Unit - 2
Basic Search Techniques
Problem-solving agents:
In Artificial Intelligence, Search techniques are universal problem-solving methods. Rational agents or Problem-solving agents in AI mostly used these search strategies or algorithms to solve a specific problem and provide the best result. Problem-solving agents are the goal-based agents and use atomic representation. In this topic, we will learn various problem-solving search algorithms.
Search Algorithm Terminologies:
- Search: Searching is a step by step procedure to solve a search-problem in a given search space. A search problem can have three main factors:
- Search Space: Search space represents a set of possible solutions, which a system may have.
- Start State: It is a state from where agent begins the search.
- Goal test: It is a function which observe the current state and returns whether the goal state is achieved or not.
- Search tree: A tree representation of search problem is called Search tree. The root of the search tree is the root node which is corresponding to the initial state.
- Actions: It gives the description of all the available actions to the agent.
- Transition model: A description of what each action do, can be represented as a transition model.
- Path Cost: It is a function which assigns a numeric cost to each path.
- Solution: It is an action sequence which leads from the start node to the goal node.
- Optimal Solution: If a solution has the lowest cost among all solutions.
Properties of Search Algorithms:
Following are the four essential properties of search algorithms to compare the efficiency of these algorithms:
- Completeness: A search algorithm is said to be complete if it guarantees to return a solution if at least any solution exists for any random input.
- Optimality: If a solution found for an algorithm is guaranteed to be the best solution (lowest path cost) among all other solutions, then such a solution for is said to be an optimal solution.
- Time Complexity: Time complexity is a measure of time for an algorithm to complete its task.
- Space Complexity: It is the maximum storage space required at any point during the search, as the complexity of the problem.
Types of search algorithms
Based on the search problems we can classify the search algorithms into uninformed (Blind search) search and informed search (Heuristic search) algorithms.
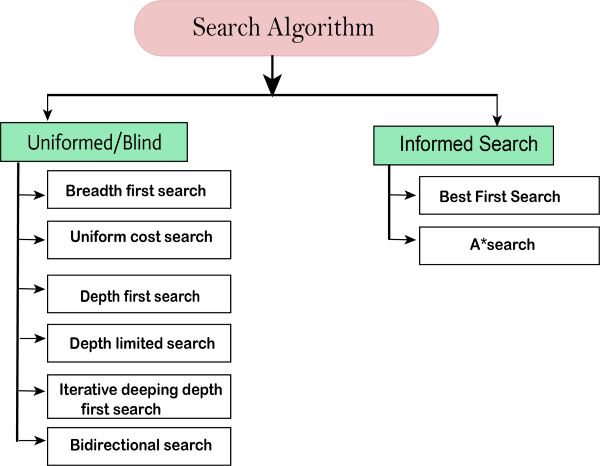
Uninformed/Blind Search:
The uninformed search does not contain any domain knowledge such as closeness, the location of the goal. It operates in a brute-force way as it only includes information about how to traverse the tree and how to identify leaf and goal nodes. Uninformed search applies a way in which search tree is searched without any information about the search space like initial state operators and test for the goal, so it is also called blind search. It examines each node of the tree until it achieves the goal node.
It can be divided into five main types:
- Breadth-first search
- Uniform cost search
- Depth-first search
- Iterative deepening depth-first search
- Bidirectional Search
Informed Search
Informed search algorithms use domain knowledge. In an informed search, problem information is available which can guide the search. Informed search strategies can find a solution more efficiently than an uninformed search strategy. Informed search is also called a Heuristic search.
A heuristic is a way which might not always be guaranteed for best solutions but guaranteed to find a good solution in reasonable time.
Informed search can solve much complex problem which could not be solved in another way.
An example of informed search algorithms is a traveling salesman problem.
- Greedy Search
- A* Search
Uninformed Search Algorithms
Uninformed search is a class of general-purpose search algorithms which operates in brute force-way. Uninformed search algorithms do not have additional information about state or search space other than how to traverse the tree, so it is also called blind search.
Following are the various types of uninformed search algorithms:
- Breadth-first Search
- Depth-first Search
- Depth-limited Search
- Iterative deepening depth-first search
- Uniform cost search
- Bidirectional Search
1. Breadth-first Search:
- Breadth-first search is the most common search strategy for traversing a tree or graph. This algorithm searches breadthwise in a tree or graph, so it is called breadth-first search.
- BFS algorithm starts searching from the root node of the tree and expands all successor node at the current level before moving to nodes of next level.
- The breadth-first search algorithm is an example of a general-graph search algorithm.
- Breadth-first search implemented using FIFO queue data structure.
Advantages:
- BFS will provide a solution if any solution exists.
- If there are more than one solutions for a given problem, then BFS will provide the minimal solution which requires the least number of steps.
Disadvantages:
- It requires lots of memory since each level of the tree must be saved into memory to expand the next level.
- BFS needs lots of time if the solution is far away from the root node.
Example:
In the below tree structure, we have shown the traversing of the tree using BFS algorithm from the root node S to goal node K. BFS search algorithm traverse in layers, so it will follow the path which is shown by the dotted arrow, and the traversed path will be:
- S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
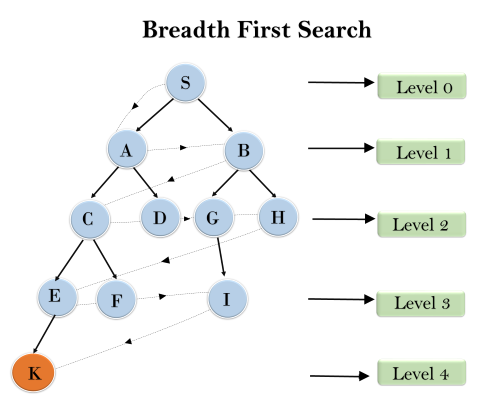
Time Complexity: Time Complexity of BFS algorithm can be obtained by the number of nodes traversed in BFS until the shallowest Node. Where the d= depth of shallowest solution and b is a node at every state.
T (b) = 1+b2+b3+.......+ bd= O (bd)
Space Complexity: Space complexity of BFS algorithm is given by the Memory size of frontier which is O(bd).
Completeness: BFS is complete, which means if the shallowest goal node is at some finite depth, then BFS will find a solution.
Optimality: BFS is optimal if path cost is a non-decreasing function of the depth of the node.
2. Depth-first Search
- Depth-first search isa recursive algorithm for traversing a tree or graph data structure.
- It is called the depth-first search because it starts from the root node and follows each path to its greatest depth node before moving to the next path.
- DFS uses a stack data structure for its implementation.
- The process of the DFS algorithm is similar to the BFS algorithm.
Note: Backtracking is an algorithm technique for finding all possible solutions using recursion.
Advantage:
- DFS requires very less memory as it only needs to store a stack of the nodes on the path from root node to the current node.
- It takes less time to reach to the goal node than BFS algorithm (if it traverses in the right path).
Disadvantage:
- There is the possibility that many states keep re-occurring, and there is no guarantee of finding the solution.
- DFS algorithm goes for deep down searching and sometime it may go to the infinite loop.
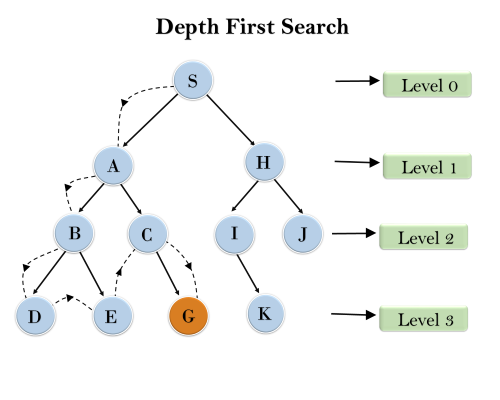
Example:
In the below search tree, we have shown the flow of depth-first search, and it will follow the order as:
Root node--->Left node ----> right node.
It will start searching from root node S, and traverse A, then B, then D and E, after traversing E, it will backtrack the tree as E has no other successor and still goal node is not found. After backtracking it will traverse node C and then G, and here it will terminate as it found goal node.
Completeness: DFS search algorithm is complete within finite state space as it will expand every node within a limited search tree.
Time Complexity: Time complexity of DFS will be equivalent to the node traversed by the algorithm. It is given by:
T(n)= 1+ n2+ n3 +.........+ nm=O(nm)
Where, m= maximum depth of any node and this can be much larger than d (Shallowest solution depth)
Space Complexity: DFS algorithm needs to store only single path from the root node, hence space complexity of DFS is equivalent to the size of the fringe set, which is O(bm).
Optimal: DFS search algorithm is non-optimal, as it may generate a large number of steps or high cost to reach to the goal node.
3. Depth-Limited Search Algorithm:
A depth-limited search algorithm is similar to depth-first search with a predetermined limit. Depth-limited search can solve the drawback of the infinite path in the Depth-first search. In this algorithm, the node at the depth limit will treat as it has no successor nodes further.
Depth-limited search can be terminated with two Conditions of failure:
- Standard failure value: It indicates that problem does not have any solution.
- Cutoff failure value: It defines no solution for the problem within a given depth limit.
Advantages:
- Depth-limited search is Memory efficient.
Disadvantages:
- Depth-limited search also has a disadvantage of incompleteness.
- It may not be optimal if the problem has more than one solution.
Example:
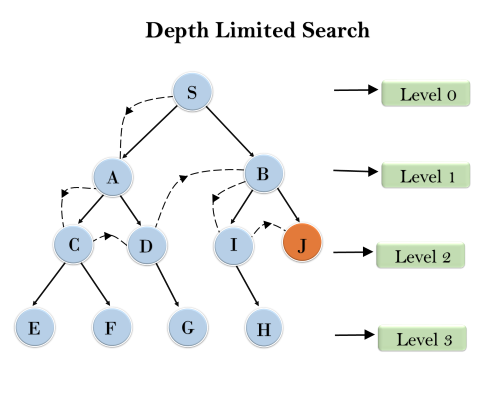
Completeness: DLS search algorithm is complete if the solution is above the depth-limit.
Time Complexity: Time complexity of DLS algorithm is O(bℓ).
Space Complexity: Space complexity of DLS algorithm is O(b×ℓ).
Optimal: Depth-limited search can be viewed as a special case of DFS, and it is also not optimal even if ℓ>d.
4. Uniform-cost Search Algorithm:
Uniform-cost search is a searching algorithm used for traversing a weighted tree or graph. This algorithm comes into play when a different cost is available for each edge. The primary goal of the uniform-cost search is to find a path to the goal node which has the lowest cumulative cost. Uniform-cost search expands nodes according to their path costs form the root node. It can be used to solve any graph/tree where the optimal cost is in demand. A uniform-cost search algorithm is implemented by the priority queue. It gives maximum priority to the lowest cumulative cost. Uniform cost search is equivalent to BFS algorithm if the path cost of all edges is the same.
Advantages:
- Uniform cost search is optimal because at every state the path with the least cost is chosen.
Disadvantages:
- It does not care about the number of steps involve in searching and only concerned about path cost. Due to which this algorithm may be stuck in an infinite loop.
Example:
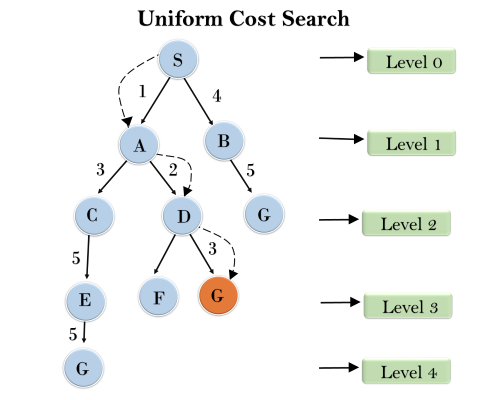
Completeness:
Uniform-cost search is complete, such as if there is a solution, UCS will find it.
Time Complexity:
Let C* is Cost of the optimal solution, and ε is each step to get closer to the goal node. Then the number of steps is = C*/ε+1. Here we have taken +1, as we start from state 0 and end to C*/ε.
Hence, the worst-case time complexity of Uniform-cost search isO(b1 + [C*/ε])/.
Space Complexity:
The same logic is for space complexity so, the worst-case space complexity of Uniform-cost search is O(b1 + [C*/ε]).
Optimal:
Uniform-cost search is always optimal as it only selects a path with the lowest path cost.
5. Iterative deepening depth-first Search:
The iterative deepening algorithm is a combination of DFS and BFS algorithms. This search algorithm finds out the best depth limit and does it by gradually increasing the limit until a goal is found.
This algorithm performs depth-first search up to a certain "depth limit", and it keeps increasing the depth limit after each iteration until the goal node is found.
This Search algorithm combines the benefits of Breadth-first search's fast search and depth-first search's memory efficiency.
The iterative search algorithm is useful uninformed search when search space is large, and depth of goal node is unknown.
Advantages:
- It combines the benefits of BFS and DFS search algorithm in terms of fast search and memory efficiency.
Disadvantages:
- The main drawback of IDDFS is that it repeats all the work of the previous phase.
Example:
Following tree structure is showing the iterative deepening depth-first search. IDDFS algorithm performs various iterations until it does not find the goal node. The iteration performed by the algorithm is given as:
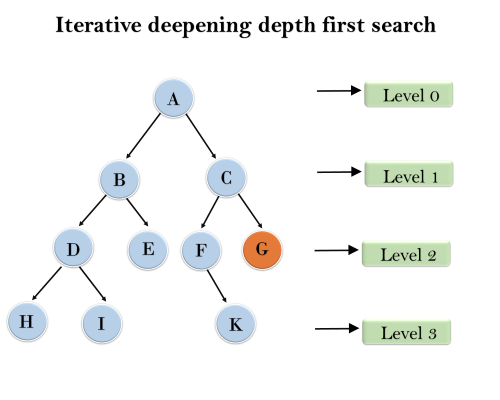
1'st Iteration-----> A
2'nd Iteration----> A, B, C
3'rd Iteration------>A, B, D, E, C, F, G
4'th Iteration------>A, B, D, H, I, E, C, F, K, G
In the fourth iteration, the algorithm will find the goal node.
Completeness:
This algorithm is complete is ifthe branching factor is finite.
Time Complexity:
Let's suppose b is the branching factor and depth is d then the worst-case time complexity is O(bd).
Space Complexity:
The space complexity of IDDFS will be O(bd).
Optimal:
IDDFS algorithm is optimal if path cost is a non- decreasing function of the depth of the node.
6. Bidirectional Search Algorithm:
Bidirectional search algorithm runs two simultaneous searches, one form initial state called as forward-search and other from goal node called as backward-search, to find the goal node. Bidirectional search replaces one single search graph with two small subgraphs in which one starts the search from an initial vertex and other starts from goal vertex. The search stops when these two graphs intersect each other.
Bidirectional search can use search techniques such as BFS, DFS, DLS, etc.
Advantages:
- Bidirectional search is fast.
- Bidirectional search requires less memory
Disadvantages:
- Implementation of the bidirectional search tree is difficult.
- In bidirectional search, one should know the goal state in advance.
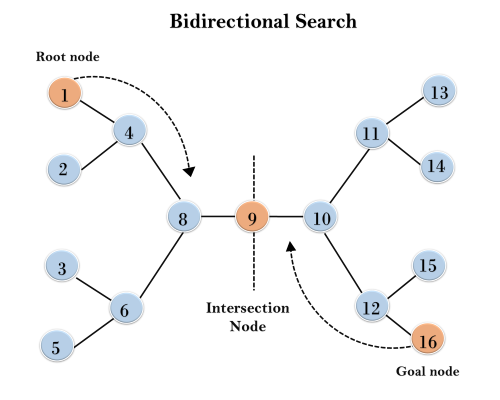
Example:
In the below search tree, bidirectional search algorithm is applied. This algorithm divides one graph/tree into two sub-graphs. It starts traversing from node 1 in the forward direction and starts from goal node 16 in the backward direction.
The algorithm terminates at node 9 where two searches meet.
Completeness: Bidirectional Search is complete if we use BFS in both searches.
Time Complexity: Time complexity of bidirectional search using BFS is O(bd).
Space Complexity: Space complexity of bidirectional search is O(bd).
Optimal: Bidirectional search is Optimal.
Uninformed search, also known as blind, exhaustive, or brute-force search, is a type of search that doesn't use any information about the problem to guide it and so isn't very efficient.
Breadth first search
The breadth first search technique is a general strategy for traversing a graph. A breadth first search takes up more memory, but it always discovers the shortest path first. In this type of search, the state space is represented as a tree. The answer can be discovered by traveling the tree. The tree's nodes indicate the initial value of starting state, multiple intermediate states, and the end state.
This search makes use of a queue data structure, which is traversed level by level. In a breadth first search, nodes are extended in order of their distance from the root. It's a path-finding algorithm that, if one exists, can always find a solution. The answer that is discovered is always the alternative option. This task demands a significant amount of memory. At each level, each node in the search tree is increased in breadth.
Algorithm:
Step 1: Place the root node inside the queue.
Step 2: If the queue is empty then stops and returns failure.
Step 3: If the FRONT node of the queue is a goal node, then stop and return success. Step 4: Remove the FRONT node from the queue. Process it and find all its neighbours that are in a ready state then place them inside the queue in any order.
Step 5: Go to Step 3.
Step 6: Exit.
Implementations
Let us implement the above algorithm of BFS by taking the following suitable example
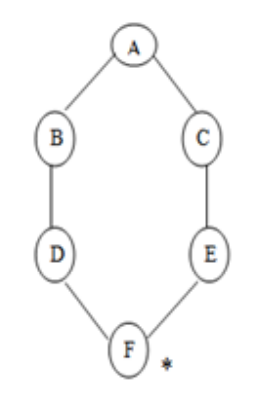
Fig 3: Example
Consider the graph below, where A is the initial node and F is the destination node (*).
Step 1: Place the root node inside the queue i.e. A
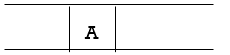
Step 2: The queue is no longer empty, and the FRONT node, i.e. A, is no longer our goal node. So, proceed to step three.
Step 3: Remove the FRONT node, A, from the queue and look for A's neighbors, B and C.
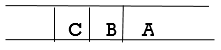
Step 4: Now, b is the queue's FRONT node. As a result, process B and look for B's neighbors, i.e., D.
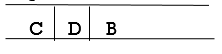
Step 5: Find out who C's neighbors are, which is E.

Ste 6: As D is the queue's FRONT node, find out who D's neighbors are.
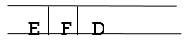
Step 7: E is now the queue's first node. As a result, E's neighbor is F, which is our objective node.
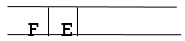
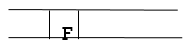
Step 8: Finally, F is the FRONT of the queue, which is our goal node. As a result, leave.
Advantages
● The goal will be achieved in whatever way possible using this strategy.
● It does not take any unproductive pathways for a long time.
● It finds the simplest answer in the situation of several pathways.
Disadvantages
● BFS consumes a significant amount of memory.
● It has a greater level of time complexity.
● It has long pathways when all paths to a destination have about the same search depth.
Key takeaway
- Breadth-first search is a search method in which the highest layer of a decision tree is entirely searched before moving on to the next layer (BFS).
- Because no feasible solutions are omitted in this technique, an optimal solution is certain to be found.
- When the search space is large, this method is frequently impractical.
The algorithm's performance is measured using the following four parameters:
1. Time complexity: The amount of time it takes the algorithm to discover a solution.
2. Space complexity: The amount of memory required by the algorithm to complete the search.
3. Optimality: The algorithm's solution will always be optimal or not.
4. Completeness: Is the calculation guaranteed to yield an answer when there isn't one available? Regardless of whether the search algorithm is thorough, this part is a Boolean marker.
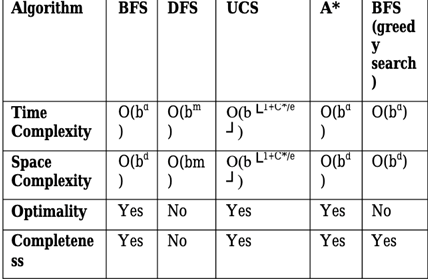
Comparison of search algorithm




