Unit 1
Introduction to Programming
In general terms, the architecture of a computer system can be considered as a catalogue of tools or attributes that are visible to the user such as instruction sets, number of bits used for data, addressing techniques, etc.
Whereas, Organization of a computer system defines the way system is structured so that all those catalogued tools can be used. The significant components of Computer organization are ALU, CPU, memory and memory organization.
A memory is just like a human brain. It is used to store data and instructions. Computer memory is the storage space in the computer, where data is to be processed and instructions required for processing are stored. The memory is divided into large number of small parts called cells. Each location or cell has a unique address, which varies from zero to memory size minus one. For example, if the computer has 64k words, then this memory unit has 64 * 1024 = 65536 memory locations. The address of these locations varies from 0 to 65535.
Memory is primarily of three types −
- Cache Memory
- Primary Memory/Main Memory
- Secondary Memory
Cache Memory
Cache memory is a very high speed semiconductor memory which can speed up the CPU. It acts as a buffer between the CPU and the main memory. It is used to hold those parts of data and program which are most frequently used by the CPU. The parts of data and programs are transferred from the disk to cache memory by the operating system, from where the CPU can access them.

Advantages
The advantages of cache memory are as follows −
- Cache memory is faster than main memory.
- It consumes less access time as compared to main memory.
- It stores the program that can be executed within a short period of time.
- It stores data for temporary use.
Disadvantages
The disadvantages of cache memory are as follows −
- Cache memory has limited capacity.
- It is very expensive.
Primary Memory (Main Memory)
Primary memory holds only those data and instructions on which the computer is currently working. It has a limited capacity and data is lost when power is switched off. It is generally made up of semiconductor device. These memories are not as fast as registers. The data and instruction required to be processed resides in the main memory. It is divided into two subcategories RAM and ROM.

Characteristics of Main Memory
- These are semiconductor memories.
- It is known as the main memory.
- Usually volatile memory.
- Data is lost in case power is switched off.
- It is the working memory of the computer.
- Faster than secondary memories.
- A computer cannot run without the primary memory.
Secondary Memory
This type of memory is also known as external memory or non-volatile. It is slower than the main memory. These are used for storing data/information permanently. CPU directly does not access these memories, instead they are accessed via input-output routines. The contents of secondary memories are first transferred to the main memory, and then the CPU can access it. For example, disk, CD-ROM, DVD, etc.

Characteristics of Secondary Memory
- These are magnetic and optical memories.
- It is known as the backup memory.
- It is a non-volatile memory.
- Data is permanently stored even if power is switched off.
- It is used for storage of data in a computer.
- Computer may run without the secondary memory.
- Slower than primary memories.
Processor
A processor, or "microprocessor," is a small chip that resides in computers and other electronic devices. Its basic job is to receive input and provide the appropriate output. While this may seem like a simple task, modern processors can handle trillions of calculations per second.
The central processor of a computer is also known as the CPU, or "central processing unit." This processor handles all the basic system instructions, such as processing mouse and keyboard input and running applications. Most desktop computers contain a CPU developed by either Intel or AMD, both of which use the x86 processor architecture. Mobile devices, such as laptops and tablets may use Intel and AMD CPUs, but can also use specific mobile processors developed by companies like ARM or Apple.
Modern CPUs often include multiple processing cores, which work together to process instructions. While these "cores" are contained in one physical unit, they are actually individual processors. In fact, if you view your computer's performance with a system monitoring utility like Windows Task Manager (Windows) or Activity Monitor (Mac OS X), you will see separate graphs for each processor. Processors that include two cores are called dual core processors, while those with four cores are called quad core processors. Some high-end workstations contain multiple CPUs with multiple cores, allowing a single machine to have eight, twelve, or even more processing cores.
Besides the central processing unit, most desktop and laptop computers also include a GPU. This processor is specifically designed for rendering graphics that are output on a monitor. Desktop computers often have a video card that contains the GPU, while mobile devices usually contain a graphics chip that is integrated into the motherboard. By using separate processors for system and graphics processing, computers are able to handle graphic-intensive applications more efficiently.
Operating system
What is an Operating System?
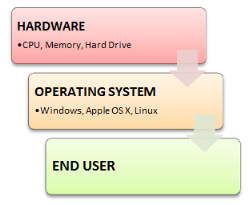
An Operating system (OS) is a software which acts as an interface between the end user and computer hardware. Every computer must have at least one OS to run other programs. An application like Chrome, MS Word, Games, etc needs some environment in which it will run and perform its task. The OS helps you to communicate with the computer without knowing how to speak the computer's language. It is not possible for the user to use any computer or mobile device without having an operating system.
Introduction Operating System
History Of OS
- Operating systems were first developed in the late 1950s to manage tape storage
- The General Motors Research Lab implemented the first OS in the early 1950s for their IBM 701
- In the mid-1960s, operating systems started to use disks
- In the late 1960s, the first version of the Unix OS was developed
- The first OS built by Microsoft was DOS. It was built in 1981 by purchasing the 86-DOS software from a Seattle company
- The present-day popular OS Windows first came to existence in 1985 when a GUI was created and paired with MS-DOS.
Features of Operating System
Here is a list commonly found important features of an Operating System:
- Protected and supervisor mode
- Allows disk access and file systems Device drivers Networking Security
- Program Execution
- Memory management Virtual Memory Multitasking
- Handling I/O operations
- Manipulation of the file system
- Error Detection and handling
- Resource allocation
- Information and Resource Protection
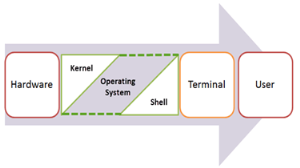
What is a Kernel?
The kernel is the central component of a computer operating systems. The only job performed by the kernel is to the manage the communication between the software and the hardware. A Kernel is at the nucleus of a computer. It makes the communication between the hardware and software possible. While the Kernel is the innermost part of an operating system, a shell is the outermost one.
Features of Kennel
- Low-level scheduling of processes
- Inter-process communication
- Process synchronization
- Context switching
Types of Kernels
There are many types of kernels that exists, but among them, the two most popular kernels are:
1.Monolithic
A monolithic kernel is a single code or block of the program. It provides all the required services offered by the operating system. It is a simplistic design which creates a distinct communication layer between the hardware and software.
2. Microkernels
Microkernel manages all system resources. In this type of kernel, services are implemented in different address space. The user services are stored in user address space, and kernel services are stored under kernel address space. So, it helps to reduce the size of both the kernel and operating system.
Functions of an Operating System
Function of an Operating System
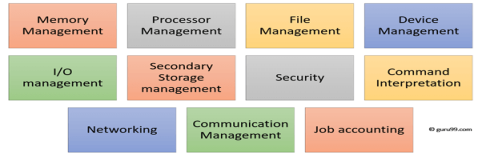
In an operating system software performs each of the function:
- Process management:- Process management helps OS to create and delete processes. It also provides mechanisms for synchronization and communication among processes.
2. Memory management:- Memory management module performs the task of allocation and de-allocation of memory space to programs in need of this resources.
3. File management:- It manages all the file-related activities such as organization storage, retrieval, naming, sharing, and protection of files.
4. Device Management: Device management keeps tracks of all devices. This module also responsible for this task is known as the I/O controller. It also performs the task of allocation and de-allocation of the devices.
5. I/O System Management: One of the main objects of any OS is to hide the peculiarities of that hardware devices from the user.
6. Secondary-Storage Management: Systems have several levels of storage which includes primary storage, secondary storage, and cache storage. Instructions and data must be stored in primary storage or cache so that a running program can reference it.
7. Security:- Security module protects the data and information of a computer system against malware threat and authorized access.
8. Command interpretation: This module is interpreting commands given by the and acting system resources to process that commands.
9. Networking: A distributed system is a group of processors which do not share memory, hardware devices, or a clock. The processors communicate with one another through the network.
10. Job accounting: Keeping track of time & resource used by various job and users.
11. Communication management: Coordination and assignment of compilers, interpreters, and another software resource of the various users of the computer systems.
Types of Operating system
- Batch Operating System
- Multitasking/Time Sharing OS
- Multiprocessing OS
- Real Time OS
- Distributed OS
- Network OS
- Mobile OS
Batch Operating System
Some computer processes are very lengthy and time-consuming. To speed the same process, a job with a similar type of needs are batched together and run as a group.
The user of a batch operating system never directly interacts with the computer. In this type of OS, every user prepares his or her job on an offline device like a punch card and submit it to the computer operator.
Multi-Tasking/Time-sharing Operating systems
Time-sharing operating system enables people located at a different terminal(shell) to use a single computer system at the same time. The processor time (CPU) which is shared among multiple users is termed as time sharing.
Real time OS
A real time operating system time interval to process and respond to inputs is very small. Examples: Military Software Systems, Space Software Systems.
Distributed Operating System
Distributed systems use many processors located in different machines to provide very fast computation to its users.
Network Operating System
Network Operating System runs on a server. It provides the capability to serve to manage data, user, groups, security, application, and other networking functions.
Mobile OS
Mobile operating systems are those OS which is especially that are designed to power smartphones, tablets, and wearables devices.
Some most famous mobile operating systems are Android and iOS, but others include BlackBerry, Web, and watchOS.
Difference between Firmware and Operating System
Firmware | Operating System |
Firmware is one kind of programming that is embedded on a chip in the device which controls that specific device. | OS provides functionality over and above that which is provided by the firmware. |
Firmware is programs that been encoded by the manufacture of the IC or something and cannot be changed. | OS is a program that can be installed by the user and can be changed. |
It is stored on non-volatile memory. | OS is stored on the hard drive. |
Difference between 32-Bit vs. 64 Bit Operating System
Parameters | 32. Bit | 64. Bit |
Architecture and Software | Allow 32 bit of data processing simultaneously | Allow 64 bit of data processing simultaneously |
Compatibility | 32-bit applications require 32-bit OS and CPUs. | 64-bit applications require a 64-bit OS and CPU. |
Systems Available | All versions of Windows 8, Windows 7, Windows Vista, and Windows XP, Linux, etc. | Windows XP Professional, Vista, 7, Mac OS X and Linux. |
Memory Limits | 32-bit systems are limited to 3.2 GB of RAM. | 64-bit systems allow a maximum 17 Billion GB of RAM. |
The advantage of using Operating System
- Allows you to hide details of hardware by creating an abstraction
- Easy to use with a GUI
- Offers an environment in which a user may execute programs/applications
- The operating system must make sure that the computer system convenient to use
- Operating System acts as an intermediary among applications and the hardware components
- It provides the computer system resources with easy to use format
- Acts as an intermediator between all hardware's and software's of the system
Disadvantages of using Operating System
- If any issue occurs in OS, you may lose all the contents which have been stored in your system
- Operating system's software is quite expensive for small size organization which adds burden on them. Example Windows
- It is never entirely secure as a threat can occur at any time
Summary
- An operating system is a software which acts as an interface between the end user and computer hardware
- Operating systems were first developed in the late 1950s to manage tape storage
- The kernel is the central component of a computer operating systems. The only job performed by the kernel is to the manage the communication between the software and the hardware.
- Two most popular kernels are Monolithic and Micro Kernels.
- Process, Device, File, I/O, Secondary-Storage, Memory management are various functions of an Operating System
- Batch, Multitasking/Time Sharing, Multiprocessing, Real Time, Distributed, Network, Mobile are various types of Operating Systems
Compiling and executing a Program
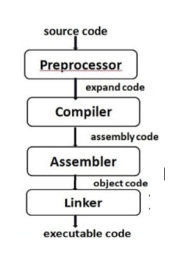
When you type cc at the command line a lot of stuff happens. There are four entities involved in the compilation process: preprocessor, compiler, assembler, linker (see Figure 1).
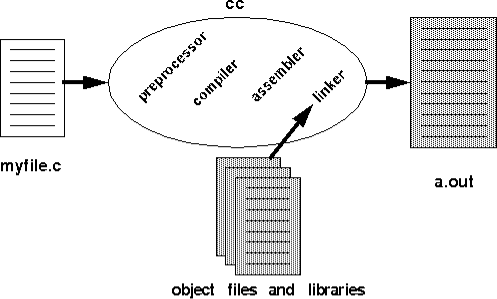
Figure 1: The internals of cc.
First, the C preprocessor cpp expands all those macros definitions and include statements (and anything else that starts with a #) and passes the result to the actual compiler. The preprocessor is not so interesting because it just replaces some short cuts you used in your code with more code. The output of cpp is just C code; if you didn't have any preprocessor statements in your file, you wouldn't need to run cpp. The preprocessor does not require any knowledge about the target architecture. If you had the correct include files, you could preprocess your C files on a LINUX machine and take the output to the instructional machines and pass that to cc. To see the output of a preprocessed file, use cc -E.
The compiler effectively translates preprocessed C code into assembly code, performing various optimizations along the way as well as register allocation. Since a compiler generates assembly code specific to a particular architecture, you cannot use the assembly output of cc from an Intel Pentium machine on one of the instructional machines (Digital Alpha machines). Compilers are very interesting which is one of the reasons why the department offers an entire course on compilers (CSE 401). To see the assembly code produced by the compiler, use cc -S.
The assembly code generated by the compilation step is then passed to the assembler which translates it into machine code; the resulting file is called an object file. On the instructional machines, both cc and gcc use the native assembler as that is provided by UNIX. You could write an assembly language program and pass it directly to as and even to cc (this is what we do in project 2 with sys.s). An object file is a binary representation of your program. The assembler gives a memory location to each variable and instruction; we will see later that these memory locations are actually represented symbolically or via offsets. It also make a lists of all the unresolved references that presumably will be defined in other object file or libraries, e.g. printf. A typical object file contains the program text (instructions) and data (constants and strings), information about instructions and data that depend on absolute addresses, a symbol table of unresolved references, and possibly some debugging information. The UNIX command nm allows you to look at the symbols (both defined and unresolved) in an object file.
Since an object file will be linked with other object files and libraries to produce a program, the assembler cannot assign absolute memory locations to all the instructions and data in a file. Rather, it writes some notes in the object file about how it assumed things were layed out. It is the job of the linker to use these notes to assign absolute memory locations to everything and resolve any unresolved references. Again, both cc and gcc on the instructional machines use the native linker, ld. Some compilers chose to have their own linkers, so that optimizations can be performed at link time; one such optimization is that of aligning procedures on page boundaries. The linker produces a binary executable that can be run from the command interface.
Notice that you could invoke each of the above steps by hand. Since it is an annoyance to call each part separately as well as pass the correct flags and files, cc does this for you. For example, you could run the entire process by hand by invoking /lib/cpp and then cc -S and then /bin/as and finally ld. If you think this is easy, try compiling a simple program in this way.
Running a Program
When you type a.out at the command line, a whole bunch of things must happen before your program is actually run. The loader magically does these things for you. On UNIX systems, the loader creates a process. This involves reading the file and creating an address space for the process. Page table entries for the instructions, data and program stack are created and the register set is initialized. Then the loader executes a jump instruction to the first instruction in the program. This generally causes a page fault and the first page of your instructions is brought into memory. On some systems the loader is a little more interesting. For example, on systems like Windows NT that provide support for dynamically loaded libraries (DLLs), the loader must resolve references to such libraries similar to the way a linker does.
Memory
Figure 2 illustrates a typical layout for program memory. It is the job of the loader to map the program, static data (including globals and strings) and the stack to physical addresses. Notice that the stack is mapped to the high addresses and grows down and the program and data are mapped to the low addresses. The area labeled heap is where the data you allocate via malloc is placed. A call to malloc may use the sbrk system call to add more physical pages to the program's address space (for more information on malloc, free and sbrk, see the man pages).
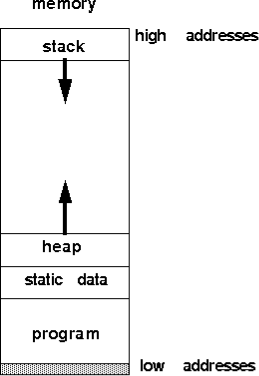
Figure 2: Memory layout.
Procedure Call Conventions
A call to a procedure is a context switch in your program. Just like any other context switch, some state must be saved by the calling procedure, or caller, so that when the called procedure, or callee, returns the caller may continue execution without distraction. To enable separate compilation, a compiler must follow a set of rules for use of the registers when calling procedures. This procedure call convention may be different across compilers (does cc and gcc use the same calling convention?) which is why object files created by one compiler cannot always be linked with that of another compiler.
A typical calling convention involves action on the part of the caller and the callee. The caller places the arguments to the callee in some agreed upon place; this place is usually a few registers and the extras are passed on the stack (the stack pointer may need to be updated). Then the caller saves the value of any registers it will need after the call and jumps to the callee's first instruction. The callee then allocates memory for its stack frame and saves any registers who's values are guaranteed to be unaltered through a procedure call, e.g. return address. When the callee is ready to return, it places the return value, if any, in a special register and restores the callee-saved registers. It then pops the stack frame and jumps to the return address.
When we type some letters or words, the computer translates them in numbers as computers can understand only numbers. A computer can understand the positional number system where there are only a few symbols called digits and these symbols represent different values depending on the position they occupy in the number.
The value of each digit in a number can be determined using −
- The digit
- The position of the digit in the number
- The base of the number system (where the base is defined as the total number of digits available in the number system)
Decimal Number System
The number system that we use in our day-to-day life is the decimal number system. Decimal number system has base 10 as it uses 10 digits from 0 to 9. In decimal number system, the successive positions to the left of the decimal point represent units, tens, hundreds, thousands, and so on.
Each position represents a specific power of the base (10). For example, the decimal number 1234 consists of the digit 4 in the units position, 3 in the tens position, 2 in the hundreds position, and 1 in the thousands position. Its value can be written as
(1 x 1000)+ (2 x 100)+ (3 x 10)+ (4 x l)
(1 x 103)+ (2 x 102)+ (3 x 101)+ (4 x l00)
1000 + 200 + 30 + 4
1234
As a computer programmer or an IT professional, you should understand the following number systems which are frequently used in computers.
S.No. | Number System and Description |
1 | Binary Number System Base 2. Digits used : 0, 1 |
2 | Octal Number System Base 8. Digits used : 0 to 7 |
3 | Hexa Decimal Number System Base 16. Digits used: 0 to 9, Letters used : A- F |
Binary Number System
Characteristics of the binary number system are as follows −
- Uses two digits, 0 and 1
- Also called as base 2 number system
- Each position in a binary number represents a 0 power of the base (2). Example 20
- Last position in a binary number represents a x power of the base (2). Example 2x where x represents the last position - 1.
Example
Binary Number: 101012
Calculating Decimal Equivalent −
Step | Binary Number | Decimal Number |
Step 1 | 101012 | ((1 x 24) + (0 x 23) + (1 x 22) + (0 x 21) + (1 x 20))10 |
Step 2 | 101012 | (16 + 0 + 4 + 0 + 1)10 |
Step 3 | 101012 | 2110 |
Note − 101012 is normally written as 10101.
Octal Number System
Characteristics of the octal number system are as follows −
- Uses eight digits, 0,1,2,3,4,5,6,7
- Also called as base 8 number system
- Each position in an octal number represents a 0 power of the base (8). Example 80
- Last position in an octal number represents a x power of the base (8). Example 8x where x represents the last position - 1
Example
Octal Number: 125708
Calculating Decimal Equivalent −
Step | Octal Number | Decimal Number |
Step 1 | 125708 | ((1 x 84) + (2 x 83) + (5 x 82) + (7 x 81) + (0 x 80))10 |
Step 2 | 125708 | (4096 + 1024 + 320 + 56 + 0)10 |
Step 3 | 125708 | 549610 |
Note − 125708 is normally written as 12570.
Hexadecimal Number System
Characteristics of hexadecimal number system are as follows −
- Uses 10 digits and 6 letters, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
- Letters represent the numbers starting from 10. A = 10. B = 11, C = 12, D = 13, E = 14, F = 15
- Also called as base 16 number system
- Each position in a hexadecimal number represents a 0 power of the base (16). Example, 160
- Last position in a hexadecimal number represents a x power of the base (16). Example 16x where x represents the last position - 1
Example
Hexadecimal Number: 19FDE16
Calculating Decimal Equivalent −
Step | Binary Number | Decimal Number |
Step 1 | 19FDE16 | ((1 x 164) + (9 x 163) + (F x 162) + (D x 161) + (E x 160))10 |
Step 2 | 19FDE16 | ((1 x 164) + (9 x 163) + (15 x 162) + (13 x 161) + (14 x 160))10 |
Step 3 | 19FDE16 | (65536+ 36864 + 3840 + 208 + 14)10 |
Step 4 | 19FDE16 | 10646210 |
Note − 19FDE16 is normally written as 19FDE.
An algorithm is the finite set of English statements which are designed to accomplish the specific task. Study of any algorithm is based on the following four criteria
1. Design of algorithm: This is the first step in the creation of an algorithm. Design of algorithm includes the problem statement which tell user about the area for which algorithm is required. After problem statement next important thing required is the information about available and required resources. The last thing required in design of algorithm phase is information about the expected output.
2. Validation of algorithm: Once an algorithm is designed, it is necessary to validate it for several possible input and make sure that algorithm is providing correct output for every input. This process is known as algorithm validation. The purpose of the validation is to assure us that this algorithm will work correctly independently of the issues concerning the programming language it will eventually be written in.
3. Analysis of algorithm: Analysis of algorithms is also called as performance analysis. This phase refers to the task of determining how much computing time and storage an algorithm requires. The efficiency is measured in best case, worst case and average case analysis.
4. Testing of algorithm : This phase is about to testing of a program which coded as per the algorithm. Testing of such program consists of two phases:
Debugging : It is the process of executing programs on sample data sets to determine whether faulty results occur or not and if occur, to correct them.
Profiling : Profiling or performance measurement is the process of executing a correct program on data sets and measuring the time and space it takes to compute the result
Characteristics of an algorithm
Input: Algorithm must accept zero or more inputs.
Output: Algorithm must provide at least one quantity.
Definiteness: Algorithm must consist of clear and unambiguous instruction.
Finiteness: Algorithm must contain finite set of instruction and algorithm will terminates after a finite number of steps.
Effectiveness: Every instruction in algorithm must be very basic and effective.
Uses of algorithm
Algorithm provide independent layout of the program.
It is easy to develop the program in any desired language with help of layout.
Algorithm representation is very easy to understand.
To design algorithm there is no need of expertise in programming language.
There are many ways to write an algorithm. Some are very informal, some are quite formal and mathematical in nature, and some are quite graphical. The instructions for connecting a DVD player to a television are an algorithm. A mathematical formula such as πR2 is a special case of an algorithm. The form is not particularly important as long as it provides a good way to describe and check the logic of the plan.
The development of an algorithm (a plan) is a key step in solving a problem. Once we have an algorithm, we can translate it into a computer program in some programming language. Our algorithm development process consists of five major steps.
Step 1: Obtain a description of the problem.
Step 2: Analyze the problem.
Step 3: Develop a high-level algorithm.
Step 4: Refine the algorithm by adding more detail.
Step 5: Review the algorithm.
Step 1: Obtain a description of the problem.
This step is much more difficult than it appears. In the following discussion, the word client refers to someone who wants to find a solution to a problem, and the word developer refers to someone who finds a way to solve the problem. The developer must create an algorithm that will solve the client's problem.
The client is responsible for creating a description of the problem, but this is often the weakest part of the process. It's quite common for a problem description to suffer from one or more of the following types of defects: (1) the description relies on unstated assumptions, (2) the description is ambiguous, (3) the description is incomplete, or (4) the description has internal contradictions. These defects are seldom due to carelessness by the client. Instead, they are due to the fact that natural languages (English, French, Korean, etc.) are rather imprecise. Part of the developer's responsibility is to identify defects in the description of a problem, and to work with the client to remedy those defects.
Step 2: Analyze the problem.
The purpose of this step is to determine both the starting and ending points for solving the problem. This process is analogous to a mathematician determining what is given and what must be proven. A good problem description makes it easier to perform this step.
When determining the starting point, we should start by seeking answers to the following questions:
- What data are available?
- Where is that data?
- What formulas pertain to the problem?
- What rules exist for working with the data?
- What relationships exist among the data values?
When determining the ending point, we need to describe the characteristics of a solution. In other words, how will we know when we're done? Asking the following questions often helps to determine the ending point.
- What new facts will we have?
- What items will have changed?
- What changes will have been made to those items?
- What things will no longer exist?
Step 3: Develop a high-level algorithm.
An algorithm is a plan for solving a problem, but plans come in several levels of detail. It's usually better to start with a high-level algorithm that includes the major part of a solution, but leaves the details until later. We can use an everyday example to demonstrate a high-level algorithm.
Problem: I need a send a birthday card to my brother, Mark.
Analysis: I don't have a card. I prefer to buy a card rather than make one myself.
High-level algorithm:
Go to a store that sells greeting cards
Select a card
Purchase a card
Mail the card
This algorithm is satisfactory for daily use, but it lacks details that would have to be added were a computer to carry out the solution. These details include answers to questions such as the following.
- "Which store will I visit?"
- "How will I get there: walk, drive, ride my bicycle, take the bus?"
- "What kind of card does Mark like: humorous, sentimental, risqué?"
These kinds of details are considered in the next step of our process.
Step 4: Refine the algorithm by adding more detail.
A high-level algorithm shows the major steps that need to be followed to solve a problem. Now we need to add details to these steps, but how much detail should we add? Unfortunately, the answer to this question depends on the situation. We have to consider who (or what) is going to implement the algorithm and how much that person (or thing) already knows how to do. If someone is going to purchase Mark's birthday card on my behalf, my instructions have to be adapted to whether or not that person is familiar with the stores in the community and how well the purchaser known my brother's taste in greeting cards.
When our goal is to develop algorithms that will lead to computer programs, we need to consider the capabilities of the computer and provide enough detail so that someone else could use our algorithm to write a computer program that follows the steps in our algorithm. As with the birthday card problem, we need to adjust the level of detail to match the ability of the programmer. When in doubt, or when you are learning, it is better to have too much detail than to have too little.
Most of our examples will move from a high-level to a detailed algorithm in a single step, but this is not always reasonable. For larger, more complex problems, it is common to go through this process several times, developing intermediate level algorithms as we go. Each time, we add more detail to the previous algorithm, stopping when we see no benefit to further refinement. This technique of gradually working from a high-level to a detailed algorithm is often called stepwise refinement.
Stepwise refinement is a process for developing a detailed algorithm by gradually adding detail to a high-level algorithm.
Step 5: Review the algorithm.
The final step is to review the algorithm. What are we looking for? First, we need to work through the algorithm step by step to determine whether or not it will solve the original problem. Once we are satisfied that the algorithm does provide a solution to the problem, we start to look for other things. The following questions are typical of ones that should be asked whenever we review an algorithm. Asking these questions and seeking their answers is a good way to develop skills that can be applied to the next problem.
- Does this algorithm solve a very specific problem or does it solve a more general problem? If it solves a very specific problem, should it be generalized?
For example, an algorithm that computes the area of a circle having radius 5.2 meters (formula π*5.22) solves a very specific problem, but an algorithm that computes the area of any circle (formula π*R2) solves a more general problem.
- Can this algorithm be simplified?
One formula for computing the perimeter of a rectangle is:
Length + width + length + width
A simpler formula would be:
2.0 * (length + width)
- Is this solution similar to the solution to another problem? How are they alike? How are they different?
For example, consider the following two formulae:
Rectangle area = length * width
Triangle area = 0.5 * base * height
Similarities: Each computes an area. Each multiplies two measurements.
Differences: Different measurements are used. The triangle formula contains 0.5.
Hypothesis: Perhaps every area formula involves multiplying two measurements.
Example: Pick and Plant
This section contains an extended example that demonstrates the algorithm development process. To complete the algorithm, we need to know that every Jeroo can hop forward, turn left and right, pick a flower from its current location, and plant a flower at its current location.
Problem Statement (Step 1)
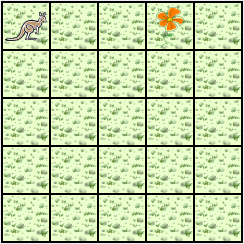
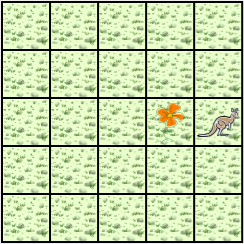
A Jeroo starts at (0, 0) facing East with no flowers in its pouch. There is a flower at location (3, 0). Write a program that directs the Jeroo to pick the flower and plant it at location (3, 2). After planting the flower, the Jeroo should hop one space East and stop. There are no other nets, flowers, or Jeroos on the island.
Start | Finish |
 |  |
Analysis of the Problem (Step 2)
- The flower is exactly three spaces ahead of the jeroo.
- The flower is to be planted exactly two spaces South of its current location.
- The Jeroo is to finish facing East one space East of the planted flower.
- There are no nets to worry about.
High-level Algorithm (Step 3)
Let's name the Jeroo Bobby. Bobby should do the following:
Get the flower
Put the flower
Hop East
Detailed Algorithm (Step 4)
Let's name the Jeroo Bobby. Bobby should do the following:
Get the flower
Hop 3 times
Pick the flower
Put the flower
Turn right Hop 2 times Plant a flower
Hop East
Turn left Hop once
Review the Algorithm (Step 5)
- The high-level algorithm partitioned the problem into three rather easy subproblems. This seems like a good technique.
- This algorithm solves a very specific problem because the Jeroo and the flower are in very specific locations.
- This algorithm is actually a solution to a slightly more general problem in which the Jeroo starts anywhere, and the flower is 3 spaces directly ahead of the Jeroo.
Java Code for "Pick and Plant"
A good programmer doesn't write a program all at once. Instead, the programmer will write and test the program in a series of builds. Each build adds to the previous one. The high-level algorithm will guide us in this process.
A good programmer works incrementally, add small pieces one at a time and constantly re-checking the work so far.
FIRST BUILD
To see this solution in action, create a new Greenfoot4Sofia scenario and use the Edit Palettes Jeroo menu command to make the Jeroo classes visible. Right-click on the Island class and create a new subclass with the name of your choice. This subclass will hold your new code.
The recommended first build contains three things:
- The main method (here myProgram() in your island subclass).
- Declaration and instantiation of every Jeroo that will be used.
- The high-level algorithm in the form of comments.
1
2
3
4
5
6
7
8
9
10
11
12
Public void myProgram()
{
Jeroo bobby = new Jeroo();
This.add(bobby);
// --- Get the flower ---
// --- Put the flower ---
// --- Hop East ---
} // ===== end of method myProgram() =====
The instantiation at the beginning of myProgram() places bobby at (0, 0), facing East, with no flowers.
Once the first build is working correctly, we can proceed to the others. In this case, each build will correspond to one step in the high-level algorithm. It may seem like a lot of work to use four builds for such a simple program, but doing so helps establish habits that will become invaluable as the programs become more complex.
SECOND BUILD
This build adds the logic to "get the flower", which in the detailed algorithm (step 4 above) consists of hopping 3 times and then picking the flower. The new code is indicated by comments that wouldn't appear in the original (they are just here to call attention to the additions). The blank lines help show the organization of the logic.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Public void myProgram()
{
Jeroo bobby = new Jeroo();
This.add(bobby);
// --- Get the flower ---
Bobby.hop(3); // <-- new code to hop 3 times
Bobby.pick(); // <-- new code to pick the flower
// --- Put the flower ---
// --- Hop East ---
} // ===== end of method myProgram() =====
By taking a moment to run the work so far, you can confirm whether or not this step in the planned algorithm works as expected.
THIRD BUILD
This build adds the logic to "put the flower". New code is indicated by the comments that are provided here to mark the additions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Public void myProgram()
{
Jeroo bobby = new Jeroo();
This.add(bobby);
// --- Get the flower ---
Bobby.hop(3);
Bobby.pick();
// --- Put the flower ---
Bobby.turn(RIGHT); // <-- new code to turn right
Bobby.hop(2); // <-- new code to hop 2 times
Bobby.plant(); // <-- new code to plant a flower
// --- Hop East ---
} // ===== end of method myProgram() =====
FOURTH BUILD (final)
This build adds the logic to "hop East".
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Public void myProgram()
{
Jeroo bobby = new Jeroo();
This.add(bobby);
// --- Get the flower ---
Bobby.hop(3);
Bobby.pick();
// --- Put the flower ---
Bobby.turn(RIGHT);
Bobby.hop(2);
Bobby.plant();
// --- Hop East ---
Bobby.turn(LEFT); // <-- new code to turn left
Bobby.hop(); // <-- new code to hop 1 time
} // ===== end of method myProgram() =====
Example: Replace Net with Flower
This section contains a second example that demonstrates the algorithm development process.
Problem Statement (Step 1)
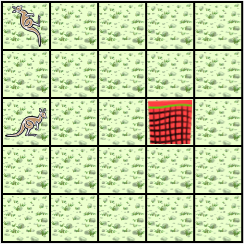
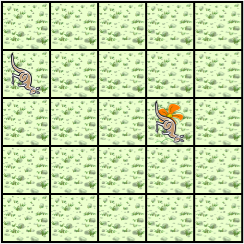
There are two Jeroos. One Jeroo starts at (0, 0) facing North with one flower in its pouch. The second starts at (0, 2) facing East with one flower in its pouch. There is a net at location (3, 2). Write a program that directs the first Jeroo to give its flower to the second one. After receiving the flower, the second Jeroo must disable the net, and plant a flower in its place. After planting the flower, the Jeroo must turn and face South. There are no other nets, flowers, or Jeroos on the island.
Start | Finish |
 |  |
Analysis of the Problem (Step 2)
- Jeroo_2 is exactly two spaces behind Jeroo_1.
- The only net is exactly three spaces ahead of Jeroo_2.
- Each Jeroo has exactly one flower.
- Jeroo_2 will have two flowers after receiving one from Jeroo_1.
One flower must be used to disable the net.
The other flower must be planted at the location of the net, i.e. (3, 2). - Jeroo_1 will finish at (0, 1) facing South.
- Jeroo_2 is to finish at (3, 2) facing South.
- Each Jeroo will finish with 0 flowers in its pouch. One flower was used to disable the net, and the other was planted.
High-level Algorithm (Step 3)
Let's name the first Jeroo Ann and the second one Andy.
Ann should do the following:
Find Andy (but don't collide with him)
Give a flower to Andy (he will be straight ahead)
After receiving the flower, Andy should do the following:
Find the net (but don't hop onto it)
Disable the net
Plant a flower at the location of the net
Face South
Detailed Algorithm (Step 4)
Let's name the first Jeroo Ann and the second one Andy.
Ann should do the following:
Find Andy
Turn around (either left or right twice)
Hop (to location (0, 1))
Give a flower to Andy
Give ahead
Now Andy should do the following:
Find the net
Hop twice (to location (2, 2))
Disable the net
Toss
Plant a flower at the location of the net
Hop (to location (3, 2))
Plant a flower
Face South
Turn right
Review the Algorithm (Step 5)
- The high-level algorithm helps manage the details.
- This algorithm solves a very specific problem, but the specific locations are not important. The only thing that is important is the starting location of the Jeroos relative to one another and the location of the net relative to the second Jeroo's location and direction.
There are three ways to represent an algorithm. Consider the following algorithm of addition of two numbers
Step 1 : Start
Step 2 : Read a number, say x and y
Step 3 : Add x and y
Step 4 : Display Addition
Step 5 : Stop
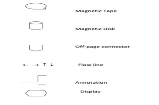
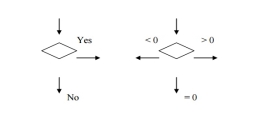
1. Flowcharts: A flow chart is a diagrammatic / pictorial representation of an algorithm. It is the simplest way of representation of algorithm. Initially an algorithm is represented in the form of flowchart and then flowchart is given to programmer to express it in some programming language. Logical error detection is very easy in flowchart as it shows the flow of operations in diagrammatic form. Once flowchart is ready it is very easy to write a program in terms of statements of a programming language. Following are the symbols used in designing the flowcharts.
2. Pseudo code : Pseudo code is the combination of English statements with programming methodology. In pseudo code, there is no restriction of following the syntax of the programming language. Pseudo codes cannot be compiled. It is just a previous step of developing a code for given algorithm.
3. Program : In this way of representation, complete algorithm is represented using some programming language by following the complete syntax of programming language.
Sr. No. | Name of Symbol | Symbol | Meaning / Purpose |
1. | Terminal |
 | To indicate START / STOP. Usually it is the first symbol and last symbol used in program logic. |
2. | Input / Output Statement |  | To indicate input / output of Data |
3. | Processing Statement |  | To indicate the processing of instructions. |
4. |
Decision Box | 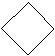
| To indicate decision making and a branch to one or more alternatives. |
5. | Flow Lines | 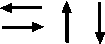 | To indicate the direction of flow of information. |
6. | Connector |

| It is used when flowchart becomes long and need to be continued. Shows the continuity of the algorithm on the next page. |

A flowchart is a schematic representation of an algorithm or a stepwise process, showing the steps as boxes of various kinds, and their order by connecting these with arrows. Flowcharts are used in designing or documenting a process or program.
Algorithm
Set of step-by-step instructions that perform a specific task or operation
Natural‖ language NOT programming language
Pseudocode
Set of instructions that mimic programming language instructions
Flowchart
Visual program design tool
Semantic‖ symbols describe operations to be performed
FLOWCHARTS
Definitions:
A flowchart is a schematic representation of an algorithm or a stepwise process, showing the steps as boxes of various kinds, and their order by connecting these with arrows. Flowcharts are used in designing or documenting a process or program.
A flow chart, or flow diagram, is a graphical representation of a process or system that details the sequencing of steps required to create output.
A flowchart is a picture of the separate steps of a process in sequential order.
TYPES:
High-Level Flowchart
A high-level (also called first-level or top-down) flowchart shows the major steps in a process. It illustrates a "birds-eye view" of a process, such as the example in the figure entitled High-Level Flowchart of Prenatal Care. It can also include the intermediate outputs of each step (the product or service produced), and the sub-steps involved. Such a flowchart offers a basic picture of the process and identifies the changes taking place within the process. It is significantly useful for identifying appropriate team members (those who are involved in the process) and for developing indicators for monitoring the process because of its focus on intermediate outputs.
Most processes can be adequately portrayed in four or five boxes that represent the major steps or activities of the process. In fact, it is a good idea to use only a few boxes, because doing so forces one to consider the most important steps. Other steps are usually sub-steps of the more important ones.
Detailed Flowchart
The detailed flowchart provides a detailed picture of a process by mapping all of the steps and activities that occur in the process. This type of flowchart indicates the steps or activities of a process and includes such things as decision points, waiting periods, tasks that frequently must be redone (rework), and feedback loops. This type of flowchart is useful for examining areas of the process in detail and for looking for problems or areas of inefficiency. For example, the Detailed Flowchart of Patient Registration reveals the delays that result when the record clerk and clinical officer are not available to assist clients.
Deployment or Matrix Flowchart
A deployment flowchart maps out the process in terms of who is doing the steps. It is in the form of a matrix, showing the various participants and the flow of steps among these participants. It is chiefly useful in identifying who is providing inputs or services to whom, as well as areas where different people may be needlessly doing the same task. See the Deployment of Matrix Flowchart.
ADVANTAGES OF USING FLOWCHARTS
The benefits of flowcharts are as follows:
Communication: Flowcharts are better way of communicating the logic of a system to all concerned.
Effective analysis: With the help of flowchart, problem can be analysed in more effective way.
Proper documentation: Program flowcharts serve as a good program documentation, which is needed for various purposes.
Efficient Coding: The flowcharts act as a guide or blueprint during the systems analysis and program development phase.
Proper Debugging: The flowchart helps in debugging process.
Efficient Program Maintenance: The maintenance of operating program becomes easy with the help of flowchart. It helps the programmer to put efforts more efficiently on that part
Advantages:
Logic Flowcharts are easy to understand. They provide a graphical representation of actions to be taken.
Logic Flowcharts are well suited for representing logic where there is intermingling among many actions.
Disadvantages:
Logic Flowcharts may encourage the use of GoTo statements leading software design that is unstructured with logic that is difficult to decipher.
Without an automated tool, it is time-consuming to maintain Logic Flowcharts.
Logic Flowcharts may be used during detailed logic design to specify a module.
However, the presence of decision boxes may encourage the use of GoTo statements, resulting in software that is not structured. For this reason, Logic Flowcharts may be better used during Structural Design
LIMITATIONS OF USING FLOWCHARTS
1. Complex logic: Sometimes, the program logic is quite complicated. In that case, flowchart becomes complex and clumsy.
2. Alterations and Modifications: If alterations are required the flowchart may require re-drawing completely.
3. Reproduction: As the flowchart symbols cannot be typed, reproduction of flowchart becomes a problem.
4. The essentials of what is done can easily be lost in the technical details of how it is done.
GUIDELINES FOR DRAWING A FLOWCHART
Flowcharts are usually drawn using some standard symbols; however, some special symbols can also be developed when required. Some standard symbols, which are frequently required for flowcharting many computer programs.

The following are some guidelines in flow charting in drawing a proper flowchart, all necessary requirements should be listed out in logical order
The flowchart should be clear, neat and easy to follow. There should not be any room for ambiguity in understanding the flowchart.
The usual direction of the flow of a procedure or system is from left to right or top to bottom
Only one flow line should come out from a process symbol.

Only one flow line should enter a decision symbol, but two or three flow lines, one for each possible answer, should leave the decision symbol.
Only one flow line is used in conjunction with terminal symbol.
Write within standard symbols briefly. As necessary, you can use the annotation symbol to describe data or computational steps more clearly.
If the flowchart becomes complex, it is better to use connector symbols to reduce the number of flow lines. Avoid the intersection of flow lines if you want to make it more effective and better way of communication.
Ensure that the flowchart has a logical start and finish.
It is useful to test the validity of the flowchart by passing through it with a simple test data.
Examples
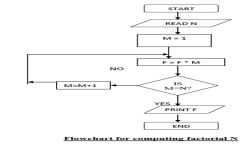
Sample flowchart
A flowchart for computing factorial N (N!) Where N! = 1 * 2 * 3 *...* N. This flowchart represents a "loop and a half" — a situation discussed in introductory programming textbooks that requires either a duplication of a component (to be both inside and outside the loop) or the component to be put inside a branch in the loop
Sample Pseudocode
ALGORITHM Sample
GET Data
WHILE There Is Data
DO Math Operation
GET Data
END WHILE
END ALGORITHM
Pseudo code is a term which is often used in programming and algorithm based fields. It is a methodology that allows the programmer to represent the implementation of an algorithm. Simply, we can say that it’s the cooked up representation of an algorithm. Often at times, algorithms are represented with the help of pseudo codes as they can be interpreted by programmers no matter what their programming background or knowledge is. Pseudo code, as the name suggests, is a false code or a representation of code which can be understood by even a layman with some school level programming knowledge.
Algorithm: It’s an organized logical sequence of the actions or the approach towards a particular problem. A programmer implements an algorithm to solve a problem. Algorithms are expressed using natural verbal but somewhat technical annotations.
Pseudo code: It’s simply an implementation of an algorithm in the form of annotations and informative text written in plain English. It has no syntax like any of the programming language and thus can’t be compiled or interpreted by the computer.
Advantages of Pseudocode
Improves the readability of any approach. It’s one of the best approaches to start implementation of an algorithm.
Acts as a bridge between the program and the algorithm or flowchart. Also works as a rough documentation, so the program of one developer can be understood easily when a pseudo code is written out. In industries, the approach of documentation is essential. And that’s where a pseudo-code proves vital.
The main goal of a pseudo code is to explain what exactly each line of a program should do, hence making the code construction phase easier for the programmer.
How to write a Pseudo-code?
Arrange the sequence of tasks and write the pseudocode accordingly.
Start with the statement of a pseudo code which establishes the main goal or the aim.
Example:
This program will allow the user to check
The number whether it's even or odd.
The way the if-else, for, while loops are indented in a program, indent the statements likewise, as it helps to comprehend the decision control and execution mechanism. They also improve the readability to a great extent.
Example:
If "1"
Print response
"I am case 1"
If "2"
Print response
"I am case 2"
Use appropriate naming conventions. The human tendency follows the approach to follow what we see. If a programmer goes through a pseudo code, his approach will be the same as per it, so the naming must be simple and distinct.
Use appropriate sentence casings, such as CamelCase for methods, upper case for constants and lower case for variables.
Elaborate everything which is going to happen in the actual code. Don’t make the pseudo code abstract.
Use standard programming structures such as ‘if-then’, ‘for’, ‘while’, ‘cases’ the way we use it in programming.
Check whether all the sections of a pseudo code is complete, finite and clear to understand and comprehend.
Don’t write the pseudo code in a complete programmatic manner. It is necessary to be simple to understand even for a layman or client, hence don’t incorporate too many technical terms.
Example:
Let’s have a look at this code
// This program calculates the Lowest Common multiple // for excessively long input values Import java.util.*; Public class LowestCommonMultiple { Private static long LcmNaive(long numberOne, long numberTwo) { Long lowestCommonMultiple; LowestCommonMultiple = (numberOne * numberTwo) / greatestCommonDivisor(numberOne, NumberTwo); Return lowestCommonMultiple; } Private static long GreatestCommonDivisor(long numberOne, long numberTwo) { If (numberTwo == 0) Return numberOne; Return greatestCommonDivisor(numberTwo, NumberOne % numberTwo); } Public static void main(String args[]) { Scanner scanner = new Scanner(System.in); System.out.println("Enter the inputs"); Long numberOne = scanner.nextInt(); Long numberTwo = scanner.nextInt(); System.out.println(lcmNaive(numberOne, numberTwo)); } } |
And here’s the Pseudo Code for the same.
Filter_none
Brightness_4
This program calculates the Lowest Common multiple For excessively long input values Function lcmNaive(Argument one, Argument two){ Calculate the lowest common variable of Argument 1 and Argument 2 by dividing their product by their Greatest common divisor product Return lowest common multiple End } Function greatestCommonDivisor(Argument one, Argument two){ If Argument two is equal to zero Then return Argument one Return the greatest common divisor End }
{ In the main function Print prompt "Input two numbers" Take the first number from the user Take the second number from the user Send the first number and second number To the lcmNaive function and print The result to the user } |
An algorithm is a step-by-step procedure for solving a certain class of problems.
This can be executed mechanically.
Program = algorithm formulated in programming language.
To be valid, the algorithm must be correct in the results it provides and it must also terminate. Meaning that an analyst has to prove these two characteristics to establish the validity of the algorithm.
To be valid, a program simply compiles (or be interpreted) and herein lies the key difference. A program is a sequence of steps written to run on a machine.
Programs usually implement algorithms, and others, like an operating system implement many algorithms. To go from an algorithm to a program is to go from an idea to a concrete thing.
In a nutshell, an algorithm is a sequence of steps that describes an idea for solving a problem meeting the criteria of correctness and terminability. A program is a sequence of steps that is specified at enough detail to be able to run on a machine.
Computer Programming is defined as the step by step process of designing and developing various sets of computer programs to accomplish a specific computing outcome. The process comprises several tasks like analysis, coding, algorithm generation, checking accuracy and resource consumption of algorithms, etc.
The purpose of computer programming is to find a sequence of instructions that solve a specific problem on a computer.
These basic elements include −
- Programming Environment
- Basic Syntax
- Data Types
- Variables
- Keywords
- Basic Operators
- Decision Making
- Loops
- Numbers
- Characters
- Arrays
- Strings
- Functions
- File I/O
Data Declarations
Declarations serve two purposes:
They tell the compiler to set aside an appropriate amount of space in memory for the program’s data (variables).
They enable the compiler to correctly operate on the variables. The compiler needs to know the data type to correctly operate on a variable. The compiler needs to know how many bytes are used by variables and the format of the bits. The meaning of the binary bits of a variable are different for different data types.
- Char is 8 bit (1 byte) ASCII, but can also store numeric data.
- Int is 4 byte 2’s complement.
- Short is 2 byte 2’s complement.
- Long is 8 byte 2’s complement.
- Unsigned (int, short, and long) are straight binary
- Float is 4 byte IEEE Floating Point Single Precision Standard.
- Double is 8 byte IEEE Floating Point Double Precision Standard.
Character - integer relation
The ASCII code is a set of integer numbers used to represent characters.
Char c = 'a'; /* 'a' has ASCII value 97 */
Int i = 65; /* 65 is ASCII for 'A' */
Printf( "%c", c + 1 ); /* b */
Printf( "%d", c + 2 ); /* 99 */
Printf( "%c", i + 3 ); /* D */
Integers
A variations of int (unsigned, long, ...) are stored binary data which is directly translated to it’s base-10 value.
Floating point data
Variables of type float and double are stored in three parts: the sign, the mantissa (normalized value), and an exponent.
Sizeof
Because some variables take different amount of memory of different systems, C provides an operator which returns the number of bytes needed to store a given type of data.
i = sizeof(char);
j = sizeof(long);
k = sizeof(double);
The sizeof operator is very useful when manually allocating memory and dealing with complex data structures.
Conversions and Casts
Two mechanisms exist to convert data from one data type to another, implicit conversion and explicit conversion, which is also called casting.
Implicit conversion
If an arithmetic operation on two variables of differing types is performed, one of the variables is converted or promoted to the same data as the other before the operation is performed. In general, smaller data types are always promoted to the larger data type.
Explicit conversion or casts
The programmer can tell the compiler what types of conversions should be performed by using a cast. A cast is formed by putting a data type keyword in parenthesis in front of a variable name or expression.
x = (float)(m * j);
i = (int)x + k;
Variables are the names you give to computer memory locations which are used to store values in a computer program.
Here are the following three simple steps −
- Create variables with appropriate names.
- Store your values in those two variables.
- Retrieve and use the stored values from the variables.
When creating a variable, we need to declare the data type it contains.
Programming languages define data types differently.
For example, almost all languages differentiate between ‘integers’ (or whole numbers, eg 12), ‘non-integers’ (numbers with decimals, eg 0.24), and ‘characters’ (letters of the alphabet or words).
- Char – a single 16-bit Unicode character, such as a letter, decimal or punctuation symbol.
- Boolean – can have only two possible values: true (1) or false (0). This data type is useful in conditional statements.
- Byte - has a minimum value of -128 and a maximum value of 127 (inclusive).
- Short– has a minimum value of -32,768 and a maximum value of 32,767
- Int: – has a minimum value of -2,147,483,648 and a maximum value of 2,147,483,647 (inclusive).
- Long – has a minimum value of -9,223,372,036,854,775,808 and a maximum value of 9,223,372,036,854,775,807 (inclusive).
- Float – a floating point number with 32-bits of precision
- Double – this is a double precision floating point number.
Error is an illegal operation performed by the user which results in abnormal working of the program.
Programming errors often remain undetected until the program is compiled or executed. Some of the errors inhibit the program from getting compiled or executed. Thus errors should be removed before compiling and executing.
The most common errors can be broadly classified as follows.
Type of errors

- Syntax errors: Errors that occur when you violate the rules of writing C/C++ syntax are known as syntax errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by compiler and thus are known as compile-time errors.
Most frequent syntax errors are:- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon like this:
// C program to illustrate // syntax error #include<stdio.h> Void main() { Int x = 10; Int y = 15;
Printf("%d", (x, y)) // semicolon missed } |
Error:
Error: expected ';' before '}' token
Syntax of a basic construct is written wrong. For example: while loop
// C program to illustrate // syntax error #include<stdio.h> Int main(void) { // while() cannot contain "." as an argument. While(.) { Printf("hello"); } Return 0; } |
Error:
Error: expected expression before '.' token
While(.)
In the given example, the syntax of while loop is incorrect. This causes a syntax error.
2. Run-time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
// C program to illustrate // run-time error #include<stdio.h> Void main() { Int n = 9, div = 0;
// wrong logic // number is divided by 0, // so this program abnormally terminates Div = n/0;
Printf("resut = %d", div); } |
Error:
Warning: division by zero [-Wdiv-by-zero]
Div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
3. Linker Errors: These error occurs when after compilation we link the different object files with main’s object using Ctrl+F9 key(RUN). These are errors generated when the executable of the program cannot be generated. This may be due to wrong function prototyping, incorrect header files. One of the most common linker error is writing Main() instead of main().
// C program to illustrate // linker error #include<stdio.h>
Void Main() // Here Main() should be main() { Int a = 10; Printf("%d", a); } |
Error:
(.text+0x20): undefined reference to main'
4. Logical Errors: On compilation and execution of a program, desired output is not obtained when certain input values are given. These types of errors which provide incorrect output but appears to be error free are called logical errors. These are one of the most common errors done by beginners of programming.
These errors solely depend on the logical thinking of the programmer and are easy to detect if we follow the line of execution and determine why the program takes that path of execution.
// C program to illustrate // logical error Int main() { Int i = 0;
// logical error : a semicolon after loop For(i = 0; i < 3; i++); { Printf("loop "); Continue; } Getchar(); Return 0; } |
No output
5. Semantic errors: This error occurs when the statements written in the program are not meaningful to the compiler.
// C program to illustrate // semantic error Void main() { Int a, b, c; a + b = c; //semantic error } |
Error
Error: lvalue required as left operand of assignment
a + b = c; //semantic error
Source code is the C program that you write in your editor and save with a ‘ .C ‘ extension which is un-compiled when written for the first time or whenever a change is made in it and saved.
Object code is the output of a compiler after it processes the source code. The object code is usually a machine code, also called a machine language, which can be understood directly by a specific type of CPU. However, some compilers are designed to convert source code into an assembly language or some other another programming language.
An assembly language is a human-readable notation using the mnemonics in the ISA of that particular CPU.
Executable (also called the Binary) is the output of a linker after it processes the object code. A machine code file can be immediately executable, runnable as a program , or it might require linking with other object code files for example libraries to produce a complete executable program.
Arithmetic Expressions consist of numeric literals, arithmetic operators, and numeric variables. They simplify to a single value, when evaluated.
Here is an example of an arithmetic expression with no variables:
3.14*10*10
This expression evaluates to 314, the approximate area of a circle with radius 10. Similarly, the expression
3.14*radius*radius
Would also evaluate to 314, if the variable radius stored the value 10.
Note that the parentheses in the last expression helps dictate which order to evaluate the expression.
Multiplication and division have a higher order of precedence than addition and subtraction. In an arithmetic expression, it is evaluated left to right, only performing the multiplications and divisions.
After doing this, process the expression again from left to right, doing all the additions and subtractions.
So,
3+4*5
First evaluates to
3+20 which then evaluates to 23.
Consider this expression:
3 + 4*5 - 6/3*4/8 + 2*6 - 4*3*2
First go through and do all the multiplications and divisions:
3 + 20 - 1 + 12 - 24
Integer Division: In particular, if the division has a leftover remainder or fraction, this is simply discarded.
For example:
13/4 evaluates to 3
19/3 evaluates to 6 but
Similarly, if you have an expression with integer variables part of a division, this evaluates to an integer as well.
For example, in this segment of code, y gets set to 2.
Int x = 8;
Int y = x/3;
However, if we did the following,
Double x = 8;
Double y = x/3;
y would equal 2.66666666 (approximately).
The way C decides whether it will do an integer division (as in the first example), or a real number division (as in the second example), is based on the TYPE of the operands.
If both operands are ints, an integer division is done.
If either operand is a float or a double, then a real division is done. The compiler will treat constants without the decimal point as integers, and constants with the decimal point as a float. Thus, the expressions 13/4 and 13/4.0 will evaluate to 3 and 3.25 respectively.
The mod operator (%)
The one new operator is the mod operator, which is denoted by the percent sign(%). This operator is ONLY defined for integer operands. It is defined as follows:
a%b evaluates to the remainder of a divided by b.
For example,
12%5 = 2
19%6 = 1
14%7 = 0
19%200 = 19
The precedence of the mod operator is the same as the precedence of multiplication and division.
Every expression in C language contains set of operators and operands. Operators are the special symbols which are used to indicate the type of operation whereas operands are the data member or variables operating as per operation specified by operator. One expression contains one or more set of operators and operands. So to avoid the ambiguity in execution of expression, C compiler fixed the precedence of operator. Depending on the operation, operators are classified into following category.
- Arithmetic Operator: These are the operators which are useful in performing mathematical calculations. Following are the list of arithmetic operator in C language. To understand the operation assume variable A contains value 10 and variable contains value 5.
Sr. No. | Operator | Description | Example |
+ | Used to add two operands | Result of A+B is 15 | |
2. | - | Used to subtract two operands | Result of A-B is 5 |
3. | * | Used to multiply two operands | Result of A*B is 50 |
4. | / | Used to divide two operands | Result of A/B is 2 |
5. | % | Find reminder of the division of two operand | Result of A%B is 0 |
Example:
#include<stdio.h>
#include<conio.h>
Void main()
{
Int a,b,c;
Clrscr();
Printf("Enter two numbers");
Scanf("%d %d",&a,&b);
Printf("\n Result of addition of %d and %d is %d",a,b,a+b);
Printf("\n Result of subtraction of %d and %d is %d",a,b,a-b);
Printf("\n Result of multiplication %d and %d is %d",a,b,a*b);
Printf("\n Result of division of %d and %d is %d",a,b,a/b);
Printf("\n Result of modulus of %d and %d is %d",a,b,a%b);
Getch();
}
Output:
Enter two numbers
5
3
Result of addition of 5 and 3 is 8
Result of subtraction of 5 and 3 is 2
Result of multiplication of 5 and 3 is 15
Result of division of 5 and 3 is 1
Result of modulus of 5 and 3 is 2
2. Relational Operators: Relational operator used to compare two operands. Relational operator produce result in terms of binary values. It returns 1 when the result is true and 0 when result is false. Following are the list of relational operator in C language. To understand the operation assume variable A contains value 10 and variable contains value 5.
Sr. No. | Operator | Description | Example |
1. | < | This is less than operator which is used to check whether the value of left operand is less than the value of right operand or not | Result of A<B is false
|
2. | > | This is greater than operator which is used to check whether the value of left operand is greater than the value of right operand or not | Result of A>B is true |
3. | <= | This is less than or equal to operator | Result of A<=B is false |
4. | >= | This is greater than or equal to operator | Result of A>=B is true |
5. | == | This is equal to operator which is used to check value of both operands are equal or not | Result of A==B is false |
6. | != | This is not equal to operator which is used to check value of both operands are equal or not | Result of A!=B is true |
Example:
#include<stdio.h>
#include<conio.h>
Void main()
{
Int a,b,c;
Clrscr();
Printf("Enter two numbers");
Scanf("%d %d",&a,&b);
Printf("\n Result of less than operator of %d and %d is %d",a,b,a<b);
Printf("\n Result of greater than operator of %d and %d is %d",a,b,a>b);
Printf("\n Result of leass than or equal to operator %d and %d is %d",a,b,a<=b);
Printf("\n Result of greater than or equal to operator of %d and %d is %d", a,b,a>=b);
Printf("\n Result of double equal to operator of %d and %d is %d",a,b,a==b);
Printf("\n Result of not equal to operator of %d and %d is %d",a,b,a!=b);
Getch();
}
Output:
Enter two numbers
5
3
Result of less than operator of 5 and 3 is 0
Result of greater than operator of 5 and 3 is 1
Result of less than or equal to operator of 5 and 3 is 0
Result of greater than or equal to operator of 5 and 3 is 1
Result of double equal to operator of 5 and 3 is 0
Result of not equal to operator of 5 and 3 is 1
Evaluate an expression represented by a String. Expression can contain parentheses; you can assume parentheses are well-matched. For simplicity, you can assume only binary operations allowed are +, -, *, and /. Arithmetic Expressions can be written in one of three forms:
Infix Notation: Operators are written between the operands they operate on, e.g. 3 + 4 .
Prefix Notation: Operators are written before the operands, e.g + 3 4
Postfix Notation: Operators are written after operands.
Infix Expressions are harder for Computers to evaluate because of the additional work needed to decide precedence. Infix notation is how expressions are written and recognized by humans and, generally, input to programs. Given that they are harder to evaluate, they are generally converted to one of the two remaining forms. A very well-known algorithm for converting an infix notation to a postfix notation is Shunting Yard Algorithm by Edgar Dijkstra. This algorithm takes as input an Infix Expression and produces a queue that has this expression converted to a postfix notation. Same algorithm can be modified so that it outputs result of evaluation of expression instead of a queue. Trick is using two stacks instead of one, one for operands and one for operators. Algorithm was described succinctly on http://www.cis.upenn.edu/ matuszek/cit594-2002/Assignments/5-expressions.htm, and is re-produced here. (Note that credit for succinctness goes to author of said page)
1. While there are still tokens to be read in,
1.2.1 A number: push it onto the value stack.
1.2.2 A variable: get its value, and push onto the value stack.
1.2.3 A left parenthesis: push it onto the operator stack.
1.2.4 A right parenthesis:
1 While the thing on top of the operator stack is not a
Left parenthesis,
1 Pop the operator from the operator stack.
2 Pop the value stack twice, getting two operands.
3 Apply the operator to the operands, in the correct order.
4 Push the result onto the value stack.
2 Pop the left parenthesis from the operator stack, and discard it.
1.2.5 An operator (call it thisOp):
1 While the operator stack is not empty, and the top thing on the
Operator stack has the same or greater precedence as thisOp,
1 Pop the operator from the operator stack.
2 Pop the value stack twice, getting two operands.
3 Apply the operator to the operands, in the correct order.
4 Push the result onto the value stack.
2 Push thisOp onto the operator stack.
2. While the operator stack is not empty,
1 Pop the operator from the operator stack.
2 Pop the value stack twice, getting two operands.
3 Apply the operator to the operands, in the correct order.
4 Push the result onto the value stack.
3. At this point the operator stack should be empty, and the value
Stack should have only one value in it, which is the final result.
Following is the implementation of above algorithm:
// CPP program to evaluate a given // expression where tokens are // separated by space. #include <bits/stdc++.h> Using namespace std;
// Function to find precedence of // operators. Int precedence(char op){ If(op == '+'||op == '-') Return 1; If(op == '*'||op == '/') Return 2; Return 0; }
// Function to perform arithmetic operations. Int applyOp(int a, int b, char op){ Switch(op){ Case '+': return a + b; Case '-': return a - b; Case '*': return a * b; Case '/': return a / b; } }
// Function that returns value of // expression after evaluation. Int evaluate(string tokens){ Int i;
// stack to store integer values. Stack <int> values;
// stack to store operators. Stack <char> ops;
For(i = 0; i < tokens.length(); i++){
// Current token is a whitespace, // skip it. If(tokens[i] == ' ') Continue;
// Current token is an opening // brace, push it to 'ops' Else if(tokens[i] == '('){ Ops.push(tokens[i]); }
// Current token is a number, push // it to stack for numbers. Else if(isdigit(tokens[i])){ Int val = 0;
// There may be more than one // digits in number. While(i < tokens.length() && Isdigit(tokens[i])) { Val = (val*10) + (tokens[i]-'0'); i++; }
Values.push(val); }
// Closing brace encountered, solve // entire brace. Else if(tokens[i] == ')') { While(!ops.empty() && ops.top() != '(') { Int val2 = values.top(); Values.pop();
Int val1 = values.top(); Values.pop();
Char op = ops.top(); Ops.pop();
Values.push(applyOp(val1, val2, op)); }
// pop opening brace. If(!ops.empty()) Ops.pop(); }
// Current token is an operator. Else { // While top of 'ops' has same or greater // precedence to current token, which // is an operator. Apply operator on top // of 'ops' to top two elements in values stack. While(!ops.empty() && precedence(ops.top()) >= precedence(tokens[i])){ Int val2 = values.top(); Values.pop();
Int val1 = values.top(); Values.pop();
Char op = ops.top(); Ops.pop();
Values.push(applyOp(val1, val2, op)); }
// Push current token to 'ops'. Ops.push(tokens[i]); } }
// Entire expression has been parsed at this // point, apply remaining ops to remaining // values. While(!ops.empty()){ Int val2 = values.top(); Values.pop();
Int val1 = values.top(); Values.pop();
Char op = ops.top(); Ops.pop();
Values.push(applyOp(val1, val2, op)); }
// Top of 'values' contains result, return it. Return values.top(); }
Int main() { Cout << evaluate("10 + 2 * 6") << "\n"; Cout << evaluate("100 * 2 + 12") << "\n"; Cout << evaluate("100 * ( 2 + 12 )") << "\n"; Cout << evaluate("100 * ( 2 + 12 ) / 14"); Return 0; }
// This code is contributed by Nikhil jindal. |
Output:
22
212
1400
100
Time Complexity: O(n)
Space Complexity: O(n)
A storage class is used to describe the following things:
- The variable scope.
- The location where the variable will be stored.
- The initialized value of a variable.
- A lifetime of a variable.

Implicit type conversion:
Also known as ‘automatic type conversion’.
- Done by the compiler on its own, without any external trigger from the user.
- Generally, takes place when in an expression more than one data type is present. In such condition type conversion (type promotion) takes place to avoid to loose data.
- All the data types of the variables are upgraded to the data type of the variable with largest data type.
Bool -> char -> short int -> int ->
Unsigned int -> long -> unsigned ->
Long long -> float -> double -> long double
It is possible for implicit conversions to lose information, signs can be lost (when signed is implicitly converted to unsigned), and overflow can occur (when long is implicitly converted to float).
Example of Type Implicit Conversion:
// An example of implicit conversion #include<stdio.h> Int main() { Int x = 10; // integer x Char y = 'a'; // character c
// y implicitly converted to int. ASCII // value of 'a' is 97 x = x + y;
// x is implicitly converted to float Float z = x + 1.0;
Printf("x = %d, z = %f", x, z); Return 0; } |
|
Output:
x=107, z = 108.000000
Explicit Type Conversion–
This process is also called type casting and it is user defined. Here the user can type cast the result to make it of a particular data type.
The syntax in C:
(type) expression
Type indicated the data type to which the result is converted.
// C program to demonstrate explicit type casting #include<stdio.h>
Int main() { Double x = 1.2;
// Explicit conversion from double to int Int sum = (int)x + 1;
Printf("sum = %d", sum);
Return 0; }
Output:
Sum =2
Advantages of type conversion:
This is done to take advantage of certain features of type hierarchies or type representations.
It helps us to compute the expression containing variables of different data types.
|
The main method
According to coding standards, a good return program must exit the main function with 0. Although we are using void main() in C, In which we have not supposed to write any kind of return statement but that doesn’t mean that C code doesn’t require 0 as exit code. Let’s see one example to clear our thinking about need of return 0 statement in our code.
Example #1 :
#include <stdio.h>
Void main() {
// This code will run properly // but in the end, // it will demand an exit code. Printf("It works fine"); } |
Output:
It works fine
Runtime Error:
NZEC
As we can see in the output the compiler throws a runtime error NZEC, Which means that Non Zero Exit Code. That means that our main program exited with non-zero exiting code so if we want to be a developer than we make these small things in our mind.
Correct Code for C :
#include <stdio.h>
Int main() {
// This code will run properly // but in the end, // it will demand an exit code. Printf("This is correct output"); Return 0; } |
Output:
This is correct output
Note: Returning value other than zero will throw the same runtime error. So make sure our code return only 0.
Example #2 :
#include <stdio.h>
Int main() {
Printf("GeeksforGeeks"); Return "gfg"; } |
Output:
It works fine
Runtime Error:
NZEC
Correct Code for C :
#include <stdio.h>
Int main() {
Printf("GeeksforGeeks"); Return 0; } |
Output:
GeeksforGeeks
In case of C++, We are not able to use void keyword with our main() function according to coding namespace standards that’s why we only intend to use int keyword only with main function in C++. Let’s see some examples to justify these statements.
Example #3 :
#include <iostream> Using namespace std;
Void main() { Cout << "GeeksforGeeks"; } |
Compile Errors:
Prog.cpp:4:11: error: '::main' must return 'int'
Void main()
^
Correct Code for C++ :
#include <iostream> Using namespace std;
Int main() { Cout << "GeeksforGeeks"; Return 0; } |
Output:
GeeksforGeeks
Example #4 :
#include <iostream> Using namespace std;
Char main() { Cout << "GeeksforGeeks"; Return "gfg"; } |
Compile Errors:
Prog.cpp:4:11: error: '::main' must return 'int'
Char main()
^
Prog.cpp: In function 'int main()':
Prog.cpp:7:9: error: invalid conversion from 'const char*' to 'int' [-fpermissive]
Return "gfg";
^
Correct Code for C++ :
#include <iostream> Using namespace std;
Int main() { Cout << "GeeksforGeeks"; Return 0; } |
Output:
GeeksforGeeks
Command line argument
The arguments passed from command line are called command line arguments. These arguments are handled by main() function.
To support command line argument, you need to change the structure of main() function as given below.
Int main(int argc, char *argv[] )
Here, argc counts the number of arguments. It counts the file name as the first argument.
The argv[] contains the total number of arguments. The first argument is the file name always.
Example
Let's see the example of command line arguments where we are passing one argument with file name.
#include <stdio.h>
Void main(int argc, char *argv[] ) {
Printf("Program name is: %s\n", argv[0]);
If(argc < 2){
Printf("No argument passed through command line.\n");
}
Else{
Printf("First argument is: %s\n", argv[1]);
}
}
Run this program as follows in Linux:
./program hello
Run this program as follows in Windows from command line:
Program.exe hello
Output:
Program name is: program
First argument is: hello
If you pass many arguments, it will print only one.
./program hello c how r u
Output:
Program name is: program
First argument is: hello
But if you pass many arguments within double quote, all arguments will be treated as a single argument only.
./program "hello c how r u"
Output:
Program name is: program
First argument is: hello c how r u
- These operators are used to work on the each bits of data. These operators can work on the binary data. If the data is non binary then computer first of all convert it into binary form and then perform the operation. Following are the list of logical operator in C language. To understand the operation assume variable A contains value 10 and variable contains value 5. So the binary values of
A = 0000 1010 and
B = 0000 0101
Sr. No. | Operator | Description | Example |
1. | & | This is bitwise AND | Result of (A&B) is 0000 0000 |
2. | | | This is bitwise OR | Result of (A|B) is 0000 1111 |
3. | ^ | This is bitwise Exclusive | Result of (A^B) is 0000 1111 |
4. | << | This is used to shift bit on left side | Result of (A<<B) is |
5. | >> | This is used to shift bit on right side | Result of (A>>B) is |
Example:
#include<stdio.h>
#include<conio.h>
Void main()
{
Int a,b,c;
Clrscr();
Printf("Enter two numbers");
Scanf("%d %d",&a,&b);
Printf("\n Result of bitwise and operator of %d and %d is %d",a,b,a&b);
Printf("\n Result of bitwise or operator of %d and %d is %d",a,b,a|b);
Printf("\n Result of bitwise exclusive operator of %d and %d is %d",a,b,a^b);
Printf("\n Result of bitwise left shift operator of %d and %d is %d",a,b,a<<b);
Printf("\n Result of bitwise right shift operator of %d and %d is %d",a,b,a>>b);
Getch();
}
Output:
Enter two numbers
5
3
Result of bitwise and operator of 5 and 3 is 1
Result of bitwise or operator of 5 and 3 is 7
Result of bitwise exclusive operator of 5 and 3 is 6
Result of bitwise left shift operator of 5 and 3 is 40
Result of bitwise right shift operator of 5 and 3 is 0
In conditional branching decision point is based on the run time logic. Conditional branching makes use of both selection logic and iteration logic. In conditional branching flow of program is transfer when the specified condition is satisfied.

Fig. Flowchart for conditional branching
In conditional branching change in sequence of statement execution is depends upon the specified condition. Conditional statements allow programmer to check a condition and execute certain parts of code depending on the result of conditional expression. Conditional expression must be resulted into Boolean value. In C language, there are two forms of conditional statements:
1. If-----else statement: It is used to select one option between two alternatives
2. Switch statement: It is used to select one option between multiple alternative
- If Statements
This statement permits the programmer to allocate condition on the execution of a statement. If the evaluated condition found to be true, the single statement following the "if" is execute. If the condition is found to be false, the following statement is skipped. Syntax of the if statement is as follows
if (condition)
statement1;
statement2;
In the above syntax, “if” is the keyword and condition in parentheses must evaluate to true or false. If the condition is satisfied (true) then compiler will execute statement1 and then statement2. If the condition is not satisfied (false) then compiler will skip statement1 and directly execute statement2.
if-----else statement
This statement permits the programmer to execute a statement out of the two statements. If the evaluated condition is found to be true, the single statement following the "if" is executed and statement following else is skipped. If the condition is found to be false, statement following the "if" is skipped and statement following else is executed.
In this statement “if” part is compulsory whereas “else” is the optional part. For every “if” statement there may be or may not be “else” statement but for every “else” statement there must be “if” part otherwise compiler will gives “Misplaced else” error.
Syntax of the “if----else” statement is as follows
If (condition)
Statement1;
Else
Statement2;
In the above syntax, “if” and “else” are the keywords and condition in parentheses must evaluate to true or false. If the condition is satisfied (true) then compiler will execute statement1 and skip statement2. If the condition is not satisfied (false) then compiler will skip statement1 and directly execute statement2.
Nested if-----else statements :
Nested “if-----else” statements are used when programmer wants to check multiple conditions. Nested “if---else” contains several “if---else” a statement out of which only one statement is executed. Number of “if----else” statements is equal to the number of conditions to be checked. Following is the syntax for nested “if---else” statements for three conditions
If (condition1)
Statement1;
Else if (condition2)
Statement2;
Else if (condition3)
Statement3;
Else
Statement4;
In the above syntax, compiler first check condition1, if it trues then it will execute statement1 and skip all the remaining statements. If condition1 is false then compiler directly checks condition2, if it is true then compiler execute statement2 and skip all the remaining statements. If condition2 is also false then compiler directly checks condition3, if it is true then compiler execute statement3 otherwise it will execute statement 4.
Note:
If the test expression is evaluated to true,
• Statements inside the body of if are executed.
• Statements inside the body of else are skipped from execution.
If the test expression is evaluated to false,
• Statements inside the body of else are executed
• Statements inside the body of if are skipped from execution.
// Check whether an integer is odd or even
#include <stdio.h>
Int main() {
Int number;
Printf("Enter an integer: ");
Scanf("%d", &number);
// True if the remainder is 0
If (number%2 == 0) {
Printf("%d is an even integer.",number);
}
Else {
Printf("%d is an odd integer.",number);
}
Return 0;
}
Program to relate two integers using =, > or < symbol
#include <stdio.h>
Int main() {
Int number1, number2;
Printf("Enter two integers: ");
Scanf("%d %d", &number1, &number2);
//checks if the two integers are equal.
If(number1 == number2) {
Printf("Result: %d = %d",number1,number2);
}
//checks if number1 is greater than number2.
Else if (number1 > number2) {
Printf("Result: %d > %d", number1, number2);
}
//checks if both test expressions are false
Else {
Printf("Result: %d < %d",number1, number2);
}
Return 0;
}
- Switch Statements
This statement permits the programmer to choose one option out of several options depending on one condition. When the “switch” statement is executed, the expression in the switch statement is evaluated and the control is transferred directly to the group of statements whose “case” label value matches with the value of the expression. Syntax for switch statement is as follows:
Switch(expression)
{
Case constant1:
Statements 1;
Break;
Case constant2:
Statements 2;
Break;
…………………..
Default:
Statements n;
Break;
}
In the above, “switch”, “case”, “break” and “default” are keywords. Out of which “switch” and “case” are the compulsory keywords whereas “break” and “default” is optional keywords.
- “switch” keyword is used to start switch statement with conditional expression.
- “case” is the compulsory keyword which labeled with a constant value. If the value of expression matches with the case value then statement followed by “case” statement is executed.
- “break” is the optional keyword in switch statement. The execution of “break” statement causes the transfer of flow of execution outside the “switch” statements scope. Absence of “break” statement causes the execution of all the following “case” statements without concerning value of the expression.
- “default” is the optional keyword in “switch” statement. When the value of expression is not match with the any of the “case” statement then the statement following “default” keyword is executed.
Example: Program to spell user entered single digit number in English is as follows
#include<stdio.h>
#include<conio.h>
Void main()
{
Int n;
Clrscr();
Printf("Enter a number");
Scanf("%d",&n);
Switch(n)
{
Case 0: printf("\n Zero");
Break;
Case 1: printf("\n One");
Break;
Case 2: printf("\n Two");
Break;
Case 3: printf("\n Three");
Break;
Case 4: printf("\n Four");
Break;
Case 5: printf("\n Five");
Break;
Case 6: printf("\n Six");
Break;
Case 7: printf("\n Seven");
Break;
Case 8: printf("\n Eight");
Break;
Case 9: printf("\n Nine");
Break;
Default: printf("Given number is not single digit number");
}
Getch();
}
Output
Enter a number
5
Five
Simple input and output with scanf and printf
C language has standard libraries that allow input and output in a program. The stdio.h or standard input output library in C that has methods for input and output.
Scanf()
The scanf() method, in C, reads the value from the console as per the type specified.
Syntax:
Scanf(“%X”, &variableOfXType);
Where %X is the format specifier in C. It is a way to tell the compiler what type of data is in a variable
And
& is the address operator in C, which tells the compiler to change the real value of this variable, stored at this address in the memory.
Printf()
The printf() method, in C, prints the value passed as the parameter to it, on the console screen.
Syntax:
Printf(“%X”, variableOfXType);
Where %X is the format specifier in C. It is a way to tell the compiler what type of data is in a variable
And
& is the address operator in C, which tells the compiler to change the real value of this variable, stored at this address in the memory.
How to take input and output of basic types in C?
The basic type in C includes types like int, float, char, etc. In order to input or output the specific type, the X in the above syntax is changed with the specific format specifier of that type.
The Syntax for input and output for these are:
- Integer:
- Input: scanf("%d", &intVariable);
- Output: printf("%d", intVariable);
- Float:
- Input: scanf("%f", &floatVariable);
- Output: printf("%f", floatVariable);
- Character:
- Input: scanf("%c", &charVariable);
- Output: printf("%c", charVariable);
Please refer Format specifiers in C for more examples.
// C program to show input and output
#include <stdio.h> Int main() {
// Declare the variables Int num; Char ch; Float f;
// --- Integer ---
// Input the integer Printf("Enter the integer: "); Scanf("%d", &num);
// Output the integer Printf("\nEntered integer is: %d", num);
// --- Float ---
// Input the float Printf("\n\nEnter the float: "); Scanf("%f", &f);
// Output the float Printf("\nEntered float is: %f", f);
// --- Character ---
// Input the Character Printf("\n\nEnter the Character: "); Scanf("%c", &ch);
// Output the Character Printf("\nEntered integer is: %c", ch);
Return 0; } |
Output:
Enter the integer: 10
Entered integer is: 10
Enter the float: 2.5
Entered float is: 2.500000
Enter the Character: A
Entered integer is: A
How to take input and output of advanced type in C?
The advanced type in C includes type like String. In order to input or output the string type, the X in the above syntax is changed with the %s format specifier.
The Syntax for input and output for String is:
Input: scanf("%s", stringVariable);
Output: printf("%s", stringVariable);
Example:
// C program to show input and output
#include <stdio.h>
Int main() {
// Declare string variable // as character array Char str[50];
// --- String --- // To read a word
// Input the Word Printf("Enter the Word: "); Scanf("%s\n", str);
// Output the Word Printf("\nEntered Word is: %s", str);
// --- String --- // To read a Sentence
// Input the Sentence Printf("\n\nEnter the Sentence: "); Scanf("%[^\n]\ns", str);
// Output the String Printf("\nEntered Sentence is: %s", str);
Return 0; } |
Output:
Enter the Word: GeeksForGeeks
Entered Word is: GeeksForGeeks
Enter the Sentence: Geeks For Geeks
Entered Sentence is: Geeks For Geeks
Formatted I/O
C++ helps you to format the I/O operations like determining the number of digits to be displayed after the decimal point, specifying number base etc.
Example:
- If we want to add + sign as the prefix of out output, we can use the formatting to do so:
- Stream.setf(ios::showpos)
If input=100, output will be +100
- If we want to add trailing zeros in out output to be shown when needed using the formatting:
- Stream.setf(ios::showpoint)
If input=100.0, output will be 100.000
Note: Here, stream is referred to the streams defined in c++ like cin, cout, cerr, clog.
There are two ways to do so:
- Using the ios class or various ios member functions.
- Using manipulators(special functions)
- Formatting using the ios members:
The stream has the format flags that control the way of formatting it means Using this self function, we can set the flags, which allow us to display a value in a particular format. The ios class declares a bitmask enumeration called fmtflags in which the values(show base, show point, oct, hex etc) are defined. These values are used to set or clear the format flags.
Few standard ios class functions are:
- Width(): The width method is used to set the required field width. The output will be displayed in the given width
- Precision(): The precision method is used to set the number of the decimal point to a float value
- Fill(): The fill method is used to set a character to fill in the blank space of a field
- Setf(): The setf method is used to set various flags for formatting output
- Unsetf(): The unsetf method is used To remove the flag setting
Working:
#include<bits/stdc++.h> Using namespace std;
// The width() function defines width // of the next value to be displayed // in the output at the console. Void IOS_width() { Cout << "--------------------------\n"; Cout << "Implementing ios::width\n\n";
Char c = 'A';
// Adjusting width will be 5. Cout.width(5); Cout << c <<"\n";
Int temp = 10;
// Width of the next value to be // displayed in the output will // not be adjusted to 5 columns. Cout<<temp; Cout << "\n--------------------------\n"; }
Void IOS_precision() { Cout << "\n--------------------------\n"; Cout << "Implementing ios::precision\n\n"; Cout << "Implementing ios::width"; Cout.setf(ios::fixed, ios::floatfield); Cout.precision(2); Cout<<3.1422; Cout << "\n--------------------------\n"; }
// The fill() function fills the unused // white spaces in a value (to be printed // at the console), with a character of choice. Void IOS_fill() { Cout << "\n--------------------------\n"; Cout << "Implementing ios::fill\n\n"; Char ch = 'a';
// Calling the fill function to fill // the white spaces in a value with a // character our of choice. Cout.fill('*');
Cout.width(10); Cout<<ch <<"\n";
Int i = 1;
// Once you call the fill() function, // you don't have to call it again to // fill the white space in a value with // the same character. Cout.width(5); Cout<<i; Cout << "\n--------------------------\n"; }
Void IOS_setf() { Cout << "\n--------------------------\n"; Cout << "Implementing ios::setf\n\n"; Int val1=100,val2=200; Cout.setf(ios::showpos); Cout<<val1<<" "<<val2; Cout << "\n--------------------------\n"; }
Void IOS_unsetf() { Cout << "\n--------------------------\n"; Cout << "Implementing ios::unsetf\n\n"; Cout.setf(ios::showpos|ios::showpoint); // Clear the showflag flag without // affecting the showpoint flag Cout.unsetf(ios::showpos); Cout<<200.0; Cout << "\n--------------------------\n"; }
// Driver Method Int main() { IOS_width(); IOS_precision; IOS_fill(); IOS_setf(); IOS_unsetf(); Return 0; } |
Output:
--------------------------
Implementing ios::width
A
10
--------------------------
--------------------------
Implementing ios::fill
*********a
****1
--------------------------
--------------------------
Implementing ios::setf
+100 +200
--------------------------
--------------------------
Implementing ios::unsetf
200.000
--------------------------
II. Formatting using Manipulators
The second way you can alter the format parameters of a stream is through the use of special functions called manipulators that can be included in an I/O expression.
The standard manipulators are shown below:
- Boolalpha: The boolalpha manipulator of stream manipulators in C++ is used to turn on bool alpha flag
- Dec: The dec manipulator of stream manipulators in C++ is used to turn on the dec flag
- Endl: The endl manipulator of stream manipulators in C++ is used to Output a newline character.
- And: The and manipulator of stream manipulators in C++ is used to Flush the stream
- Ends: The ends manipulator of stream manipulators in C++ is used to Output a null
- Fixed: The fixed manipulator of stream manipulators in C++ is used to Turns on the fixed flag
- Flush: The flush manipulator of stream manipulators in C++ is used to Flush a stream
- Hex: The hex manipulator of stream manipulators in C++ is used to Turns on hex flag
- Internal: The internal manipulator of stream manipulators in C++ is used to Turns on internal flag
- Left: The left manipulator of stream manipulators in C++ is used to Turns on the left flag
- Noboolalpha: The noboolalpha manipulator of stream manipulators in C++ is used to Turns off bool alpha flag
- Noshowbase: The noshowbase manipulator of stream manipulators in C++ is used to Turns off showcase flag
- Noshowpoint: The noshowpoint manipulator of stream manipulators in C++ is used to Turns off show point flag
- Noshowpos: The noshowpos manipulator of stream manipulators in C++ is used to Turns off showpos flag
- Noskipws: The noskipws manipulator of stream manipulators in C++ is used to Turns off skipws flag
- Nounitbuf: The nounitbuf manipulator of stream manipulators in C++ is used to Turns off the unit buff flag
- Nouppercase: The nouppercase manipulator of stream manipulators in C++ is used to Turns off the uppercase flag
- Oct: The oct manipulator of stream manipulators in C++ is used to Turns on oct flag
- Resetiosflags(fmtflags f): The resetiosflags manipulator of stream manipulators in C++ is used to Turns off the flag specified in f
- Right: The right manipulator of stream manipulators in C++ is used to Turns on the right flag
- Scientific: The scientific manipulator of stream manipulators in C++ is used to Turns on scientific flag
- Setbase(int base): The setbase manipulator of stream manipulators in C++ is used to Set the number base to base
- Setfill(int ch): The setfill manipulator of stream manipulators in C++ is used to Set the fill character to ch
- Setiosflags(fmtflags f): The setiosflags manipulator of stream manipulators in C++ is used to Turns on the flag specified in f
- Setprecision(int p): The setprecision manipulator of stream manipulators in C++ is used to Set the number of digits of precision
- Setw(int w): The setw manipulator of stream manipulators in C++ is used to Set the field width to w
- Showbase: The showbase manipulator of stream manipulators in C++ is used to Turns on showbase flag
- Showpoint: The showpoint manipulator of stream manipulators in C++ is used to Turns on show point flag
- Showpos: The showpos manipulator of stream manipulators in C++ is used to Turns on showpos flag
- Skipws: The skipws manipulator of stream manipulators in C++ is used to Turns on skipws flag
- Unitbuf: The unitbuf manipulator of stream manipulators in C++ is used to turn on unitbuf flag
- Uppercase: The uppercase manipulator of stream manipulators in C++ is used to turn on the uppercase flag
- Ws: The ws manipulator of stream manipulators in C++ is used to skip leading white space
To access manipulators that take parameters (such as setw( )), you must include “iomanip” header file in your program.
Example:
#include <iomanip> #include <iostream> Using namespace std; Void Example() { // performs ssame as setf( ) Cout << setiosflags(ios::showpos); Cout << 123<<"\n";
// hexadecimal base (i.e., radix 16) Cout << hex << 100 << endl;
// Set the field width Cout << setfill('*') << setw(10) << 2343.0; }
Int main() { Example(); Return 0; } |
Output:
+123
64
*****+2343
The manipulator setiosflags( ) .
When we say Input, it means to feed some data into a program. An input can be given in the form of a file or from the command line. C programming provides a set of built-in functions to read the given input and feed it to the program as per requirement.
When we say Output, it means to display some data on screen, printer, or in any file. C programming provides a set of built-in functions to output the data on the computer screen as well as to save it in text or binary files.
The Standard Files
C programming treats all the devices as files. So devices such as the display are addressed in the same way as files and the following three files are automatically opened when a program executes to provide access to the keyboard and screen.
Standard File | File Pointer | Device |
Standard input | Stdin | Keyboard |
Standard output | Stdout | Screen |
Standard error | Stderr | Your screen |
The file pointers are the means to access the file for reading and writing purpose. This section explains how to read values from the screen and how to print the result on the screen.
The getchar() and putchar() Functions
The int getchar(void) function reads the next available character from the screen and returns it as an integer. This function reads only single character at a time. You can use this method in the loop in case you want to read more than one character from the screen.
The int putchar(int c) function puts the passed character on the screen and returns the same character. This function puts only single character at a time. You can use this method in the loop in case you want to display more than one character on the screen. Check the following example −
#include <stdio.h>
Int main( ) {
Int c;
Printf( "Enter a value :");
c = getchar( );
Printf( "\nYou entered: ");
Putchar( c );
Return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then the program proceeds and reads only a single character and displays it as follows −
$./a.out
Enter a value : this is test
You entered: t
The gets() and puts() Functions
The char *gets(char *s) function reads a line from stdin into the buffer pointed to by s until either a terminating newline or EOF (End of File).
The int puts(const char *s) function writes the string 's' and 'a' trailing newline to stdout.
NOTE: Though it has been deprecated to use gets() function, Instead of using gets, you want to use fgets().
#include <stdio.h>
Int main( ) {
Char str[100];
Printf( "Enter a value :");
Gets( str );
Printf( "\nYou entered: ");
Puts( str );
Return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then the program proceeds and reads the complete line till end, and displays it as follows −
$./a.out
Enter a value : this is test
You entered: this is test
The scanf() and printf() Functions
The int scanf(const char *format, ...) function reads the input from the standard input stream stdin and scans that input according to the format provided.
The int printf(const char *format, ...) function writes the output to the standard output stream stdout and produces the output according to the format provided.
The format can be a simple constant string, but you can specify %s, %d, %c, %f, etc., to print or read strings, integer, character or float respectively. There are many other formatting options available which can be used based on requirements. Let us now proceed with a simple example to understand the concepts better −
#include <stdio.h>
Int main( ) {
Char str[100];
Int i;
Printf( "Enter a value :");
Scanf("%s %d", str, &i);
Printf( "\nYou entered: %s %d ", str, i);
Return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then program proceeds and reads the input and displays it as follows −
$./a.out
Enter a value : seven 7
You entered: seven 7
Here, it should be noted that scanf() expects input in the same format as you provided %s and %d, which means you have to provide valid inputs like "string integer". If you provide "string string" or "integer integer", then it will be assumed as wrong input. Secondly, while reading a string, scanf() stops reading as soon as it encounters a space, so "this is test" are three strings for scanf().
The arguments passed from command line are called command line arguments. These arguments are handled by main() function.
To support command line argument, you need to change the structure of main() function as given below.
- Int main(int argc, char *argv[] )
Here, argc counts the number of arguments. It counts the file name as the first argument.
The argv[] contains the total number of arguments. The first argument is the file name always.
Example
Let's see the example of command line arguments where we are passing one argument with file name.
- #include <stdio.h>
- Void main(int argc, char *argv[] ) {
- Printf("Program name is: %s\n", argv[0]);
- If(argc < 2){
- Printf("No argument passed through command line.\n");
- }
- Else{
- Printf("First argument is: %s\n", argv[1]);
- }
- }
Run this program as follows in Linux:
- ./program hello
Run this program as follows in Windows from command line:
- Program.exe hello
Output:
Program name is: program
First argument is: hello
If you pass many arguments, it will print only one.
- ./program hello c how r u
Output:
Program name is: program
First argument is: hello
But if you pass many arguments within double quote, all arguments will be treated as a single argument only.
- ./program "hello c how r u"
Output:
Program name is: program
First argument is: hello c how r u




