Unit - 4
Artificial Neural Networks
Deep learning is an artificial intelligence (AI) function that imitates the workings of the human brain in processing data and creating patterns for use in decision making. Deep learning is a subset of machine learning in artificial intelligence that has networks capable of learning unsupervised from data that is unstructured or unlabeled. Also known as deep neural learning or deep neural network.
Deep learning has evolved hand-in-hand with the digital era, which has brought about an explosion of data in all forms and from every region of the world. This data, known simply as big data, is drawn from sources like social media, internet search engines, e-commerce platforms, and online cinemas, among others. This enormous amount of data is readily accessible and can be shared through fintech applications like cloud computing.
However, the data, which normally is unstructured, is so vast that it could take decades for humans to comprehend it and extract relevant information. Companies realize the incredible potential that can result from unraveling this wealth of information and are increasingly adapting to AI systems for automated support.
Recurrent Neural Network remembers the past and its decisions are influenced by what it has learnt from the past. Basic feed forward networks remember things but they remember what they learnt during training. For example, an image classifier learns what a “1” looks like during training and then uses that knowledge to classify things in production.
While RNNs learn similarly while training they remember things learnt from prior inputs while generating output. It’s a part of the network. RNNs can take one or more input vectors and the outputs are influenced not just weights applied on inputs like a regular NN, but also hidden state vector representing the context based on prior input(s) / output(s). So, the input could produce a different output depending on the previous inputs in the series.
Convolutional neural networks are composed of multiple layers of artificial neurons. Artificial neurons, a rough imitation of their biological counterparts, are mathematical functions that calculate the weighted sum of multiple inputs and outputs an activation value.
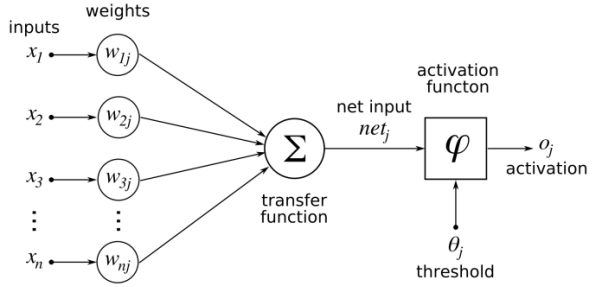
Figure 1. Convolutional Neural Networks
The behaviour of each neuron is defined by its weights. When fed with the pixel values, the artificial neurons of a CNN pick out various visual features.
When you input an image into a ConvNet, each of its layers generates several activation maps. Activation maps highlight the relevant features of the image. Each of the neurons takes a patch of pixels as input, multiplies their colour values by its weights, sums them up, and runs them through the activation function.
The first (or bottom) layer of the CNN usually detects basic features such as horizontal, vertical, and diagonal edges. The output of the first layer is fed as input of the next layer, which extracts more complex features, such as corners and combinations of edges. As you move deeper into the convolutional neural network, the layers start detecting higher-level features such as objects, faces, and more.
Mathematically speaking, any neural network architecture aims at finding any mathematical function y= f(x) that can map attributes(x) to output(y). The accuracy of this function i.e., mapping differs depending on the distribution of the dataset and the architecture of the network employed. The function f(x) can be arbitrarily complex. The Universal Approximation Theorem tells us that Neural Networks has a kind of universality i.e., no matter what f(x) is, there is a network that can approximately approach the result and do the job! This result holds for any number of inputs and outputs.
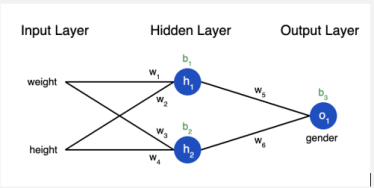
Figure 2. Approximation theorem
If we observe the neural network above, considering the input attributes provided as height and width, our job is to predict the gender of the person. If we exclude all the activation layers from the above network, we realize that h₁ is a linear function of both weight and height with parameters w₁, w₂, and the bias term b₁. Therefore mathematically,
h₁ = w₁*weight + w₂*height + b₁
Similarly,
h2 = w₃*weight + w₄*height + b₂
Going along these lines we realize that o1 is also a linear function of h₁ and h2, and therefore depends linearly on input attributes weight and height as well.
Generative adversarial networks (GANs) are an exciting recent innovation in machine learning. GANs are generative models: they create new data instances that resemble your training data. For example, GANs can create images that look like photographs of human faces, even though the faces don't belong to any real person. These images were created by a GAN:

Figure 3: Images generated by a GAN.
GANs achieve this level of realism by pairing a generator, which learns to produce the target output, with a discriminator, which learns to distinguish true data from the output of the generator. The generator tries to fool the discriminator, and the discriminator tries to keep from being fooled.
References:
1. Artificial Intelligence: A Modern Approach by Stuart Russell and Peter Norvig, Prentice Hall
2. Artificial Intelligence by Kevin Knight, Elaine Rich, Shivashankar B. Nair, Publisher: McGraw
Hill
3. Data Mining: Concepts and Techniques by Jiawei Han, Micheline Kamber, Jian Pei,
Publisher: Elsevier Science.
4. Speech & Language Processing by Dan Jurafsky, Publisher: Pearson Education
5. Neural Networks and Deep Learning A Textbook by Charu C. Aggarwal, Publisher: Springer
International Publishing
6. Introduction to Artificial Intelligence By Rajendra Akerkar, Publisher : PHI Learning




