UNIT 4
Computational Learning Theory
Computational learning theory also known as statistical learning theory is a mathematical framework for quantifying learning tasks and algorithms. It is one of the many sub-fields of machine learning.
“One can extend statistical learning theory by taking computational complexity of the learner into account. This field is called computational learning theory or COLT”
4.1.1 Sample Complexity for Finite Hypothesis spaces
sample complexity is growing in some required training examples with its defined problem size of a learning problem.
4.1.2 Sample Complexity for Infinite Hypothesis spaces
Motivation: classification is to distinguish subsets.
• A set of instances 𝑆 and a hypothesis space 𝐻.
• Can 𝐻 distinguish all subsets of 𝑆?
• The number of concepts over 𝑆: 2 𝑆 .
• (Def) 𝑆 is shattered by 𝐻 if all the concepts over 𝑆 are included in 𝐻.
• I.e., for any bi-partition (𝑆1, 𝑆2) of 𝑆, there exists one ℎ in 𝐻, such that ℎ(𝑠) = 0 for every 𝑠 ∈ 𝑆1 and ℎ(𝑠) = 1 for each 𝑠 ∈ 𝑆2.
• Corollary: 𝐻 ≥ 2 𝑆 if 𝐻 can shatter 𝑆.
4.1.3 The Mistake Bound Model of Learning
Mistake Bound Model of Learning algorithms for learning are:

KEY TAKEAWAYS
Instance-based learning methods simply store the training examples instead of learning an explicit description of the target function.
Instance-based learning includes
Instance-based methods are sometimes referred to as lazy learning methods because they delay processing until a new instance must be classified.
• A key advantage of lazy learning is it can estimate target function locally and differently for each new instance to be classified instead of estimating it only once for the entire instance space.
4.2.1 k-Nearest Neighbour Learning
k-Nearest Neighbor Learning algorithm assumes all instances correspond to points in the n-dimensional space Rn
• The nearest neighbors of an instance are defined in terms of Euclidean distance. • Euclidean distance between the instances xi = and xj = are:
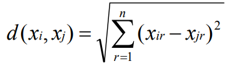
• For a given query instance xq, f(xq) is calculated the function values of a k-nearest neighbor of xq
The KNN algorithm assumes that similar things exist in close proximity. In other words, similar things stay near to each other.
3. for each example in the data
3.1 Calculate the distance between the query example and the current example from the data.
3.2 Add the distance and the index of the example to an ordered collection
4. Sort the ordered collection of distances and indices from smallest to largest (in ascending order) by the distances
5. Pick the first K entries from the sorted collection
6. Get the labels of the selected K entries
7. If regression, return the mean of the K labels
8. If classification, return the mode of the K labels
when to apply KNN
Advantages
Disadvantages
4.2.2 Locally Weighted Regression
KNN forms local approximation to f for each query point xq
• so to form an explicit approximation f(x) for the region surrounding xq
Locally Weighted Regression
Given a new query instance xq, the general approach in locally weighted regression is to construct an approximation f that fits the training examples in the neighborhood surrounding xq.
• This approximation is then used to calculate the value f(xq), which is output as the estimated target value for the query instance.
• Locally weighted regression uses nearby or distance-weighted training examples to form this local approximation to f.
• We might approximate the target function in the neighbourhood surrounding x, using a linear function, a quadratic function, a multilayer neural network.
The phrase "locally weighted regression" is called
4.2.3 Radial basis function networks
One approach to function approximation that is closely related to distance-weighted regression and also to artificial neural networks is learning with radial basis functions.
• The learned hypothesis is a function of the form

In Radial Basis Function Networks Each hidden unit produces an activation determined by a Gaussian function centered at some instance xu. Therefore, its activation will be close to zero unless the input x is near xu. The output unit produces a linear combination of the hidden unit activations.
Case-Based Reasoning classifiers (CBR) exploits a database of problem solutions to solve new problems. It stores tuples or cases for problem-solving as complex symbolic descriptions.
Working:
When a new case arises to classify, a CBR will first check if an identical training case exists. If found, then the accompanying solution to that case is returned. If no identical case is found, then the CBR will search for training cases having components that are similar to that new case. Assuming that these training cases may be considered as neighbours of the new case.
If cases are represented as graphs, it involves searching for sub-graphs that are similar to sub-graphs of new cases. The CBR efforts to combine solutions of the neighbouring training cases to propose a solution for the new case. If compatibilities are located within the individual solutions, then backtracking to search for other solutions may be necessary.
The CBR may employ background knowledge and problem-solving strategies to propose a feasible solution.
Applications of CBR includes:
Issues in CBR
CBR becomes more intelligent as the number of the trade-off between accuracy and efficiency evolves as the number of stored cases becomes very large. But after a certain point, the system’s efficiency will suffer as the time required to search for and process relevant cases increases.
KEY TAKEAWAYS
References:
UNIT 4
Computational Learning Theory
Computational learning theory also known as statistical learning theory is a mathematical framework for quantifying learning tasks and algorithms. It is one of the many sub-fields of machine learning.
“One can extend statistical learning theory by taking computational complexity of the learner into account. This field is called computational learning theory or COLT”
4.1.1 Sample Complexity for Finite Hypothesis spaces
sample complexity is growing in some required training examples with its defined problem size of a learning problem.
4.1.2 Sample Complexity for Infinite Hypothesis spaces
Motivation: classification is to distinguish subsets.
• A set of instances 𝑆 and a hypothesis space 𝐻.
• Can 𝐻 distinguish all subsets of 𝑆?
• The number of concepts over 𝑆: 2 𝑆 .
• (Def) 𝑆 is shattered by 𝐻 if all the concepts over 𝑆 are included in 𝐻.
• I.e., for any bi-partition (𝑆1, 𝑆2) of 𝑆, there exists one ℎ in 𝐻, such that ℎ(𝑠) = 0 for every 𝑠 ∈ 𝑆1 and ℎ(𝑠) = 1 for each 𝑠 ∈ 𝑆2.
• Corollary: 𝐻 ≥ 2 𝑆 if 𝐻 can shatter 𝑆.
4.1.3 The Mistake Bound Model of Learning
Mistake Bound Model of Learning algorithms for learning are:

KEY TAKEAWAYS
Instance-based learning methods simply store the training examples instead of learning an explicit description of the target function.
Instance-based learning includes
Instance-based methods are sometimes referred to as lazy learning methods because they delay processing until a new instance must be classified.
• A key advantage of lazy learning is it can estimate target function locally and differently for each new instance to be classified instead of estimating it only once for the entire instance space.
4.2.1 k-Nearest Neighbour Learning
k-Nearest Neighbor Learning algorithm assumes all instances correspond to points in the n-dimensional space Rn
• The nearest neighbors of an instance are defined in terms of Euclidean distance. • Euclidean distance between the instances xi = and xj = are:
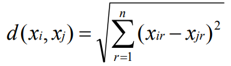
• For a given query instance xq, f(xq) is calculated the function values of a k-nearest neighbor of xq
The KNN algorithm assumes that similar things exist in close proximity. In other words, similar things stay near to each other.
3. for each example in the data
3.1 Calculate the distance between the query example and the current example from the data.
3.2 Add the distance and the index of the example to an ordered collection
4. Sort the ordered collection of distances and indices from smallest to largest (in ascending order) by the distances
5. Pick the first K entries from the sorted collection
6. Get the labels of the selected K entries
7. If regression, return the mean of the K labels
8. If classification, return the mode of the K labels
when to apply KNN
Advantages
Disadvantages
4.2.2 Locally Weighted Regression
KNN forms local approximation to f for each query point xq
• so to form an explicit approximation f(x) for the region surrounding xq
Locally Weighted Regression
Given a new query instance xq, the general approach in locally weighted regression is to construct an approximation f that fits the training examples in the neighborhood surrounding xq.
• This approximation is then used to calculate the value f(xq), which is output as the estimated target value for the query instance.
• Locally weighted regression uses nearby or distance-weighted training examples to form this local approximation to f.
• We might approximate the target function in the neighbourhood surrounding x, using a linear function, a quadratic function, a multilayer neural network.
The phrase "locally weighted regression" is called
4.2.3 Radial basis function networks
One approach to function approximation that is closely related to distance-weighted regression and also to artificial neural networks is learning with radial basis functions.
• The learned hypothesis is a function of the form

In Radial Basis Function Networks Each hidden unit produces an activation determined by a Gaussian function centered at some instance xu. Therefore, its activation will be close to zero unless the input x is near xu. The output unit produces a linear combination of the hidden unit activations.
Case-Based Reasoning classifiers (CBR) exploits a database of problem solutions to solve new problems. It stores tuples or cases for problem-solving as complex symbolic descriptions.
Working:
When a new case arises to classify, a CBR will first check if an identical training case exists. If found, then the accompanying solution to that case is returned. If no identical case is found, then the CBR will search for training cases having components that are similar to that new case. Assuming that these training cases may be considered as neighbours of the new case.
If cases are represented as graphs, it involves searching for sub-graphs that are similar to sub-graphs of new cases. The CBR efforts to combine solutions of the neighbouring training cases to propose a solution for the new case. If compatibilities are located within the individual solutions, then backtracking to search for other solutions may be necessary.
The CBR may employ background knowledge and problem-solving strategies to propose a feasible solution.
Applications of CBR includes:
Issues in CBR
CBR becomes more intelligent as the number of the trade-off between accuracy and efficiency evolves as the number of stored cases becomes very large. But after a certain point, the system’s efficiency will suffer as the time required to search for and process relevant cases increases.
KEY TAKEAWAYS
References:




