UNIT-3
Semantics and Pragmatics
One would consider the need of NLP in order to allow people or machines that speak 2 very distinct and different languages to be able to communicate and share ideas with each other throughout the entire process. One can represent the meaning of these languages in the way people talk and make conversation. Each conversation is made up of sentences put together. So these sentences are made up of words which are then made up of letters. The letters are pronounced in the way that they are phonetically correct.
If we want to refer to the meaning of the text that we are using we call it semantics. To have a language that can be correctly interpreted it is very important that the semantics describe how people think and learn about different ideas being portrayed in that language. This theory of unifying all meanings for any set language may not be available readily which is why people resort to different types of methods to achieve the same. This being us to the question of why representation and why do people use it ?
Verifiability
As the name suggests it talks about the verification of a certain text or other ideas present in the NLP semantics. We can define this as the ability of any system to compare or model the knowledge achieved from one data model to the knowledge achieved from a knowledge base. This simply means that one can match their knowledge against the facts that are already in existence about the same.
E.g. India is a country of only 1 religion.
This statement if made by one of the worlds described is compared to the one with all trained realistic situations and data in it, it would come out as false. This is how semantics helps people understand of their very own data is correct or incorrect by comprehending the meaning of the data.
Unambiguous Representation
NLP is filled with ambiguous situations which was one of the main problems we studied in the previous model. We need to have a lot more than just a single context in order to make any inferences from an ambiguous statement. So let us take an example of the following.
E.g. Rakesh wants to eat at a place close to the Hawa Mahal.
This statement is filled with ambiguity because of the fact that there could be so many different places to eat near ‘Hawa Mahal’. Rakesh would like to try one of them but which one is not known for sure. There needs to be a certain kind of appropriate representation analysis of the same.
However, when we talk about the representation of a system we need to ensure that it is free from any type of ambiguity. This is because the representation talks about the semantics (meanings). For the user to allow the system to comprehend any amount of information one would need to understand the whole process of determining the same.
Vagueness
Once again this concept is very much related to the previous term called ambiguity. Vagueness is a form of ambiguity which simply does not allow parts of the sentence to be specified. The meaning of the representation is thus not achieved. One must note that it does not give rise to different types of representations for the same string.
E.g. Mukesh likes to eat Indian food.
The cuisine of the food is specified. However, the cuisine could include so many dishes which makes it very difficult to represent the meaning accurately without potentially causing a blunder in the same.
Canonical Representation
This is the concept where one is able to map different inputs to the same output. The form that is given as a meaning is forged as part of a representation. We could use simple grammatical rules to relate the sentences and form a certain meaning of the same. We would be able to easily understand this with the help of examples.
- Does Sagar serve vegetarian food ?
- Do they have veg. Food at Sagar ?
- Does Sagar have any vegetarian dishes ?
Now if we look at all of the 3 examples given above it is sure that one would understand the relation between all 3 of them. They all imply the same thing but with words that are not so similar. The system might not be able to comprehend the words like ‘food’, ‘dishes’ together. This would make it very difficult to represent the meaning. However, we could do this by simply converting them to a simple and general form with a difference in the placement as well.
- Sagar serves vegetarian food.
- Vegetarian food is served at Sagar.
A simple yet elegant representation shows us that this is a clear representation that follows the two parts of ‘Sagar’ and ‘Vegetarian food’ being related to each other despite being placed in different parts of the sentence.
Inference
When we deal with sentences that are a little more complex than the above examples we need our system to understand the context and make inferences based on the data it is trained with.
E.g. Can Vegetarians eat food at Sagar ?
This sentence ultimately asks the question about the availability of veg. Food at Sagar. One would need to infer this form the statement considering the key ‘tokens’ that are available. Inference is used to describe the inputs and give some background knowledge about the same.
Key Takeaways:
- Verifiability talks about the verification of a certain text or other ideas present in the NLP semantics.
- Vagueness is a form of ambiguity which simply does not allow parts of the sentence to be specified.
- Inference is used to describe the inputs and give some background knowledge about the same.
First -Order logic which is also referred to as FOL is a logic that has been developed to understand and comprehend the meaning representations that could come out of every different string that we might intend to process. It allows the system to run a computational analysis to infer the requirements and match the data in order to provide appropriate semantic analysis of the natural language.
FOL also has a feature that allows it to have a say in the representation of different structures that might be part of the whole process. Schemes that are related may achieve a certain amount of inference from the above. We will further deal with the elements that make up First - Order Logic and its applications.
- Term
This refers to the examination of a certain notion that is part of the string that is to be processed. The representation of certain terms can be done wit the help of 3 different blocks given below.
2. Constants
FOL has constants that basically refer to a certain object that is being described. These can easily be identified because of their representation. IT is either in the form of a type of letter like ‘A or ‘Z’’. This may also be possible for the constant if they are depicted with the help of proper nouns like ‘Sagar’ or ‘Hari’.
3. Functions
FOL uses this term in order to correspond to the semantics that would describe the current status or state of an object. We could talk about the location of ‘Hari’. This would have a representation similar to.
Representation = Location of ( Hari )
These functions are same in terms of their syntax. They will always refer to objects that are unique. Most of the cases are very favourable to get an idea about the same. But for most of the part they are all unique and represented as stated above.
4. Variables
This is the mechanism given by FOL which is used in order to simply refer to objects. These are depicted in the form of lower case letters. We can use this in order to make certain inferences about the object that we have in question. We can easily relate a certain object to one that is distant in the form of other meanings.
Representation = Serves (Sagar, Vegetarian)
- Semantics of First – Order Logic
There is a table that needs to be followed in order to make the correct inferences based on the logic provided by the notations. One can follow up with the table in order to make appropriate deductions.
¬ = NOT
∧ = AND
∨ = OR
F = FALSE
T = TRUE
P | B | ¬ P | P ∧ Q | P ∨ Q | P Q |
F | F | T | F | F | T |
F | T | T | F | T | T |
T | F | F | F | T | F |
T | T | F | T | T | T |
- Description Logic
To allow the language to work the magic that it has it is very important to understand the references that have been made about it. The description of the same needs to be done very well. We us a different type of logic in order to correctly specify different types of semantics for the structured representations. A framework has been created in order to get a grip on the model. It essentially describes the set of FOL by being part of the subsets.
Terminology
We need to emphasize the process of representation while having descriptive logics work to separate the categories. It is simply the backbone of the entire process of description logic. We can call all the categories as well as the concepts that go into the application as terminology.
We also have a base of knowledge that is known to contain all this terminologies and is rightly known as TBox. Apart from this there is also a box that contains certain facts about the data that we are intending to describe. This is called the ABox. Further, all these terminologies are arranged in the form of hierarchy to produce inferences through set theory. This process is also known as ontology.
Subsumption
Now that we have an idea about all the facts that can go into the mainframe while describing the algorithm for logic. We look at the different sets that are formed as part of the ontology. Let us say we have 2 sets C and D. These 2 are represented with the same symbol as that of a ‘proper subset’. It is also read as C is subsumed by D. This simply implies that all the elements that are part of the C set are also part of the D set.
We can see this in a diagrammatic representation of the same very easily. Here we area referring to different cuisines being part of the whole term known as ‘restaurant’.
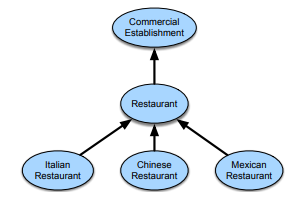 
|
Semantic Roles and Analysis
Semantics is the study that allows people to work and get a better idea of the happenings between two languages. These representations of the shallow semantics are very important. We need to have a certain number of labels that can assign riles to the different types of restrictions.
Semantics is essentially used in order to provide its construction segments with meaning. The tokens are given a certain discrete structure. Symbols as well as other features are easily interpreted by the study of semantics. The analysis part is only key part in deciding whether the structure that was created using semantics is useful in terms of meaning or not. We can write this in the form of a formula as :
CFG (Context Free Grammar) + Semantic Rules = Syntax Definitions
This usually depends heavily on the concurrent parsing or other different levels of parsing. E can use Lambda expressions as a combination with the same in order to find the FOL arguments. We use the Principle of Compositionality in order to study the syntax that is used to understand the sematic analysis. This has 2 main factors that speak volumes about the process given below.
- The meaning of certain parts or tokens are used in order to build the meaning of the entire corpus.
- There are certain relations like syntactic ones that are used to guide the following process.
The semantic analysis is first done by conduction the lexical analysis of the entire paraphrase which tells us whether the structure is fundamentally sound. Sematic analysis is key in order to evaluate the grammar and other language use. We can do the same as follows :
- Resolution of Scope
- Checking of the Type
- Checking bound to arrays
Semantic Errors :
There are a few different types of errors that can easily be recognized by the analyzer. A list of these are given below :
- Mismatching of the type
- Variable not being declared
- Misuse of a reserved identifier
- Multiple variables being declared
- Accessing a variable that is out of scope
- The formal parameter mismatching with the actual one
Attribute Grammar
This is a very special type of grammar that is made up of CFG along with the addition of certain attributes. There are appended to the non-terminal components. The values are well-defined. E.g. Char, float, int, string, etc.
One can easily understand the semantics that is used in a programming language with the help of attribute grammar. Value scan be passed of the same while being seen in the form of a parse tree.
A A + T { A.value = A.value + T.value }
There are also 2 different types of attributes used which are :
- Synthesized attributes
- Inherited attributes
 |
There 2 separate approaches that are used in the process of Semantic analysis.
- Unification based Approach
- Store and Retrieve Approach
Word Senses
Words are used in any language in order to construct sentences which will go on forward to make more sense. This is a very simple method used in order to communicate between different people around. Words can also mean a lot of different things. This involves a certain sense of ambiguity surrounding them.
Word sense can be defined as the representation of a certain aspect that makes a word discretely. This is controlled online with the help of the WordNet. This is basically a database that is used in order to represent all of the word senses easily. We need to establish a certain relationship between the words that are used in order to make the relations a little simpler. Let us take 2 words which are synonyms. Having a relation between both of the words can make it easier for the language to process the same when asked.
A sense can give very discrete understanding about the word. Let us take the English language as an example. There are a few words that could have different meanings and at the same time be pronounced and spelled the same.
E.g.
1. Mouse [1] = A device used to scroll around a desktop computer.
2. Mouse [2] = An animal that is usually found in houses and other places with food.
- Bank [1] = A place where people store money and also make financial transactions.
- Bank [2] = The part beside a river.
The above words that are used to give textual definitions for the words in order to have a unique word sense are known as glosses. These are not exactly used to give a formal description but come in handy to the users going through the algorithm.
Number of Senses for a Word
The number of words that can be same and have different meanings are endless. To analyze and get a better understanding we can build something known as a thesaurus. This can provide the user with a certain specific criteria that is easily used to pose different conditions. These can be distinct as well as similar. One can join two word senses and form a conjunction which is known as zeugma.
E.g.
- Which of these flights serve lunch ?
2. Does Air Asia serve Mumbai ?
3. ? Does Air Asia serve lunch and Mumbai ?
The question mark ( ? ) is used in order to depict sentences that are semantically incorrect or wrongly formed. We cannot find a suitable way to explain the 3rd case which is an example of zeugma.
Relations Between Senses
Word sense talk about the words that have discrete meanings. Here wee will look at how these senses could be related to each other based on different factors.
- Synonymy
When 2 words that are in a certain string may or may not have the same spelling and pronunciation but have meanings that are exactly the same or very identical, we can call them synonyms. The technical term while processing the language for terms like these are also called synonymy.
E.g.
- Sofa = couch
- Throw up = vomit
- Car = vehicle
- Back = behind
- Finish = End
- Big = Huge
A synonymy works as more of a relation between senses that it does between words. We only need to be able to grasp the meaning of the word and find out if we could swap a word in place of that. This is the main aim.
2. Antonymy
This is exactly the opposite of the previous terminology that we learned about. When 2 words that are in a certain string may or may not have the same spelling and pronunciation but have their meanings exactly opposite to each other are known as antonyms.
E.g.
- Short = long
- In = out
- Outside = inside
- Behind = front
- Hot = cold
- Wet = dry
An antonymy works as more of a relation between the negation of senses rather than simple words. There are also a separate type of antonymy’s which are known to be the opposites for those words that change with respect to opposite directions. These are also known as reverslves.
3. Taxonomic Relations
We must also consider that there are different ways in which one could relate word senses. The main one would be known in two types.
- Hyponym
A word sense is also called a hyponym if it makes the previous word a little more specific about itself. It essentially is a part of the subclass of the same.
E.g.
Cat is the hyponym of animal.
Apple is the hyponym of fruits.
- Hypernym
This is the exact opposite of a hyponym. In a hypernym the same two words that were hyponyms, when reversed become this. They simply switch places in order to exist.
E.g.
Animal is the hypernym of cat.
Fruit is the hypernym of apple.
 |
4. Meronym
We could call this relation one that tells us the relation between the 2 words as a whole. One of the words is part of the set of another. The word A would be part of the set B.
E.g.
Wheel is the meronym of cycle.
Knee is a meronym of leg.
5. Structured Polysemy
We can make a relation between the 2-word sense through semantics. This is also known as structured polysemy.
 |
Thematic Roles
The algorithm which assigns the verb to the Thematic properties are called Thematic Roles.
- Agent – The action of the verb is carried out by this particular entity. This action is carried out intentionally in order to know that the function is taking place.
2. Experiencer – This refers to a certain emotion that is carried out by a certain entity. This can also tell us about the perception that the entity has for the verb who is carrying out the action.
3. Theme – If there is an entity that is going to receive the action that is carried on by the agent. This is the work of the verb to carry out the action on it.
4. Instrument – This is basically the person or entity that is going to carry out the action that is happening to the theme. If there was a mediator in any process, the instrument would have a role very synonymous to it.
5. Goal – After the action is carried out by the verb, the entity might move in a certain direction (metaphorically). This is essentially the goal or the final objective of the verb action.
6. Source – Just as the verb is carried out on the theme, one would expect some effect from it as well. This could also be influenced by the direction from where the verb has originated.
7. Location – Just as the word says correctly it talks about the location of the action happening. Here, the action that takes place between the agent and theme through the mediation of the instrument has a certain location.
8. Benefactive – The final result may have consequences on the theme or anything that is directly or indirectly influenced by it. The entity that is objected to the abstract feeling delivered to it by the verb is known as benefactive.
E.g.
- Raju hit Shyam
Here Raju is the agent and Shyam is the theme.
2. Baburao bought his dhoti from Raju at the shop
Here Baburao is the agent, Raju is the theme and the shop is the source.
3. Raju was fooled in his house by Laxmi Chit Fund.
Here Raju is the theme, Laxmi Chit Fund is the agent and the house is the location.
Key Takeaways:
- Term, constant, function and variable are ethe main features of FOL.
- The algorithm which assigns the verb to the Thematic properties are called Thematic Roles.
- An antonymy works as more of a relation between the negation of senses rather than simple words.
- Word sense can be defined as the representation of a certain aspect that makes a word discretely. This is controlled online with the help of the WordNet.
The process of making the selection of an appropriate word sense to suit a word that is chose is known as word sense disambiguation. A lot of algorithms are written based in the above in order to have potential outputs being scanned. This can be done in a lot of different steps which are noted below.
Tasks and Datasets of the WSD Algorithm
There are different tags that are essential in order to get the correct output. We need to have proper datasets that can be used in order to process different algorithms being used in the above section. WordNet is a good source of resources that can be used to train the same model and algorithm. Let us consider the word ‘BASS’. This is going to have different meanings which can be seen easily with the help of the diagram that is given below.
 |
We could also go through the algorithm being used for different words that serve as input models for the above. Nouns, adjectives as well as other parts of speech are part of this algorithm.
 |
Evaluation of WSD algorithm using thesaurus
Evaluating a WSD algorithm can be done with th help of 2 heuristics. These are key to understand the relations between the word sense and help analyze them further and bring out inferences as well.
These systems are evaluated in the intrinsic form. We can use the F1 hand-labelled tags which can evaluate it on the basis of each corpora. To understand the same we use a term that is known as most frequent sense. We have to choose each word or token from the labels that are present in the corpus. Each word may be tagged as well with their counts coming from the WordNet part. This baseline of most frequent sense is fairly accurate and can be used as a default in order to train a supervised algorithm, especially with data that is insufficient.
There was another observation made while going through this algorithm which stated that a certain word may appear multiple times in a corpus with the same sense. This heuristic is known as one sense per discourse. We notice that this case runs very well for word sense that are in the form of homonymy than simply polysemy. There is bound to be some sense of ambiguity throughout the whole process of evaluation.
1 – nearest – neighbour – algorithm
When we look at all the different WSD algorithms that are present around us we notice that this particular algorithm that uses word embeddings that are contextual, stands out to be one of the most efficient.
When we pass each string through a certain algorithm at the time of training, there is embedding done for each word or token that is selected from the string. When we take each sense ci along with each word c, we are able to compute the average embedding sense Vs through that sentence. The formula is given below as follows :
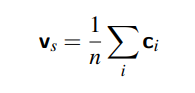 |
For testing the algorithm, we simply use the formula below to calculate the embedding and also choose appropriate nearest neighbours. All of this is done from the training set.
 |
- Hidden Markov Model
A Hidden Markov Model (HMM) is a model that is a modified stochastic tagging model with the main process being underlined throughout the main process. The result is simply the same if not more accurate. However, the processes that get done cannot be seen. The results of each sequence throughout the process is the only part that can be seen and comprehended.
To understand this a little better we need to understand the term Markov chain. This is simply a model that gives us inferences about the sequences from the different probability densities occurring throughout the corpus. To make a prediction the markov chain relies heavily on the current position of the tag or word count in the string. The Hidden Markov Model allows the user to dwell around both visible events (input strings) as well as hidden events (POS tagging).
Let us take an example to understand better the HMM process for a certain example. Say we have to build an HMM of the problem where coins are tossed in a certain sequence. To get a better understand we can break this down into the 2 processes and factors
- Visible Events
These are the events that we know are happening and can physically or virtually picture them. In this case it is the tossing of coins. We are sure that coins are being tossed with an option of either showing ‘heads’ or ‘tails’ as the outcome.
2. Hidden Events
These are the factors that are completely hidden from the user. In this case they could be the number of coins that are used in the problem or the order in which the coins are tossed up in case they are different or weighted. One could conclude so many different models to understand this process better. One of the forms of the model is given below.
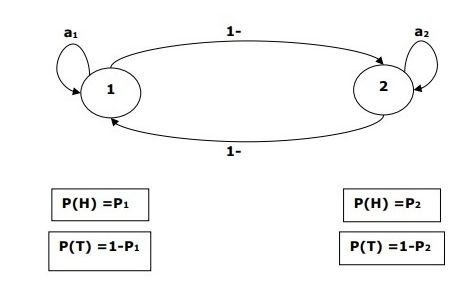 |
Tags in each of the following are basically sequences that generate tags for the outputs being given in the hidden states. These states have tags that could give an output which is observable to the user.
- Maximum Entropy Markov Model (MEMM)
This model is used as an alternate form for the above Markov Model. In this model, the sequences which are taking place are replaced by a single function that we can define. This model can simply tell us about the happenings in the predicted state s while knowing the past states’ as well as the current observation o. P (s | s’ , o)
The main difference that we can get ourselves familiar with is the part where HMM’s are only dependent on the current state whereas the MEMM’s have their inferences which can be based on the current as well as the past states. This could involve a better form of accuracy while going through the entire tagging process. We can even see the difference in the diagram which is given below.
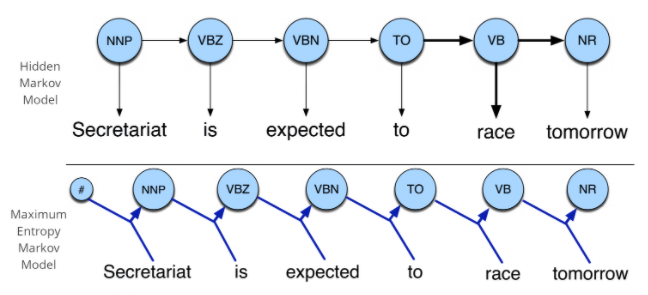 |
Disadvantages of MEMM’s
- MEMM models have a problem due to the label bias problem. Once the state has been selected, the observation which is going to succeed the current one will select all of the transitions that might be leaving the state.
2. There are a few examples in words such as “rib” and “rob” which when placed in the algorithm in their raw from have a little different path as compared to the other words. When we have “r_b” there is a path that goes through 0-1 and 0-4 to get the probability mass function. Both the paths would be equally likely not allowing the model to select one fixed word that could be predicted by the model correctly.
Key Takeaways:
- The process of making the selection of an appropriate word sense to suit a word that is chose is known as word sense disambiguation.
References:
- Fundamentals of Speech Recognition by Lawrence Rabiner
- Speech and Language Processing by Daniel Jurafsky and James H. Martin




