Unit - 3
Clustering
Clustering is the process of grouping data. Based on some similarity measure, the resulting groups should be such that data within the same group should be identical and data within different groups should be dissimilar. A good clustering algorithm can create groups that maximize data similarity among similar groups while minimizing data similarity among different groups.
Application of clustering
Classes are conceptually important groups of objects with identical characteristics. Data that is defined in terms of classes offers a better image than raw data.
An image, for example, may be defined as "a picture of houses, vehicles, and people" or by specifying the pixel value. The first approach is more useful for finding out what the picture is about.
Clustering is also seen as a prelude to more sophisticated data processing techniques.
As an example,
● A music streaming service could divide users into groups based on their musical preferences. Instead of estimating music recommendations for each individual person, these classes can be measured. It's also simpler for a new consumer to find out who their closest neighbors are.
● Time is proportional to n2 in linear regression, where n is the number of samples. As a result, nearby data points may be grouped together as a single representative point in large datasets. On this smaller dataset, regression can be used.
● There may be millions of colors in a single picture. To make the color palette smaller, identical RGB values could be grouped together.
Types of clusters
Depending on the issue at hand, clusters may be of various forms. Clusters can be anything from
● Well separated clusters
Each data point in a well-separated cluster is closer to all points within the cluster than to any point outside of it. When clusters are well apart, this is more likely to occur.
● Prototype based clusters
Each cluster in prototype-based clusters is represented by a single data point. Clusters are allocated to data points. Each point in a cluster is closer to that cluster's representative than any other cluster's representative.
● Graph based clusters
A cluster is a group of linked data points that do not have a connection to any point outside the cluster if data is described as a graph with nodes as data points and edges as connections. Depending on the issue, the word "related" can mean various things.
● Density based clusters
A density-based cluster is a dense set of data points surrounded by a low-density area.
K - means
K-Means Clustering is an unsupervised learning approach used in machine learning and data science to solve clustering problems. K specifies the number of pre-defined clusters that must be produced during the process; for example, if K=2, two clusters will be created, and if K=3, three clusters will be created, and so on.
It allows us to cluster data into different groups and provides a simple technique to determine the categories of groups in an unlabeled dataset without any training.
It's a centroid-based approach, which means that each cluster has its own centroid. The main goal of this technique is to reduce the sum of distances between data points and the clusters that they belong to.
For numeric results, K-Means clustering is one of the most commonly used prototype-based clustering algorithms. The centroid or mean of all the data points in a cluster is the prototype of a cluster in k-means. As a consequence, the algorithm works best with continuous numeric data. When dealing with data that includes categorical variables or a mixture of quantitative and categorical variables.
The technique takes an unlabeled dataset as input, separates it into a k-number of clusters, and continues the procedure until no better clusters are found. In this algorithm, the value of k should be predetermined.
The k-means clustering algorithm primarily accomplishes two goals:
● Iteratively determines the optimal value for K centre points or centroids.
● Each data point is assigned to the k-center that is closest to it. A cluster is formed by data points that are close to a specific k-center.
As a result, each cluster contains datapoints with certain commonality and is isolated from the others.
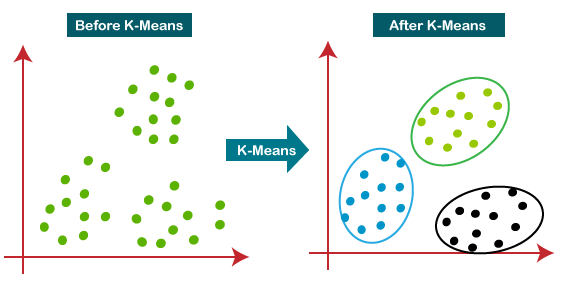
Fig 1: Working of the K-means Clustering Algorithm
Pseudo Algorithm
- Choose an appropriate value of K (number of clusters we want)
- Generate K random points as initial cluster centroids
- Until convergence (Algorithm converges when centroids remain the same between iterations):
● Assign each point to a cluster whose centroid is nearest to it ("Nearness" is measured as the Euclidean distance between two points)
● Calculate new values of centroids of each cluster as the mean of all points assigned to that cluster
K-Means as an optimization problem
Any learning algorithm has the aim of minimizing a cost function. We'll see how, by using centroid as a cluster prototype, we can minimize a cost function called "sum of squared error".
Cost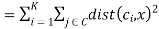
The sum of squared error is the square of all points' distances from their respective cluster prototypes.
We get by taking the partial derivative of the cost function with respect to and cluster prototype and equating it to 0.
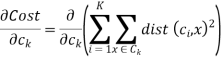
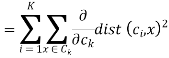
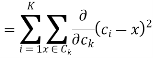
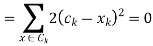
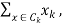 Where
Where 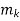 is the number of points in cluster k.
is the number of points in cluster k.
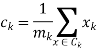
Cluster centroids are thus the prototypes that minimize the cost function.
Key takeaway:
● K-Means clustering is one of the most commonly used prototype-based clustering algorithms.
● The algorithm works best with continuous numeric data.
● When dealing with data that includes categorical variables or a mixture of quantitative and categorical variables.
● K-Means is a more effective algorithm. Defining distances between each diamond takes longer than computing a mean.
Hierarchical
Hierarchical clustering, also known as hierarchical cluster analysis or HCA, is another unsupervised machine learning approach for grouping unlabeled datasets into clusters.
The hierarchy of clusters is developed in the form of a tree in this technique, and this tree-shaped structure is known as the dendrogram.
Although the results of K-means clustering and hierarchical clustering may appear to be comparable at times, their methods differ. As opposed to the K-Means algorithm, there is no need to predetermine the number of clusters.
There are two ways to hierarchical clustering:
● Agglomerative - Agglomerative is a bottom-up strategy in which the algorithm begins by grouping all data points into single clusters and merging them until only one remains.
● Divisive - Because it is a top-down method, the divisive algorithm is the inverse of the agglomerative algorithm.
Why we need hierarchical clustering?
Why do we need hierarchical clustering when we already have alternative clustering methods like K-Means Clustering? So, as we've seen with K-means clustering, this algorithm has some limitations, such as a set number of clusters and a constant attempt to construct clusters of the same size. We can utilise the hierarchical clustering algorithm to tackle these two problems because we don't need to know the specified number of clusters in this algorithm.
Key takeaway
Clustering is the process of grouping data. Based on some similarity measure, the resulting groups should be such that data within the same group should be identical and data within different groups should be dissimilar.
K-Means clustering is one of the most commonly used prototype-based clustering algorithms. The algorithm works best with continuous numeric data.
When dealing with data that includes categorical variables or a mixture of quantitative and categorical variables.
K-Means is a more effective algorithm. Defining distances between each diamond takes longer than computing a mean.
Dimensionality refers to the amount of input characteristics, variables, or columns in a dataset, and dimensionality reduction refers to the process of reducing these features.
In some circumstances, a dataset has a large number of input features, making predictive modelling more difficult. Because it is difficult to visualise or forecast a training dataset with a large number of characteristics, dimensionality reduction techniques must be used in such circumstances.
"It is a strategy of turning the higher dimensions dataset into fewer dimensions dataset while guaranteeing that it gives similar information," says one definition.
These methods are commonly utilised in machine learning to develop a more accurate predictive model while solving classification and regression challenges.
Speech recognition, signal processing, bioinformatics, and other fields that deal with high-dimensional data use it frequently. It can also be used to visualise data, reduce noise, and do cluster analysis, among other things.
Benefits to applying dimensionality reduction
The following are some of the advantages of using a dimensionality reduction technique on a given dataset:
● The space required to store the dataset is lowered by lowering the dimensionality of the features.
● Reduced feature dimensions necessitate less Computation training time.
● The reduced dimensions of the dataset's features aid in quickly displaying the data.
● It takes care of multicollinearity to remove redundant features (if any are present).
Disadvantages
There are a few drawbacks to using dimensionality reduction, which are listed below:
● Due to the reduction in dimensionality, some data may be lost.
● The principal components that must be considered in the PCA dimensionality reduction technique are occasionally unknown.
Common techniques of Dimensionality Reduction
● Principal Component Analysis
● Backward Elimination
● Forward Selection
● Score comparison
● Missing Value Ratio
● Low Variance Filter
● High Correlation Filter
● Random Forest
● Factor Analysis
● Auto-Encoder
Approaches of Dimension Reduction
The dimension reduction approach can be used in two ways, as shown below:
Feature selection
To develop a high-accuracy model, feature selection is the process of picking a subset of important characteristics and excluding irrelevant features from a dataset. In other words, it's a method for choosing the best characteristics from a dataset.
The feature selection is done in three ways:
- Filters method
The dataset is filtered in this manner, and only the relevant features are taken as a subset. The following are some examples of filtering techniques:
● Correlation
● Chi-Square Test
● ANOVA
● Information Gain, etc.
2. Wrappers Methods
The wrapper method achieves the same aim as the filter function, but it evaluates it using a machine learning model. In this procedure, various features are fed into the machine learning model, and the performance is evaluated. To improve the model's accuracy, the performance selects whether to include or eliminate those features. This method is more accurate than filtering, but it is more difficult to implement.
The following are some examples of wrapper methods:
● Forward Selection
● Backward Selection
● Bi-directional Elimination
3. Embedded Methods
Methods that are embedded Examine the machine learning model's several training iterations and rank the value of each feature. Embedded methods are used in a variety of ways, including:
● LASSO
● Elastic Net
● Ridge Regression, etc.
Feature Extraction
The process of changing a space with many dimensions into a space with fewer dimensions is known as feature extraction. This method is handy when we want to keep all of the information while processing it with fewer resources.
The following are some examples of common feature extraction techniques:
● Principal Component Analysis
● Linear Discriminant Analysis
● Kernel PCA
● Quadratic Discriminant Analysis
Key takeaway
Dimensionality refers to the amount of input characteristics, variables, or columns in a dataset, and dimensionality reduction refers to the process of reducing these features.
Principal Component Analysis is an unsupervised learning approach used in machine learning to reduce dimensionality. With the help of orthogonal transformation, it is a statistical technique that turns observations of correlated features into a set of linearly uncorrelated data. The Principal Components are the newly altered features. It's one of the most widely used programmes for exploratory data analysis and predictive modelling. It's a method for extracting strong patterns from a dataset by lowering variances.
PCA seeks out the lowest-dimensional surface on which to project the high-dimensional data.
The variance of each characteristic is taken into account by PCA since the high attribute indicates a good separation between the classes and so minimises dimensionality. Image processing, movie recommendation systems, and optimising power allocation in multiple communication channels are some of the real-world uses of PCA. Because it is a feature extraction technique, it keeps the significant variables while discarding the less important ones.
The PCA algorithm is based on the following mathematical concepts:
● Variance and Covariance
● Eigenvalues and Eigen factors
Principal components in PCA
The Principal Components are the converted new features or the result of PCA, as stated above. The number of PCs in this dataset is either equal to or less than the number of original features in the dataset. The following are some of the properties of these main components:
● The linear combination of the original features must be the main component.
● These components are orthogonal, which means there is no link between two variables.
● When going from 1 to n, the importance of each component declines, indicating that the 1 PC is the most important and the n PC is the least important.
Steps for PCA algorithm
● Getting the dataset
To begin, we must divide the input dataset into two halves, X and Y, with X being the training set and Y being the validation set.
● Representing data into a structure
Now we'll use a structure to represent our data. As an example, the two-dimensional matrix of independent variable X will be represented. Each column correlates to the Features, and each row corresponds to the data elements. The dataset's dimensions are determined by the number of columns.
● Standardizing the data
We'll normalise our data in this stage. In a given column, for example, features with a large variance are more essential than features with a lower variance.
If the importance of features is unaffected by the variance of the feature, we shall divide each data item in a column by the column's standard deviation. The matrix will be referred to as Z in this case.
● Calculating the Covariance of Z
We will take the matrix Z and transpose it to get the covariance of Z. We'll multiply it by Z after it's been transposed. The Covariance matrix of Z will be the output matrix.
● Calculating the Eigen Values and Eigen Vectors
The eigenvalues and eigenvectors for the resulting covariance matrix Z must now be calculated. The directions of the axes with high information are called eigenvectors or the covariance matrix. The eigenvalues are defined as the coefficients of these eigenvectors.
● Sorting the Eigen Vectors
We'll take all of the eigenvalues and arrange them in decreasing order, from largest to smallest, in this phase. In the eigen values matrix P, sort the eigenvectors in the same order. P* will be the name of the resulting matrix.
● Calculating the new features Or Principal Components
We'll calculate the new features here. We'll do this by multiplying the P* matrix by the Z. Each observation in the resulting matrix Z* is a linear combination of the original features. The Z* matrix's columns are all independent of one another.
● Remove less or unimportant features from the new dataset
We'll determine what to keep and what to discard now that the new feature set has arrived. It indicates that only relevant or crucial features will be kept in the new dataset, while unimportant ones will be deleted.
Applications
● PCA is mostly utilised as a dimensionality reduction approach in AI applications like computer vision and picture compression.
● If the data includes a lot of dimensions, it can also be utilised to find hidden patterns. Finance, data mining, psychology, and other fields employ PCA.
Key takeaway
Principal Component Analysis is an unsupervised learning approach used in machine learning to reduce dimensionality. With the help of orthogonal transformation, it is a statistical technique that turns observations of correlated features into a set of linearly uncorrelated data.
Anomaly Detection is a technique for finding uncommon occurrences or observations that are statistically distinct from the rest of the observations and can raise suspicions. Such "abnormal" behaviour usually indicates a problem, such as credit card fraud, a failed server system, a cyber assault, and so on.
Anomaly detection (also known as outlier detection) is the process of identifying unusual things, occurrences, or observations that raise suspicion by deviating greatly from the rest of the data. Typically, the anomalous things will point to a problem such as bank fraud, a structural flaw, medical issues, or textual flaws. Outliers, novelties, noise, deviations, and exceptions are all terms used to describe anomalies.
In the context of abuse and network intrusion detection, the intriguing objects are frequently sudden bursts of activity rather than infrequent items. Many outlier detection methods (in particular unsupervised approaches) may fail on such data unless it has been aggregated adequately, as this pattern does not adhere to the usual statistical definition of an outlier as an uncommon object. A cluster analysis method, on the other hand, might be able to recognise the micro clusters generated by these patterns.
Anomalies can be classified into one of three groups:
● Point Anomaly: If a tuple in a dataset deviates significantly from the rest of the data, it is referred to as a Point Anomaly.
● Contextual Anomaly: An observation is a Contextual Anomaly if it is anomalous due to the observation's context.
● Collective Anomaly: A group of data instances can aid in the detection of an abnormality.
The concepts of Machine Learning can be used to discover anomalies. It can be done in a variety of ways:
● Supervised Anomaly Detection: To build a prediction model to categorise future data points, this method requires a labelled dataset including both normal and anomalous samples. Supervised Neural Networks, Support Vector Machine Learning, K-Nearest Neighbors Classifier, and other techniques are often employed for this purpose.
● Unsupervised Anomaly Detection: This method does not require any training data and instead relies on two assumptions about the data: only a small fraction of data is anomalous, and any anomaly is statistically distinct from the normal samples. The data is then clustered using a similarity metric based on the previous assumptions, and data points that are far from the cluster are called anomalies.
Application
Intrusion detection, fraud detection, fault detection, system health monitoring, event detection in sensor networks, detecting ecological changes, and defect identification in images using machine vision are all examples of anomaly detection. It's frequently used in preprocessing to get rid of erroneous data from a dataset. Removing anomalous data from a dataset often results in a statistically significant gain in accuracy in supervised learning.
Key takeaway
Anomaly Detection is a technique for finding uncommon occurrences or observations that are statistically distinct from the rest of the observations and can raise suspicions.
Anomaly detection (also known as outlier detection) is the process of identifying unusual things, occurrences, or observations that raise suspicion by deviating greatly from the rest of the data.
The problem with machine learning systems is that it's extremely difficult for teams – including machine learning experts – to predict how tough it will be to construct a model or feature without first experimenting with data and creating first-pass, baseline models for a task. Simply said, feasibility cannot be determined by a single judgement call by a seasoned technical team; it is an explicit, time-limited phase in the product development lifecycle.
It's also iterative, because the team may find that while the original challenge described during Discovery isn't solvable, a variation (maybe a down-scoped version) is. The attention then changes to determining whether or not this newly-formulated task still has an impact on the business and end-users.
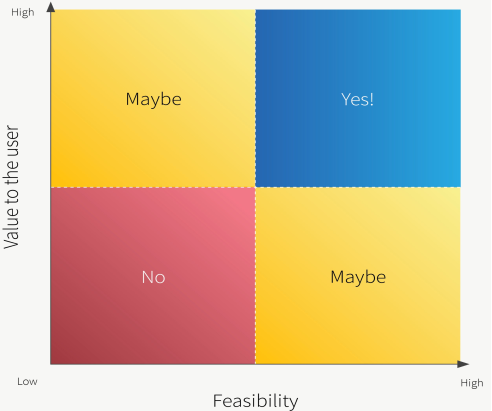
Fig: Feasibility study
Impact-feasibility evaluations are clearly still valuable in machine learning applications. They must, however, be considered as live documents that change and solidify as the team gains a better understanding of the data, algorithms, and technological restrictions that apply to their task and issue domain.
This phase is known as a feasibility study at Borealis AI, and it is used at the start of our projects to assist us decide whether or not to pursue a project and to manage the expectations of our business partners.
Reinforcement Learning is a feedback-based Machine Learning technique in which an agent learns how to behave in a given environment by executing actions and seeing the outcomes of those actions. The agent receives positive feedback for each excellent action, and negative feedback or a penalty for each bad action.
Unlike supervised learning, the agent learns autonomously utilising feedback and no labelled data in Reinforcement Learning. Because there is no labelled data, the agent must rely only on its own experience to learn.
RL is used to tackle a certain sort of problem in which sequential decision-making is required and the aim is long-term, such as game-playing, robotics, and so on. The agent interacts with and explores the world on its own. In reinforcement learning, an agent's primary goal is to increase performance by obtaining the most positive rewards.
The agent learns through trial and error, and as a result of its experience, it improves its ability to complete the task. As a result, "reinforcement learning" can be defined as "a form of machine learning method in which an intelligent agent (computer programme) interacts with the environment and learns how to function within it." Reinforcement learning is demonstrated by the way a robotic dog learns to move his arms.
Reinforcement learning is a fundamental idea in artificial intelligence, and it is used by all AI agents. We don't need to programme the agent ahead of time because it learns from its own experiences without the need for human assistance.
Features of Reinforcement learning
● In real life, the agent is not given any instructions regarding the surroundings or the tasks that must be taken.
● It is based on the hit-or-miss method.
● The agent performs the next action and changes states in response to the previous activity's feedback.
● A delayed incentive could be given to the agent.
● Because the environment is stochastic, the agent must explore it in order to maximise positive rewards.
Approaches to implement Reinforcement Learning
In machine learning, there are primarily three methods for implementing reinforcement learning:
Value-based:
The value-based approach is concerned with determining the optimal value function, or the maximum value at a given state under any policy. As a result, the agent anticipates a long-term return in any state(s) covered by the policy π.
Policy-based:
Without employing the value function, a policy-based approach is used to identify the best policy for the best future rewards. In this technique, the agent strives to apply a strategy in which each step's action contributes to the future reward being maximised.
There are primarily two types of policies in the policy-based approach:
● Deterministic: The policy () produces the same action in every state.
● Stochastic: In this policy, the resulting action is determined by probability.
Model-based:
In the model-based method, a virtual model of the environment is generated, and the agent explores it to learn about it. Because the model representation differs depending on the context, there is no specific solution or algorithm for this approach.
Types of Reinforcement learning
Reinforcement learning can be divided into two categories:
● Positive Reinforcement
● Negative Reinforcement
Positive Reinforcement:
Positive reinforcement learning entails doing something to increase the likelihood of the desired behaviour occurring again. It has a beneficial effect on the agent's behaviour and raises the strength of the conduct.
This form of reinforcement can last a long period, but too much positive reinforcement might result in an overload of states, which can lessen the consequences.
Negative Reinforcement:
Bad reinforcement learning is the polar opposite of positive reinforcement learning in that it enhances the likelihood of the given behaviour recurring by avoiding the negative situation.
Depending on the situation and conduct, it may be more successful than positive reinforcement, although it only offers reinforcement for the bare minimum of activity.
Example:
For a robot, an environment is a place where it has been put to use. Remember this, the robot is itself the agent. For example, a textile factory where a robot is used to move materials from one place to another.
These tasks have a property in common:
These tasks involve an environment and expect the agents to learn from that environment. This is where traditional machine learning fails and hence the need for reinforcement learning.
q-learning
Q-learning is another type of reinforcement learning algorithm that seeks to find the best action to take given the current state. It’s considered as the off-policy because the q-learning function learns from actions that are outside the current policy, such as taking random actions, and therefore a policy isn’t needed.
More specifically, q-learning seeks to learn a policy that maximizes the total reward.
Role of ‘Q’
The ‘q’ in q-learning stands for quality. Quality in this case represents how useful a given action is in gaining some future reward.
Create a q-table
When q-learning is performed we create what’s called a q-table or matrix that follows the shape of [state, action] and we initialize our values to zero. We then update and store our q-values after an episode. This q-table becomes a reference table for our agent to select the best action based on the q-value.
Updating the q-table
The updates occur after each step or action and end when an episode is done. Done in this case means reaching some terminal point by the agent. A terminal state for example can be anything like landing on a checkout page, reaching the end of some game, completing some desired objective, etc. The agent will not learn much after a single episode, but eventually, with enough exploring (steps and episodes) it will converge and learn the optimal q-values or q-star (Q∗).
Here are the 3 basic steps:
- The agent starts in a state (s1) takes an action (a1) and receives a reward (r1)
- The agent selects action by referencing Q-table with the highest value (max) OR by random (epsilon, ε)
- Update q-values
Key takeaway
Reinforcement learning (RL) solves a particular kind of problem where decision making is sequential, and the goal is long-term, such as game playing, robotics, resource management, or logistics.
References:
- Tom Mitchell. Machine Learning (McGraw Hill)
- Understanding Machine Learning. Shai Shalev-Shwartz and Shai Ben-David. Cambridge University Press.
- Artificial Neural Network, B. Yegnanarayana, PHI, 2005




