Unit - 5
Evolutionary algorithm
An evolutionary algorithm is a computer application based on evolutionary AI that solves issues by using methods that mirror the behaviours of biological things. As a result, it employs mechanisms such as reproduction, mutation, and recombination that are commonly associated with biological evolution.
The weakest solutions are eliminated in a Darwinian-like natural selection process, while stronger, more viable possibilities are maintained and re-evaluated in the following evolution—the goal being to arrive at optimal behaviours to achieve the desired outcomes.
Evolutionary algorithms are a heuristic-based technique to tackle problems that are difficult to answer in polynomial time, such as NP-Hard problems and anything else that would take too long to process exhaustively.
An evolutionary algorithm (EA) is a subset of evolutionary computation, a generic population-based metaheuristic optimization technique in computer intelligence (CI). EAs use biological evolution-inspired mechanisms like reproduction, mutation, recombination, and selection. Individuals in a population are represented by candidate solutions to the optimization problem, and the fitness function determines the quality of the answers. Following the recurrent application of the aforesaid operators, population evolution occurs.
Because they ideally do not make any assumptions about the underlying fitness landscape, evolutionary algorithms often do well at approximating solutions to a wide range of issues. Explorations of microevolutionary processes and planning models based on cellular processes are the most common applications of evolutionary algorithms to biological evolution modelling. Computational complexity is a barrier in most real-world EA applications.
In fact, the evaluation of fitness functions is the source of this computational complexity. One way to get around this problem is to use fitness approximation. However, relatively basic EA can address often complicated problems; thus, there may not be a straight relationship between algorithm complexity and problem complexity.
The advantages of evolutionary algorithms for business
Evolutionary algorithms have a number of business advantages, including:
● Increased flexibility: Evolutionary algorithm concepts can be tweaked and altered to address the most difficult difficulties humans confront while still achieving their goals.
● Better optimization: All viable solutions are considered as part of a large "population." This means that the algorithm isn't limited to a single solution.
● Unlimited solutions: Unlike traditional approaches, which present and seek to retain a single best answer, evolutionary algorithms consider and can present a variety of possible solutions to a problem.
Genetic algorithms function by producing a set of random solutions and forcing them to compete in an environment where only the best survive. They are based on the notion of natural selection. Each of the solutions in the set represents a chromosome. Learning algorithms based on genetic algorithms are based on natural adaptation and evolution models. Through processes that simulate population genetics and survival of the fittest, these learning methods increase their performance.
A population is subjected to an environment that sets pressures on its members in the realm of genetics. Matting and replication are reserved for those who adapt successfully. Reproduction, crossover, and mutation are the three basic genetic operators used in most genetic algorithms. To evolve a new population, these are blended. The algorithm employs these operators and the fitness function to steer its search for the best answer, starting with a random selection of solutions.
The fitness function makes an educated guess as to how good the answer is and provides a measure of its capacity. The genetic operators copy systems based on human evolution principles. The main advantage of the genetic algorithm formulation is that fairly accurate results may be obtained using a very simple algorithm.
The evolutionary algorithm is a mechanism for determining a good solution to a problem based on feedback from previous attempts at solving it. The GA's attempts to solve a problem are judged by the fitness function. GA is unable to deduce the answer to a problem, but they can learn from the fitness function.
The GA follows the following steps: Generate, Evaluate, Value Assignment, Mate, and Mutate. Allowing the GA to run for a specified amount of cycles is one of the criteria. Allowing the GA to run until a reasonable solution is discovered is the second option.
Mutation is also an operation that ensures that all locations in the rule space can be reached, and that every conceivable rule in the rule space may be evaluated. To avoid random wandering in the search space, the mutation operator is normally used only sparingly.
Let's look at the genetic algorithm in more detail:
Step 1: Generate the initial population.
Step 2: Calculate the fitness function of each individual.
Step 3: Some sort of performance utility values or the fitness values are assigned to individuals.
Step 4: New populations are generated from the best individuals by the process of selection.
Step 5: Perform the crossover and mutation operation.
Step 6: Replace the old population with the new individuals.
Step 7: Perform step-2 until the goal is reached.
Advantages of GA
● It has a lot of parallel processing power.
● It can solve issues involving discrete functions, multi-objective problems, and continuous functions, among others.
● It gives you answers that get better over time.
● Derivative information is not required by a genetic algorithm.
Limitation of GA
● They are ineffective when it comes to tackling minor problems.
● Due to a lack of suitable implementation, the algorithm may converge to a suboptimal result.
● The final solution's quality cannot be guaranteed.
● Repeatedly calculating fitness values may cause some problems to face computing difficulties.
Key takeaway
Genetic algorithm learning methods are based on models of natural adaption and evolution.
The genetic algorithm is a method of finding a good answer to a problem, based on the feedback received from its repeated attempts at a solution.
In most supervised machine learning algorithms, our main aim is to figure out a potential hypothesis from the hypothesis space that could potentially map out the inputs to the correct outputs.
The following figure shows the common method to find out the possible hypothesis from the Hypothesis space:
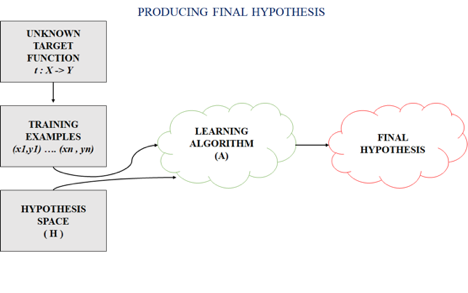
Fig 2: Hypothesis space
Hypothesis Space (H):
Hypothesis space is the set of all the possible legal hypothesis. This is the set from which the machine learning algorithm will decide the best possible (only one) which would best represent the target function or the outputs.
The hypothesis space that an ML system uses is the collection of all hypotheses that it can return. It's usually identified by a Hypothesis Language, which could be tied to a Language Bias.
Many machine learning algorithms rely on a search methodology: given a set of perceptions and a space of all possible hypotheses in the hypothesis space. They look in this area for hypotheses that appropriately provide data or are ideal in terms of some other quality criterion.
We surmised an anonymous objective function that can most reliably map inputs to outputs on all expected perceptions from the difficult domain, referred to as function estimate, in which we surmised an anonymous objective function that can most reliably map inputs to outputs on all expected perceptions from the difficult domain. Hypothesis testing in machine learning is an illustration of a model that approximates the mappings and goal function of inputs to outputs.
In machine learning, the hypothesis of all possible hypotheses that you are considering, with minimal regard for their structure. Because learning approaches often only work on one type at a time, the hypothesis class is usually required to be merely each form of function or model in turn for the sake of accommodation. However, this does not have to be the case:
● Hypothesis classes don't have to be made up of only one type of function. If you're seeking for exponential, quadratic, or overall linear functions, your connected hypothesis class is where you'll find them.
● Hypothesis classes also don't have to be made up entirely of simple functions. Those functions are what your hypothesis class contains if you figure out how to look over all piecewise-tanh2 functions.
The huge trade-off is that the larger your machine learning hypothesis class, the better the best hypothesis represents the underlying actual function, but the harder it is to find that best hypothesis. The bias-variance trade-off is a term used to describe this.
Hypothesis (h):
A hypothesis is a function that best describes the goal in supervised machine learning. The hypothesis that an algorithm will come up depends upon the data and also depends upon the constraints and prejudice that we have put on the data. To better understand the Hypothesis Space and Hypothesis consider the following coordinate that shows the distribution of some data:
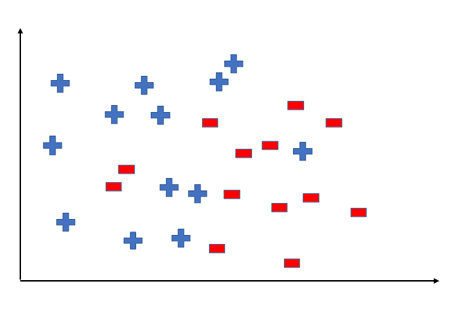
Fig 3: Distribution of data
In machine learning, a hypothesis function best describes the target. The hypothesis that an algorithm might create is based on the facts, as well as the bias and constraints that we have imposed on it.
In machine learning, the hypothesis formula is:
y= mx b
Where,
y is range
m changes in y divided by change in x
x is domain
b is intercept
The goal of constraining hypothesis space in machine learning is to ensure that it fits well with the general data that the user requires. It examines observations or inputs to see if they are accurate or if they are deceptive. As a result, it is incredibly useful, and it performs the valuable job of mapping all inputs till they are outputs. As a result, in ML, the target functions are analysed and restricted based on the outputs (regardless of whether or not they are free of bias).
The hypothesis space in machine learning and inductive bias in machine learning is a set of viable hypotheses. Hypothesis, for example, every single desirable function; on the other hand, a learning algorithm's inductive bias (also known as learning bias) is a set of expectations that the learner uses to predict outputs from unknown sources of input. Regression and classification are two types of analysis that use continuous and discrete values successively. Because we distinguish a function by inducting it on data, this type of issue (learning) is referred to as inductive learning challenges.
Enhancement adds a Bayesian probability framework to fitting model parameters to training data in the Maximum a Posteriori or MAP hypothesis in machine learning, while another choice and sibling may be a more traditional Maximum Likelihood Estimation system. Given the data, MAP learning selects a single in all probability theory. The previously mentioned hypothesis in machine learning is still used, and the technique is frequently more controllable than full Bayesian learning.
Key takeaway
Hypothesis space is the set of all the possible legal hypothesis.
In most supervised machine learning algorithms, our main aim is to figure out a potential hypothesis from the hypothesis space that could potentially map out the inputs to the correct outputs.
By replicating biological breeding and Darwinian evolution, genetic programming is an approach for creating algorithms that can programme themselves. Instead than programming a model to address a specific problem, genetic programming merely gives the model a broad goal and lets it figure out the details on its own. The main idea is to let the machine test several simple evolutionary algorithms automatically before "breeding" the most successful programmes into new generations.
While evolutionary and genetic algorithms use natural selection, crossover, mutations, and other reproduction methods, gene programming takes the process a step further by automatically developing new models and allowing the system to choose its own goals.
The entire procedure is currently under investigation. Quantifying the fitness function, or how much each new programme contributes to achieving the desired goal, is one of the major barriers to wider use of this genetic machine learning approach.
Genetic programming (GP) is an artificial intelligence technique for creating programmes suited for a specific job from a population of unfit (typically random) programmes by applying operations akin to natural genetic processes on the population of programmes. It's essentially a heuristic search strategy known as 'hill climbing,' which entails looking for an optimal or at least adequate programme in a space of all possible programmes.
Selection of the fittest programmes for reproduction (crossover) and mutation based on a preset fitness metric, typically proficiency at the target task, are the operations. The crossover procedure entails switching random bits of selected pairings (parents) in order to develop fresh and distinct offspring that become part of a new generation of programmes. Mutation is the process of replacing a random part of a programme with another random part of a programme. Some programmes that were not chosen for reproduction are transmitted from one generation to the next. The selection and other processes are then applied to the new generation of programmes in a recursive manner.
Members of each new generation are typically more fit than members of prior generations, and the best-of-generation programme is frequently better than previous generations' best-of-generation programmes. When an individual programme reaches a predetermined skill or fitness level, the recursion comes to an end.
A given run of the algorithm may, and frequently does, result in premature convergence to a local maximum, which is not a globally optimal or even decent solution. To get a satisfactory result, multiple runs (dozens to hundreds) are frequently required. To achieve a high-quality output, several runs (dozens to hundreds) are normally required. To avoid diseases, it may also be required to raise the starting population size and individual variability.
How to set up a Genetic program
A person must first describe a high-level definition of the problem through various preparatory stages in order to build up a basic genetic programme:
● Specify terminals – For example, independent variables of the problem, zero-argument functions, or random constants for each branch of program that will be go through evolution.
● Define initial “primitive” functions for each branch of the genetic program.
● Choose a fitness measure – this measures the fitness of individuals in the population to determine if they should reproduce.
● Any special performance parameters for controlling the run.
● Select termination criterion and methods for reaching the run’s goals.
The algorithm then runs automatically without the need for any training data.
Based on the basic functions and terminals given by the human, a random initial population (generation 0) of simple programmes will be constructed.
Each programme will be carried out and the results will be used to determine its fitness. The most effective or "fit" programmes will be breeding stock to produce a new generation, with some new population members being directly replicated (reproduction), some via crossover (randomly breeding pieces of the programmes), and others through random mutations. Unlike evolutionary programming, a new generation's framework is controlled by an additional architecture-altering procedure, analogous to a species.
These generations are repeated as needed until the termination requirement is met, at which point the best programme is chosen as the run's winner.
Key takeaway
Genetic programming (GP) is an artificial intelligence technique for creating programmes suited for a specific job from a population of unfit (typically random) programmes by applying operations akin to natural genetic processes on the population of programmes.
The collective behaviour of decentralised, self-organized systems, whether natural or artificial, is referred to as swarm intelligence (SI). The notion is used in artificial intelligence research. In 1989, Gerardo Beni and Jing Wang used the phrase in the context of cellular robotic systems.
SI systems are often made up of a population of simple agents or boids that interact with one another and their surroundings on a local level. Nature, particularly biological systems, is a frequent source of inspiration. Although there is no centralised control structure dictating how individual agents should behave, local, and to some extent random, interactions between such agents result in the creation of "intelligent" global behaviour, which is unknown to the individual agents. Ant colonies, bee colonies, bird flocking, hawk hunting, animal herding, bacterial growth, fish schooling, and microbial intelligence are all examples of swarm intelligence in natural systems.
Swarm robotics is the application of swarm concepts to robots, while swarm intelligence refers to a broader collection of algorithms. In the area of forecasting difficulties, swarm prediction has been applied. In synthetic collective intelligence, genetically engineered organisms are being studied for approaches similar to those proposed for swarm robots.
Applications
Techniques based on swarm intelligence can be applied in a variety of situations. The US military is looking at swarm control systems for unmanned vehicles. An orbital swarm for self-assembly and interferometry is being considered by the European Space Agency. NASA is looking into using swarm technology to map out the planets. M. Anthony Lewis and George A. Bekey wrote a study in 1992 about the idea of employing swarm intelligence to direct nanobots inside the body to eliminate cancer tumours. Al-Rifaie and Aber, on the other hand, used stochastic diffusion search to find tumours. Data mining and cluster analysis have also used swarm intelligence. Modern management theory also includes ant-based models.
Ant based routing
In the form of ant-based routing, the use of swarm intelligence in telecommunication networks has also been investigated. Dorigo et al. And Hewlett Packard both pioneered this in the mid-1990s, and there are several variations. Essentially, each "ant" (a small control packet) that floods the network is rewarded/reinforced for successfully traversing a route using a probabilistic routing table. Reinforcement of the route in the forward, reverse, and both directions at the same time has been studied: backwards reinforcement necessitates a symmetric network that connects the two directions; forwards reinforcement rewards a path before the outcome is known (but then one would pay for the cinema before one knows how good the film is). There are significant barriers to commercial adoption because the system behaves stochastically and so lacks repeatability. Due to swarm intelligence, mobile media and new technologies have the ability to modify the threshold for collective action.
The location of wireless communication network transmission infrastructure is a complex engineering problem with competing goals. Only a small number of locations (or sites) are necessary to provide appropriate coverage for users. Stochastic diffusion search (SDS), a swarm intelligence technique inspired by ants, has been successfully employed to provide a general model for this problem, which is related to circle packing and set covering. It has been demonstrated that the SDS can be used to find appropriate solutions even for huge problems.
Ant-based routing has also been utilised by airlines to assign aircraft arrivals to airport gates. A software tool at Southwest Airlines employs swarm theory, or swarm intelligence—the premise that a colony of ants performs better than a single ant. Each pilot behaves as if he or she is an ant looking for the best airport gate. "The pilot learns what's best for him from his experience, and it turns out that's the greatest option for the airline," Douglas A. Lawson explains. As a result, the "colony" of pilots always chooses gates that are easy to get to and leave from. The computer can even warn a pilot ahead of time if there will be a plane back-up. "We know it'll happen," Lawson says, "so we'll have a gate ready."
Crowd simulation
Swarm technology is being used by artists to create complicated interactive systems and to simulate crowds.
Instances
During fight scenes in the Lord of the Rings film trilogy, a comparable technology known as Massive (software) was used. Swarm technology is particularly appealing due to its low cost, robustness, and simplicity.
The first movie to use swarm technology for rendering was Breaking the Ice, which used the Boids system to realistically show the movements of groups of fish and birds.
Human swarming
Networks of scattered users can be organised into "human swarms" by the implementation of real-time closed-loop control systems, thanks to mediating software like Unanimous A.I.'s SWARM platform (formerly unu). According to Rosenberg (2015), real-time systems enable groups of human participants to act as a cohesive collective intelligence that makes predictions, answers queries, and elicits opinions as a single entity.
Such systems, also known as "Artificial Swarm Intellect" (or Swarm AI), have been shown to greatly enhance human intelligence, resulting in a series of high-profile predictions with extraordinary accuracy. Human swarms can out predict people in a range of real-world scenarios, according to academic research. In response to a challenge from media, human swarming was famously employed to correctly predict the Kentucky Derby Superfecta against 541 to 1 odds.
Human Swarming in Medicine—studies published in 2018 by Stanford University School of Medicine and Unanimous AI showed that groups of human doctors, when connected by real-time swarming algorithms, could diagnose medical conditions with significantly higher accuracy than individual doctors or groups of doctors using traditional crowd-sourcing methods.
In one study, swarms of human radiologists were charged with diagnosing chest x-rays and showed a 33 percent reduction in diagnostic errors when compared to traditional human methods and a 22 percent improvement over traditional machine-learning. The University of California San Francisco (UCSF) School of Medicine published a study in 2021 that used the SWARM platform for small groups of collaborating doctors to diagnose MRI scans. When compared to a majority vote, the study found that applying Artificial Swarm Intelligence (ASI) technology improved diagnostic accuracy by 23%.
Swarm grammars
Swarm grammars are a collection of stochastic grammars that may be used to explain complicated features like those seen in art and architecture. These grammars interact as swarm intelligence agents who follow swarm intelligence rules. When the translation of such swarms to neural circuits is examined, such behaviour can also suggest deep learning techniques.
Swarmic art
Al-Rifaie et al. Have successfully combined two swarm intelligence algorithms—one that mimics the foraging behaviour of one species of ants (Leptothorax acervorum) and the other that mimics the flocking behaviour of birds (particle swarm optimization, PSO)—to describe a novel integration strategy that exploits the local search properties of the PSO with global SDS behaviour.
The resulting hybrid algorithm is used to sketch new drawings of an input image, taking advantage of an artistic tension between the local behaviour of the "birds flocking"—as they try to follow the input sketch—and the global behaviour of the "ants foraging"—as they try to encourage the flock to explore new regions of the canvas. In the framework of Deleuze's "Orchid and Wasp" metaphor, the "creativity" of this hybrid swarm system has been examined through the philosophical lens of the "rhizome."
"Swarmic Sketches and Attention Mechanism," by al-Rifaie et al.,[74], provides a novel technique to deploying the mechanism of "attention" by using SDS to selectively attend to precise parts of a digital canvas. When the swarm's attention is brought to a specific line on the canvas, PSO's capability is employed to create a swarm sketch of the attended line.
The swarms swarm over the digital canvas, attempting to fulfil their dynamic roles—paying attention to places with more details—assigned to them by their fitness function. The performance of the participating swarms creates a unique, non-identical sketch each time the 'artist' swarms begin analysing the input line drawings after associating the rendering process with the ideas of attention. In other works, PSO is in charge of the drawing process, whereas SDS is in charge of the swarm's attention.
Key takeaway
SI systems are often made up of a population of simple agents or boids that interact with one another and their surroundings on a local level. Nature, particularly biological systems, is a frequent source of inspiration.
References:
- Tom Mitchell. Machine Learning (McGraw Hill)
- Understanding Machine Learning. Shai Shalev-Shwartz and Shai Ben-David. Cambridge University Press.
- Artificial Neural Network, B. Yegnanarayana, PHI, 2005




