Unit 4
Strings
Strings are amongst the most popular types in Python. We can create them simply by enclosing characters in quotes. Python treats single quotes the same as double quotes. Creating strings is as simple as assigning a value to a variable. For example −
Var1 = 'Hello World!'
Var2 = "Python Programming"
Accessing Values in Strings
Python does not support a character type; these are treated as strings of length one, thus also considered a substring.
To access substrings, use the square brackets for slicing along with the index or indices to obtain your substring. For example −
#!/usr/bin/python
Var1 = 'Hello World!'
Var2 = "Python Programming"
Print "var1[0]: ", var1[0]
Print "var2[1:5]: ", var2[1:5]
When the above code is executed, it produces the following result −
Var1[0]: H
Var2[1:5]: ytho
Updating Strings
You can "update" an existing string by (re)assigning a variable to another string. The new value can be related to its previous value or to a completely different string altogether. For example −
#!/usr/bin/python
Var1 = 'Hello World!'
Print "Updated String :- ", var1[:6] + 'Python'
When the above code is executed, it produces the following result −
Updated String :- Hello Python
Escape Characters
Following table is a list of escape or non-printable characters that can be represented with backslash notation.
An escape character gets interpreted; in a single quoted as well as double quoted strings.
Backslash notation | Hexadecimal character | Description |
\a | 0x07 | Bell or alert |
\b | 0x08 | Backspace |
\cx |
| Control-x |
\C-x |
| Control-x |
\e | 0x1b | Escape |
\f | 0x0c | Formfeed |
\M-\C-x |
| Meta-Control-x |
\n | 0x0a | Newline |
\nnn |
| Octal notation, where n is in the range 0.7 |
\r | 0x0d | Carriage return |
\s | 0x20 | Space |
\t | 0x09 | Tab |
\v | 0x0b | Vertical tab |
\x |
| Character x |
\xnn |
| Hexadecimal notation, where n is in the range 0.9, a.f, or A.F |
String Special Operators
Assume string variable a holds 'Hello' and variable b holds 'Python', then −
Operator | Description | Example |
+ | Concatenation - Adds values on either side of the operator | a + b will give HelloPython |
* | Repetition - Creates new strings, concatenating multiple copies of the same string | a*2 will give -HelloHello |
[] | Slice - Gives the character from the given index | a[1] will give e |
[ : ] | Range Slice - Gives the characters from the given range | a[1:4] will give ell |
In | Membership - Returns true if a character exists in the given string | H in a will give 1 |
Not in | Membership - Returns true if a character does not exist in the given string | M not in a will give 1 |
r/R | Raw String - Suppresses actual meaning of Escape characters. The syntax for raw strings is exactly the same as for normal strings with the exception of the raw string operator, the letter "r," which precedes the quotation marks. The "r" can be lowercase (r) or uppercase (R) and must be placed immediately preceding the first quote mark. | Print r'\n' prints \n and print R'\n'prints \n |
% | Format - Performs String formatting | See at next section |
String Formatting Operator
One of Python's coolest features is the string format operator %. This operator is unique to strings and makes up for the pack of having functions from C's printf() family. Following is a simple example −
#!/usr/bin/python
Print "My name is %s and weight is %d kg!" % ('Zara', 21)
When the above code is executed, it produces the following result −
My name is Zara and weight is 21 kg!
Here is the list of complete set of symbols which can be used along with % −
Format Symbol | Conversion |
%c | Character |
%s | String conversion via str() prior to formatting |
%i | Signed decimal integer |
%d | Signed decimal integer |
%u | Unsigned decimal integer |
%o | Octal integer |
%x | Hexadecimal integer (lowercase letters) |
%X | Hexadecimal integer (UPPERcase letters) |
%e | Exponential notation (with lowercase 'e') |
%E | Exponential notation (with UPPERcase 'E') |
%f | Floating point real number |
%g | The shorter of %f and %e |
%G | The shorter of %f and %E |
Other supported symbols and functionality are listed in the following table −
Symbol | Functionality |
* | Argument specifies width or precision |
- | Left justification |
+ | Display the sign |
<sp> | Leave a blank space before a positive number |
# | Add the octal leading zero ( '0' ) or hexadecimal leading '0x' or '0X', depending on whether 'x' or 'X' were used. |
0 | Pad from left with zeros (instead of spaces) |
% | '%%' leaves you with a single literal '%' |
(var) | Mapping variable (dictionary arguments) |
m.n. | m is the minimum total width and n is the number of digits to display after the decimal point (if appl.) |
Triple Quotes
Python's triple quotes comes to the rescue by allowing strings to span multiple lines, including verbatim NEWLINEs, TABs, and any other special characters.
The syntax for triple quotes consists of three consecutive single or double quotes.
#!/usr/bin/python
Para_str = """this is a long string that is made up of
Several lines and non-printable characters such as
TAB ( \t ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
This within the brackets [ \n ], or just a NEWLINE within
The variable assignment will also show up.
"""
Print para_str
When the above code is executed, it produces the following result. Note how every single special character has been converted to its printed form, right down to the last NEWLINE at the end of the string between the "up." and closing triple quotes. Also note that NEWLINEs occur either with an explicit carriage return at the end of a line or its escape code (\n) −
This is a long string that is made up of
Several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
This within the brackets [
], or just a NEWLINE within
The variable assignment will also show up.
Raw strings do not treat the backslash as a special character at all. Every character you put into a raw string stays the way you wrote it −
#!/usr/bin/python
Print 'C:\\nowhere'
When the above code is executed, it produces the following result −
C:\nowhere
Now let's make use of raw string. We would put expression in r'expression' as follows −
#!/usr/bin/python
Print r'C:\\nowhere'
When the above code is executed, it produces the following result −
C:\\nowhere
Unicode String
Normal strings in Python are stored internally as 8-bit ASCII, while Unicode strings are stored as 16-bit Unicode. This allows for a more varied set of characters, including special characters from most languages in the world. I'll restrict my treatment of Unicode strings to the following −
#!/usr/bin/python
Print u'Hello, world!'
When the above code is executed, it produces the following result −
Hello, world!
As you can see, Unicode strings use the prefix u, just as raw strings use the prefix r.
Built-in String Methods
Python includes the following built-in methods to manipulate strings −
Sr.No. | Methods with Description |
1 | Capitalize() Capitalizes first letter of string |
2 | Center(width, fillchar) Returns a space-padded string with the original string centered to a total of width columns.
|
3 | Count(str, beg= 0,end=len(string)) Counts how many times str occurs in string or in a substring of string if starting index beg and ending index end are given.
|
4 | Decode(encoding='UTF-8',errors='strict') Decodes the string using the codec registered for encoding. Encoding defaults to the default string encoding.
|
5 | Encode(encoding='UTF-8',errors='strict') Returns encoded string version of string; on error, default is to raise a ValueError unless errors is given with 'ignore' or 'replace'.
|
6 | Endswith(suffix, beg=0, end=len(string)) Determines if string or a substring of string (if starting index beg and ending index end are given) ends with suffix; returns true if so and false otherwise.
|
7 | Expandtabs(tabsize=8) Expands tabs in string to multiple spaces; defaults to 8 spaces per tab if tabsize not provided.
|
8 | Find(str, beg=0 end=len(string)) Determine if str occurs in string or in a substring of string if starting index beg and ending index end are given returns index if found and -1 otherwise.
|
9 | Index(str, beg=0, end=len(string)) Same as find(), but raises an exception if str not found. |
10 | Isalnum() Returns true if string has at least 1 character and all characters are alphanumeric and false otherwise. |
11 | Isalpha() Returns true if string has at least 1 character and all characters are alphabetic and false otherwise. |
12 | Isdigit() Returns true if string contains only digits and false otherwise. |
13 | Islower() Returns true if string has at least 1 cased character and all cased characters are in lowercase and false otherwise. |
14 | Isnumeric() Returns true if a unicode string contains only numeric characters and false otherwise. |
15 | Isspace() Returns true if string contains only whitespace characters and false otherwise. |
16 | Istitle() Returns true if string is properly "titlecased" and false otherwise. |
17 | Isupper() Returns true if string has at least one cased character and all cased characters are in uppercase and false otherwise. |
18 | Join(seq) Merges (concatenates) the string representations of elements in sequence seq into a string, with separator string. |
19 | Len(string) Returns the length of the string |
20 | Ljust(width[, fillchar]) Returns a space-padded string with the original string left-justified to a total of width columns. |
21 | Lower() Converts all uppercase letters in string to lowercase. |
22 | Lstrip() Removes all leading whitespace in string. |
23 | Maketrans() Returns a translation table to be used in translate function. |
24 | Max(str) Returns the max alphabetical character from the string str. |
25 | Min(str) Returns the min alphabetical character from the string str. |
26 | Replace(old, new [, max]) Replaces all occurrences of old in string with new or at most max occurrences if max given. |
27 | Rfind(str, beg=0,end=len(string)) Same as find(), but search backwards in string. |
28 | Rindex( str, beg=0, end=len(string)) Same as index(), but search backwards in string. |
29 | Rjust(width,[, fillchar]) Returns a space-padded string with the original string right-justified to a total of width columns. |
30 | Rstrip() Removes all trailing whitespace of string. |
31 | Split(str="", num=string.count(str)) Splits string according to delimiter str (space if not provided) and returns list of substrings; split into at most num substrings if given. |
32 | Splitlines( num=string.count('\n')) Splits string at all (or num) NEWLINEs and returns a list of each line with NEWLINEs removed. |
33 | Startswith(str, beg=0,end=len(string)) Determines if string or a substring of string (if starting index beg and ending index end are given) starts with substring str; returns true if so and false otherwise. |
34 | Strip([chars]) Performs both lstrip() and rstrip() on string. |
35 | Swapcase() Inverts case for all letters in string. |
36 | Title() Returns "titlecased" version of string, that is, all words begin with uppercase and the rest are lowercase. |
37 | Translate(table, deletechars="") Translates string according to translation table str(256 chars), removing those in the del string. |
38 | Upper() Converts lowercase letters in string to uppercase. |
39 | Zfill (width) Returns original string leftpadded with zeros to a total of width characters; intended for numbers, zfill() retains any sign given (less one zero). |
40 | Isdecimal() Returns true if a unicode string contains only decimal characters and false otherwise. |
Introduction
Models that process natural language often handle different languages with different character sets. Unicode is a standard encoding system that is used to represent character from almost all languages. Each character is encoded using a unique integer code point between 0 and 0x10FFFF. A Unicode string is a sequence of zero or more code points.
How to represent Unicode strings in TensorFlow and manipulate them using Unicode equivalents of standard string ops. It separates Unicode strings into tokens based on script detection.
Import tensorflow as tf
The tf.string data type
The basic TensorFlow tf.stringdtype allows you to build tensors of byte strings. Unicode strings are utf-8 encoded by default.
Tf.constant(u"Thanks 😊")
<tf.Tensor: shape=(), dtype=string, numpy=b'Thanks \xf0\x9f\x98\x8a'>
A tf.string tensor can hold byte strings of varying lengths because the byte strings are treated as atomic units. The string length is not included in the tensor dimensions.
Tf.constant([u"You're", u"welcome!"]).shape
TensorShape([2])
Note: When using python to construct strings, the handling of unicode differs betweeen v2 and v3. In v2, unicode strings are indicated by the "u" prefix, as above. In v3, strings are unicode-encoded by default.
Representing Unicode
There are two standard ways to represent a Unicode string in TensorFlow:
- String scalar — where the sequence of code points is encoded using a known character encoding.int32 vector — where each position contains a single code point.
For example, the following three values all represent the Unicode string "语言处理" (which means "language processing" in Chinese):
# Unicode string, represented as a UTF-8 encoded string scalar.
text_utf8 =tf.constant(u"语言处理")
text_utf8
<tf.Tensor: shape=(), dtype=string, numpy=b'\xe8\xaf\xad\xe8\xa8\x80\xe5\xa4\x84\xe7\x90\x86'>
# Unicode string, represented as a UTF-16-BE encoded string scalar.
text_utf16be =tf.constant(u"语言处理".encode("UTF-16-BE"))
text_utf16be
<tf.Tensor: shape=(), dtype=string, numpy=b'\x8b\xed\x8a\x00Y\x04t\x06'>
# Unicode string, represented as a vector of Unicode code points.
text_chars =tf.constant([ord(char)forcharin u"语言处理"])
text_chars
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([35821, 35328, 22788, 29702], dtype=int32)>
Converting between representations
TensorFlow provides operations to convert between these different representations:
- Tf.strings.unicode_decode : Converts an encoded string scalar to a vector of code points.
- Tf.strings.unicode_encode : Converts a vector of code points to an encoded string scalar.
- Tf.strings.unicode_transcode : Converts an encoded string scalar to a different encoding.
Tf.strings.unicode_decode(text_utf8,
input_encoding='UTF-8')
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([35821, 35328, 22788, 29702], dtype=int32)>
Tf.strings.unicode_encode(text_chars,
output_encoding='UTF-8')
<tf.Tensor: shape=(), dtype=string, numpy=b'\xe8\xaf\xad\xe8\xa8\x80\xe5\xa4\x84\xe7\x90\x86'>
Tf.strings.unicode_transcode(text_utf8,
input_encoding='UTF8',
output_encoding='UTF-16-BE')
<tf.Tensor: shape=(), dtype=string, numpy=b'\x8b\xed\x8a\x00Y\x04t\x06'>
Batch dimensions
When decoding multiple strings, the number of characters in each string may not be equal. The return result is atf.RaggedTensor , where the length of the innermost dimension varies depending on the number of characters in each string:
# A batch of Unicode strings, each represented as a UTF8-encoded string.
batch_utf8 =[s.encode('UTF-8')for s in
[u'hÃllo', u'What is the weather tomorrow', u'Göödnight', u'😊']]
batch_chars_ragged = tf.strings.unicode_decode(batch_utf8,
input_encoding='UTF-8')
for sentence_chars in batch_chars_ragged.to_list():
print(sentence_chars)
[104, 195, 108, 108, 111]
[87, 104, 97, 116, 32, 105, 115, 32, 116, 104, 101, 32, 119, 101, 97, 116, 104, 101, 114, 32, 116, 111, 109, 111, 114, 114, 111, 119]
[71, 246, 246, 100, 110, 105, 103, 104, 116]
[128522]
You can use this tf.RaggedTensor directly, or convert it to a dense tf.Tensor with padding or a tf.SparseTensor using the methods tf.RaggedTensor.to_tensor and tf.RaggedTensor.to_sparse.
Batch_chars_padded = batch_chars_ragged.to_tensor(default_value=-1)
print(batch_chars_padded.numpy())
[[ 104 195 108 108 111 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1]
[ 87 104 97 116 32 105 115 32 116 104
101 32 119 101 97 116 104 101 114 32
116 111 109 111 114 114 111 119]
[ 71 246 246 100 110 105 103 104 116 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1]
[128522 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1]]
Batch_chars_sparse = batch_chars_ragged.to_sparse()
When encoding multiple strings with the same lengths, a tf.Tensor may be used as input:
Tf.strings.unicode_encode([[99,97,116],[100,111,103],[99,111,119]],
output_encoding='UTF-8')
<tf.Tensor: shape=(3,), dtype=string, numpy=array([b'cat', b'dog', b'cow'], dtype=object)>
When encoding multiple strings with varying length, a tf.RaggedTensor should be used as input:
Tf.strings.unicode_encode(batch_chars_ragged, output_encoding='UTF-8')
<tf.Tensor: shape=(4,), dtype=string, numpy=
Array([b'h\xc3\x83llo', b'What is the weather tomorrow',
b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
If you have a tensor with multiple strings in padded or sparse format, then convert it to a tf.RaggedTensor before calling unicode_encode:
Tf.strings.unicode_encode(
tf.RaggedTensor.from_sparse(batch_chars_sparse),
output_encoding='UTF-8')
<tf.Tensor: shape=(4,), dtype=string, numpy=
Array([b'h\xc3\x83llo', b'What is the weather tomorrow',
b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
Tf.strings.unicode_encode(
tf.RaggedTensor.from_tensor(batch_chars_padded, padding=-1),
output_encoding='UTF-8')
<tf.Tensor: shape=(4,), dtype=string, numpy=
Array([b'h\xc3\x83llo', b'What is the weather tomorrow',
b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
Unicode operations
Character length
The tf.strings.length operation has a parameter unit, which indicates how lengths should be computed. Unit defaults to "BYTE", but it can be set to other values, such as "UTF8_CHAR" or "UTF16_CHAR", to determine the number of Unicode codepoints in each encoded string.
# Note that the final character takes up 4 bytes in UTF8.
thanks = u'Thanks 😊'.encode('UTF-8')
num_bytes = tf.strings.length(thanks).numpy()
num_chars = tf.strings.length(thanks, unit='UTF8_CHAR').numpy()
print('{} bytes; {} UTF-8 characters'.format(num_bytes, num_chars))
11 bytes; 8 UTF-8 characters
Character substrings
Similarly, the tf.strings.substr operation accepts the "unit" parameter, and uses it to determine what kind of offsets the "pos" and "len" paremeters contain.
# default: unit='BYTE'. With len=1, we return a single byte.
tf.strings.substr(thanks, pos=7, len=1).numpy()
b'\xf0'
# Specifying unit='UTF8_CHAR', we return a single character, which in this case
# is 4 bytes.
print(tf.strings.substr(thanks, pos=7, len=1, unit='UTF8_CHAR').numpy())
b'\xf0\x9f\x98\x8a'
Split Unicode strings
The tf.strings.unicode_split operation splits unicode strings into substrings of individual characters:
Tf.strings.unicode_split(thanks,'UTF-8').numpy()
Array([b'T', b'h', b'a', b'n', b'k', b's', b' ', b'\xf0\x9f\x98\x8a'],
Dtype=object)
Byte offsets for characters
To align the character tensor generated by tf.strings.unicode_decode with the original string, it's useful to know the offset for where each character begins. The method tf.strings.unicode_decode_with_offsets is similar to unicode_decode, except that it returns a second tensor containing the start offset of each character.
Codepoints, offsets = tf.strings.unicode_decode_with_offsets(u"🎈🎉🎊",'UTF-8')
for(codepoint, offset)in zip(codepoints.numpy(), offsets.numpy()):
print("At byte offset {}: codepoint {}".format(offset, codepoint))
At byte offset 0: codepoint 127880
At byte offset 4: codepoint 127881
At byte offset 8: codepoint 127882
Unicode scripts
Each Unicode code point belongs to a single collection of code points known as a script . A character's script is helpful in determining which language the character might be in. For example, knowing that 'Б' is in Cyrillic script indicates that modern text containing that character is likely from a Slavic language such as Russian or Ukrainian.
TensorFlow provides the tf.strings.unicode_script operation to determine which script a given codepoint uses. The script codes are int32 values corresponding to International Components for Unicode (ICU) UScriptCode values.
Uscript= tf.strings.unicode_script([33464,1041]) # ['芸', 'Б']
print(uscript.numpy()) # [17, 8] == [USCRIPT_HAN, USCRIPT_CYRILLIC]
[17 8]
The tf.strings.unicode_script operation can also be applied to multidimensional tf.Tensors or tf.RaggedTensors of codepoints:
Print(tf.strings.unicode_script(batch_chars_ragged))
<tf.RaggedTensor [[25, 25, 25, 25, 25], [25, 25, 25, 25, 0, 25, 25, 0, 25, 25, 25, 0, 25, 25, 25, 25, 25, 25, 25, 0, 25, 25, 25, 25, 25, 25, 25, 25], [25, 25, 25, 25, 25, 25, 25, 25, 25], [0]]>
Example: Simple segmentation
Segmentation is the task of splitting text into word-like units. This is often easy when space characters are used to separate words, but some languages (like Chinese and Japanese) do not use spaces, and some languages (like German) contain long compounds that must be split in order to analyze their meaning. In web text, different languages and scripts are frequently mixed together, as in "NY株価" (New York Stock Exchange).
We can perform very rough segmentation (without implementing any ML models) by using changes in script to approximate word boundaries. This will work for strings like the "NY株価" example above. It will also work for most languages that use spaces, as the space characters of various scripts are all classified as USCRIPT_COMMON, a special script code that differs from that of any actual text.
# dtype: string; shape: [num_sentences]
#
# The sentences to process. Edit this line to try out different inputs!
sentence_texts =[u'Hello, world.', u'世界こんにちは']
First, we decode the sentences into character codepoints, and find the script identifeir for each character.
# dtype: int32; shape: [num_sentences, (num_chars_per_sentence)]
#
# sentence_char_codepoint[i, j] is the codepoint for the j'th character in
# the i'th sentence.
sentence_char_codepoint = tf.strings.unicode_decode(sentence_texts,'UTF-8')
print(sentence_char_codepoint)
# dtype: int32; shape: [num_sentences, (num_chars_per_sentence)]
#
# sentence_char_scripts[i, j] is the unicode script of the j'th character in
# the i'th sentence.
sentence_char_script = tf.strings.unicode_script(sentence_char_codepoint)
print(sentence_char_script)
<tf.RaggedTensor [[72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 46], [19990, 30028, 12371, 12435, 12395, 12385, 12399]]>
<tf.RaggedTensor [[25, 25, 25, 25, 25, 0, 0, 25, 25, 25, 25, 25, 0], [17, 17, 20, 20, 20, 20, 20]]>
Next, we use those script identifiers to determine where word boundaries should be added. We add a word boundary at the beginning of each sentence, and for each character whose script differs from the previous character:
# dtype: bool; shape: [num_sentences, (num_chars_per_sentence)]
#
# sentence_char_starts_word[i, j] is True if the j'th character in the i'th
# sentence is the start of a word.
sentence_char_starts_word = tf.concat(
[tf.fill([sentence_char_script.nrows(),1],True),
tf.not_equal(sentence_char_script[:,1:], sentence_char_script[:,:-1])],
axis=1)
# dtype: int64; shape: [num_words]
#
# word_starts[i] is the index of the character that starts the i'th word (in
# the flattened list of characters from all sentences).
word_starts =tf.squeeze(tf.where(sentence_char_starts_word.values), axis=1)
print(word_starts)
Tf.Tensor([ 0 5 7 12 13 15], shape=(6,), dtype=int64)
We can then use those start offsets to build a RaggedTensor containing the list of words from all batches:
# dtype: int32; shape: [num_words, (num_chars_per_word)]
#
# word_char_codepoint[i, j] is the codepoint for the j'th character in the
# i'th word.
word_char_codepoint = tf.RaggedTensor.from_row_starts(
values=sentence_char_codepoint.values,
row_starts=word_starts)
print(word_char_codepoint)
<tf.RaggedTensor [[72, 101, 108, 108, 111], [44, 32], [119, 111, 114, 108, 100], [46], [19990, 30028], [12371, 12435, 12395, 12385, 12399]]>
And finally, we can segment the word codepoints RaggedTensor back into sentences:
# dtype: int64; shape: [num_sentences]
#
# sentence_num_words[i] is the number of words in the i'th sentence.
sentence_num_words = tf.reduce_sum(
tf.cast(sentence_char_starts_word, tf.int64),
axis=1)
# dtype: int32; shape: [num_sentences, (num_words_per_sentence), (num_chars_per_word)]
#
# sentence_word_char_codepoint[i, j, k] is the codepoint for the k'th character
# in the j'th word in the i'th sentence.
sentence_word_char_codepoint = tf.RaggedTensor.from_row_lengths(
values=word_char_codepoint,
row_lengths=sentence_num_words)
print(sentence_word_char_codepoint)
<tf.RaggedTensor [[[72, 101, 108, 108, 111], [44, 32], [119, 111, 114, 108, 100], [46]], [[19990, 30028], [12371, 12435, 12395, 12385, 12399]]]>
To make the final result easier to read, we can encode it back into UTF-8 strings:
Tf.strings.unicode_encode(sentence_word_char_codepoint,'UTF-8').to_list()
[[b'Hello', b', ', b'world', b'.'],
[b'\xe4\xb8\x96\xe7\x95\x8c',
b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf']]
A string is a list of characters in order.
A character is anything you can type on the keyboard in one keystroke,
like a letter, a number, or a backslash.
Strings can have spaces:
"hello world".
An empty string is a string that has 0 characters.
Python strings are immutable
Python recognize as strings everything that is delimited by quotation marks
(” ” or ‘ ‘).
String Manipulation
To manipulate strings, we can use some of Pythons built-in methods.
Creation
Word="Hello World"
>>>print word
Hello World
Accessing
Use [ ] to access characters in a string
Word="Hello World"
Letter=word[0]
>>>print letter
H
Length
Word="Hello World"
>>>len(word)
11
Finding
Word="Hello World">>>print word.count('l')# count how many times l is in the string
3
>>>print word.find("H")# find the word H in the string
0
>>>print word.index("World")# find the letters World in the string
6
Count
s ="Count, the number of spaces"
>>>prints.count(' ')
8
Slicing
Use [ # : # ] to get set of letter
Keep in mind that python, as many other languages, starts to count from 0!!
Word="Hello World"
Print word[0]#get one char of the word
Print word[0:1]#get one char of the word (same as above)
Print word[0:3]#get the first three char
Print word[:3]#get the first three char
Print word[-3:]#get the last three char
Print word[3:]#get all but the three first char
Print word[:-3]#get all but the three last character
Word="Hello World"
Word[start:end]# items start through end-1
Word[start:]# items start through the rest of the list
Word[:end]# items from the beginning through end-1
Word[:]# a copy of the whole list
Split Strings
Word="Hello World"
>>>word.split(' ')# Split on whitespace
['Hello','World']
Startswith / Endswith
Word="hello world"
>>>word.startswith("H")
True
>>>word.endswith("d")
True
>>>word.endswith("w")
False
Repeat Strings
Print"."*10# prints ten dots
>>>print"."*10
..........
Replacing
Word="Hello World"
>>>word.replace("Hello","Goodbye")
'Goodbye World'
Changing Upper and Lower Case Strings
String="Hello World"
>>>printstring.upper()
HELLO WORLD
>>>printstring.lower()
Hello world
>>>printstring.title()
Hello World
>>>printstring.capitalize()
Hello world
>>>printstring.swapcase()
HELLO wORLD
Reversing
String="Hello World"
>>>print' '.join(reversed(string))
d l r o W o l l e H
Strip
Python strings have the strip(), lstrip(), rstrip() methods for removing
any character from both ends of a string.
If the characters to be removed are not specified then white-space will be removed
Word="Hello World"
Strip off newline characters from end of the string
>>>printword.strip('
')
Hello World
Strip()#removes from both ends
Lstrip()#removes leading characters (Left-strip)
Rstrip()#removes trailing characters (Right-strip)
>>>word=" xyz "
>>>print word
Xyz
>>>printword.strip()
Xyz
>>>printword.lstrip()
Xyz
>>>printword.rstrip()
Xyz
Concatenation
To concatenate strings in Python use the “+” operator.
"Hello "+"World"# = "Hello World"
"Hello "+"World"+"!"# = "Hello World!"
Join
>>>print":".join(word)# #add a : between every char
H:e:l:l:o::W:o:r:l:d
>>>print" ".join(word)# add a whitespace between every char
H e l l o W o r l d
You can use ( > , < , <= , <= , == , != ) to compare two strings. Python compares string lexicographically i.e using ASCII value of the characters.
Suppose you have str1 as "Mary" andstr2 as "Mac". The first two characters from str1 andstr2 ( M and M ) are compared. As they are equal, the second two characters are compared. Because they are also equal, the third two characters (r and c ) are compared. And because r has greater ASCII value than c, str1 is greater than str2.
Here are some more examples:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | >>> "tim" == "tie" False >>> "free" != "freedom" True >>> "arrow" > "aron" True >>> "right" >= "left" True >>> "teeth" < "tee" False >>> "yellow" <= "fellow" False >>> "abc" > "" True >>> |
Try it out:
1
Print("tim" == "tie")
2
3
Print("free" != "freedom")
4
5
Print("arrow" > "aron")
6
7
Print("right" >= "left")
8
9
Print("teeth" < "tee")
10
11
Print("yellow" <= "fellow")
12
13
Print("abc" > "")
14
False
True
True
True
False
False
True
In Python, Strings are arrays of bytes representing Unicode characters. However, Python does not have a character data type, a single character is simply a string with a length of 1. Square brackets [] can be used to access elements of the string.
Example:
# Python program to demonstrate # strings
# Assign Welcome string to the variable var1 Var1 ="Welcome"
# Assign statistics string to the variable var2 Var2 ="statistics"
# print the result Print(var1) Print(var2) |
Output:
Welcome
Statistics
String Concatenation in Python
String Concatenation is the technique of combining two strings. String Concatenation can be done using many ways.
We can perform string concatenation using following ways:
- Using + operator
- Using join() method
- Using % operator
- Using format() function
Using + Operator
It’s very easy to use + operator for string concatenation. This operator can be used to add multiple strings together. However, the arguments must be a string.
Note: Strings are immutable, therefore, whenever it is concatenated, it is assigned to a new variable.
Example:
# Python program to demonstrate # string concatenation
# Defining strings Var1 ="Hello " Var2 ="World"
# + Operator is used to combine strings Var3 =var1 +var2 Print(var3) |
Output:
Hello World
Here, the variable var1 stores the string “Hello ” and variable var2 stores the string “World”. The + Operator combines the string that is stored in the var1 and var2 and stores in another variable var3.
Using join() Method
The join() method is a string method and returns a string in which the elements of sequence have been joined by str separator.
Example:
# Python program to demonstrate # string concatenation
Var1 ="Hello" Var2 ="World"
# join() method is used to combine the strings Print("".join([var1, var2]))
# join() method is used here to combine # the string with a separator Space(" ") Var3 =" ".join([var1, var2])
Print(var3) |
Output:
HelloWorld
Hello World
In the above example, the variable var1 stores the string “Hello” and variable var2 stores the string “World”. The join() method combines the string that is stored in the var1 and var2. The join method accepts only the list as it’s argument and list size can be anything. We can store the combined string in another variable var3 which is separated by space.
Using % Operator
We can use % operator for string formatting, it can also be used for string concatenation. It’s useful when we want to concatenate strings and perform simple formatting.
Example:
# Python program to demonstrate # string concatenation
Var1 ="Hello" Var2 ="World"
# % Operator is used here to combine the string Print("% s % s"%(var1, var2)) |
Output:
Hello World
Here, the % Operator combine the string that is stored in the var1 and var2. The %s denotes string data type. The value in both the variable is passed to the string %s and becomes “Hello World”.
Using format() function
Str.format() is one of the string formatting methods in Python, which allows multiple substitutions and value formatting. This method lets us concatenate elements within a string through positional formatting.
Example:
# Python program to demonstrate # string concatenation
Var1 ="Hello" Var2 ="World"
# format function is used here to # combine the string Print("{} {}".format(var1, var2))
# store the result in another variable Var3 ="{} {}".format(var1, var2)
Print(var3) |
Output:
Hello World
Hello World
Here, the format() function combines the string that is stored in the var1 and var2 and stores in another variable var3. The curly braces {} are used to set the position of strings. The first variable stores in the first curly braces and second variable stores in the second curly braces. Finally it prints the value “Hello World”.
Python slicing is about obtaining a sub-string from the given string by slicing it respectively from start to end.
Python slicing can be done in two ways.
- Slice() Constructor
- Extending Indexing
slice() Constructor
The slice() constructor creates a slice object representing the set of indices specified by range(start, stop, step).
Syntax:
- Slice(stop)
- Slice(start, stop, step)
Parameters:
start: Starting index where the slicing of object starts.
stop: Ending index where the slicing of object stops.
step: It is an optional argument that determines the increment between each index for slicing.
Return Type: Returns a sliced object containing elements in the given range only.
Index tracker for positive and negative index:
Negative comes into considers when tracking the string in reverse.
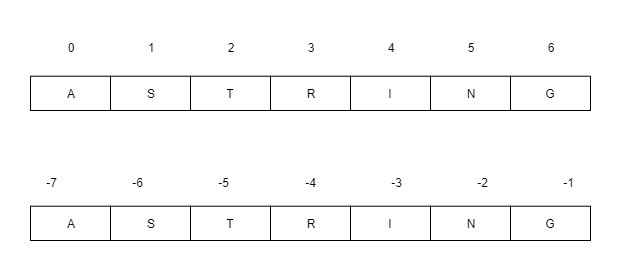
Example
# Python program to demonstrate # string slicing
# String slicing String ='ASTRING'
# Using slice constructor s1 =slice(3) s2 =slice(1, 5, 2) s3 =slice(-1, -12, -2)
Print("String slicing") Print(String[s1]) Print(String[s2]) Print(String[s3]) |
Output:
String slicing
AST
SR
GITA
Extending indexing
In Python, indexing syntax can be used as a substitute for the slice object. This is an easy and convenient way to slice a string both syntax wise and execution wise.
Syntax
String[start:end:step]
Start, end and step have the same mechanism as slice() constructor.
Example
# Python program to demonstrate # string slicing
# String slicing String ='ASTRING'
# Using indexing sequence Print(String[:3]) Print(String[1:5:2]) Print(String[-1:-12:-2])
# Prints string in reverse Print("\nReverse String") Print(String[::-1]) |
Output:
AST
SR
GITA
Reverse String
GNIRTSA
A string is a sequence of one or more characters (letters, numbers, symbols). Strings are a common form of data in computer programs, and we may need to convert strings to numbers or numbers to strings fairly often, especially when we are taking in user-generated data.
Converting Numbers to Strings
We can convert numbers to strings through using the str() method. We’ll pass either a number or a variable into the parentheses of the method and then that numeric value will be converted into a string value.
Let’s first look at converting integers. To convert the integer 12 to a string value, you can pass 12 into the str() method:
Str(12)
When running str(12) in the Python interactive shell with the python command in a terminal window, you’ll receive the following output:
Output
'12'
The quotes around the number 12 signify that the number is no longer an integer but is now a string value.
With variables we can begin to see how practical it can be to convert integers to strings. Let’s say we want to keep track of a user’s daily programming progress and are inputting how many lines of code they write at a time. We would like to show this feedback to the user and will be printing out string and integer values at the same time:
User="Sammy"
Lines=50
Print("Congratulations, "+ user +"! You just wrote "+ lines +" lines of code.")
When we run this code, we receive the following error:
Output
TypeError: Can't convert 'int' object to str implicitly
We’re not able to concatenate strings and integers in Python, so we’ll have to convert the variable lines to be a string value:
User="Sammy"
Lines=50
Print("Congratulations, "+ user +"! You just wrote "+str(lines)+" lines of code.")
Now, when we run the code, we receive the following output that congratulates our user on their progress:
Output
Congratulations, Sammy! You just wrote 50 lines of code.
If we are looking to convert a float to a string rather than an integer to a string, we follow the same steps and format. When we pass a float into the str() method, a string value of the float will be returned. We can use either the float value itself or a variable:
Print(str(421.034))
f =5524.53
Print(str(f))
Output
421.034
5524.53
We can test to make sure it’s right by concatenating with a string:
f =5524.53
Print("Sammy has "+str(f)+" points.")
Output
Sammy has 5524.53 points.
We can be sure our float was properly converted to a string because the concatenation was performed without error.
Converting Strings to Numbers
Strings can be converted to numbers by using the int() and float() methods.
If your string does not have decimal places, you’ll most likely want to convert it to an integer by using the int() method.
Let’s use the example of the user Sammy keeping track of lines of code written each day. We may want to manipulate those values with math to provide more interesting feedback for the user, but those values are currently stored in strings:
Lines_yesterday ="50"
Lines_today ="108"
Lines_more = lines_today - lines_yesterday
Print(lines_more)
Output
TypeError: unsupported operand type(s) for -: 'str' and 'str'
Because the two numeric values were stored in strings, we received an error. The operand - for subtraction is not a valid operand for two string values.
Let’s modify the code to include the int() method that will convert the strings to integers, and allow us to do math with values these that were originally strings.
Lines_yesterday ="50"
Lines_today ="108"
Lines_more =int(lines_today)-int(lines_yesterday)
Print(lines_more)
Output
58
The variable lines_more is automatically an integer, and it is equal to the numeric value of 58 in this example.
We can also convert the numbers in the example above to float values by using the float() method in place of the int() method. Instead of receiving the output of 58, we’ll receive the output of 58.0, a float.
The user Sammy is earning points in decimal values
Total_points ="5524.53"
New_points ="45.30"
New_total_points = total_points + new_points
Print(new_total_points)
Output
5524.5345.30
In this case, using the + operand with two strings is a valid operation, but it is concatenating two strings rather than adding two numeric values together. So, our output looks unusual since it just places the two values next to each other.
We’ll want to convert these strings to floats prior to performing any math with the float() method:
Total_points ="5524.53"
New_points ="45.30"
New_total_points =float(total_points)+float(new_points)
Print(new_total_points)
Output
5569.83
Now that we have converted the two strings to floats, we receive the anticipated result that adds 45.30 to 5524.53.
If we try to convert a string value with decimal places to an integer, we’ll receive an error:
f ="54.23"
Print(int(f))
Output
ValueError: invalid literal for int() with base 10: '54.23'
If we pass a decimal value in a string to the int() method we’ll receive an error because it will not convert to an integer.
Converting strings to numbers enables us to quickly modify the data type we are working with so that we can perform operations on numeric values that were originally cast as strings.
Python provides inbuilt functions for creating, writing and reading files. There are two types of files that can be handled in python, normal text files and binary files (written in binary language,0s and 1s).
- Text files: In this type of file, Each line of text is terminated with a special character called EOL (End of Line), which is the new line character (‘\n’) in python by default.
- Binary files: In this type of file, there is no terminator for a line and the data is stored after converting it into machine understandable binary language.
In this article, we will be focusing on opening, closing, reading and writing data in a text file.
File Access Modes
Access modes govern the type of operations possible in the opened file. It refers to how the file will be used once its opened. These modes also define the location of the File Handle in the file. File handle is like a cursor, which defines from where the data has to be read or written in the file. There are 6 access modes in python.
- Read Only (‘r’) :Open text file for reading. The handle is positioned at the beginning of the file. If the file does not exists, raises I/O error. This is also the default mode in which file is opened.
- Read and Write (‘r+’) : Open the file for reading and writing. The handle is positioned at the beginning of the file. Raises I/O error if the file does not exists.
- Write Only (‘w’) : Open the file for writing. For existing file, the data is truncated and over-written. The handle is positioned at the beginning of the file. Creates the file if the file does not exists.
- Write and Read (‘w+’) : Open the file for reading and writing. For existing file, data is truncated and over-written. The handle is positioned at the beginning of the file.
- Append Only (‘a’) : Open the file for writing. The file is created if it does not exist. The handle is positioned at the end of the file. The data being written will be inserted at the end, after the existing data.
- Append and Read (‘a+’) :Open the file for reading and writing. The file is created if it does not exist. The handle is positioned at the end of the file. The data being written will be inserted at the end, after the existing data.
Opening a File
It is done using the open() function. No module is required to be imported for this function.
File_object = open(r"File_Name","Access_Mode")
The file should exist in the same directory as the python program file else, full address of the file should be written on place of filename.
Note: The r is placed before filename to prevent the characters in filename string to be treated as special character. For example, if there is \temp in the file address, then \t is treated as the tab character and error is raised of invalid address. The r makes the string raw, that is, it tells that the string is without any special characters. The r can be ignored if the file is in same directory and address is not being placed.
# Open function to open the file "MyFile1.txt" # (same directory) in append mode and File1 =open("MyFile.txt","a")
# store its reference in the variable file1 # and "MyFile2.txt" in D:\Text in file2 File2 =open(r"D:\Text\MyFile2.txt","w+") |
Here, file1 is created as object for MyFile1 and file2 as object for MyFile2
Closing a file
Close() function closes the file and frees the memory space acquired by that file. It is used at the time when the file is no longer needed or if it is to be opened in a different file mode.
File_object.close()
# Opening and Closing a file "MyFile.txt" # for object name file1. File1 =open("MyFile.txt","a") File1.close() |
Writing to a file
There are two ways to write in a file.
- Write() : Inserts the string str1 in a single line in the text file.
File_object.write(str1)
2. writelines() : For a list of string elements, each string is inserted in the text file.Used to insert multiple strings at a single time.
File_object.writelines(L) for L = [str1, str2, str3]
Reading from a file
There are three ways to read data from a text file.
- Read() : Returns the read bytes in form of a string. Reads n bytes, if no n specified, reads the entire file.
File_object.read([n])
2. readline() : Reads a line of the file and returns in form of a string.For specified n, reads at most n bytes. However, does not reads more than one line, even if n exceeds the length of the line.
File_object.readline([n])
3. readlines() : Reads all the lines and return them as each line a string element in a list.
File_object.readlines()
Note: ‘\n’ is treated as a special character of two bytes
# Program to show various ways to read and # write data in a file. File1 =open("myfile.txt","w") L =["This is Delhi \n","This is Paris \n","This is London \n"]
# \n is placed to indicate EOL (End of Line) File1.write("Hello \n") File1.writelines(L) File1.close() #to change file access modes
File1 =open("myfile.txt","r+")
Print"Output of Read function is " Printfile1.read()
# seek(n) takes the file handle to the nth # bite from the beginning. File1.seek(0)
Print"Output of Readline function is " Printfile1.readline()
File1.seek(0)
# To show difference between read and readline Print"Output of Read(9) function is " Printfile1.read(9)
File1.seek(0)
Print"Output of Readline(9) function is " Printfile1.readline(9)
File1.seek(0) # readlines function Print"Output of Readlines function is " Printfile1.readlines() File1.close() |
Output:
Output of Read function is
Hello
This is Delhi
This is Paris
This is London
Output of Readline function is
Hello
Output of Read(9) function is
Hello
Th
Output of Readline(9) function is
Hello
Output of Readlines function is
['Hello \n', 'This is Delhi \n', 'This is Paris \n', 'This is London \n']
Appending to a file
# Python program to illustrate # Append vs write mode File1 =open("myfile.txt","w") L =["This is Delhi \n","This is Paris \n","This is London \n"] File1.close()
# Append-adds at last File1 =open("myfile.txt","a")#append mode File1.write("Today \n") File1.close()
File1 =open("myfile.txt","r") Print"Output of Readlines after appending" Printfile1.readlines() File1.close()
# Write-Overwrites File1 =open("myfile.txt","w")#write mode File1.write("Tomorrow \n") File1.close()
File1 =open("myfile.txt","r") Print"Output of Readlines after writing" Printfile1.readlines() File1.close() |
Output:
Output of Readlines after appending
['This is Delhi \n', 'This is Paris \n', 'This is London \n', 'Today \n']
Output of Readlines after writing
['Tomorrow \n']
Python Directory
If there are a large number of files to handle in our Python program, we can arrange our code within different directories to make things more manageable.
A directory or folder is a collection of files and subdirectories. Python has the os module that provides us with many useful methods to work with directories (and files as well).
Get Current Directory
We can get the present working directory using the getcwd() method of the os module.
This method returns the current working directory in the form of a string. We can also use the getcwdb() method to get it as bytes object.
import os
os.getcwd()
'C:\\Program Files\\PyScripter'
os.getcwdb()
b'C:\\Program Files\\PyScripter'
The extra backslash implies an escape sequence. The print() function will render this properly.
print(os.getcwd())
C:\Program Files\PyScripter
Changing Directory
We can change the current working directory by using the chdir() method.
The new path that we want to change into must be supplied as a string to this method. We can use both the forward-slash / or the backward-slash \ to separate the path elements.
It is safer to use an escape sequence when using the backward slash.
os.chdir('C:\\Python33')
print(os.getcwd())
C:\Python33
List Directories and Files
All files and sub-directories inside a directory can be retrieved using the listdir() method.
This method takes in a path and returns a list of subdirectories and files in that path. If no path is specified, it returns the list of subdirectories and files from the current working directory.
print(os.getcwd())
C:\Python33
os.listdir()
['DLLs',
'Doc',
'include',
'Lib',
'libs',
'LICENSE.txt',
'NEWS.txt',
'python.exe',
'pythonw.exe',
'README.txt',
'Scripts',
'tcl',
'Tools']
os.listdir('G:\\')
['$RECYCLE.BIN',
'Movies',
'Music',
'Photos',
'Series',
'System Volume Information']
Making a New Directory
We can make a new directory using the mkdir() method.
This method takes in the path of the new directory. If the full path is not specified, the new directory is created in the current working directory.
os.mkdir('test')
os.listdir()
['test']
Renaming a Directory or a File
The rename() method can rename a directory or a file.
For renaming any directory or file, the rename() method takes in two basic arguments: the old name as the first argument and the new name as the second argument.
os.listdir()
['test']
os.rename('test','new_one')
os.listdir()
['new_one']
Removing Directory or File
A file can be removed (deleted) using the remove() method.
Similarly, the rmdir() method removes an empty directory.
os.listdir()
['new_one', 'old.txt']
os.remove('old.txt')
os.listdir()
['new_one']
os.rmdir('new_one')
os.listdir()
[]
Note: The rmdir() method can only remove empty directories.
In order to remove a non-empty directory, we can use the rmtree() method inside the shutil module.
os.listdir()
['test']
os.rmdir('test')
Traceback (most recent call last):
...
OSError: [WinError 145] The directory isnot empty: 'test'
import shutil
shutil.rmtree('test')
os.listdir()
[]
The os and sys modules provide numerous tools to deal with filenames, paths, directories. The os module contains two sub-modules os.sys (same as sys) and os.path that are dedicated to the system and directories; respectively.
Whenever possible, you should use the functions provided by these modules for file, directory, and path manipulations. These modules are wrappers for platform-specific modules, so functions like os.path.split work on UNIX, Windows, Mac OS, and any other platform supported by Python.
Quick start
You can build multi-platform path using the proper separator symbol:
>>>importos
>>>importos.path
>>>os.path.join(os.sep,'home','user','work')
'/home/user/work'
>>>os.path.split('/usr/bin/python')
('/usr/bin', 'python')
Functions
The os module has lots of functions. We will not cover all of them thoroughly but this could be a good start to use the module.
Manipulating Directories
The getcwd() function returns the current directory (in unicode format with getcwdu() ).
The current directory can be changed using chdir():
Os.chdir(path)
The listdir() function returns the content of a directory. Note, however, that it mixes directories and files.
The mkdir() function creates a directory. It returns an error if the parent directory does not exist. If you want to create the parent directory as well, you should rather use makedirs():
>>>os.mkdir('temp')# creates temp directory inside the current directory
>>>os.makedirs(/tmp/temp/temp")
Once created, you can delete an empty directory with rmdir():
>>>importos
>>>os.mkdir('/tmp/temp')
>>>os.rmdir('/tmp/temp')
You can remove all directories within a directory (if there are not empty) by usingos.removedirs().
If you want to delete a non-empty directory, use shutil.rmtree() (with cautious).
Removing a file
To remove a file, useos.remove(). It raise the OSError exception if the file cannot be removed. Under Linux, you can also use os.unlink().
Renaming files or directories
You can rename a file from an old name to a new one by using os.rename().
Permission
You can change the mode of a file using chmod(). See also chown, chroot, fchmod, fchown.
The os.access() verifies the access permission specified in the mode argument. Returns 1 if the access is granted, 0 otherwise. The mode can be:
|
|
Os.F_OK | Value to pass as the mode parameter of access() to test the existence of path. |
Os.R_OK: | Value to include in the mode parameter of access() to test the readability of path. |
Os.W_OK | Value to include in the mode parameter of access() to test the writability of path. |
Os.X_OK | Value to include in the mode parameter of access() to determine if path can be |
>>>os.access("validFile",os.F_OK)
True
You can change the mask of a file using the the os.unmask() function. The mask is just a number that summarises the permissions of a file:
Os.umask(644)
Using more than one process
On Unix systems, os.fork() tells the computer to copy everything about the currently running program into a newly created program that is separated, but almost entirely identical. The newly created process is the child process and gets the data and code of the parent process. The child process gets a process number known as pid. The parent and child processes are independent.
The following code works on Unix and Unix-like systems only:
Importos
Pid=os.fork()
Ifpid==0:# the child
Print"this is the child"
Elifpid>0:
Print"the child is pid %d"%pid
Else:
Print("An error occured")
Here, the fork is zithin the executed script but ,ost of the time; you would require the
One of the most common things to do after an os.fork call is to call os.execl immediately afterward to run another program. Os.execl is an instruction to replace the running program with a new program, so the calling program goes away, and a new program appears in its place:
Import os
Pid = os.fork()
# fork and exec together
Print "second test"
If pid == 0: # This is the child
Print "this is the child"
Print "I'm going to exec another program now"
Os.execl(/bin/cat', cat', /etc/motd')
Else:
Print "the child is pid %d" % pid
Os.wait()
The os.wait function instructs Python that you want the parent to not do anything until the child process returns. It is very useful to know how this works because it works well only under Unix and Unix-like platforms such as Linux. Windows also has a mechanism for starting up new processes. To make the common task of starting a new program easier, Python offers a single family of functions that combines os.fork and os.exec on Unix-like systems, and enables you to do something similar on Windows platforms. When you want to just start up a new program, you can use the os.spawn family of functions.
The different between the different spawn versions:
- v requires a list/vector os parameters. This allows a command to be run with very different commands from one instance to the next without needing to alter the program at all.
- l requires a simple list of parameters.
- e requires a dictionary containing names and values to replace the current environment.
- p requires the value of the PATH key in the environment dictionary to find the program. The
p variants are available only on Unix-like platforms. The least of what this means is that on Windows your programs must have a completely qualified path to be usable by the os.spawn calls, or you have to search the path yourself:
Import os, sys
If sys.platform == win32':
Print "Running on a windows platform"
Command = "C:\\winnt\\system32\\cmd.exe"
Params = []
If sys.platform == linux2':
Print "Running on a Linux system, identified by %s" % sys.platform
Command = /bin/uname'
Params = [uname', -a']
Print "Running %s" % command
Os.spawnv(os.P_WAIT, command, params)
The exec function comes in different flavours:
- Execl(path, args) or execle(path, args, env) env is a dict with env variables.
- Exexp(file; a1; a2, a3) or exexp(file; a1; a2, a3, env)
Todo
Os.getloadavg os.setegid
Os.getlogin os.seteuid
Os.abort os.getpgid os.setgid
Os.getpgrp os.setgroups
Os.setpgid os.setpgrp
Os.UserDict os.getresgid os.setregid
Os.getresuid os.setresgid os.getsid
Os.setresuid os.setreuid
Os.closerange os.initgroups os.setsid
Os.confstr os.isatty os.setuid
Os.confstr_names os.ctermid
Os.defpath os.devnull
Os.link os.dup os.dup2
Os.errno os.major
Os.error os.makedev os.stat_float_times
Os.execl
Os.execle os.minor os.statvfs
Os.execlp os.statvfs_result
Os.execlpe os.mkfifo os.strerror
Os.execv os.mknod os.symlink
Os.execve
Os.execvp os.sysconf
Os.execvpe os.open os.sysconf_names
Os.extsep os.openpty os.system
Os.fchdir os.pardir os.tcgetpgrp
Os.tcsetpgrp os.pathconf os.tempnam
Os.fdatasync os.pathconf_names os.times
Os.fdopen os.tmpfile
Os.pipe os.tmpnam
Os.forkpty os.popen os.ttyname
Os.fpathconf os.popen2 os.popen3
Os.fstatvfs os.popen4
Os.fsync os.putenv os.unsetenv
Os.ftruncate os.read os.urandom
Os.readlink os.utime
Os.wait os.wait3
Os.getenv os.wait4
Os.waitpid os.getgroups
The os.walk() function allows to recursively scan a directory and obtain tuples containing tuples of (dirpath, dirnames, filename) where dirnames is a list of directories found in dirpath, and filenames the list of files found in dirpath.
Alternatevely, the os.path.walk can also be used but works in a different way (see below).
Cross platform os attributes
An alternative character used by the OS to separate pathame components is provided by os.altsep().
The os.curdir() refers to the current directory. .for unix and windows and : for Mac OS.
Another multi-platform function that could be useful is the line separator. Indeed the final character that ends a line is coded differently under Linux, Windows and MAC. For instance under Linux, it is the n character but you may have r or rn. Using the os.linesep() guarantees to use a universal line_ending character.
The os.uname gives more information about your system:
>>>os.uname
('Linux',
'localhost.localdomain',
'3.3.4-5.fc17.x86_64',
'#1 SMP Mon May 7 17:29:34 UTC 2012',
'x86_64')
The function os.name() returns the OS-dependent module (e.g., posix, doc, mac,...)
The function os.pardir() refers to the parent directory (.. For unix and windows and :: for Mac OS).
The os.pathsep() function (also found in os.path.sep()) returns the correct path separator for your system (slash / under Linux and backslash under Windows).
Finally, the os.sep() is the character that separates pathname components (/ for Unix, for windows and : for Mac OS). It is also available in os.path.sep()
>>># under linux
>>>os.path.sep
'/'
Another function that is related to multi-platform situations is the os.path.normcase() that is useful under Windows where the OS ignore cases. So, to compare two filenames you will need this function.
More about directories and files
Os.path provides methods to extract information about path and file names:
>>>os.path.curdir# returns the current directory ('.')
>>>os.path.isdir(dir)# returns True if dir exists
>>>os.path.isfile(file)# returns True if file exists
>>>os.path.islink(link)# returns True if link exists
>>>os.path.exists(dir)# returns True if dir exists (full pathname or filename)
>>>os.path.getsize(filename)# returns size of a file without opening it.
You can access to the time when a file was last modified. Nevertheless, the output is not friendly user. Under Unix it corresponds to the time since the Jan 1, 1970 (GMT) and under Mac OS since Jan 1, 1904 (GMT)Use the time module to make it easier to read:
>>>importtime
>>>mtime=os.path.getmtime(filename)# returns time when the file was last modified
The output is not really meaningful since it is expressed in seconds. You can use the time module to get a better layout of that time:
>>>printtime.ctime(mtime)
Tue Jan 01 02:02:02 2000
Similarly, the function os.path.getatime() returns the last access time of a file and os.path.getctime() the metadata change time of a file.
Finally, you can get a all set of information using os.stat() such as file’s size, access time and so on. The stat() returns a tuple of numbers, which give you information about a file (or directory).
>>>importstat
>>>importtime
>>>defdump(st):
... Mode,ino,dev,nlink,uid,gid,size,atime,mtime,ctime=st
... Print"- size:",size,"bytes"
... Print"- owner:",uid,gid
... Print"- created:",time.ctime(ctime)
... Print"- last accessed:",time.ctime(atime)
... Print"- last modified:",time.ctime(mtime)
... Print"- mode:",oct(mode)
... Print"- inode/dev:",ino,dev
>>>dump(os.stat("todo.txt"))
- size: 0 bytes
- owner: 1000 1000
- created: Wed Dec 19 19:40:02 2012
- last accessed: Wed Dec 19 19:40:02 2012
- last modified: Wed Dec 19 19:40:02 2012
- mode: 0100664
- inode/dev: 23855323 64770
There are other similar function os.lstat() for symbolic links, os.fstat() for file descriptor
You can determine is a path is a mount point using os.ismount(). Under unix, it checks if a path or file is mounted on an other device (e.g. An external hard disk).
Splitting paths
To get the base name of a path (last component):
>>>importos
>>>os.path.basename("/home/user/temp.txt")
Temp.txt
To get the directory name of a path, useos.path.dirname():
>>>importos
>>>os.path.dirname("/home/user/temp.txt")
/home/user
The os.path.abspath() returns the absolute path of a file:
>>>importos
>>>os.path.abspath('temp.txt')
In summary, consider a file temp.txt in /home/user:
Function | Output |
Basename | ‘temp.txt’ |
Dirname | ‘’ |
Split | (‘’, ‘temp.txt’) |
Splitdrive | (‘’, ‘temp.txt’) |
Splitext | (‘temp’; ‘txt’) |
Abspath | ‘/home/user/temp.txt |
Os.path.extsep os.path.genericpath os.path.realpath
Os.path.relpath os.path.samefile
Os.path.sameopenfile os.path.samestat
Os.path.isab
Os.path.commonprefix
Os.path.defpath os.path.supports_unicode_filenames
Os.path.devnull os.path.lexists
Os.path.warnings .expanduser os.path.expandvars
Split the basename and directory name in one function call using os.path.split(). The split function only splits off the last part of a component. In order to split off all parts, you need to write your own function:
Note
The path should not end with ‘/’, otherwise the name is empty.
Os.path.split(‘/home/user’) is not the same as os.path.split(‘/home/user/’)
>>>defsplit_all(path):
... Parent,name=os.path.split(path)
... Ifname=='':
... Return(parent,)
... Else:
... Returnsplit_all(parent)+(name,)
>>>split_all('/home/user/Work')
('/', 'home', 'user', 'Work')
The os.path.splitext() function splits off the extension of a file:
>>>os.path.splitext('image.png')
('image', 'png')
For windows users, you can use the os.splitdrive() that returns a tuple with 2 strings, there first one being the drive.
Conversely, the join method allows to join several directory name to create a full path name:
>>>os.path.join('/home','user')
'/home/user'
Os.path.walk() scan a directory recursively and apply a function of each item found
Defprint_info(arg,dir,files):
Forfileinfiles:
Printdir+' '+file
Os.path.walk('.',print_info,0)
Accessing environment variables
You can easily acecss to the environmental variables:
Importos
Os.environ.keys()
And if you know what you are doing, you can add or replace a variable:
Os.environ[NAME]=VALUE
Sys module
When starting a Python shell, Python provides 3 file objects called stadnard input, stadn output and standard error. There are accessible via the sys module:
Sys.stderr
Sys.stdin
Sys.stdout
The sys.argv is used to retrieve user argument when your module is executable.
Another useful attribute in the sys.path that tells you where Python is searching for modules on your system.
Information
- Sys.platform returns the platform version (e.g., linux2)
- Sys.version returns the python version
- Sys.version_info returns a named tuple
Sys.exitfunc sys.last_value sys.pydebug
Sys.flags sys.long_info sys.real_prefix
Sys.builtin_module_names sys.float_info sys.setcheckinterval
Sys.byteorder sys.float_repr_style sys.maxsize sys.setdlopenflags
Sys.call_tracing sys.getcheckinterval sys.maxunicode sys.setprofile
Sys.callstats sys.meta_path sys.copyright
Sys.getdlopenflags sys.modules sys.settrace
Sys.displayhook sys.getfilesystemencoding sys.path
Sys.dont_write_bytecode sys.getprofile sys.path_hooks
Sys.exc_clear sys.path_importer_cache
Sys.exc_info sys.getrefcount sys.exc_type sys.getsizeof sys.prefix sys.excepthook
Sys.gettrace sys.ps1
Sys.exec_prefix sys.ps2 sys.warnoptions
Sys.executable sys.last_traceback sys.ps3
Sys.last_type sys.py3kwarning
The sys.modules attribute returns list of all the modules that have been imported so far in your environment.
Python provides some inbuilt functions for reading, writing, or accessing files. Python can handle mainly two types of files. The normal text file and the binary files.
For the text files, each lines are terminated with a special character '\n' (It is known as EOL or End Of Line). For the Binary file, there is no line ending character. It saves the data after converting the content into bit stream.
In this section we will discuss about the text files.
File Accessing Modes
Sr.No | Modes & Description |
1 | R It is Read Only mode. It opens the text file for reading. When the file is not present, it raises I/O Error. |
2 | r+ This mode for Reading and Writing. When the file is not present, it will raise I/O Error. |
3 | W It is for write only jobs. When file is not present, it will create a file first, then start writing, when the file is present, it will remove the contents of that file, and start writing from beginning. |
4 | w+ It is Write and Read mode. When file is not present, it can create the file, or when the file is present, the data will be overwritten. |
5 | A This is append mode. So it writes data at the end of a file. |
6 | a+ Append and Read mode. It can append data as well as read the data. |
Now see how a file can be written using writelines() and write() method.
Example code
#Create an empty file and write some lines
Line1 ='This is first line. \n'
Lines=['This is another line to store into file.\n',
'The Third Line for the file.\n',
'Another line... !@#$%^&*()_+.\n',
'End Line']
#open the file as write mode
My_file =open('file_read_write.txt','w')
My_file.write(line1)
My_file.writelines(lines)#Write multiple lines
My_file.close()
Print('Writing Complete')
Output
Writing Complete
After writing the lines, we are appending some lines into the file.
Example code
#program to append some lines
Line1 ='\n\nThis is a new line. This line will be appended. \n'
#open the file as append mode
My_file =open('file_read_write.txt','a')
My_file.write(line1)
My_file.close()
Print('Appending Done')
Output
Appending Done
At last, we will see how to read the file content from the read() and readline() method. We can provide some integer number 'n' to get first 'n' characters.
Example code
#program to read from file
#open the file as read mode
My_file =open('file_read_write.txt','r')
Print('Show the full content:')
Print(my_file.read())
#Show first two lines
My_file.seek(0)
Print('First two lines:')
Print(my_file.readline(),end='')
Print(my_file.readline(),end='')
#Show upto 25 characters
My_file.seek(0)
Print('\n\nFirst 25 characters:')
Print(my_file.read(25),end='')
My_file.close()
Output
Show the full content:
This is first line.
This is another line to store into file.
The Third Line for the file.
Another line... !@#$%^&*()_+.
End Line
This is a new line. This line will be appended.
First two lines:
This is first line.
This is another line to store into file.
First 25 characters:
This is first line.
This
What is a CSV file?
A CSV file is a type of plain text file that uses specific structuring to arrange tabular data. CSV is a common format for data interchange as it's compact, simple and general. Many online services allow its users to export tabular data from the website into a CSV file. Files of CSV will open into Excel, and nearly all databases have a tool to allow import from CSV file. The standard format is defined by rows and columns data. Moreover, each row is terminated by a newline to begin the next row. Also within the row, each column is separated by a comma.
CSV Sample File.
Data in the form of tables is also called CSV (comma separated values) - literally "comma-separated values." This is a text format intended for the presentation of tabular data. Each line of the file is one line of the table. The values of individual columns are separated by a separator symbol - a comma (,), a semicolon (;) or another symbol. CSV can be easily read and processed by Python.
Consider the following Tabe
Table Data
Programming language | Designed by | Appeared | Extension |
Python | Guido van Rossum | 1991 | .py |
Java | James Gosling | 1995 | .java |
C++ | Bjarne Stroustrup | 1983 | .cpp |
You can represent this table in csv as below.
CSV Data
Programming language, Designed by, Appeared, Extension
Python, Guido van Rossum, 1991, .py
Java, James Gosling, 1995, .java
C++, Bjarne Stroustrup,1983,.cpp
As you can see each row is a new line, and each column is separated with a comma. This is an example of how a CSV file looks like.
Python CSV Module
Python provides a CSV module to handle CSV files. To read/write data, you need to loop through rows of the CSV. You need to use the split method to get data from specified columns.
CSV Module Functions
In CSV module documentation you can find following functions:
- Csv.field_size_limit – return maximum field size
- Csv.get_dialect – get the dialect which is associated with the name
- Csv.list_dialects – show all registered dialects
- Csv.reader – read data from a csv file
- Csv.register_dialect - associate dialect with name
- Csv.writer – write data to a csv file
- Csv.unregister_dialect - delete the dialect associated with the name the dialect registry
- Csv.QUOTE_ALL - Quote everything, regardless of type.
- Csv.QUOTE_MINIMAL - Quote fields with special characters
- Csv.QUOTE_NONNUMERIC - Quote all fields that aren't numbers value
- Csv.QUOTE_NONE – Don't quote anything in output
In this tutorial, we are going to focus only on the reader and writer functions which allow you to edit, modify, and manipulate the data in a CSV file.
How to Read a CSV File
To read data from CSV files, you must use the reader function to generate a reader object.
The reader function is developed to take each row of the file and make a list of all columns. Then, you have to choose the column you want the variable data for.
It sounds a lot more intricate than it is. Let's take a look at this example, and we will find out that working with csv file isn't so hard.
#import necessary modules
Import csv
With open('X:\data.csv','rt')as f:
Data = csv.reader(f)
For row in data:
Print(row)
When you execute the program above, the output will be:
['Programming language; Designed by; Appeared; Extension']
['Python; Guido van Rossum; 1991; .py']
['Java; James Gosling; 1995; .java']
['C++; Bjarne Stroustrup;1983;.cpp']
How to Read a CSV as a Dictionary
You can also you use DictReader to read CSV files. The results are interpreted as a dictionary where the header row is the key, and other rows are values.
Consider the following code
#import necessary modules
Import csv
Reader = csv.DictReader(open("file2.csv"))
For raw in reader:
Print(raw)
The result of this code is:
OrderedDict([('Programming language', 'Python'), ('Designed by', 'Guido van Rossum'), (' Appeared', ' 1991'), (' Extension', ' .py')])
OrderedDict([('Programming language', 'Java'), ('Designed by', 'James Gosling'), (' Appeared', ' 1995'), (' Extension', ' .java')])
OrderedDict([('Programming language', 'C++'), ('Designed by', ' Bjarne Stroustrup'), (' Appeared', ' 1985'), (' Extension', ' .cpp')])
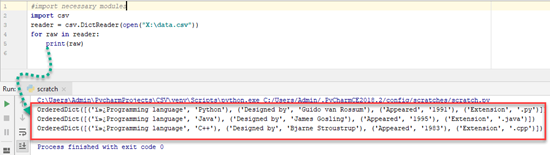
And this way to read data from CSV file is much easier than earlier method. However, this is not isn't the best way to read data.
How to write CSV File
When you have a set of data that you would like to store in a CSV file you have to use writer() function. To iterate the data over the rows(lines), you have to use the writerow() function.
Consider the following example. We write data into a file "writeData.csv" where the delimiter is an apostrophe.
#import necessary modules
Import csv
With open('X:\writeData.csv', mode='w') as file:
Writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
#way to write to csv file
Writer.writerow(['Programming language', 'Designed by', 'Appeared', 'Extension'])
Writer.writerow(['Python', 'Guido van Rossum', '1991', '.py'])
Writer.writerow(['Java', 'James Gosling', '1995', '.java'])
Writer.writerow(['C++', 'Bjarne Stroustrup', '1985', '.cpp'])
Result in csv file is:
Programming language, Designed by, Appeared, Extension
Python, Guido van Rossum, 1991, .py
Java, James Gosling, 1995, .java
C++, Bjarne Stroustrup,1983,.cpp
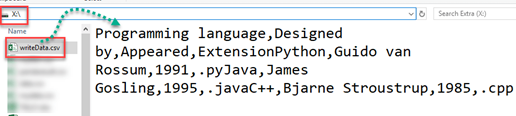
Reading CSV Files with Pandas
Pandas is an opensource library that allows to you perform data manipulation in Python. Pandas provide an easy way to create, manipulate and delete the data.
You must install pandas library with command <code>pip install pandas</code>. In windows, you will execute this command in Command Prompt while in Linux in the Terminal.
Reading the CSV into a pandas DataFrame is very quick and easy:
#import necessary modules
Import pandas
Result = pandas.read_csv('X:\data.csv')
Print(result)
Result:
Programming language, Designed by, Appeared, Extension
0 Python, Guido van Rossum, 1991, .py
1 Java, James Gosling, 1995, .java
2 C++, Bjarne Stroustrup,1983,.cpp
Very useful library. In just three lines of code you the same result as earlier. Pandas know that the first line of the CSV contained column names, and it will use them automatically.
Writing to CSV Files with Pandas
Writing to CSV file with Pandas is as easy as reading. Here you can convince in it. First you must create DataFrame based on the following code.
From pandas import DataFrame
C = {'Programming language': ['Python','Java', 'C++'],
'Designed by': ['Guido van Rossum', 'James Gosling', 'Bjarne Stroustrup'],
'Appeared': ['1991', '1995', '1985'],
'Extension': ['.py', '.java', '.cpp'],
}
Df = DataFrame(C, columns= ['Programming language', 'Designed by', 'Appeared', 'Extension'])
Export_csv = df.to_csv (r'X:\pandaresult.csv', index = None, header=True) # here you have to write path, where result file will be stored
Print (df)
Here is the output
Programming language, Designed by, Appeared, Extension
0 Python, Guido van Rossum, 1991, .py
1 Java, James Gosling, 1995, .java
2 C++, Bjarne Stroustrup,1983,.cpp
And CSV file is created at the specified location.

Conclusion
So, now you know how use method 'csv' and also read and write data in CSV format. CSV files are widely used in software applications because they are easy to read and manage, and their small size makes them relatively fast for processing and transmission.
The csv module provides various functions and classes which allow you to read and write easily. You can look at the official Python documentation and find some more interesting tips and modules. CSV is the best way for saving, viewing, and sending data. Actually, it isn't so hard to learn as it seems at the beginning. But with a little practice, you'll master it.
Pandas is a great alternative to read CSV files.
Also, there are other ways to parse text files with libraries like ANTLR, PLY, and PlyPlus. They can all handle heavy-duty parsing, and if simple String manipulation doesn't work, there are regular expressions which you can use.
Reference Books:
1 Computers Today by Sanders.
2 Fundamentals of Computers TTTI Publication.
3 Learning Python by Mark Lutz, 5th edition
4 Python cookbook, by David Beazley , 3rd Edition
5 Python Essential Reference, by David Beazley , 4th edition
6 Python in a Nutshell, by Alex Mortelli, 2nd Edition.
7 Python programming: An Introduction to computer science, by John Zelle, 2nd Edition.




