Unit - 3
IoT Application Development
Integration refers to the process of making disparately designed programs and data operate well together. In the context of establishing end-to-end IoT business solutions, IoT integration means making the combination of new IoT devices, IoT data, IoT platforms, and IoT applications — combined with IT assets (business applications, legacy data, mobile, and SaaS) — function effectively together. The IoT integration market is defined as the set of IoT integration capabilities that IoT project implementers require to integrate end-to-end IoT business solutions successfully.
There are several reasons why you might want to facilitate direct and automatic data entry into a computer system while designing a custom application to support your organization's business processes.
Perhaps your business has field personnel, such as sales reps or inspectors. Rather than logging data on a dedicated equipment in the field and manually transferring it to the office, these experts may utilize an iPad to collect data, with the data automatically synchronizing to a centralized database.
Device integration has the potential to revolutionize business processes in a multitude of domains and ways.
Let's look at five of the most important advantages that device integration can provide in terms of driving more efficient procedures.
- Improved data accuracy
An automated approach increases the accuracy of data collected by an organization, in part by removing the danger of data being erroneously transferred or lost in transit to a centralized system. Furthermore, an integrated approach allows for automated data validation, resulting in higher-quality data and less opportunities for human error.
2. Greater efficiency
A process with connected devices is substantially more efficient when properly executed, allowing a team to focus on higher-value activities rather than manually transmitting data. Because data is processed as soon as it is collected, not only does the data collection process become more efficient, but an organization may make judgments or act on more up-to-date data.
3. More effective decentralized team
A decentralized team can have regular access to relevant data with effective device integration, allowing the support team to monitor and analyze data from any location. This enhanced coordination can be a major benefit for large or small firms dispersed across the country or the globe.
4. More reliable response strategies
Automated monitoring and extensive logging are possible because to thoughtful device integration, which means that a system could trigger alert conditions in particular instances. Rather than depending solely on human inspection, firms may verify that automated responses to specific mistake scenarios are consistent and trustworthy.
5. An increasingly rich archive of data
Collecting a body of logged data allows firms the capacity to examine it afterwards, possibly even refining their business processes further based on the data they collect, much like any database system. Device integration entails creating a growing and interconnected repository of usable data, which can be quite valuable over time.
Key takeaway
Integration refers to the process of making disparately designed programs and data operate well together.
In the context of establishing end-to-end IoT business solutions, IoT integration means making the combination of new IoT devices, IoT data, IoT platforms, and IoT applications.
To assess traffic on a busy highway, researchers used a ThingSpeak, Raspberry Pi 3 Model B, and a webcam to construct an Internet of Things (IoT) based smart real-time traffic monitoring system. The Raspberry Pi device should then be connected to the machine for deployment and configuration of the traffic-monitoring algorithm. ThingSpeak is a cloud aggregator that allows you to store, analyze, and visualize data online. Analytics are employed everywhere in the Internet of Things (IoT):
- The edge node
- Offline on the desktop
- In the cloud
We've demonstrated how to monitor real-time traffic data on a busy roadway and how to collect real-time data on the cloud. After storing the aggregated data on the cloud, the edge device can perform analytics, and then the cloud data can be analyzed. The diagram shows a workflow analysis framework and how to execute online analysis on cloud data. ThingSpeak is used for both storage and analysis in this system.
As indicated in Fig, the suggested architecture based on the Internet of Things might include four layers. The Sensing layer, Data processing layer, IoT sensor data analysis layer, and Application layer are the four layers.
- Session layer - This layer is responsible for collecting data from various IoT devices. In the suggested framework, this is the lowest layer that can be found. It gathers different heterogeneous types of data gathered from heterogeneous IoT devices such as sensors, actuators, protocols, and data formats, among others. The large volume of big data is sent to the next level layer, the Data processing layer, for data analysis and raw data processing.
2. Data processing layer - This layer is responsible for obtaining the required data from the raw data obtained by the physical layer. Feature extraction and Foreground Detector data are the two sub-modules that make up the data processing layer. To manage real-time data, feature extraction is employed to extract raw data using camera vision algorithms such as SPP-net and GMM. This layer is responsible for obtaining the required data from the raw data obtained by the physical layer. Feature extraction and Foreground Detector data are the two sub-modules that make up the data processing layer. To manage the real-time data, feature extraction is employed to extract raw data using camera vision algorithms such as SPP-net and GMM.
3. Data analysis layer - This is the most important layer in the proposed framework. This layer has had the Simulink model applied to it. It will use the data once it has been pre-processed on the data processing layer to annotate the IoT sensor data. The Simulink model is used to reduce the ambiguity of the foreground detector data. The domain knowledge systems based on ThingSpeak have employed context-aware data to forecast real-time traffic statistics in order to reduce traffic congestion and unexpected delays.
4. Application layer - This layer is used to analyze and visualize the data collected from IoT sensors for users on the ThingSpeak cloud platform. In real-time settings, this layer generates traffic alerts and vehicle counts. These data can be used in IoT smart city applications such as smart traffic, smart homes, smart grids, and smart health, among others.

Fig 1: The proposed framework for IoT sensor data analysis
Your computer's physical capacity is no longer a factor in storage capacity. There are numerous choices for storing your files while preserving space on your computer, phone, or tablet. You can unload files onto a physical storage device if your devices are slow and running out of capacity. Better still, store your information to the cloud using the latest storage technology.
Unstructured data used for?
Textual unstructured data can be searched for simple content. Traditional analytics solutions are designed to work with highly organized relational data, therefore they're useless for unstructured data like rich media, consumer interactions, and social media.
Big Data and unstructured data are frequently associated: according to IDC, 90 percent of these massive databases are unstructured. New technologies for analyzing these and other unstructured sources have lately become accessible. Such platforms, which are powered by AI and machine learning, operate in near real-time and educate themselves depending on the patterns and insights they unearth. These systems are being used on big unstructured datasets to enable applications that have never been conceivable before, such as:
● Examining communications in order to ensure regulatory compliance.
● Customer social media chats and interactions are being tracked and analyzed.
● Obtaining trustworthy information on common customer behavior and preferences.
Cloud storage
Cloud storage, while not technically a device, is the newest and most adaptable sort of computer storage. The "cloud" is a massive collection of servers situated in data centers all over the world, rather than a single location or thing. You're saving a document on these servers when you save it to the cloud.
Because cloud storage stores everything online, it saves space by not using any of your computer's secondary storage.
Cloud storage offers much better storage capabilities than USB flash drives and other physical choices. You won't have to search through each device to find the proper file this way.
External hard drives and solid-state drives (HDDs and SSDs) were formerly popular because of their portability, but they, too, fall short when compared to cloud storage. There aren't many external hard drives that are small enough to fit in your pocket. They are still physical devices, despite being smaller and lighter than a computer's internal storage drive. The cloud, on the other hand, may accompany you everywhere you go without taking up physical space or exposing you to the physical risks of an external drive.
External storage devices were also popular as a speedy way to transfer files, but they're only useful if each actual device can be accessed. As many firms increasingly function remotely, cloud computing is flourishing.
Creating a Cloud Strategy for Unstructured Data
Unstructured data is becoming a bigger issue for businesses. A growing number of these businesses have billions of files and storage capabilities exceeding 1 terabyte. These businesses are turning to the cloud to help them deal with some of their unstructured data management issues.
The issue is that most cloud solutions isolate unstructured data storage into its own silo. IT must maintain this separate silo on its own, employing a completely different storage software stack than the organization's on-premises storage. As a result, the company runs one file system in the cloud and another on-premises.
Developing an Unstructured Data Strategy for the Cloud
When developing an unstructured data strategy that takes use of the cloud, IT must ensure that the solution can support all cloud use cases. Unstructured data can be stored on the cloud, and cloud storage can be used as an archive tier. They can also use cloud computing to quickly scale up thousands of processors to evaluate an unstructured data set. Companies may also want to use the cloud to enable distributed access to a shared data set.
On-Premises Lives On!
At the same time, many enterprises will continue to rely on their on-premises processing and storage capabilities to handle and store unstructured data volumes on a daily basis. When it comes to processing and storing unstructured data, both on-premises and cloud storage have distinct advantages. Each organization's strategy should ensure that both organizations' distinct talents are utilized.
Same File System Software On-Premises and in the Cloud
In an ideal world, businesses would seek out solutions that allow them to execute file system software both on-premises and in the cloud. Because the two places are using the same software, they can communicate with one another. It also eliminates the need for IT to learn two alternative approaches to managing the same data set. Applications can now move smoothly between on-premises and cloud environments without requiring any changes.
Because the two instances use the same file system software, both on-premises and in the cloud, they may collaborate. Organizations can, for example, employ the storage solution's replication software to duplicate data to the cloud-based file system. It also means that the cloud file system can be used as an archive by the on-premises file system. The file system software must allow the company to swiftly detect inactive material and move it to a cloud archive storage tier to enable archiving. Archiving has become a simple issue of moving data from one file system to another from the standpoint of the file system.
Each instance of the file system software, whether on-premises or in one of the supported cloud providers, can take advantage of the specific capabilities accessible to it. For example, each site may have a distinct scaling model. Because CPU resources are relatively static on-premises, the software can scale by deploying nodes with pre-defined CPU and storage capacity. Because CPU resources are available by the minute in the cloud, software may allow for momentary, huge scaling of processing to speed up IO-intensive applications. When the job is finished, the file system software can "return" any unused processing power.
Solving the Remote Employee Problem
Organizations can also provide distributed and secure data access by using the same software in the cloud as they do on-premise. For instance, if a company wishes to allow a new employee to work on data from a remote location, it can migrate the data to a cloud-based file system.
The employee can then use cloud processing to work on the data set by creating a workstation instance in the cloud. In their remote workplace, the individual does not need to download data or have a high-powered desktop. All of the processing and data transfer is handled by the cloud. The device that is used to connect to the cloud workstation is similar to a terminal. Following the completion of the task by the remote worker, the business can view the data in the cloud NAS instance or relocate it back to its on-premises instance.
Storage Swiss Take
The key to a successful cloud strategy for unstructured data is to use the same NAS software on-premises and in the cloud so that data may flow effortlessly between the two. With this capacity, IT can take advantage of the best of both on-premises and cloud capabilities.
Key takeaway
Your computer's physical capacity is no longer a factor in storage capacity. There are numerous choices for storing your files while preserving space on your computer, phone, or tablet.
Big Data and unstructured data are frequently associated: according to IDC, 90 percent of these massive databases are unstructured.
Cloud storage, while not technically a device, is the newest and most adaptable sort of computer storage.
The "cloud" is a massive collection of servers situated in data centers all over the world, rather than a single location or thing.
Authentication and authorization are two crucial components in the ongoing effort to keep Internet clients and devices safe. Because, at its most basic level, the Internet of Things is just devices—from simple sensors to intricate automobiles and mobile devices—connecting together to share data, these components are critical to any IoT project. These connections need to be protected, and authentication and authorization can help.
Although there are some parallels between the two notions, they each represent something very different in this context:
Authentication
The process of recognizing the device is known as authentication. The authentication method for Message Queuing Telemetry Transport (MQTT) is to ensure that the device's client ID is valid, that is, that the ID belongs to the device in question.
Authorization
Authorization is a method of associating a certain device with specific permissions. Authorization is split into two steps using Edge Connect:
● Associating devices with groups
● Creating a link between groups and issues
Authentication and authorization can be divided into two categories: device-based and user-based.
Let's take a closer look at each of them and how they're used.
Device based authentication and authorization
Device-based authentication and authorization will most likely be utilized for devices that do not have operators (or users), or for devices where the connection is not dependent on the operator. An automobile is an excellent example: whether or not the car has user-specific communication—such as running user applications or offering user-specific configurations—the device (i.e., the car) will most likely wish to be linked to share car-specific information. Diagnostics, command and control, software updates, and advanced feature availability are all examples of data that is exclusive to the car rather than the driver.
Client-side certificates saved in the automobile are used for device-based authentication and authorization. During the TLS handshake, authentication takes place. The automobile will send up its certificate, which will be signed by a preset signing authority, as well as information signed by its private key, as part of the handshake. The device is authenticated after the handshake is completed, and the client ID is taken from the certificate. The client ID for an automobile might be the vehicle identification number (VIN).
After the car has been validated and the client ID has been determined, the proper authorization groups must be determined. A device can join an authorization group simply by connecting. Because the device in this case is a car, all automobiles that connect will be assigned to the authorization group "car." Additional groups, just like the client ID, can be derived from the certificate. The VIN of our car, for example, can be used to extract a range of groups.
The following is a schematic of a typical VIN:
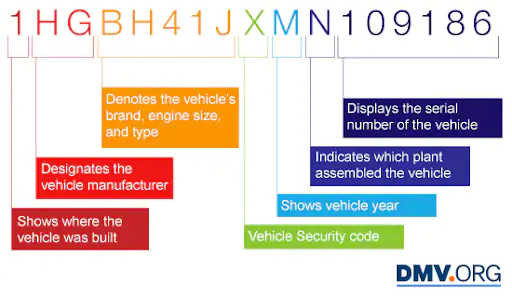
Fig 2: VIN
We already know the manufacturer in this scenario because the client has already been validated by the manufacturer. However, the certificate/VIN can also be used to derive the brand and year. The authorization group “B-BH” (which stands for “Brand=BH”) and the group “Y-M” (which stands for “Year=M”) would be allocated to the car in this situation. Other fields that may include features can be retrieved and turned into groups as well. The car's device-based authorization groups would be something like: car, B-BH, Y-M, NAV, assuming we pulled information from another field and established that the car was a premium package with a navigation system.
User - based authentication and authorization
The person is the focus of user-based authentication and authorization rather than the device. While a device must still offer a unique device ID, the authorization groups in this case are determined by the user's identification. Edge Connect supports JSON Web Tokens for this type of connection (JWT). The user will log in with credentials on the device by sending a request to a JWT server (not included with Edge Connect); once verified and authorized, a JWT token will be returned, as shown in Figure A below. Claims in this token include the client ID, user, authorization groups, and an expiry date. The token is also signed to confirm that it is legitimate.
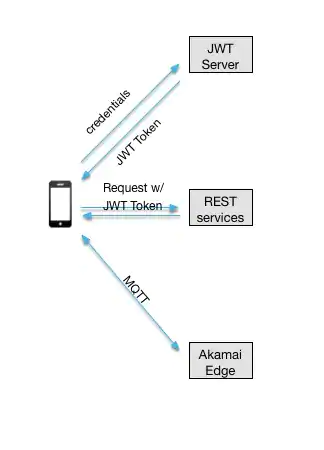
Fig 3: JWT
The next step
The next step is to link these authorizations to subjects after a device or user has been authenticated and allocated authorization groups (topics are basically named channels, or queues, that messages are published against). The first step in the binding process is to create subject access control lists, or "topic ACLs." Topic ACLs are made up of a topic or a topic filter (i.e., a wildcard topic) and a list (or lists) of publishers and/or subscribers. ACLs with topic filters, publishers, and subscribers are shown in the graph below. The first ACL illustrates a typical wildcard subject filter with PUB1 as the sole publisher and SUB1 as the single subscriber, as well as a typical wildcard topic filter.
Any connection to the PUB1 permission group would be able to publish to any subject that met the filter's requirements. Thus, a connection to the PUB1 permission group could publish to topic/foo, topic/bar, and topic/foo/bar in this situation. The # wildcard means that “topic/” can be followed by any number of paths; if the topic filter had been topic/+, topic/foo and topic/bar would have matched, but topic/foo/bar would not.

It's worth noting that the percent c path and the percent u path are defined in two different sets of ACLs. Permissions to the topic are granted to devices whose client ID matches percent c in the percent c ACLs. Only a device with the client ID dev0001 would be able to publish to device/dev0001/up for the device/percent c/up topic. Anyone in the SUB2 authorization group might, of course, subscribe to (or read from) the topic. A device-specific topic is what it's termed. Only the device having an authorized client ID that matches the subject can publish to (or subscribe to, in the second ACL) that topic.
The percent u works in the same way as the percent c, except it uses the username instead of the client ID. User-specific themes are what they're called. The connection must send a JWT token with a username in a claim—often the sub(ject) claim—to obtain access to these subjects as a user. For user-based services, this form of topic ACL is ideal. Chat is a good example of such a service because it allows users to join from their mobile device, desktop device, and web-based device all at once. They must all have unique client IDs, but they're all serving the same person. As a result, it's a user-specific subject.
All ACLs are examined while determining permissions, therefore one or more ACLs may apply to a certain topic. There are five ACLs in all, as shown in the chart below, with the subject my/topic/foo/bar matching three of them. Pub1, pub2, and sub1, sub2, sub3 are the publishers and subscribers in this scenario, accordingly. The authorization groups are cumulative when more than one ACL is matched, as seen below.

Key takeaway
Authentication and authorization are two crucial components in the ongoing effort to keep Internet clients and devices safe. Because, at its most basic level, the Internet of Things is just devices—from simple sensors to intricate automobiles and mobile devices—connecting together to share data, these components are critical to any IoT project.
The process of recognizing the device is known as authentication.
Authorization is a method of associating a certain device with specific permissions.
References:
- Olivier Hersent, David Boswarthick, Omar Elloumi “The Internet of Things key applications and protocols”, willey
- Jeeva Jose, Internet of Things, Khanna Publications
- Michael Miller “The Internet of Things” by Pearson
- Raj Kamal “INTERNET OF THINGS”, McGraw-Hill, 1ST Edition, 2016
- ArshdeepBahga, Vijay Madisetti “Internet of Things (A hands-on approach)” 1ST edition, VPI publications,2014
- Adrian McEwen, Hakin Cassimally “Designing the Internet of Things” Wiley India
- Https://storageswiss.com/2019/09/26/creating-cloud-strategy-for-unstructured-data/
- Https://www.researchgate.net/publication/334380484_A_Framework_for_IoT_Sensor_Data_Acquisition_and_Analysis
- Https://artandlogic.com/2015/01/device-integration-5-ways-to-improve-your-business-processes/




