Unit-5
Software Maintenance and Software Project Management
Software evolution is a concept that refers to the process of creating software and then upgrading it on a regular basis for different purposes, such as adding new features or removing obsolete functionality. Change analysis, release preparation, system implementation, and system release to customers are all part of the evolution process.
The cost and effect of these changes was examined to determine how much of the system will be impacted by the reform and how much it will cost to enforce it. A new version of the software system is expected if the proposed improvements are approved. All potential changes are taken into account during release preparation.
The Importance of Software Evolution
Software evaluation is needed for the following reasons:
● Change in requirement with time: The organization's needs and modus operandi of working change significantly over time, so the tools (software) that they use must change to maximize output in this rapidly changing time.
● Environment change: When the working environment changes, the items (tools) that allow us to operate in that environment change proportionally. When the working environment changes, organisations must reintroduce old applications with revised features and functionality in order to adapt to the new environment.
● Errors and bugs: As the age of an organization's deployed software increases, its precision or impeccability decreases, and its ability to handle increasingly complex workloads continues to deteriorate.
● Security risks: Using obsolete software inside an enterprise will put you at risk of a variety of software-based cyberattacks, as well as reveal sensitive data that is inappropriately linked to the software in use. As a result, regular assessments of the security patches/modules used inside the program are needed to prevent such security breaches.
Key takeaway:
Software maintenance is becoming an important activity of a large number of software organizations. This is no surprise, given the rate of hardware obsolescence, the immortality of a software product per se, and the demand of the user community to see the existing software products run on newer platforms, run in newer environments, and/or with enhanced features. When the hardware platform is changed, and a software product performs some low-level functions, maintenance is necessary.
Also, whenever the support environment of a software product changes, the software product requires rework to cope up with the newer interface. For instance, a software product may need to be maintained when the operating system changes. Thus, every software product continues to evolve after its development through maintenance efforts.
It is necessary to perform software maintenance in order to:-
● Correct errors.
● The needs of the consumer evolve over time.
● Hardware and software specifications are changing.
● To increase the performance of the system.
● To make the code run more quickly.
● To make changes to the components
● To lessen any unfavorable side effects.
As a result, maintenance is needed to ensure that the system continues to meet the needs of its users.
There are basically three types of software maintenance. These are:
● Preventive: It's the method we use to save our system from being redundant. It entails the reengineering and reverse engineering concepts, in which an existing device of old technology is re-engineered with new technology. The machine will not die as a result of this maintenance.
● Corrective: Corrective maintenance of a software product is necessary to rectify the bugs observed while the system is in use.
● Adaptive: A software product might need maintenance when the customers need the product to run on new platforms, on new operating systems, or when they need the product to interface with new hardware or software.
● Perfective: A software product needs maintenance to support the new features that users want it to support, to change different functionalities of the system according to customer demands, or to enhance the performance of the system.
According to reports, the cost of maintenance is heavy. According to a report on calculating software maintenance costs, maintenance can account for up to 67 percent of the total cost of the software process period.
The cost of software maintenance accounts for more than half of the total cost of all SDLC phases. There are a number of factors that cause maintenance costs to rise, including:
Real-world factor affecting Maintenance Cost:
● Any software can be considered old if it has been around for 10 to 15 years.
● Older software’s, which were designed to run on slow computers with limited memory and storage, are unable to compete with newly released improved software on modern hardware.
● Maintaining old software becomes more expensive as technology progresses.
● Most repair engineers are inexperienced and rely on trial and error to solve problems.
● Frequently, adjustments can easily harm the software's original structure, making subsequent changes difficult.
● Changes are often left undocumented, which can lead to potential disputes.
Software-end factors affecting Maintenance Cost :
● Structure of Software Program
● Programming Language
● Dependence on external environment
● Staff reliability and availability
Key takeaway:
Software re-engineering is the process of updating software to keep it current in the market without affecting its functionality. It is a lengthy procedure in which the software design is altered and programs are rewritten.
Legacy apps can't keep up with the most up-to-date technologies on the market. When hardware becomes outdated, software updates become a headache. And if software becomes obsolete over time, the functionality remains unchanged.
Unix, for example, was created in assembly language at first. Unix was re-engineered in C when the language C was created because working in assembly language was difficult.
Aside from that, programmers can find that some parts of software need more maintenance than others, as well as re-engineering.
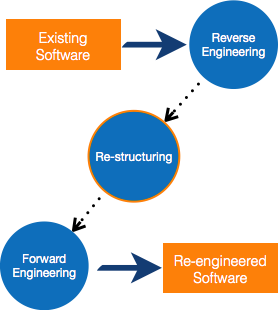
Fig 1: Re-engineering process
Process of Reengineering
● Determine what needs to be re-engineered. Is it the whole program or just a portion of it?
● Reverse engineering is a technique for obtaining requirements for current applications.
● If necessary, restructure the program. Changing function-oriented programs to object-oriented programs, for example.
● Reorganize data as needed.
● Fill out an application To get re-engineered applications, use forward engineering principles.
Key takeaway:
Software reverse engineering is the process of recovering the design and the requirements specification of a product from an analysis of its code. The purpose of reverse engineering is to facilitate maintenance work by improving the understandability of a system and to produce the necessary documents for a legacy system. Reverse engineering is becoming important, since legacy software products lack proper documentation, and are highly unstructured.
Even well designed products become legacy software as their structure degrades through a series of maintenance efforts. The first stage of reverse engineering usually focuses on carrying out cosmetic changes to the code to improve its readability, structure, and understandability, without changing its functionalities. A process model for reverse engineering has been shown in figure.
A program can be reformatted using any of the several available pretty printer programs which layout the program neatly. Many legacy software products with complex control structures and unthoughtful variable names are difficult to comprehend.
Assigning meaningful variable names is important because meaningful variable names are the most helpful thing in code documentation. All variables, data structures, and functions should be assigned meaningful names wherever possible. Complex nested conditionals in the program can be replaced by simpler conditional statements or whenever appropriate by case statements
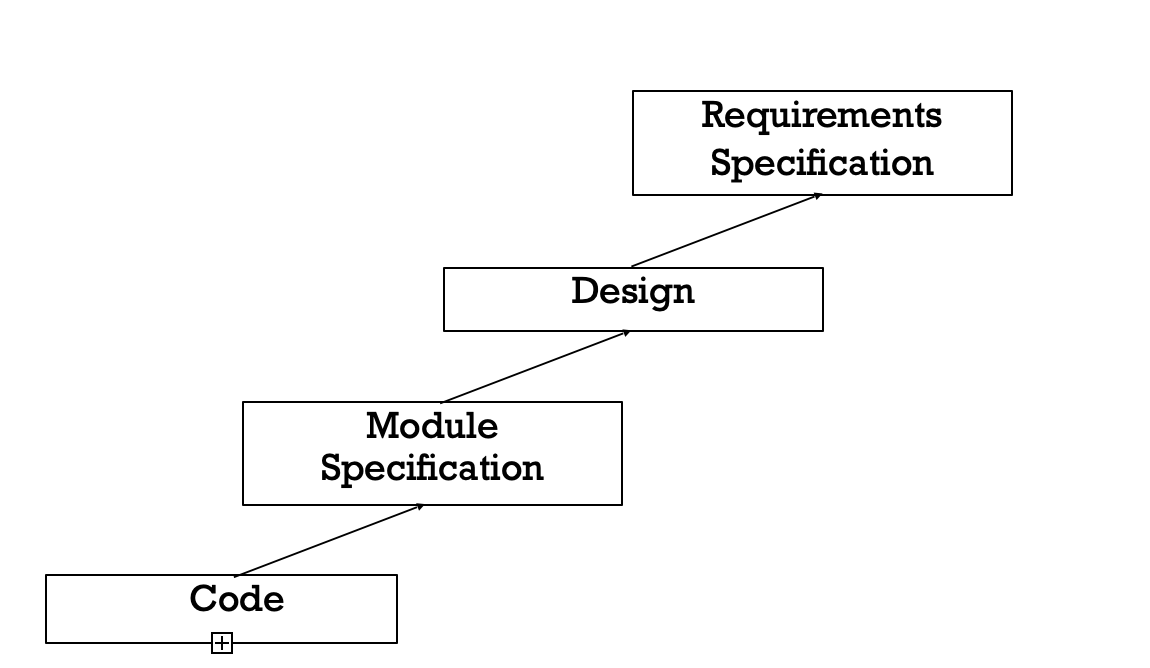
Fig 2: A process model for reverse engineering
After the cosmetic changes have been carried out on a legacy software the process of extracting the code, design, and the requirements specification can begin. In order to extract the design, a full understanding of the code is needed. Some automatic tools can be used to derive the data flow and control flow diagram from the code. The structure chart should also be extracted. The SRS document can be written once the full code has been thoroughly understood and the design extracted.
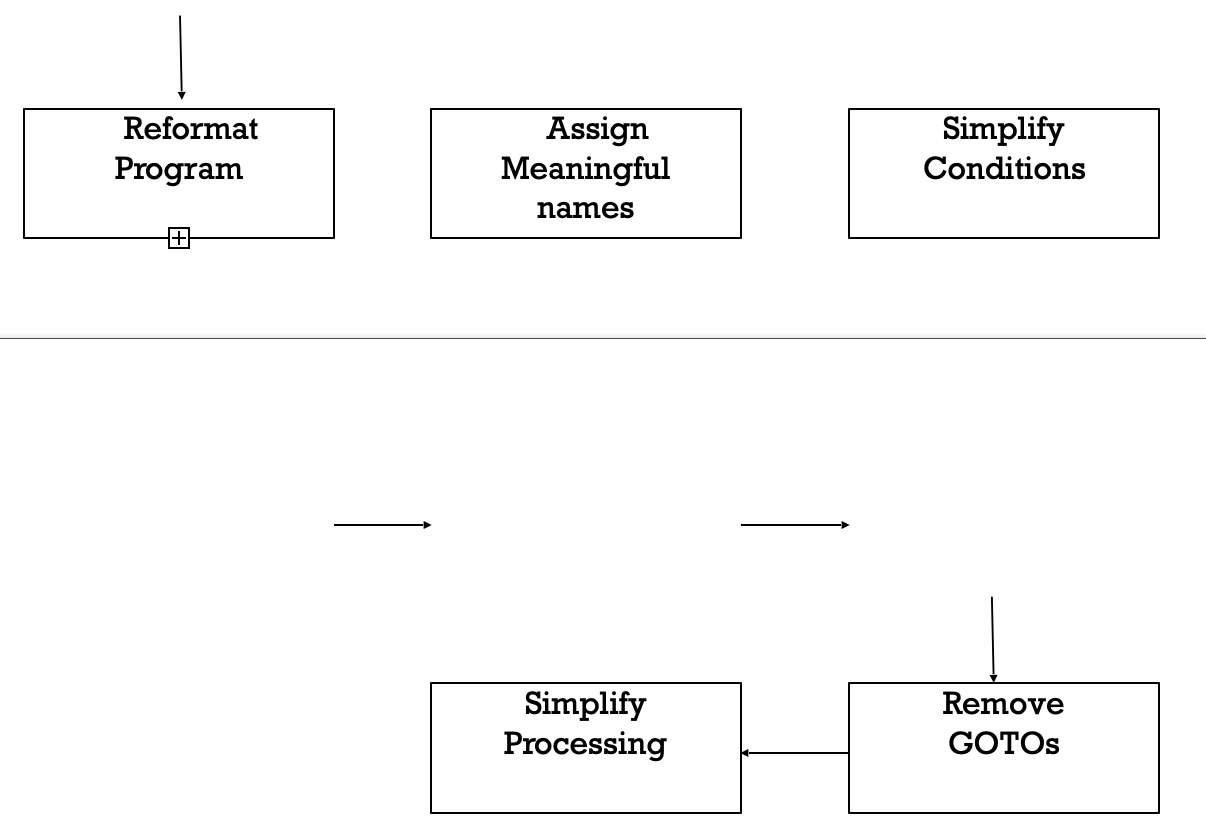
Fig 3: Cosmetic changes carried out before reverse engineering
Key takeaway:
Software configuration management (SCM) is an umbrella activity that is applied throughout the software process, because change can occur at any time.
SCM activities are developed to
● Identify change,
● Control change,
● Ensure that change is being properly implemented, and
● Report changes to others who may have an interest.
It is important to make a clear distinction between software support and software configuration management. Support is a set of software engineering activities that occur after software has been delivered to the customer and put into operation. Software configuration management is a set of tracking and control activities that begin when a software engineering project begins and terminate only when the software is taken out of operation.
A primary goal of software engineering is to improve the ease with which changes can be accommodated and reduce the amount of effort expended when changes must be made.
The output of the software process is information that may be divided into three broad categories:
● Computer programs (both source level and executable forms);
● Documents that describe the computer programs (targeted at both technical practitioners and users), and
● Data (contained within the program or external to it).
The items that comprise all information produced as part of the software process are collectively called a software configuration.
As the software process progresses, the number of software configuration items (SCIs) grows rapidly. A System Specification spawns a Software Project Plan and Software Requirements Specification (as well as hardware related documents). These in turn spawn other documents to create a hierarchy of information.
If each SCI simply spawned other SCIs, little confusion would result. Unfortunately, another variable enters the process—change. Change may occur at any time, for any reason. In fact, the First Law of System Engineering states: “No matter where you are in the system life cycle, the system will change, and the desire to change it will persist throughout the life cycle.”
There are four fundamental sources of change:
● New business or market conditions dictate changes in product requirements or business rules.
● New customers need modification of data produced by information systems, functionality delivered by products, or services delivered by a computer-based system.
● Reorganization or business growth/downsizing causes changes in project priorities or software engineering team structure.
● Budgetary or scheduling constraints cause a redefinition of the system or product.
Software configuration management is a set of activities that have been developed to manage change throughout the life cycle of computer software. SCM can be viewed as a software quality assurance activity that is applied throughout the software process.
In certain situations, more than one risk can be traced to the issues that arise during a project. The attempt to assign origin (what risk(s) caused the problems in the project) is another risk monitoring mission.
Key takeaway:
Controlling changes to Configuration items (CI).
In order to determine technical merit, possible side effects, overall impact on other configuration artefacts and device functions, and the estimated cost of the update, a change request (CR) is submitted and assessed.
The assessment results are viewed as a change report used by a change control board (CCB)-a individual or body that makes a final decision on the change's status and priority. For each approved change, an engineering change Request (ECR) is created.
In the event that the modification is refused for good reason, CCB often notifies the creator. The ECR outlines the improvements to be made, the constraints that need to be met, and the evaluation and audit criteria.
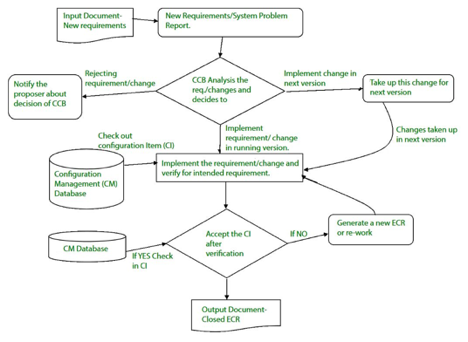
Fig 4: change control
The object to be altered is "checked out" from the database of the project, the alteration is made, and the object is reviewed again. The object is then 'checked in' to the database and the next version of the programme is generated using acceptable version control mechanisms.
Using the SCM framework to construct versions/specifications of an existing product to develop new products.
Suppose the configuration object's version moves from 1.0 to 1.1 after some changes. Minor corrections and adjustments occur in the 1.1.1 and 1.1.2 versions, which are followed by a significant update to 1.2.
Object 1.0's growth continues through 1.3 and 1.4, but a notable update to the object ultimately results in a new evolutionary direction, version 2.0.0. It currently supports both models.
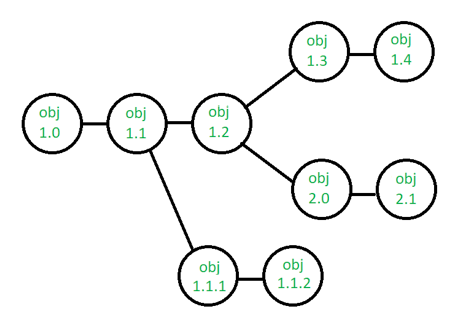
Fig 5: version control
CASE stands for Engineering with Computer Assisted Applications. This implies, with the assistance of various automated development tools, designing and managing software projects.
CASE instruments may assist engineers with the work of evaluating, designing, coding and checking. Software engineering is hard work and there are major benefits to instruments that minimize the effort needed to create a work product or achieve a milestone.
The main objectives of using CASE related tools are:
● To improve productivity
● To establish good quality software at a cheaper cost.
Components of CASE
Based on their use at a specific SDLC stage, CASE tools can be broadly divided into the following parts:
● Central Repository - A central repository is required for CASE tools and can serve as a source of common, integrated and consistent information. The central repository is a central storage location where product specifications, requirement records, related reports and diagrams are stored, as well as other valuable management material. The central repository also acts as a data dictionary.
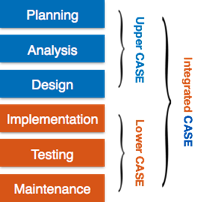
Fig 6: case tools
● Upper Case Tools - In the preparation, study and design phases of SDLC, the Upper-CASE instruments are used.
● Lower Case Tools - In deployment, monitoring and maintenance, Lower CASE tools are used.
● Integrated Case Tools - In all the phases of SDLC, from the selection of specifications to testing and documentation, integrated CASE resources are beneficial.
Key takeaways:
Software project managers begin project preparation once a project is determined to be feasible. Even before any construction work begins, project preparation is done and completed. The following activities are needed for project planning:
Estimating the project's following characteristics:
Project size: How complex will the problem be in terms of effort and time to produce the product?
Cost: How much is the project going to cost to develop?
Duration: How long is it going to take to complete development?
Effort: What level of effort is required?
The precision of these estimations determines the efficacy of subsequent preparation activities.
The Constructive Cost Model (COCOMO) is an empirical estimation model i.e., the model uses a theoretically derived formula to predict cost related factors. This model was created by “Barry Boehm”. The COCOMO model consists of three models:-
The Basic COCOMO model: - It computes the effort & related cost applied on the software development process as a function of program size expressed in terms of estimated lines of code (LOC or KLOC).
The Intermediate COCOMO model: - It computes the software development effort as a function of – a) Program size, and b) A set of cost drivers that includes subjective assessments of product, hardware, personnel, and project attributes.
The Advanced COCOMO model: - It incorporates all the characteristics of the intermediate version along with an assessment of the cost driver’s impact on each step of the software engineering process.
The COCOMO models are defined for three classes of software projects, stated as follows:-
Organic projects: - These are relatively small and simple software projects which require small team structure having good application experience. The project requirements are not rigid.
Semi-detached projects: - These are medium size projects with a mix of rigid and less than rigid requirements level.
Embedded projects: - These are large projects that have a very rigid requirements level. Here the hardware, software and operational constraints are of prime importance.
Basic COCOMO Model
The effort equation is as follows: -
E = a * (KLOC) b
D = c * (E) d
Where E effort applied per person per month, D = development time in consecutive months, KLOC estimated thousands of lines of code delivered for the project. The coefficients a, b, and the coefficients c, d are given in the Table below
Software Project | a | B | c | d |
Organic | 2.4 | 1.05 | 2.5 | 0.38 |
Semi Detached | 3.0 | 1.12 | 2.5 | 0.35 |
Embedded | 3.6 | 1.20 | 2.5 | 0.32 |
Intermediate COCOMO Model
The effort equation is as follows: -
E = a * (KLOC) b * EAF
Where E = efforts applied per person per month, KLOC = estimated thousands of lines of code delivered for the project, and the coefficients a and exponent b are given in the Table below. EAF is Effort Adjustment Factor whose typical ranges from 0.9 to 1.4 and the value of EAF can be determined by the tables published by “Barry Boehm '' for four major categories – product attributes, hardware attributes, personal attributes and project attributes.
Software Project | A | b |
Organic | 3.2 | 1.05 |
Semi Detached | 3.0 | 1.12 |
Embedded | 2.8 | 1.20 |
Key takeaway:
The Lawrence Putnam model estimates how much time and effort it would take to complete a software project of a given scale. To estimate project effort, schedule, and defect rate, Putnam uses a so-called The Norden / Rayleigh Curve, as shown in fig:
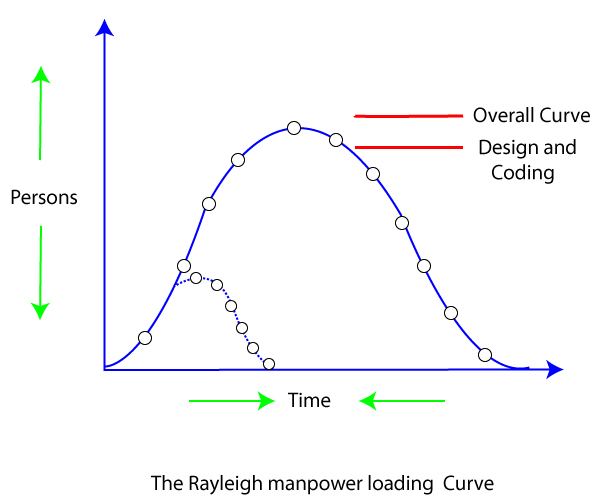
Fig 7: the Rayleigh manpower curve
Putnam found that the Rayleigh distribution was accompanied by software staffing profiles. Putnam derived the program equation from his observation of efficiency levels:
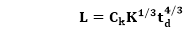
The various term of above equation:
● K- L is the product estimate in KLOC, and K is the cumulative effort spent (in PM) in product growth.
● td - The period of device and integration testing is described by td. As a result, td can be thought of as the time taken to manufacture the product.
● Ck - Is the state of technology constant and represents requirements that obstruct the program's development.
○ Typical values of Ck = 2 for poor development environment
Putnam suggested that the Rayleigh curve could be used to determine how much a project's staff develops. To carry out planning and specification tasks, only a small number of engineers are needed at the start of a project. The number of engineers required grows as the project progresses and more extensive work is required. The number of project employees decreases after implementation and unit testing.
Key takeaway:
Risk analysis and management are a series of steps that help a software team to understand and manage uncertainty. Many problems can plague a software project. A risk is a potential problem—it might happen, it might not.
Steps of Risk Analysis and Management:-
1. Recognizing what can go wrong is the first step, called “risk identification.”
2. Each risk is analyzed to determine the likelihood that it will occur and the damage that it will do if it does occur.
3. Risks are ranked, by probability and impact.
4. Finally, a plan is developed to manage those risks with high probability and high impact.
In short, the four steps are:
1. Risk identification
2. Risk Projection
3. Risk assessment
4. Risk management
Risk always involves two characteristics; a set of risk information sheets is produced.
1. Uncertainty—the risk may or may not happen; that is, there are no 100% probable risks.
2. Loss—if the risk becomes a reality, unwanted consequences or losses will occur.
Types of risks that are we likely to encounter as the software is built:
● Project risks threaten the project plan. That is, if project risks become real, it is likely that the project schedule will slip and that costs will increase. Project risks identify potential budgetary, schedule, personnel (staffing and organization), resource, customer, and requirements problems and their impact on a software project.
● Technical risks threaten the quality and timeliness of the software to be produced. If a technical risk becomes a reality, implementation may become difficult or impossible.
● Business risks threaten the viability of the software to be built. Business risks often jeopardize the project or the product. Candidates for the top five business risks are:
● Market risk,
● Strategic risk,
● Management risk, and
● Budget risks.
● Known risks are those that can be uncovered after careful evaluation of the project plan.
● Predictable risks are extrapolated from past project experience (e.g., staff turnover, poor communication with the customer, dilution of staff effort as ongoing maintenance requests are serviced).
● Unpredictable risks are the joker in the deck. They can and do occur, but they are extremely difficult to identify in advance.
Reactive risk strategies:-
● Reactive risk strategies follow that the risks have to be tackled at the time of their occurrence.
● No precautions are to be taken as per this strategy.
● They are meant for risks with relatively smaller impact.
Proactive risk strategies:-
● Proactive risk strategies follow that the risks have to be identified before the start of the project.
● They have to be analyzed by assessing their probability of occurrence, their impact after occurrence, and steps to be followed for its precaution.
● They are meant for risks with relatively higher impact.
Key takeaway:
References:
2. Kassem Saleh, “Software Engineering”, Cengage Learning.
3. P fleeger, Software Engineering, Macmillan Publication




