UNIT-2
Syntactic Analysis
To understand the need of having a good amount of context-free grammar we need to first get familiar with a term which is known as a constituency. This simply propagates the fact that all the strings or words present in the string behave like independent single units. These units come together to constitute the corpus. Grammar is simply based on the use of this constituency to develop the language further.
Let us consider a noun phrase, which is essentially a string of words that has a noun followed by an object in it. We can look at some examples of the same.
- Clifford the horse
- The Nazi Germans
- They
All of these may not make complete sense while being written alone. They need to have a few more words as part of the entire constituent that surrounds the noun phrase. We can simply see this when we assign a certain number of verbs or verb phrases to these to get a better idea.
- Clifford the horse trots away.
- The Nazi Germans tortured the Jews.
- They wandered off in the forest.
With this simple addition, the sentence now makes complete sense. However, to be recognized and understood, the sentences need to be placed as a constituent of different phrases as learned in the previous unit. Certainly, noun phrases would most definitely occur before verbs in the sentence.
The constituency of a sentence can be further understood by placing a phrase in different parts of a sentence that would mean the same. The structure of the statement is one that has an immense understanding of it. If the phrase is placed at the start it is known as preposed and if it is placed at the end it is known as postposed. Let us see some examples of the same.’
- On November eight, I would like to travel to New Delhi.
- I would like to travel to New Delhi on November eight.
As you can see the first example has the phrase ‘on November eight’ at the start of the sentence and the second example has it at the end. However, both of the examples mean the same thing in their entirety. Now that we know how a sentence is constituted and formed, we can move on to understanding Context-free Grammar (CFG).
Context-free Grammar (CFG) is one of the most commonly used nomenclatures to model a certain sentence or phrase in the English language. This can also be done in any other natural language that could be used. CFG makes use of the constituents to make a fundamentally correct sentence. This type of grammar is also known as Phrase Structure Grammar.
There are a few rules from the base of writing appropriate Context-free grammar that could be used to structure the constituents in a string. Let us look at some of the rules which are given below carefully. Each rule is essentially made up of a left side as well as a right side in a language. The left side shows the category whereas the right side shows the constituent parts that make up the left.
CFG is made up of 4 very important parts which are given in the set C = ( V, S, T, P )
- V – Set of variables
The set V can have examples of V = {S, NOUN, VERB, AUXILLARY VERB, PROPER NOUN, VP, Det, PREPOSITION, etc.}
NP = Determiner noun
VP = Verb determiner noun
Det = ‘the’, ‘a’
Preposition = ‘around’, ‘near’
Verb = ‘worked’, ‘ate’
- T – Set of terminal symbols
The set T can have examples T = {‘maggi’, ‘ate’, ‘a’, ‘boy’, ‘knife’, ‘with’}
- S – Set of start symbols
- P – Set rules for production
We can understand the same by looking at an example of how the same is formed with the help of a flowchart.
Derivation:
S = NP + VP
= Det + Noun + VP
= The + Noun + VP
= The + child + VP
= The + child + Verb + NP
= The + child + ate + NP
= The + child + ate + Det + NP
= The + child + ate + a + NP
= The + child + ate + a + mango
Sentence = “The child ate a mango.”
Another example in terms of a flowchart is given below as
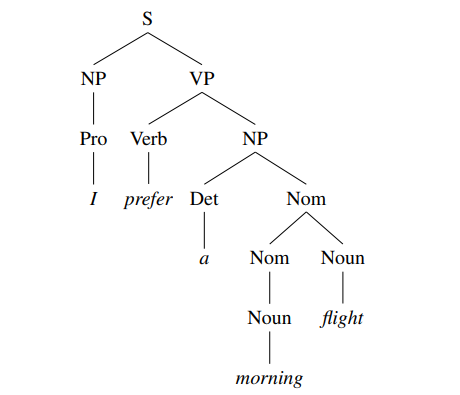 |
Fig. Description 1: Flowchart breakdown of the entire table into 2 parts
Noun Phrase: A noun phrase can either be constituted of a ‘Proper Noun’ or a ‘determiner’. This is followed by a Nominal which can have different types of nouns that are part of it.
NOUN PHRASE = PROPER NOUN / DETERMINER NOUN + NOMINAL (NOUN)
Key Takeaways:
- CFG is made up of 4 very important parts which are given in the set C = ( V, S, T, P )
- A CFG is known to be in Chomsky Normal Form when all of the production is in a particular form which is A BC OR A a
Grammar is the most important part of any language. Having a grammatically correct sentence allows fluent communication with the user to get the task done correctly. This can be further divided into different types of ways to get an idea of having appropriate rules that are used for grammar.
- Sentence Construction
The sentence is made up of words that are made up in turn of letters. The sentence forms part of a string which further is part of the corpus. People need to understand that if a sentence is well constructed it would most definitely mean a well-defined and inferentially active corpus. There are 5 types of sentences as given below:
- Assertive sentence
This sentence is also known as a declarative sentence which allows the user to say something without having a point of emphasis or interrogation. This could just be a plain sentence that does not ask any person to work.
Model = NP
E.g. 1. He rides a bike.
2. They swam across the river yesterday.
- Imperative sentence
This type of sentence is used when a person wants to request or show some authority for a work that is to be done. It usually begins with a Verb Phrase because people show their authority through verbs.
Model = VP
E.g. 1. Get me to work fast.
2. Show me the fastest route
- Yes/ No question
These are as simple as the name suggests. The answer in reply to this interrogative question would either be a yes or a no. The user can elaborate on the answer if they wish. However, a single word answer would also suffice. They mainly begin with an auxiliary verb. It could also be a request just as the above examples but with an interrogation.
Model = Aux. Verb + NP + VP
E.g. 1. Do any of these cars work?
2. Could you please show me to the nearest hotel?
- Wh question
The WH-sentence is one of the most complex forms out of all. This is because the answer could be anything including a simple yes/no as a reply. They must contain a Wh-question as part. Some examples of the same are {who, where, what, which, when, whose, how, why}.
Model = Wh-NP + VP
E.g. 1. Which car company does this belong to?
2. What airlines fly from New Delhi to Mumbai?
- Non-Wh question
This type of sentence would be speaking about the wh is not the main subject in the sentence. There is also another subject that is part of the entire sentence. There would be a ‘wh phrase’ as well as a regular ‘NP phrase’.
Model = Wh-NP + Aux. Verb + NP + VP
E.g. 1. What flights do you have from New Delhi to Mumbai?
Key Takeaways:
- Sentences can be transformed into different types with the help of features and components identified in them
Having a well-designed corpus would mean some strings make complete sense in the same and following grammatical meanings. Treebanks are essentially used to assign a parse tree to the string. This would simply mean that it is possible to go through a corpus and build a treebank for the same that shows a similar correspondence as to the same corpus.
To get a better understanding of the above let us look at a famous example of a treebank which is also known as the Penn Treebank Project. This treebank was made from the corpora of the Brown and WSJ pages. There was a type of syntactic movement in the treebank that was made to get a better idea. Below are representations of the same in terms of the sentence, “That cold, empty sky was full of fire and light.”:
- Parsed sentences
Fig. No. 2

Fig. Description 2: Parsed sentences breakdown entirely
- Treebank
 |
Fig Description: Breakdown of the word giving a detailed analysis
Treebanks can also be used in the form of grammar. They are the main basis on which the user can use tags that are given to the same to get the entire NP rules. We can see below that there are some rules which are made to sustain the NP form of conduct. A sentence is made up of S = NP + VP
Now,
NOUN PHRASES:
NP = DT + JJ + NN
NP = DT + JJ + NNS
NP = DT + JJ + NN + NN
NP = DT + JJ + JJ + NN
NP = DT + JJ + CD + NNS
NP = RB + DT+ JJ + NN + NN
NP = RB + DT + JJ + JJ + NNS
NP = DT + JJ + JJ + NNP + NNS
NP = DT + JJ + JJ + VBG + NN + NNP + NNP +FW + NNP
NP = DT + JJ + MMP + CC +JJ +JJ + NN + NNS
VERB PHRASES:
VP = VBD + PP
VP = VBD + PP + PP
VP = VBD + PP + PP + PP
VP = VBD + PP + PP + PP + PP
VP = VB + PP + ADVP
VP = VB + ADVP + PP
VP = ADVP + VB + PP
VP = VBP + PP + PP + PP + PP + ADVP + PP
Hence, we are certain that a sentence can be made up of a noun phrase and well as a word phrase. Knowing the appropriate constituent compositions that can be achieved from the following we get an idea of the sentence that can be formed. Above are all the combinations in the form of their POS TAGs as we have studied in the previous unit.
Key Takeaways:
- Treebanks are essentially used to assign a parse tree to the string. This would simply mean that it is possible to go through a corpus and build a treebank for the same that shows a similar correspondence as to the same corpus.
We notice that when we reduce the grammar in a particular corpus there is a minimization of the same. However, standardization does not take place throughout. This takes place mainly because the right-hand side of RHS products has no particular format that can be used. To make sure that the corpus is standardized we come across two normalization forms that can be used for the same.
- Chomsky Normal Form
This is a type of CFG that involves having the terminals and non-terminal components to normalize the corpus. A CFG is known to be in Chomsky Normal Form when all of the production area in a particular form which is:
A BC OR A a; Here A, B, C are known to NOT be terminals whereas ‘a’ is one.
CONCLUSION:
- For the grammar to be in the CNF form there need to be 2 non-terminal components as well as one single component.
- The RHS of a certain product has the maximum number of symbols to be accommodated as 2.
- These symbols must be a couple of non-terminal components or a single terminal component.
We can look at the different steps used to solve a certain example to get a good idea of the same.
Q) Standardize the following
M aAD
A aB / bAB
B b
D d
Solution: We notice that there are 2 non-terminal components as well as a single terminal component. This prompts to us the fact that this is in CNF. Now to convert it to CFG we need to follow certain steps.
- Step 1
Reduce it to the simplest form, we notice that the grammar is already in the simplest form which is:
M aAD
A aB / bAB
B b
D d
- Step 2
We need to spot if any of the given expressions are already in CNF. Out of the following,
B b and D d are already in CNF and will hence not have any changes.
We need to also convert M aAD and A aB / bAB into CNF which we will do in the next step now that we have identified them.
- Step 3
Replace the letters a and b with new symbols. Let us say they are replaced by C’ and C’’ respectively.
Therefore,
C’ a
C’’ b
Hence, we get
M C’AD
A C’B / C’’AB
- Step 4
We now work to replace the combination of non-terminal components with different letters.
Therefore,
AB E’
AD E”
Hence, we get;
M C’E’’
A C’B / C’’E’
- Step 5
Through all the above conversions we finally get our normal form of all the expressions which are shown below as follows:
- M C’E’’
2. A C’B / C’’E’
3. B b
4. D d
5. C’ a
6. C’’ b
7. AB E’
8. AD E”
This is the final conversion of the given question into CNF.
Key Takeaways:
- A CFG is known to be in Chomsky Normal Form when all of the production is in a particular form which is A BC OR A a
Syntactic Parsing is the process of having the program recognize a string and assign a certain syntactic structure to it. This is done after the normalization process as seen above. Parse trees are the exact thing that is assigned to each string in the process of parsing. This becomes very useful to the person who is going to have tasks like grammar checking as well as word processing say the least.
Parse trees are very important because they have good knowledge about the semantic analysis that takes place throughout the entire process of language processing. Before we work with certain algorithms there is always a question regarding the ambiguity that is proposed to the system before any change is made to it. Hence, we need to understand the topic of ambiguity before getting any further into the dynamics of parsing.
Key Takeaways:
- Syntactic Parsing is the process of having the program recognize a string and assign a certain syntactic structure to it
Being ambiguous is one of the main strengths of an algorithm. However, this very fact is the reason for its downfall. People understand that the structure is made up of strings in the corpus. So let us get on with an important understanding of the same. Different types of ambiguities are present in NLP.
- Structural Ambiguity
This is the ambiguity that deals with the problems posed by the syntactic parsers to gain a comfortable yet challenging role of the same. This has a different structure that can be seen while making the same sentence. This type of ambiguity can give more than just a single parse to a certain string.
Let us take the example of a sentence that can be written in a very normal form whereas one that can be written in a little funnier form.
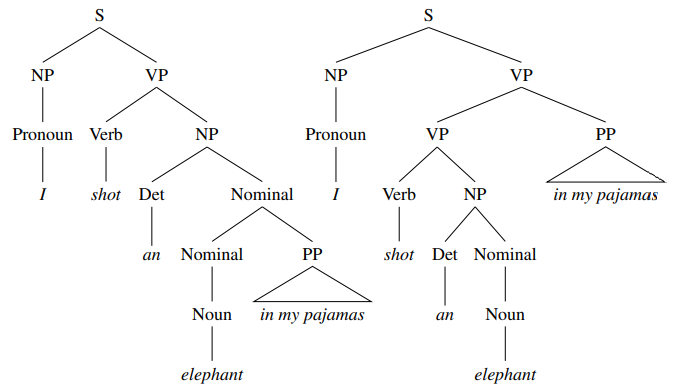 |
Fig Description 4: The above figure shows the difference in the structure faced by the entire sentence while being formed
The left parse tree signifies that the person in context shot the elephant while the elephant was in its pyjamas. The one on the rights speaks otherwise saying that the person was in his/her pyjamas while shooting the elephant. A little change in the structure caused a heavy amount of ambiguity.
2. Attachment Ambiguity
The next type of ambiguity that we have is known as attachment ambiguity. A string is called an attachment ambiguity when there is a parse tree at more than one position on the string. It must contain a prepositional phrase right behind the verb and noun. It must make the string syntactically ambiguous.
3. Coordination Ambiguity
The next type of ambiguity that we have is one that combines two strings that are from the corpus. We are then going to use conjunctions which are the parts of speech. If we take an example of the sentence, “The boys and girls are together.” We can see that 2 tokens viz. Boys and girls.
Key Takeaways:
- There are 3 types of ambiguities viz. Structural ambiguity, attachment ambiguity and coordination ambiguity.
Whenever we look at different algorithms, we need to understand the different happenings that take place in the sequential process. Having a dynamic programming approach allows us to get a frame that can sustain all the problems. This is a very similar algorithm when it comes to the processes like Minimum Edit Distance and the Viterbi algorithm.
Key Takeaways:
- Having a dynamic programming approach allows us to get a frame that can sustain all the problems.
A lot of languages may not need too much parsing due to the lesser complex structure of the corpus. To make sure that the parsing takes place we use shallow parsing. Information retrieval can take place throughout the entire system taking place. Partial parsing has so many different approaches that can be used to allow the algorithm to work. One can simply use FST’s or other tree-like representations.
There is a certain flatness that would arise from the entire function throughout the transducer attachments. The intent to make parse trees throughout the algorithm while managing the lesser complex strategy. The alternate style that has been developed throughout is known as chunking. It is the process of classifying the segments that do not overlap in a particular sentence after identifying it from the corpus. POS contents containing noun phrases as well as verb phrases and other phrases come into the algorithm of shallow parsing.
Let us understand this with the help of an example in a sentence.
- [The evening flight] [from] [New Delhi] [has arrived].
NP PP NP VP
- [The evening flight] from [New Delhi] has arrived.
NP NP
Evaluating Chunking Systems
As we get an idea about the chunking parsing, we need to understand that the model needs to be evaluated at constant intervals. Evaluation of POS chunkers behaves like normal annotators. We can evaluate the following with the help of being precise. F-measure is a measure of understanding the precision.
Precision is a part of the whole process that speaks about the system chunks that need correction throughout the whole process. Chunk labels are different for each model that has been decided. We can see the formula that is given by:
Precision = ( Total correct chunks gave by the system ) /
( Total chunks in the system )
Recall measures the percentage of correct chunks that might be present in the output. The difference between precision and recall is that it talks about the total chunks in the corpus rather than the entire system.
Recall = ( Total correct chunks given by system ) /
( Total number of chunks given in the text )
The F-measure allows the chunking system to be measured along with a single metric.
 |
β is the term that talks about the different weight being given to the system based on precision and recall. These are the different types of β values:
- β > 1 implies that we favour recall
- β < 1 implies that we favour precision
- β = 1 implies that both precision and recall are balanced equally
Key Takeaways:
- β > 1 implies that we favour recall
- β < 1 implies that we favour precision
- β = 1 implies that both precision and recall are balanced equally
When the user wants to augment the Context-free grammar, the simplest way to do so is by adopting the Probabilistic Context-free Grammar model. This is also known as the Stochastic Context-free Grammar model. As one would recall that the usual CFG is made up of 4 tuples. It means that there are essentially 4 main parameters that play an important role in understanding the augmentation that takes place in the entire sequence.
They are
- V – Set of variables
The set V can have examples of V = {S, NOUN, VERB, AUXILLARY VERB, PROPER NOUN, VP, Det, PREPOSITION, etc.}
NP = Determiner noun
VP = Verb determiner noun
Det = ‘the’, ‘a’
Preposition = ‘around’, ‘near’
Verb = ‘worked’, ‘ate’
- T – Set of terminal symbols
The set T can have examples T = {‘maggi’, ‘ate’, ‘a’, ‘boy’, ‘knife’, ‘with’}
- S – Set of start symbols
- P – Set rules for production
We can understand the same by looking at an example of how the same is formed with the help of a flowchart.
The new model simply adds a conditional probability to each of the 4 parameters. Let us call this conditional probability ‘p’. This conditional probability will tell us about the expansion of a non-terminal component (LHS) into the β sequence.
This can be represented as P( AB ) or also as P( LHS|RHS ). If we consider all the possible events of the conditional probability that has been assigned to the model, we conclude that the sum is equal to 1.
Consistency of a PCFG
We need to also figure out if the model is consistent or not. This would give the user a clear idea about the probabilities being assigned to the same. Grammar rules can also be very recursive at times. This involves loops to be formed. A PCFG is said to be consistent if the probabilities of all the strings summed up to equal 1. These PCFG’s can be used easily to estimate the probabilities coming out of each string present in the parse tree.
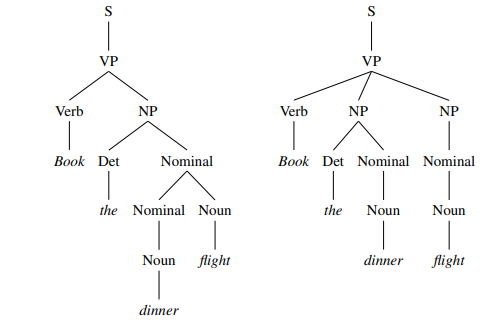 |
Fig. Description 5: There is a comparison between the consistencies in each of the sentences composed of the same words.
Key Takeaways:
- A PCFG is said to be consistent if the probabilities of all the strings summed up to equal 1.
A simple problem that is created due to parsing by a PCFG is a parse tree which we can call T which is unique for a particular sentence S. All of these are simply an extension or a modified version of the algorithms that have been used formerly for parsing. Now a probabilistic CYK algorithm simply assumes that the CFG is already in the CNF form. The CNF now has a simple rule as mentioned earlier which states that the CNF must have either 2 non-terminal components or a single terminal component on the RHS of it.
This same property of terminal and non-terminal components has been exploited a little and each word/token in the sentence is given a specific index to work with.
E.g. The boy lives in Mumbai.
Form = [0] The [1] boy [2] lives [3] in [4] Mumbai [5]
The indices that have been assigned to the sentence are taken from the parse tree and placed in a 2 x 2 matrix. Let us say we have a sentence of length l and it contains either 2 non-terminals or 1 terminal. The upper triangle of the 2 x 2 matrix is used. The matrix is also called (l+1) x (l+1).
In a probabilistic model, there is a 3rd dimension that comes into play. This speaks about a factor that is not constant but is made out of inferences through statistical gawking. This 3rd dimension in the matrix is V = maximum length. Hence, the matrix for a probabilistic model is (l+1) x (l+1) x V.
The new CNF algorithm uses grammar which is made up of other works. Converting to a grammar form can cause different probabilities to be assigned to it. Let us have a look at some of the different probabilities assigned to some of the POS tags.
Fig. No. 6
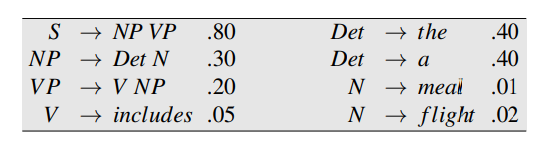 |
Fig. Description 6: These are the 4 main components of the CNF algorithm
PCFG problems
- Assumptions poorly made (independent): The rules that are made by CFG is made to impose a kind of independence on the probability assumptions. This would lead to a problem with the models as well as the structures that come in the output of the sparse tree.
2. Very less lexicon conditioning: Most of the structures that are made through the lexical analysis fall short because of the discrepancies brought up by the different ambiguous problems. There is also an issue in remodelling the structure.
Key Takeaways:
- A probabilistic CYK algorithm simply assumes that the CFG is already in the CNF form.
We have seen how the CYK algorithm is used in an attempt to parse raw Context-free Grammar. Doing this there is a high accuracy that is achieved through the application of this model. This is only possible if all the rules are correctly applied by the model. We are now going to have a look at a model that is similar to the probabilistic CYK algorithm.
This algorithm is similar in terms of the result. However, the major difference that is made between both the models is that the new model also called the probabilistic lexicalized CFG model modifies the model for parsing instead of modifying the rules of grammar. This simply allows the model to also be applicable for lexicalized rules. There is a tree that is made up of the lexical analysis.
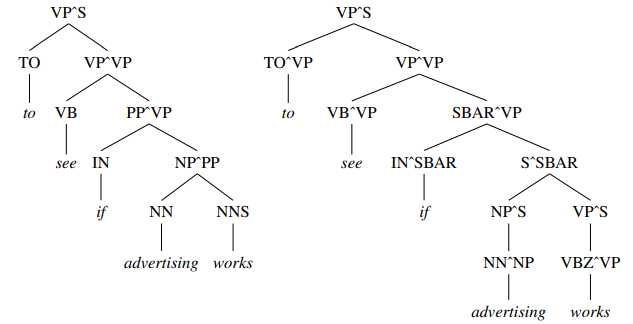 |
Fig. Description 7: The above figure shows 2 examples of Lexicalized CFG’s
This diagram above has two separate parse trees. The one on the left is incorrect whereas the one on the right is correct. The one on the right has the terminals before the nodes split up.
Key Takeaways:
- The probabilistic lexicalized CFG model modifies the model for parsing instead of modifying the rules of grammar.
These are often written as notes to the attributes mentioned in the matrices defined by the number from the previous CYK algorithm. It is essentially a mapping structure that helps the user identify the values which are given to every feature written down. These features can be normal strings or sentences which are written or part of the corpus.
E.g., Consider a matrix talking about the singular factor of the 2nd person. If we need to represent the same in the form of a matrix it would look something like this.
[ number = 'sing' ]
[ person = 2 ]
We can also represent the following in terms of a graph that can be used. This is also known as a directed graph. Let us take an example of a cat, person, number, and the AGR. There is a directed graph that is very similar to a tree structure that is given below.
Fig. No. 8
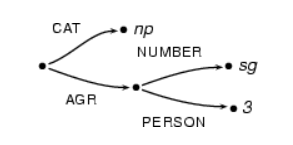 |
Fig. Description 8: This is the tree structure of all the features
There are a few paths that can be specified when it comes to a feature structure. Knowledge of the tuple, as well as the path, could help get an idea of the feature structure value that we are intending to calculate.
There are 2 types of feature structures known.
- Feature dictionaries: The identifiers that are implemented are in the form of strings.
2. Feature lists: The identifiers that are implemented are in the form of integers.
Key Takeaways:
- There are 2 types of feature structures viz. Feature dictionaries and Feature Lists.
As the name very rightly suggests this tells us about the unification process that takes place while getting a good understanding of the Feature structure. We now know that the feature structure can be written in the form of a matrix. We can better understand the unification with the help of an example.
Let F1 be a certain feature structure 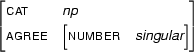 Let F2 be a certain feature structure 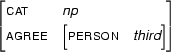
|
Now when we apply the unification of both the above feature structure we expect that the information coded in both of them is available in the final matrix that is formed. This would give us a resultant matrix
F1 U F2 = 
|
Now let us try to understand an example that would mean that the unification would not exist.
Let F1 be a feature structure [MAN np]
Let F2 be a feature structure [MAN vp]
The unification matrix of F1 and F2 would not exist because there would not be any matrix that contains all the information summed up from both the F1 and the F2 matrix together.
There are a few precise properties of unification that need to be assumed and put into practice before looking into finding the feature structure unification.
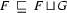 where F U G is subsumed by F
where F U G is subsumed by F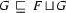 where F U G is subsumed by G
where F U G is subsumed by G- If H is a feature structure such that F U G is the feature that is the smallest one and all satisfies the 2 properties above
Another example of the following is given below
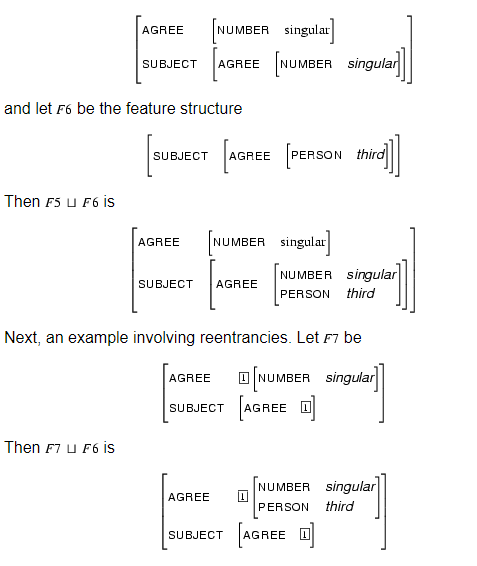 |
Key Takeaways:
- Precision = ( Total correct chunks gave by the system ) /
( Total chunks in the system )
References:
- Fundamentals of Speech Recognition by Lawrence Rabiner
- Speech and Language Processing by Daniel Jurafsky and James H. Martin




