Unit – 2
Relational data Model and Language
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Data models are used to describe the design of a database at the logical level.
Some of the data models are: -
1. Entity-Relationship Model
2. Relational Model
3. Hierarchical Model
4. Network Model
5. Object Relational Model
Entity-Relationship(E-R) Model:
● The logical structure of a database can be expressed by an E-R diagram.
● Relationships are defined in this database model by dividing the object of interest into an entity and its characteristics into attributes.
● Using relationships, various entities are related.
● To make it easier for various stakeholders to understand, E-R models are established to represent relationships in pictorial form.
The Main Components of ER Diagram are:
a) Rectangles - Entity Sets
b) Ellipses - Attributes
c) Diamond - Relation among entity sets
d) Lines - Connects attributes to entity sets and entity sets to relationships.
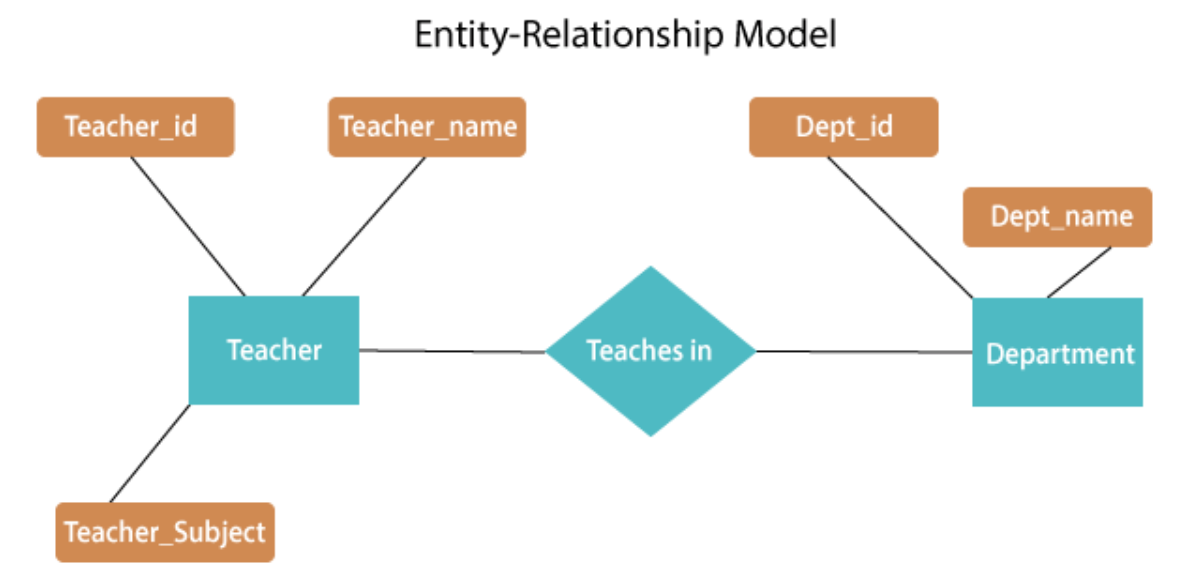
Fig 1: E - R diagram
The above E-R diagram has two entities: Teacher and Department
Teacher entity has three attributes:
Teacher_id
Teacher_name
Teacher_Subject
Department entity has two attributes:-
Dept_id
Dept_name
Relation Teaches in gives relationship between Teacher, Department .
Relationship can be of the type:
1:1→One to one
1:M →One to many
M:1 →Many to one
M:M →Many to many
Relational Model:
● Relational model uses a collection of tables to represent both data and the relationships among those data.
● This model is useful for constructing a database that can then be converted into relational model tables.
● Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
● In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
- Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
B. Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
C. Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Hierarchical Model:
● This model of the database organises information into a tree-like structure with a single root to which all the other information is connected. The hierarchy begins from the root data and extends to the parent nodes like a tree, adding child nodes.
● A child node can only have a single parent node in this model.
● A Hierarchical model uses tree structure to represent relationships among entities.
● This model represents many real-world relationships effectively, such as a book index, recipes, etc.
● Data is structured into a tree-like structure in the hierarchical model with a one-to-many relationship between two different data forms.
For instance, one department can have many classes, many professors and many students of course.
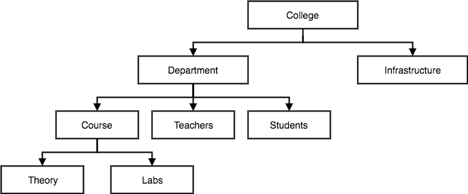
Fig 2: Hierarchical model
Network Model:
● Network model uses two different data structures:
a) A record type is used to represent an entity set.
b) A set type is used to represent a directed relationship between two record types.
● This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
● Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
● This was the most commonly used database architecture prior to the advent of the Relational Model.
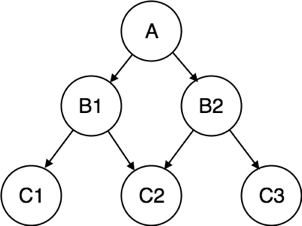
Fig 3: Network model
Object Relational Model:
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
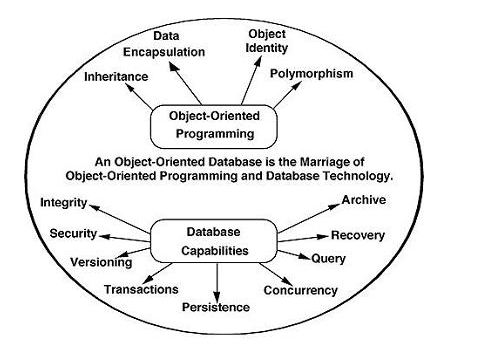
Fig 4: Object - oriented model
Object-oriented databases use small, recyclable separated of software
Called objects. The objects themselves are stored in the object-oriented
Database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with
The data.
There are two types of ORM:
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types, operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Key takeaway:
- The logical structure of a database can be expressed by an E-R diagram.
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- A Hierarchical model uses tree structure to represent relationships among entities.
- Network model is the Hierarchical model's extension
Constraints on honesty are a set of rules. It is used to maintain information quality.
Integrity constraints ensure that it is important to perform data insertion, updating, and other procedures in such a way that data integrity is not compromised.
Therefore, to protect against unintended damage to the database, integrity constraints are used.
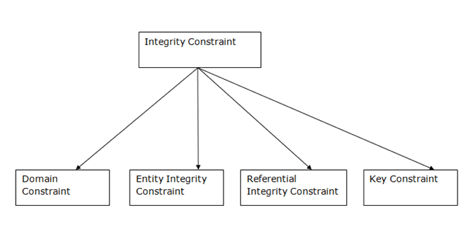
Fig 5: Types of integrity constraints
Domain Constraints
● As a description of a valid set of values for an attribute, domain constraints can be specified.
● The domain data type consists of a string, character, integer, time, date, currency, etc. In the corresponding domain, the value of the attribute must be available.
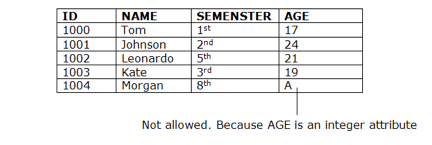
Fig 6: Example of domain constraints
Entity Integrity Constraints
● The honesty restriction of the organization states that the primary key value should not be zero.
● This is because the primary key value is used to define the relationship between individual rows, and if the primary key has a null value, then those rows cannot be identified.
● A table may contain a null value other than the field for the primary key.
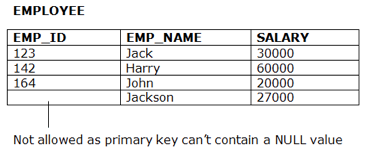
Fig 7: Example of entity constraints
Referential Constraints
● Between two relations or tables, the referential integrity constraints are defined and used to preserve the consistency between the tuples in two relationships.
● If an attribute of the foreign key of the relationship R1 has the same domain(s) as the primary key of the relationship R2, then the foreign key of R1 is said to refer to or refer to the primary key of the relationship R2.
● Foreign key values in the R1 relationship tuple can either take the primary key values for a certain R2 relationship tuple, or they can take NULL values, but cannot be zero.
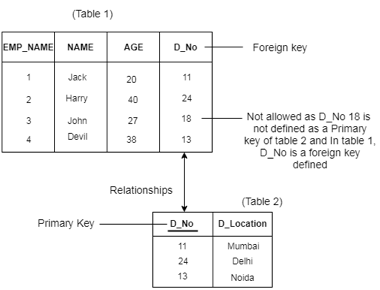
Fig 8: Example of integrity constraints
Key Constraints
● Keys are the collection of entities used to uniquely define an object within its entity set.
● A group of entities may have several keys, but the primary key will be one key. A primary key may contain in the relational table a unique and null value.
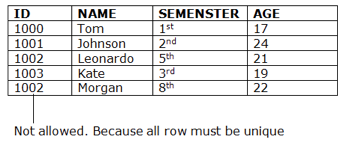
Fig 9: Example of key constraints
Key takeaway:
- Constraints on honesty are a set of rules.
- It is used to maintain information quality.
- The domain data type consists of a string, character, integer, time, date, currency.
- Between two relations or tables, the referential integrity constraints are defined.
- Keys are the collection of entities used to uniquely define an object within its entity set.
Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R :
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
● Theta join
● EQUI join
● Natural join
Outer join:
● Left Outer Join
● Right Outer Join
● Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8.Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Key takeaway:
- Relational Algebra is procedural query language.
- It takes Relation as input and generates relation as output.
- Data stored in a database can be retrieved using a query.
Tuple Relational Calculus (TRC)
● To select the tuples in a relationship, the tuple relational calculus is defined. The filtering variable in TRC uses relationship tuples.
● You may have one or more tuples as a consequence of the partnership.
Notation: {T | P (T)} or {T | Condition (T)}
Where,
T - resulting tuple
P (T) - condition used to fetch T.
Example 1:
{ T.name | Author(T) AND T.article = 'database' }
Output :
Select tuples from the AUTHOR relationship in this question. It returns a 'name' tuple from the author who wrote a 'database' post.
TRC (tuple relational calculus) can be quantified. We may use existential (∃) and universal quantifiers (∀) in TRC.
Example 2:
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Output : This question is going to generate the same result as the previous one.
Domain Relational Calculus
● Domain relational calculus is known as the second type of relationship. The filtering variable uses the domain attributes in the domain relational calculus.
● The same operators as the tuple calculus are used in domain relational calculus. It utilises logical relations ∧ (and), ∨ (or) and ┓ (not).
● To connect the variable, it uses Existential (∃) and Universal Quantifiers (∀).
Notation:
{ a1, a2, a3, ..., an | P (a1, a2, a3, ... ,an)}
Where,
a1,a2 - attributes
P - formula built by inner attributes
Example
{< article, page, subject > | ∈ CSE ∧ subject = 'database'}
Output: This query will result from the relational CSE, where the topic is a database, to the post, page, and subject.
Key takeaway:
- To select the tuples in a relationship, the tuple relational calculus is defined.
- Domain relational calculus is known as the second type of relationship.
Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database. SQL comes in different versions and forms. All of these versions are based upon the ANSI SQL.
Currently, MySQL is the most common programme for database management systems used for relational database management. It is an open-source, Oracle Company - supported database programme. In comparison to Microsoft SQL Server and Oracle Database, the database management system is fast, scalable, and easy to use. It is widely used for building efficient and interactive server-side or web-based business applications in combination with PHP scripts.
Characteristics of SQL
● It is quick to learn SQL.
● For accessing data from relational database management systems, SQL is used.
● SQL will perform database queries against it.
● To describe data, SQL is used.
● SQL is used in the database to describe the data and manipulate it when appropriate.
● To build and drop the database and the table, SQL is used.
● SQL is used in a database to construct a view, a stored procedure, a function.
● SQL allows users to set tables, procedures, and display permissions.
Advantages of SQL
● SQL is easy to learn and use.
● SQL is a non-procedural language. It means we have to specify only what to retrieve and not the procedure for retrieving data.
● SQL can be embedded within other languages using SQL modules, pre-compilers.
● Allows creating procedure, functions, and views using PL-SQL.
● Allows users to drop databases, tables, views, procedure and cursors.
● Allows users to set access permissions on tables, views and procedures.
SQL data types
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
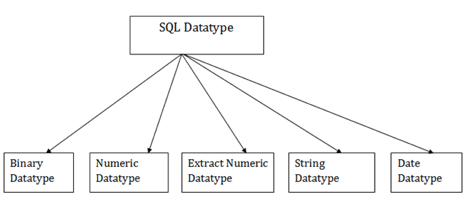
Fig 10: SQL data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Literals
Literals are notes or the concept of representing/expressing a meaning that does not change. Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
We will explain the various forms of literal statements in this section and how they can be used in MySQL statements.
The following are the literal forms:
S.no |
Literal type & example |
1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
Key takeaway:
- MySQL is the most common programme for database management systems used for relational database management.
- Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database.
- SQL comes in different versions and forms.
- Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
- Literals are notes or the concept of representing/expressing a meaning that does not change
The Structured Query Language (SQL), as we all know, is a database language that allows one to perform certain operations on existing databases as well as build new databases. To complete the tasks, SQL employs commands such as Create, Drop, and Insert.
These SQL commands are primarily divided into four groups:
● DDL (Data Definition Language)
● DML (Data Manipulation Language)
● DQL (Data Query Language)
● DCL (Data Control Language)
● TCL (Transactional control commands)
DDL:
DDL stands for Data Definition Language, and it is a part of SQL that allows a database user to build and restructure database objects, such as tables.
The following are some of the most basic DDL commands that will be addressed in the coming hours:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
ALTER INDEX
DROP INDEX
CREATE VIEW
DROP VIEW
DML:
DML, or Data Manipulation Language, is a part of SQL that allows you to manipulate data within relational database objects.
DML commands are divided into three categories:
INSERT
UPDATE
DELETE
DQL:
Data Query Language (DQL) is the most focused subject of SQL for modern relational database users, despite having only one instruction.
The following is the base command:
SELECT
A query is a request for information from a database. A query to the database is normally sent to it through an application interface or a command line prompt.
DCL:
In SQL, you can use data control commands to limit who has access to data in the database. These DCL commands are typically used to build objects related to user access and to manage privilege distribution among users.
The following are some data access commands:
ALTER PASSWORD
GRANT
REVOKE
CREATE SYNONYM
TCL:
Only DML commands like INSERT, DELETE, and UPDATE can be used with TCL commands. Since these operations are automatically committed to the database, they can't be used to create or drop tables.
Here are some examples of TCL commands:
COMMIT Saves database transactions
ROLLBACK Undoes database transactions
SAVEPOINT Creates points within groups of transactions in which to ROLLBACK
SET TRANSACTION Places a name on a transaction
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations. These Operators are used to define conditions in SQL statements and to function as conjunctions for multiple conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
● Operators used to negate conditions
Arithmetic operator
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
+ (Addition) | Values are added to both sides of the operator. | a + b will give 30 |
- (Subtraction) | Takes the right hand operand and subtracts it from the left hand operand. | a - b will give -10 |
* (Multiplication) | Values on both sides of the operator are multiplied. | a * b will give 200 |
/ (Division) | Divides the left and right hand operands. | b / a will give 2 |
% (Modulus) | Returns the remainder after dividing the left hand operand by the right hand operand. | b % a will give 0 |
Comparison operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
= | Checks if the values of two operands are equal, and if they are, the condition is valid. | (a = b) is not true. |
!= | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a != b) is true. |
<> | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is valid. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is valid. | (a < b) is true. |
>= | If the left operand's value is greater than or equal to the right operand's value, then the condition is valid. | (a >= b) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is valid. | (a <= b) is true. |
!< | If the value of the left operand is greater than the value of the right operand, the condition is valid. | (a !< b) is false. |
!> | If the value of the left operand is less than the value of the right operand, then the condition is valid. | (a !> b) is true. |
Logical operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Sr.No | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows multiple conditions to occur in the WHERE clause of a SQL statement. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the condition. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a given table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been defined, the IN operator is used. |
7 | LIKE The LIKE operator compares a value to other values that are identical using wildcard operators. |
8 | NOT The NOT operator flips the definition of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL statement to combine several conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is used. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
A SQL Table is a list of data that has been arranged into rows and columns. The table is referred to as a relation, and the row is referred to as a tuple in relational databases.
A table is a basic data storage format. A table may also be thought of as a simple way to portray relationships.
Example: Employee table
EMP_NAME | ADDRESS | SALARY |
Ankit | Lucknow | 15000 |
Raman | Allahabad | 18000 |
Mike | New York
| 20000 |
The table name is "Employee," and the column names are "EMP NAME," "ADDRESS," and "SALARY." A row is formed by the combination of data from multiple columns, such as "Ankit," "Lucknow," and 15000.
Operation on table:
- Create table
- Drop table
- Delete table
- Rename table
Create Table:
To create a table in the database, use SQL create table. To define the table, you must first define the table's name, as well as the table's columns and data types.
Syntax:
Create table "table_name"
("column1" "data type",
"column2" "data type",
"column3" "data type",
...
"columnN" "data type");
Drop Table
A SQL drop table is used to remove a table's description as well as all of its results. When this command is run, all of the data in the table is permanently lost, so be cautious when using it.
Syntax:
DROP TABLE "table_name";
Delete Table:
To delete rows from a table in SQL, use the DELETE expression. To delete a particular row from a table, we can use the WHERE condition. You don't need to use the WHERE clause if you want to remove all the records from the table.
Syntax:
DELETE FROM table_name WHERE condition;
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
A MySQL subquery is a query nested within another query such as select, insert, update or delete. In addition, a MySQL subquery can be nested inside another subquery.
A MySQL subquery is called an inner query while the query that contains the subquery is called an outer query. A subquery can be used anywhere that expression is used and must be closed in parentheses.
A subquery is also known as a nested query. It is a SELECT query embedded within the WHERE or HAVING clause of another SQL query. The data returned by the subquery is used by the outer statement in the same way a literal value would be used.
Subqueries provide an easy and efficient way to handle the queries that depend on the results from another query. They are almost identical to the normal SELECT statements, but there are few restrictions.
The most important ones are listed below:
● A subquery must always appear within parentheses.
● A subquery must return only one column. This means you cannot use SELECT * in a subquery unless the table you are referring to has only one column. You may use a subquery that returns multiple columns, if the purpose is row comparison.
● You can only use subqueries that return more than one row with multiple value operators, such as the IN or NOT IN operator.
● A subquery cannot be a UNION. Only a single SELECT statement is allowed.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the
Result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who have placed orders worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- MySQL subquery can be nested inside another subquery.
- A subquery is also known as a nested query.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
The data that you need is not always stored in the tables. However, you can get it by
Performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from
The order details table because the order details table stores only the quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
- AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
2. MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
3. MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
4. TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
5. MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Insert
The syntax for the insertion of a new record into a table is quite simple:
INSERT INTO table_name (field1, field2, ...)
VALUES (value1, value2, ...);
Where
● field1 and field2 are fields from table_name.
● Values 1 and 2 are the values for fields 1 and 2, respectively. SQL allows you the flexibility to list the fields in the order you want, as long as the corresponding values are defined accordingly. The following code is thus identical to the question above:
INSERT INTO table_name (field2, field1, ...)
VALUES (value2, value1, ...);
A variant of INSERT makes it possible to insert many comma-separated records at once, as follows:
INSERT INTO table_name (field1, field2, ...)
VALUES (value3, value4, ...),
(value5, value6, ...),
(value7, value8, ...);
Update
To change the data that is already in the database, the SQL UPDATE statement is used. In the WHERE clause, the condition determines which row is to be changed.
Syntax
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Updating single record
Adjust the EMP NAME column and set the value in the row where SALARY is 500000 to 'Emma'.
Syntax
UPDATE table_name
SET column_name = value
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Emma'
WHERE SALARY = 500000;
Updating multiple record
You can divide each field allocated by a comma if you want to update several columns. Adjust the EMP NAME column to 'Kevin' in the EMPLOYEE table, and CITY to 'Boston' where the EMP ID is 5.
Syntax
UPDATE table_name
SET column_name = value1, column_name2 = value2
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Kevin', City = 'Boston'
WHERE EMP_ID = 5;
Delete
To delete rows from a table, the SQL DELETE statement is used. The DELETE statement usually removes one or more records from a table.
Syntax
DELETE FROM table_name WHERE some_condition;
Deleting single record
Remove the EMPLOYEE table row, where EMP NAME = 'Kristen'. Just the fourth row will be omitted here.
Syntax
DELETE FROM EMPLOYEE
WHERE EMP_NAME = 'Kristen';
Deleting multiple record
Remove the row where AGE is 30 from the EMPLOYEE table. Two rows will be deleted by this (first and third row).
Syntax
DELETE FROM EMPLOYEE WHERE AGE= 30;
JOIN, as the name implies, is a word that means "to combine." In SQL, JOIN means "to join two or more tables together."
The JOIN clause in SQL is used to join records from two or more database tables.
Broadly, there are four types of methods for joining:
● INNER JOIN
● LEFT JOIN
● RIGHT JOIN
● FULL JOIN
Inner Join
INNER JOIN selects records in both tables that have matching values as long as the condition is met in SQL. It returns a set of all rows from both tables that satisfy the condition.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
INNER JOIN table2
ON table1.matching_column = table2.matching_column;
Left Join
The SQL left join returns all of the values from the left table as well as the values from the right table that match. It will return NULL if there is no matching join value.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
LEFT JOIN table2
ON table1.matching_column = table2.matching_column;
Right Join
RIGHT JOIN returns all the values from the rows of the right table as well as the matched values from the left table in SQL. It will return NULL if there is no match in both tables.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
RIGHT JOIN table2
ON table1.matching_column = table2.matching_column;
Full Join
A FULL JOIN in SQL is the product of combining left and right outer joins. The records from both tables are combined in the join tables. It places a NULL in the position of any matches that were not identified.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
FULL JOIN table2
ON table1.matching_column = table2.matching_column;
Key takeaway:
- There are numerous joining techniques between two tables to perform.
Unions
To combine the effects of two or more SELECT statements, use UNION. It can, however, remove redundant rows from the result set. In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
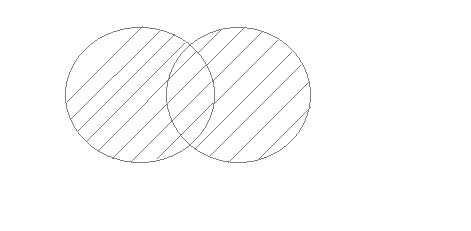
Fig 11: Unions
Example:
First table
ID | Name |
1 | Sam |
2 | Abhi |
Second table
ID | Name |
2 | Abhi |
3 | Bhu |
Query will be: SELECT * FROM First
UNION
SELECT * FROM Second;
ID | Name |
1 | Sam |
2 | Abhi |
3 | Bhu |
Intersection
The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both. The number of columns and datatype must be the same when using Intersect.
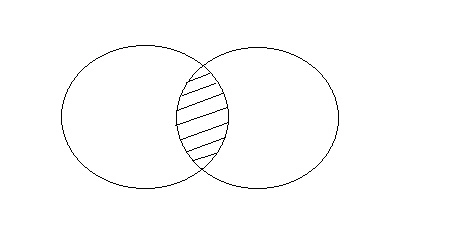
Fig 12: Intersection
Consider the above two tables.
Query will be: SELECT * FROM First
INTERSECT
SELECT * FROM Second;
ID | Name |
2 | Abhi |
Minus
The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
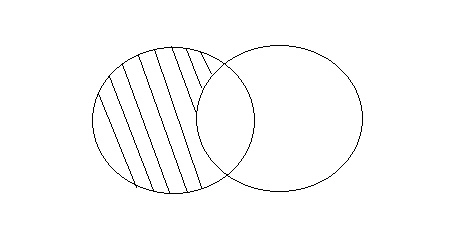
Fig 13: Minus
Consider the above two tables,
Query will be: SELECT * FROM First
MINUS
SELECT * FROM Second;
ID | Name |
1 | Sam |
Cursors
A cursor is a form of temporary memory or workstation. It is allocated by the database server when a user performs DML operations on a table. Database Tables are stored in cursors.
Implicit and explicit cursors are the two types of cursors. These are clarified in the following paragraphs.
Implicit cursors: Implicit cursors are also known as SQL SERVER's Default Cursors. When a user performs DML operations, SQL SERVER allocates these cursors.
Explicit cursors: When a user needs an explicit cursor, the user creates it. For fetching data from a table in a row-by-row manner, explicit cursors are used.
Key takeaway:
- In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
- The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both.
- The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
- A cursor is a form of temporary memory or workstation.
A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database. For instance, when a row is inserted into a specified table or when certain table columns are being modified, a trigger can be invoked.
In fact, triggers are written for execution in response to any of the following events.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
You may identify triggers for the table, display, schema, or database that the event is associated with.
Benefits of Triggers
● Generating some derived column values automatically
● Enforcing referential integrity
● Event logging and storing information on table access
● Auditing
● Synchronous replication of tables
● Imposing security authorizations
● Preventing invalid transactions
Syntax
Create trigger [trigger_name]
[before | after]
{insert | update | delete}
On [table_name]
[for each row]
[trigger_body]
Key takeaway:
- A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database.
A procedure is a PL/SQL block that performs one or more specific tasks. Procedures in other programming languages are analogous to this.
A header and a body appear in the procedure.
Header: The procedure's name and the parameters or variables passed to the procedure are both listed in the header.
Body: Similar to a general PL/SQL block, the body has a declaration, execution, and exception section.
How to pass parameters in procedure:
When you want to create a procedure or function, you have to define parameters. There is three ways to pass parameters in procedure:
IN parameters: The IN parameter can be referenced by the procedure or function. The value of the parameter cannot be overwritten by the procedure or the function.
OUT parameters: The OUT parameter cannot be referenced by the procedure or function, but the value of the parameter can be overwritten by the procedure or function.
INOUT parameters: The INOUT parameter can be referenced by the procedure or function and the value of the parameter can be overwritten by the procedure or function.
PL/SQL Create Procedure
Syntax:
CREATE [OR REPLACE] PROCEDURE procedure_name
[ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_name];
PL/SQL Drop Procedure
Syntax:
DROP PROCEDURE procedure_name;
Key takeaway:
- A procedure is a PL/SQL block that performs one or more specific tasks.
- Procedures in other programming languages are analogous to this.
References:
- RAMAKRISHNAN "Database Management Systems", McGraw Hill
2. Leon & Leon, “Database Management Systems”, Vikas Publishing House
3. Bipin C. Desai, “An Introduction to Database Systems”, Gagotia Publications
4. Majumdar & Bhattacharya, “Database Management System”, TMH
5. https://www.javatpoint.com
Unit – 2
Relational data Model and Language
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Data models are used to describe the design of a database at the logical level.
Some of the data models are: -
1. Entity-Relationship Model
2. Relational Model
3. Hierarchical Model
4. Network Model
5. Object Relational Model
Entity-Relationship(E-R) Model:
● The logical structure of a database can be expressed by an E-R diagram.
● Relationships are defined in this database model by dividing the object of interest into an entity and its characteristics into attributes.
● Using relationships, various entities are related.
● To make it easier for various stakeholders to understand, E-R models are established to represent relationships in pictorial form.
The Main Components of ER Diagram are:
a) Rectangles - Entity Sets
b) Ellipses - Attributes
c) Diamond - Relation among entity sets
d) Lines - Connects attributes to entity sets and entity sets to relationships.
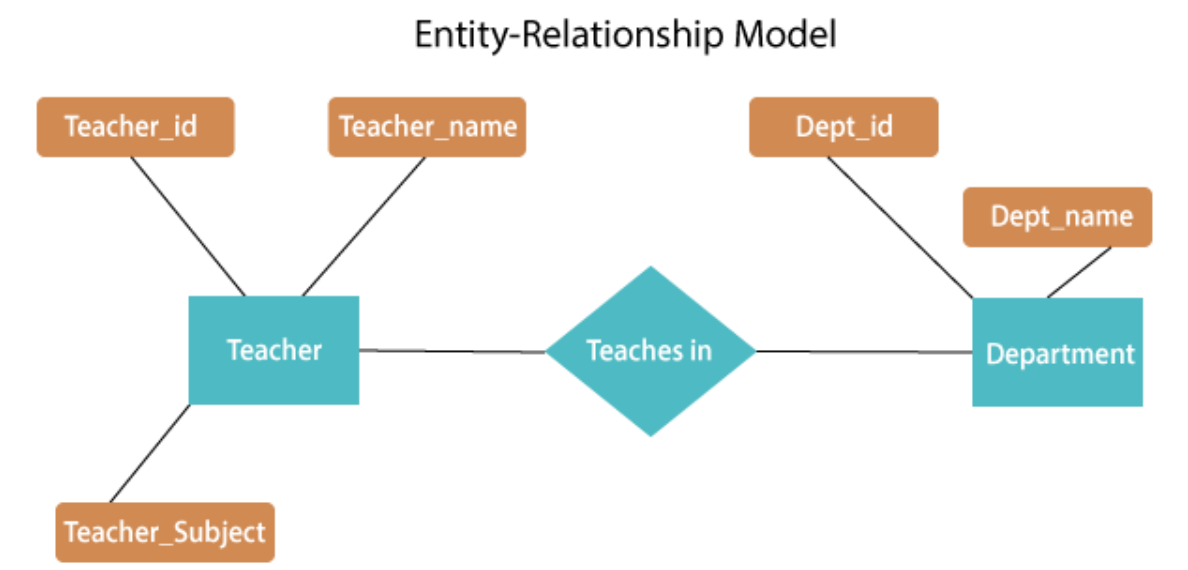
Fig 1: E - R diagram
The above E-R diagram has two entities: Teacher and Department
Teacher entity has three attributes:
Teacher_id
Teacher_name
Teacher_Subject
Department entity has two attributes:-
Dept_id
Dept_name
Relation Teaches in gives relationship between Teacher, Department .
Relationship can be of the type:
1:1→One to one
1:M →One to many
M:1 →Many to one
M:M →Many to many
Relational Model:
● Relational model uses a collection of tables to represent both data and the relationships among those data.
● This model is useful for constructing a database that can then be converted into relational model tables.
● Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
● In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
- Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
B. Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
C. Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Hierarchical Model:
● This model of the database organises information into a tree-like structure with a single root to which all the other information is connected. The hierarchy begins from the root data and extends to the parent nodes like a tree, adding child nodes.
● A child node can only have a single parent node in this model.
● A Hierarchical model uses tree structure to represent relationships among entities.
● This model represents many real-world relationships effectively, such as a book index, recipes, etc.
● Data is structured into a tree-like structure in the hierarchical model with a one-to-many relationship between two different data forms.
For instance, one department can have many classes, many professors and many students of course.
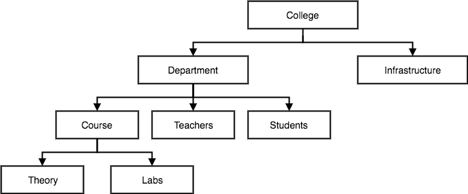
Fig 2: Hierarchical model
Network Model:
● Network model uses two different data structures:
a) A record type is used to represent an entity set.
b) A set type is used to represent a directed relationship between two record types.
● This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
● Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
● This was the most commonly used database architecture prior to the advent of the Relational Model.
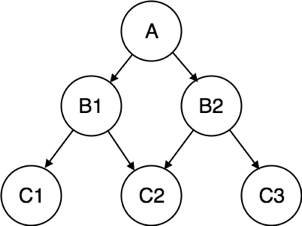
Fig 3: Network model
Object Relational Model:
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
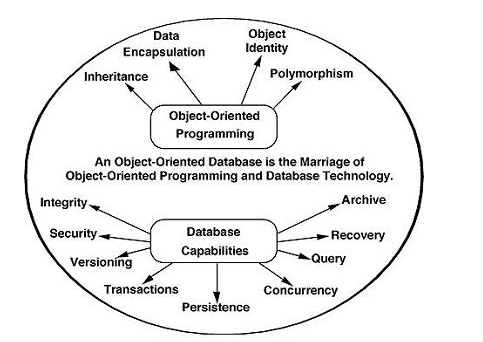
Fig 4: Object - oriented model
Object-oriented databases use small, recyclable separated of software
Called objects. The objects themselves are stored in the object-oriented
Database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with
The data.
There are two types of ORM:
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types, operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Key takeaway:
- The logical structure of a database can be expressed by an E-R diagram.
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- A Hierarchical model uses tree structure to represent relationships among entities.
- Network model is the Hierarchical model's extension
Constraints on honesty are a set of rules. It is used to maintain information quality.
Integrity constraints ensure that it is important to perform data insertion, updating, and other procedures in such a way that data integrity is not compromised.
Therefore, to protect against unintended damage to the database, integrity constraints are used.
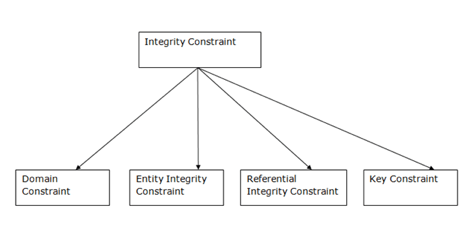
Fig 5: Types of integrity constraints
Domain Constraints
● As a description of a valid set of values for an attribute, domain constraints can be specified.
● The domain data type consists of a string, character, integer, time, date, currency, etc. In the corresponding domain, the value of the attribute must be available.
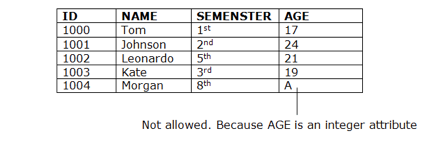
Fig 6: Example of domain constraints
Entity Integrity Constraints
● The honesty restriction of the organization states that the primary key value should not be zero.
● This is because the primary key value is used to define the relationship between individual rows, and if the primary key has a null value, then those rows cannot be identified.
● A table may contain a null value other than the field for the primary key.
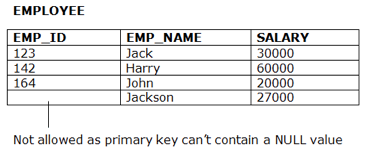
Fig 7: Example of entity constraints
Referential Constraints
● Between two relations or tables, the referential integrity constraints are defined and used to preserve the consistency between the tuples in two relationships.
● If an attribute of the foreign key of the relationship R1 has the same domain(s) as the primary key of the relationship R2, then the foreign key of R1 is said to refer to or refer to the primary key of the relationship R2.
● Foreign key values in the R1 relationship tuple can either take the primary key values for a certain R2 relationship tuple, or they can take NULL values, but cannot be zero.
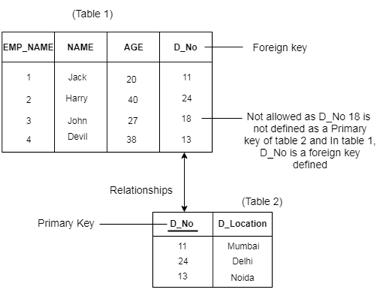
Fig 8: Example of integrity constraints
Key Constraints
● Keys are the collection of entities used to uniquely define an object within its entity set.
● A group of entities may have several keys, but the primary key will be one key. A primary key may contain in the relational table a unique and null value.
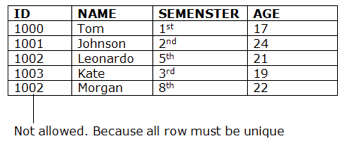
Fig 9: Example of key constraints
Key takeaway:
- Constraints on honesty are a set of rules.
- It is used to maintain information quality.
- The domain data type consists of a string, character, integer, time, date, currency.
- Between two relations or tables, the referential integrity constraints are defined.
- Keys are the collection of entities used to uniquely define an object within its entity set.
Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R :
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
● Theta join
● EQUI join
● Natural join
Outer join:
● Left Outer Join
● Right Outer Join
● Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8.Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Key takeaway:
- Relational Algebra is procedural query language.
- It takes Relation as input and generates relation as output.
- Data stored in a database can be retrieved using a query.
Tuple Relational Calculus (TRC)
● To select the tuples in a relationship, the tuple relational calculus is defined. The filtering variable in TRC uses relationship tuples.
● You may have one or more tuples as a consequence of the partnership.
Notation: {T | P (T)} or {T | Condition (T)}
Where,
T - resulting tuple
P (T) - condition used to fetch T.
Example 1:
{ T.name | Author(T) AND T.article = 'database' }
Output :
Select tuples from the AUTHOR relationship in this question. It returns a 'name' tuple from the author who wrote a 'database' post.
TRC (tuple relational calculus) can be quantified. We may use existential (∃) and universal quantifiers (∀) in TRC.
Example 2:
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Output : This question is going to generate the same result as the previous one.
Domain Relational Calculus
● Domain relational calculus is known as the second type of relationship. The filtering variable uses the domain attributes in the domain relational calculus.
● The same operators as the tuple calculus are used in domain relational calculus. It utilises logical relations ∧ (and), ∨ (or) and ┓ (not).
● To connect the variable, it uses Existential (∃) and Universal Quantifiers (∀).
Notation:
{ a1, a2, a3, ..., an | P (a1, a2, a3, ... ,an)}
Where,
a1,a2 - attributes
P - formula built by inner attributes
Example
{< article, page, subject > | ∈ CSE ∧ subject = 'database'}
Output: This query will result from the relational CSE, where the topic is a database, to the post, page, and subject.
Key takeaway:
- To select the tuples in a relationship, the tuple relational calculus is defined.
- Domain relational calculus is known as the second type of relationship.
Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database. SQL comes in different versions and forms. All of these versions are based upon the ANSI SQL.
Currently, MySQL is the most common programme for database management systems used for relational database management. It is an open-source, Oracle Company - supported database programme. In comparison to Microsoft SQL Server and Oracle Database, the database management system is fast, scalable, and easy to use. It is widely used for building efficient and interactive server-side or web-based business applications in combination with PHP scripts.
Characteristics of SQL
● It is quick to learn SQL.
● For accessing data from relational database management systems, SQL is used.
● SQL will perform database queries against it.
● To describe data, SQL is used.
● SQL is used in the database to describe the data and manipulate it when appropriate.
● To build and drop the database and the table, SQL is used.
● SQL is used in a database to construct a view, a stored procedure, a function.
● SQL allows users to set tables, procedures, and display permissions.
Advantages of SQL
● SQL is easy to learn and use.
● SQL is a non-procedural language. It means we have to specify only what to retrieve and not the procedure for retrieving data.
● SQL can be embedded within other languages using SQL modules, pre-compilers.
● Allows creating procedure, functions, and views using PL-SQL.
● Allows users to drop databases, tables, views, procedure and cursors.
● Allows users to set access permissions on tables, views and procedures.
SQL data types
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
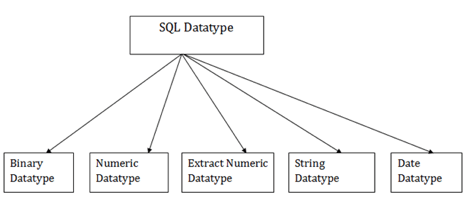
Fig 10: SQL data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Literals
Literals are notes or the concept of representing/expressing a meaning that does not change. Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
We will explain the various forms of literal statements in this section and how they can be used in MySQL statements.
The following are the literal forms:
S.no |
Literal type & example |
1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
Key takeaway:
- MySQL is the most common programme for database management systems used for relational database management.
- Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database.
- SQL comes in different versions and forms.
- Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
- Literals are notes or the concept of representing/expressing a meaning that does not change
The Structured Query Language (SQL), as we all know, is a database language that allows one to perform certain operations on existing databases as well as build new databases. To complete the tasks, SQL employs commands such as Create, Drop, and Insert.
These SQL commands are primarily divided into four groups:
● DDL (Data Definition Language)
● DML (Data Manipulation Language)
● DQL (Data Query Language)
● DCL (Data Control Language)
● TCL (Transactional control commands)
DDL:
DDL stands for Data Definition Language, and it is a part of SQL that allows a database user to build and restructure database objects, such as tables.
The following are some of the most basic DDL commands that will be addressed in the coming hours:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
ALTER INDEX
DROP INDEX
CREATE VIEW
DROP VIEW
DML:
DML, or Data Manipulation Language, is a part of SQL that allows you to manipulate data within relational database objects.
DML commands are divided into three categories:
INSERT
UPDATE
DELETE
DQL:
Data Query Language (DQL) is the most focused subject of SQL for modern relational database users, despite having only one instruction.
The following is the base command:
SELECT
A query is a request for information from a database. A query to the database is normally sent to it through an application interface or a command line prompt.
DCL:
In SQL, you can use data control commands to limit who has access to data in the database. These DCL commands are typically used to build objects related to user access and to manage privilege distribution among users.
The following are some data access commands:
ALTER PASSWORD
GRANT
REVOKE
CREATE SYNONYM
TCL:
Only DML commands like INSERT, DELETE, and UPDATE can be used with TCL commands. Since these operations are automatically committed to the database, they can't be used to create or drop tables.
Here are some examples of TCL commands:
COMMIT Saves database transactions
ROLLBACK Undoes database transactions
SAVEPOINT Creates points within groups of transactions in which to ROLLBACK
SET TRANSACTION Places a name on a transaction
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations. These Operators are used to define conditions in SQL statements and to function as conjunctions for multiple conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
● Operators used to negate conditions
Arithmetic operator
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
+ (Addition) | Values are added to both sides of the operator. | a + b will give 30 |
- (Subtraction) | Takes the right hand operand and subtracts it from the left hand operand. | a - b will give -10 |
* (Multiplication) | Values on both sides of the operator are multiplied. | a * b will give 200 |
/ (Division) | Divides the left and right hand operands. | b / a will give 2 |
% (Modulus) | Returns the remainder after dividing the left hand operand by the right hand operand. | b % a will give 0 |
Comparison operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
= | Checks if the values of two operands are equal, and if they are, the condition is valid. | (a = b) is not true. |
!= | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a != b) is true. |
<> | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is valid. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is valid. | (a < b) is true. |
>= | If the left operand's value is greater than or equal to the right operand's value, then the condition is valid. | (a >= b) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is valid. | (a <= b) is true. |
!< | If the value of the left operand is greater than the value of the right operand, the condition is valid. | (a !< b) is false. |
!> | If the value of the left operand is less than the value of the right operand, then the condition is valid. | (a !> b) is true. |
Logical operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Sr.No | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows multiple conditions to occur in the WHERE clause of a SQL statement. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the condition. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a given table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been defined, the IN operator is used. |
7 | LIKE The LIKE operator compares a value to other values that are identical using wildcard operators. |
8 | NOT The NOT operator flips the definition of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL statement to combine several conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is used. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
A SQL Table is a list of data that has been arranged into rows and columns. The table is referred to as a relation, and the row is referred to as a tuple in relational databases.
A table is a basic data storage format. A table may also be thought of as a simple way to portray relationships.
Example: Employee table
EMP_NAME | ADDRESS | SALARY |
Ankit | Lucknow | 15000 |
Raman | Allahabad | 18000 |
Mike | New York
| 20000 |
The table name is "Employee," and the column names are "EMP NAME," "ADDRESS," and "SALARY." A row is formed by the combination of data from multiple columns, such as "Ankit," "Lucknow," and 15000.
Operation on table:
- Create table
- Drop table
- Delete table
- Rename table
Create Table:
To create a table in the database, use SQL create table. To define the table, you must first define the table's name, as well as the table's columns and data types.
Syntax:
Create table "table_name"
("column1" "data type",
"column2" "data type",
"column3" "data type",
...
"columnN" "data type");
Drop Table
A SQL drop table is used to remove a table's description as well as all of its results. When this command is run, all of the data in the table is permanently lost, so be cautious when using it.
Syntax:
DROP TABLE "table_name";
Delete Table:
To delete rows from a table in SQL, use the DELETE expression. To delete a particular row from a table, we can use the WHERE condition. You don't need to use the WHERE clause if you want to remove all the records from the table.
Syntax:
DELETE FROM table_name WHERE condition;
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
A MySQL subquery is a query nested within another query such as select, insert, update or delete. In addition, a MySQL subquery can be nested inside another subquery.
A MySQL subquery is called an inner query while the query that contains the subquery is called an outer query. A subquery can be used anywhere that expression is used and must be closed in parentheses.
A subquery is also known as a nested query. It is a SELECT query embedded within the WHERE or HAVING clause of another SQL query. The data returned by the subquery is used by the outer statement in the same way a literal value would be used.
Subqueries provide an easy and efficient way to handle the queries that depend on the results from another query. They are almost identical to the normal SELECT statements, but there are few restrictions.
The most important ones are listed below:
● A subquery must always appear within parentheses.
● A subquery must return only one column. This means you cannot use SELECT * in a subquery unless the table you are referring to has only one column. You may use a subquery that returns multiple columns, if the purpose is row comparison.
● You can only use subqueries that return more than one row with multiple value operators, such as the IN or NOT IN operator.
● A subquery cannot be a UNION. Only a single SELECT statement is allowed.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the
Result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who have placed orders worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- MySQL subquery can be nested inside another subquery.
- A subquery is also known as a nested query.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
The data that you need is not always stored in the tables. However, you can get it by
Performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from
The order details table because the order details table stores only the quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
- AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
2. MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
3. MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
4. TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
5. MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Insert
The syntax for the insertion of a new record into a table is quite simple:
INSERT INTO table_name (field1, field2, ...)
VALUES (value1, value2, ...);
Where
● field1 and field2 are fields from table_name.
● Values 1 and 2 are the values for fields 1 and 2, respectively. SQL allows you the flexibility to list the fields in the order you want, as long as the corresponding values are defined accordingly. The following code is thus identical to the question above:
INSERT INTO table_name (field2, field1, ...)
VALUES (value2, value1, ...);
A variant of INSERT makes it possible to insert many comma-separated records at once, as follows:
INSERT INTO table_name (field1, field2, ...)
VALUES (value3, value4, ...),
(value5, value6, ...),
(value7, value8, ...);
Update
To change the data that is already in the database, the SQL UPDATE statement is used. In the WHERE clause, the condition determines which row is to be changed.
Syntax
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Updating single record
Adjust the EMP NAME column and set the value in the row where SALARY is 500000 to 'Emma'.
Syntax
UPDATE table_name
SET column_name = value
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Emma'
WHERE SALARY = 500000;
Updating multiple record
You can divide each field allocated by a comma if you want to update several columns. Adjust the EMP NAME column to 'Kevin' in the EMPLOYEE table, and CITY to 'Boston' where the EMP ID is 5.
Syntax
UPDATE table_name
SET column_name = value1, column_name2 = value2
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Kevin', City = 'Boston'
WHERE EMP_ID = 5;
Delete
To delete rows from a table, the SQL DELETE statement is used. The DELETE statement usually removes one or more records from a table.
Syntax
DELETE FROM table_name WHERE some_condition;
Deleting single record
Remove the EMPLOYEE table row, where EMP NAME = 'Kristen'. Just the fourth row will be omitted here.
Syntax
DELETE FROM EMPLOYEE
WHERE EMP_NAME = 'Kristen';
Deleting multiple record
Remove the row where AGE is 30 from the EMPLOYEE table. Two rows will be deleted by this (first and third row).
Syntax
DELETE FROM EMPLOYEE WHERE AGE= 30;
JOIN, as the name implies, is a word that means "to combine." In SQL, JOIN means "to join two or more tables together."
The JOIN clause in SQL is used to join records from two or more database tables.
Broadly, there are four types of methods for joining:
● INNER JOIN
● LEFT JOIN
● RIGHT JOIN
● FULL JOIN
Inner Join
INNER JOIN selects records in both tables that have matching values as long as the condition is met in SQL. It returns a set of all rows from both tables that satisfy the condition.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
INNER JOIN table2
ON table1.matching_column = table2.matching_column;
Left Join
The SQL left join returns all of the values from the left table as well as the values from the right table that match. It will return NULL if there is no matching join value.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
LEFT JOIN table2
ON table1.matching_column = table2.matching_column;
Right Join
RIGHT JOIN returns all the values from the rows of the right table as well as the matched values from the left table in SQL. It will return NULL if there is no match in both tables.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
RIGHT JOIN table2
ON table1.matching_column = table2.matching_column;
Full Join
A FULL JOIN in SQL is the product of combining left and right outer joins. The records from both tables are combined in the join tables. It places a NULL in the position of any matches that were not identified.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
FULL JOIN table2
ON table1.matching_column = table2.matching_column;
Key takeaway:
- There are numerous joining techniques between two tables to perform.
Unions
To combine the effects of two or more SELECT statements, use UNION. It can, however, remove redundant rows from the result set. In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
Fig 11: Unions
Example:
First table
ID | Name |
1 | Sam |
2 | Abhi |
Second table
ID | Name |
2 | Abhi |
3 | Bhu |
Query will be: SELECT * FROM First
UNION
SELECT * FROM Second;
ID | Name |
1 | Sam |
2 | Abhi |
3 | Bhu |
Intersection
The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both. The number of columns and datatype must be the same when using Intersect.
Fig 12: Intersection
Consider the above two tables.
Query will be: SELECT * FROM First
INTERSECT
SELECT * FROM Second;
ID | Name |
2 | Abhi |
Minus
The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
Fig 13: Minus
Consider the above two tables,
Query will be: SELECT * FROM First
MINUS
SELECT * FROM Second;
ID | Name |
1 | Sam |
Cursors
A cursor is a form of temporary memory or workstation. It is allocated by the database server when a user performs DML operations on a table. Database Tables are stored in cursors.
Implicit and explicit cursors are the two types of cursors. These are clarified in the following paragraphs.
Implicit cursors: Implicit cursors are also known as SQL SERVER's Default Cursors. When a user performs DML operations, SQL SERVER allocates these cursors.
Explicit cursors: When a user needs an explicit cursor, the user creates it. For fetching data from a table in a row-by-row manner, explicit cursors are used.
Key takeaway:
- In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
- The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both.
- The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
- A cursor is a form of temporary memory or workstation.
A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database. For instance, when a row is inserted into a specified table or when certain table columns are being modified, a trigger can be invoked.
In fact, triggers are written for execution in response to any of the following events.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
You may identify triggers for the table, display, schema, or database that the event is associated with.
Benefits of Triggers
● Generating some derived column values automatically
● Enforcing referential integrity
● Event logging and storing information on table access
● Auditing
● Synchronous replication of tables
● Imposing security authorizations
● Preventing invalid transactions
Syntax
Create trigger [trigger_name]
[before | after]
{insert | update | delete}
On [table_name]
[for each row]
[trigger_body]
Key takeaway:
- A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database.
A procedure is a PL/SQL block that performs one or more specific tasks. Procedures in other programming languages are analogous to this.
A header and a body appear in the procedure.
Header: The procedure's name and the parameters or variables passed to the procedure are both listed in the header.
Body: Similar to a general PL/SQL block, the body has a declaration, execution, and exception section.
How to pass parameters in procedure:
When you want to create a procedure or function, you have to define parameters. There is three ways to pass parameters in procedure:
IN parameters: The IN parameter can be referenced by the procedure or function. The value of the parameter cannot be overwritten by the procedure or the function.
OUT parameters: The OUT parameter cannot be referenced by the procedure or function, but the value of the parameter can be overwritten by the procedure or function.
INOUT parameters: The INOUT parameter can be referenced by the procedure or function and the value of the parameter can be overwritten by the procedure or function.
PL/SQL Create Procedure
Syntax:
CREATE [OR REPLACE] PROCEDURE procedure_name
[ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_name];
PL/SQL Drop Procedure
Syntax:
DROP PROCEDURE procedure_name;
Key takeaway:
- A procedure is a PL/SQL block that performs one or more specific tasks.
- Procedures in other programming languages are analogous to this.
References:
- RAMAKRISHNAN "Database Management Systems", McGraw Hill
2. Leon & Leon, “Database Management Systems”, Vikas Publishing House
3. Bipin C. Desai, “An Introduction to Database Systems”, Gagotia Publications
4. Majumdar & Bhattacharya, “Database Management System”, TMH
5. https://www.javatpoint.com
Unit – 2
Relational data Model and Language
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Data models are used to describe the design of a database at the logical level.
Some of the data models are: -
1. Entity-Relationship Model
2. Relational Model
3. Hierarchical Model
4. Network Model
5. Object Relational Model
Entity-Relationship(E-R) Model:
● The logical structure of a database can be expressed by an E-R diagram.
● Relationships are defined in this database model by dividing the object of interest into an entity and its characteristics into attributes.
● Using relationships, various entities are related.
● To make it easier for various stakeholders to understand, E-R models are established to represent relationships in pictorial form.
The Main Components of ER Diagram are:
a) Rectangles - Entity Sets
b) Ellipses - Attributes
c) Diamond - Relation among entity sets
d) Lines - Connects attributes to entity sets and entity sets to relationships.
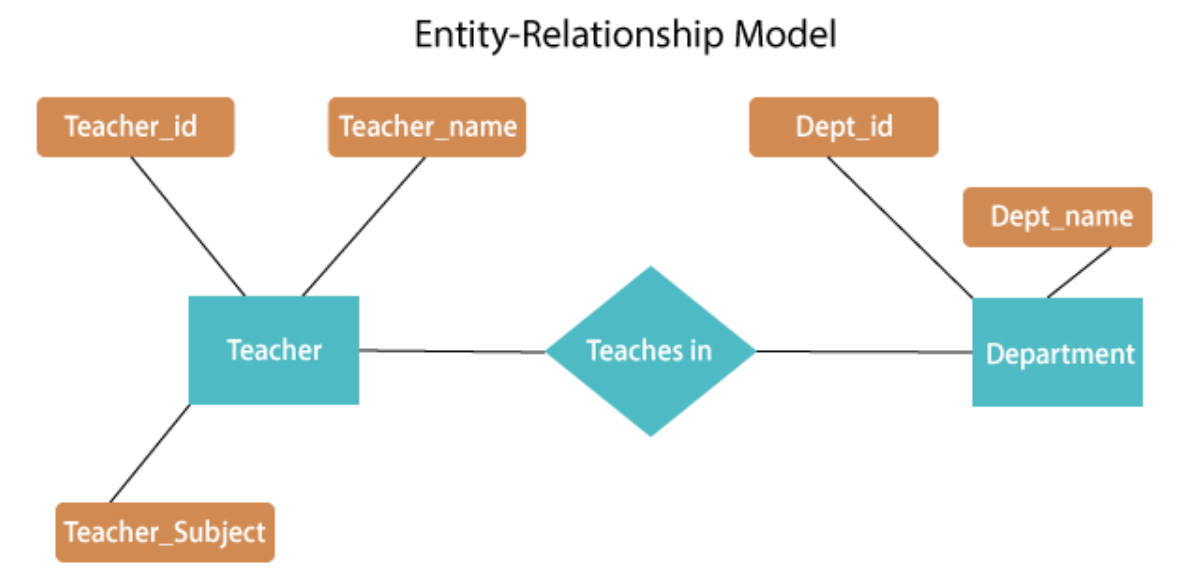
Fig 1: E - R diagram
The above E-R diagram has two entities: Teacher and Department
Teacher entity has three attributes:
Teacher_id
Teacher_name
Teacher_Subject
Department entity has two attributes:-
Dept_id
Dept_name
Relation Teaches in gives relationship between Teacher, Department .
Relationship can be of the type:
1:1→One to one
1:M →One to many
M:1 →Many to one
M:M →Many to many
Relational Model:
● Relational model uses a collection of tables to represent both data and the relationships among those data.
● This model is useful for constructing a database that can then be converted into relational model tables.
● Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
● In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
- Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
B. Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
C. Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Hierarchical Model:
● This model of the database organises information into a tree-like structure with a single root to which all the other information is connected. The hierarchy begins from the root data and extends to the parent nodes like a tree, adding child nodes.
● A child node can only have a single parent node in this model.
● A Hierarchical model uses tree structure to represent relationships among entities.
● This model represents many real-world relationships effectively, such as a book index, recipes, etc.
● Data is structured into a tree-like structure in the hierarchical model with a one-to-many relationship between two different data forms.
For instance, one department can have many classes, many professors and many students of course.
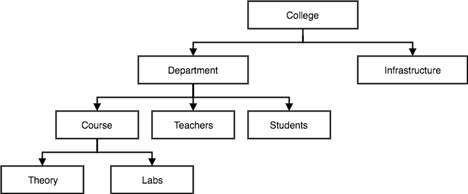
Fig 2: Hierarchical model
Network Model:
● Network model uses two different data structures:
a) A record type is used to represent an entity set.
b) A set type is used to represent a directed relationship between two record types.
● This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
● Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
● This was the most commonly used database architecture prior to the advent of the Relational Model.
Fig 3: Network model
Object Relational Model:
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
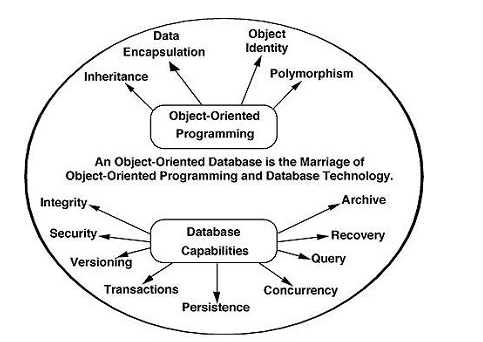
Fig 4: Object - oriented model
Object-oriented databases use small, recyclable separated of software
Called objects. The objects themselves are stored in the object-oriented
Database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with
The data.
There are two types of ORM:
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types, operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Key takeaway:
- The logical structure of a database can be expressed by an E-R diagram.
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- A Hierarchical model uses tree structure to represent relationships among entities.
- Network model is the Hierarchical model's extension
Constraints on honesty are a set of rules. It is used to maintain information quality.
Integrity constraints ensure that it is important to perform data insertion, updating, and other procedures in such a way that data integrity is not compromised.
Therefore, to protect against unintended damage to the database, integrity constraints are used.
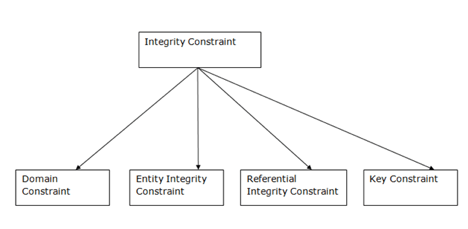
Fig 5: Types of integrity constraints
Domain Constraints
● As a description of a valid set of values for an attribute, domain constraints can be specified.
● The domain data type consists of a string, character, integer, time, date, currency, etc. In the corresponding domain, the value of the attribute must be available.
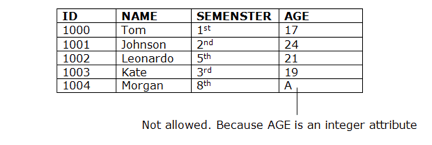
Fig 6: Example of domain constraints
Entity Integrity Constraints
● The honesty restriction of the organization states that the primary key value should not be zero.
● This is because the primary key value is used to define the relationship between individual rows, and if the primary key has a null value, then those rows cannot be identified.
● A table may contain a null value other than the field for the primary key.
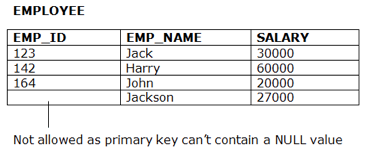
Fig 7: Example of entity constraints
Referential Constraints
● Between two relations or tables, the referential integrity constraints are defined and used to preserve the consistency between the tuples in two relationships.
● If an attribute of the foreign key of the relationship R1 has the same domain(s) as the primary key of the relationship R2, then the foreign key of R1 is said to refer to or refer to the primary key of the relationship R2.
● Foreign key values in the R1 relationship tuple can either take the primary key values for a certain R2 relationship tuple, or they can take NULL values, but cannot be zero.
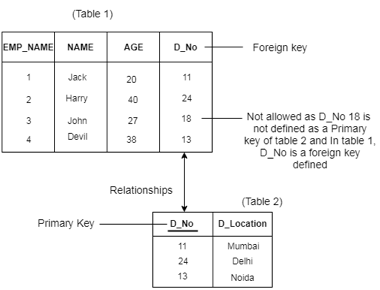
Fig 8: Example of integrity constraints
Key Constraints
● Keys are the collection of entities used to uniquely define an object within its entity set.
● A group of entities may have several keys, but the primary key will be one key. A primary key may contain in the relational table a unique and null value.
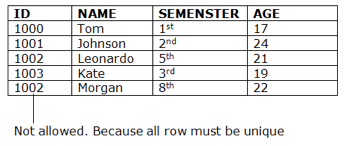
Fig 9: Example of key constraints
Key takeaway:
- Constraints on honesty are a set of rules.
- It is used to maintain information quality.
- The domain data type consists of a string, character, integer, time, date, currency.
- Between two relations or tables, the referential integrity constraints are defined.
- Keys are the collection of entities used to uniquely define an object within its entity set.
Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R :
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
● Theta join
● EQUI join
● Natural join
Outer join:
● Left Outer Join
● Right Outer Join
● Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8.Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Key takeaway:
- Relational Algebra is procedural query language.
- It takes Relation as input and generates relation as output.
- Data stored in a database can be retrieved using a query.
Tuple Relational Calculus (TRC)
● To select the tuples in a relationship, the tuple relational calculus is defined. The filtering variable in TRC uses relationship tuples.
● You may have one or more tuples as a consequence of the partnership.
Notation: {T | P (T)} or {T | Condition (T)}
Where,
T - resulting tuple
P (T) - condition used to fetch T.
Example 1:
{ T.name | Author(T) AND T.article = 'database' }
Output :
Select tuples from the AUTHOR relationship in this question. It returns a 'name' tuple from the author who wrote a 'database' post.
TRC (tuple relational calculus) can be quantified. We may use existential (∃) and universal quantifiers (∀) in TRC.
Example 2:
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Output : This question is going to generate the same result as the previous one.
Domain Relational Calculus
● Domain relational calculus is known as the second type of relationship. The filtering variable uses the domain attributes in the domain relational calculus.
● The same operators as the tuple calculus are used in domain relational calculus. It utilises logical relations ∧ (and), ∨ (or) and ┓ (not).
● To connect the variable, it uses Existential (∃) and Universal Quantifiers (∀).
Notation:
{ a1, a2, a3, ..., an | P (a1, a2, a3, ... ,an)}
Where,
a1,a2 - attributes
P - formula built by inner attributes
Example
{< article, page, subject > | ∈ CSE ∧ subject = 'database'}
Output: This query will result from the relational CSE, where the topic is a database, to the post, page, and subject.
Key takeaway:
- To select the tuples in a relationship, the tuple relational calculus is defined.
- Domain relational calculus is known as the second type of relationship.
Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database. SQL comes in different versions and forms. All of these versions are based upon the ANSI SQL.
Currently, MySQL is the most common programme for database management systems used for relational database management. It is an open-source, Oracle Company - supported database programme. In comparison to Microsoft SQL Server and Oracle Database, the database management system is fast, scalable, and easy to use. It is widely used for building efficient and interactive server-side or web-based business applications in combination with PHP scripts.
Characteristics of SQL
● It is quick to learn SQL.
● For accessing data from relational database management systems, SQL is used.
● SQL will perform database queries against it.
● To describe data, SQL is used.
● SQL is used in the database to describe the data and manipulate it when appropriate.
● To build and drop the database and the table, SQL is used.
● SQL is used in a database to construct a view, a stored procedure, a function.
● SQL allows users to set tables, procedures, and display permissions.
Advantages of SQL
● SQL is easy to learn and use.
● SQL is a non-procedural language. It means we have to specify only what to retrieve and not the procedure for retrieving data.
● SQL can be embedded within other languages using SQL modules, pre-compilers.
● Allows creating procedure, functions, and views using PL-SQL.
● Allows users to drop databases, tables, views, procedure and cursors.
● Allows users to set access permissions on tables, views and procedures.
SQL data types
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
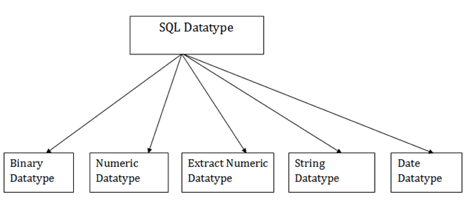
Fig 10: SQL data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Literals
Literals are notes or the concept of representing/expressing a meaning that does not change. Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
We will explain the various forms of literal statements in this section and how they can be used in MySQL statements.
The following are the literal forms:
S.no |
Literal type & example |
1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
Key takeaway:
- MySQL is the most common programme for database management systems used for relational database management.
- Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database.
- SQL comes in different versions and forms.
- Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
- Literals are notes or the concept of representing/expressing a meaning that does not change
The Structured Query Language (SQL), as we all know, is a database language that allows one to perform certain operations on existing databases as well as build new databases. To complete the tasks, SQL employs commands such as Create, Drop, and Insert.
These SQL commands are primarily divided into four groups:
● DDL (Data Definition Language)
● DML (Data Manipulation Language)
● DQL (Data Query Language)
● DCL (Data Control Language)
● TCL (Transactional control commands)
DDL:
DDL stands for Data Definition Language, and it is a part of SQL that allows a database user to build and restructure database objects, such as tables.
The following are some of the most basic DDL commands that will be addressed in the coming hours:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
ALTER INDEX
DROP INDEX
CREATE VIEW
DROP VIEW
DML:
DML, or Data Manipulation Language, is a part of SQL that allows you to manipulate data within relational database objects.
DML commands are divided into three categories:
INSERT
UPDATE
DELETE
DQL:
Data Query Language (DQL) is the most focused subject of SQL for modern relational database users, despite having only one instruction.
The following is the base command:
SELECT
A query is a request for information from a database. A query to the database is normally sent to it through an application interface or a command line prompt.
DCL:
In SQL, you can use data control commands to limit who has access to data in the database. These DCL commands are typically used to build objects related to user access and to manage privilege distribution among users.
The following are some data access commands:
ALTER PASSWORD
GRANT
REVOKE
CREATE SYNONYM
TCL:
Only DML commands like INSERT, DELETE, and UPDATE can be used with TCL commands. Since these operations are automatically committed to the database, they can't be used to create or drop tables.
Here are some examples of TCL commands:
COMMIT Saves database transactions
ROLLBACK Undoes database transactions
SAVEPOINT Creates points within groups of transactions in which to ROLLBACK
SET TRANSACTION Places a name on a transaction
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations. These Operators are used to define conditions in SQL statements and to function as conjunctions for multiple conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
● Operators used to negate conditions
Arithmetic operator
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
+ (Addition) | Values are added to both sides of the operator. | a + b will give 30 |
- (Subtraction) | Takes the right hand operand and subtracts it from the left hand operand. | a - b will give -10 |
* (Multiplication) | Values on both sides of the operator are multiplied. | a * b will give 200 |
/ (Division) | Divides the left and right hand operands. | b / a will give 2 |
% (Modulus) | Returns the remainder after dividing the left hand operand by the right hand operand. | b % a will give 0 |
Comparison operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
= | Checks if the values of two operands are equal, and if they are, the condition is valid. | (a = b) is not true. |
!= | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a != b) is true. |
<> | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is valid. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is valid. | (a < b) is true. |
>= | If the left operand's value is greater than or equal to the right operand's value, then the condition is valid. | (a >= b) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is valid. | (a <= b) is true. |
!< | If the value of the left operand is greater than the value of the right operand, the condition is valid. | (a !< b) is false. |
!> | If the value of the left operand is less than the value of the right operand, then the condition is valid. | (a !> b) is true. |
Logical operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Sr.No | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows multiple conditions to occur in the WHERE clause of a SQL statement. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the condition. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a given table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been defined, the IN operator is used. |
7 | LIKE The LIKE operator compares a value to other values that are identical using wildcard operators. |
8 | NOT The NOT operator flips the definition of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL statement to combine several conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is used. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
A SQL Table is a list of data that has been arranged into rows and columns. The table is referred to as a relation, and the row is referred to as a tuple in relational databases.
A table is a basic data storage format. A table may also be thought of as a simple way to portray relationships.
Example: Employee table
EMP_NAME | ADDRESS | SALARY |
Ankit | Lucknow | 15000 |
Raman | Allahabad | 18000 |
Mike | New York
| 20000 |
The table name is "Employee," and the column names are "EMP NAME," "ADDRESS," and "SALARY." A row is formed by the combination of data from multiple columns, such as "Ankit," "Lucknow," and 15000.
Operation on table:
- Create table
- Drop table
- Delete table
- Rename table
Create Table:
To create a table in the database, use SQL create table. To define the table, you must first define the table's name, as well as the table's columns and data types.
Syntax:
Create table "table_name"
("column1" "data type",
"column2" "data type",
"column3" "data type",
...
"columnN" "data type");
Drop Table
A SQL drop table is used to remove a table's description as well as all of its results. When this command is run, all of the data in the table is permanently lost, so be cautious when using it.
Syntax:
DROP TABLE "table_name";
Delete Table:
To delete rows from a table in SQL, use the DELETE expression. To delete a particular row from a table, we can use the WHERE condition. You don't need to use the WHERE clause if you want to remove all the records from the table.
Syntax:
DELETE FROM table_name WHERE condition;
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
A MySQL subquery is a query nested within another query such as select, insert, update or delete. In addition, a MySQL subquery can be nested inside another subquery.
A MySQL subquery is called an inner query while the query that contains the subquery is called an outer query. A subquery can be used anywhere that expression is used and must be closed in parentheses.
A subquery is also known as a nested query. It is a SELECT query embedded within the WHERE or HAVING clause of another SQL query. The data returned by the subquery is used by the outer statement in the same way a literal value would be used.
Subqueries provide an easy and efficient way to handle the queries that depend on the results from another query. They are almost identical to the normal SELECT statements, but there are few restrictions.
The most important ones are listed below:
● A subquery must always appear within parentheses.
● A subquery must return only one column. This means you cannot use SELECT * in a subquery unless the table you are referring to has only one column. You may use a subquery that returns multiple columns, if the purpose is row comparison.
● You can only use subqueries that return more than one row with multiple value operators, such as the IN or NOT IN operator.
● A subquery cannot be a UNION. Only a single SELECT statement is allowed.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the
Result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who have placed orders worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- MySQL subquery can be nested inside another subquery.
- A subquery is also known as a nested query.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
The data that you need is not always stored in the tables. However, you can get it by
Performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from
The order details table because the order details table stores only the quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
- AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
2. MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
3. MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
4. TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
5. MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Insert
The syntax for the insertion of a new record into a table is quite simple:
INSERT INTO table_name (field1, field2, ...)
VALUES (value1, value2, ...);
Where
● field1 and field2 are fields from table_name.
● Values 1 and 2 are the values for fields 1 and 2, respectively. SQL allows you the flexibility to list the fields in the order you want, as long as the corresponding values are defined accordingly. The following code is thus identical to the question above:
INSERT INTO table_name (field2, field1, ...)
VALUES (value2, value1, ...);
A variant of INSERT makes it possible to insert many comma-separated records at once, as follows:
INSERT INTO table_name (field1, field2, ...)
VALUES (value3, value4, ...),
(value5, value6, ...),
(value7, value8, ...);
Update
To change the data that is already in the database, the SQL UPDATE statement is used. In the WHERE clause, the condition determines which row is to be changed.
Syntax
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Updating single record
Adjust the EMP NAME column and set the value in the row where SALARY is 500000 to 'Emma'.
Syntax
UPDATE table_name
SET column_name = value
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Emma'
WHERE SALARY = 500000;
Updating multiple record
You can divide each field allocated by a comma if you want to update several columns. Adjust the EMP NAME column to 'Kevin' in the EMPLOYEE table, and CITY to 'Boston' where the EMP ID is 5.
Syntax
UPDATE table_name
SET column_name = value1, column_name2 = value2
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Kevin', City = 'Boston'
WHERE EMP_ID = 5;
Delete
To delete rows from a table, the SQL DELETE statement is used. The DELETE statement usually removes one or more records from a table.
Syntax
DELETE FROM table_name WHERE some_condition;
Deleting single record
Remove the EMPLOYEE table row, where EMP NAME = 'Kristen'. Just the fourth row will be omitted here.
Syntax
DELETE FROM EMPLOYEE
WHERE EMP_NAME = 'Kristen';
Deleting multiple record
Remove the row where AGE is 30 from the EMPLOYEE table. Two rows will be deleted by this (first and third row).
Syntax
DELETE FROM EMPLOYEE WHERE AGE= 30;
JOIN, as the name implies, is a word that means "to combine." In SQL, JOIN means "to join two or more tables together."
The JOIN clause in SQL is used to join records from two or more database tables.
Broadly, there are four types of methods for joining:
● INNER JOIN
● LEFT JOIN
● RIGHT JOIN
● FULL JOIN
Inner Join
INNER JOIN selects records in both tables that have matching values as long as the condition is met in SQL. It returns a set of all rows from both tables that satisfy the condition.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
INNER JOIN table2
ON table1.matching_column = table2.matching_column;
Left Join
The SQL left join returns all of the values from the left table as well as the values from the right table that match. It will return NULL if there is no matching join value.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
LEFT JOIN table2
ON table1.matching_column = table2.matching_column;
Right Join
RIGHT JOIN returns all the values from the rows of the right table as well as the matched values from the left table in SQL. It will return NULL if there is no match in both tables.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
RIGHT JOIN table2
ON table1.matching_column = table2.matching_column;
Full Join
A FULL JOIN in SQL is the product of combining left and right outer joins. The records from both tables are combined in the join tables. It places a NULL in the position of any matches that were not identified.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
FULL JOIN table2
ON table1.matching_column = table2.matching_column;
Key takeaway:
- There are numerous joining techniques between two tables to perform.
Unions
To combine the effects of two or more SELECT statements, use UNION. It can, however, remove redundant rows from the result set. In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
Fig 11: Unions
Example:
First table
ID | Name |
1 | Sam |
2 | Abhi |
Second table
ID | Name |
2 | Abhi |
3 | Bhu |
Query will be: SELECT * FROM First
UNION
SELECT * FROM Second;
ID | Name |
1 | Sam |
2 | Abhi |
3 | Bhu |
Intersection
The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both. The number of columns and datatype must be the same when using Intersect.
Fig 12: Intersection
Consider the above two tables.
Query will be: SELECT * FROM First
INTERSECT
SELECT * FROM Second;
ID | Name |
2 | Abhi |
Minus
The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
Fig 13: Minus
Consider the above two tables,
Query will be: SELECT * FROM First
MINUS
SELECT * FROM Second;
ID | Name |
1 | Sam |
Cursors
A cursor is a form of temporary memory or workstation. It is allocated by the database server when a user performs DML operations on a table. Database Tables are stored in cursors.
Implicit and explicit cursors are the two types of cursors. These are clarified in the following paragraphs.
Implicit cursors: Implicit cursors are also known as SQL SERVER's Default Cursors. When a user performs DML operations, SQL SERVER allocates these cursors.
Explicit cursors: When a user needs an explicit cursor, the user creates it. For fetching data from a table in a row-by-row manner, explicit cursors are used.
Key takeaway:
- In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
- The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both.
- The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
- A cursor is a form of temporary memory or workstation.
A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database. For instance, when a row is inserted into a specified table or when certain table columns are being modified, a trigger can be invoked.
In fact, triggers are written for execution in response to any of the following events.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
You may identify triggers for the table, display, schema, or database that the event is associated with.
Benefits of Triggers
● Generating some derived column values automatically
● Enforcing referential integrity
● Event logging and storing information on table access
● Auditing
● Synchronous replication of tables
● Imposing security authorizations
● Preventing invalid transactions
Syntax
Create trigger [trigger_name]
[before | after]
{insert | update | delete}
On [table_name]
[for each row]
[trigger_body]
Key takeaway:
- A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database.
A procedure is a PL/SQL block that performs one or more specific tasks. Procedures in other programming languages are analogous to this.
A header and a body appear in the procedure.
Header: The procedure's name and the parameters or variables passed to the procedure are both listed in the header.
Body: Similar to a general PL/SQL block, the body has a declaration, execution, and exception section.
How to pass parameters in procedure:
When you want to create a procedure or function, you have to define parameters. There is three ways to pass parameters in procedure:
IN parameters: The IN parameter can be referenced by the procedure or function. The value of the parameter cannot be overwritten by the procedure or the function.
OUT parameters: The OUT parameter cannot be referenced by the procedure or function, but the value of the parameter can be overwritten by the procedure or function.
INOUT parameters: The INOUT parameter can be referenced by the procedure or function and the value of the parameter can be overwritten by the procedure or function.
PL/SQL Create Procedure
Syntax:
CREATE [OR REPLACE] PROCEDURE procedure_name
[ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_name];
PL/SQL Drop Procedure
Syntax:
DROP PROCEDURE procedure_name;
Key takeaway:
- A procedure is a PL/SQL block that performs one or more specific tasks.
- Procedures in other programming languages are analogous to this.
References:
- RAMAKRISHNAN "Database Management Systems", McGraw Hill
2. Leon & Leon, “Database Management Systems”, Vikas Publishing House
3. Bipin C. Desai, “An Introduction to Database Systems”, Gagotia Publications
4. Majumdar & Bhattacharya, “Database Management System”, TMH
5. https://www.javatpoint.com
Unit – 2
Relational data Model and Language
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Data models are used to describe the design of a database at the logical level.
Some of the data models are: -
1. Entity-Relationship Model
2. Relational Model
3. Hierarchical Model
4. Network Model
5. Object Relational Model
Entity-Relationship(E-R) Model:
● The logical structure of a database can be expressed by an E-R diagram.
● Relationships are defined in this database model by dividing the object of interest into an entity and its characteristics into attributes.
● Using relationships, various entities are related.
● To make it easier for various stakeholders to understand, E-R models are established to represent relationships in pictorial form.
The Main Components of ER Diagram are:
a) Rectangles - Entity Sets
b) Ellipses - Attributes
c) Diamond - Relation among entity sets
d) Lines - Connects attributes to entity sets and entity sets to relationships.
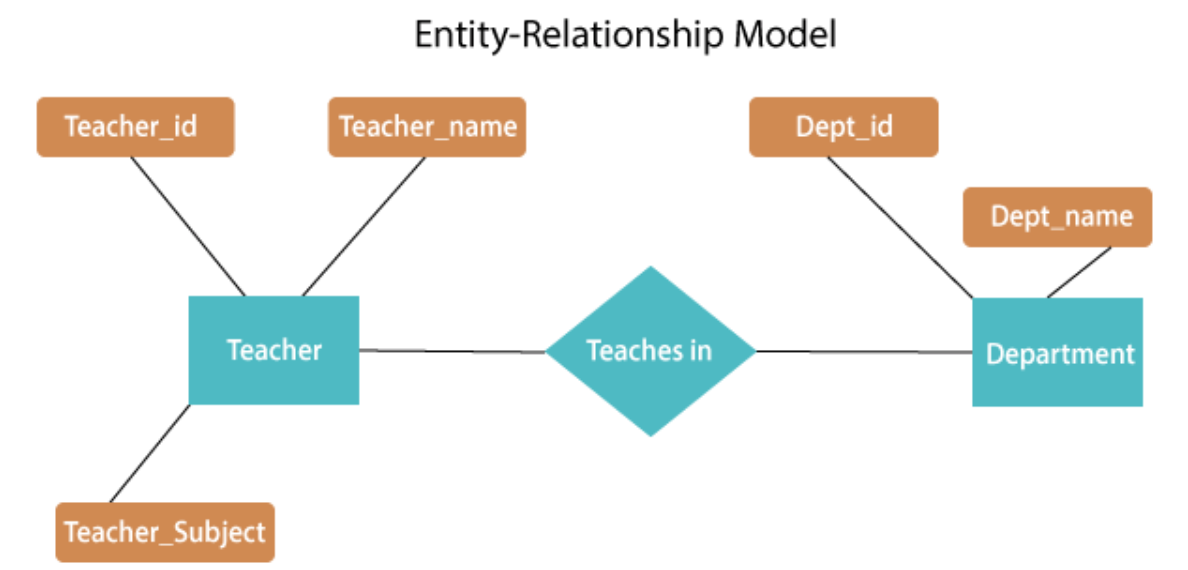
Fig 1: E - R diagram
The above E-R diagram has two entities: Teacher and Department
Teacher entity has three attributes:
Teacher_id
Teacher_name
Teacher_Subject
Department entity has two attributes:-
Dept_id
Dept_name
Relation Teaches in gives relationship between Teacher, Department .
Relationship can be of the type:
1:1→One to one
1:M →One to many
M:1 →Many to one
M:M →Many to many
Relational Model:
● Relational model uses a collection of tables to represent both data and the relationships among those data.
● This model is useful for constructing a database that can then be converted into relational model tables.
● Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
● In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
- Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
B. Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
C. Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Hierarchical Model:
● This model of the database organises information into a tree-like structure with a single root to which all the other information is connected. The hierarchy begins from the root data and extends to the parent nodes like a tree, adding child nodes.
● A child node can only have a single parent node in this model.
● A Hierarchical model uses tree structure to represent relationships among entities.
● This model represents many real-world relationships effectively, such as a book index, recipes, etc.
● Data is structured into a tree-like structure in the hierarchical model with a one-to-many relationship between two different data forms.
For instance, one department can have many classes, many professors and many students of course.
Fig 2: Hierarchical model
Network Model:
● Network model uses two different data structures:
a) A record type is used to represent an entity set.
b) A set type is used to represent a directed relationship between two record types.
● This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
● Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
● This was the most commonly used database architecture prior to the advent of the Relational Model.
Fig 3: Network model
Object Relational Model:
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
Fig 4: Object - oriented model
Object-oriented databases use small, recyclable separated of software
Called objects. The objects themselves are stored in the object-oriented
Database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with
The data.
There are two types of ORM:
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types, operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Key takeaway:
- The logical structure of a database can be expressed by an E-R diagram.
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- A Hierarchical model uses tree structure to represent relationships among entities.
- Network model is the Hierarchical model's extension
Constraints on honesty are a set of rules. It is used to maintain information quality.
Integrity constraints ensure that it is important to perform data insertion, updating, and other procedures in such a way that data integrity is not compromised.
Therefore, to protect against unintended damage to the database, integrity constraints are used.
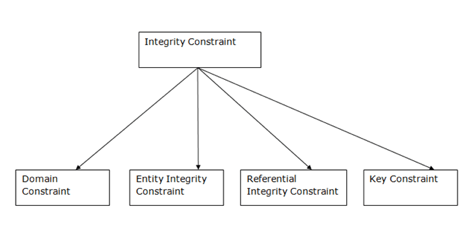
Fig 5: Types of integrity constraints
Domain Constraints
● As a description of a valid set of values for an attribute, domain constraints can be specified.
● The domain data type consists of a string, character, integer, time, date, currency, etc. In the corresponding domain, the value of the attribute must be available.
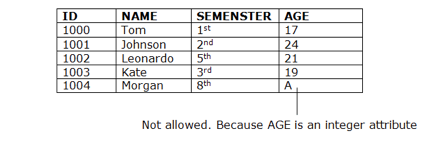
Fig 6: Example of domain constraints
Entity Integrity Constraints
● The honesty restriction of the organization states that the primary key value should not be zero.
● This is because the primary key value is used to define the relationship between individual rows, and if the primary key has a null value, then those rows cannot be identified.
● A table may contain a null value other than the field for the primary key.
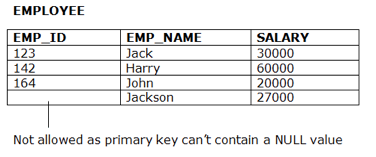
Fig 7: Example of entity constraints
Referential Constraints
● Between two relations or tables, the referential integrity constraints are defined and used to preserve the consistency between the tuples in two relationships.
● If an attribute of the foreign key of the relationship R1 has the same domain(s) as the primary key of the relationship R2, then the foreign key of R1 is said to refer to or refer to the primary key of the relationship R2.
● Foreign key values in the R1 relationship tuple can either take the primary key values for a certain R2 relationship tuple, or they can take NULL values, but cannot be zero.
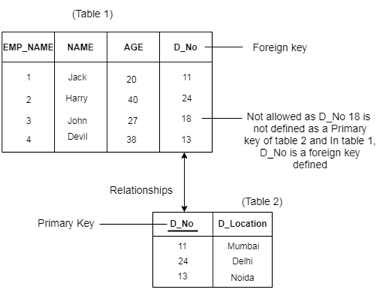
Fig 8: Example of integrity constraints
Key Constraints
● Keys are the collection of entities used to uniquely define an object within its entity set.
● A group of entities may have several keys, but the primary key will be one key. A primary key may contain in the relational table a unique and null value.
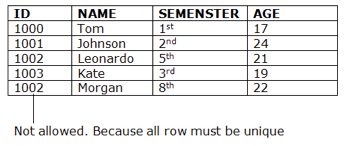
Fig 9: Example of key constraints
Key takeaway:
- Constraints on honesty are a set of rules.
- It is used to maintain information quality.
- The domain data type consists of a string, character, integer, time, date, currency.
- Between two relations or tables, the referential integrity constraints are defined.
- Keys are the collection of entities used to uniquely define an object within its entity set.
Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R :
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
● Theta join
● EQUI join
● Natural join
Outer join:
● Left Outer Join
● Right Outer Join
● Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8.Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Key takeaway:
- Relational Algebra is procedural query language.
- It takes Relation as input and generates relation as output.
- Data stored in a database can be retrieved using a query.
Tuple Relational Calculus (TRC)
● To select the tuples in a relationship, the tuple relational calculus is defined. The filtering variable in TRC uses relationship tuples.
● You may have one or more tuples as a consequence of the partnership.
Notation: {T | P (T)} or {T | Condition (T)}
Where,
T - resulting tuple
P (T) - condition used to fetch T.
Example 1:
{ T.name | Author(T) AND T.article = 'database' }
Output :
Select tuples from the AUTHOR relationship in this question. It returns a 'name' tuple from the author who wrote a 'database' post.
TRC (tuple relational calculus) can be quantified. We may use existential (∃) and universal quantifiers (∀) in TRC.
Example 2:
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Output : This question is going to generate the same result as the previous one.
Domain Relational Calculus
● Domain relational calculus is known as the second type of relationship. The filtering variable uses the domain attributes in the domain relational calculus.
● The same operators as the tuple calculus are used in domain relational calculus. It utilises logical relations ∧ (and), ∨ (or) and ┓ (not).
● To connect the variable, it uses Existential (∃) and Universal Quantifiers (∀).
Notation:
{ a1, a2, a3, ..., an | P (a1, a2, a3, ... ,an)}
Where,
a1,a2 - attributes
P - formula built by inner attributes
Example
{< article, page, subject > | ∈ CSE ∧ subject = 'database'}
Output: This query will result from the relational CSE, where the topic is a database, to the post, page, and subject.
Key takeaway:
- To select the tuples in a relationship, the tuple relational calculus is defined.
- Domain relational calculus is known as the second type of relationship.
Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database. SQL comes in different versions and forms. All of these versions are based upon the ANSI SQL.
Currently, MySQL is the most common programme for database management systems used for relational database management. It is an open-source, Oracle Company - supported database programme. In comparison to Microsoft SQL Server and Oracle Database, the database management system is fast, scalable, and easy to use. It is widely used for building efficient and interactive server-side or web-based business applications in combination with PHP scripts.
Characteristics of SQL
● It is quick to learn SQL.
● For accessing data from relational database management systems, SQL is used.
● SQL will perform database queries against it.
● To describe data, SQL is used.
● SQL is used in the database to describe the data and manipulate it when appropriate.
● To build and drop the database and the table, SQL is used.
● SQL is used in a database to construct a view, a stored procedure, a function.
● SQL allows users to set tables, procedures, and display permissions.
Advantages of SQL
● SQL is easy to learn and use.
● SQL is a non-procedural language. It means we have to specify only what to retrieve and not the procedure for retrieving data.
● SQL can be embedded within other languages using SQL modules, pre-compilers.
● Allows creating procedure, functions, and views using PL-SQL.
● Allows users to drop databases, tables, views, procedure and cursors.
● Allows users to set access permissions on tables, views and procedures.
SQL data types
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
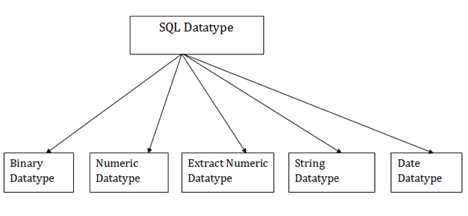
Fig 10: SQL data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Literals
Literals are notes or the concept of representing/expressing a meaning that does not change. Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
We will explain the various forms of literal statements in this section and how they can be used in MySQL statements.
The following are the literal forms:
S.no |
Literal type & example |
1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
Key takeaway:
- MySQL is the most common programme for database management systems used for relational database management.
- Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database.
- SQL comes in different versions and forms.
- Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
- Literals are notes or the concept of representing/expressing a meaning that does not change
The Structured Query Language (SQL), as we all know, is a database language that allows one to perform certain operations on existing databases as well as build new databases. To complete the tasks, SQL employs commands such as Create, Drop, and Insert.
These SQL commands are primarily divided into four groups:
● DDL (Data Definition Language)
● DML (Data Manipulation Language)
● DQL (Data Query Language)
● DCL (Data Control Language)
● TCL (Transactional control commands)
DDL:
DDL stands for Data Definition Language, and it is a part of SQL that allows a database user to build and restructure database objects, such as tables.
The following are some of the most basic DDL commands that will be addressed in the coming hours:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
ALTER INDEX
DROP INDEX
CREATE VIEW
DROP VIEW
DML:
DML, or Data Manipulation Language, is a part of SQL that allows you to manipulate data within relational database objects.
DML commands are divided into three categories:
INSERT
UPDATE
DELETE
DQL:
Data Query Language (DQL) is the most focused subject of SQL for modern relational database users, despite having only one instruction.
The following is the base command:
SELECT
A query is a request for information from a database. A query to the database is normally sent to it through an application interface or a command line prompt.
DCL:
In SQL, you can use data control commands to limit who has access to data in the database. These DCL commands are typically used to build objects related to user access and to manage privilege distribution among users.
The following are some data access commands:
ALTER PASSWORD
GRANT
REVOKE
CREATE SYNONYM
TCL:
Only DML commands like INSERT, DELETE, and UPDATE can be used with TCL commands. Since these operations are automatically committed to the database, they can't be used to create or drop tables.
Here are some examples of TCL commands:
COMMIT Saves database transactions
ROLLBACK Undoes database transactions
SAVEPOINT Creates points within groups of transactions in which to ROLLBACK
SET TRANSACTION Places a name on a transaction
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations. These Operators are used to define conditions in SQL statements and to function as conjunctions for multiple conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
● Operators used to negate conditions
Arithmetic operator
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
+ (Addition) | Values are added to both sides of the operator. | a + b will give 30 |
- (Subtraction) | Takes the right hand operand and subtracts it from the left hand operand. | a - b will give -10 |
* (Multiplication) | Values on both sides of the operator are multiplied. | a * b will give 200 |
/ (Division) | Divides the left and right hand operands. | b / a will give 2 |
% (Modulus) | Returns the remainder after dividing the left hand operand by the right hand operand. | b % a will give 0 |
Comparison operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Operator | Description | Example |
= | Checks if the values of two operands are equal, and if they are, the condition is valid. | (a = b) is not true. |
!= | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a != b) is true. |
<> | Checks if the values of two operands are equal; if they aren't, the condition is valid. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is valid. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is valid. | (a < b) is true. |
>= | If the left operand's value is greater than or equal to the right operand's value, then the condition is valid. | (a >= b) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is valid. | (a <= b) is true. |
!< | If the value of the left operand is greater than the value of the right operand, the condition is valid. | (a !< b) is false. |
!> | If the value of the left operand is less than the value of the right operand, then the condition is valid. | (a !> b) is true. |
Logical operator:
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Sr.No | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows multiple conditions to occur in the WHERE clause of a SQL statement. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the condition. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a given table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been defined, the IN operator is used. |
7 | LIKE The LIKE operator compares a value to other values that are identical using wildcard operators. |
8 | NOT The NOT operator flips the definition of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL statement to combine several conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is used. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
A SQL Table is a list of data that has been arranged into rows and columns. The table is referred to as a relation, and the row is referred to as a tuple in relational databases.
A table is a basic data storage format. A table may also be thought of as a simple way to portray relationships.
Example: Employee table
EMP_NAME | ADDRESS | SALARY |
Ankit | Lucknow | 15000 |
Raman | Allahabad | 18000 |
Mike | New York
| 20000 |
The table name is "Employee," and the column names are "EMP NAME," "ADDRESS," and "SALARY." A row is formed by the combination of data from multiple columns, such as "Ankit," "Lucknow," and 15000.
Operation on table:
- Create table
- Drop table
- Delete table
- Rename table
Create Table:
To create a table in the database, use SQL create table. To define the table, you must first define the table's name, as well as the table's columns and data types.
Syntax:
Create table "table_name"
("column1" "data type",
"column2" "data type",
"column3" "data type",
...
"columnN" "data type");
Drop Table
A SQL drop table is used to remove a table's description as well as all of its results. When this command is run, all of the data in the table is permanently lost, so be cautious when using it.
Syntax:
DROP TABLE "table_name";
Delete Table:
To delete rows from a table in SQL, use the DELETE expression. To delete a particular row from a table, we can use the WHERE condition. You don't need to use the WHERE clause if you want to remove all the records from the table.
Syntax:
DELETE FROM table_name WHERE condition;
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
A MySQL subquery is a query nested within another query such as select, insert, update or delete. In addition, a MySQL subquery can be nested inside another subquery.
A MySQL subquery is called an inner query while the query that contains the subquery is called an outer query. A subquery can be used anywhere that expression is used and must be closed in parentheses.
A subquery is also known as a nested query. It is a SELECT query embedded within the WHERE or HAVING clause of another SQL query. The data returned by the subquery is used by the outer statement in the same way a literal value would be used.
Subqueries provide an easy and efficient way to handle the queries that depend on the results from another query. They are almost identical to the normal SELECT statements, but there are few restrictions.
The most important ones are listed below:
● A subquery must always appear within parentheses.
● A subquery must return only one column. This means you cannot use SELECT * in a subquery unless the table you are referring to has only one column. You may use a subquery that returns multiple columns, if the purpose is row comparison.
● You can only use subqueries that return more than one row with multiple value operators, such as the IN or NOT IN operator.
● A subquery cannot be a UNION. Only a single SELECT statement is allowed.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the
Result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who have placed orders worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- MySQL subquery can be nested inside another subquery.
- A subquery is also known as a nested query.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
The data that you need is not always stored in the tables. However, you can get it by
Performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from
The order details table because the order details table stores only the quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
- AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
2. MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
3. MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
4. TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
5. MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Insert
The syntax for the insertion of a new record into a table is quite simple:
INSERT INTO table_name (field1, field2, ...)
VALUES (value1, value2, ...);
Where
● field1 and field2 are fields from table_name.
● Values 1 and 2 are the values for fields 1 and 2, respectively. SQL allows you the flexibility to list the fields in the order you want, as long as the corresponding values are defined accordingly. The following code is thus identical to the question above:
INSERT INTO table_name (field2, field1, ...)
VALUES (value2, value1, ...);
A variant of INSERT makes it possible to insert many comma-separated records at once, as follows:
INSERT INTO table_name (field1, field2, ...)
VALUES (value3, value4, ...),
(value5, value6, ...),
(value7, value8, ...);
Update
To change the data that is already in the database, the SQL UPDATE statement is used. In the WHERE clause, the condition determines which row is to be changed.
Syntax
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Updating single record
Adjust the EMP NAME column and set the value in the row where SALARY is 500000 to 'Emma'.
Syntax
UPDATE table_name
SET column_name = value
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Emma'
WHERE SALARY = 500000;
Updating multiple record
You can divide each field allocated by a comma if you want to update several columns. Adjust the EMP NAME column to 'Kevin' in the EMPLOYEE table, and CITY to 'Boston' where the EMP ID is 5.
Syntax
UPDATE table_name
SET column_name = value1, column_name2 = value2
WHERE condition;
Query
UPDATE EMPLOYEE
SET EMP_NAME = 'Kevin', City = 'Boston'
WHERE EMP_ID = 5;
Delete
To delete rows from a table, the SQL DELETE statement is used. The DELETE statement usually removes one or more records from a table.
Syntax
DELETE FROM table_name WHERE some_condition;
Deleting single record
Remove the EMPLOYEE table row, where EMP NAME = 'Kristen'. Just the fourth row will be omitted here.
Syntax
DELETE FROM EMPLOYEE
WHERE EMP_NAME = 'Kristen';
Deleting multiple record
Remove the row where AGE is 30 from the EMPLOYEE table. Two rows will be deleted by this (first and third row).
Syntax
DELETE FROM EMPLOYEE WHERE AGE= 30;
JOIN, as the name implies, is a word that means "to combine." In SQL, JOIN means "to join two or more tables together."
The JOIN clause in SQL is used to join records from two or more database tables.
Broadly, there are four types of methods for joining:
● INNER JOIN
● LEFT JOIN
● RIGHT JOIN
● FULL JOIN
Inner Join
INNER JOIN selects records in both tables that have matching values as long as the condition is met in SQL. It returns a set of all rows from both tables that satisfy the condition.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
INNER JOIN table2
ON table1.matching_column = table2.matching_column;
Left Join
The SQL left join returns all of the values from the left table as well as the values from the right table that match. It will return NULL if there is no matching join value.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
LEFT JOIN table2
ON table1.matching_column = table2.matching_column;
Right Join
RIGHT JOIN returns all the values from the rows of the right table as well as the matched values from the left table in SQL. It will return NULL if there is no match in both tables.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
RIGHT JOIN table2
ON table1.matching_column = table2.matching_column;
Full Join
A FULL JOIN in SQL is the product of combining left and right outer joins. The records from both tables are combined in the join tables. It places a NULL in the position of any matches that were not identified.
Syntax:
SELECT table1.column1, table1.column2, table2.column1,....
FROM table1
FULL JOIN table2
ON table1.matching_column = table2.matching_column;
Key takeaway:
- There are numerous joining techniques between two tables to perform.
Unions
To combine the effects of two or more SELECT statements, use UNION. It can, however, remove redundant rows from the result set. In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
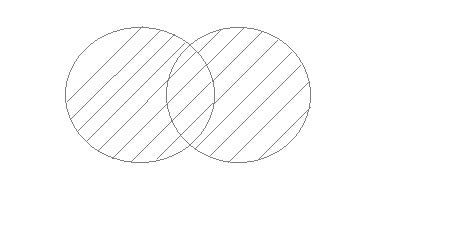
Fig 11: Unions
Example:
First table
ID | Name |
1 | Sam |
2 | Abhi |
Second table
ID | Name |
2 | Abhi |
3 | Bhu |
Query will be: SELECT * FROM First
UNION
SELECT * FROM Second;
ID | Name |
1 | Sam |
2 | Abhi |
3 | Bhu |
Intersection
The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both. The number of columns and datatype must be the same when using Intersect.
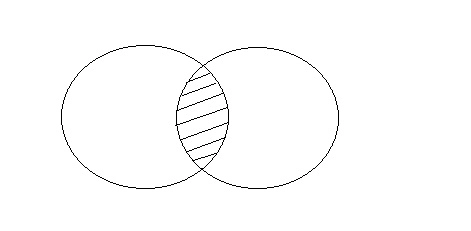
Fig 12: Intersection
Consider the above two tables.
Query will be: SELECT * FROM First
INTERSECT
SELECT * FROM Second;
ID | Name |
2 | Abhi |
Minus
The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
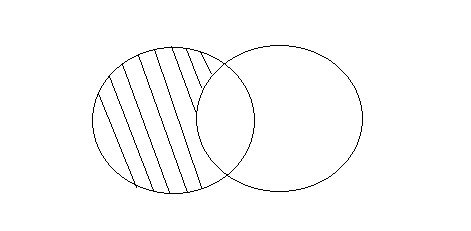
Fig 13: Minus
Consider the above two tables,
Query will be: SELECT * FROM First
MINUS
SELECT * FROM Second;
ID | Name |
1 | Sam |
Cursors
A cursor is a form of temporary memory or workstation. It is allocated by the database server when a user performs DML operations on a table. Database Tables are stored in cursors.
Implicit and explicit cursors are the two types of cursors. These are clarified in the following paragraphs.
Implicit cursors: Implicit cursors are also known as SQL SERVER's Default Cursors. When a user performs DML operations, SQL SERVER allocates these cursors.
Explicit cursors: When a user needs an explicit cursor, the user creates it. For fetching data from a table in a row-by-row manner, explicit cursors are used.
Key takeaway:
- In the case of a union, the number of columns and datatype in both tables on which the UNION operation is performed must be the same.
- The intersect procedure is used to join two SELECT statements together, but it only returns the records that are similar to both.
- The Minus operation combines the results of two SELECT statements and returns only those in the final outcome, which is part of the first package.
- A cursor is a form of temporary memory or workstation.
A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database. For instance, when a row is inserted into a specified table or when certain table columns are being modified, a trigger can be invoked.
In fact, triggers are written for execution in response to any of the following events.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
You may identify triggers for the table, display, schema, or database that the event is associated with.
Benefits of Triggers
● Generating some derived column values automatically
● Enforcing referential integrity
● Event logging and storing information on table access
● Auditing
● Synchronous replication of tables
● Imposing security authorizations
● Preventing invalid transactions
Syntax
Create trigger [trigger_name]
[before | after]
{insert | update | delete}
On [table_name]
[for each row]
[trigger_body]
Key takeaway:
- A trigger is a stored database procedure which is automatically invoked if a special event occurs in the database.
A procedure is a PL/SQL block that performs one or more specific tasks. Procedures in other programming languages are analogous to this.
A header and a body appear in the procedure.
Header: The procedure's name and the parameters or variables passed to the procedure are both listed in the header.
Body: Similar to a general PL/SQL block, the body has a declaration, execution, and exception section.
How to pass parameters in procedure:
When you want to create a procedure or function, you have to define parameters. There is three ways to pass parameters in procedure:
IN parameters: The IN parameter can be referenced by the procedure or function. The value of the parameter cannot be overwritten by the procedure or the function.
OUT parameters: The OUT parameter cannot be referenced by the procedure or function, but the value of the parameter can be overwritten by the procedure or function.
INOUT parameters: The INOUT parameter can be referenced by the procedure or function and the value of the parameter can be overwritten by the procedure or function.
PL/SQL Create Procedure
Syntax:
CREATE [OR REPLACE] PROCEDURE procedure_name
[ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_name];
PL/SQL Drop Procedure
Syntax:
DROP PROCEDURE procedure_name;
Key takeaway:
- A procedure is a PL/SQL block that performs one or more specific tasks.
- Procedures in other programming languages are analogous to this.
References:
- RAMAKRISHNAN "Database Management Systems", McGraw Hill
2. Leon & Leon, “Database Management Systems”, Vikas Publishing House
3. Bipin C. Desai, “An Introduction to Database Systems”, Gagotia Publications
4. Majumdar & Bhattacharya, “Database Management System”, TMH
5. https://www.javatpoint.com




