UNIT 1
Introduction to Programming
All types of computers follow the same basic logical structure and perform the following five basic operations for converting raw input data into information useful to their users.
S.No. | Operation | Description |
1 | Take Input | The process of entering data and instructions into the computer system. |
2 | Store Data | Saving data and instructions so that they are available for processing as and when required. |
3 | Processing Data | Performing arithmetic, and logical operations on data in order to convert them into useful information. |
4 | Output Information | The process of producing useful information or results for the user, such as a printed report or visual display. |
5 | Control the workflow | Directs the manner and sequence in which all of the above operations are performed. |
Input Unit
This unit contains devices with the help of which we enter data into the computer. This unit creates a link between the user and the computer. The input devices translate the information into a form understandable by the computer.
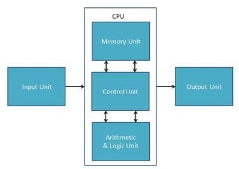
CPU (Central Processing Unit)
CPU is considered as the brain of the computer. CPU performs all types of data processing operations. It stores data, intermediate results, and instructions (program). It controls the operation of all parts of the computer.
CPU itself has the following three components −
- ALU (Arithmetic Logic Unit)
- Memory Unit
- Control Unit
Output Unit
The output unit consists of devices with the help of which we get the information from the computer. This unit is a link between the computer and the users. Output devices translate the computer's output into a form understandable by the users.
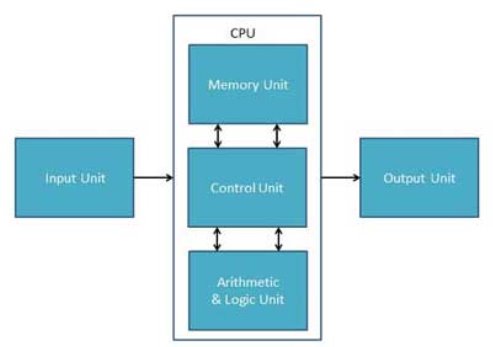
CPU (Central Processing Unit)
Central Processing Unit (CPU) consists of the following features −
- CPU is considered as the brain of the computer.
- CPU performs all types of data processing operations.
- It stores data, intermediate results, and instructions (program).
- It controls the operation of all parts of the computer.

CPU itself has following three components.
- Memory or Storage Unit
- Control Unit
- ALU(Arithmetic Logic Unit)
Memory or Storage Unit
This unit can store instructions, data, and intermediate results. This unit supplies information to other units of the computer when needed. It is also known as internal storage unit or the main memory or the primary storage or Random Access Memory (RAM).
Its size affects speed, power, and capability. Primary memory and secondary memory are two types of memories in the computer. Functions of the memory unit are −
- It stores all the data and the instructions required for processing.
- It stores intermediate results of processing.
- It stores the final results of processing before these results are released to an output device.
- All inputs and outputs are transmitted through the main memory.
Control Unit
This unit controls the operations of all parts of the computer but does not carry out any actual data processing operations.
Functions of this unit are −
- It is responsible for controlling the transfer of data and instructions among other units of a computer.
- It manages and coordinates all the units of the computer.
- It obtains the instructions from the memory, interprets them, and directs the operation of the computer.
- It communicates with Input/Output devices for transfer of data or results from storage.
- It does not process or store data.
ALU (Arithmetic Logic Unit)
This unit consists of two subsections namely,
- Arithmetic Section
- Logic Section
Arithmetic Section
Function of arithmetic section is to perform arithmetic operations like addition, subtraction, multiplication, and division. All complex operations are done by making repetitive use of the above operations.
Logic Section
Function of logic section is to perform logic operations such as comparing, selecting, matching, and merging of data.
Input Devices
Following are some of the important input devices which are used in a computer −
- Keyboard
- Mouse
- Joy Stick
- Light pen
- Track Ball
- Scanner
- Graphic Tablet
- Microphone
- Magnetic Ink Card Reader(MICR)
- Optical Character Reader(OCR)
- Bar Code Reader
- Optical Mark Reader(OMR)
Keyboard
Keyboard is the most common and very popular input device which helps to input data to the computer. The layout of the keyboard is like that of traditional typewriter, although there are some additional keys provided for performing additional functions.

Keyboards are of two sizes 84 keys or 101/102 keys, but now keyboards with 104 keys or 108 keys are also available for Windows and Internet.
The keys on the keyboard are as follows −
S.No | Keys & Description |
1 | Typing Keys These keys include the letter keys (A-Z) and digit keys (09) which generally give the same layout as that of typewriters. |
2 | Numeric Keypad It is used to enter the numeric data or cursor movement. Generally, it consists of a set of 17 keys that are laid out in the same configuration used by most adding machines and calculators. |
3 | Function Keys The twelve function keys are present on the keyboard which are arranged in a row at the top of the keyboard. Each function key has a unique meaning and is used for some specific purpose. |
4 | Control keys These keys provide cursor and screen control. It includes four directional arrow keys. Control keys also include Home, End, Insert, Delete, Page Up, Page Down, Control(Ctrl), Alternate(Alt), Escape(Esc). |
5 | Special Purpose Keys Keyboard also contains some special purpose keys such as Enter, Shift, Caps Lock, Num Lock, Space bar, Tab, and Print Screen. |
Mouse
Mouse is the most popular pointing device. It is a very famous cursor-control device having a small palm size box with a round ball at its base, which senses the movement of the mouse and sends corresponding signals to the CPU when the mouse buttons are pressed.
Generally, it has two buttons called the left and the right button and a wheel is present between the buttons. A mouse can be used to control the position of the cursor on the screen, but it cannot be used to enter text into the computer.

Advantages
- Easy to use
- Not very expensive
- Moves the cursor faster than the arrow keys of the keyboard.
Joystick
Joystick is also a pointing device, which is used to move the cursor position on a monitor screen. It is a stick having a spherical ball at its both lower and upper ends. The lower spherical ball moves in a socket. The joystick can be moved in all four directions.

The function of the joystick is similar to that of a mouse. It is mainly used in Computer Aided Designing (CAD) and playing computer games.
Light Pen
Light pen is a pointing device similar to a pen. It is used to select a displayed menu item or draw pictures on the monitor screen. It consists of a photocell and an optical system placed in a small tube.
When the tip of a light pen is moved over the monitor screen and the pen button is pressed, its photocell sensing element detects the screen location and sends the corresponding signal to the CPU.
Track Ball
Track ball is an input device that is mostly used in notebook or laptop computer, instead of a mouse. This is a ball which is half inserted and by moving fingers on the ball, the pointer can be moved.

Since the whole device is not moved, a track ball requires less space than a mouse. A track ball comes in various shapes like a ball, a button, or a square.
Scanner
Scanner is an input device, which works more like a photocopy machine. It is used when some information is available on paper and it is to be transferred to the hard disk of the computer for further manipulation.

Scanner captures images from the source which are then converted into a digital form that can be stored on the disk. These images can be edited before they are printed.
Digitizer
Digitizer is an input device which converts analog information into digital form. Digitizer can convert a signal from the television or camera into a series of numbers that could be stored in a computer. They can be used by the computer to create a picture of whatever the camera had been pointed at.

Digitizer is also known as Tablet or Graphics Tablet as it converts graphics and pictorial data into binary inputs. A graphic tablet as digitizer is used for fine works of drawing and image manipulation applications.
Microphone
Microphone is an input device to input sound that is then stored in a digital form.

The microphone is used for various applications such as adding sound to a multimedia presentation or for mixing music.
Magnetic Ink Card Reader (MICR)
MICR input device is generally used in banks as there are large number of cheques to be processed every day. The bank's code number and cheque number are printed on the cheques with a special type of ink that contains particles of magnetic material that are machine readable.

This reading process is called Magnetic Ink Character Recognition (MICR). The main advantages of MICR is that it is fast and less error prone.
Optical Character Reader (OCR)
OCR is an input device used to read a printed text.

OCR scans the text optically, character by character, converts them into a machine readable code, and stores the text on the system memory.
Bar Code Readers
Bar Code Reader is a device used for reading bar coded data (data in the form of light and dark lines). Bar coded data is generally used in labelling goods, numbering the books, etc. It may be a handheld scanner or may be embedded in a stationary scanner.

Bar Code Reader scans a bar code image, converts it into an alphanumeric value, which is then fed to the computer that the bar code reader is connected to.
Optical Mark Reader (OMR)
OMR is a special type of optical scanner used to recognize the type of mark made by pen or pencil. It is used where one out of a few alternatives is to be selected and marked.

It is specially used for checking the answer sheets of examinations having multiple choice questions.
Output Devices
Following are some of the important output devices used in a computer.
- Monitors
- Graphic Plotter
- Printer
Monitors
Monitors, commonly called as Visual Display Unit (VDU), are the main output device of a computer. It forms images from tiny dots, called pixels that are arranged in a rectangular form. The sharpness of the image depends upon the number of pixels.
There are two kinds of viewing screen used for monitors.
- Cathode-Ray Tube (CRT)
- Flat-Panel Display
Cathode-Ray Tube (CRT) Monitor
The CRT display is made up of small picture elements called pixels. The smaller the pixels, the better the image clarity or resolution. It takes more than one illuminated pixel to form a whole character, such as the letter ‘e’ in the word help.

A finite number of characters can be displayed on a screen at once. The screen can be divided into a series of character boxes - fixed location on the screen where a standard character can be placed. Most screens are capable of displaying 80 characters of data horizontally and 25 lines vertically.
There are some disadvantages of CRT −
- Large in Size
- High power consumption
Flat-Panel Display Monitor
The flat-panel display refers to a class of video devices that have reduced volume, weight and power requirement in comparison to the CRT. You can hang them on walls or wear them on your wrists. Current uses of flat-panel displays include calculators, video games, monitors, laptop computer, and graphics display.

The flat-panel display is divided into two categories −
- Emissive Displays− Emissive displays are devices that convert electrical energy into light. For example, plasma panel and LED (Light-Emitting Diodes).
- Non-Emissive Displays− Non-emissive displays use optical effects to convert sunlight or light from some other source into graphics patterns. For example, LCD (Liquid-Crystal Device).
Printers
Printer is an output device, which is used to print information on paper.
There are two types of printers −
- Impact Printers
- Non-Impact Printers
Impact Printers
Impact printers print the characters by striking them on the ribbon, which is then pressed on the paper.
Characteristics of Impact Printers are the following −
- Very low consumable costs
- Very noisy
- Useful for bulk printing due to low cost
- There is physical contact with the paper to produce an image
These printers are of two types −
- Character printers
- Line printers
Character Printers
Character printers are the printers which print one character at a time.
These are further divided into two types:
- Dot Matrix Printer(DMP)
- Daisy Wheel
Dot Matrix Printer
In the market, one of the most popular printers is Dot Matrix Printer. These printers are popular because of their ease of printing and economical price. Each character printed is in the form of pattern of dots and head consists of a Matrix of Pins of size (5*7, 7*9, 9*7 or 9*9) which come out to form a character which is why it is called Dot Matrix Printer.

Advantages
- Inexpensive
- Widely Used
- Other language characters can be printed
Disadvantages
- Slow Speed
- Poor Quality
Daisy Wheel
Head is lying on a wheel and pins corresponding to characters are like petals of Daisy (flower) which is why it is called Daisy Wheel Printer. These printers are generally used for word-processing in offices that require a few letters to be sent here and there with very nice quality.

Advantages
- More reliable than DMP
- Better quality
- Fonts of character can be easily changed
Disadvantages
- Slower than DMP
- Noisy
- More expensive than DMP
Line Printers
Line printers are the printers which print one line at a time.

These are of two types −
- Drum Printer
- Chain Printer
Drum Printer
This printer is like a drum in shape hence it is called drum printer. The surface of the drum is divided into a number of tracks. Total tracks are equal to the size of the paper, i.e. for a paper width of 132 characters, drum will have 132 tracks. A character set is embossed on the track. Different character sets available in the market are 48 character set, 64 and 96 characters set. One rotation of drum prints one line. Drum printers are fast in speed and can print 300 to 2000 lines per minute.
Advantages
- Very high speed
Disadvantages
- Very expensive
- Characters fonts cannot be changed
Chain Printer
In this printer, a chain of character sets is used, hence it is called Chain Printer. A standard character set may have 48, 64, or 96 characters.
Advantages
- Character fonts can easily be changed.
- Different languages can be used with the same printer.
Disadvantages
- Noisy
Non-impact Printers
Non-impact printers print the characters without using the ribbon. These printers print a complete page at a time, thus they are also called as Page Printers.
These printers are of two types −
- Laser Printers
- Inkjet Printers
Characteristics of Non-impact Printers
- Faster than impact printers
- They are not noisy
- High quality
- Supports many fonts and different character size
Laser Printers
These are non-impact page printers. They use laser lights to produce the dots needed to form the characters to be printed on a page.

Advantages
- Very high speed
- Very high quality output
- Good graphics quality
- Supports many fonts and different character size
Disadvantages
- Expensive
- Cannot be used to produce multiple copies of a document in a single printing
Inkjet Printers
Inkjet printers are non-impact character printers based on a relatively new technology. They print characters by spraying small drops of ink onto paper. Inkjet printers produce high quality output with presentable features.

They make less noise because no hammering is done and these have many styles of printing modes available. Color printing is also possible. Some models of Inkjet printers can produce multiple copies of printing also.
Advantages
- High quality printing
- More reliable
Disadvantages
- Expensive as the cost per page is high
- Slow as compared to laser printer
Memory
A memory is just like a human brain. It is used to store data and instructions. Computer memory is the storage space in the computer, where data is to be processed and instructions required for processing are stored. The memory is divided into large number of small parts called cells. Each location or cell has a unique address, which varies from zero to memory size minus one. For example, if the computer has 64k words, then this memory unit has 64 * 1024 = 65536 memory locations. The address of these locations varies from 0 to 65535.
Memory is primarily of three types −
- Cache Memory
- Primary Memory/Main Memory
- Secondary Memory
Cache Memory
Cache memory is a very high speed semiconductor memory which can speed up the CPU. It acts as a buffer between the CPU and the main memory. It is used to hold those parts of data and program which are most frequently used by the CPU. The parts of data and programs are transferred from the disk to cache memory by the operating system, from where the CPU can access them.

Advantages
The advantages of cache memory are as follows −
- Cache memory is faster than main memory.
- It consumes less access time as compared to main memory.
- It stores the program that can be executed within a short period of time.
- It stores data for temporary use.
Disadvantages
The disadvantages of cache memory are as follows −
- Cache memory has limited capacity.
- It is very expensive.
Primary Memory (Main Memory)
Primary memory holds only those data and instructions on which the computer is currently working. It has a limited capacity and data is lost when power is switched off. It is generally made up of semiconductor device. These memories are not as fast as registers. The data and instruction required to be processed resides in the main memory. It is divided into two subcategories RAM and ROM.

Characteristics of Main Memory
- These are semiconductor memories.
- It is known as the main memory.
- Usually volatile memory.
- Data is lost in case power is switched off.
- It is the working memory of the computer.
- Faster than secondary memories.
- A computer cannot run without the primary memory.
Secondary Memory
This type of memory is also known as external memory or non-volatile. It is slower than the main memory. These are used for storing data/information permanently. CPU directly does not access these memories, instead they are accessed via input-output routines. The contents of secondary memories are first transferred to the main memory, and then the CPU can access it. For example, disk, CD-ROM, DVD, etc.

Characteristics of Secondary Memory
- These are magnetic and optical memories.
- It is known as the backup memory.
- It is a non-volatile memory.
- Data is permanently stored even if power is switched off.
- It is used for storage of data in a computer.
- Computer may run without the secondary memory.
- Slower than primary memories.
Random Access Memory
RAM (Random Access Memory) is the internal memory of the CPU for storing data, program, and program result. It is a read/write memory which stores data until the machine is working. As soon as the machine is switched off, data is erased.

Access time in RAM is independent of the address, that is, each storage location inside the memory is as easy to reach as other locations and takes the same amount of time. Data in the RAM can be accessed randomly but it is very expensive.
RAM is volatile, i.e. data stored in it is lost when we switch off the computer or if there is a power failure. Hence, a backup Uninterruptible Power System (UPS) is often used with computers. RAM is small, both in terms of its physical size and in the amount of data it can hold.
RAM is of two types −
- Static RAM (SRAM)
- Dynamic RAM (DRAM)
Static RAM (SRAM)
The word static indicates that the memory retains its contents as long as power is being supplied. However, data is lost when the power gets down due to volatile nature. SRAM chips use a matrix of 6-transistors and no capacitors. Transistors do not require power to prevent leakage, so SRAM need not be refreshed on a regular basis.
There is extra space in the matrix, hence SRAM uses more chips than DRAM for the same amount of storage space, making the manufacturing costs higher. SRAM is thus used as cache memory and has very fast access.
Characteristic of Static RAM
- Long life
- No need to refresh
- Faster
- Used as cache memory
- Large size
- Expensive
- High power consumption
Dynamic RAM (DRAM)
DRAM, unlike SRAM, must be continually refreshed in order to maintain the data. This is done by placing the memory on a refresh circuit that rewrites the data several hundred times per second. DRAM is used for most system memory as it is cheap and small. All DRAMs are made up of memory cells, which are composed of one capacitor and one transistor.
Characteristics of Dynamic RAM
- Short data lifetime
- Needs to be refreshed continuously
- Slower as compared to SRAM
- Used as RAM
- Smaller in size
- Less expensive
- Less power consumption
Read Only Memory
ROM stands for Read Only Memory. The memory from which we can only read but cannot write on it. This type of memory is non-volatile. The information is stored permanently in such memories during manufacture. A ROM stores such instructions that are required to start a computer. This operation is referred to as bootstrap. ROM chips are not only used in the computer but also in other electronic items like washing machine and microwave oven.

Let us now discuss the various types of ROMs and their characteristics.
MROM (Masked ROM)
The very first ROMs were hard-wired devices that contained a pre-programmed set of data or instructions. These kind of ROMs are known as masked ROMs, which are inexpensive.
PROM (Programmable Read Only Memory)
PROM is read-only memory that can be modified only once by a user. The user buys a blank PROM and enters the desired contents using a PROM program. Inside the PROM chip, there are small fuses which are burnt open during programming. It can be programmed only once and is not erasable.
EPROM (Erasable and Programmable Read Only Memory)
EPROM can be erased by exposing it to ultra-violet light for a duration of up to 40 minutes. Usually, an EPROM eraser achieves this function. During programming, an electrical charge is trapped in an insulated gate region. The charge is retained for more than 10 years because the charge has no leakage path. For erasing this charge, ultra-violet light is passed through a quartz crystal window (lid). This exposure to ultra-violet light dissipates the charge. During normal use, the quartz lid is sealed with a sticker.
EEPROM (Electrically Erasable and Programmable Read Only Memory)
EEPROM is programmed and erased electrically. It can be erased and reprogrammed about ten thousand times. Both erasing and programming take about 4 to 10 ms (millisecond). In EEPROM, any location can be selectively erased and programmed. EEPROMs can be erased one byte at a time, rather than erasing the entire chip. Hence, the process of reprogramming is flexible but slow.
Advantages of ROM
The advantages of ROM are as follows −
- Non-volatile in nature
- Cannot be accidentally changed
- Cheaper than RAMs
- Easy to test
- More reliable than RAMs
- Static and do not require refreshing
- Contents are always known and can be verified
Motherboard
The motherboard serves as a single platform to connect all of the parts of a computer together. It connects the CPU, memory, hard drives, optical drives, video card, sound card, and other ports and expansion cards directly or via cables. It can be considered as the backbone of a computer.

Features of Motherboard
A motherboard comes with following features −
- Motherboard varies greatly in supporting various types of components.
- Motherboard supports a single type of CPU and few types of memories.
- Video cards, hard disks, sound cards have to be compatible with the motherboard to function properly.
- Motherboards, cases, and power supplies must be compatible to work properly together.
Popular Manufacturers
Following are the popular manufacturers of the motherboard.
- Intel
- ASUS
- AOpen
- ABIT
- Biostar
- Gigabyte
- MSI
Description of Motherboard
The motherboard is mounted inside the case and is securely attached via small screws through pre-drilled holes. Motherboard contains ports to connect all of the internal components. It provides a single socket for CPU, whereas for memory, normally one or more slots are available. Motherboards provide ports to attach the floppy drive, hard drive, and optical drives via ribbon cables. Motherboard carries fans and a special port designed for power supply.
There is a peripheral card slot in front of the motherboard using which video cards, sound cards, and other expansion cards can be connected to the motherboard.
On the left side, motherboards carry a number of ports to connect the monitor, printer, mouse, keyboard, speaker, and network cables. Motherboards also provide USB ports, which allow compatible devices to be connected in plug-in/plug-out fashion. For example, pen drive, digital cameras, etc.
10 Steps to Solving a Programming Problem
1. Read the problem at least three times (or however many makes you feel comfortable)
You can’t solve a problem you don’t understand. There is a difference between the problem and the problem you think you are solving. It’s easy to start reading the first few lines in a problem and assume the rest of it because it’s similar to something you’ve seen in the past. If you are making even a popular game like Hangman, be sure to read through any rules even if you’ve played it before. I once was asked to make a game like Hangman that I realized was “Evil Hangman” only after I read through the instructions (it was a trick!).
Sometimes I’ll even try explaining the problem to a friend and see if her understanding of my explanation matches the problem I am tasked with. You don’t want to find out halfway through that you misunderstood the problem. Taking extra time in the beginning is worth it. The better you understand the problem, the easier it will be to solve it.
Let’s pretend we are creating a simple function selectEvenNumbers that will take in an array of numbers and return an array evenNumbers of only even numbers. If there are no even numbers, return the empty array evenNumbers.
FunctionselectEvenNumbers() {
// your code here
}
Here are some questions that run through my mind:
- How can a computer tell what is an even number? Divide that number by 2 and see if its remainder is 0.
- What am I passing into this function? An array
- What will that array contain? One or more numbers
- What are the data types of the elements in the array? Numbers
- What is the goal of this function?What am I returning at the end of this function? The goal is to take all the even numbers and return them in an array. If there are no even numbers, return an empty array.
2. Work through the problem manually with at least three sets of sample data
Take out a piece of paper and work through the problem manually. Think of at least three sets of sample data you can use. Consider corner and edge cases as well.
Corner case: a problem or situation that occurs outside of normal operating parameters, specifically when multiple environmental variables or conditions are simultaneously at extreme levels, even though each parameter is within the specified range for that parameter.
Edge case: problem or situation that occurs only at an extreme (maximum or minimum) operating parameter
For example, below are some sets of sample data to use:
[1]
[1, 2]
[1, 2, 3, 4, 5, 6]
[-200.25]
[-800.1, 2000, 3.1, -1000.25, 42, 600]
When you are first starting out, it is easy to gloss over the steps. Because your brain may already be familiar with even numbers, you may just look at a sample set of data and pull out numbers like2 ,4 , 6 and so forth in the array without fully being aware of each and every step your brain is taking to solve it. If this is challenging, try using large sets of data as it will override your brain’s ability to naturally solve the problem just by looking at it. That helps you work through the real algorithm.
Let’s go through the first array [1]
- Look at the only element in the array [1]
- Decide if it is even. It is not
- Notice that there are no more elements in this array
- Determine there are no even numbers in this provided array
- Return an empty array
Let’s go through the array [1, 2]
- Look at the first element in array [1, 2]
- It is 1
- Decide if it is even. It is not
- Look at the next element in the array
- It is 2
- Decide if it is even. It is even
- Make an array evenNumbers and add 2 to this array
- Notice that there are no more elements in this array
- Return the array evenNumbers which is [2]
I go through this a few more times. Notice how the steps I wrote down for [1] varies slightly from [1, 2]. That is why I try to go through a couple of different sets. I have some sets with just one element, some with floats instead of just integers, some with multiple digits in an element, and some with negatives just to be safe.
3. Simplify and optimize your steps
Look for patterns and see if there’s anything you can generalize. See if you can reduce any steps or if you are repeating any steps.
- Create a function selectEvenNumbers
- Create a new empty array evenNumbers where I store even numbers, if any
- Go through each element in the array [1, 2]
- Find the first element
- Decide if it is even by seeing if it is divisible by 2. If it is even, I add that to evenNumbers
- Find the next element
- Repeat step #4
- Repeat step #5 and #4 until there are no more elements in this array
- Return the array evenNumbers, regardless of whether it has anything in it
- Show it is true for n = 1, n = 2, ...
- Suppose it is true for n = k
- Prove it is true for n = k + 1
Example of pseudocode
4. Write pseudocode
Even after you’ve worked out general steps, writing out pseudocode that you can translate into code will help with defining the structure of your code and make coding a lot easier.Write pseudocode line by line. You can do this either on paper or as comments in your code editor. If you’re starting out and find blank screens to be daunting or distracting, I recommend doing it on paper.
Pseudocode generally does not actually have specific rules in particular but sometimes, I might end up including some syntax from a language just because I am familiar enough with an aspect of the programming language. Don’t get caught up with the syntax. Focus on the logic and steps.
For our problem, there are many different ways to do this. For example, you can use filter but for the sake of keeping this example as easy to follow along as possible, we will use a basic for loop for now (but we will use filter later when we refactor our code).
Here is an example of pseudocode that has more words:
Function selectEvenNumberscreate an array evenNumbers and set that equal to an empty arrayfor each element in that array
see if that element is even
if element is even (if there is a remainder when divided by 2)
add to that to the array evenNumbersreturnevenNumbers
Here is an example of pseudocode that has fewer words:
FunctionselectEvenNumbersevenNumbers = []for i = 0 to i = length of evenNumbers
if (element % 2 === 0)
add to that to the array evenNumbersreturnevenNumbers
Either way is fine as long as you are writing it out line-by-line and understand the logic on each line.
Refer back to the problem to make sure you are on track.
5. Translate pseudocode into code and debug
When you have your pseudocode ready, translate each line into real code in the language you are working on. We will use JavaScript for this example.
If you wrote it out on paper, type this up as comments in your code editor. Then replace each line in your pseudocode.
Then I call the function and give it some sample sets of data we used earlier. I use them to see if my code returns the results I want. You can also write tests to check if the actual output is equal to the expected output.
SelectEvenNumbers([1])
selectEvenNumbers([1, 2])
selectEvenNumbers([1, 2, 3, 4, 5, 6])
selectEvenNumbers([-200.25])
selectEvenNumbers([-800.1, 2000, 3.1, -1000.25, 42, 600])
I generally use console.log() after each variable or line or so. This helps me check if the values and code are behaving as expected before I move on. By doing this, I catch any issues before I get too far. Below is an example of what values I would check when I am first starting out. I do this throughout my code as I type it out.
FunctionselectEvenNumbers(arrayofNumbers) {let evenNumbers = []
console.log(evenNumbers) // I remove this after checking output
console.log(arrayofNumbers) // I remove this after checking output}
After working though each line of my pseudocode, below is what we end up with. // is what the line was in pseudocode. Text that is bolded is the actual code in JavaScript.
// function selectEvenNumbers
function selectEvenNumbers(arrayofNumbers) {// evenNumbers = []
let evenNumbers = []// for i = 0 to i = length of evenNumbers
for (vari = 0; i<arrayofNumbers.length; i++) {// if (element % 2 === 0)
if (arrayofNumbers[i] % 2 === 0) {// add to that to the array evenNumbers
evenNumbers.push(arrayofNumbers[i])
}
}// return evenNumbers
return evenNumbers
}
I get rid of the pseudocode to avoid confusion.
FunctionselectEvenNumbers(arrayofNumbers) {
let evenNumbers = []for (vari = 0; i<arrayofNumbers.length; i++) {
if (arrayofNumbers[i] % 2 === 0) {
evenNumbers.push(arrayofNumbers[i])
}
}return evenNumbers
}
Sometimes new developers will get hung up with the syntax that it becomes difficult to move forward. Remember that syntax will come more naturally over time and there is no shame in referencing material for the correct syntax later on when coding.
6. Simplify and optimize your code
You’ve probably noticed by now that simplifying and optimizing are recurring themes.
“Simplicity is prerequisite for reliability.”
In this example, one way of optimizing it would be to filter out items from an array by returning a new array using filter. This way, we don’t have to define another variable evenNumbers because filter will return a new array with copies of elements that match the filter. This will not change the original array. We also don’t need to use a for loop with this approach. Filter will go through each item, return either true, to have that element in the array, or false to skip it.
FunctionselectEvenNumbers(arrayofNumbers) {
let evenNumbers = arrayofNumbers.filter(n => n % 2 === 0)
return evenNumbers
}
Simplifying and optimizing your code may require you to iterate a few times, identifying ways to further simplify and optimize code.
Here are some questions to keep in mind:
- What are your goals for simplifying and optimizing? The goals will depend on your team’s style or your personal preference. Are you trying to condense the code as much as possible? Is the goal to make it the code more readable? If that’s the case, you may prefer taking that extra line to define the variable or compute something rather than trying to define and compute all in one line.
- How else can you make the code more readable?
- Are there any more extra steps you can take out?
- Are there any variables or functions you ended up not even needing or using?
- Are you repeating some steps a lot? See if you can define in another function.
- Are there better ways to handle edge cases?
“Programs must be written for people to read, and only incidentally for machines to execute.”
7. Debug
This step really should be throughout the process. Debugging throughout will help you catch any syntax errors or gaps in logic sooner rather than later. Take advantage of your Integrated Development Environment (IDE) and debugger. When I encounter bugs, I trace the code line-by-line to see if there was anything that did not go as expected. Here are some techniques I use:
- Check the console to see what the error message says. Sometimes it’ll point out a line number I need to check. This gives me a rough idea of where to start, although the issue sometimes may not be at this line at all.
- Comment out chunks or lines of code and output what I have so far to quickly see if the code is behaving how I expected. I can always uncomment the code as needed.
- Use other sample data if there are scenarios I did not think of and see if the code will still work.
- Save different versions of my file if I am trying out a completely different approach. I don’t want to lose any of my work if I end up wanting to revert back to it!
“The most effective debugging tool is still careful thought, coupled with judiciously placed print statements.”
8. Write useful comments
You may not always remember what every single line meant a month later. And someone else working on your code may not know either. That’s why it’s important to write useful comments to avoid problems and save time later on if you need to come back to it.
Stay away from comments such as:
// This is an array. Iterate through it.
// This is a variable
I try to write brief, high-level comments that help me understand what’s going on if it is not obvious. This comes in handy when I am working on more complex problems. It helps understand what a particular function is doing and why. Through the use of clear variable names, function names, and comments, you (and others) should be able to understand:
- What is this code for?
- What is it doing?
9. Get feedback through code reviews
Get feedback from your teammates, professors, and other developers. Check out Stack Overflow. See how others tackled the problem and learn from them. There are sometimes several ways to approach a problem. Find out what they are and you’ll get better and quicker at coming up with them yourself.
10. Practice, practice, practice
Even experienced developers are always practicing and learning. If you get helpful feedback, implement it. Redo a problem or do similar problems. Keep pushing yourself. With each problem you solve, the better a developer you become. Celebrate each success and be sure to remember how far you’ve come. Remember that programming, like with anything, comes easier and more naturally with time.
FLOW CHART
Flow chart is defined as graphical representation of the logic for problem solving.
The purpose of flowchart is making the logic of the program clear in a visual representation.
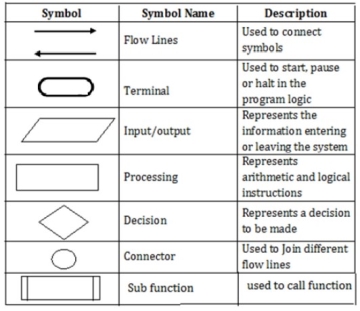
Rules for drawing a flowchart
1. The flowchart should be clear, neat and easy to follow.
2. The flowchart must have a logical start and finish.
3. Only one flow line should come out from a process symbol.
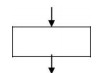
4. Only one flow line should enter a decision symbol. However, two or three flow lines may leave the decision symbol.
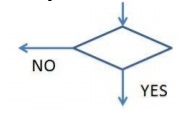
5. Only one flow line is used with a terminal symbol.
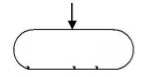
6. Within standard symbols, write briefly and precisely.
7. Intersection of flow lines should be avoided.
Advantages of flowchart:
1. Communication: - Flowcharts are better way of communicating the logic of asystem to all concerned.
2. Effective analysis: - With the help of flowchart, problem can be analysed in moreeffective way.
3. Proper documentation: - Program flowcharts serve as a good programdocumentation, which is needed for various purposes.
4. Efficient Coding: - The flowcharts act as a guide or blueprint during the systemsanalysis and program development phase.
5. Proper Debugging: - The flowchart helps in debugging process.
6. Efficient Program Maintenance: - The maintenance of operating program becomes easy with the help of flowchart. It helps the programmer to put efforts more efficiently on that part.
Disadvantages of flow chart:
1. Complex logic: - Sometimes, the program logic is quite complicated. In that case,flowchart becomes complex and clumsy.
2. Alterations and Modifications: - If alterations are required the flowchart mayrequire re-drawing completely.
3. Reproduction: - As the flowchart symbols cannot be typed, reproduction offlowchart becomes a problem.
4. Cost: For large application the time and cost of flowchart drawing becomescostly.
PSEUDO CODE:
v Pseudo code consists of short, readable and formally styled English languages used for explain an algorithm.
v It does not include details like variable declaration, subroutines.
v It is easier to understand for the programmer or non programmer to understand the general working of the program, because it is not based on any programming language.
v It gives us the sketch of the program before actual coding.
v It is not a machine readable
v Pseudo code can’t be compiled and executed.
v There is no standard syntax for pseudo code.
Guidelines for writing pseudo code:
v Write one statement per line
v Capitalize initial keyword
v Indent to hierarchy
v End multiline structure
v Keep statements language independent
Common keywords used in pseudocode
The following gives common keywords used in pseudocodes.
1. //: This keyword used to represent a comment.
2. BEGIN,END: Begin is the first statement and end is the last statement.
3. INPUT, GET, READ: The keyword is used to inputting data.
4. COMPUTE, CALCULATE: used for calculation of the result of the given expression. 5. ADD, SUBTRACT, INITIALIZE used for addition, subtraction and initialization.
6. OUTPUT, PRINT, DISPLAY: It is used to display the output of the program.
7. IF, ELSE, ENDIF: used to make decision.
8. WHILE, ENDWHILE: used for iterative statements.
9. FOR, ENDFOR: Another iterative incremented/decremented tested automatically.
Syntax for if else:
IF (condition)THEN
Statement
...
ELSE
Statement
...
ENDIF
Example: Greates of two numbers
BEGIN
READ a,b
IF (a>b) THEN
DISPLAY a is greater
ELSE
DISPLAY b is greater
END IF
END
Syntax for For:
FOR( start-value to end-value) DO
Statement
...
ENDFOR
Example: Print n natural numbers
BEGIN
GET n
INITIALIZE i=1
FOR (i<=n) DO
PRINT i
i=i+1
ENDFOR
END
Syntax for A while:
WHILE (condition) DO
Statement
...
ENDWHILE
Example: Print n natural numbers
BEGIN
GET n
INITIALIZE i=1
WHILE(i<=n) DO
PRINT i
i=i+1
ENDWHILE
END
Advantages:
v Pseudo is independent of any language; it can be used by most programmers.
v It is easy to translate pseudo code into a programming language.
v It can be easily modified as compared to flowchart.
v Converting a pseudo code to programming language is very easy as comparedwith converting a flowchart to programming language.
Disadvantages:
v It does not provide visual representation of the program’s logic.
v There are no accepted standards for writing pseudo codes.
v It cannot be compiled nor executed.
v For a beginner, It is more difficult to follow the logic or write pseudo code ascompared to flowchart.
Example:
Addition of two numbers:
BEGIN
GET a,b
ADD c=a+b
PRINT c
END
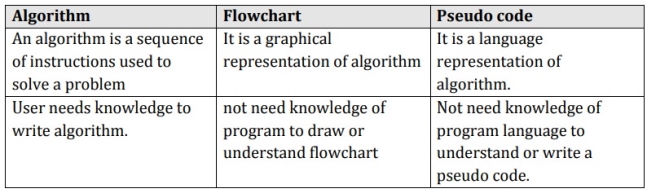
Examples algorithms: pseudo code, flow chart, programming language
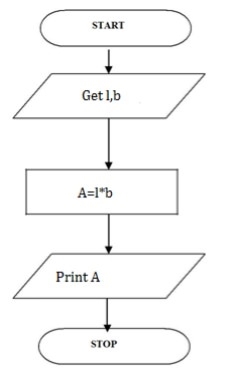
Write an algorithm to find area of a rectangle
Step 1: Start
Step 2: get l,b values
Step 3: Calculate A=l*b
Step 4: Display A
Step 5: Stop
BEGIN
READ l,b
CALCULATE A=l*b
DISPLAY A
END
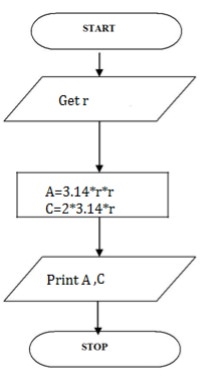
Write an algorithm for Calculating area and circumference of circle
Step 1: Start
Step 2: get r value
Step 3: Calculate A=3.14*r*r
Step 4: Calculate C=2.3.14*r
Step 5: Display A,C
Step 6: Stop
BEGIN
READ r
CALCULATE A and C
A=3.14*r*r
C=2*3.14*r
DISPLAY A
END
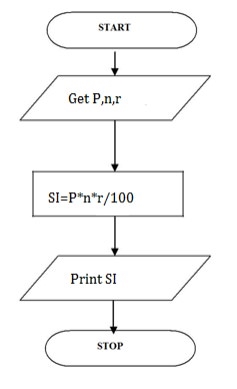
Write an algorithm for Calculating simple interest
Step 1: Start
Step 2: get P, n, r value
Step3:Calculate
SI=(p*n*r)/100
Step 4: Display S
Step 5: Stop
BEGIN
READ P, n, r
CALCULATE S
SI=(p*n*r)/100
DISPLAY SI
END
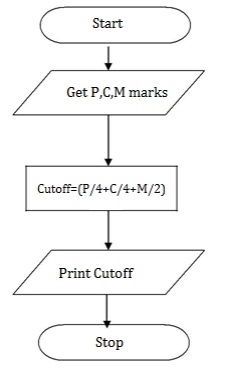
Write an algorithm for Calculating engineering cutoff
Step 1: Start
Step2: get P,C,M value
Step3:calculate
Cutoff= (P/4+C/4+M/2)
Step 4: Display Cutoff
Step 5: Stop
BEGIN
READ P,C,M
CALCULATE
Cutoff= (P/4+C/4+M/2)
DISPLAY Cutoff
END
To check greatest of two numbers
Step 1: Start
Step 2: get a,b value
Step 3: check if(a>b) print a is greater
Step 4: else b is greater
Step 5: Stop
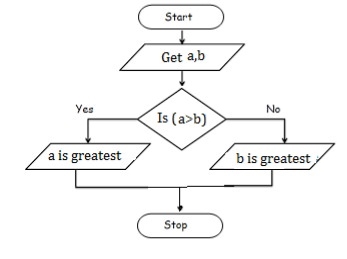
BEGIN
READ a,b
IF (a>b) THEN
DISPLAY a is greater
ELSE
DISPLAY b is greater
END IF
END
To check leap year or not
Step 1: Start
Step 2: get y
Step 3: if(y%4==0) print leap year
Step 4: else print not leap year
Step 5: Stop
BEGIN
READ y
IF (y%4==0) THEN
DISPLAY leap year
ELSE
DISPLAY not leap year
END IF
END
To check positive or negative number
Step 1: Start
Step 2: get num
Step 3: check if(num>0) print a is positive
Step 4: else num is negative
Step 5: Stop
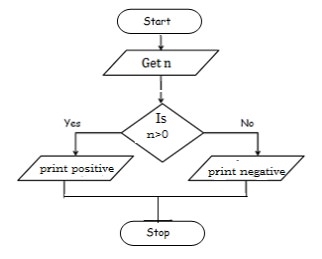
BEGIN
READ num
IF (num>0) THEN
DISPLAY num is positive
ELSE
DISPLAY num is negative
END IF
END
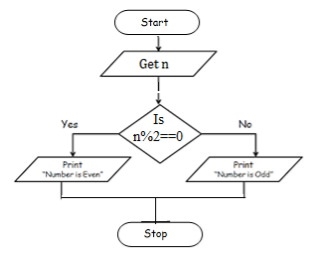
To check odd or even number
Step 1: Start
Step 2: get num
Step 3: check if(num%2==0) print num is even
Step 4: else num is odd
Step 5: Stop
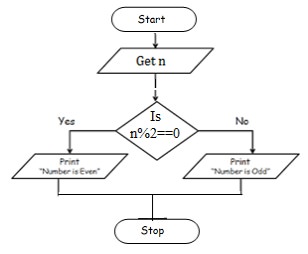
BEGIN
READ num
IF (num%2==0) THEN
DISPLAY num is even
ELSE
DISPLAY num is odd
END IF
END
To check greatest of three numbers
Step1: Start
Step2: Get A, B, C
Step3: if(A>B) goto Step4 else goto step5
Step4: If(A>C) print A else print C
Step5: If(B>C) print B else print C
Step6: Stop
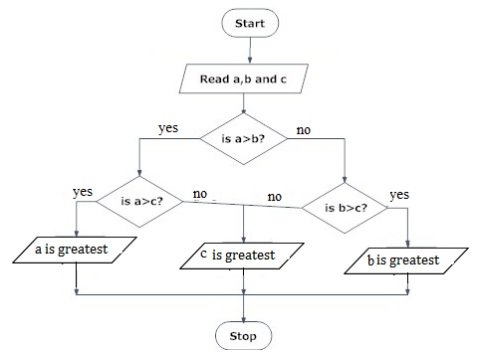
BEGIN
READ a, b, c
IF (a>b) THEN
IF(a>c) THEN
DISPLAY a is greater
ELSE
DISPLAY c is greater
END IF
ELSE
IF(b>c) THEN
DISPLAY b is greater
ELSE
DISPLAY c is greater
END IF
END IF
END
Write an algorithm to check whether given number is +ve, -ve or zero.
Step 1: Start
Step 2: Get n value.
Step 3: if (n ==0) print “Given number is Zero” Else goto step4
Step 4: if (n > 0) then Print “Given number is +ve”
Step 5: else Print “Given number is -ve”
Step 6: Stop
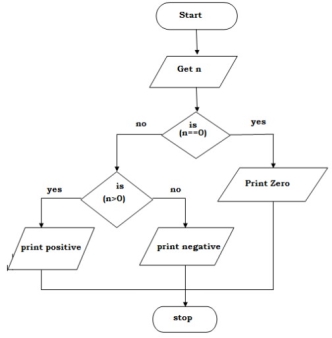
BEGIN
GET n
IF(n==0) THEN
DISPLAY “ n is zero”
ELSE
IF(n>0) THEN
DISPLAY “n is positive”
ELSE
DISPLAY “n is positive”
END IF
END IF
END
Write an algorithm to print all natural numbers up to n
Step 1: Start
Step 2: get n value.
Step 3: initialize i=1
Step 4: if (i<=n) go to step 5 else go to step 8
Step 5: Print i value
Step 6 : increment i value by 1
Step 7: go to step 4
Step 8: Stop
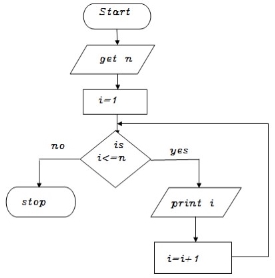
BEGIN
GET n
INITIALIZE i=1
WHILE(i<=n) DO
PRINT i
i=i+1
ENDWHILE
END
Write an algorithm to print n odd numbers
Step 1: start
Step 2: get n value
Step 3: set initial value i=1
Step 4: check if(i<=n) goto step 5 else goto step 8
Step 5: print i value
Step 6: increment i value by 2
Step 7: goto step 4
Step 8: stop
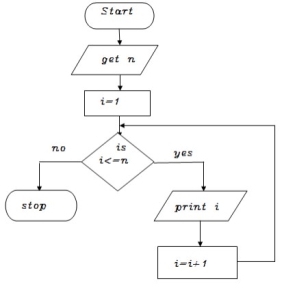
BEGIN
GET n
INITIALIZE i=1
WHILE(i<=n) DO
PRINT i
i=i+2
ENDWHILE
END
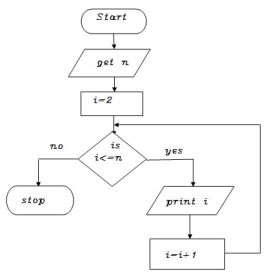
Write an algorithm to print n even numbers
Step 1: start
Step 2: get n value
Step 3: set initial value i=2
Step 4: check if(i<=n) goto step 5 else goto step8
Step 5: print i value
Step 6: increment i value by 2
Step 7: goto step 4
Step 8: stop
BEGIN
GET n
INITIALIZE i=2
WHILE(i<=n) DO
PRINT i
i=i+2
ENDWHILE
END
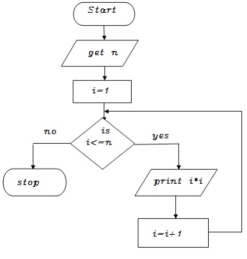
Write an algorithm to print squares of a number
Step 1: start
Step 2: get n value
Step 3: set initial value i=1
Step 4: check i value if(i<=n) goto step 5 else goto step8
Step 5: print i*i value
Step 6: increment i value by 1
Step 7: goto step 4
Step 8: stop
BEGIN
GET n
INITIALIZE i=1
WHILE(i<=n) DO
PRINT i*i
i=i+2
ENDWHILE
END
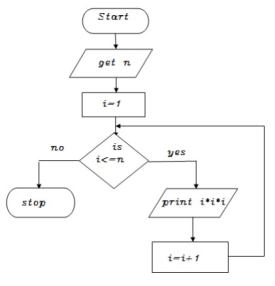
Write an algorithm to print to print cubes of a number
Step 1: start
Step 2: get n value
Step 3: set initial value i=1
Step 4: check i value if(i<=n) goto step 5 else goto step8
Step 5: print i*i *i value
Step 6: increment i value by 1
Step 7: goto step 4
Step 8: stop
BEGIN
GET n
INITIALIZE i=1
WHILE(i<=n) DO
PRINT i*i*i
i=i+2
ENDWHILE
END
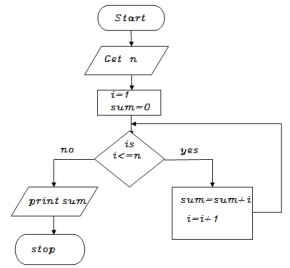
Write an algorithm to find sum of a given number
Step 1: start
Step 2: get n value
Step 3: set initial value i=1, sum=0
Step 4: check i value if(i<=n) goto step 5 else goto step8
Step 5: calculate sum=sum+i
Step 6: increment i value by 1
Step 7: goto step 4
Step 8: print sum value
Step 9: stop
BEGIN
GET n
INITIALIZE i=1,sum=0
WHILE(i<=n) DO
Sum=sum+i
i=i+1
ENDWHILE
PRINT sum
END
Write an algorithm to find factorial of a given number
Step 1: start
Step 2: get n value
Step 3: set initial value i=1, fact=1
Step 4: check i value if(i<=n) goto step 5 else goto step8
Step 5: calculate fact=fact*i
Step 6: increment i value by 1
Step 7: goto step 4
Step 8: print fact value
Step 9: stop
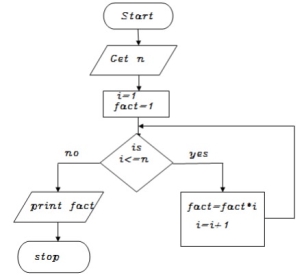
BEGIN
GET n
INITIALIZE i=1,fact=1
WHILE(i<=n) DO
Fact=fact*i
i=i+1
ENDWHILE
PRINT fact
END
What is an algorithm?
- An algorithm is a recipe for solving a set of problems.
- It is a set of instructions that tells you what to do step by step.
- An algorithm is something conceptual and can be described using language, flowcharts or pseudocode.
- An algorithm can be implemented in different programming languages.
Pseudocode
The idea is to use an intermediate way of communication between natural language and programming language. It does not have a formal syntax but it usually has the following structure:
- The concept of variable and assignment is used. Eg: "a <- 5" means that the variable a has the constant 5 assigned.
- The input and output data are shown.
- Conditional statements are used: E.g: "if <condition> then <instructions>
- Cycle instructions like "repeat until ..." are used
Algorithm example:
Algorithm to define if a triangle is scalene, isosceles or equilateral
Input data: side1, side2, side3
Output data: triangle type
If side1 = side2 and side1 = side3
Then
Type<- equilateral
Else
If (side1 = side2) or (side1 = side3) or (side2 = side3)
Then
Type<- isosceles
Else
Type<- scalene
What is a program?
A program is intrinsically linked to the existence of a computer. Computers run programs. The programs read data from files, databases, networks, keyboards and write data to files, databases, networks, screens, etc..
Programs are executed by the computer processor. For this, they must be loaded onto the main memory RAM.
The loading of the programs onto the memory is carried out by a special type of software or program called operating system.
Differences between Algorithm and Program
Although they may be mixed up because they are both a set of instructions, they represent two very different concepts. An algorithm is more like an idea, a way to solve a problem, while a program is more linked to the execution of one or more tasks by a computer.
A program can implement one or more algorithms, or it may be so simple that we don´t have to use an algorithm.
The task of a developer usually starts by designing algorithms to solve the problems and then implement them and include them in a program.
When we talk about a program there is always the idea that it will be executed by a computer while an algorithm could be executed by a person.
A program is written in machine language or at least in a language that can be compiled or interpreted by some kind of machine (sometimes a virtual machine).
Source code is the fundamental component of a computer program that is created by a programmer. It can be read and easily understood by a human being. When a programmer types a sequence of C programming language statements into Windows Notepad, for example, and saves the sequence as a text file, the text file is said to contain the source code.
Source code and object code are sometimes referred to as the "before" and "after" versions of a compiled computer program. For script (non compiled or interpreted) program languages, such as JavaScript, the terms source code and object code do not apply, since there is only one form of the code.
Programmers can use a text editor, a visual programming tool or an integrated development environment (IDE) such as software development kit (SDK) to create source code. In large program development environments, there are often management systems that help programmers separate and keep track of different states and levels of source code files.
Purposes of source code
Beyond providing the foundation for software creation, source code has other important purposes, as well. For example, skilled users who have access to source code can more easily customize software installations, if needed.
Meanwhile, other developers can use source code to create similar programs for other operating platforms -- a task that would be trickier without the coding instructions.
Access to source code also allows programmers to contribute to their community, either through sharing code for learning purposes or by recycling portions of it for other applications.
Organization of source code
Many different programs exist to create source code. Here is an example of the source code for a Hello World program in C language:
/* Hello World program */
#include<stdio.h>
Main()
{
printf("Hello World");
}
Even a person with no background in programming can read the C programming source code above and understand that the goal of the program is to print the words "Hello World." In order to carry out the instructions, however, this source code must first be translated into a machine language that the computer's processor can understand; that is the job of a special interpreter program called a compiler -- in this case, a C compiler.
After programmers compile source code, the file that contains the resulting output is referred to as object code.
Object code consists mainly of the numbers one and zero and cannot be easily read or understood by humans. Object code can then be "linked" to create an executable file that runs to perform the specific program functions.
Source code management systems can help programmers better collaborate on source code development; for example, preventing one coder from inadvertently overwriting the work of another.
History of source code
Determining the historical start of source code is a subjective -- and elusive -- exercise. The first software was written in binary code in the 1940s, so depending on one's viewpoint, such programs may be the initial samples of source code.
One of the earliest examples of source code as we recognize it today was written by Tom Kilburn, an early pioneer in computer science. Kilburn created the first successful digital program held electronically in a computer's memory in 1948 (the software solved a mathematical equation).
In the 1950s and '60s, source code was often provided for free with software by the companies that created the programs. As growing computer companies expanded software's use, source code became more prolific and sought after. Computing magazines prior to the internet age would often print source code in their pages, with readers needing to retype the code character for character for their own use. Later, floppy disks decreased the price for electronically sharing source code, and then the internet further deleted these obstacles.
What is a Variable?
A variable is an identifier which is used to store some value. Constants can never change at the time of execution. Variables can change during the execution of a program and update the value stored inside it.
A single variable can be used at multiple locations in a program. A variable name must be meaningful. It should represent the purpose of the variable.
Example: Height, age, are the meaningful variables that represent the purpose it is being used for. Height variable can be used to store a height value. Age variable can be used to store the age of a person
A variable must be declared first before it is used somewhere inside the program. A variable name is formed using characters, digits and an underscore.
Following are the rules that must be followed while creating a variable:
- A variable name should consist of only characters, digits and an underscore.
- A variable name should not begin with a number.
- A variable name should not consist of whitespace.
- A variable name should not consist of a keyword.
- 'C' is a case sensitive language that means a variable named 'age' and 'AGE' are different.
Following are the examples of valid variable names in a 'C' program:
Height or HEIGHT
_height
_height1
My_name
Following are the examples of invalid variable names in a 'C' program:
1height
Hei$ght
My name
For example, we declare an integer variable my_variable and assign it the value 48:
Intmy_variable;
My_variable = 48;
By the way, we can both declare and initialize (assign an initial value) a variable in a single statement:
Intmy_variable = 48;
Data types
'C' provides various data types to make it easy for a programmer to select a suitable data type as per the requirements of an application. Following are the three data types:
- Primitive data types
- Derived data types
- User-defined data types
There are five primary fundamental data types,
- Int for integer data
- Char for character data
- Float for floating point numbers
- Double for double precision floating point numbers
- Void
Array, functions, pointers, structures are derived data types. 'C' language provides more extended versions of the above mentioned primary data types. Each data type differs from one another in size and range. Following table displays the size and range of each data type.
Data type | Size in bytes | Range |
Char or signed char | 1 | -128 to 127 |
Unsigned char | 1 | 0 to 255 |
Int or signed int | 2 | -32768 to 32767 |
Unsigned int | 2 | 0 to 65535 |
Short int or Unsigned short int | 2 | 0 to 255 |
Signed short int | 2 | -128 to 127 |
Long int or Signed long int | 4 | -2147483648 to 2147483647 |
Unsigned long int | 4 | 0 to 4294967295 |
Float | 4 | 3.4E-38 to 3.4E+38 |
Double | 8 | 1.7E-308 to 1.7E+308 |
Long double | 10 | 3.4E-4932 to 1.1E+4932 |
Note: In C, there is no Boolean data type.
Integer data type
Integer is nothing but a whole number. The range for an integer data type varies from machine to machine. The standard range for an integer data type is -32768 to 32767.
An integer typically is of 2 bytes which means it consumes a total of 16 bits in memory. A single integer value takes 2 bytes of memory. An integer data type is further divided into other data types such as short int, int, and long int.
Each data type differs in range even though it belongs to the integer data type family. The size may not change for each data type of integer family.
The short int is mostly used for storing small numbers, int is used for storing averagely sized integer values, and long int is used for storing large integer values.
Whenever we want to use an integer data type, we have place int before the identifier such as,
Int age;
Here, age is a variable of an integer data type which can be used to store integer values.
Floating point data type
Like integers, in 'C' program we can also make use of floating point data types. The 'float' keyword is used to represent the floating point data type. It can hold a floating point value which means a number is having a fraction and a decimal part. A floating point value is a real number that contains a decimal point. Integer data type doesn't store the decimal part hence we can use floats to store decimal part of a value.
Generally, a float can hold up to 6 precision values. If the float is not sufficient, then we can make use of other data types that can hold large floating point values. The data type double and long double are used to store real numbers with precision up to 14 and 80 bits respectively.
While using a floating point number a keyword float/double/long double must be placed before an identifier. The valid examples are,
Float division;
DoubleBankBalance;
Character data type
Character data types are used to store a single character value enclosed in single quotes.
A character data type takes up-to 1 byte of memory space.
Example,
Char letter;
Void data type
A void data type doesn't contain or return any value. It is mostly used for defining functions in 'C'.
Example,
VoiddisplayData()
Type declaration of a variable
Int main() {
Int x, y;
Float salary = 13.48;
Char letter = 'K';
x = 25;
y = 34;
Int z = x+y;
Printf("%d \n", z);
Printf("%f \n", salary);
Printf("%c \n", letter);
Return 0;}
Output:
59
13.480000
K
We can declare multiple variables with the same data type on a single line by separating them with a comma. Also, notice the use of format specifiers in printf output function float (%f) and char (%c) and int (%d).
Memory locations
A typical memory representation of C program consists of following sections.
1. Text segment
2. Initialized data segment
3. Uninitialized data segment
4. Stack
5. Heap
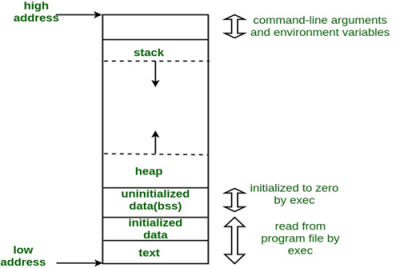
A typical memory layout of a running process
1. Text Segment:
A text segment , also known as a code segment or simply as text, is one of the sections of a program in an object file or in memory, which contains executable instructions.
As a memory region, a text segment may be placed below the heap or stack in order to prevent heaps and stack overflows from overwriting it.
Usually, the text segment is sharable so that only a single copy needs to be in memory for frequently executed programs, such as text editors, the C compiler, the shells, and so on. Also, the text segment is often read-only, to prevent a program from accidentally modifying its instructions.
2. Initialized Data Segment:
Initialized data segment, usually called simply the Data Segment. A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
Note that, data segment is not read-only, since the values of the variables can be altered at run time.
This segment can be further classified into initialized read-only area and initialized read-write area.
For instance the global string defined by char s[] = “hello world” in C and a C statement like int debug=1 outside the main (i.e. global) would be stored in initialized read-write area. And a global C statement like const char* string = “hello world” makes the string literal “hello world” to be stored in initialized read-only area and the character pointer variable string in initialized read-write area.
Ex: static inti = 10 will be stored in data segment and global inti = 10 will also be stored in data segment
3. Uninitialized Data Segment:
Uninitialized data segment, often called the “bss” segment, named after an ancient assembler operator that stood for “block started by symbol.” Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing
Uninitialized data starts at the end of the data segment and contains all global variables and static variables that are initialized to zero or do not have explicit initialization in source code.
For instance a variable declared static inti; would be contained in the BSS segment.
For instance a global variable declared int j; would be contained in the BSS segment.
4. Stack:
The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted. (With modern large address spaces and virtual memory techniques they may be placed almost anywhere, but they still typically grow opposite directions.)
The stack area contains the program stack, a LIFO structure, typically located in the higher parts of memory. On the standard PC x86 computer architecture it grows toward address zero; on some other architectures it grows the opposite direction. A “stack pointer” register tracks the top of the stack; it is adjusted each time a value is “pushed” onto the stack. The set of values pushed for one function call is termed a “stack frame”; A stack frame consists at minimum of a return address.
Stack, where automatic variables are stored, along with information that is saved each time a function is called. Each time a function is called, the address of where to return to and certain information about the caller’s environment, such as some of the machine registers, are saved on the stack. The newly called function then allocates room on the stack for its automatic and temporary variables. This is how recursive functions in C can work. Each time a recursive function calls itself, a new stack frame is used, so one set of variables doesn’t interfere with the variables from another instance of the function.
5. Heap:
Heap is the segment where dynamic memory allocation usually takes place.
The heap area begins at the end of the BSS segment and grows to larger addresses from there.The Heap area is managed by malloc, realloc, and free, which may use the brk and sbrk system calls to adjust its size (note that the use of brk/sbrk and a single “heap area” is not required to fulfill the contract of malloc/realloc/free; they may also be implemented using mmap to reserve potentially non-contiguous regions of virtual memory into the process’ virtual address space). The Heap area is shared by all shared libraries and dynamically loaded modules in a process.
Examples.
The size(1) command reports the sizes (in bytes) of the text, data, and bss segments. ( for more details please refer man page of size(1) )
1. Check the following simple C program
#include <stdio.h>
Intmain(void) { Return0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bssdec hex filename
960 248 8 1216 4c0 memory-layout
2. Let us add one global variable in program, now check the size of bss (highlighted in red color).
#include <stdio.h>
Intglobal; /* Uninitialized variable stored in bss*/
Intmain(void) { Return0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bssdec hex filename
960 248 12 1220 4c4 memory-layout
3. Let us add one static variable which is also stored in bss.
#include <stdio.h>
Intglobal; /* Uninitialized variable stored in bss*/
Intmain(void) { Staticinti; /* Uninitialized static variable stored in bss */ Return0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bssdec hex filename
960 248 16 1224 4c8 memory-layout
4. Let us initialize the static variable which will then be stored in Data Segment (DS)
#include <stdio.h>
Intglobal; /* Uninitialized variable stored in bss*/
Intmain(void) { Staticinti = 100; /* Initialized static variable stored in DS*/ Return0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bssdec hex filename
960 252 12 1224 4c8 memory-layout
5. Let us initialize the global variable which will then be stored in Data Segment (DS)
#include <stdio.h>
Intglobal = 10; /* initialized global variable stored in DS*/
Intmain(void) { Staticinti = 100; /* Initialized static variable stored in DS*/ Return0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bssdec hex filename
960 256 8 1224 4c8 memory-layout
As such, C programming does not provide direct support for error handling but being a system programming language, it provides you access at lower level in the form of return values. Most of the C or even Unix function calls return -1 or NULL in case of any error and set an error code errno. It is set as a global variable and indicates an error occurred during any function call. You can find various error codes defined in <error.h> header file.
So a C programmer can check the returned values and can take appropriate action depending on the return value. It is a good practice, to set errno to 0 at the time of initializing a program. A value of 0 indicates that there is no error in the program.
Errno, perror(). Andstrerror()
The C programming language provides perror() and strerror() functions which can be used to display the text message associated with errno.
- The perror() function displays the string you pass to it, followed by a colon, a space, and then the textual representation of the current errno value.
- The strerror() function, which returns a pointer to the textual representation of the current errno value.
Let’s try to simulate an error condition and try to open a file which does not exist. Here I’m using both the functions to show the usage, but you can use one or more ways of printing your errors. Second important point to note is that you should use stderr file stream to output all the errors.
#include <stdio.h>
#include <errno.h>
#include <string.h>
Externinterrno ;
Int main () {
FILE * pf;
Interrnum;
Pf = fopen ("unexist.txt", "rb");
If (pf == NULL) {
Errnum = errno;
Fprintf(stderr, "Value of errno: %d\n", errno);
Perror("Error printed by perror");
Fprintf(stderr, "Error opening file: %s\n", strerror( errnum ));
} else {
Fclose (pf);
}
Return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of errno: 2
Error printed by perror: No such file or directory
Error opening file: No such file or directory
Divide by Zero Errors
It is a common problem that at the time of dividing any number, programmers do not check if a divisor is zero and finally it creates a runtime error.
The code below fixes this by checking if the divisor is zero before dividing −
#include <stdio.h>
#include <stdlib.h>
Main() {
Int dividend = 20;
Int divisor = 0;
Int quotient;
If( divisor == 0){
Fprintf(stderr, "Division by zero! Exiting...\n");
Exit(-1);
}
Quotient = dividend / divisor;
Fprintf(stderr, "Value of quotient : %d\n", quotient );
Exit(0);
}
When the above code is compiled and executed, it produces the following result −
Division by zero! Exiting...
Program Exit Status
It is a common practice to exit with a value of EXIT_SUCCESS in case of program coming out after a successful operation. Here, EXIT_SUCCESS is a macro and it is defined as 0.
If you have an error condition in your program and you are coming out then you should exit with a status EXIT_FAILURE which is defined as -1. So let’s write above program as follows −
#include <stdio.h>
#include <stdlib.h>
Main() {
Int dividend = 20;
Int divisor = 5;
Int quotient;
If( divisor == 0) {
Fprintf(stderr, "Division by zero! Exiting...\n");
Exit(EXIT_FAILURE);
}
Quotient = dividend / divisor;
Fprintf(stderr, "Value of quotient : %d\n", quotient );
Exit(EXIT_SUCCESS);
}
When the above code is compiled and executed, it produces the following result −
Value of quotient : 4
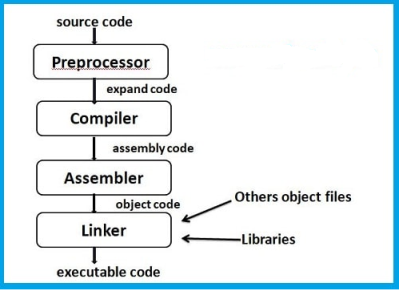
Source code is the C program that you write in your editor and save with a ‘ .C ‘ extension. Which is un-compiled (when written for the first time or whenever a change is made in it and saved).
Object code is the output of a compiler after it processes the source code. The object code is usually a machine code, also called a machine language, which can be understood directly by a specific type of CPU (central processing unit), such as x86 (i.e., Intel-compatible) or PowerPC. However, some compilers are designed to convert source code into anassembly language or some other another programming language. An assembly language is a human-readable notation using the mnemonics (mnemonicis a symbolic name for a single executable machine language instruction called an opcode) in the ISA ( Instruction Set Architecture) of that particular CPU .
Executable (also called the Binary) is the output of a linker after it processes the object code. A machine code file can be immediately executable (i.e., runnable as a program), or it might require linking with other object code files (e.g. Libraries) to produce a complete executable program.
Suggested Text Books
Byron Gottfried, Schaum's Outline of Programming with C, McGraw-Hill
E. Balaguruswamy, Programming in ANSI C, Tata McGraw-Hill
Suggested Reference Books
Brian W. Kernighan and Dennis M. Ritchie, The C Programming Language, Prentice Hall of India




