UNIT - 4
Basic Concepts of Speech Processing
Phonetics and Phonology
Phonology deals with word structure in individual languages: the approach distinctions in sound are accustomed differentiate linguistic concepts, and therefore the ways in which the sound structure of the ‘same’ part varies as an operand of the opposite sounds in the context.
Synchronic linguistics and acoustics each involve sound in linguistic communication, however dissent in this acoustics deals with sounds from a language-independent purpose of read, whereas synchronic linguistics studies the ways in which during which they're distributed and deployed at intervals specific languages.
Key Takeaways:
Phonology is important because it decides the main basics on which the language can be interpreted and constructed.
Articulatory Phonetics may be a branch of acoustics that deals with describing the speech sounds of the world's languages in terms of their articulations, that is, the movements and/or positions of the vocal organs (articulators). the foremost potent system of pronunciation description and transcription of speech sounds has been that of the International Phonetic Association (IPA), that aims to supply a phenome for each phone for each language.
Within the IPA tradition, speech is characterised as sequences of separate speech segments (consonants and vowels), and every sound is outlined as a mixture of pronunciation phonetic properties. Many laboratory techniques are accustomed to get data concerning the articulations of speech sounds, that successively is employed in modelling of vocalization itself, and of articulatory-acoustic relations.
Key Takeaways:
This is the branch of NLP that involves the sound in the process of auditory analysis.
When we speak the phonetics can be very helpful to work on algorithms and other semantics.
Acoustics deals with transmission of sounds from speaker to beholder. This approach offers a chance to review the nature of speech signal for various sounds no matter the options that represent these sounds. It doesn't embrace modelling techniques and have extraction ways, rather
it is the simplest way to investigate and perceive nature of various
sounds like vowels, semi-vowels, diphthongs, etc.
Acoustics deal with transmission of sounds from speaker to beholder. This approach offers a chance to review the nature of speech signal for various sounds no matter the options that represent these sounds. It doesn't embrace modelling techniques and have extraction ways, rather it's the simplest way to investigate and perceive nature of various appears like vowels, semi-vowels, diphthongs, etc.
Acoustic Phonetic approach is getting used by researchers to handle these problems and solve totally different issues of speech recognition space. There are also totally different areas during which this approach is helpful. a number of them are listed below:
• Multilingual speech recognition
• Accent classification
• Speech Activity Detection Systems
• Speech recognition for Indian languages
• Speech recognition for Asian languages
• Vocal Melody Extraction
To describe a consonant sound, we need to have vital items of data. We'd like to grasp the subsequent relating to its production:
the air stream mechanism; the state of the glottis; the position of the soft-palate; the active articulator; the passive articulator; the structure concerned.
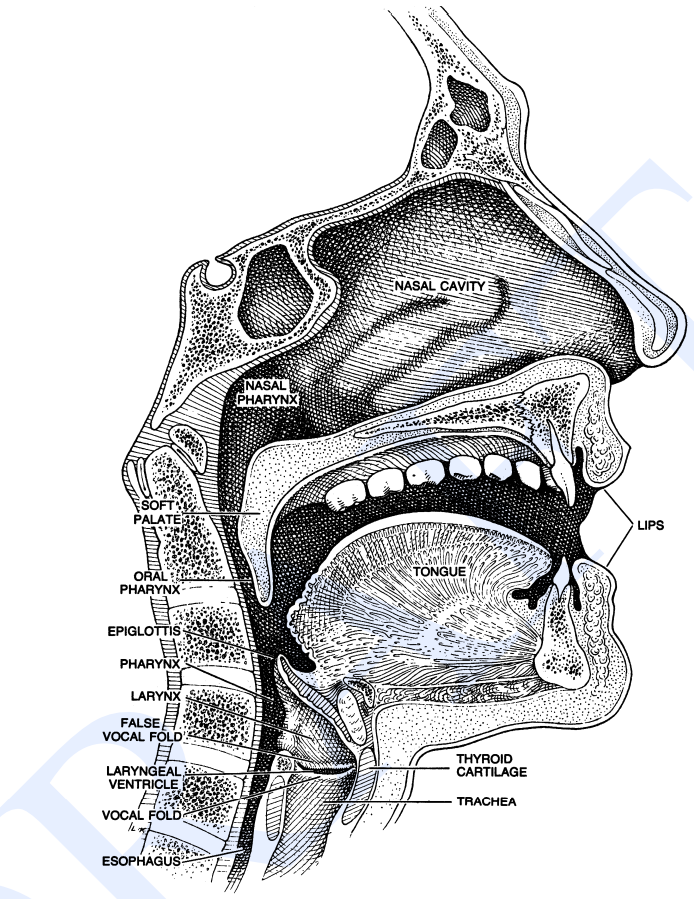 |
Most sounds in human spoken languages are created by activity air from the lungs through the cartilaginous tube (technically the trachea) and so out the mouth or nose.
• As it passes through the trachea, the air passes through the voice box additionally called Adam’s apple. The voice box contains 2 little folds of muscle, the plica which might be rapt along and apart. The area between these folds is understood as speech organ.
• If the folds are approximate (but not tightly closed), they're going to vibrate as air passes through them; if they're so much apart, they won’t vibrate. Sounds created with the vocal folds along and vibratory are referred to as voiced; sounds created while not this plica vocalis vibration are referred to as unvoiced or voiceless.
• Voiced sounds embrace [b], [d], [g], [v], [z], and every one land vowels, among others. Unvoiced sounds embrace [p], [t], [k], [f], [s], and others. the world higher than the trachea is named the vocal tract, and consists of the oral tract and therefore the nasal tract. when the air leaves the trachea, it will exit the body through the mouth or the nose. Most sounds are created by air passing through the mouth. SOUNDS created by air passing through the nose are referred to as nasal sounds; nasal sounds use each the oral and nasal tracts as resonant cavities; English nasal sounds embrace m, and n, and ng.
• Phones are divided into 2 main classes: consonants and vowels. each types of sounds are formed by the motion of air through the mouth, throat or nose. Consonants are created by restricting or obstructing the flowing in a way, and will be voiced or unvoiced. Vowels that have less obstruction are also typically voiced, and appear usually louder and longer-lasting than consonants. The technical use of those terms is way just like the common usage; [p], [b], [t], [d], [k], [g], [f], [v], [s], [z], [r], [l], etc., are consonants; [aa], [ae], [ao], [ih], [aw], [ow], [uw], etc., are vowels. Semivowels (such as [y] and [w]) have a number of the properties of both; they're voiced like vowels, however they're short and a bit less syllabic like consonants.
CONSONANTS
Because consonants are created by restricting the flowing in a way, consonants is distinguished by wherever this restriction is made: the purpose of most restriction is named the place of articulation of a consonant. Places of articulation, shown in Fig, are usually employed in automatic speech recognition as a helpful means of grouping phones along into equivalence categories.
LABIAL :
Consonants whose main restriction is created by the 2 lips returning along have a bilabial place of articulation. In English these embrace [p] as in possum, [b] as in bear, and [m] as in marmot. the English labiodental consonants [v] and [f] are created by pressing the bottom lip against the higher row of teeth and letting the air flow through the area within the upper teeth.
DENTAL:
Sounds that are created by putting the tongue against the teeth are dentals. Most of the dentals in English become the [th] of issue or the [dh] of although, articulatory phonetics seven created by putting the tongue behind the teeth with the tip slightly between the teeth.
 |
ALVEOLAR :
The alveolar ridge is the portion of the roof of the mouth simply behind the higher teeth. Most speakers of Yankee English build the phones [s], [z], [t], and [d] by putting the tip of the tongue against the alveolar ridge. The word coronal coronal is commonly used to check with each dental and alveolar.
PALATAL:
The roof of the mouth (the palate) rises sharply from the rear of the alveolar ridge. The palato-alveolar sounds [sh] (shrimp), [ch] (china), [zh] (Asian), and [jh] (jar) are created with the blade of the tongue against this rising back of the alveolar ridge. The palatal sound [y] of yak is formed by putting the front of the tongue up on the brink of the surface.
VELAR:
The velum or soft palate is a movable muscular flap at the very back of the roof of the mouth. The sounds [k] (cuckoo), [g] (goose), and [N] (kingfisher) are created by pressing the rear of the tongue up against the velum.
GLOTTAL : The glottal stop [q] (IPA [P]) is formed by closing the glottis
(by conveyance the vocal folds together)
VOWELS:
Like consonants, vowels is characterised by the position of the articulators as they're created. The 3 most relevant parameters for vowels are what's known as vowel height, that correlates roughly with the peak of the very best a part of the tongue, vowel frontness or backness, that indicates whether or not this section is toward the front or back of the oral tract, and therefore the form of the lips (rounded or not). Fig. Shows the position of the tongue for various vowels.
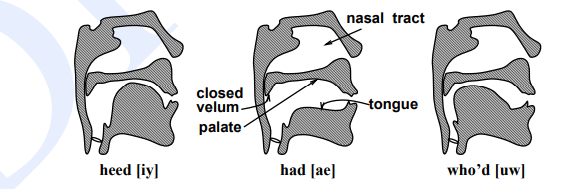 |
In the vowel [iy], as an example, the very best purpose of the tongue is toward the front of the mouth. within the vowel [uw], against this, the high-point of the tongue is found toward the rear of the mouth. Vowels within which the tongue is raised toward the front are known as front vowels; those within which the tongue is raised toward the rear are back vowels.
Note that whereas each [ih] and [eh], these are front vowels, the tongue is higher for [ih] than for [eh]. Vowels within which the very best purpose of the tongue is relatively high are high vowels; vowels with middle or low values of most tongue height are known as mid vowels or low vowels, respectively.
Digital Signal Processing Brief Notes
A signal is defined as any physical quantity that varies with time, space or another independent variable. A system can be recognised as a physical device that performs different operations on a signal. Systems can be differentiated by the different types of operation that are performed on a signal. These operations are referred to as signal processing.
Classification of Signals:
Based on Variables:
Based on independent Variable
Continuous Time Signal
Discrete Time Signal
Continuous Time Signals | Discrete Time Signals |
Continuous time signals are also known as analog signals
| These signals are defined only at discrete times. |
They have continuous amplitude and time | Every signal has independent value. |
They have values at each instant of time | Amplitude show discrete characteristics here. E.g. Digital signals |
Types of Continuous Time Signals:
Unit Impulse or Delta Function:
A signal, that satisfies the condition, δ(t)=limϵ→∞ x(t) is understood as unit impulse signal. This signal tends to infinity once t = zero and tends to zero once t ≠ zero such that the area underneath its curve is usually equals to 1.
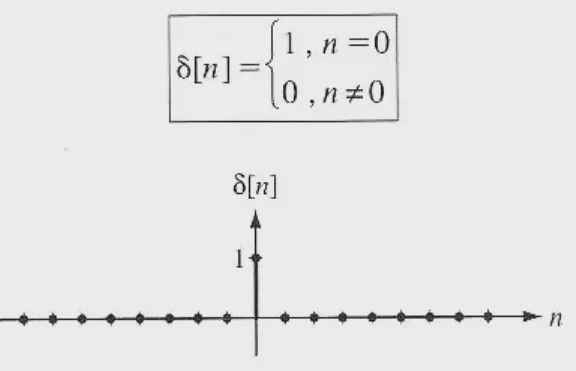 |
The delta function has zero amplitude.
Unit Step Signal:
A signal, that satisfies the subsequent 2 conditions − • U(t)=1(when t≥0) and
• U(t)=0(when t<0) Such a sign is understood as unit step signal.
It shows discontinuity at t=0.
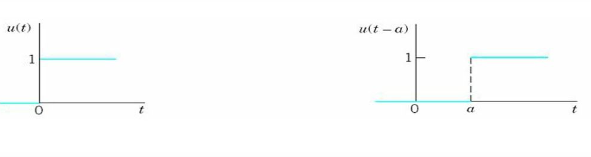 |
Ramp Signal:
Integration of step signal leads to a Ramp signal. it's depicted by RTT. Ramp signal additionally satisfies the condition r(t)=∫t−∞U(t)dt=tU(t). it's neither energy nor power NENP
 |
Signum Function:
This is given by the function as sgn(t)= {1 for t>0 −1 for t<0
It is a power signal. Its power value and RMS Root Mean sq. values, both are 1.
Average price of signum function is zero.
It is additionally a function of sine and is written as −
SinC(t)=SinΠt/ΠT=Sa(Πt)
 |
Sinusoidal Signal
A signal, that is continuous in nature is known as continuous signal. General format of a sinusoidal signal is
x(t)=Asin(ωt+ϕ)
 |
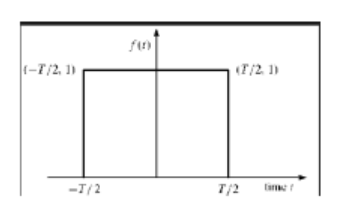
Rectangular function
A signal is alleged to be rectangular function kind if it satisfies the following the subsequent
π(tτ)=1, for t ≤ τ
0, Otherwise
 |
Types of discrete Time Signals:
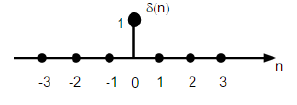
1. Unit Impulse Sequence
It is denoted as δn in distinct time domain and may be outlined as;
δ(n)={1, for n=0 and = 0 (for other cases)
 |
2. Unit Step Signal
Discrete {time unit step signal is outlined as;
U(n)=1, for n≥0
0, for n<0
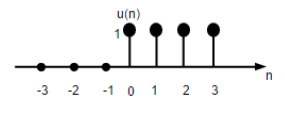 |
The figure {above shows the graphical illustration of a discrete step function.
3. Unit Ramp function
A distinct unit ramp perform will be outlined as −
r(n)=n, for n≥0
0, for n<0
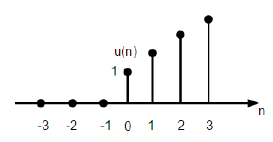 |
The figure given above shows the graphical illustration of a distinct ramp signal.
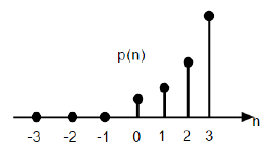
4. Parabolic function
Discrete unit parabolic function is denoted as δn and may be outlined as;
p(n)=n^2, for n≥0
0,for n<0
 |
5. Sinusoidal Signal
All continuous-time signals are periodic. The discrete- time sinusoidal sequences might or might not be periodic. They depend upon the worth the value. For a discrete time signal to be periodic, the angular frequency ω should be a rational multiple of 2π.
 |
A discrete curved signal is shown within the figure on top of.
Discrete type of a sinusoidal signal will be diagrammatic within the within the
x(n)=Asin(ωn+ϕ)
Here A, ω and φ have their usual meaning and n is that the number. time period of the discrete sinusoidal signal is given by −
N=2πm/ω
Where, N and m are integers. We can further make some classifications based on the factors as given below :
1. Relying upon variety of independent variables.
1-D Signals
2-D Signals
2. Relying upon certainty by that signal will be unambiguously described
Deterministic signal
Random Signal
3. Based on repetition
Periodic signal
a. Continuous time signal
b. discrete time signal
Non-Periodic signal
a. Continuous time signal
b. discrete time signal
4. Based on Symmetry
a. Even Signal
X(t) = X(-t) Continuous time signal
X(n) = X(-n) discrete time signal
b. Odd Signal
X(t) = -X(-t) Continuous time signal
X(n) = -X(-n) discrete time signal
5. Based on representation:
1. Analog signal
2. Sampled signal
3. quantized signal
4. Digital Signal
6. Based on duration:
1. Right-sided signal
2. Left-sided signal
3. causal signal
4. Anti-causal signal
5. Non-Causal signal
7. Based on Shape:
Unit Sample
Discrete Pulse
SinC(n/N)
Exponential Series
Sinusoidal Sequence
Operations on signals:
1. Shifting
x(n) shift right or delay = x(n-m)
x(n) shift left or advance = x(n+m)
2. Time reversal or Fold
x(-n+2) is x(-n) delayed by 2 samples.
x(-n-2) is x(-n) advanced by 2 samples.
Classification of Systems:
1. Static or Dynamic System
y(n) = a x (n)
= n x(n) + b x3 (n)
= [x(n)]2
= a(n-1) x(n) y(n)
= [x(n), n]
If its o/p at each value of ‘n’ depends on the o/p until (n-1) and i/p at an equivalent value of ‘n’ or previous value of ‘n’
Key Takeaways:
There are 2 major types of signals which are Discrete Time signals as well as Continuous time signals.
All these signals have different properties and can be used in order to transmit phonetic responses and auditory waves.
STFT may be a sequence of Fourier transform that has time-localized frequency info for situations wherever frequency info for situation in frequency elements of a sign vary over time.
It is given by :
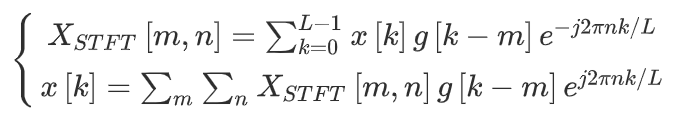 |
where x[k] denotes a signal and g[k] denotes an L-point window function. From the figure the STFT of x[k] will be understood because the Fourier transform of the product x[k]g[k–m].
Visualization of STFT is usually realised via its exposure, that is associate intensity plot of STFT magnitude over time.
Time-frequency analysis
The STFT is employed to perform time-frequency analysis. it's accustomed to generate representations that capture both the standard time and frequency captured within the signal. Like Fourier transform, the STFT additionally depends on fixed basis functions; however, it additionally uses fixed-size time-shifted window functions w(n) to get a change of the ultimate signal and may be expressed as :
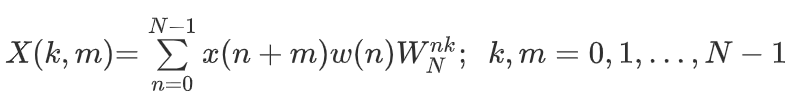 |
Key Takeaways:
Short-Time Fourier Transform is a type of Fourier transform that has time-localized frequency info for situations wherever frequency info for situation in frequency elements of a sign vary over time.
Filter banks are arrangements of low pass, bandpass, and highpass filters used for the spectral decomposition and composition of signals. They play a very important role in several fashionable signal process applications like audio and image writing.
Filter banks that involve numerous sampling rates known as variable systems.
e.g. M-Channel Filter Banks
Multirate Filter Bank
A multirate filter bank do a particular a particular work of dividing a signal into variety of subbands, that are analysed at totally different rates similar to the bandwidth of the frequency bands. This implementation uses downsampling (decimation) and upsampling (expansion).
Multidimensional Filter Banks
1-D filter banks are well developed. However, several signals, like image, video, 3D sound, radar, are third-dimensional, multidimensional styles of multidimensional filter banks.
The simplest design style in an exceedingly multi-dimensional filter bank is to cascade 1D filter banks within the kind of a tree structure wherever the decimation matrix is diagonal and knowledge is processed in every dimension on an individual basis. These systems are called separable systems. In some cases, the support region for the filter banks isn’t separable. In such cases style of filter bank is complicated. In majority of the cases we have a tendency to come with non-separable systems.
A filter bank has an analysis stage and a synthesis stage. every stage encompasses a set of filters in parallel to each other. The filter bank design is the design of the filters within the analysis and synthesis stages. These filters divide the signal into overlapping or non-overlapping sub-bands. The synthesis filters can reconstruct the input back from the sub-bands once the outputs of those filters are combined along. process is usually performed when the analysis stage.
These filter banks are often designed as Infinite impulse response (IIR) or Finite impulse response (FIR). so as to scale back the info rate, downsampling and upsampling are performed within the analysis and synthesis stages, severally.
Key Takeaways:
There are 2 types of filter banks viz, Multirate Filter Banks and Multidimensional Filter Banks.
Linear Predictive Coding (LPC) is known to be a method that is used in the process of speech coding as well as the synthesis of the same. One can verify the different storage galleries that come into play during the entire process. These processes are used to give accurate estimations that are used in order to keep the efficiency of the whole process higher.
One can use this method specifically in order to get samples that have been used in as a combination to get the value of the next prediction. This is used for the purpose of recognition. We can see this with the help of an equation.
 |
We can solve the LPC equations with different types of methods which are given as:
Covariance Method
Autocovariance Method
Inner Product Method
Spectral Estimation Method
Maximum Likelihood Method
Lattice Method
Basic Principles of LPC
There is a filter that is based on the variance of time that helps note down the pulse shapes as well as the different types of forms.
There is also a train that is based on the impulse generator from voice or noise recognition.
We can see a representation of this given below. This model is also known as the “all-pole model”.
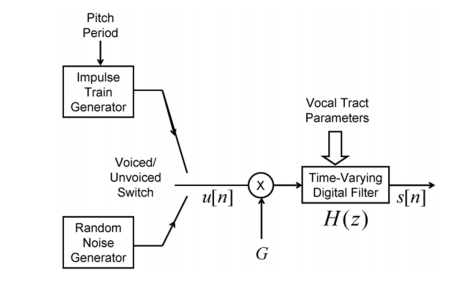 |
Key Takeaways:
Linear Predictive Coding (LPC) is known to be a method that is used in the process of speech coding as well as the synthesis of the same.
References:
Fundamentals of Speech Recognition by Lawrence Rabiner
Speech and Language Processing by Daniel Jurafsky and James H. Martin




