UNIT 1
Introduction
A computer system is basically a machine that simplifies complicated tasks. It should maximize performance and reduce costs as well as power consumption. The different components in the Computer System Architecture are Input Unit, Output Unit, Storage Unit, Arithmetic Logic Unit, Control Unit etc.
A diagram that shows the flow of data between these units is as follows −
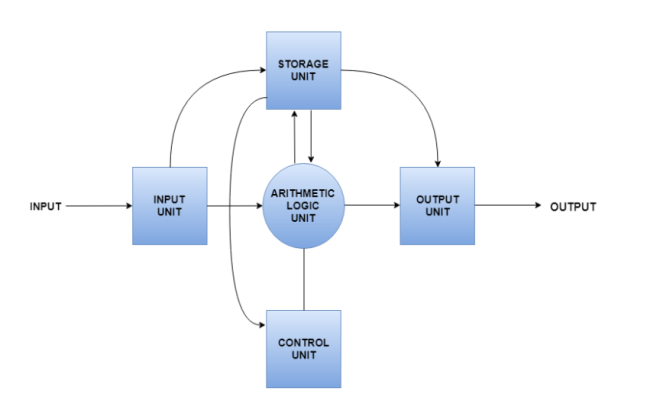
The input data travels from input unit to ALU. Similarly, the computed data travels from ALU to output unit. The data constantly moves from storage unit to ALU and back again. This is because stored data is computed on before being stored again. The control unit controls all the other units as well as their data.
Details about all the computer units are −
- Input Unit
The input unit provides data to the computer system from the outside. So, basically it links the external environment with the computer. It takes data from the input devices, converts it into machine language and then loads it into the computer system. Keyboard, mouse etc. are the most commonly used input devices.
- Output Unit
The output unit provides the results of computer process to the users i.e it links the computer with the external environment. Most of the output data is the form of audio or video. The different output devices are monitors, printers, speakers, headphones etc.
- Storage Unit
Storage unit contains many computer components that are used to store data. It is traditionally divided into primary storage and secondary storage. Primary storage is also known as the main memory and is the memory directly accessible by the CPU. Secondary or external storage is not directly accessible by the CPU. The data from secondary storage needs to be brought into the primary storage before the CPU can use it. Secondary storage contains a large amount of data permanently.
- Arithmetic Logic Unit
All the calculations related to the computer system are performed by the arithmetic logic unit. It can perform operations like addition, subtraction, multiplication, division etc. The control unit transfers data from storage unit to arithmetic logic unit when calculations need to be performed. The arithmetic logic unit and the control unit together form the central processing unit.
- Control Unit
This unit controls all the other units of the computer system and so is known as its central nervous system. It transfers data throughout the computer as required including from storage unit to central processing unit and vice versa. The control unit also dictates how the memory, input output devices, arithmetic logic unit etc. should behave.
Central Processing Unit (CPU) consists of the following features −
- CPU is considered as the brain of the computer.
- CPU performs all types of data processing operations.
- It stores data, intermediate results, and instructions (program).
- It controls the operation of all parts of the computer.

CPU itself has following three components.
- Memory or Storage Unit
- Control Unit
- ALU(Arithmetic Logic Unit)
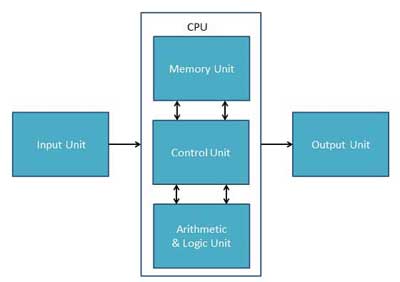
Memory or Storage Unit
This unit can store instructions, data, and intermediate results. This unit supplies information to other units of the computer when needed. It is also known as internal storage unit or the main memory or the primary storage or Random Access Memory (RAM).
Its size affects speed, power, and capability. Primary memory and secondary memory are two types of memories in the computer. Functions of the memory unit are −
- It stores all the data and the instructions required for processing.
- It stores intermediate results of processing.
- It stores the final results of processing before these results are released to an output device.
- All inputs and outputs are transmitted through the main memory.
Control Unit
This unit controls the operations of all parts of the computer but does not carry out any actual data processing operations.
Functions of this unit are −
- It is responsible for controlling the transfer of data and instructions among other units of a computer.
- It manages and coordinates all the units of the computer.
- It obtains the instructions from the memory, interprets them, and directs the operation of the computer.
- It communicates with Input/output devices for transfer of data or results from storage.
- It does not process or store data.
ALU (Arithmetic Logic Unit)
This unit consists of two subsections namely,
- Arithmetic Section
- Logic Section
Arithmetic Section
Function of arithmetic section is to perform arithmetic operations like addition, subtraction, multiplication, and division. All complex operations are done by making repetitive use of the above operations.
Logic Section
Function of logic section is to perform logic operations such as comparing, selecting, matching, and merging of data.
A memory is just like a human brain. It is used to store data and instructions. Computer memory is the storage space in the computer, where data is to be processed and instructions required for processing are stored. The memory is divided into large number of small parts called cells. Each location or cell has a unique address, which varies from zero to memory size minus one. For example, if the computer has 64k words, then this memory unit has 64 * 1024 = 65536 memory locations. The address of these locations varies from 0 to 65535.
Memory is primarily of three types −
- Cache Memory
- Primary Memory/Main Memory
- Secondary Memory
Cache Memory
Cache memory is a very high speed semiconductor memory which can speed up the CPU. It acts as a buffer between the CPU and the main memory. It is used to hold those parts of data and program which are most frequently used by the CPU. The parts of data and programs are transferred from the disk to cache memory by the operating system, from where the CPU can access them.

Advantages
The advantages of cache memory are as follows −
- Cache memory is faster than main memory.
- It consumes less access time as compared to main memory.
- It stores the program that can be executed within a short period of time.
- It stores data for temporary use.
Disadvantages
The disadvantages of cache memory are as follows −
- Cache memory has limited capacity.
- It is very expensive.
Primary Memory (Main Memory)
Primary memory holds only those data and instructions on which the computer is currently working. It has a limited capacity and data is lost when power is switched off. It is generally made up of semiconductor device. These memories are not as fast as registers. The data and instruction required to be processed resides in the main memory. It is divided into two subcategories RAM and ROM.

Characteristics of Main Memory
- These are semiconductor memories.
- It is known as the main memory.
- Usually volatile memory.
- Data is lost in case power is switched off.
- It is the working memory of the computer.
- Faster than secondary memories.
- A computer cannot run without the primary memory.
Secondary Memory
This type of memory is also known as external memory or non-volatile. It is slower than the main memory. These are used for storing data/information permanently. CPU directly does not access these memories, instead they are accessed via input-output routines. The contents of secondary memories are first transferred to the main memory, and then the CPU can access it. For example, disk, CD-ROM, DVD, etc.

Characteristics of Secondary Memory
- These are magnetic and optical memories.
- It is known as the backup memory.
- It is a non-volatile memory.
- Data is permanently stored even if power is switched off.
- It is used for storage of data in a computer.
- Computer may run without the secondary memory.
- Slower than primary memories.
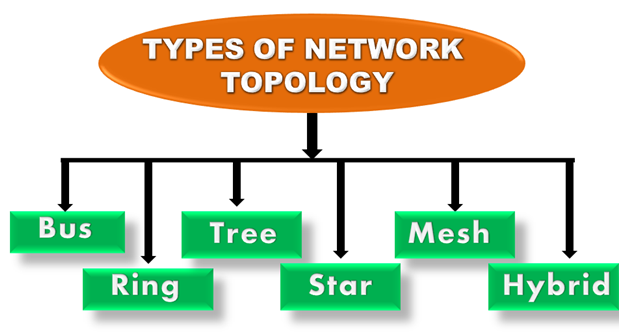
Topology defines the structure of the network of how all the components are interconnected to each other. There are two types of topology: physical and logical topology.
Physical topology is the geometric representation of all the nodes in a network.
Bus Topology
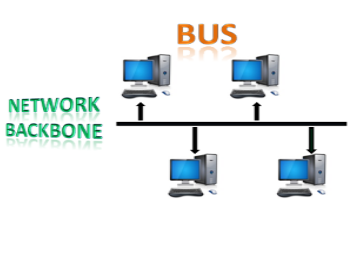
- The bus topology is designed in such a way that all the stations are connected through a single cable known as a backbone cable.
- Each node is either connected to the backbone cable by drop cable or directly connected to the backbone cable.
- When a node wants to send a message over the network, it puts a message over the network. All the stations available in the network will receive the message whether it has been addressed or not.
- The bus topology is mainly used in 802.3 (ethernet) and 802.4 standard networks.
- The configuration of a bus topology is quite simpler as compared to other topologies.
- The backbone cable is considered as a "single lane" through which the message is broadcast to all the stations.
- The most common access method of the bus topologies is CSMA (Carrier Sense Multiple Access).
CSMA: It is a media access control used to control the data flow so that data integrity is maintained, i.e., the packets do not get lost. There are two alternative ways of handling the problems that occur when two nodes send the messages simultaneously.
- CSMA CD: CSMA CD (Collision detection) is an access method used to detect the collision. Once the collision is detected, the sender will stop transmitting the data. Therefore, it works on "recovery after the collision".
- CSMA CA: CSMA CA (Collision Avoidance) is an access method used to avoid the collision by checking whether the transmission media is busy or not. If busy, then the sender waits until the media becomes idle. This technique effectively reduces the possibility of the collision. It does not work on "recovery after the collision".
Advantages of Bus topology:
- Low-cost cable: In bus topology, nodes are directly connected to the cable without passing through a hub. Therefore, the initial cost of installation is low.
- Moderate data speeds: Coaxial or twisted pair cables are mainly used in bus-based networks that support upto 10 Mbps.
- Familiar technology: Bus topology is a familiar technology as the installation and troubleshooting techniques are well known, and hardware components are easily available.
- Limited failure: A failure in one node will not have any effect on other nodes.
Disadvantages of Bus topology:
- Extensive cabling: A bus topology is quite simpler, but still it requires a lot of cabling.
- Difficult troubleshooting: It requires specialized test equipment to determine the cable faults. If any fault occurs in the cable, then it would disrupt the communication for all the nodes.
- Signal interference: If two nodes send the messages simultaneously, then the signals of both the nodes collide with each other.
- Reconfiguration difficult: Adding new devices to the network would slow down the network.
- Attenuation: Attenuation is a loss of signal leads to communication issues. Repeaters are used to regenerate the signal.
Ring Topology
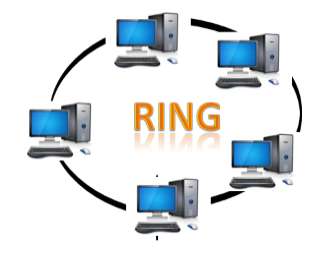
- Ring topology is like a bus topology, but with connected ends.
- The node that receives the message from the previous computer will retransmit to the next node.
- The data flows in one direction, i.e., it is unidirectional.
- The data flows in a single loop continuously known as an endless loop.
- It has no terminated ends, i.e., each node is connected to other node and having no termination point.
- The data in a ring topology flow in a clockwise direction.
- The most common access method of the ring topology is token passing.
- Token passing: It is a network access method in which token is passed from one node to another node.
- Token: It is a frame that circulates around the network.
Working of Token passing
- A token moves around the network, and it is passed from computer to computer until it reaches the destination.
- The sender modifies the token by putting the address along with the data.
- The data is passed from one device to another device until the destination address matches. Once the token received by the destination device, then it sends the acknowledgment to the sender.
- In a ring topology, a token is used as a carrier.
Advantages of Ring topology:
- Network Management: Faulty devices can be removed from the network without bringing the network down.
- Product availability: Many hardware and software tools for network operation and monitoring are available.
- Cost: Twisted pair cabling is inexpensive and easily available. Therefore, the installation cost is very low.
- Reliable: It is a more reliable network because the communication system is not dependent on the single host computer.
Disadvantages of Ring topology:
- Difficult troubleshooting: It requires specialized test equipment to determine the cable faults. If any fault occurs in the cable, then it would disrupt the communication for all the nodes.
- Failure: The breakdown in one station leads to the failure of the overall network.
- Reconfiguration difficult: Adding new devices to the network would slow down the network.
- Delay: Communication delay is directly proportional to the number of nodes. Adding new devices increases the communication delay.
Star Topology
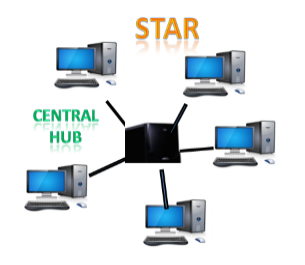
- Star topology is an arrangement of the network in which every node is connected to the central hub, switch or a central computer.
- The central computer is known as a server, and the peripheral devices attached to the server are known as clients.
- Coaxial cable or RJ-45 cables are used to connect the computers.
- Hubs or Switches are mainly used as connection devices in a physical star topology.
- Star topology is the most popular topology in network implementation.
Advantages of Star topology
- Efficient troubleshooting: Troubleshooting is quite efficient in a star topology as compared to bus topology. In a bus topology, the manager has to inspect the kilometres of cable. In a star topology, all the stations are connected to the centralized network. Therefore, the network administrator has to go to the single station to troubleshoot the problem.
- Network control: Complex network control features can be easily implemented in the star topology. Any changes made in the star topology are automatically accommodated.
- Limited failure: As each station is connected to the central hub with its own cable, therefore failure in one cable will not affect the entire network.
- Familiar technology: Star topology is a familiar technology as its tools are cost-effective.
- Easily expandable: It is easily expandable as new stations can be added to the open ports on the hub.
- Cost effective: Star topology networks are cost-effective as it uses inexpensive coaxial cable.
- High data speeds: It supports a bandwidth of approx 100Mbps. Ethernet 100BaseT is one of the most popular Star topology networks.
Disadvantages of Star topology
- A Central point of failure: If the central hub or switch goes down, then all the connected nodes will not be able to communicate with each other.
- Cable: Sometimes cable routing becomes difficult when a significant amount of routing is required.
Tree topology
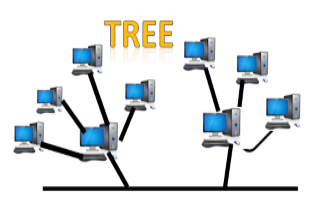
- Tree topology combines the characteristics of bus topology and star topology.
- A tree topology is a type of structure in which all the computers are connected with each other in hierarchical fashion.
- The top-most node in tree topology is known as a root node, and all other nodes are the descendants of the root node.
- There is only one path exists between two nodes for the data transmission. Thus, it forms a parent-child hierarchy.
Advantages of Tree topology
- Support for broadband transmission: Tree topology is mainly used to provide broadband transmission, i.e., signals are sent over long distances without being attenuated.
- Easily expandable: We can add the new device to the existing network. Therefore, we can say that tree topology is easily expandable.
- Easily manageable: In tree topology, the whole network is divided into segments known as star networks which can be easily managed and maintained.
- Error detection: Error detection and error correction are very easy in a tree topology.
- Limited failure: The breakdown in one station does not affect the entire network.
- Point-to-point wiring: It has point-to-point wiring for individual segments.
Disadvantages of Tree topology
- Difficult troubleshooting: If any fault occurs in the node, then it becomes difficult to troubleshoot the problem.
- High cost: Devices required for broadband transmission are very costly.
- Failure: A tree topology mainly relies on main bus cable and failure in main bus cable will damage the overall network.
- Reconfiguration difficult: If new devices are added, then it becomes difficult to reconfigure.
Mesh topology
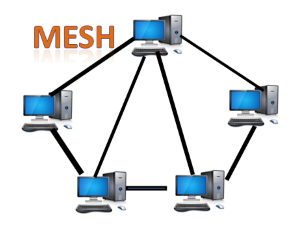
- Mesh technology is an arrangement of the network in which computers are interconnected with each other through various redundant connections.
- There are multiple paths from one computer to another computer.
- It does not contain the switch, hub or any central computer which acts as a central point of communication.
- The Internet is an example of the mesh topology.
- Mesh topology is mainly used for WAN implementations where communication failures are a critical concern.
- Mesh topology is mainly used for wireless networks.
- Mesh topology can be formed by using the formula:
Number of cables = (n*(n-1))/2;
Where n is the number of nodes that represents the network.
Mesh topology is divided into two categories:
- Fully connected mesh topology
- Partially connected mesh topology
- Full Mesh Topology: In a full mesh topology, each computer is connected to all the computers available in the network.
- Partial Mesh Topology: In a partial mesh topology, not all but certain computers are connected to those computers with which they communicate frequently.
Advantages of Mesh topology:
Reliable: The mesh topology networks are very reliable as if any link breakdown will not affect the communication between connected computers.
Fast Communication: Communication is very fast between the nodes.
Easier Reconfiguration: Adding new devices would not disrupt the communication between other devices.
Disadvantages of Mesh topology
- Cost: A mesh topology contains a large number of connected devices such as a router and more transmission media than other topologies.
- Management: Mesh topology networks are very large and very difficult to maintain and manage. If the network is not monitored carefully, then the communication link failure goes undetected.
- Efficiency: In this topology, redundant connections are high that reduces the efficiency of the network.
Hybrid Topology
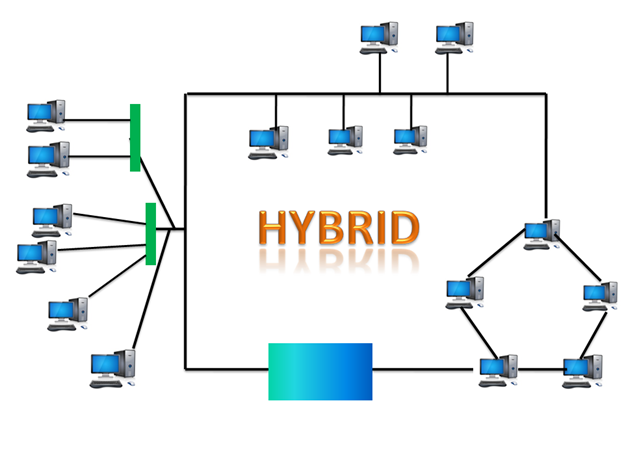
- The combination of various different topologies is known as Hybrid topology.
- A Hybrid topology is a connection between different links and nodes to transfer the data.
- When two or more different topologies are combined together is termed as Hybrid topology and if similar topologies are connected with each other will not result in Hybrid topology. For example, if there exist a ring topology in one branch of ICICI bank and bus topology in another branch of ICICI bank, connecting these two topologies will result in Hybrid topology.
Advantages of Hybrid Topology
- Reliable: If a fault occurs in any part of the network will not affect the functioning of the rest of the network.
- Scalable: Size of the network can be easily expanded by adding new devices without affecting the functionality of the existing network.
- Flexible: This topology is very flexible as it can be designed according to the requirements of the organization.
- Effective: Hybrid topology is very effective as it can be designed in such a way that the strength of the network is maximized and weakness of the network is minimized.
Disadvantages of Hybrid topology
- Complex design: The major drawback of the Hybrid topology is the design of the Hybrid network. It is very difficult to design the architecture of the Hybrid network.
- Costly Hub: The Hubs used in the Hybrid topology are very expensive as these hubs are different from usual Hubs used in other topologies.
- Costly infrastructure: The infrastructure cost is very high as a hybrid network requires a lot of cabling, network devices, etc.
What is a storage device?
Storage devices are the computer hardware used to remember/store data.
There are many types of storage devices, each with their own benefits and drawbacks.
Hard Disk Drive (HDD)

What is a hard disk drive?
Hard disk drives are non-volatile magnetic storage devices capable of remembering vast amounts of data.
An electromagnet in the read/write head charges the disk’s surface with either a positive or negative charge, this is how binary 1 or 0 is represented.
The read/write head is then capable of detecting the magnetic charges left on the disk’s surface, this is how data is read.
The disk surface is divided into concentric circles (tracks) and sectors (wedges). Dividing the surface in this way provides physical addresses to remember where data is saved.
A circuit board carefully co-ordinates the rotating disk and swinging actuator arm to allow the read/write head to access any location very quickly.
Typical HDD capacities are measured in Terabytes (TB).
They can be installed inside a computer or purchased in a portable (external) format.
Typical applications for hard disk drives
- Desktop computers
- Laptop computers
- TV and satellite recorders
- Servers and mainframes
- Portable (external) drives are sometimes used to backup home computers or transfer large files
Benefits of hard disk drives
- Capable of holding vast amounts of data at affordable prices
- Fast read and write speeds
- Reliable technology
- Relatively small in size
Drawbacks of hard disk drives
- Due to the nature of its moving parts, they will eventually wear and break
- Although very fast, waiting for the moving parts means it will never perform as fast as solid state drives
- More fragile and less robust than a solid state drive
- Higher power consumption than a SSD
- Some noise is created by the moving parts
Solid State Drive (SSD)

What is a solid state drive?
Solid state drives are non-volatile storage devices capable of holding large amounts of data.
They use NAND flash memories (millions of transistors wired in a series on a circuit board), giving them the advantage of having no mechanical moving parts and therefore immediate access to the data.
Solid state drives perform faster than traditional hard disk drives, however they are significantly more expensive.
This expense means that typical capacities are usually measured in Gigabytes (GB).
They can be installed inside a computer or purchased in a portable (external) format.
Until we reach a point where large capacity SSDs is affordable, a compromise is to run two disk drives inside a computer. An SSD as the primary drive for your important programs and operating system, and a traditional HDD to store music, documents and pictures (which don’t need the faster access times).
The lack of moving parts in an SSD makes it very robust and reliable, ideal for a portable device.
Typical applications for solid state drives
- Smartphones
- Tablet computers
- High-end laptops
- Two drive desktop solutions
- Portable drives are sometimes used in HD video cameras
Benefits of solid state drives
- Extremely fast read/write speeds
- Small in physical size and very light, ideal for portable devices
- No moving parts to wear, fail or get damaged – ideal for making portable computers and devices more reliable and durable
- Uses less power than a HDD, increasing battery life time
- Very quiet
- Generates less heat
Drawbacks of solid state drives
- Expensive to buy (per GB)
- Limited in capacity due to the expense
- Limited amount of writes
Random Access Memory (RAM)

What is RAM?
RAM is a computer’s primary memory. It is a very fast solid state storage medium that is directly accessible by the CPU.
Any open programs or files on a computer are temporarily stored in RAM whilst being used.
Being volatile, any data stored in RAM will be lost when power is removed. This makes RAM totally unsuitable for the long term permanent storage of data – that is the role of a HDD or SSD instead.
Data is copied from secondary storage (HDD, SSD) to RAM as and when it is needed. This is because using a HDD as the primary memory would cause a computer to perform much slower (a HDD or SSD is not directly accessible to the CPU, and isn’t as fast as RAM).
RAM is a relatively expensive storage device and typical capacities are measured in Gigabytes (GB).
Computers operating with a capacity of RAM above the recommended minimum will benefit from better performance and multitasking.
There are two types of RAM (SRAM and DRAM), each with their own advantages and disadvantages.
Typical applications of RAM
- The fast and directly accessible temporary (working) memory needed by a computer
Benefits of RAM
- Directly accessible to the CPU, making processing data faster
- Fast solid state storage, making processing data faster
Drawbacks of RAM
- Relatively expensive memory
- Volatile – any data stored in RAM is lost when power is removed
Static RAM (SRAM)
Data on SRAM does not require refreshing.
However, the technology is bulkier meaning less memory per chip.
- More expensive than DRAM
- Much faster than DRAM
- Consumes less power
- Commonly used in cache memory
Dynamic RAM (DRAM)
The most common type of RAM in use.
The data needs to be continually refreshed otherwise it fades away.
Continually refreshing the data takes time and reduces performance speeds.
- Cheaper than SRAM
- Commonly used in main memory
CD, DVD and Blu-Ray Discs

What are optical storage discs?
CD, DVD and Blue-ray drives are optical storage devices.
Binary data is stored as changes to the texture of the disc’s surface, sometimes thought of as microscopic pits and bumps.
These ‘bumps’ are located on a continuous spiral track, starting at the centre of the disc.
Whilst the disc is rotating at a constant speed, a laser is pointed at the spiral track of ‘bumps’.
The laser will reflect/bounce off the disc surface in different directions depending upon whether a 1 or 0 has been read.
Disc capacities
In the pursuit of larger optical storage capacities, DVDs were created, followed by Blu-Ray.
CD | DVD | Blu-Ray |
700 MB | 4.7 GB | 25 GB – 128 GB |
Typical applications for optical media
- CD – Audio and small amounts of data
- DVD – Standard definition movies and data
- Blu-Ray – HD video and large amounts of data
DVD
Despite being the same physical size, a DVD can hold more data than a CD.
To achieve this, a more tightly packed spiral track is used to store the data on the disc.
To accurately access the smaller ‘bumps’, a finer red laser is used in a DVD drive than that found in a standard CD drive.
To increase capacity further, DVDs are also capable of dual layering.
Blu-Ray
Blu-Ray technology squashes even more data into the same size disc as a CD or DVD.
The spiral data tracks on a Blu-Ray disc are so small a special blue (violet) laser has to be used to read the ‘bumps’.
Like a DVD, Blu-Ray discs are capable of storing data on multiple layers.
Recordable Optical Media
CD-ROM, DVD-ROM, Blu-Ray-ROM
Read only – the data is permanently written to the disc at the point of manufacture.
CD-R, DVD-R, BD-R
Recordable – blank discs that can be burnt (written to) once.
CD-RW, DVD-RW, BD-RE
Re-writable – blank discs that can be burnt (written to) over and over again (can be erased and reused many times).
DVD-RAM

What is DVD-RAM?
DVD-RAM is an optical media storage device.
It differs from a traditional DVD in that data is stored in concentric tracks (like a HDD) which allows read and write operations to be carried out at the same time.
This means, for example, that when used in a personal video recorder you can record one television programme whilst watching a recording of another. This allows handy features such as ‘time slip’ to be possible.
When used within a CCTV system you could review footage whilst still recording your cameras.
The capacity of DVD-RAM is 4.7 GB, or 9.4 GB for double-sided discs.
Typical applications for DVD-RAM
- Personal and digital video recorders
- High-end CCTV
Benefits of DVD-RAM
- Read and write at the same time
- Can be rewritten to many more times than a traditional DVD-RW
- Has write-protect tabs to prevent accidental deletion when used in an optional cartridge
- Data is retained for an estimated 30 years. This long life is great for archiving data
- Reliable writing of discs because the verification done by the hardware, not by software
Drawbacks of DVD-RAM
- Disc speeds higher than 5x are less common
- Less compatibility than DVD-RW
ROM

What is ROM?
ROM is a non-volatile memory chip whose contents cannot be altered.
It is often used to store the start-up routines in a computer (e.g. The BIOS).
Typical applications for ROM
- Storing the computer’s start up routine
USB Flash Memory

What is USB Flash Memory?
Flash are non-volatile solid state storage devices which use NAND flash memories to store data (millions of transistors).
USB refers to the USB connection that allows users to plug the device into the USB port of a computer.
Other types of flash storage include the memory cards used in digital cameras.
Flash memory comes in a variety of capacities to suit most budgets and requirements.
Typical applications for flash memory
- USB memory sticks – saving and transferring documents etc
- Memory cards in digital cameras
Benefits of flash memory
- Portable, small and lightweight
- Durability, flash has no moving parts to damage
- Range of capacities available
- Fast speeds, with no moving parts of boot up time
Drawbacks of flash memory
- Limited (but huge) number of write cycles possible
- Really high capacities are uncommon
- In relative terms, an expensive storage option compared to a HDD
We assume you are well aware of English Language, which is a well-known Human Interface Language. English has a predefined grammar, which needs to be followed to write English statements in a correct way. Likewise, most of the Human Interface Languages (Hindi, English, Spanish, French, etc.) are made of several elements like verbs, nouns, adjectives, adverbs, propositions, and conjunctions, etc.
Similar to Human Interface Languages, Computer Programming Languages are also made of several elements. We will take you through the basics of those elements and make you comfortable to use them in various programming languages. These basic elements include −
- Programming Environment
- Basic Syntax
- Data Types
- Variables
- Keywords
- Basic Operators
- Decision Making
- Loops
- Numbers
- Characters
- Arrays
- Strings
- Functions
- File I/O
We will explain all these elements in subsequent chapters with examples using different programming languages. First, we will try to understand the meaning of all these terms in general and then, we will see how these terms can be used in different programming languages.
This tutorial has been designed to give you an idea about the following most popular programming languages −
- C Programming
- Java Programming
- Python Programming
A major part of the tutorial has been explained by taking C as programming language and then we have shown how similar concepts work in Java and Python. So after completion of this tutorial, you will be quite familiar with these popular programming languages.
A programming language defines a set of instructions that are compiled together to perform a specific task by the CPU (Central Processing Unit). The programming language mainly refers to high-level languages such as C, C++, Pascal, Ada, COBOL, etc.
Each programming language contains a unique set of keywords and syntax, which are used to create a set of instructions. Thousands of programming languages have been developed till now, but each language has its specific purpose. These languages vary in the level of abstraction they provide from the hardware. Some programming languages provide less or no abstraction while some provide higher abstraction. Based on the levels of abstraction, they can be classified into two categories:
- Low-level language
- High-level language
The image which is given below describes the abstraction level from hardware. As we can observe from the below image that the machine language provides no abstraction, assembly language provides less abstraction whereas high-level language provides a higher level of abstraction.
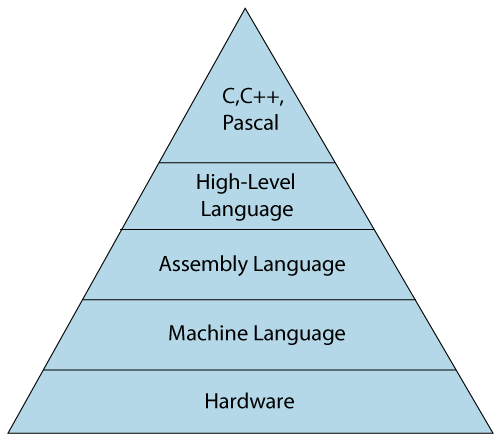
Low-level language
The low-level language is a programming language that provides no abstraction from the hardware, and it is represented in 0 or 1 forms, which are the machine instructions. The languages that come under this category are the Machine level language and Assembly language.
Machine-level language
The machine-level language is a language that consists of a set of instructions that are in the binary form 0 or 1. As we know that computers can understand only machine instructions, which are in binary digits, i.e., 0 and 1, so the instructions given to the computer can be only in binary codes. Creating a program in a machine-level language is a very difficult task as it is not easy for the programmers to write the program in machine instructions. It is error-prone as it is not easy to understand, and its maintenance is also very high. A machine-level language is not portable as each computer has its machine instructions, so if we write a program in one computer will no longer be valid in another computer.
The different processor architectures use different machine codes, for example, a PowerPC processor contains RISC architecture, which requires different code than intel x86 processor, which has a CISC architecture.
Assembly Language
The assembly language contains some human-readable commands such as mov, add, sub, etc. The problems which we were facing in machine-level language are reduced to some extent by using an extended form of machine-level language known as assembly language. Since assembly language instructions are written in English words like mov, add, sub, so it is easier to write and understand.
As we know that computers can only understand the machine-level instructions, so we require a translator that converts the assembly code into machine code. The translator used for translating the code is known as an assembler.
The assembly language code is not portable because the data is stored in computer registers, and the computer has to know the different sets of registers.
The assembly code is not faster than machine code because the assembly language comes above the machine language in the hierarchy, so it means that assembly language has some abstraction from the hardware while machine language has zero abstraction.
Differences between Machine-Level language and Assembly language
The following are the differences between machine-level language and assembly language:
Machine-level language | Assembly language |
The machine-level language comes at the lowest level in the hierarchy, so it has zero abstraction level from the hardware. | The assembly language comes above the machine language means that it has less abstraction level from the hardware. |
It cannot be easily understood by humans. | It is easy to read, write, and maintain. |
The machine-level language is written in binary digits, i.e., 0 and 1. | The assembly language is written in simple English language, so it is easily understandable by the users. |
It does not require any translator as the machine code is directly executed by the computer. | In assembly language, the assembler is used to convert the assembly code into machine code. |
It is a first-generation programming language. | It is a second-generation programming language. |
High-Level Language
The high-level language is a programming language that allows a programmer to write the programs which are independent of a particular type of computer. The high-level languages are considered as high-level because they are closer to human languages than machine-level languages.
When writing a program in a high-level language, then the whole attention needs to be paid to the logic of the problem.
A compiler is required to translate a high-level language into a low-level language.
Advantages of a high-level language
- The high-level language is easy to read, write, and maintain as it is written in English like words.
- The high-level languages are designed to overcome the limitation of low-level language, i.e., portability. The high-level language is portable; i.e., these languages are machine-independent.
Differences between Low-Level language and High-Level language
The following are the differences between low-level language and high-level language:
Low-level language | High-level language |
It is a machine-friendly language, i.e., the computer understands the machine language, which is represented in 0 or 1. | It is a user-friendly language as this language is written in simple English words, which can be easily understood by humans. |
The low-level language takes more time to execute. | It executes at a faster pace. |
It requires the assembler to convert the assembly code into machine code. | It requires the compiler to convert the high-level language instructions into machine code. |
The machine code cannot run on all machines, so it is not a portable language. | The high-level code can run all the platforms, so it is a portable language. |
It is memory efficient. | It is less memory efficient. |
Debugging and maintenance are not easier in a low-level language. | Debugging and maintenance are easier in a high-level language. |
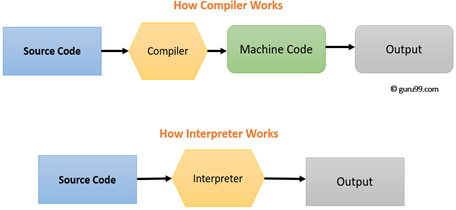
What is Compiler?
A compiler is a computer program that transforms code written in a high-level programming language into the machine code. It is a program which translates the human-readable code to a language a computer processor understands (binary 1 and 0 bits). The computer processes the machine code to perform the corresponding tasks.
A compiler should comply with the syntax rule of that programming language in which it is written. However, the compiler is only a program and cannot fix errors found in that program. So, if you make a mistake, you need to make changes in the syntax of your program. Otherwise, it will not compile.
What is Interpreter?
An interpreter is a computer program, which coverts each high-level program statement into the machine code. This includes source code, pre-compiled code, and scripts. Both compiler and interpreters do the same job which is converting higher level programming language to machine code. However, a compiler will convert the code into machine code (create an exe) before program run. Interpreters convert code into machine code when the program is run.
KEY DIFFERENCE
- Compiler transforms code written in a high-level programming language into the machine code, at once, before program runs, whereas Interpreter coverts each high-level program statement, one by one, into the machine code, during program run.
- Compiled code runs faster while interpreted code runs slower.
- Compiler displays all errors after compilation; on the other hand, the Interpreter displays errors of each line one by one.
- Compiler is based on translation linking-loading model, whereas Interpreter is based on Interpretation Method.
- Compiler takes an entire program whereas the Interpreter takes a single line of code.
Difference between Compiler and Interpreter
Basis of difference | Compiler | Interpreter |
Programming Steps |
|
|
Advantage | The program code is already translated into machine code. Thus, it code execution time is less. | Interpreters are easier to use, especially for beginners. |
Disadvantage | You can't change the program without going back to the source code. | Interpreted programs can run on computers that have the corresponding interpreter. |
Machine code | Store machine language as machine code on the disk | Not saving machine code at all. |
Running time | Compiled code run faster | Interpreted code run slower |
Model | It is based on language translation linking-loading model. | It is based on Interpretation Method. |
Program generation | Generates output program (in the form of exe) which can be run independently from the original program. | Do not generate output program. So they evaluate the source program at every time during execution. |
Execution | Program execution is separate from the compilation. It performed only after the entire output program is compiled. | Program Execution is a part of Interpretation process, so it is performed line by line. |
Memory requirement | Target program execute independently and do not require the compiler in the memory. | The interpreter exists in the memory during interpretation. |
Best suited for | Bounded to the specific target machine and cannot be ported. C and C++ are a most popular a programming language which uses compilation model. | For web environments, where load times are important. Due to all the exhaustive analysis is done, compiles take relatively larger time to compile even small code that may not be run multiple times. In such cases, interpreters are better. |
Code Optimization | The compiler sees the entire code upfront. Hence, they perform lots of optimizations that make code run faster | Interpreters see code line by line, and thus optimizations are not as robust as compilers |
Dynamic Typing | Difficult to implement as compilers cannot predict what happens at turn time. | Interpreted languages support Dynamic Typing |
Usage | It is best suited for the Production Environment | It is best suited for the program and development environment. |
Error execution | Compiler displays all errors and warning at the compilation time. Therefore, you can't run the program without fixing errors | The interpreter reads a single statement and shows the error if any. You must correct the error to interpret next line. |
Input | It takes an entire program | It takes a single line of code. |
Output | Compliers generate intermediate machine code. | Interpreter never generates any intermediate machine code. |
Errors | Display all errors after, compilation, all at the same time. | Displays all errors of each line one by one. |
Pertaining Programming languages | C,C++,C#, Scala, Java all use complier. | PHP, Perl, Ruby uses an interpreter. |
Role of Compiler
- Compliers reads the source code, outputs executable code
- Translates software written in a higher-level language into instructions that computer can understand. It converts the text that a programmer writes into a format the CPU can understand.
- The process of compilation is relatively complicated. It spends a lot of time analyzing and processing the program.
- The executable result is some form of machine-specific binary code.
Role of Interpreter
- The interpreter converts the source code line-by-line during RUN Time.
- Interpret completely translates a program written in a high-level language into machine level language.
- Interpreter allows evaluation and modification of the program while it is executing.
- Relatively less time spent for analysing and processing the program
- Program execution is relatively slow compared to compiler
HIGH-LEVEL LANGUAGES
High-level languages, like C, C++, JAVA, etc., are very near to English. It makes programming process easy. However, it must be translated into machine language before execution. This translation process is either conducted by either a compiler or an interpreter. Also known as source code.
MACHINE CODE
Machine languages are very close to the hardware. Every computer has its machine language. A machine language programs are made up of series of binary pattern. (Eg. 110110) It represents the simple operations which should be performed by the computer. Machine language programs are executable so that they can be run directly.
OBJECT CODE
On compilation of source code, the machine code generated for different processors like Intel, AMD, an ARM is different. TTo make code portable, the source code is first converted to Object Code. It is an intermediary code (similar to machine code) that no processor will understand. At run time, the object code is converted to the machine code of the underlying platform.
Java is both Compiled and Interpreted.
To exploit relative advantages of compilers are interpreters some programming language like Java are both compiled and interpreted. The Java code itself is compiled into Object Code. At run time, the JVM interprets the Object code into machine code of the target computer.
What is C programming?
C is a general-purpose programming language that is extremely popular, simple and flexible. It is machine-independent, structured programming language which is used extensively in various applications.
C was the basic language to write everything from operating systems (Windows and many others) to complex programs like the Oracle database, Git, Python interpreter and more.
It is said that 'C' is a god's programming language. One can say, C is a base for the programming. If you know 'C,' you can easily grasp the knowledge of the other programming languages that uses the concept of 'C'
It is essential to have a background in computer memory mechanisms because it is an important aspect when dealing with the C programming language.
History of C language
The base or father of programming languages is 'ALGOL.' It was first introduced in 1960. 'ALGOL' was used on a large basis in European countries. 'ALGOL' introduced the concept of structured programming to the developer community. In 1967, a new computer programming language was announced called as 'BCPL' which stands for Basic Combined Programming Language. BCPL was designed and developed by Martin Richards, especially for writing system software. This was the era of programming languages. Just after three years, in 1970 a new programming language called 'B' was introduced by Ken Thompson that contained multiple features of 'BCPL.' This programming language was created using UNIX operating system at AT&T and Bell Laboratories. Both the 'BCPL' and 'B' were system programming languages.
In 1972, a great computer scientist Dennis Ritchie created a new programming language called 'C' at the Bell Laboratories. It was created from 'ALGOL', 'BCPL' and 'B' programming languages. 'C' programming language contains all the features of these languages and many more additional concepts that make it unique from other languages.
'C' is a powerful programming language which is strongly associated with the UNIX operating system. Even most of the UNIX operating system is coded in 'C'. Initially 'C' programming was limited to the UNIX operating system, but as it started spreading around the world, it became commercial, and many compilers were released for cross-platform systems. Today 'C' runs under a variety of operating systems and hardware platforms. As it started evolving many different versions of the language were released. At times it became difficult for the developers to keep up with the latest version as the systems were running under the older versions. To assure that 'C' language will remain standard, American National Standards Institute (ANSI) defined a commercial standard for 'C' language in 1989. Later, it was approved by the International Standards Organization (ISO) in 1990. 'C' programming language is also called as 'ANSI C'.

History of C
Languages such as C++/Java are developed from 'C'. These languages are widely used in various technologies. Thus, 'C' forms a base for many other languages that are currently in use.
Where is C used? Key Applications
- 'C' language is widely used in embedded systems.
- It is used for developing system applications.
- It is widely used for developing desktop applications.
- Most of the applications by Adobe are developed using 'C' programming language.
- It is used for developing browsers and their extensions. Google's Chromium is built using 'C' programming language.
- It is used to develop databases. MySQL is the most popular database software which is built using 'C'.
- It is used in developing an operating system. Operating systems such as Apple's OS X, Microsoft's Windows, and Symbian are developed using 'C' language. It is used for developing desktop as well as mobile phone's operating system.
- It is used for compiler production.
- It is widely used in IOT applications.
Why learn 'C'?
As we studied earlier, 'C' is a base language for many programming languages. So, learning 'C' as the main language will play an important role while studying other programming languages. It shares the same concepts such as data types, operators, control statements and many more. 'C' can be used widely in various applications. It is a simple language and provides faster execution. There are many jobs available for a 'C' developer in the current market.
'C' is a structured programming language in which program is divided into various modules. Each module can be written separately and together it forms a single 'C' program. This structure makes it easy for testing, maintaining and debugging processes.
'C' contains 32 keywords, various data types and a set of powerful built-in functions that make programming very efficient.
Another feature of 'C' programming is that it can extend itself. A 'C' program contains various functions which are part of a library. We can add our features and functions to the library. We can access and use these functions anytime we want in our program. This feature makes it simple while working with complex programming.
Various compilers are available in the market that can be used for executing programs written in this language.
It is a highly portable language which means programs written in 'C' language can run on other machines. This feature is essential if we wish to use or execute the code on another computer.
How 'C' Works?
C is a compiled language. A compiler is a special tool that compiles the program and converts it into the object file which is machine readable. After the compilation process, the linker will combine different object files and creates a single executable file to run the program. The following diagram shows the execution of a 'C' program
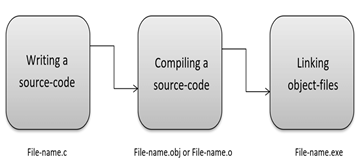
Nowadays, various compilers are available online, and you can use any of those compilers. The functionality will never differ and most of the compilers will provide the features required to execute both 'C' and 'C++' programs.
Following is the list of popular compilers available online:
- Clang compiler
- MinGW compiler (Minimalist GNU for Windows)
- Portable 'C' compiler
- Turbo C
Summary
- 'C' was developed by Dennis Ritchie in 1972.
- It is a robust language.
- It is a low programming level language close to machine language
- It is widely used in the software development field.
- It is a procedure and structure oriented language.
- It has the full support of various operating systems and hardware platforms.
- Many compilers are available for executing programs written in 'C'.
- A compiler compiles the source file and generates an object file.
- A linker links all the object files together and creates one executable file.
- It is highly portable.
As every language contains a set of characters used to construct words, statements, etc., C language also has a set of characters which include alphabets, digits, and special symbols. C language supports a total of 256 characters.
Every C program contains statements. These statements are constructed using words and these words are constructed using characters from C character set. C language character set contains the following set of characters...
- Alphabets
- Digits
- Special Symbols
Alphabets
C language supports all the alphabets from the English language. Lower and upper case letters together support 52 alphabets.
Lower case letters - a to z
UPPER CASE LETTERS - A to Z
Digits
C language supports 10 digits which are used to construct numerical values in C language.
Digits - 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
Special Symbols
C language supports a rich set of special symbols that include symbols to perform mathematical operations, to check conditions, white spaces, backspaces, and other special symbols.
Special Symbols - ~ @ # $ % ^ & * ( ) _ - + = { } [ ] ; : ' " / ? . > , < \ | tab newline space NULL bell backspace vertical tab etc.,
Every character in C language has its equivalent ASCII (American Standard Code for Information Interchange) value.
Tokens are the smallest elements of a program, which are meaningful to the compiler.
The following are the types of tokens: Keywords, Identifiers, Constant, Strings, Operators, etc.
Let us begin with Keywords.
Keywords
Keywords are predefined, reserved words in C and each of which is associated with specific features. These words help us to use the functionality of C language. They have special meaning to the compilers.
There are total 32 keywords in C.
Auto | Double | Int | Struct |
Break | Else | Long | Switch |
Case | Enum | Register | Typedef |
Char | Extern | Return | Union |
Continue | For | Signed | Void |
Do | If | Static | While |
Default | Goto | Sizeof | Volatile |
Const | Float | Short | Unsigned |
Identifiers
Each program element in C programming is known as an identifier. They are used for naming of variables, functions, array etc. These are user-defined names which consist of alphabets, number, underscore ‘_’. Identifier’s name should not be same or same as keywords. Keywords are not used as identifiers.
Rules for naming C identifiers −
- It must begin with alphabets or underscore.
- Only alphabets, numbers, underscore can be used, no other special characters, punctuations are allowed.
- It must not contain white-space.
- It should not be a keyword.
- It should be up to 31 characters long.
Constants
Its value is fixed throughout the program that means constants are those variables which value is not changed throughout the program.
C constants can be divided into two major categories:
- Primary Constants
- Secondary Constants
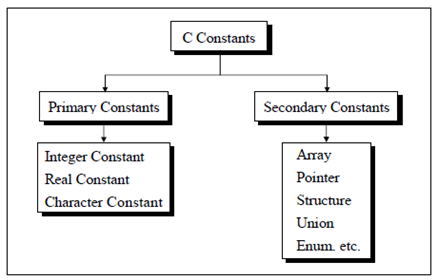
There are two simple ways in C to define constants:
1. Using#define
e.g.
#include <stdio.h>
#define value 10
Void main() {
Int data;
Data = value*value;
Printf("value of data : %d",data);
}
Output
value of data : 100
2. Using const keyword
e.g.
#include <stdio.h>
Void main() {
Const int value = 10;
Int data;
Data =value*value;
Printf("value of data : %d",value);
}
Output
value of data : 100
Variables
Variable is used to store the value. As name indicates its value can be changed or also it can be reused many times.
Syntax
Data type variable_name;
e.g.
Int a;
Where a is the variables.
There are many types of variables in c:
- Local variable
- Global variable
- Static variable
- External variable
- Automatic variable
1. Local variable – A variable which is declared inside the function is known as local variable. It is used only inside the function in which it is declared.
2. Global variable – A variable which is declared outside the function is known as global variable. It can be used throughout the program.
3. Static variable – It is used to retain its value between multiple function calls. It is declared using static keyword.
4. External variable – You can share a variable in multiple C source files by using external variable. It is declared using extern keyword.
5. Automatic variable – Variable which is declared inside the block is known as automatic variable by default.
A data type specifies the type of data that a variable can store such as integer, floating, character, etc.
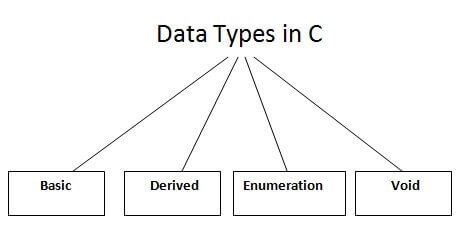
There are the following data types in C language.
Types | Data Types |
Basic Data Type | Int, char, float, double |
Derived Data Type | Array, pointer, structure, union |
Enumeration Data Type | Enum |
Void Data Type | Void |
Basic Data Types
The basic data types are integer-based and floating-point based. C language supports both signed and unsigned literals.
The memory size of the basic data types may change according to 32 or 64-bit operating system.
Let's see the basic data types. Its size is given according to 32-bit architecture.
Data Types | Memory Size | Range |
Char | 1 byte | −128 to 127 |
Signed char | 1 byte | −128 to 127 |
Unsigned char | 1 byte | 0 to 255 |
Short | 2 byte | −32,768 to 32,767 |
Signed short | 2 byte | −32,768 to 32,767 |
Unsigned short | 2 byte | 0 to 65,535 |
Int | 2 byte | −32,768 to 32,767 |
Signed int | 2 byte | −32,768 to 32,767 |
Unsigned int | 2 byte | 0 to 65,535 |
Short int | 2 byte | −32,768 to 32,767 |
Signed short int | 2 byte | −32,768 to 32,767 |
Unsigned short int | 2 byte | 0 to 65,535 |
Long int | 4 byte | -2,147,483,648 to 2,147,483,647 |
Signed long int | 4 byte | -2,147,483,648 to 2,147,483,647 |
Unsigned long int | 4 byte | 0 to 4,294,967,295 |
Float | 4 byte |
|
Double | 8 byte |
|
Long double | 10 byte |
|
A variable is a name of the memory location. It is used to store data. Its value can be changed, and it can be reused many times.
It is a way to represent memory location through symbol so that it can be easily identified.
Let's see the syntax to declare a variable:
- Type variable_list;
The example of declaring the variable is given below:
- Int a;
- Float b;
- Char c;
Here, a, b, c are variables. The int, float, char are the data types.
We can also provide values while declaring the variables as given below:
- Int a=10,b=20;//declaring 2 variable of integer type
- Float f=20.8;
- Char c='A';
Rules for defining variables
- A variable can have alphabets, digits, and underscore.
- A variable name can start with the alphabet, and underscore only. It can't start with a digit.
- No whitespace is allowed within the variable name.
- A variable name must not be any reserved word or keyword, e.g. Int, float, etc.
Valid variable names:
- Int a;
- Int _ab;
- Int a30;
Invalid variable names:
- Int 2;
- Int a b;
- Int long;
Types of Variables in C
There are many types of variables in c:
- Local variable
- Global variable
- Static variable
- Automatic variable
- External variable
Local Variable
A variable that is declared inside the function or block is called a local variable.
It must be declared at the start of the block.
- Void function1(){
- Int x=10;//local variable
- }
You must have to initialize the local variable before it is used.
Global Variable
A variable that is declared outside the function or block is called a global variable. Any function can change the value of the global variable. It is available to all the functions.
It must be declared at the start of the block.
- Int value=20;//global variable
- Void function1(){
- Int x=10;//local variable
- }
Static Variable
A variable that is declared with the static keyword is called static variable.
It retains its value between multiple function calls.
- Void function1(){
- Int x=10;//local variable
- Static int y=10;//static variable
- x=x+1;
- y=y+1;
- Printf("%d,%d",x,y);
- }
If you call this function many times, the local variable will print the same value for each function call, e.g, 11,11,11 and so on. But the static variable will print the incremented value in each function call, e.g. 11, 12, 13 and so on.
Automatic Variable
All variables in C that are declared inside the block, are automatic variables by default. We can explicitly declare an automatic variable using auto keyword.
- Void main(){
- Int x=10;//local variable (also automatic)
- Auto int y=20;//automatic variable
- }
External Variable
We can share a variable in multiple C source files by using an external variable. To declare an external variable, you need to use extern keyword.
Myfile.h
- Extern int x=10;//external variable (also global)
Program1.c
- #include "myfile.h"
- #include <stdio.h>
- Void printValue(){
- Printf("Global variable: %d", global_variable);
- }
The value of Pi is a constant, it never changes. The only question we really have with Pi is, “How precise do we want to be?” We need to insure a uniform amount of precision throughout the program, so that the value will not be changed by mistake. This means that we do not want the value of Pi to vary from function to function.
After all, the whole point of variables is that they are mutable. If we store Pi in a variable, there is nothing to insure that the value won’t be modified by accident.
A symbolic constant is a constant that is represented by a symbol in our program. Whenever we need the symbolic constant’s value in our program, we can its name just as we would use a variable’s name.
There are two ways to implement symbolic constants in C. Our first option here is to define Pi as a symbol that will be replaced in the program by a specified value during compilation. In this case, Pi wouldn’t be a variable at all, it would more like an alias or stand-in for the value it represents. We do this using what is know as a #define directive.
#include <stdio.h>
#define PI 3.14159
int main(void){
double diameter = 5.5;
double radius = diameter / 2.0;
double circumference = 2.0*radius*PI;
double area = PI*radius*radius;
printf("The diameter of the circle is %.2f\n", diameter);
printf("The radius of the circle is %.2f\n", radius);
printf("The circumference of the circle is %.3f\n", circumference);
printf("The area of the circle is %.3f\n", area);
return 0;
}
Note that by convention identifiers that appear in a #define statement are written in capital letters.
All #define directives should be grouped together near the beginning of the file and before the main() function.
#include <stdio.h>
#define GRAMS_PER_POUND 454
#define METERS_PER_FOOT .3048
int main(void){
int pounds1 = 115;
int pounds2 = 175;
int feet1 = 6;
int feet2 = 300;
printf("%d pounds = %d grams\n", pounds1, pounds1 * GRAMS_PER_POUND);
printf("%d pounds = %d grams\n", pounds2, pounds2 * GRAMS_PER_POUND);
printf("%d feet = %f meters\n", feet1, METERS_PER_FOOT * (double)feet1);
printf("%d feet = %f meters\n", feet2, METERS_PER_FOOT * (double)feet2);
return 0;
}
The second way to define a symbolic constant is with the const keyword. We can make the value of any variable immutable by prefixing the type name with the keyword const when we declare the variable. A value is initialized at the time of declaration and is then prohibited from being changed. Any code that attempts to change its value will be flagged as an error and the compilation will fail.
#include <stdio.h>
int main(void){
const double Pi = 3.14159;
double radius = 11.11;
double circumference = radius * 2.0 * Pi;
double area = radius * radius * Pi;
printf("The radius of the circle is %f\n", radius);
printf("The circumference of the circle is %f\n", circumference);
printf("The area of the circle is %f\n", area);
return 0;
}
Note that many functions in the standard library use const in their parameter declarations.
The header file <limits.h> defines symbolic constants that represent values for the limits of each integer data type.
#include <stdio.h>
#include <limits.h>
int main(void){
printf("The char type stores values from %d to %d\n", CHAR_MIN, CHAR_MAX);
printf("The int type stores values from %d to %d\n", INT_MIN, INT_MAX);
printf("The unsigned int type stores values from 0 to %u\n", UINT_MAX);
printf("The long long int type stores values form %lld to %lld\n", LLONG_MIN, LLONG_MAX);
return 0;
}
An operator is a symbol that tells the compiler to perform specific mathematical or logical functions. C language is rich in built-in operators and provides the following types of operators −
- Arithmetic Operators
- Relational Operators
- Logical Operators
- Bitwise Operators
- Assignment Operators
- Misc. Operators
We will, in this chapter, look into the way each operator works.
Arithmetic Operators
The following table shows all the arithmetic operators supported by the C language. Assume variable A holds 10 and variable B holds 20 then −
Show Examples
Operator | Description | Example |
+ | Adds two operands. | A + B = 30 |
− | Subtracts second operand from the first. | A − B = -10 |
* | Multiplies both operands. | A * B = 200 |
/ | Divides numerator by de-numerator. | B / A = 2 |
% | Modulus Operator and remainder of after an integer division. | B % A = 0 |
++ | Increment operator increases the integer value by one. | A++ = 11 |
-- | Decrement operator decreases the integer value by one. | A-- = 9 |
Relational Operators
The following table shows all the relational operators supported by C. Assume variable A holds 10 and variable B holds 20 then −
Show Examples
Operator | Description | Example |
== | Checks if the values of two operands are equal or not. If yes, then the condition becomes true. | (A == B) is not true. |
!= | Checks if the values of two operands are equal or not. If the values are not equal, then the condition becomes true. | (A != B) is true. |
> | Checks if the value of left operand is greater than the value of right operand. If yes, then the condition becomes true. | (A > B) is not true. |
< | Checks if the value of left operand is less than the value of right operand. If yes, then the condition becomes true. | (A < B) is true. |
>= | Checks if the value of left operand is greater than or equal to the value of right operand. If yes, then the condition becomes true. | (A >= B) is not true. |
<= | Checks if the value of left operand is less than or equal to the value of right operand. If yes, then the condition becomes true. | (A <= B) is true. |
Logical Operators
Following table shows all the logical operators supported by C language. Assume variable A holds 1 and variable B holds 0, then −
Show Examples
Operator | Description | Example |
&& | Called Logical AND operator. If both the operands are non-zero, then the condition becomes true. | (A && B) is false. |
|| | Called Logical OR Operator. If any of the two operands is non-zero, then the condition becomes true. | (A || B) is true. |
! | Called Logical NOT Operator. It is used to reverse the logical state of its operand. If a condition is true, then Logical NOT operator will make it false. | !(A && B) is true. |
Bitwise Operators
Bitwise operator works on bits and perform bit-by-bit operation. The truth tables for &, |, and ^ is as follows −
p | q | p & q | p | q | p ^ q |
0 | 0 | 0 | 0 | 0 |
0 | 1 | 0 | 1 | 1 |
1 | 1 | 1 | 1 | 0 |
1 | 0 | 0 | 1 | 1 |
Assume A = 60 and B = 13 in binary format, they will be as follows −
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
The following table lists the bitwise operators supported by C. Assume variable 'A' holds 60 and variable 'B' holds 13, then −
Show Examples
Operator | Description | Example |
& | Binary AND Operator copies a bit to the result if it exists in both operands. | (A & B) = 12, i.e., 0000 1100 |
| | Binary OR Operator copies a bit if it exists in either operand. | (A | B) = 61, i.e., 0011 1101 |
^ | Binary XOR Operator copies the bit if it is set in one operand but not both. | (A ^ B) = 49, i.e., 0011 0001 |
~ | Binary One's Complement Operator is unary and has the effect of 'flipping' bits. | (~A ) = ~(60), i.e,. -0111101 |
<< | Binary Left Shift Operator. The left operands value is moved left by the number of bits specified by the right operand. | A << 2 = 240 i.e., 1111 0000 |
>> | Binary Right Shift Operator. The left operands value is moved right by the number of bits specified by the right operand. | A >> 2 = 15 i.e., 0000 1111 |
Assignment Operators
The following table lists the assignment operators supported by the C language −
Show Examples
Operator | Description | Example |
= | Simple assignment operator. Assigns values from right side operands to left side operand | C = A + B will assign the value of A + B to C |
+= | Add AND assignment operator. It adds the right operand to the left operand and assign the result to the left operand. | C += A is equivalent to C = C + A |
-= | Subtract AND assignment operator. It subtracts the right operand from the left operand and assigns the result to the left operand. | C -= A is equivalent to C = C - A |
*= | Multiply AND assignment operator. It multiplies the right operand with the left operand and assigns the result to the left operand. | C *= A is equivalent to C = C * A |
/= | Divide AND assignment operator. It divides the left operand with the right operand and assigns the result to the left operand. | C /= A is equivalent to C = C / A |
%= | Modulus AND assignment operator. It takes modulus using two operands and assigns the result to the left operand. | C %= A is equivalent to C = C % A |
<<= | Left shift AND assignment operator. | C <<= 2 is same as C = C << 2 |
>>= | Right shift AND assignment operator. | C >>= 2 is same as C = C >> 2 |
&= | Bitwise AND assignment operator. | C &= 2 is same as C = C & 2 |
^= | Bitwise exclusive OR and assignment operator. | C ^= 2 is same as C = C ^ 2 |
|= | Bitwise inclusive OR and assignment operator. | C |= 2 is same as C = C | 2 |
Misc Operators ↦ sizeof & ternary
Besides the operators discussed above, there are a few other important operators including sizeof and ? : supported by the C Language.
Show Examples
Operator | Description | Example |
Sizeof() | Returns the size of a variable. | Sizeof(a), where a is integer, will return 4. |
& | Returns the address of a variable. | &a; returns the actual address of the variable. |
* | Pointer to a variable. | *a; |
? : | Conditional Expression. | If Condition is true ? then value X : otherwise value Y |
Operators Precedence in C
Operator precedence determines the grouping of terms in an expression and decides how an expression is evaluated. Certain operators have higher precedence than others; for example, the multiplication operator has a higher precedence than the addition operator.
For example, x = 7 + 3 * 2; here, x is assigned 13, not 20 because operator * has a higher precedence than +, so it first gets multiplied with 3*2 and then adds into 7.
Here, operators with the highest precedence appear at the top of the table, those with the lowest appear at the bottom. Within an expression, higher precedence operators will be evaluated first.
Increment and decrement operators
Increment Operators: The increment operator is used to increment the value of a variable in an expression. In the Pre-Increment, value is first incremented and then used inside the expression. Whereas in the Post-Increment, value is first used inside the expression and then incremented.
Syntax:
// PREFIX
++m
// POSTFIX
m++
Where m is a variable
Example:
#include <stdio.h>
Int increment(int a, int b) { a = 5;
// POSTFIX b = a++; Printf("%d", b);
// PREFIX Int c = ++b; Printf("\n%d", c); }
// Driver code Int main() { Int x, y; Increment(x, y);
Return 0; } |
Decrement Operators: The decrement operator is used to decrement the value of a variable in an expression. In the Pre-Decrement, value is first decremented and then used inside the expression. Whereas in the Post-Decrement, value is first used inside the expression and then decremented.
Syntax:
// PREFIX
--m
// POSTFIX
m--
Where m is a variable
Example:
#include <stdio.h>
Int decrement(int a, int b) { a = 5;
// POSTFIX b = a--; Printf("%d", b);
// PREFIX Int c = --b; Printf("\n%d", c); }
// Driver code Int main() { Int x, y; Decrement(x, y);
Return 0; } |
Differences between Increment and Decrement Operators:
Increment Operators | Decrement Operators |
Increment Operator adds 1 to the operand. | Decrement Operator subtracts 1 from the operand. |
Postfix increment operator means the expression is evaluated first using the original value of the variable and then the variable is incremented(increased). | Postfix decrement operator means the expression is evaluated first using the original value of the variable and then the variable is decremented(decreased). |
Prefix increment operator means the variable is incremented first and then the expression is evaluated using the new value of the variable. | Prefix decrement operator means the variable is decremented first and then the expression is evaluated using the new value of the variable. |
Generally, we use this in decision making and looping. | This is also used in decision making and looping. |
Conditional operator
The conditional operator is also known as a ternary operator. The conditional statements are the decision-making statements which depends upon the output of the expression. It is represented by two symbols, i.e., '?' and ':'.
As conditional operator works on three operands, so it is also known as the ternary operator.
The behavior of the conditional operator is similar to the 'if-else' statement as 'if-else' statement is also a decision-making statement.
Syntax of a conditional operator
- Expression1? expression2: expression3;
The pictorial representation of the above syntax is shown below:
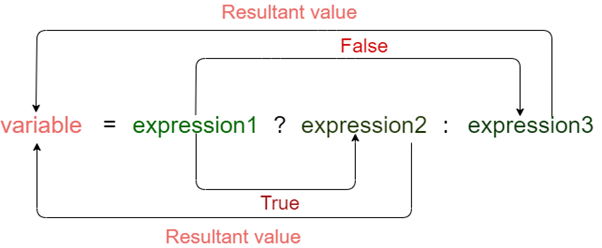
Meaning of the above syntax.
- In the above syntax, the expression1 is a Boolean condition that can be either true or false value.
- If the expression1 results into a true value, then the expression2 will execute.
- The expression2 is said to be true only when it returns a non-zero value.
- If the expression1 returns false value then the expression3 will execute.
- The expression3 is said to be false only when it returns zero value.
Let's understand the ternary or conditional operator through an example.
- #include <stdio.h>
- Int main()
- {
- Int age; // variable declaration
- Printf("Enter your age");
- Scanf("%d",&age); // taking user input for age variable
- (age>=18)? (printf("eligible for voting")) : (printf("not eligible for voting")); // conditional operator
- Return 0;
- }
In the above code, we are taking input as the 'age' of the user. After taking input, we have applied the condition by using a conditional operator. In this condition, we are checking the age of the user. If the age of the user is greater than or equal to 18, then the statement1 will execute, i.e., (printf("eligible for voting")) otherwise, statement2 will execute, i.e., (printf("not eligible for voting")).
Let's observe the output of the above program.
If we provide the age of user below 18, then the output would be:

If we provide the age of user above 18, then the output would be:
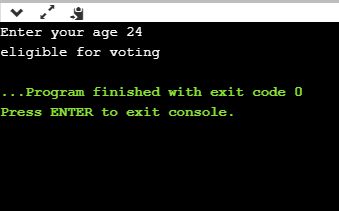
As we can observe from the above two outputs that if the condition is true, then the statement1 is executed; otherwise, statement2 will be executed.
Till now, we have observed that how conditional operator checks the condition and based on condition, it executes the statements. Now, we will see how a conditional operator is used to assign the value to a variable.
Let's understand this scenario through an example.
- #include <stdio.h>
- Int main()
- {
- Int a=5,b; // variable declaration
- b=((a==5)?(3):(2)); // conditional operator
- Printf("The value of 'b' variable is : %d",b);
- Return 0;
- }
In the above code, we have declared two variables, i.e., 'a' and 'b', and assign 5 value to the 'a' variable. After the declaration, we are assigning value to the 'b' variable by using the conditional operator. If the value of 'a' is equal to 5 then 'b' is assigned with a 3 value otherwise 2.
Output
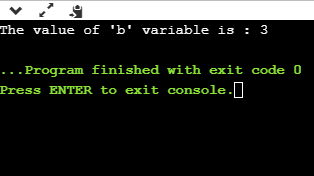
The above output shows that the value of 'b' variable is 3 because the value of 'a' variable is equal to 5.
As we know that the behaviour of conditional operator and 'if-else' is similar but they have some differences. Let's look at their differences.
- A conditional operator is a single programming statement, while the 'if-else' statement is a programming block in which statements come under the parenthesis.
- A conditional operator can also be used for assigning a value to the variable, whereas the 'if-else' statement cannot be used for the assignment purpose.
- It is not useful for executing the statements when the statements are multiple, whereas the 'if-else' statement proves more suitable when executing multiple statements.
- The nested ternary operator is more complex and cannot be easily debugged, while the nested 'if-else' statement is easy to read and maintain.
Special Operators in C:
Below are some of the special operators that the C programming language offers.
Operators | Description |
& | This is used to get the address of the variable. Example : &a will give address of a. |
* | This is used as pointer to a variable. Example : * a where, * is pointer to the variable a. |
Sizeof () | This gives the size of the variable. Example : size of (char) will give us 1. |
Example program for & and * operators in C:
In this program, “&” symbol is used to get the address of the variable and “*” symbol is used to get the value of the variable that the pointer is pointing to. Please refer C – pointer topic to know more about pointers.
C
1 2 3 4 5 6 7 8 9 10 11 | #include <stdio.h> Int main() { Int *ptr, q; q = 50; /* address of q is assigned to ptr */ Ptr = &q; /* display q's value using ptr variable */ Printf("%d", *ptr); Return 0; } |
Output:
50 |
Example program for sizeof() operator in C:
Sizeof() operator is used to find the memory space allocated for each C data types.
C
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h> #include <limits.h>
Int main() { Int a; Char b; Float c; Double d; Printf("Storage size for int data type:%d \n",sizeof(a)); Printf("Storage size for char data type:%d \n",sizeof(b)); Printf("Storage size for float data type:%d \n",sizeof(c)); Printf("Storage size for double data type:%d\n",sizeof(d)); Return 0; } |
Output:
Storage size for int data type:4 Storage size for char data type:1 |
Continue on types of C operators:
Click on each operator name below for detailed description and example programs.
Types of Operators | Description |
Arithmetic operator | These are used to perform mathematical calculations like addition, subtraction, multiplication, division and modulus |
Assignment operators | These are used to assign the values for the variables in C programs. |
Relational operators | These operators are used to compare the value of two variables. |
Logical operators | These operators are used to perform logical operations on the given two variables. |
Bit wise operators | These operators are used to perform bit operations on given two variables. |
Conditional (ternary) operators | Conditional operators return one value if condition is true and returns another value is condition is false. |
Increment/decrement operators | These operators are used to either increase or decrease the value of the variable by one. |
Special operators | &, *, sizeof( ) and ternary operators. |
C Expressions
An expression is a formula in which operands are linked to each other by the use of operators to compute a value. An operand can be a function reference, a variable, an array element or a constant.
Let's see an example:
- a-b;
In the above expression, minus character (-) is an operator, and a, and b are the two operands.
There are four types of expressions exist in C:
- Arithmetic expressions
- Relational expressions
- Logical expressions
- Conditional expressions
Each type of expression takes certain types of operands and uses a specific set of operators. Evaluation of a particular expression produces a specific value.
For example:
- x = 9/2 + a-b;
The entire above line is a statement, not an expression. The portion after the equal is an expression.
Arithmetic Expressions
An arithmetic expression is an expression that consists of operands and arithmetic operators. An arithmetic expression computes a value of type int, float or double.
When an expression contains only integral operands, then it is known as pure integer expression when it contains only real operands, it is known as pure real expression, and when it contains both integral and real operands, it is known as mixed mode expression.
Evaluation of Arithmetic Expressions
The expressions are evaluated by performing one operation at a time. The precedence and associativity of operators decide the order of the evaluation of individual operations.
When individual operations are performed, the following cases can be happened:
- When both the operands are of type integer, then arithmetic will be performed, and the result of the operation would be an integer value. For example, 3/2 will yield 1 not 1.5 as the fractional part is ignored.
- When both the operands are of type float, then arithmetic will be performed, and the result of the operation would be a real value. For example, 2.0/2.0 will yield 1.0, not 1.
- If one operand is of type integer and another operand is of type real, then the mixed arithmetic will be performed. In this case, the first operand is converted into a real operand, and then arithmetic is performed to produce the real value. For example, 6/2.0 will yield 3.0 as the first value of 6 is converted into 6.0 and then arithmetic is performed to produce 3.0.
Let's understand through an example.
6*2/ (2+1 * 2/3 + 6) + 8 * (8/4)
Evaluation of expression | Description of each operation |
6*2/( 2+1 * 2/3 +6) +8 * (8/4) | An expression is given. |
6*2/(2+2/3 + 6) + 8 * (8/4) | 2 is multiplied by 1, giving value 2. |
6*2/(2+0+6) + 8 * (8/4) | 2 is divided by 3, giving value 0. |
6*2/ 8+ 8 * (8/4) | 2 is added to 6, giving value 8. |
6*2/8 + 8 * 2 | 8 is divided by 4, giving value 2. |
12/8 +8 * 2 | 6 is multiplied by 2, giving value 12. |
1 + 8 * 2 | 12 is divided by 8, giving value 1. |
1 + 16 | 8 is multiplied by 2, giving value 16. |
17 | 1 is added to 16, giving value 17. |
Relational Expressions
- A relational expression is an expression used to compare two operands.
- It is a condition which is used to decide whether the action should be taken or not.
- In relational expressions, a numeric value cannot be compared with the string value.
- The result of the relational expression can be either zero or non-zero value. Here, the zero value is equivalent to a false and non-zero value is equivalent to true.
Relational Expression | Description |
x%2 = = 0 | This condition is used to check whether the x is an even number or not. The relational expression results in value 1 if x is an even number otherwise results in value 0. |
a!=b | It is used to check whether a is not equal to b. This relational expression results in 1 if a is not equal to b otherwise 0. |
a+b = = x+y | It is used to check whether the expression "a+b" is equal to the expression "x+y". |
a>=9 | It is used to check whether the value of a is greater than or equal to 9. |
Let's see a simple example:
- #include <stdio.h>
- Int main()
- {
- Int x=4;
- If(x%2==0)
- {
- Printf("The number x is even");
- }
- Else
- Printf("The number x is not even");
- Return 0;
- }
Output
Logical Expressions
- A logical expression is an expression that computes either a zero or non-zero value.
- It is a complex test condition to take a decision.
Let's see some example of the logical expressions.
Logical Expressions | Description |
( x > 4 ) && ( x < 6 ) | It is a test condition to check whether the x is greater than 4 and x is less than 6. The result of the condition is true only when both the conditions are true. |
x > 10 || y <11 | It is a test condition used to check whether x is greater than 10 or y is less than 11. The result of the test condition is true if either of the conditions holds true value. |
! ( x > 10 ) && ( y = = 2 ) | It is a test condition used to check whether x is not greater than 10 and y is equal to 2. The result of the condition is true if both the conditions are true. |
Let's see a simple program of "&&" operator.
- #include <stdio.h>
- Int main()
- {
- Int x = 4;
- Int y = 10;
- If ( (x <10) && (y>5))
- {
- Printf("Condition is true");
- }
- Else
- Printf("Condition is false");
- Return 0;
- }
Output
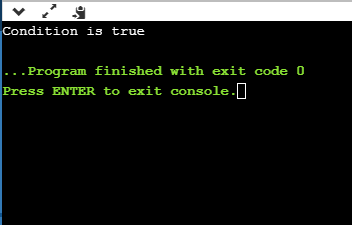
Let's see a simple example of "| |" operator
- #include <stdio.h>
- Int main()
- {
- Int x = 4;
- Int y = 9;
- If ( (x <6) || (y>10))
- {
- Printf("Condition is true");
- }
- Else
- Printf("Condition is false");
- Return 0;
- }
Output
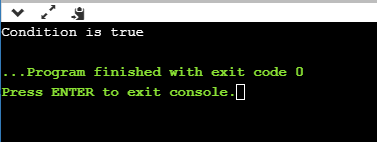
Conditional Expressions
- A conditional expression is an expression that returns 1 if the condition is true otherwise 0.
- A conditional operator is also known as a ternary operator.
The Syntax of Conditional operator
Suppose exp1, exp2 and exp3 are three expressions.
Exp1 ? exp2 : exp3
The above expression is a conditional expression which is evaluated on the basis of the value of the exp1 expression. If the condition of the expression exp1 holds true, then the final conditional expression is represented by exp2 otherwise represented by exp3.
Let's understand through a simple example.
- #include<stdio.h>
- #include<string.h>
- Int main()
- {
- Int age = 25;
- Char status;
- Status = (age>22) ? 'M': 'U';
- If(status == 'M')
- Printf("Married");
- Else
- Printf("Unmarried");
- Return 0;
- }
Output
Operator Precedence and Associativity
Operator precedence determines the grouping of terms in an expression and decides how an expression is evaluated. Certain operators have higher precedence than others; for example, the multiplication operator has a higher precedence than the addition operator.
For example, x = 7 + 3 * 2; here, x is assigned 13, not 20 because operator * has a higher precedence than +, so it first gets multiplied with 3*2 and then adds into 7.
Here, operators with the highest precedence appear at the top of the table, those with the lowest appear at the bottom. Within an expression, higher precedence operators will be evaluated first.
Category | Operator | Associativity |
Postfix | () [] -> . ++ - - | Left to right |
Unary | + - ! ~ ++ - - (type)* & sizeof | Right to left |
Multiplicative | * / % | Left to right |
Additive | + - | Left to right |
Shift | << >> | Left to right |
Relational | < <= > >= | Left to right |
Equality | == != | Left to right |
Bitwise AND | & | Left to right |
Bitwise XOR | ^ | Left to right |
Bitwise OR | | | Left to right |
Logical AND | && | Left to right |
Logical OR | || | Left to right |
Conditional | ?: | Right to left |
Assignment | = += -= *= /= %=>>= <<= &= ^= |= | Right to left |
Comma | , | Left to right |
Example Code
#include <stdio.h>
Main() {
Int a = 20;
Int b = 10;
Int c = 15;
Int d = 5;
Int e;
e = (a + b) * c / d; // ( 30 * 15 ) / 5
Printf("Value of (a + b) * c / d is : %d\n", e );
e = ((a + b) * c) / d; // (30 * 15 ) / 5
Printf("Value of ((a + b) * c) / d is : %d\n" , e );
e = (a + b) * (c / d); // (30) * (15/5)
Printf("Value of (a + b) * (c / d) is : %d\n", e );
e = a + (b * c) / d; // 20 + (150/5)
Printf("Value of a + (b * c) / d is : %d\n" , e );
Return 0;
}
Output
Value of (a + b) * c / d is : 90
Value of ((a + b) * c) / d is : 90
Value of (a + b) * (c / d) is : 90
Value of a + (b * c) / d is : 50
Converting one datatype into another is known as type casting or, type-conversion. For example, if you want to store a 'long' value into a simple integer then you can type cast 'long' to 'int'. You can convert the values from one type to another explicitly using the cast operator as follows −
(type_name) expression
Consider the following example where the cast operator causes the division of one integer variable by another to be performed as a floating-point operation −
#include <stdio.h>
Main() {
Int sum = 17, count = 5;
Double mean;
Mean = (double) sum / count;
Printf("Value of mean : %f\n", mean );
}
When the above code is compiled and executed, it produces the following result −
Value of mean : 3.400000
It should be noted here that the cast operator has precedence over division, so the value of sum is first converted to type double and finally it gets divided by count yielding a double value.
Type conversions can be implicit which is performed by the compiler automatically, or it can be specified explicitly through the use of the cast operator. It is considered good programming practice to use the cast operator whenever type conversions are necessary.
Integer Promotion
Integer promotion is the process by which values of integer type "smaller" than int or unsigned int are converted either to int or unsigned int. Consider an example of adding a character with an integer −
#include <stdio.h>
Main() {
Int i = 17;
Char c = 'c'; /* ascii value is 99 */
Int sum;
Sum = i + c;
Printf("Value of sum : %d\n", sum );
}
When the above code is compiled and executed, it produces the following result −
Value of sum : 116
Here, the value of sum is 116 because the compiler is doing integer promotion and converting the value of 'c' to ASCII before performing the actual addition operation.
Usual Arithmetic Conversion
The usual arithmetic conversions are implicitly performed to cast their values to a common type. The compiler first performs integer promotion; if the operands still have different types, then they are converted to the type that appears highest in the following hierarchy −

The usual arithmetic conversions are not performed for the assignment operators, nor for the logical operators && and ||. Let us take the following example to understand the concept −
#include <stdio.h>
Main() {
Int i = 17;
Char c = 'c'; /* ascii value is 99 */
Float sum;
Sum = i + c;
Printf("Value of sum : %f\n", sum );
}
When the above code is compiled and executed, it produces the following result −
Value of sum : 116.000000
Here, it is simple to understand that first c gets converted to integer, but as the final value is double, usual arithmetic conversion applies and the compiler converts i and c into 'float' and adds them yielding a 'float' result.
Text Books:
1. V. Rajaraman “Fundamentals of Computers” PHI publication, Fifth Edition.
2. E. Balaguruswamy,” Programming in C”, TMH Publication
3. Wei-Meng Lee” Android™ Application Development” Wiley Publication
Reference Books:
1. Pradeep K. Sinha, Priti Sinha, “Computer Fundamentals”, BPB Publication, Sixth Edition.
2. C.Xavier, Worldwide web Design with HTML, TMH Publication.
3. Yashwant Kanetkar,” Let us C”, Narosa Publication.
4. Kernighan Brian W. And Ritchie Dennis M, ‘The C Programming” Pearson Education.
5. Ed Burnette, “Hello, Android: Introducing Google's Mobile Development Platform”




