes with different levels of granularity:
Intention Mode Lock
Intention-shared (IS): At a lower level of the tree, it has explicit locking, but only with shared locks.
Intention-Exclusive (IX): It has explicit locking with exclusive or shared locks at a lower level.
Shared & Intention-Exclusive (SIX): The node is locked in shared mode in this lock, while another node is locked in exclusive mode by the same transaction.
Compatibility Matrix with Intention Lock Modes: The compatibility matrix for these lock modes is shown in the table below:
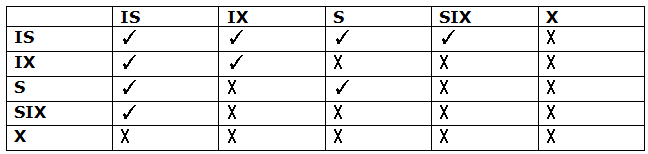
To assure serializability, it employs intention lock modes. It stipulates that if a transaction tries to lock a node, the node must adhere to the following protocols:
● The lock-compatibility matrix should be followed by transaction T1.
● T1 is the first transaction to lock the tree's root. It has the ability to lock it in any mode.
● If T1 currently has the parent of the node locked in either IX or IS mode, T1 will only lock the node in S or IS mode.
● T1 will lock a node in X, SIX, or IX mode only if the parent of the node is currently locked in IX or SIX mode.
● T1 can lock a node if T1 has not previously unlocked any nodes.
● Transaction T1 will unlock a node if none of the descendants of the node are currently locked.
The locks are obtained in top-down order in multiple-granularity, and they must be released in bottom-up order.
● If transaction T1 reads record Ra9 from file Fa, the database, region A1, and file Fa must be locked in IX mode. Finally, Ra2 must be locked in S mode.
● After locking the database, region A1, and file Fa in IX mode, transaction T2 can modify record Ra9 in file Fa. Finally, the Ra9 must be locked in X mode.
● If transaction T3 reads all of the records from file Fa, it must lock the database and put region A into IS mode. Finally, Fa must be locked in S mode.
● When transaction T4 reads the full database, the database must be locked in S mode.
Key takeaway
- It is defined as dividing the database into chunks that can be locked in a hierarchical manner.
- Multiple Granularity improves concurrency while lowering lock overhead.
- It makes it simple to choose whether to lock or unlock a data item. A tree can be used to graphically display this type of organization.
When a data item is modified, other protocols for concurrency control preserve the old values. Because many versions (values) of an object are kept, this is referred to as multiversion concurrency control. When a transaction requires access to an item, an appropriate version is selected to preserve the serializability of the currently running schedule, if at all possible.
The concept is that by reading an older version of the item, some read operations that would be refused by other techniques can still be allowed, preserving serializability. When a transaction publishes an item, it creates a new version while keeping the old version(s). Rather than conflict serializability, some multiversion concurrency control techniques use the idea of view serializability.
Multiversion approaches have the obvious disadvantage of requiring extra storage to keep several versions of database items. Older versions, on the other hand, may need to be kept for various reasons, such as recovery. Furthermore, some database systems necessitate the preservation of prior versions in order to keep a history of data item value evolution. A temporal database, on the other hand, keeps track of all changes and the times at which they occurred. Multiversion approaches have no additional storage penalty in such instances.
There have been several multiversion concurrency control techniques proposed. Here, we'll look at two schemes: one based on timestamp ordering and the other on 2PL. In addition, the concurrency control mechanism for validation keeps track of various versions.
Multiversion Technique Based on Timestamp Ordering
Each data item X is preserved in several versions X1, X2,..., Xk using this manner. The value of version Xi, as well as the following two timestamps, are preserved for each version:
Read_TS(Xi) - The read timestamp of X is the most recent of all the timestamps of transactions that have read version Xi successfully.
Write_TS(Xi) - The timestamp of the transaction that wrote the value of version Xi is the write timestamp of Xi.
When a transaction T is granted permission to do a write item(X) operation, a new version Xk+1 of item X is produced, with both the write TS(Xk+1) and read TS(Xk+1) set to TS (T). When a transaction T is permitted to read the value of version Xi, read TS(Xi) is set to the bigger of the current read TS(Xi) and TS values (T).
Multiversion 2 phase locking:
Each successful write creates a new version of the data item that was written. Versions are identified by timestamps. Select an appropriate version of X based on the transaction's timestamp when a read(X) operation is issued.
Key takeaway
- To boost concurrency, multiversion techniques keep outdated versions of data items.
- Multiversion approaches have the obvious disadvantage of requiring extra storage to keep several versions of database items.
When more than one transaction is being processed at the same time, the logs are interleaved. It would be tough for the recovery system to backtrack all logs and then start recovering during recovery.
Multiple transactions can be completed at the same time with concurrency control, resulting in interleaved logs. However, because transaction results may change, keep the order in which those operations are executed.
It would be quite difficult for the recovery system to backtrack all of the logs and then begin the recovery process.
Concurrent transaction recovery can be accomplished in one of four methods:
- Interaction with concurrency control
- Transaction rollback
- Checkpoints
- Restart recovery
Interaction with concurrency control
The recovery mechanism in this system is very dependent on the concurrency control scheme used. To undo the updates made by a failed transaction, we must rewind the transaction.
Transaction rollback
We use the log to revert a failed transaction in this scheme. After scanning the log backwards for a failed transaction, the system restores the data item for each log entry identified in the log.
Checkpoints
● Checkpoints are a way of keeping a snapshot of the state of an application so that it can be restarted from that point in the event of a failure.
● A checkpoint is a point in time when a record from the buffers is written to the database.
● The recuperation time is cut in half when you use a checkpoint.
● The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with each subsequent transaction step until the next checkpoint, and so on.
● The checkpoint specifies the moment in time when the DBMS was in a consistent state and all transactions had been committed.
The ‘Checkpoints' concept is employed by the majority of DBMS to alleviate this difficulty.
● Checkpoints were employed in this approach to limit the number of log records the system had to scan when it recovered from a crash.
● We demand that the checkpoint log record in a concurrent transaction processing system be of the form checkpoint L>, where ‘L' is a list of transactions active at the moment of the checkpoint.
● A fuzzy checkpoint is a checkpoint that allows transactions to make modifications while buffer blocks are being written out.
Restart recovery
● The system creates two lists when it recovers from a crash.
● The undo-list contains transactions that need to be undone, whereas the redo-list contains transactions that need to be redone.
● The following is how the system generates the two lists: They're both empty at first. The system examines each record in the log backwards until it reaches the initial <checkpoint> entry.
Key takeaway
- Multiple transactions can be completed at the same time with concurrency control, resulting in interleaved logs.
- It would be quite difficult for the recovery system to backtrack all of the logs and then begin the recovery process.
Oracle's adoption of internet technologies gained hold in the early years of the new millennium, even as the so-called "internet economy" slowed. Despite a drop in enterprise IT spending during this time, Oracle continued to innovate and achieve results. Major technical advances for Oracle highlighted the era, some of which were the product of millions of dollars and years of research and development and would set the company's future trajectory. Oracle Real Application Clusters, Oracle E-Business Suite, Oracle Grid Computing, enterprise Linux support, and Oracle Fusion are all part of Oracle's 30-year commitment to innovation and leadership.
Current performance
● The corporation has lowered costs and saved $ 1 billion in comparison to the previous year's budget.
● Due to decreased consulting services growth rates, revenues climbed by 15%, which was lower than previous years.
● Sales and marketing costs account for 26% of total operating costs.
● Expenses for research and development increased by 20%.
● As earnings per share climbed, the P/E ratio decreased.
● Liquidity is adequate.
● It is funded by equity rather than debt, which is more expensive.
● The return on investment has multiplied by 2.82.
Analysis of Strategic Factor
Strength
● Oracle is the world's number one integrated suite of enterprise applications, compatible with any operating system.
● Has become the gold standard for database technology and applications in businesses all around the world, from multinational organizations to the corner coffee shop.
● It had attracted legions of developers with its aggressive marketing initiatives.
● Its sales from subsidiaries and agents around the world account for over half of its total revenue.
● The amount of money made from online sales will skyrocket.
● In all respects, there is a high level of professionalism.
Weaknesses
● The cost of an Oracle varies per country.
● Liabilities must cover investments more than equity because it is less expensive.
● The CEO's eagerness in speaking to competitors could result in legal issues.
● Some staff may be demotivated by the CEO's harsh attitude toward them.
Opportunity
● Expand your market share by developing new products and services.
● The IT industry is booming all over the world.
● The enormous success of the E-business suite, as well as the company's strong financial position, will attract a large number of investors and venture capital funds.
Threats
“Microsoft will always be the biggest threat because of the great efforts it employs on R&D and dominating power in the market.”
Strategic Alternatives:
Concentric Diversification: Acquire companies in comparable industries to ensure market share and reduce competitive threats.
Recommended Strategy:
● Because of the fierce competition, growth strategy is the most effective short- and long-term approach.
● By incorporating new applications into the company's information system, the retrenchment strategy will be maintained and reinforced.
● Oracle's quality will be maintained by continuing to invest in research and development.
Implementation
● When the e-commerce suite is more widely used, employee costs will fall.
● When the e-commerce suite is more widely used, IT expenditures will fall.
● Because of its extensive experience and dedicated efforts, R&D will develop innovative goods and services.
Evaluation and Control
“Oracle is and owns the #1 integrated suite of enterprise applications for evaluation and control. It has applied it internally with great success and the result was high efficiency and effectiveness”
Key takeaway
- Oracle's adoption of internet technologies gained hold in the early years of the new millennium, even as the so-called "internet economy" slowed.
- Despite a drop in enterprise IT spending during this time, Oracle continued to innovate and achieve results.
References:
- RAMAKRISHNAN"Database Management Systems",McGraw Hill
- Leon & Leon,”Database Management Systems”, Vikas Publishing House
- Bipin C. Desai, “An Introduction to Database Systems”, Gagotia Publications
- Majumdar & Bhattacharya, “Database Management System”, TMH




