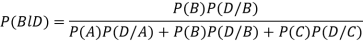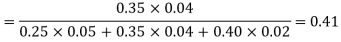Unit–2
Continuous and Bivariate probability distribution
A continuous random variable is a random variable where the data can take infinitely many values. For example, a random variable measuring the time taken for something to be done is continuous since there are an infinite number of possible times that can be taken.
Continuous random variable is called by a probability density function p (x), with given properties: p (x) ≥ 0 and the area between the x-axis & the curve is 1: ... Standard deviation of a variable Random is defined by σ x = √Variance (x).
- A continuous random variable is known by a probability density function p(x), with these things: p(x) ≥ 0 and the area on the x-axis and the curve is 1:
∫-∞∞ p(x) dx = 1.
2. The expected value E(x) of a discrete variable is known as:
E(x) = Σi=1n xi pi
3. The expected value E(x) of a continuous variable is called as:
E(x) = ∫-∞∞ x p(x) dx
4. The Variance(x) of a random variable is known as Variance(x) = E[(x - E(x)2].
5. 2 random variable x and y are independent if E[xy] = E(x)E(y).
6. Standard deviation of a random variable is known asσx = √Variance(x).
7. Given value of standard error is used in its place of standard deviation when denoting to the sample mean.
σmean = σx / √n
8. If x is a normal random variable with limitsμ and σ2 (spread = σ), mark in symbols: x ˜ N(μ, σ2).
9. The sample variance of x1, x2, ..., xn is given by-
sx2 = |
|
10. If x1, x2, ... , xn are explanationssince a random sample, the sample standard deviation s is known the square root of variance:
sx = | √ |
|
11. Sample Co-variance of x1, x2, ..., xn is known-
sxy = |
|
12. A random vector is a column vector of random variable.
v = (x1 ... xn)T
13. Expected value of Random vector E(v) is known byvector of expected value of component.
If v = (x1 ... xn)T
E(v) = [E(x1) ... E(xn)]T
14. Co-variance of matrix Co-variance(v) of a random vector is the matrix of variances and Co-variance of component.
If v = (x1 ... xn)T, the ijth component of the Co-variance(v) is sij
Properties
Starting from properties 1 to 7, c is a constant; x and y are random variables.
- E(x + y) = E(x) + E(y).
- E(cx) = c E(y).
- Variance(x) = E(x2) - E(x)2
- If x and y are indiviadual, then Variance(x + y) = Variance(x) + Variance(y).
- Variance(x + c) = Variance(x)
- Variance(cx) = c2 Variance(x)
- Co-variance(x + c, y) = Co-variance(x, y)
- Co-variance(cx, y) = c Co-variance(x, y)
- Co-variance(x, y + c) = Co-variance(x, y)
- Co-variance(x, cy) = c Co-variance(x, y)
- If x1, x2, ...,xn are discrete and N(μ, σ2), then E(x) = μ. We say that x is neutral for μ.
- If x1, x2, ... ,xn are independent and N(μ, σ2), then E(s) = σ2. We can told S is neutral for σ2.
From given properties 8 to 12, w and v is random vector; b is a continuous vector; A is a continuous matrix.
8. E(v + w) = E(v) + E(w)
9. E(b) = b
10. E(Av) = A E(v)
11. Co-variance(v + b) = Co-variance(v)
12. Co-variance(Av) = A Co-variance(v) AT
Problem 1.
Let X be a random variable with PDF given by
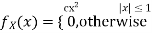
a, Find the constant c.
b. Find EX and Var (X).
c. Find P(X 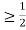 ).
).
Solution.
- To find c, we can use
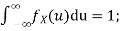
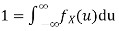
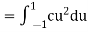
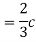
Thus we must have 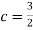 .
.
b. To find EX we can write
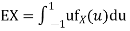
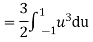
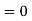
In fact, we could have guessed EX = 0 because the PDF is symmetric around x = 0. To find Var (X) we have
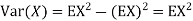
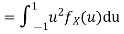
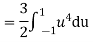
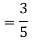
c. To find 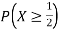 we can write
we can write
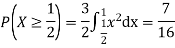
Problem 2. Let X be a continuous random variable with PDF given by
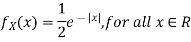
If 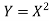 , find the CDF of Y.
, find the CDF of Y.
Solution. First we note that 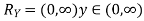 , we have
, we have
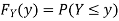
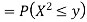
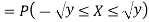
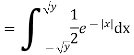
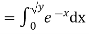
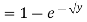
Thus, 
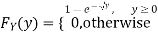
Problem 3. Let X be a continuous random variable with PDF
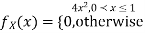
Find 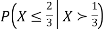 .
.
Solution. We have 
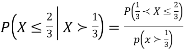
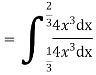
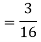
Probability Distribution:
A probability distribution is a arithmetical function which defines completely possible values &possibilities that a random variable can take in a given range. This range will be bounded between the minimum and maximum possible values. But exactly where the possible value is possible to be plotted on the probability distribution depends on a number of influences. These factors include the distribution's mean, SD, Skewness, and kurtosis.
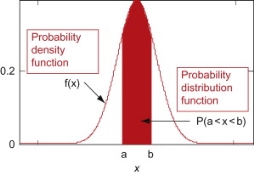
Probability Density:
Probability density function (PDF) is a arithmetical appearance which gives a probability distribution for a discrete random variable as opposite to a continuous random variable. The difference among a discrete random variable is that we check an exact value of the variable. Like, the value for the variable, a stock worth, only goes two decimal points outside the decimal (Example 32.22), while a continuous variable have an countless number of values (Example 32.22564879…).
When the PDF is graphically characterized, the area under the curve will show the interval in which the variable will decline. The total area in this interval of the graph equals the probability of a discrete random variable happening. More exactly, since the absolute prospect of a continuous random variable taking on any exact value is zero owing to the endless set of possible values existing, the value of a PDF can be used to determine the likelihood of a random variable dropping within a exact range of values.
Example. The probability density function of a variable X is
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
P(X) | k | 3k | 5k | 7k | 9k | 11k | 13k |
(i) Find 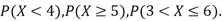
(ii) What will be e minimum value of k so that 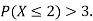
Solution. (i) If X is a random variable then
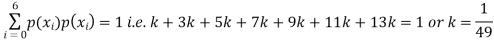
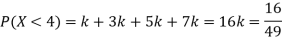
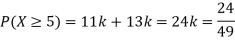
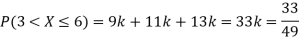
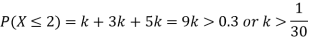
(ii)Thus minimum value of k=1/30.
Continuous probability distribution
When a variate X takes every value in an interval it gives rise to continuous distribution of X. The distribution defined by the vidiots like heights or weights are continuous distributions.
a major conceptual difference however exist between discrete and continuous probabilities. When thinking in discrete terms the probability associated with an event is meaningful. With continuous events however where the number of events is infinitely large, the probability that a specific event will occur is practically zero. For this reason continuous probability statements on must be worth did some work differently from discrete ones. Instead of finding the probability that x equals some value, we find the probability of x falling in a small interval.
Thus the probability distribution of a continuous variate x is defined by a function f (x) such that the probability of the variate x falling in the small interval 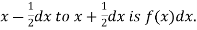 Symbolically it can be expressed as
Symbolically it can be expressed as 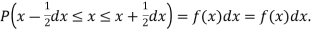 Thus f (x) is called the probability density function and then continuous curve y = f(x) is called the probability of curve.
Thus f (x) is called the probability density function and then continuous curve y = f(x) is called the probability of curve.
The range of the variable may be finite or infinite. But even when the range is finite, it is convenient to consider it as infinite by opposing the density function to be zero outside the given range. Thus if f (x) =(x) be the density function denoted for the variate x in the interval (a,b), then it can be written as
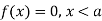
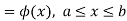
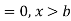
The density function f (x) is always positive and 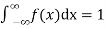 (i.e. the total area under the probability curve and the the x-axis is is unity which corresponds to the requirements that the total probability of happening of an event is unity).
(i.e. the total area under the probability curve and the the x-axis is is unity which corresponds to the requirements that the total probability of happening of an event is unity).
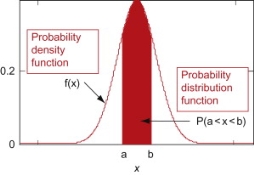
(2) Distribution function
If 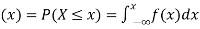
Then F(x) is defined as the commutative distribution function or simply the distribution function the continuous variate X. It is the probability that the value of the variate X will be ≤x. The graph of F(x) in this case is as shown in figure 26.3 (b).
The distribution function F (x) has the following properties
(i) 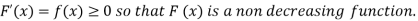
(ii) 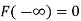
(iii) 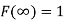
(iv) P(a ≤x ≤b)= 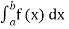 =
= 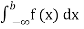 =F (b) – F (a).
=F (b) – F (a).
Example.
(i) Is the function defined as follows a density function.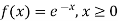
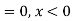
(ii) If so determine the probability that the variate having this density will fall in the interval (1.2).
(iii) Also find the cumulative probability function F (2)?
Solution. (i) f (x) is clearly ≥0 for every x in (1,2) and
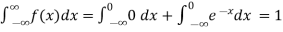
Hence the function f (x) satisfies the requirements for a density function.
(ii)Required probability = 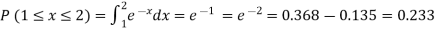
This probability is equal to the shaded area in figure 26.3 (a).
(iii)Cumulative probability function F(2)
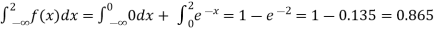
Which is shown in figure.
Exponential Distribution:
The exponential distribution is a C.D. Which is usually use to define to come time till some precise event happens. Like, the amount of time until a storm or other unsafe weather event occurs follows an exponential distribution law.
The one-parameter exponential distribution of the probability density function PDF is defined:
f(x)=λ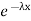 ,x≥0,
,x≥0,
Where, the rate λ signifies the
Normal amount of events in single time.
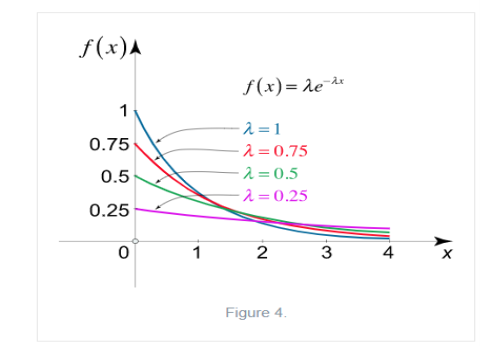
The mean value is μ=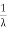 . The median of the exponential distribution is m=
. The median of the exponential distribution is m=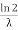 , and the variance is shown by
, and the variance is shown by 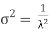 .
.
Normal Distribution:
Normal distribution
Now we consider continuous distribution of fundamental importance namely the normal distribution. Any quantity whose variation depends on random causes is distributed according to the normal law. Its importance lies in the fact that a large number of distributions approximate to the normal distribution.
Latest define a variate 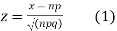
Where x no and S.D. 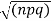 so that z is a very eighth with mean zero and variance unity. In the limit as n tends to infinity the distribution of z becomes a continuous distribution extending from
so that z is a very eighth with mean zero and variance unity. In the limit as n tends to infinity the distribution of z becomes a continuous distribution extending from 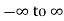 .
.
It can be shown that the limiting form of the binomial distribution (1) for large values of n when neither p nor q is very small is the normal distribution. The normal curve is of the form
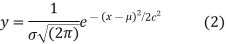
Where μ and 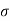 are the mean and standard deviation respectively..
are the mean and standard deviation respectively..
The normal distribution is the utmost broadly identified P.D. Then it defines many usual spectacles.
The PDF of the normal distribution is shown by method
f(x)=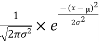 ,
,
Where μ is mean of the distribution, and 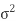 is the variance.
is the variance.
The 2 limitations μ and σ completely describe the figure and all additional things of the normal distribution function.
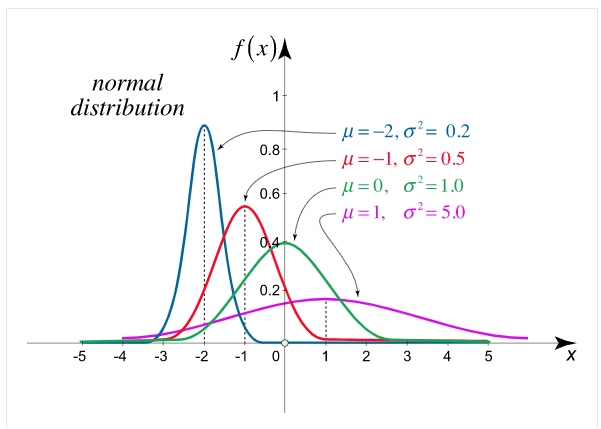
Example. X is a normal variate with mean 30 and S.D. 5, find the probabilities that
(i) 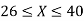
(ii) 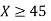
(iii) |X-30|≥5
Solution. We have μ =30 and 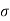 =5
=5
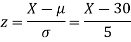
(i) When X = 26,z = -0.8, when X =40, z =-2
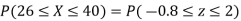
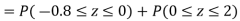
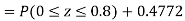
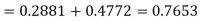
(ii) When X =45, z =3
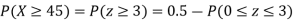
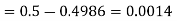
(iii) 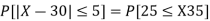
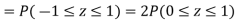
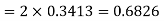
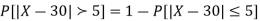
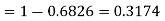
Example. In a normal distribution 31% of the items are under 45 and 8% are over 64. Find the mean and standard deviation of the distribution.
Solution. Let 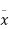 be the mean and
be the mean and 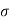 the standard deviation 31% of the items are under 45 means area to the left of the ordinate x = 45 (figure 26.6)
the standard deviation 31% of the items are under 45 means area to the left of the ordinate x = 45 (figure 26.6)
When x = 45, let z 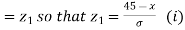
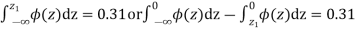
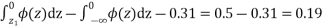
From table III 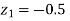
When x = 64, let 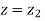 so that
so that 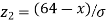
Hence, 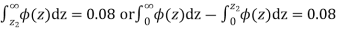
From table III 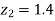
From (i) and (ii), 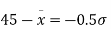
From (iii) and (iv), 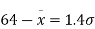
Solving these equations we get 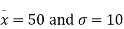
Example. In a test on 2000 electric bulbs, it was found that the life of a particular make was normally distributed with an average life of 2040 hours and standard deviation of 60 hours. Estimated number of bulbs likely to burn for
(a) More than 2150 hours
(b) Less than 1950 hours and
(c) More than 1920 hours and but less than 2 160 hours
Solution. Here μ = 2040 hours and 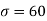 hours
hours
(a) For x = 2150, 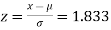
Area against z = 1.83 in the table III = 0.4664
We however require the area to the right of the ordinate at z = 1.83. This area = 0.5-0.4664=0.0336
Thus the number of bulbs expected to burn for more than 2150 hours.
= 0.0336×2000 = 67 approximately
(b) For x = 1950, 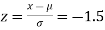
The area required in this case is to be left of z = -1.33
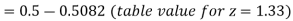
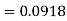
Therefore the number of bulbs expected to burn for less than 1950 hours
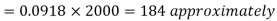
(c) When x = 1920, 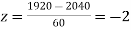
When x = 2160, 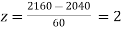
The number of bulbs expected to learn for more than 1920 hours but less than 2160 hours will be represented by the area between z = -2 and z = 2. This is twice the area from the table for z =2, i.e. 2 × 0.4772=0.9544
Thus required number of bulbs = 0.9544 × 2000 = 1909 nearly
Gamma density
Consider the distribution of the sum of 2autonomous Exponential (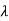 ) R.V.
) R.V.
Density of the form:
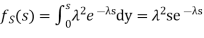
Density is known Gamma (2,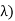 density. In common the gamma density is precise with 2 reasons (t,
density. In common the gamma density is precise with 2 reasons (t,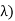 as being non zero on the +ve reals and called:
as being non zero on the +ve reals and called:
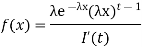
Where F (t) is the endless which symbols integral of the density quantity to one:
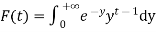
By integration by parts we presented the significant recurrence relative:
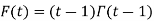
Because 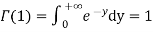 , we have for integer t=m
, we have for integer t=m
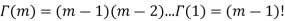
The specific case of the integer t can be linked to the sum of n independent exponential, it is the waiting time to the nth event, it is the matching of the negative binomial.
From that we can estimate what the estimated value and the variance are going to be: If all the Xi's are independent exponential (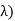 , then if we sum n of them we
, then if we sum n of them we
Have 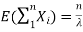 and if they are independent:
and if they are independent: 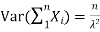
This simplifies to the non-integer t case:
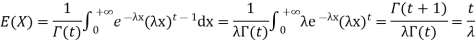
Example1: Following probability distribution
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P(x) | 0 | 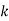 | 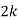 | 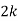 | 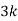 | 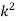 | 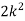 | 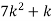 |
Find: (i) k (ii) 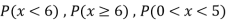
(i) Distribution function
(ii) If 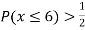 find minimum value of C
find minimum value of C
(iii) Find 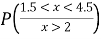
Solution:
If P(x) is p.m.f –
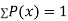
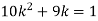
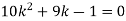
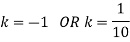
(i)
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P(x) | 0 | 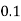 | 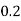 | 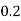 | 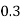 | 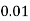 | 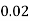 | 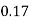 |
(ii)
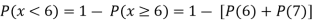
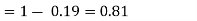
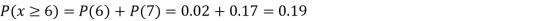
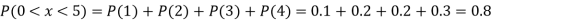
(iii)
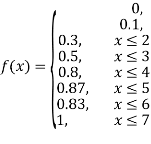
(iv)
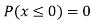
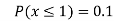
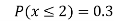
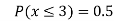
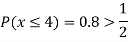
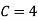
(v)
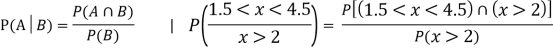
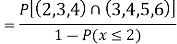
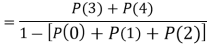
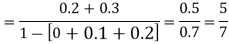
Example 2. I choose real number uniformly at random in the interval [a, b], and call it X. Buy uniformly at random, we mean all intervals in [a, b] that have the same length must have the same probability. Find the CDF of X.
Solution.
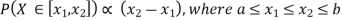
Since 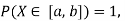 we conclude
we conclude
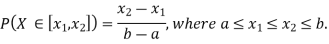
Now, let us find the CDF. By definition 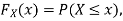 thus immediately have
thus immediately have
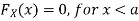
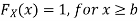
For 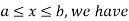
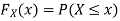
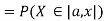
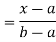
Thus, to summarize
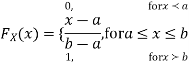
Note that hear it does not matter if we use “<” or “≤” as each individual point has probability zero, so for example 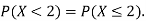 Figure 4.1 shows the CDF of X. As we expect the CDF starts at 0 at end at 1.
Figure 4.1 shows the CDF of X. As we expect the CDF starts at 0 at end at 1.
Example 3.
Find the mean value μ and the median m of the exponential distribution 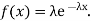
Solution. The mean value μ is determined by the integral
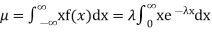
Integrating by parts we have
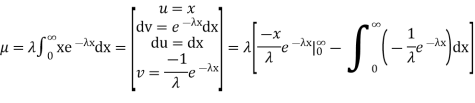
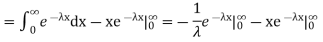
We evaluate the second term with the help of 1 Hopital's Rule:
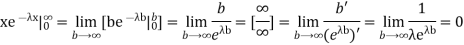
Hence the mean (average) value of the exponential distribution is
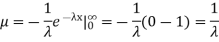
Determine the median m
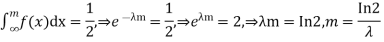
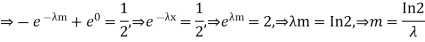
A bivariate distribution, setonly, is the probability that a definite event will happen when there are 2 independent random variables in your scenario. E.g, having two bowls, individually complete with 2dissimilarkinds of candies, and drawing one candy from each bowl gives you 2 independent random variables, the 2dissimilar candies. Since you are pulling one candy from each bowl at the same time, you have a bivariate distribution when calculating your probability of finish up with specific types of candies.
Properties:
Properties 1. Two random variables X and Y are said to be bivariate normal, or jointly normal distribution for all 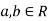
Properties 2:
Two random variables X and Y are set to have the standard bivariate normal distribution with correlation efficient if their joint PDF is given by
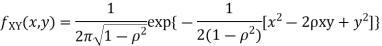
Where 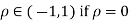 then we just say X and Y have the standard by will it normal distribution.
then we just say X and Y have the standard by will it normal distribution.
Properties 3:
Two random variables X and Y are set to have a bivariate normal distribution with parameters 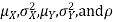 if their joint PDF is given by
if their joint PDF is given by
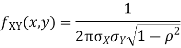
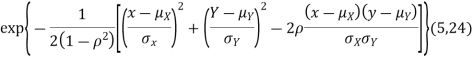
Where 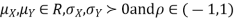 are all constants.
are all constants.
Properties 4:
Suppose X and Y are jointly normal random variables with parameters 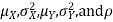 . Then given X = x, Y is normally distributed with
. Then given X = x, Y is normally distributed with
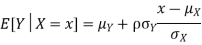
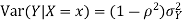
Example.
Let 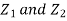 be two independent N (0, 1) random variables. Define
be two independent N (0, 1) random variables. Define
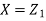
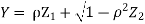
Where 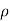 is a real number in (-1, 1).
is a real number in (-1, 1).
- Show that X and Y are bivariate normal.
- Find the joint PDF of X and Y.
- Find
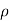 (X,Y)
(X,Y)
Solution.
First note that since 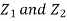 are normal and independent they are jointly normal with the joint PDF
are normal and independent they are jointly normal with the joint PDF
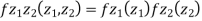
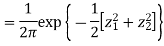
- We need to show aX + bY is normal for all. We have
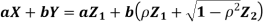
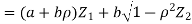
Which is the linear combination of 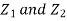 and thus it is normal.
and thus it is normal.
b. We can use the method of transformations (theorem 5.1) to find the joint PDF of X and Y. The inverse transformation is given by
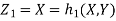
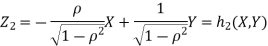
We have
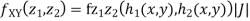
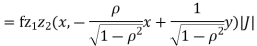
Where, 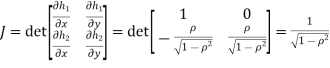
Thus we conclude that
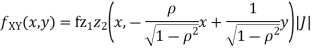
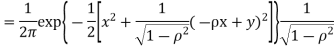
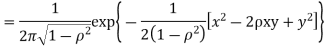
c. To find 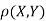 FIRST NOTE
FIRST NOTE
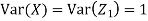
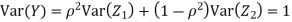
Therefore,
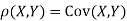
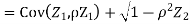
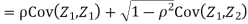
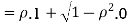
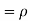
Example . Let X and Y be jointly normal random variable with parameters 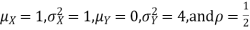
- Find P (2X+ Y≤3)
- Find
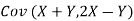
- Find
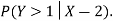
Solution.
- Since X and Y are jointly normal the random variables V =2 X +Y is normal. We have
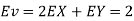
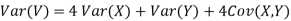
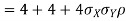
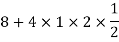
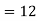
Thus V ~ N (2, 12). Therefore,
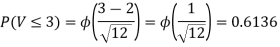
b. Note that Cov (X,Y)= 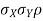 (X,Y) =1. We have
(X,Y) =1. We have
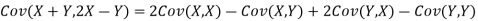
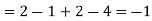
c. Using properties we conclude that given X =2, Y is normally distributed with
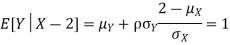
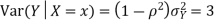
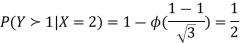
Given random variables X and Y that are defined on a probability space, the joint probability distribution for X and Y is a probability distribution that gives the probability that each of X and Y falls in any particular range or discrete set of values specified for that variable. In the case of only two random variables, this is called a bivariate distribution, but the concept generalizes to any number of random variables, giving a multivariate distribution.
The joint probability distribution can be expressed either in terms of a joint cumulative distribution function or in terms of a joint probability density function (in the case of continuous variables) or joint probability mass function (in the case of discrete variables). These in turn can be used to find two other types of distributions: the marginal distribution giving the probabilities for any one of the variables with no reference to any specific ranges of values for the other variables, and the conditional probability distribution giving the probabilities for any subset of the variables conditional on particular values of the remaining variables.
Example. A die is tossed thrice. A success is getting 1 or 6 on a toss. Find the mean and variance of the number of successes.
Solution. Probability of success 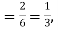 probability of failures
probability of failures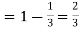
Probability of no success= probability of all three failures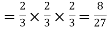
Probability of one successes and two failures 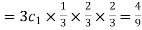
Probability of Two successes and one failure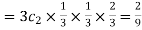
Probability of three successes 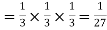
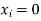 | 1 | 2 | 3 |
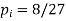 | 4/9 | 2/9 | 1/27 |
Mean 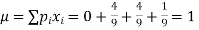
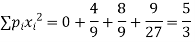
Variance ,
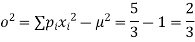
Example. Random variable X has the following probability function
x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P (x) | 0 | k | 2k | 2k | 3k | 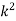 | 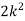 | 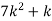 |
(i) Find the value of the k
(ii) Evaluate P (X < 6), P (X≥6)
Solution. (i) if X is a random variable then
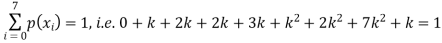
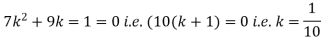
(ii)P (X < 6) =P( X=0) +P(X=1)+P(X=2)+ P(X=3) +P(X=4) + P (X=5)
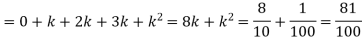
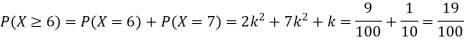
(iii) 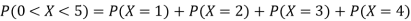
In probability theory assumed two jointly distributed R.V. X & Y the conditional probability distribution of Y given X is the probability distribution of Y when X is known to be a precise value; in some suitcases the conditional probabilities may be stated as functions containing the unnamedx value of X as a limitation. Once together X and Yare given variables, a conditional probability is characteristically used to indicate the conditional probability. The conditional distribution differences with the marginal distribution of a random variable, which is distribution deprived of reference to the value of the additional variable.
the conditional probability distribution of Y given X is the probability distribution of Y when X is known to be a precise value; in some suitcases the conditional probabilities may be stated as functions containing the unnamedx value of X as a limitation. Once together X and Yare given variables, a conditional probability is characteristically used to indicate the conditional probability. The conditional distribution differences with the marginal distribution of a random variable, which is distribution deprived of reference to the value of the additional variable.
If conditional distribution of Y under X is a continuous distribution, then probability density function is called as conditional density function. The properties of a conditional distribution, such as the moments, are frequently denoted to by corresponding names such as the conditional mean and conditional variance.
Let A and B be two events of a sample space S and let 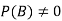 . Then conditional probability of the event A, given B, denoted by P (A/B) is defined by
. Then conditional probability of the event A, given B, denoted by P (A/B) is defined by
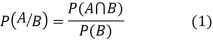
Theorem. If the events A and B defined on a sample space S of a random experiment are independent then
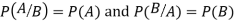
Proof. A and B are given to be independent events.
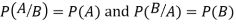
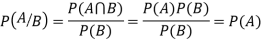
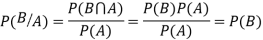
Bayes' rule
If 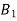 ,
, 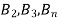 are mutually exclusive events with
are mutually exclusive events with 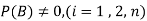 of a random experiment then for any arbitrary event
of a random experiment then for any arbitrary event 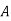 of the sample space of the above experiment with
of the sample space of the above experiment with 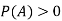 , we have
, we have
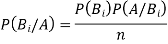
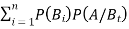 (for
(for 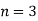 )
)
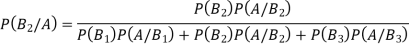
Example1: An urn  contains 3 white and 4 red balls and an urn lI contains 5 white and 6 red balls. One ball is drawn at random from one ofthe urns and isfound to be white. Find the probability that it was drawn from urn 1.
contains 3 white and 4 red balls and an urn lI contains 5 white and 6 red balls. One ball is drawn at random from one ofthe urns and isfound to be white. Find the probability that it was drawn from urn 1.
Solution: Let 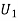 : the ball is drawn from urn I
: the ball is drawn from urn I
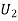 : the ball is drawn from urn II
: the ball is drawn from urn II
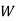 : the ball is white.
: the ball is white.
We have to find 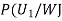
By Bayes Theorem
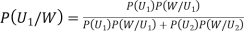 ... (1)
... (1)
Since two urns are equally likely to be selected, 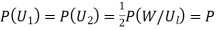 (a white ball is drawn from urn
(a white ball is drawn from urn  )
) 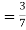
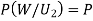 (a white ball is drawn from urn II)
(a white ball is drawn from urn II) 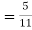
From(1), 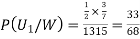
Example2: Three urns contains 6 red, 4 black, 4 red, 6 black; 5 red, 5 black balls respectively. One of the urns is selected at random and a ball is drawn from it. Lf the ball drawn is red find the probability that it is drawn from thefirst urn.
Solution: Let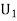 : the ball is drawn from urn 1.
: the ball is drawn from urn 1.
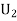 : the ball is drawn from urn lI.
: the ball is drawn from urn lI.
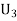 : the ball is drawn from urn 111.
: the ball is drawn from urn 111.
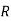 : the ball is red.
: the ball is red.
We have to find 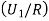 .
.
By Baye’s Theorem,
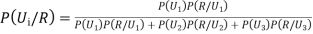 ... (1)
... (1)
Since the three urns are equally likely to be selected 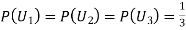
Also 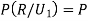 (a red ball is drawn from urn
(a red ball is drawn from urn 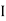 )
) 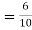
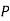 (R/
(R/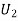 )
) 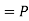 (a red ball is drawn from urn II)
(a red ball is drawn from urn II) 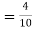
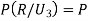 (a red ball is drawn from urn III)
(a red ball is drawn from urn III) 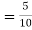
From (1), we have 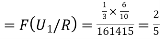
Example3: ln a bolt factory machines 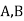 and
and 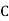 manufacturerespectively 25%, 35% and 40% of the total. Lf their output 5, 4 and 2 per cent are defective bolts. A bolt is drawn at random from the product and is found to be defective. What is the probability that it was manufactured by machine B.
manufacturerespectively 25%, 35% and 40% of the total. Lf their output 5, 4 and 2 per cent are defective bolts. A bolt is drawn at random from the product and is found to be defective. What is the probability that it was manufactured by machine B. ?
?
Solution: bolt is manufactured by machine 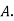
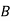 : bolt is manufactured by machine
: bolt is manufactured by machine 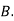
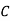 : bolt is manufactured by machine
: bolt is manufactured by machine 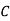
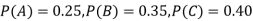
The probability ofdrawing a defective bolt manufactured by machine  is
is 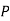 (D/A)
(D/A) 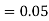
Similarly, 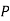 (D/B)
(D/B) 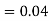 and
and 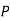 (D/C)
(D/C) 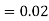
By Baye’s theorem
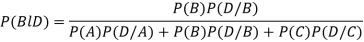
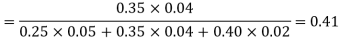
Unit–2
Continuous and Bivariate probability distribution
A continuous random variable is a random variable where the data can take infinitely many values. For example, a random variable measuring the time taken for something to be done is continuous since there are an infinite number of possible times that can be taken.
Continuous random variable is called by a probability density function p (x), with given properties: p (x) ≥ 0 and the area between the x-axis & the curve is 1: ... Standard deviation of a variable Random is defined by σ x = √Variance (x).
- A continuous random variable is known by a probability density function p(x), with these things: p(x) ≥ 0 and the area on the x-axis and the curve is 1:
∫-∞∞ p(x) dx = 1.
2. The expected value E(x) of a discrete variable is known as:
E(x) = Σi=1n xi pi
3. The expected value E(x) of a continuous variable is called as:
E(x) = ∫-∞∞ x p(x) dx
4. The Variance(x) of a random variable is known as Variance(x) = E[(x - E(x)2].
5. 2 random variable x and y are independent if E[xy] = E(x)E(y).
6. Standard deviation of a random variable is known asσx = √Variance(x).
7. Given value of standard error is used in its place of standard deviation when denoting to the sample mean.
σmean = σx / √n
8. If x is a normal random variable with limitsμ and σ2 (spread = σ), mark in symbols: x ˜ N(μ, σ2).
9. The sample variance of x1, x2, ..., xn is given by-
sx2 = |
|
10. If x1, x2, ... , xn are explanationssince a random sample, the sample standard deviation s is known the square root of variance:
sx = | √ |
|
11. Sample Co-variance of x1, x2, ..., xn is known-
sxy = |
|
12. A random vector is a column vector of random variable.
v = (x1 ... xn)T
13. Expected value of Random vector E(v) is known byvector of expected value of component.
If v = (x1 ... xn)T
E(v) = [E(x1) ... E(xn)]T
14. Co-variance of matrix Co-variance(v) of a random vector is the matrix of variances and Co-variance of component.
If v = (x1 ... xn)T, the ijth component of the Co-variance(v) is sij
Properties
Starting from properties 1 to 7, c is a constant; x and y are random variables.
- E(x + y) = E(x) + E(y).
- E(cx) = c E(y).
- Variance(x) = E(x2) - E(x)2
- If x and y are indiviadual, then Variance(x + y) = Variance(x) + Variance(y).
- Variance(x + c) = Variance(x)
- Variance(cx) = c2 Variance(x)
- Co-variance(x + c, y) = Co-variance(x, y)
- Co-variance(cx, y) = c Co-variance(x, y)
- Co-variance(x, y + c) = Co-variance(x, y)
- Co-variance(x, cy) = c Co-variance(x, y)
- If x1, x2, ...,xn are discrete and N(μ, σ2), then E(x) = μ. We say that x is neutral for μ.
- If x1, x2, ... ,xn are independent and N(μ, σ2), then E(s) = σ2. We can told S is neutral for σ2.
From given properties 8 to 12, w and v is random vector; b is a continuous vector; A is a continuous matrix.
8. E(v + w) = E(v) + E(w)
9. E(b) = b
10. E(Av) = A E(v)
11. Co-variance(v + b) = Co-variance(v)
12. Co-variance(Av) = A Co-variance(v) AT
Problem 1.
Let X be a random variable with PDF given by
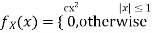
a, Find the constant c.
b. Find EX and Var (X).
c. Find P(X 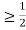 ).
).
Solution.
- To find c, we can use
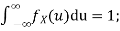
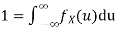
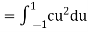
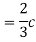
Thus we must have 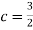 .
.
b. To find EX we can write
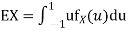
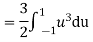
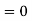
In fact, we could have guessed EX = 0 because the PDF is symmetric around x = 0. To find Var (X) we have
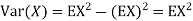
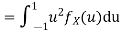
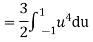
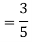
c. To find 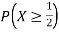 we can write
we can write
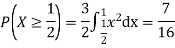
Problem 2. Let X be a continuous random variable with PDF given by
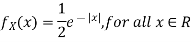
If 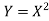 , find the CDF of Y.
, find the CDF of Y.
Solution. First we note that 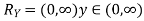 , we have
, we have
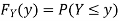
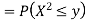
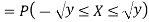
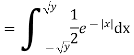
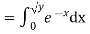
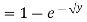
Thus, 
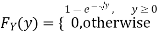
Problem 3. Let X be a continuous random variable with PDF
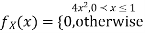
Find 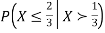 .
.
Solution. We have 
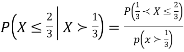
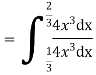
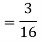
Probability Distribution:
A probability distribution is a arithmetical function which defines completely possible values &possibilities that a random variable can take in a given range. This range will be bounded between the minimum and maximum possible values. But exactly where the possible value is possible to be plotted on the probability distribution depends on a number of influences. These factors include the distribution's mean, SD, Skewness, and kurtosis.
Probability Density:
Probability density function (PDF) is a arithmetical appearance which gives a probability distribution for a discrete random variable as opposite to a continuous random variable. The difference among a discrete random variable is that we check an exact value of the variable. Like, the value for the variable, a stock worth, only goes two decimal points outside the decimal (Example 32.22), while a continuous variable have an countless number of values (Example 32.22564879…).
When the PDF is graphically characterized, the area under the curve will show the interval in which the variable will decline. The total area in this interval of the graph equals the probability of a discrete random variable happening. More exactly, since the absolute prospect of a continuous random variable taking on any exact value is zero owing to the endless set of possible values existing, the value of a PDF can be used to determine the likelihood of a random variable dropping within a exact range of values.
Example. The probability density function of a variable X is
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
P(X) | k | 3k | 5k | 7k | 9k | 11k | 13k |
(i) Find 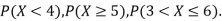
(ii) What will be e minimum value of k so that 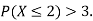
Solution. (i) If X is a random variable then
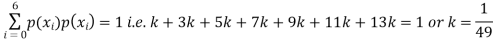
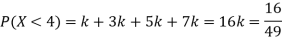
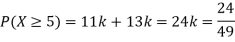
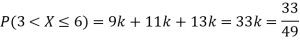
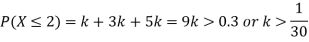
(ii)Thus minimum value of k=1/30.
Continuous probability distribution
When a variate X takes every value in an interval it gives rise to continuous distribution of X. The distribution defined by the vidiots like heights or weights are continuous distributions.
a major conceptual difference however exist between discrete and continuous probabilities. When thinking in discrete terms the probability associated with an event is meaningful. With continuous events however where the number of events is infinitely large, the probability that a specific event will occur is practically zero. For this reason continuous probability statements on must be worth did some work differently from discrete ones. Instead of finding the probability that x equals some value, we find the probability of x falling in a small interval.
Thus the probability distribution of a continuous variate x is defined by a function f (x) such that the probability of the variate x falling in the small interval 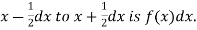 Symbolically it can be expressed as
Symbolically it can be expressed as 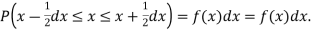 Thus f (x) is called the probability density function and then continuous curve y = f(x) is called the probability of curve.
Thus f (x) is called the probability density function and then continuous curve y = f(x) is called the probability of curve.
The range of the variable may be finite or infinite. But even when the range is finite, it is convenient to consider it as infinite by opposing the density function to be zero outside the given range. Thus if f (x) =(x) be the density function denoted for the variate x in the interval (a,b), then it can be written as
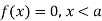
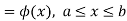
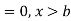
The density function f (x) is always positive and 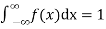 (i.e. the total area under the probability curve and the the x-axis is is unity which corresponds to the requirements that the total probability of happening of an event is unity).
(i.e. the total area under the probability curve and the the x-axis is is unity which corresponds to the requirements that the total probability of happening of an event is unity).
(2) Distribution function
If 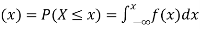
Then F(x) is defined as the commutative distribution function or simply the distribution function the continuous variate X. It is the probability that the value of the variate X will be ≤x. The graph of F(x) in this case is as shown in figure 26.3 (b).
The distribution function F (x) has the following properties
(i) 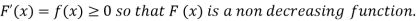
(ii) 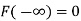
(iii) 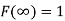
(iv) P(a ≤x ≤b)= 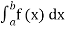 =
= 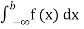 =F (b) – F (a).
=F (b) – F (a).
Example.
(i) Is the function defined as follows a density function.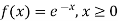
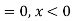
(ii) If so determine the probability that the variate having this density will fall in the interval (1.2).
(iii) Also find the cumulative probability function F (2)?
Solution. (i) f (x) is clearly ≥0 for every x in (1,2) and
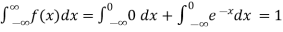
Hence the function f (x) satisfies the requirements for a density function.
(ii)Required probability = 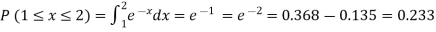
This probability is equal to the shaded area in figure 26.3 (a).
(iii)Cumulative probability function F(2)
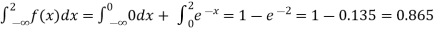
Which is shown in figure.
Exponential Distribution:
The exponential distribution is a C.D. Which is usually use to define to come time till some precise event happens. Like, the amount of time until a storm or other unsafe weather event occurs follows an exponential distribution law.
The one-parameter exponential distribution of the probability density function PDF is defined:
f(x)=λ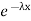 ,x≥0,
,x≥0,
Where, the rate λ signifies the
Normal amount of events in single time.
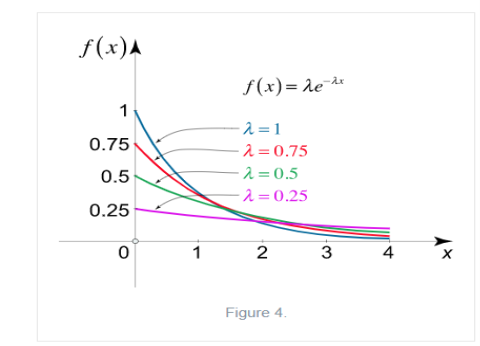
The mean value is μ=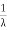 . The median of the exponential distribution is m=
. The median of the exponential distribution is m=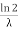 , and the variance is shown by
, and the variance is shown by 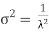 .
.
Normal Distribution:
Normal distribution
Now we consider continuous distribution of fundamental importance namely the normal distribution. Any quantity whose variation depends on random causes is distributed according to the normal law. Its importance lies in the fact that a large number of distributions approximate to the normal distribution.
Latest define a variate 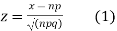
Where x no and S.D. 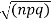 so that z is a very eighth with mean zero and variance unity. In the limit as n tends to infinity the distribution of z becomes a continuous distribution extending from
so that z is a very eighth with mean zero and variance unity. In the limit as n tends to infinity the distribution of z becomes a continuous distribution extending from 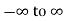 .
.
It can be shown that the limiting form of the binomial distribution (1) for large values of n when neither p nor q is very small is the normal distribution. The normal curve is of the form
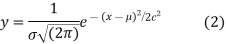
Where μ and 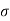 are the mean and standard deviation respectively..
are the mean and standard deviation respectively..
The normal distribution is the utmost broadly identified P.D. Then it defines many usual spectacles.
The PDF of the normal distribution is shown by method
f(x)=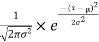 ,
,
Where μ is mean of the distribution, and 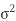 is the variance.
is the variance.
The 2 limitations μ and σ completely describe the figure and all additional things of the normal distribution function.
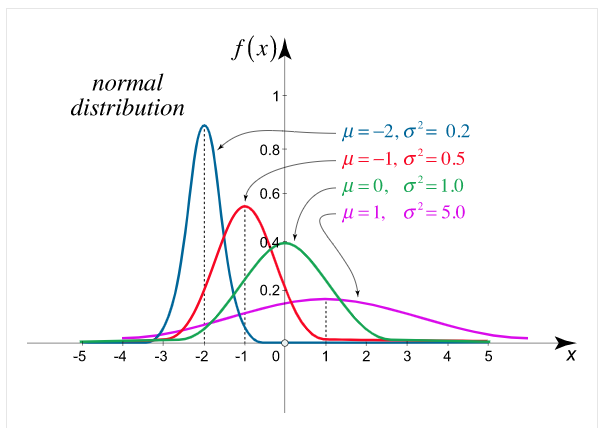
Example. X is a normal variate with mean 30 and S.D. 5, find the probabilities that
(i) 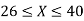
(ii) 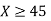
(iii) |X-30|≥5
Solution. We have μ =30 and 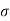 =5
=5
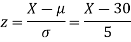
(i) When X = 26,z = -0.8, when X =40, z =-2
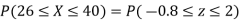
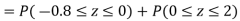
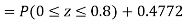
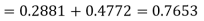
(ii) When X =45, z =3
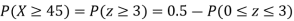
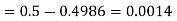
(iii) 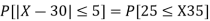
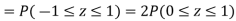
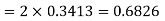
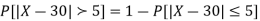
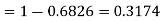
Example. In a normal distribution 31% of the items are under 45 and 8% are over 64. Find the mean and standard deviation of the distribution.
Solution. Let 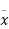 be the mean and
be the mean and 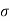 the standard deviation 31% of the items are under 45 means area to the left of the ordinate x = 45 (figure 26.6)
the standard deviation 31% of the items are under 45 means area to the left of the ordinate x = 45 (figure 26.6)
When x = 45, let z 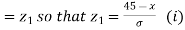
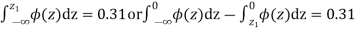
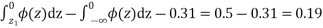
From table III 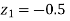
When x = 64, let 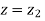 so that
so that 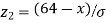
Hence, 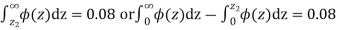
From table III 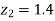
From (i) and (ii), 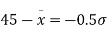
From (iii) and (iv), 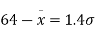
Solving these equations we get 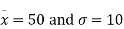
Example. In a test on 2000 electric bulbs, it was found that the life of a particular make was normally distributed with an average life of 2040 hours and standard deviation of 60 hours. Estimated number of bulbs likely to burn for
(a) More than 2150 hours
(b) Less than 1950 hours and
(c) More than 1920 hours and but less than 2 160 hours
Solution. Here μ = 2040 hours and 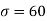 hours
hours
(a) For x = 2150, 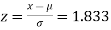
Area against z = 1.83 in the table III = 0.4664
We however require the area to the right of the ordinate at z = 1.83. This area = 0.5-0.4664=0.0336
Thus the number of bulbs expected to burn for more than 2150 hours.
= 0.0336×2000 = 67 approximately
(b) For x = 1950, 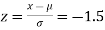
The area required in this case is to be left of z = -1.33
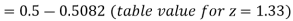
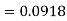
Therefore the number of bulbs expected to burn for less than 1950 hours
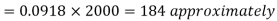
(c) When x = 1920, 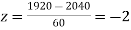
When x = 2160, 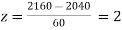
The number of bulbs expected to learn for more than 1920 hours but less than 2160 hours will be represented by the area between z = -2 and z = 2. This is twice the area from the table for z =2, i.e. 2 × 0.4772=0.9544
Thus required number of bulbs = 0.9544 × 2000 = 1909 nearly
Gamma density
Consider the distribution of the sum of 2autonomous Exponential (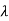 ) R.V.
) R.V.
Density of the form:
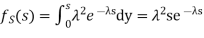
Density is known Gamma (2,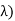 density. In common the gamma density is precise with 2 reasons (t,
density. In common the gamma density is precise with 2 reasons (t,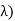 as being non zero on the +ve reals and called:
as being non zero on the +ve reals and called:
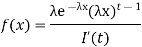
Where F (t) is the endless which symbols integral of the density quantity to one:
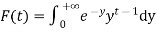
By integration by parts we presented the significant recurrence relative:
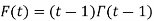
Because 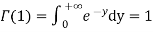 , we have for integer t=m
, we have for integer t=m
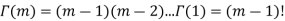
The specific case of the integer t can be linked to the sum of n independent exponential, it is the waiting time to the nth event, it is the matching of the negative binomial.
From that we can estimate what the estimated value and the variance are going to be: If all the Xi's are independent exponential (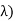 , then if we sum n of them we
, then if we sum n of them we
Have 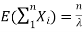 and if they are independent:
and if they are independent: 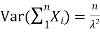
This simplifies to the non-integer t case:
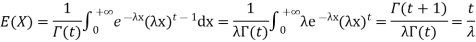
Example1: Following probability distribution
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P(x) | 0 | 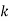 | 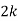 | 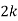 | 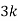 | 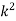 | 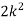 | 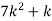 |
Find: (i) k (ii) 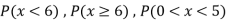
(i) Distribution function
(ii) If 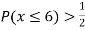 find minimum value of C
find minimum value of C
(iii) Find 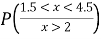
Solution:
If P(x) is p.m.f –
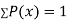
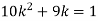
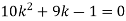
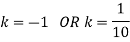
(i)
X | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P(x) | 0 | 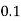 | 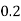 | 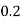 | 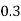 | 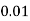 | 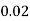 | 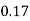 |
(ii)
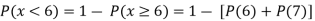
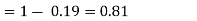
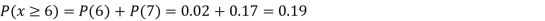
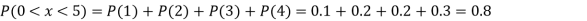
(iii)
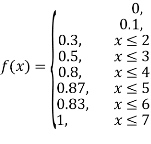
(iv)
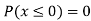
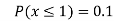
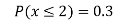
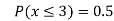
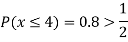
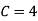
(v)
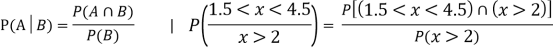
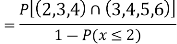
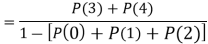
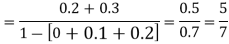
Example 2. I choose real number uniformly at random in the interval [a, b], and call it X. Buy uniformly at random, we mean all intervals in [a, b] that have the same length must have the same probability. Find the CDF of X.
Solution.
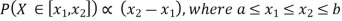
Since 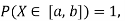 we conclude
we conclude
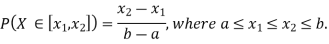
Now, let us find the CDF. By definition 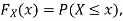 thus immediately have
thus immediately have
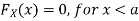
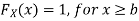
For 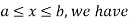
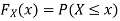
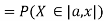
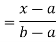
Thus, to summarize
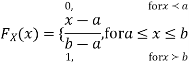
Note that hear it does not matter if we use “<” or “≤” as each individual point has probability zero, so for example 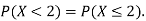 Figure 4.1 shows the CDF of X. As we expect the CDF starts at 0 at end at 1.
Figure 4.1 shows the CDF of X. As we expect the CDF starts at 0 at end at 1.
Example 3.
Find the mean value μ and the median m of the exponential distribution 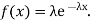
Solution. The mean value μ is determined by the integral
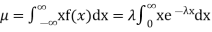
Integrating by parts we have
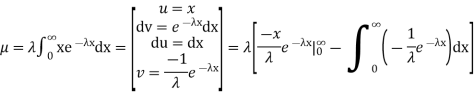
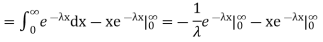
We evaluate the second term with the help of 1 Hopital's Rule:
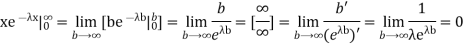
Hence the mean (average) value of the exponential distribution is
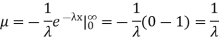
Determine the median m
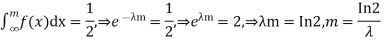
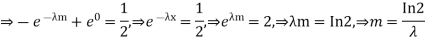
A bivariate distribution, setonly, is the probability that a definite event will happen when there are 2 independent random variables in your scenario. E.g, having two bowls, individually complete with 2dissimilarkinds of candies, and drawing one candy from each bowl gives you 2 independent random variables, the 2dissimilar candies. Since you are pulling one candy from each bowl at the same time, you have a bivariate distribution when calculating your probability of finish up with specific types of candies.
Properties:
Properties 1. Two random variables X and Y are said to be bivariate normal, or jointly normal distribution for all 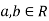
Properties 2:
Two random variables X and Y are set to have the standard bivariate normal distribution with correlation efficient if their joint PDF is given by
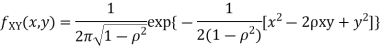
Where 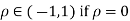 then we just say X and Y have the standard by will it normal distribution.
then we just say X and Y have the standard by will it normal distribution.
Properties 3:
Two random variables X and Y are set to have a bivariate normal distribution with parameters 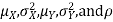 if their joint PDF is given by
if their joint PDF is given by
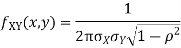
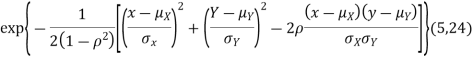
Where 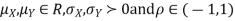 are all constants.
are all constants.
Properties 4:
Suppose X and Y are jointly normal random variables with parameters 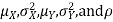 . Then given X = x, Y is normally distributed with
. Then given X = x, Y is normally distributed with
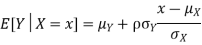
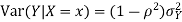
Example.
Let 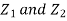 be two independent N (0, 1) random variables. Define
be two independent N (0, 1) random variables. Define
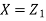
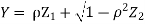
Where 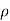 is a real number in (-1, 1).
is a real number in (-1, 1).
- Show that X and Y are bivariate normal.
- Find the joint PDF of X and Y.
- Find
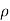 (X,Y)
(X,Y)
Solution.
First note that since 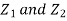 are normal and independent they are jointly normal with the joint PDF
are normal and independent they are jointly normal with the joint PDF
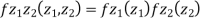
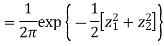
- We need to show aX + bY is normal for all. We have
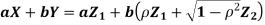
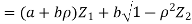
Which is the linear combination of 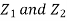 and thus it is normal.
and thus it is normal.
b. We can use the method of transformations (theorem 5.1) to find the joint PDF of X and Y. The inverse transformation is given by
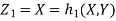
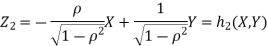
We have
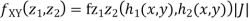
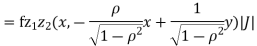
Where, 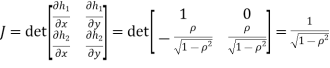
Thus we conclude that
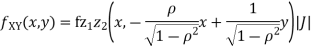
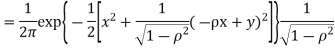
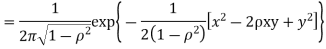
c. To find 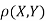 FIRST NOTE
FIRST NOTE
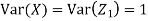
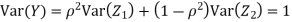
Therefore,
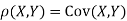
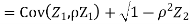
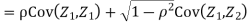
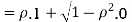
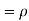
Example . Let X and Y be jointly normal random variable with parameters 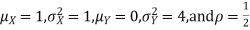
- Find P (2X+ Y≤3)
- Find
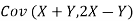
- Find
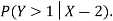
Solution.
- Since X and Y are jointly normal the random variables V =2 X +Y is normal. We have
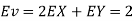
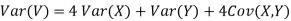
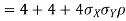
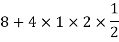
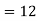
Thus V ~ N (2, 12). Therefore,
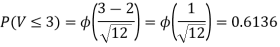
b. Note that Cov (X,Y)= 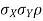 (X,Y) =1. We have
(X,Y) =1. We have
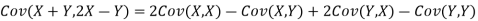
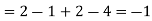
c. Using properties we conclude that given X =2, Y is normally distributed with
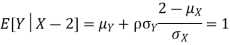
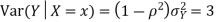
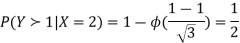
Given random variables X and Y that are defined on a probability space, the joint probability distribution for X and Y is a probability distribution that gives the probability that each of X and Y falls in any particular range or discrete set of values specified for that variable. In the case of only two random variables, this is called a bivariate distribution, but the concept generalizes to any number of random variables, giving a multivariate distribution.
The joint probability distribution can be expressed either in terms of a joint cumulative distribution function or in terms of a joint probability density function (in the case of continuous variables) or joint probability mass function (in the case of discrete variables). These in turn can be used to find two other types of distributions: the marginal distribution giving the probabilities for any one of the variables with no reference to any specific ranges of values for the other variables, and the conditional probability distribution giving the probabilities for any subset of the variables conditional on particular values of the remaining variables.
Example. A die is tossed thrice. A success is getting 1 or 6 on a toss. Find the mean and variance of the number of successes.
Solution. Probability of success 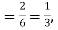 probability of failures
probability of failures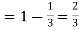
Probability of no success= probability of all three failures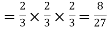
Probability of one successes and two failures 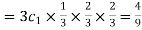
Probability of Two successes and one failure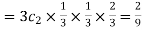
Probability of three successes 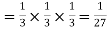
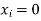 | 1 | 2 | 3 |
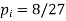 | 4/9 | 2/9 | 1/27 |
Mean 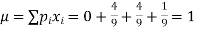
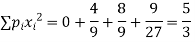
Variance ,
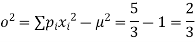
Example. Random variable X has the following probability function
x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
P (x) | 0 | k | 2k | 2k | 3k | 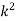 | 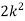 | 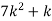 |
(i) Find the value of the k
(ii) Evaluate P (X < 6), P (X≥6)
Solution. (i) if X is a random variable then
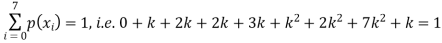
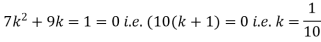
(ii)P (X < 6) =P( X=0) +P(X=1)+P(X=2)+ P(X=3) +P(X=4) + P (X=5)
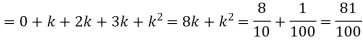
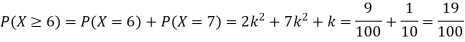
(iii) 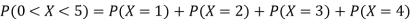
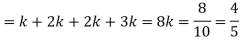
In probability theory assumed two jointly distributed R.V. X & Y the conditional probability distribution of Y given X is the probability distribution of Y when X is known to be a precise value; in some suitcases the conditional probabilities may be stated as functions containing the unnamedx value of X as a limitation. Once together X and Yare given variables, a conditional probability is characteristically used to indicate the conditional probability. The conditional distribution differences with the marginal distribution of a random variable, which is distribution deprived of reference to the value of the additional variable.
the conditional probability distribution of Y given X is the probability distribution of Y when X is known to be a precise value; in some suitcases the conditional probabilities may be stated as functions containing the unnamedx value of X as a limitation. Once together X and Yare given variables, a conditional probability is characteristically used to indicate the conditional probability. The conditional distribution differences with the marginal distribution of a random variable, which is distribution deprived of reference to the value of the additional variable.
If conditional distribution of Y under X is a continuous distribution, then probability density function is called as conditional density function. The properties of a conditional distribution, such as the moments, are frequently denoted to by corresponding names such as the conditional mean and conditional variance.
Let A and B be two events of a sample space S and let 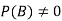 . Then conditional probability of the event A, given B, denoted by P (A/B) is defined by
. Then conditional probability of the event A, given B, denoted by P (A/B) is defined by
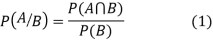
Theorem. If the events A and B defined on a sample space S of a random experiment are independent then
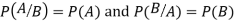
Proof. A and B are given to be independent events.
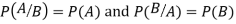
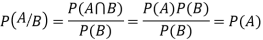
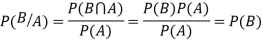
Bayes' rule
If 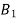 ,
, 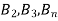 are mutually exclusive events with
are mutually exclusive events with 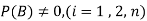 of a random experiment then for any arbitrary event
of a random experiment then for any arbitrary event 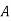 of the sample space of the above experiment with
of the sample space of the above experiment with 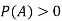 , we have
, we have
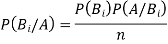
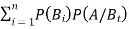 (for
(for 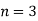 )
)
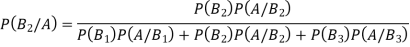
Example1: An urn  contains 3 white and 4 red balls and an urn lI contains 5 white and 6 red balls. One ball is drawn at random from one ofthe urns and isfound to be white. Find the probability that it was drawn from urn 1.
contains 3 white and 4 red balls and an urn lI contains 5 white and 6 red balls. One ball is drawn at random from one ofthe urns and isfound to be white. Find the probability that it was drawn from urn 1.
Solution: Let 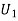 : the ball is drawn from urn I
: the ball is drawn from urn I
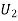 : the ball is drawn from urn II
: the ball is drawn from urn II
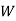 : the ball is white.
: the ball is white.
We have to find 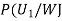
By Bayes Theorem
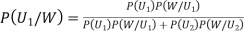 ... (1)
... (1)
Since two urns are equally likely to be selected, 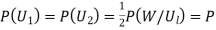 (a white ball is drawn from urn
(a white ball is drawn from urn 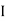 )
) 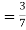
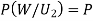 (a white ball is drawn from urn II)
(a white ball is drawn from urn II) 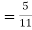
From(1), 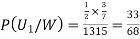
Example2: Three urns contains 6 red, 4 black, 4 red, 6 black; 5 red, 5 black balls respectively. One of the urns is selected at random and a ball is drawn from it. Lf the ball drawn is red find the probability that it is drawn from thefirst urn.
Solution: Let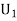 : the ball is drawn from urn 1.
: the ball is drawn from urn 1.
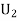 : the ball is drawn from urn lI.
: the ball is drawn from urn lI.
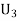 : the ball is drawn from urn 111.
: the ball is drawn from urn 111.
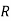 : the ball is red.
: the ball is red.
We have to find 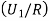 .
.
By Baye’s Theorem,
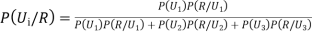 ... (1)
... (1)
Since the three urns are equally likely to be selected 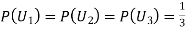
Also 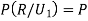 (a red ball is drawn from urn
(a red ball is drawn from urn  )
) 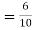
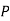 (R/
(R/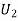 )
) 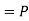 (a red ball is drawn from urn II)
(a red ball is drawn from urn II) 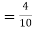
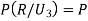 (a red ball is drawn from urn III)
(a red ball is drawn from urn III) 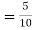
From (1), we have 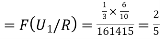
Example3: ln a bolt factory machines 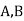 and
and 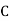 manufacturerespectively 25%, 35% and 40% of the total. Lf their output 5, 4 and 2 per cent are defective bolts. A bolt is drawn at random from the product and is found to be defective. What is the probability that it was manufactured by machine B.
manufacturerespectively 25%, 35% and 40% of the total. Lf their output 5, 4 and 2 per cent are defective bolts. A bolt is drawn at random from the product and is found to be defective. What is the probability that it was manufactured by machine B.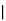 ?
?
Solution: bolt is manufactured by machine 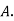
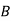 : bolt is manufactured by machine
: bolt is manufactured by machine 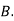
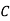 : bolt is manufactured by machine
: bolt is manufactured by machine 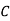
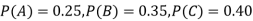
The probability ofdrawing a defective bolt manufactured by machine 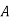 is
is 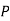 (D/A)
(D/A) 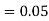
Similarly, 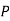 (D/B)
(D/B) 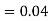 and
and 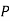 (D/C)
(D/C) 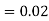
By Baye’s theorem