Unit - 6
Information transfer
The genetic code is nearly universal, and the arrangement of the codons in the standard codon table is highly non-random. The stereochemistry theory is the basis of the three main concepts on the origin and evolution of the code, according to the theory codon assignments are dictated by physicochemical affinity between amino acids and the cognate codons (anticodons); amino acid biosynthesis pathways, is the pathway where the code structure evolved which is depicted by the coevolution theory, and the error minimization theory under which selection to minimize the adverse effect of point mutations and translation errors was the principal factor of the code's evolution. These theories are not mutually exclusive and are also compatible with the frozen accident hypothesis, which means, all life forms share a common ancestor was always the notionand that the standard code might have no special properties but was fixed simply, with subsequent changes to the code, mostly, precluded by the deleterious effect of codon reassignment. Mathematical analysis of the structure and all the possible evolutionary trajectories of the code shows that it is highly strong to translational misreading but there are numerous more robust codes, so the standard code potentially could evolve from a random code through a short sequence of codon series reassignments. Thus, much of the evolution that led to the standard code could be a combination of error minimization and frozen accident, although metabolic pathways and weak affinities between amino acids and nucleotide triplets and contributions from coevolution of the code cannot be ruled out. However, the relevance to primodal evolution is uncertain and such scenarios for the code evolution are based on formal schemes. A real understanding of the code origin and evolution is likely to be attainable only in the translation system and conjunction with a credible scenario for the evolution of the coding principle itself’
Scientists had narrowed down that the genetic material was on chromosomes presentin the nucleus of a cell. However, the exact molecule of DNA was discovered only much later. Let’s take a look at the series of experiments that scientists undertook that brings us closer to the discovery of DNA.
Frederick Griffith
While working with Streptococcus pneumoniae (the bacterium that causes pneumonia) in 1928, Frederick Griffith observed something nothing short of a miracle. He observed a transformation in this bacterium. When this bacterium is grown on a culture plate, after incubation some produce colonies that were shiny in nature (denoted as ‘S’) while some produce rough colonies (denoted as ‘R’).
The S strain bacteria have a specific coat known as the polysaccharide coat which gives rise to smooth, shiny colonies. The R strain lacks this coat and hence, it gives rough colonies. Also, the S strain is virulent and causes pneumonia; while the R strain is non-virulent. He performed the following experiment with these strains and saw different observations.
- S strain → Inject into mice → Mice develop pneumonia and die.
- R strain → Inject into mice → Mice live.
- Heat-killed S strain → Inject into mice → Mice live. (Griffith found that heating kills the bacteria).
- Heat-killed S strain + R strain → Inject into mice → Mice die.
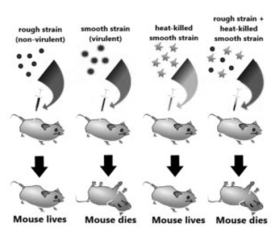
Fig:1 This is the experiment conducted by Griffith that determined the ‘Transforming principle that transformed from the S strain to R strain.
Observations – Not only did the mice injected with the heat-killed S strain + R strain die, but Griffith most importantlyrecovered thelive S strain bacteria from these dead mice.
Conclusions – He concluded that this was because the R strain had somehow been ‘transformed’ by the heat-killed S strain. This he argued was due to the transfer of a ‘transforming principle ‘from the S strain to the R strain, which made the R strain virulent. Although significant, his observations did not identify the biochemical nature of the transforming principle.
Oswald Avery, Colin MacLeod & Maclym McCarty
Avery, MacLeod, and McCarty, the three set were determined to study the biochemical nature of the ‘transforming principle’ identified by Griffith. The observations led to further processes where DNA, RNA, and proteins were purifiedfrom the heat-killed S strain by these people to analyse which macromolecule was responsible for converting the R strain into the S strain.
- Experiment – They first treated the heat-killed S strain with protease enzyme to break down proteins. Subsequently, they treated it with RNAse enzyme and then finallyDNAse to break down RNA and DNA, respectively.
- Observations – It was observed that both protease and RNAse treatments did not affect the transformation of the R strain into the virulent one. Finally, it was observed that the transformation of the R strain was inhibited with DNAses.
- Conclusions – These experiments and observations led to the conclusions that the genetic material was DNA and not protein or RNA. However, the drawback was these discovery and observations was not accepted by all biologists.
Alfred Hershey & Martha Chase
Much earlier, Protein was thought to be the genetic material by mostscientists. In 1952, Hershey & Chase were successful in proving that prove that DNA is the genetic material. They major work was done with bacteriophages – these phages are the viruses that infect bacteria. A bacteriophage attaches and transfers its genetic material into a bacterial cell, – This experiment conclusively showed that the genetic material was not protein but DNA is the genetic material transferred from virus to bacteria.
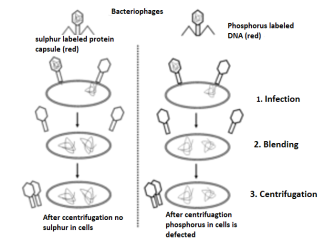
Fig 2: A phage is a small virus that infects bacteria. Its structure consists of a protein coat that holds the inside the coat genetic material. When a phage infects a bacterium, it pushes its genetic material into the bacterium, while its coat remains outside. In a first experiment, T2 phases with radioactive P32-labeled DNA were infected into bacteria. In a second experiment, T2 phages with radioactive S35-labeled protein were into bacteria. In both experiments, bacteria were breakup from the phage coats by blending process followed by centrifugation. Most of the radioactivity was found in the infected bacteria during the first experiment, most of the radioactivity was found in the phage coat in the second experiment. These experiments that were demonstrated proved that DNA is the genetic material of phage and that protein does not transmit genetic information.
Single-strand DNA-binding protein (SSB) is a protein that is present in Escherichia coli (E. Coli) bacteria, this bacteria binds to single strands present on the regions of deoxyribonucleic acid (DNA). Single-stranded DNA is featured in every aspect of DNA metabolism: repair, replication, andre combination and also stabilize this single-stranded DNA, the functions of numerous proteins that are involved in all these processes are modulated by the SSB proteins.
Active E. Coli SSB is composed of four 19 kDa subunits that are identical. At different modes the binding of single-stranded DNA to the tetramer can occur, with SSB that occupydifferent numbers of DNA bases depending on various factors, including salt concentration. The various functions of binding modes require further work to elucidate it.
The genetic material in most organisms of all forms of life is DNA or Deoxyribonucleic acid; however, in some viruses, it is RNA or Ribonucleic acid. Two polypeptide chain is found in DNA molecule i.e. chains with multiple nucleotides.
Structure of Polynucleotide Chain
A nucleotide is made of the following components:
Pentose sugar – A pentose sugar is a 5-carbon sugar compound. In RNA the sugar is Ribose whereas in case of DNA, this sugar is deoxyribose.
- The Phosphate groups
- Nitrogenous base – Thereare of two types – Purines and Pyrimidines. Purines include Adenine and Guanine whereas pyrimidines include Cytosine and Thymine. In RNA, thymine is replaced by Uracil.
Pentose sugar +Nitrogenous base + (via N-glycosidic linkage) = Nucleoside.
Nucleoside + phosphate group (via phosphoester linkage) = Nucleotide.
Nucleotide + Nucleotide (via 3′-5′ phosphodiester linkage) = Dinucleotide.
Many nucleotides linked together = Polynucleotide.
A polynucleotide has a free phosphate group at the 5′end positionof the sugar and this is called the 5′ end. Similarly, the sugar also has a free 3′-OH group at the other end of the polynucleotide which is known as the 3′end. The backbone of a polynucleotide chain consists of phosphate groups and pentose sugars;however, the nitrogenous bases project out of this backbone.
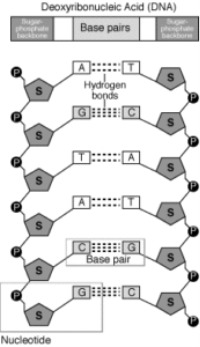
Fig 3: Polynucleotide of DNA and its components
Double Helix Structure
DNA is a long polymer and therefore, it makes it difficult to isolate from cells in an intact form. Therefore, it becomes difficult to study its structure. However, in 1953, James Watson and Francis introduced the ‘double helix’ model of the structure of DNA, from Maurice Wilkins and Rosalind Franklin based on their X-ray diffraction data.
A specific nature of the polynucleotide-base pairing is revealed in this model. It refers to the hydrogen bonds that connect the nitrogen bases on opposite DNA strands. The base pairing gives rise to strands that are complementary in nature i.e.if the sequence of bases on one strand is known, the bases on the other strand can be predicted. Further, if each DNA strand acts as a template for synthesis (parent) of a new strand, then thestrand that is formed which is new and double-stranded DNA (daughters) will be identical to the DNA ofparental strand.
Salient Features of DNA -Helix
- The structure consists of two polynucleotide chains where the sugar and phosphate group form the backbone of the structure and the nitrogenous bases project inside the helix.
- The two polynucleotide chains have anti-parallel polarity i.e. if one strand has 5′ → 3′ polarity, on the other hand the other strand has 3′ → 5′ polarity.
- The bases on the opposite strands are connected through hydrogen bonds that form base pairs (bp). Adenine always binds to thymine with two hydrogen bonds from the opposite strand and the other way round. Guanine bonds with cytosine with three hydrogen bonds from the opposite strand and vice-versa. Subsequently, a purine always pairs with a pyrimidine on the other strand, giving rise to a uniform distance between the two strands of the double helix.
- The two strands coil in a right-handed fashion. Each turn of the helix is 3.4nm (or 34 Angstrom units) that consist of 10 nucleotides. These nucleotides are placed at a distance of 0.34nm (or 3.4 Angstrom units).
- The presence of the base pairs makes the helix more stable as these base pairs that arestacked over one another and the hydrogenbonds hold the bases together.
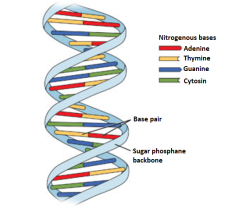
Fig 4: The double helix structure of DNA, the bases on the opposite strands are connected through hydrogen bonds that form base pairs, the helix is stable because of the base pairs.
Packaging of DNA Helix
The length of DNA in a typical mammalian cell, it is approximately 2.2 meters. The dimension of a typical nucleus is only about 10-6 meters! Then, the question arises as to how does such a long polymer fit in the nucleus of a cell?
In Prokaryotes like E. Coli, which do not have awell-defined nucleus. Here, the positively charged proteins andthe negatively-charged DNA are held together in large loops in a structure called ‘nucleoid’. In Eukaryotes, the DNA is present in the Nucleus and the organization of DNA in the nucleus is much more complex.
- The negatively-charged DNA is wrapped around a positively-charged (protein) histone octamer i.e. octamer aunit consistingof 8 histone molecules. This forms a structure called ‘Nucleosome ‘. Histones are positively-charged proteins that are rich in basic amino acids – arginines and lysines. A typical nucleosome has 200basepairs of DNA helix.
- In the Nucleus many nucleosomes join together to form a thread-like structure – Chromatin. When observed under the microscope, the nucleosomes in chromatin appear as ‘beads-on-string’.
- The chromatin is packaged to form chromatin fibres which are further coiled and condensed to form chromosomes. The higher-level packaging of chromatin requires another set of proteins – Non-histone Chromosomal (NHC) proteins.
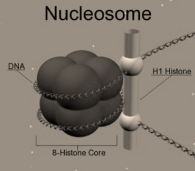
Fig 5: Nucleosomes are the negatively-charged DNA wrapped around a positively-charged (protein) histone octamer i.e. octamer aunit consisting of 8 histone molecules. This forms a structure called ‘Nucleosome ‘.
The relationship between the sequence of nucleotides in DNA or mRNA and the sequence of amino acids in a polypeptidechain is called as the genetic code.
Characteristics of Genetic code
- Triplet code
- Start signal
- Stop signal
- Universal code
- No ambiguous codons
- Related codons
- Commaless
- Polarity
- Degeneracy of code
It presides over the transmission of genetic information to proteins, i.e., it makes up the protein synthesised by each cell by determines the sequence of amino acids in the polypeptide chain.
Genetic information is coded in DNA by the of four bases: two purines (guanine and adenine and) and two pyrimidines (cytosine and thymine and).
The three bases present in the adjacent sequence (a codon) will determine the insertion of an amino acid that is specific in nature.
In RNA, the amino acid uracil replaces thymine, the specific three consecutive nucleotides present in DNA of the chromosome determines the insertion of a specific amino acid in suitable places in a protein. In plant and Animal kingdom the genetic code is almost universal throughout the prokaryotic.
However, there are two known exceptions: In ciliated protozoans, the triplets AGA and AGG are read as termination signals instead of as Larginine. This is also observed of in human mitochondrial code, where, in addition, uses AUA as a code for L-methionine (instead of L-isoleucine) and UGA for L-tryptophan (instead of a termination signal).
The biochemical basis is that
The set of DNA and RNA sequences that determine the amino acid sequences usedin the synthesis of an organism's proteins, and nearly universal in all organisms.
For protein synthesis a set of 64 codons corresponding to the 20 amino acids are used and as the signals for starting and stopping protein synthesis.
Degeneracy of Genetic Code:
There are two methods by which the same amino acid is specified by two or more codons:
1. “isoacceptortRNAs” is a codon formed when the tRNAs accepts the same amino acid andare different for different synonymous codons. The codon formed is one such tRNA and they differ in anticodons. For example, one of the tRNAs carrying leucine is tRNA1leu with anticodon 3′ GAC5′, while the other is tRNA2leu with anticodon 3′ GAG5′.
2. A single type of tRNA pairs with two or more synonymous codons. For example, tRNA. Accepting the amino acid alanine in yeast (tRNAaIa) bears the anticodon 3′ CGI5′ that can pair with the codons 5′ GCU3′, 5′ GCC3 and 5′ GCA3′ on mRNA Crick in 1966 proposed the “wobble hypothesis” to explain the pairing of a single type anticodon with synonymous codons.
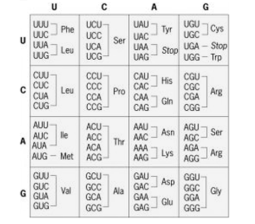
 Fig 6: The standard Genetic code
Fig 6: The standard Genetic code
According to the Wobble hypothesis, the base position at the 5′-end of anticodon is the “wobble position”. Two bases of anticodon from 3′-end are complementary to the two bases of the codon (in mRNA). The base at the wobble position can pair with different bases. For example, a single type of tRNAgly with the anticodon 3′ CCI5′ can pair with the codons 5’GGC3′5’GGU3′, and 5’GGA3′ specifying the amino acid glycine.
Thus inosine (I) at the wobble position can pair, with C, U and A in the codon. Similarly, we can pair with A and G, while G at the wobble position can pair with C and/U.
Universality of the Genetic Code:
The meaning of the universality of genetic code means that the same genetic code is utilized by all the organisms. For example, the lac+ gene producing the enzyme P-galactosidase, this enzyme is produced in human fibroblast tissue culture cells deficient of this enzyme is also seen in E. Coli. When the heamoglobin mRNA molecules are injected into the Xenopus eggs, protein synthesis occurs and the α and β polypeptide chains are produced. However, variation in the genetic code has been observed in mitochondria where some of the condons are differently translated.
The termination codon is UGA (termination codon in universal code) specifies tryptophane, similarly for AUA (for isoleucine in universal code) specifies methionine in mitochondria. Furthermore, the genetic code differs in the mitochondria of different organisms. For example, CUA is a codon for threonine in yeast mitochondria, while it specifies leucine in Drosophila and mammalian mitochondria.
So, it may be concluded that the genetic code is not entirely universal.
When two mutants combine to restore the phenotype for a particular character the process is called Complementation. For example, when two mutant strains are matedit results in a wild type phenotype due to complementation. Thus, alleles which are wild type express its phenotype in offspring due to complementation effect. Moreover, the position of mutation determines importance of complementation. To determine if the gene is same or in a different geneis determined by a complementation test, infact when mutations are present in different genes only then complementation is possible.
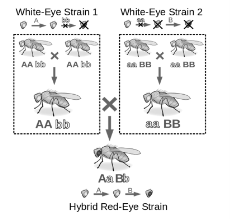
Fig 7: The experiment is an example of complementation process, where two mutants are mated that results is a wild Phenotype. The functionality of a particular pathway is determined by Complementation. Therefore, in various biochemical pathways the products are deduced by the phenomenon of complementation.
Recombination is the process when the genetic material between two normal organisms are mixed to produce a recombinant organism or a mutant. The resulting mutant can be harmful or beneficial product. Moreover, the process of recombination is deliberately to doneintroduce positive characters to the new organism. In genetic recombination, the two parents contribute to form the mutant with altered genetic composition.

Fig 8: Shows recombination. That occurs when when the genetic material between two normal organisms are mixed to produce a recombinant organism or a mutant
Genetically modified organisms are produced by Recombination is a promising technique for the present era. The recombinant organism is produced through different techniques. Plasmids which act as microbial vector systems play a key role in recombination. In addition, bacteriophages are also used in genetic recombination. Furthermore, in genetic recombination physical mutagens such as radiation, chemicals are of great importance.
In recombination, the two normal phenotype genes or organisms recombine to produce a genetically mutant organism. The reverse happens in Complementation where two genes or two organisms that are mutated complement each other and result in a genetically normal phenotype. During recombination, the mutant can either contain harmful characters or result in beneficial characters. Moreover, complementation is a more efficient technique in comparison to recombination. Thus, this summarizes the difference between complementation and recombination.
References:
- DNA the Secret of Life- James Watson
- The Gene-Siddhartha -Mukherjee.
- Genetics and Evolution of Inheritance- Jill Bailey.




