UNIT 1
Concept Of Algorithms
What is an Algorithm?
An algorithm is a process or a set of rules required to perform calculations or some other problem-solving operations especially by a computer. The formal definition of an algorithm is that it contains the finite set of instructions which are being carried in a specific order to perform the specific task. It is not the complete program or code; it is just a solution (logic) of a problem, which can be represented either as an informal description using a Flowchart or Pseudocode.
Characteristics of an Algorithm
The following are the characteristics of an algorithm:
- Input: An algorithm has some input values. We can pass 0 or some input value to an algorithm.
- Output: We will get 1 or more output at the end of an algorithm.
- Unambiguity: An algorithm should be unambiguous which means that the instructions in an algorithm should be clear and simple.
- Finiteness: An algorithm should have finiteness. Here, finiteness means that the algorithm should contain a limited number of instructions, i.e., the instructions should be countable.
- Effectiveness: An algorithm should be effective as each instruction in an algorithm affects the overall process.
- Language independent: An algorithm must be language-independent so that the instructions in an algorithm can be implemented in any of the languages with the same output.
Dataflow of an Algorithm
- Problem: A problem can be a real-world problem or any instance from the real-world problem for which we need to create a program or the set of instructions. The set of instructions is known as an algorithm.
- Algorithm: An algorithm will be designed for a problem which is a step by step procedure.
- Input: After designing an algorithm, the required and the desired inputs are provided to the algorithm.
- Processing unit: The input will be given to the processing unit, and the processing unit will produce the desired output.
- Output: The output is the outcome or the result of the program.
Why do we need Algorithms?
We need algorithms because of the following reasons:
- Scalability: It helps us to understand the scalability. When we have a big real-world problem, we need to scale it down into small-small steps to easily analyze the problem.
- Performance: The real-world is not easily broken down into smaller steps. If the problem can be easily broken into smaller steps means that the problem is feasible.
Let's understand the algorithm through a real-world example. Suppose we want to make a lemon juice, so following are the steps required to make a lemon juice:
Step 1: First, we will cut the lemon into half.
Step 2: Squeeze the lemon as much you can and take out its juice in a container.
Step 3: Add two tablespoon sugar in it.
Step 4: Stir the container until the sugar gets dissolved.
Step 5: When sugar gets dissolved, add some water and ice in it.
Step 6: Store the juice in a fridge for 5 to minutes.
Step 7: Now, it's ready to drink.
The above real-world can be directly compared to the definition of the algorithm. We cannot perform the step 3 before the step 2, we need to follow the specific order to make lemon juice. An algorithm also says that each and every instruction should be followed in a specific order to perform a specific task.
Now we will look an example of an algorithm in programming.
We will write an algorithm to add two numbers entered by the user.
The following are the steps required to add two numbers entered by the user:
Step 1: Start
Step 2: Declare three variables a, b, and sum.
Step 3: Enter the values of a and b.
Step 4: Add the values of a and b and store the result in the sum variable, i.e., sum=a+b.
Step 5: Print sum
Step 6: Stop
Factors of an Algorithm
The following are the factors that we need to consider for designing an algorithm:
- Modularity: If any problem is given and we can break that problem into small-small modules or small-small steps, which is a basic definition of an algorithm, it means that this feature has been perfectly designed for the algorithm.
- Correctness: The correctness of an algorithm is defined as when the given inputs produce the desired output, which means that the algorithm has been designed algorithm. The analysis of an algorithm has been done correctly.
- Maintainability: Here, maintainability means that the algorithm should be designed in a very simple structured way so that when we redefine the algorithm, no major change will be done in the algorithm.
- Functionality: It considers various logical steps to solve the real-world problem.
- Robustness: Robustness means that how an algorithm can clearly define our problem.
- User-friendly: If the algorithm is not user-friendly, then the designer will not be able to explain it to the programmer.
- Simplicity: If the algorithm is simple then it is easy to understand.
- Extensibility: If any other algorithm designer or programmer wants to use your algorithm then it should be extensible.
Importance of Algorithms
- Theoretical importance: When any real-world problem is given to us and we break the problem into small-small modules. To break down the problem, we should know all the theoretical aspects.
- Practical importance: As we know that theory cannot be completed without the practical implementation. So, the importance of algorithm can be considered as both theoretical and practical.
Issues of Algorithms
The following are the issues that come while designing an algorithm:
- How to design algorithms: As we know that an algorithm is a step-by-step procedure so we must follow some steps to design an algorithm.
- How to analyze algorithm efficiency
Approaches of Algorithm
The following are the approaches used after considering both the theoretical and practical importance of designing an algorithm:
- Brute force algorithm: The general logic structure is applied to design an algorithm. It is also known as an exhaustive search algorithm that searches all the possibilities to provide the required solution. Such algorithms are of two types:
- Optimizing: Finding all the solutions of a problem and then take out the best solution or if the value of the best solution is known then it will terminate if the best solution is known.
- Sacrificing: As soon as the best solution is found, then it will stop.
- Divide and conquer: It is a very implementation of an algorithm. It allows you to design an algorithm in a step-by-step variation. It breaks down the algorithm to solve the problem in different methods. It allows you to break down the problem into different methods, and valid output is produced for the valid input. This valid output is passed to some other function.
- Greedy algorithm: It is an algorithm paradigm that makes an optimal choice on each iteration with the hope of getting the best solution. It is easy to implement and has a faster execution time. But, there are very rare cases in which it provides the optimal solution.
- Dynamic programming: It makes the algorithm more efficient by storing the intermediate results. It follows five different steps to find the optimal solution for the problem:
- It breaks down the problem into a sub problem to find the optimal solution.
- After breaking down the problem, it finds the optimal solution out of these sub problems.
- Stores the result of the sub problems is known as memorization.
- Reuse the result so that it cannot be recomputed for the same sub problems.
- Finally, it computes the result of the complex program.
- Branch and Bound Algorithm: The branch and bound algorithm can be applied to only integer programming problems. This approach divides all the sets of feasible solutions into smaller subsets. These subsets are further evaluated to find the best solution.
- Randomized Algorithm: As we have seen in a regular algorithm, we have predefined input and required output. Those algorithms that have some defined set of inputs and required output, and follow some described steps are known as deterministic algorithms. What happens that when the random variable is introduced in the randomized algorithm?. In a randomized algorithm, some random bits are introduced by the algorithm and added in the input to produce the output, which is random in nature. Randomized algorithms are simpler and efficient than the deterministic algorithm.
- Backtracking: Backtracking is an algorithmic technique that solves the problem recursively and removes the solution if it does not satisfy the constraints of a problem.
The major categories of algorithms are given below:
- Sort: Algorithm developed for sorting the items in a certain order.
- Search: Algorithm developed for searching the items inside a data structure.
- Delete: Algorithm developed for deleting the existing element from the data structure.
- Insert: Algorithm developed for inserting an item inside a data structure.
- Update: Algorithm developed for updating the existing element inside a data structure.
Algorithm Analysis
The algorithm can be analyzed in two levels, i.e., first is before creating the algorithm, and second is after creating the algorithm. The following are the two analysis of an algorithm:
- Priori Analysis: Here, priori analysis is the theoretical analysis of an algorithm which is done before implementing the algorithm. Various factors can be considered before implementing the algorithm like processor speed, which has no effect on the implementation part.
- Posterior Analysis: Here, posterior analysis is a practical analysis of an algorithm. The practical analysis is achieved by implementing the algorithm using any programming language. This analysis basically evaluate that how much running time and space taken by the algorithm.
Algorithm Complexity
The performance of the algorithm can be measured in two factors:
- Time complexity: The time complexity of an algorithm is the amount of time required to complete the execution. The time complexity of an algorithm is denoted by the big O notation. Here, big O notation is the asymptotic notation to represent the time complexity. The time complexity is mainly calculated by counting the number of steps to finish the execution. Let's understand the time complexity through an example.
- Sum=0;
- // Suppose we have to calculate the sum of n numbers.
- For i=1 to n
- Sum=sum+i;
- // when the loop ends then sum holds the sum of the n numbers
- Return sum;
In the above code, the time complexity of the loop statement will be atleast n, and if the value of n increases, then the time complexity also increases. While the complexity of the code, i.e., return sum will be constant as its value is not dependent on the value of n and will provide the result in one step only. We generally consider the worst-time complexity as it is the maximum time taken for any given input size.
- Space complexity: An algorithm's space complexity is the amount of space required to solve a problem and produce an output. Similar to the time complexity, space complexity is also expressed in big O notation.
For an algorithm, the space is required for the following purposes:
- To store program instructions
- To store constant values
- To store variable values
- To track the function calls, jumping statements, etc.
Auxiliary space: The extra space required by the algorithm, excluding the input size, is known as an auxiliary space. The space complexity considers both the spaces, i.e., auxiliary space, and space used by the input.
So,
Space complexity = Auxiliary space + Input size.
Types of Algorithms
The following are the types of algorithm:
- Search Algorithm
- Sort Algorithm
Search Algorithm
On each day, we search for something in our day to day life. Similarly, with the case of computer, huge data is stored in a computer that whenever the user asks for any data then the computer searches for that data in the memory and provides that data to the user. There are mainly two techniques available to search the data in an array:
- Linear search
- Binary search
Linear Search
Linear search is a very simple algorithm that starts searching for an element or a value from the beginning of an array until the required element is not found. It compares the element to be searched with all the elements in an array, if the match is found, then it returns the index of the element else it returns -1. This algorithm can be implemented on the unsorted list.
Binary Search
A Binary algorithm is the simplest algorithm that searches the element very quickly. It is used to search the element from the sorted list. The elements must be stored in sequential order or the sorted manner to implement the binary algorithm. Binary search cannot be implemented if the elements are stored in a random manner. It is used to find the middle element of the list.
Sorting Algorithms
Sorting algorithms are used to rearrange the elements in an array or a given data structure either in an ascending or descending order. The comparison operator decides the new order of the elements.
Why do we need a sorting algorithm?
- An efficient sorting algorithm is required for optimizing the efficiency of other algorithms like binary search algorithm as a binary search algorithm requires an array to be sorted in a particular order, mainly in ascending order.
- It produces information in a sorted order, which is a human-readable format.
- Searching a particular element in a sorted list is faster than the unsorted list.
Flowchart is a diagrammatic representation of sequence of logical steps of a program. Flowcharts use simple geometric shapes to depict processes and arrows to show relationships and process/data flow.
Flowchart Symbols
Here is a chart for some of the common symbols used in drawing flowcharts.
Symbol | Symbol Name | Purpose |
 | Start/Stop | Used at the beginning and end of the algorithm to show start and end of the program. |
 | Process | Indicates processes like mathematical operations. |
 | Input/ Output | Used for denoting program inputs and outputs. |
 | Decision | Stands for decision statements in a program, where answer is usually Yes or No. |
 | Arrow | Shows relationships between different shapes. |
 | On-page Connector | Connects two or more parts of a flowchart, which are on the same page. |
 | Off-page Connector | Connects two parts of a flowchart which are spread over different pages. |
Guidelines for Developing Flowcharts
These are some points to keep in mind while developing a flowchart −
- Flowchart can have only one start and one stop symbol
- On-page connectors are referenced using numbers
- Off-page connectors are referenced using alphabets
- General flow of processes is top to bottom or left to right
- Arrows should not cross each other
Example Flowcharts
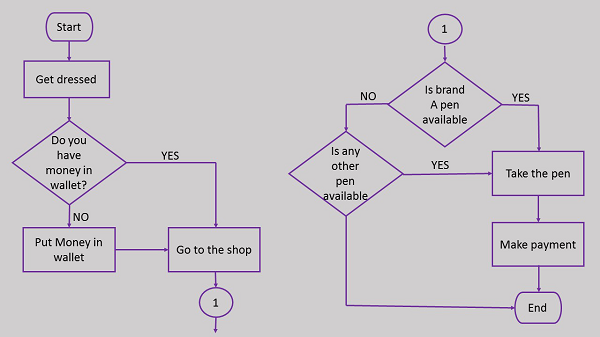
Here is the flowchart for going to the market to purchase a pen.
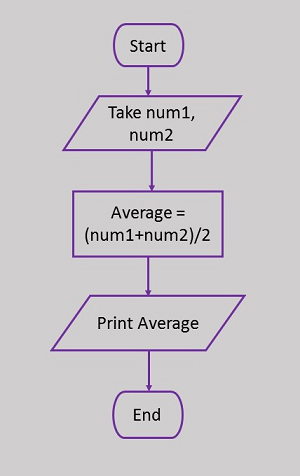
Here is a flowchart to calculate the average of two numbers.
Introduction to Compiler
- A compiler is a translator that converts the high-level language into the machine language.
- High-level language is written by a developer and machine language can be understood by the processor.
- Compiler is used to show errors to the programmer.
- The main purpose of compiler is to change the code written in one language without changing the meaning of the program.
- When you execute a program which is written in HLL programming language then it executes into two parts.
- In the first part, the source program compiled and translated into the object program (low level language).
- In the second part, object program translated into the target program through the assembler.
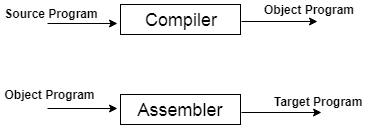
Fig: Execution process of source program in Compiler
Compiler Phases
The compilation process contains the sequence of various phases. Each phase takes source program in one representation and produces output in another representation. Each phase takes input from its previous stage.
There are the various phases of compiler:
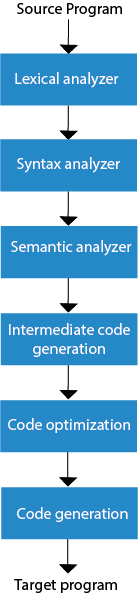
Fig: phases of compiler
Lexical Analysis:
Lexical analyzer phase is the first phase of compilation process. It takes source code as input. It reads the source program one character at a time and converts it into meaningful lexemes. Lexical analyzer represents these lexemes in the form of tokens.
Syntax Analysis
Syntax analysis is the second phase of compilation process. It takes tokens as input and generates a parse tree as output. In syntax analysis phase, the parser checks that the expression made by the tokens is syntactically correct or not.
Semantic Analysis
Semantic analysis is the third phase of compilation process. It checks whether the parse tree follows the rules of language. Semantic analyzer keeps track of identifiers, their types and expressions. The output of semantic analysis phase is the annotated tree syntax.
Intermediate Code Generation
In the intermediate code generation, compiler generates the source code into the intermediate code. Intermediate code is generated between the high-level language and the machine language. The intermediate code should be generated in such a way that you can easily translate it into the target machine code.
Code Optimization
Code optimization is an optional phase. It is used to improve the intermediate code so that the output of the program could run faster and take less space. It removes the unnecessary lines of the code and arranges the sequence of statements in order to speed up the program execution.
Code Generation
Code generation is the final stage of the compilation process. It takes the optimized intermediate code as input and maps it to the target machine language. Code generator translates the intermediate code into the machine code of the specified computer.
Example:
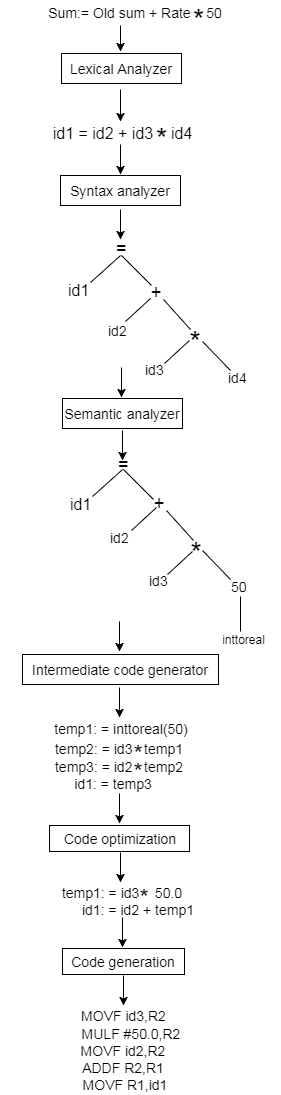
Compiler Passes
Pass is a complete traversal of the source program. Compiler has two passes to traverse the source program.
Multi-pass Compiler
- Multi pass compiler is used to process the source code of a program several times.
- In the first pass, compiler can read the source program, scan it, extract the tokens and store the result in an output file.
- In the second pass, compiler can read the output file produced by first pass, build the syntactic tree and perform the syntactical analysis. The output of this phase is a file that contains the syntactical tree.
- In the third pass, compiler can read the output file produced by second pass and check that the tree follows the rules of language or not. The output of semantic analysis phase is the annotated tree syntax.
- This pass is going on, until the target output is produced.
One-pass Compiler
- One-pass compiler is used to traverse the program only once. The one-pass compiler passes only once through the parts of each compilation unit. It translates each part into its final machine code.
- In the one pass compiler, when the line source is processed, it is scanned and the token is extracted.
- Then the syntax of each line is analyzed and the tree structure is build. After the semantic part, the code is generated.
- The same process is repeated for each line of code until the entire program is compiled.
Computers are a balanced mix of software and hardware. Hardware is just a piece of mechanical device and its functions are being controlled by a compatible software. Hardware understands instructions in the form of electronic charge, which is the counterpart of binary language in software programming. Binary language has only two alphabets, 0 and 1. To instruct, the hardware codes must be written in binary format, which is simply a series of 1s and 0s. It would be a difficult and cumbersome task for computer programmers to write such codes, which is why we have compilers to write such codes.
Language Processing System
We have learnt that any computer system is made of hardware and software. The hardware understands a language, which humans cannot understand. So we write programs in high-level language, which is easier for us to understand and remember. These programs are then fed into a series of tools and OS components to get the desired code that can be used by the machine. This is known as Language Processing System.
Language Processing System
The high-level language is converted into binary language in various phases. A compiler is a program that converts high-level language to assembly language. Similarly, an assembler is a program that converts the assembly language to machine-level language.
Let us first understand how a program, using C compiler, is executed on a host machine.
User writes a program in C language (high-level language). The C compiler, compiles the program and translates it to assembly program (low-level language). An assembler then translates the assembly program into machine code (object). A linker tool is used to link all the parts of the program together for execution (executable machine code). A loader loads all of them into memory and then the program is executed.
Before diving straight into the concepts of compilers, we should understand a few other tools that work closely with compilers.
Preprocessor
A preprocessor, generally considered as a part of compiler, is a tool that produces input for compilers. It deals with macro-processing, augmentation; file inclusion, language extension, etc.
Interpreter
An interpreter, like a compiler, translates high-level language into low-level machine language. The difference lies in the way they read the source code or input. A compiler reads the whole source code at once, creates tokens, checks semantics, generates intermediate code, executes the whole program and may involve many passes. In contrast, an interpreter reads a statement from the input, converts it to an intermediate code, executes it, then takes the next statement in sequence. If an error occurs, an interpreter stops execution and reports it. Whereas a compiler reads the whole program even if it encounters several errors.
Assembler
An assembler translates assembly language programs into machine code. The output of an assembler is called an object file, which contains a combination of machine instructions as well as the data required to place these instructions in memory.
Linker
Linker is a computer program that links and merges various object files together in order to make an executable file. All these files might have been compiled by separate assemblers. The major task of a linker is to search and locate referenced module/routines in a program and to determine the memory location where these codes will be loaded, making the program instruction to have absolute references.
Loader
Loader is a part of operating system and is responsible for loading executable files into memory and executes them. It calculates the size of a program (instructions and data) and creates memory space for it. It initializes various registers to initiate execution.
Cross-compiler
A compiler that runs on platform (A) and is capable of generating executable code for platform (B) is called a cross-compiler.
Source-to-source Compiler
A compiler that takes the source code of one programming language and translates it into the source code of another programming language is called a source-to-source compiler.
Before we study the basic building blocks of the C programming language, let us look at a bare minimum C program structure so that we can take it as a reference in the upcoming chapters.
Hello World Example
A C program basically consists of the following parts −
- Preprocessor Commands
- Functions
- Variables
- Statements & Expressions
- Comments
Let us look at a simple code that would print the words "Hello World" −
#include<stdio.h>
Int main(){
/* my first program in C */
Printf("Hello, World! \n");
Return0;
}
Let us take a look at the various parts of the above program −
- The first line of the program #include<stdio.h> is a preprocessor command, which tells a C compiler to include stdio.h file before going to actual compilation.
- The next line int main() is the main function where the program execution begins.
- The next line /*...*/ will be ignored by the compiler and it has been put to add additional comments in the program. So such lines are called comments in the program.
- The next line printf(...) is another function available in C which causes the message "Hello, World!" to be displayed on the screen.
- The next line return 0; terminates the main() function and returns the value 0.
Compile and Execute C Program
Let us see how to save the source code in a file, and how to compile and run it. Following are the simple steps −
- Open a text editor and add the above-mentioned code.
- Save the file as hello.c
- Open a command prompt and go to the directory where you have saved the file.
- Type gcchello.c and press enter to compile your code.
- If there are no errors in your code, the command prompt will take you to the next line and would generate a.out executable file.
- Now, type a.out to execute your program.
- You will see the output "Hello World" printed on the screen.
$ gcchello.c
$ ./a.out
Hello, World!
Make sure the gcc compiler is in your path and that you are running it in the directory containing the source file hello.c.
The compilation and execution process of C can be divided in to multiple steps:
- Preprocessing - Using a Preprocessor program to convert C source code in expanded source code. "#includes" and "#defines" statements will be processed and replaced actually source codes in this step.
- Compilation - Using a Compiler program to convert C expanded source to assembly source code.
- Assembly - Using a Assembler program to convert assembly source code to object code.
- Linking - Using a Linker program to convert object code to executable code. Multiple units of object codes are linked to together in this step.
- Loading - Using a Loader program to load the executable code into CPU for execution.
Here is a simple table showing input and output of each step in the compilation and execution process:
Input Program Output
Source code >Preprocessor> expanded source code
Expanded source code > Compiler > assembly source code
Assembly code > Assembler > object code
Object code > Linker > executable code
Executable code > Loader > execution
Here are examples of commonly used programs for different compilation and execution steps on a Linux system:
- "cpphello.c -o hello.i" - Preprocessorpreprocessinghello.c and saving output to hello.i.
- "cc1 hello.i -o hello.s" - Compiler compiling hello.i and saving output to hello.s.
- "ashello.s -o hello.o" - Assembler assembling hello.s and saving output to hello.o.
- "ldhello.o -o hello" - Linker linking hello.o and saving output to hello.
- "load hello" - Loader loading hello and running hello.
Text Books:
[T1] Herbert Schildt, ―C: The Complete Reference‖, OsbourneMcgraw Hill, 4th Edition, 2002.
[T2] Forouzan Behrouz A. ―Computer Science: A Structured Programming Approach Using C, Cengage Learning 2/e
Reference Books:
[R1] Kernighan & Ritchie, ―C Programming Language‖, The (Ansi C version), PHI, 2/e
[R2] K.R Venugopal, ―Mastering C ‖, TMH
[R3] R.S. Salaria "Application Programming in C " Khanna Publishers4/e
[R4] YashwantKanetkar― Test your C Skills ‖ , BPB Publications
[R5] http://www.codeblocks.org/
[R6] http://gcc.gnu.org/
[R7] Programming in ANSI C, E. Balagurusamy; Mc Graw Hill, 6th Edition.




