UNIT 5
Memory Management, Virtual Memory
Computer memory can be defined as a collection of some data represented in the binary format. On the basis of various functions, memory can be classified into various categories. We will discuss each one of them later in detail.
A computer device that is capable to store any information or data temporally or permanently, is called storage device.
How Data is being stored in a computer system?
In order to understand memory management, we have to make everything clear about how data is being stored in a computer system.
Machine understands only binary language that is 0 or 1. Computer converts every data into binary language first and then stores it into the memory.
That means if we have a program line written as int α = 10 then the computer converts it into the binary language and then store it into the memory blocks.
The representation of inti = 10 is shown below.
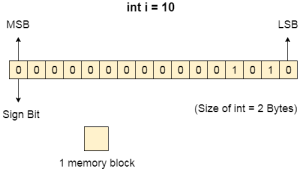
The binary representation of 10 is 1010. Here, we are considering 32 bit system therefore, the size of int is 2 bytes i.e. 16 bit. 1 memory block stores 1 bit. If we are using signed integer then the most significant bit in the memory array is always a signed bit.
Signed bit value 0 represents positive integer while 1 represents negative integer. Here, the range of values that can be stored using the memory array is -32768 to +32767.
well, we can enlarge this range by using unsigned int. in that case, the bit which is now storing the sign will also store the bit value and therefore the range will be 0 to 65,535.
Need for Multi programming
However, The CPU can directly access the main memory, Registers and cache of the system. The program always executes in main memory. The size of main memory affects degree of Multi programming to most of the extant. If the size of the main memory is larger than CPU can load more processes in the main memory at the same time and therefore will increase degree of Multi programming as well as CPU utilization.
Let's consider,
Process Size = 4 MB
Main memory size = 4 MB
The process can only reside in the main memory at any time.
If the time for which the process does IO is P,
Then,
CPU utilization = (1-P)
let's say,
P = 70%
CPU utilization = 30 %
Now, increase the memory size, Let's say it is 8 MB.
Process Size = 4 MB
Two processes can reside in the main memory at the same time.
Let's say the time for which, one process does its IO is P,
Then
CPU utilization = (1-P^2)
let's say P = 70 %
CPU utilization = (1-0.49) =0.51 = 51 %
Therefore, we can state that the CPU utilization will be increased if the memory size gets increased.
Key takeaway
Computer memory can be defined as a collection of some data represented in the binary format. On the basis of various functions, memory can be classified into various categories. We will discuss each one of them later in detail.
A computer device that is capable to store any information or data temporally or permanently, is called storage device.
Physical Address Space
Physical address space in a system can be defined as the size of the main memory. It is really important to compare the process size with the physical address space. The process size must be less than the physical address space.
Physical Address Space = Size of the Main Memory
If, physical address space = 64 KB = 2 ^ 6 KB = 2 ^ 6 X 2 ^ 10 Bytes = 2 ^ 16 bytes
Let us consider,
word size = 8 Bytes = 2 ^ 3 Bytes
Hence,
Physical address space (in words) = (2 ^ 16) / (2 ^ 3) = 2 ^ 13 Words
Therefore,
Physical Address = 13 bits
In General,
If, Physical Address Space = N Words
then, Physical Address = log2 N
Logical Address Space
Logical address space can be defined as the size of the process. The size of the process should be less enough so that it can reside in the main memory.
Let's say,
Logical Address Space = 128 MB = (2 ^ 7 X 2 ^ 20) Bytes = 2 ^ 27 Bytes
Word size = 4 Bytes = 2 ^ 2 Bytes
Logical Address Space (in words) = (2 ^ 27) / (2 ^ 2) = 2 ^ 25 Words
Logical Address = 25 Bits
In general,
If, logical address space = L words
Then, Logical Address = Log2L bits
What is a Word?
The Word is the smallest unit of the memory. It is the collection of bytes. Every operating system defines different word sizes after analyzing the n-bit address that is inputted to the decoder and the 2 ^ n memory locations that are produced from the decoder.
Key takeaway
Physical address space in a system can be defined as the size of the main memory. It is really important to compare the process size with the physical address space. The process size must be less than the physical address space.
Physical Address Space = Size of the Main Memory
Memory Management Techniques
Here, are some most crucial memory management techniques:
Single Contiguous Allocation
It is the easiest memory management technique. In this method, all types of computer's memory except a small portion which is reserved for the OS is available for one application. For example, MS-DOS operating system allocates memory in this way. An embedded system also runs on a single application.
Partitioned Allocation
It divides primary memory into various memory partitions, which is mostly contiguous areas of memory. Every partition store all the information for a specific task or job. This method consists of allotting a partition to a job when it starts & unallocated when it ends.
Paged Memory Management
This method divides the computer's main memory into fixed-size units known as page frames. This hardware memory management unit maps pages into frames which should be allocated on a page basis.
Segmented Memory Management
Segmented memory is the only memory management method that does not provide the user's program with a linear and contiguous address space.
Segments need hardware support in the form of a segment table. It contains the physical address of the section in memory, size, and other data like access protection bits and status.
What is Swapping?
Swapping is a method in which the process should be swapped temporarily from the main memory to the backing store. It will be later brought back into the memory for continue execution.
Backing store is a hard disk or some other secondary storage device that should be big enough inorder to accommodate copies of all memory images for all users. It is also capable of offering direct access to these memory images.
Benefits of Swapping
Here, are major benefits/pros of swapping:
It offers a higher degree of multiprogramming.
Allows dynamic relocation. For example, if address binding at execution time is being used, then processes can be swap in different locations. Else in case of compile and load time bindings, processes should be moved to the same location.
It helps to get better utilization of memory.
Minimum wastage of CPU time on completion so it can easily be applied to a priority-based scheduling method to improve its performance.
What is Memory allocation?
Memory allocation is a process by which computer programs are assigned memory or space.
Here, main memory is divided into two types of partitions
Low Memory - Operating system resides in this type of memory.
High Memory- User processes are held in high memory.
Partition Allocation
Memory is divided into different blocks or partitions. Each process is allocated according to the requirement. Partition allocation is an ideal method to avoid internal fragmentation.
Below are the various partition allocation schemes:
First Fit: In this type fit, the partition is allocated, which is the first sufficient block from the beginning of the main memory.
Best Fit: It allocates the process to the partition that is the first smallest partition among the free partitions.
Worst Fit: It allocates the process to the partition, which is the largest sufficient freely available partition in the main memory.
Next Fit: It is mostly similar to the first Fit, but this Fit, searches for the first sufficient partition from the last allocation point.
What is Paging?
Paging is a storage mechanism that allows OS to retrieve processes from the secondary storage into the main memory in the form of pages. In the Paging method, the main memory is divided into small fixed-size blocks of physical memory, which is called frames. The size of a frame should be kept the same as that of a page to have maximum utilization of the main memory and to avoid external fragmentation. Paging is used for faster access to data, and it is a logical concept.
What is Fragmentation?
Processes are stored and removed from memory, which creates free memory space, which are too small to use by other processes.
After sometimes, that processes not able to allocate to memory blocks because its small size and memory blocks always remain unused is called fragmentation. This type of problem happens during a dynamic memory allocation system when free blocks are quite small, so it is not able to fulfil any request.
Two types of Fragmentation methods are:
External fragmentation
Internal fragmentation
External fragmentation can be reduced by rearranging memory contents to place all free memory together in a single block.
The internal fragmentation can be reduced by assigning the smallest partition, which is still good enough to carry the entire process.
What is Segmentation?
Segmentation method works almost similarly to paging. The only difference between the two is that segments are of variable-length, whereas, in the paging method, pages are always of fixed size.
A program segment includes the program's main function, data structures, utility functions, etc. The OS maintains a segment map table for all the processes. It also includes a list of free memory blocks along with its size, segment numbers, and its memory locations in the main memory or virtual memory.
What is Dynamic Loading?
Dynamic loading is a routine of a program which is not loaded until the program calls it. All routines should be contained on disk in a relocatable load format. The main program will be loaded into memory and will be executed. Dynamic loading also provides better memory space utilization.
What is Dynamic Linking?
Linking is a method that helps OS to collect and merge various modules of code and data into a single executable file. The file can be loaded into memory and executed. OS can link system-level libraries into a program that combines the libraries at load time. In Dynamic linking method, libraries are linked at execution time, so program code size can remain small.
Difference Between Static and Dynamic Loading
Static Loading | Dynamic Loading |
Static loading is used when you want to load your program statically. Then at the time of compilation, the entire program will be linked and compiled without need of any external module or program dependency. | In a Dynamically loaded program, references will be provided and the loading will be done at the time of execution. |
At loading time, the entire program is loaded into memory and starts its execution. | Routines of the library are loaded into memory only when they are required in the program. |
Difference Between Static and Dynamic Linking
Here is main difference between Static vs. Dynamic Linking:
Static Linking | Dynamic Linking |
Static linking is used to combine all other modules, which are required by a program into a single executable code. This helps OS prevent any runtime dependency. | When dynamic linking is used, it does not need to link the actual module or library with the program. Instead of it use a reference to the dynamic module provided at the time of compilation and linking. |
Summary:
Memory management is the process of controlling and coordinating computer memory, assigning portions called blocks to various running programs to optimize the overall performance of the system.
It allows you to check how much memory needs to be allocated to processes that decide which processor should get memory at what time.
In Single Contiguous Allocation, all types of computer's memory except a small portion which is reserved for the OS is available for one application
Partitioned Allocation method divides primary memory into various memory partitions, which is mostly contiguous areas of memory
Paged Memory Management method divides the computer's main memory into fixed-size units known as page frames
Segmented memory is the only memory management method that does not provide the user's program with a linear and contiguous address space.
Swapping is a method in which the process should be swapped temporarily from the main memory to the backing store. It will be later brought back into the memory for continue execution.
Memory allocation is a process by which computer programs are assigned memory or space.
Paging is a storage mechanism that allows OS to retrieve processes from the secondary storage into the main memory in the form of pages.
Fragmentation refers to the condition of a disk in which files are divided into pieces scattered around the disk.
Segmentation method works almost similarly to paging. The only difference between the two is that segments are of variable-length, whereas, in the paging method, pages are always of fixed size.
Dynamic loading is a routine of a program which is not loaded until the program calls it.
Linking is a method that helps OS to collect and merge various modules of code and data into a single executable file.
Key takeaway
It is the easiest memory management technique. In this method, all types of computer's memory except a small portion which is reserved for the OS is available for one application. For example, MS-DOS operating system allocates memory in this way. An embedded system also runs on a single application.
Paging
In Operating Systems, Paging is a storage mechanism used to retrieve processes from the secondary storage into the main memory in the form of pages.
The main idea behind the paging is to divide each process in the form of pages. The main memory will also be divided in the form of frames.
One page of the process is to be stored in one of the frames of the memory. The pages can be stored at the different locations of the memory but the priority is always to find the contiguous frames or holes.
Pages of the process are brought into the main memory only when they are required otherwise, they reside in the secondary storage.
Different operating system defines different frame sizes. The sizes of each frame must be equal. Considering the fact that the pages are mapped to the frames in Paging, page size needs to be as same as frame size.

Fig 1 – Collection of frames
Example
Let us consider the main memory size 16 Kb and Frame size is 1 KB therefore the main memory will be divided into the collection of 16 frames of 1 KB each.
There are 4 processes in the system that is P1, P2, P3 and P4 of 4 KB each. Each process is divided into pages of 1 KB each so that one page can be stored in one frame.
Initially, all the frames are empty therefore pages of the processes will get stored in the contiguous way.
Frames, pages and the mapping between the two is shown in the image below.
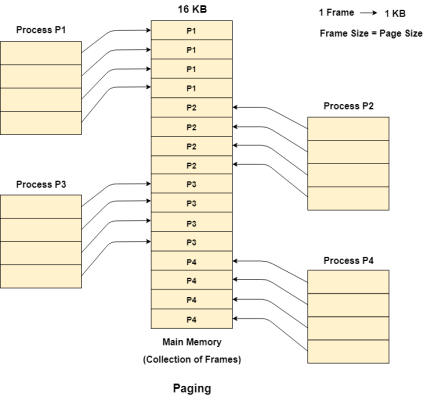
Fig 2 - Paging
Let us consider that, P2 and P4 are moved to waiting state after some time. Now, 8 frames become empty and therefore other pages can be loaded in that empty place. The process P5 of size 8 KB (8 pages) is waiting inside the ready queue.
Given the fact that, we have 8 non-contiguous frames available in the memory and paging provides the flexibility of storing the process at the different places. Therefore, we can load the pages of process P5 in the place of P2 and P4.
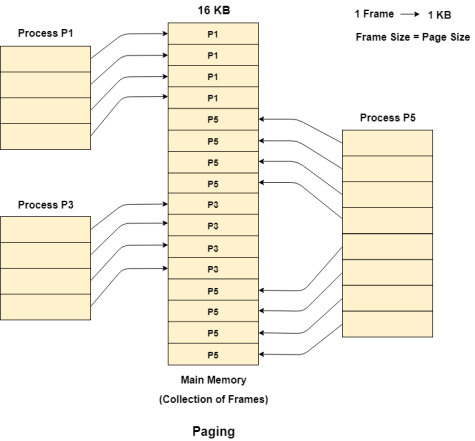
Fig 3 - example
Memory Management Unit
The purpose of Memory Management Unit (MMU) is to convert the logical address into the physical address. The logical address is the address generated by the CPU for every page while the physical address is the actual address of the frame where each page will be stored.
When a page is to be accessed by the CPU by using the logical address, the operating system needs to obtain the physical address to access that page physically.
The logical address has two parts.
Page Number
Offset
Memory management unit of OS needs to convert the page number to the frame number.
Example
Considering the above image, let’s say that the CPU demands 10th word of 4th page of process P3. Since the page number 4 of process P1 gets stored at frame number 9 therefore the 10th word of 9th frame will be returned as the physical address.
Segmentation
In Operating Systems, Segmentation is a memory management technique in which, the memory is divided into the variable size parts. Each part is known as segment which can be allocated to a process.
The details about each segment are stored in a table called as segment table. Segment table is stored in one (or many) of the segments.
Segment table contains mainly two information about segment:
Base: It is the base address of the segment
Limit: It is the length of the segment.
Why Segmentation is required?
Till now, we were using Paging as our main memory management technique. Paging is closer to Operating system rather than the User. It divides all the process into the form of pages regardless of the fact that a process can have some relative parts of functions which needs to be loaded in the same page.
Operating system doesn’t care about the User’s view of the process. It may divide the same function into different pages and those pages may or may not be loaded at the same time into the memory. It decreases the efficiency of the system.
It is better to have segmentation which divides the process into the segments. Each segment contains same type of functions such as main function can be included in one segment and the library functions can be included in the other segment,
Translation of Logical address into physical address by segment table
CPU generates a logical address which contains two parts:
Segment Number
Offset
The Segment number is mapped to the segment table. The limit of the respective segment is compared with the offset. If the offset is less than the limit then the address is valid otherwise it throws an error as the address is invalid.
In the case of valid address, the base address of the segment is added to the offset to get the physical address of actual word in the main memory.
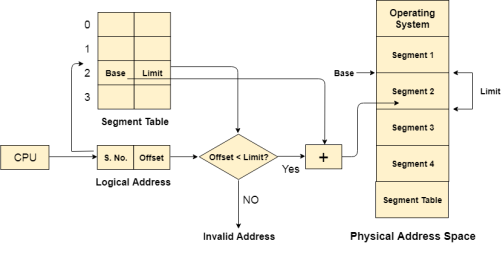
Fig 4 – Physical address space
Advantages of Segmentation
1. No internal fragmentation
2. Average Segment Size is larger than the actual page size.
3. Less overhead
4. It is easier to relocate segments than entire address space.
5. The segment table is of lesser size as compare to the page table in paging.
Disadvantages
1. It can have external fragmentation.
2. It is difficult to allocate contiguous memory to variable sized partition.
3. Costly memory management algorithms.
Paging VS Segmentation
Sr No. | Paging | Segmentation |
1 | Non-Contiguous memory allocation | Non-contiguous memory allocation |
2 | Paging divides program into fixed size pages. | Segmentation divides program into variable size segments. |
3 | OS is responsible | Compiler is responsible. |
4 | Paging is faster than segmentation | Segmentation is slower than paging |
5 | Paging is closer to Operating System | Segmentation is closer to User |
6 | It suffers from internal fragmentation | It suffers from external fragmentation |
7 | There is no external fragmentation | There is no external fragmentation |
8 | Logical address is divided into page number and page offset | Logical address is divided into segment number and segment offset |
9 | Page table is used to maintain the page information. | Segment Table maintains the segment information |
10 | Page table entry has the frame number and some flag bits to represent details about pages. | Segment table entry has the base address of the segment and some protection bits for the segments. |
Key takeaway
In Operating Systems, Paging is a storage mechanism used to retrieve processes from the secondary storage into the main memory in the form of pages.
The main idea behind the paging is to divide each process in the form of pages. The main memory will also be divided in the form of frames.
One page of the process is to be stored in one of the frames of the memory. The pages can be stored at the different locations of the memory but the priority is always to find the contiguous frames or holes.
Memory Page Allocation
Consider Tasks A, B, and C that need to be loaded into memory for execution. We have a total memory space sized at 32Mb. Memory frames have been partitioned into 4Mb compartments. An area is reserved exclusively for the operating system.
Task A requires 8Mb of memory for execution. This means that task A will have to be allocated two 4Mb frames. This is indicated by pages A0 and A1 in main memory.
Task B requires 11Mb of memory for execution. This means Task B will have to be allocated three 4Mb frames denoted by pages B0, B1, and B2, to accommodate its size.
Task C requires less than 4Mb, but will have to occupy one 4MB frame, shown as page C0
|
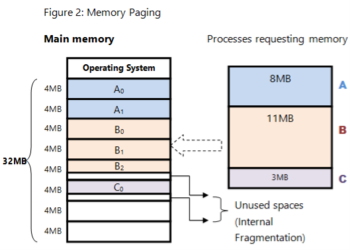
Fig 5 – memory paging
Internal Fragmentation
So, what happens to the unoccupied spaces within the frames allocated to pages B2 and C0? These spaces are referred to as internal fragmentation in memory, which occurs when allocated memory is larger than the requested memory. Memory is precious, and fragmentation can be a disadvantage.
We must note however, that pages do not need to be allocated in contiguous spaces in memory for tasks to be executed successfully. We see that page B0 is followed by page B1, which follows with page B2. This is not always the case. Process A, for example, can complete execution and be removed from memory to allow other awaiting tasks to load into memory.
Let's introduce Task D as a 16Mb process waiting to be loaded into memory. The frames previously occupied by Process A are now available, and process D is allocated these frames as denoted by pages D0 and D1.
The rest of the pages for process D are allocated in frames located after the pages of tasks B and C, as seen. The non-contiguous frames into which pages of Task D are loaded do not affect its execution. An empty frame can be used by any task.
|
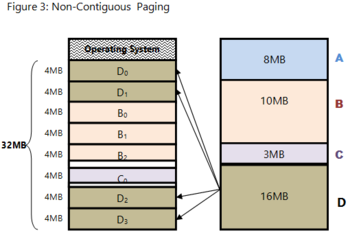
Fig 6 – non-contiguous paging
Frame use has to be tracked and monitored by the operating system (OS) to ensure that as processes are swapped in and out of memory, task executions are not impacted. The OS must know the location of every page. The OS does this by using page tables, which we'll talk about in a bit.
Demand and Page Tables
Demand page memory allocation is the technique in which pages within a particular process or task are swapped in and out of main memory from secondary memory as required for execution. This process is also tracked through the use of page tables.
Page tables are used to track and locate where the different pages of a process or task are located in memory (frames). A page table shows the mapping of physical address locations with virtual address locations. Because pages of a process can occupy non-contiguous frames positions, the OS needs to keep track of where each page is stored.
To better understand page tables, we will first assign frame identifiers called addresses (usually stored in hexadecimal format) to the memory frames. This way, we are able to determine which particular frame stores the page of a particular task.
|
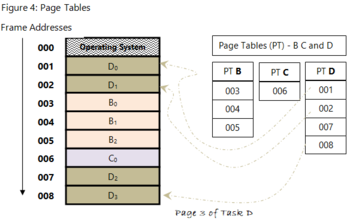
Fig 7 – Page tables
The columns in each table identify the task or process (PT B, PT C and PT D). Each page table (PT) consists of rows. Each row stores the mapping information of the different pages within that task. The first row therefore represents the mapping information for the first page (denoted by page 0); the next row contains the mapping information for page 1; and so on for that specific process.
Let's take PT D for example. PT D consists of 4 rows. This means that task D was split into 4 pages. D0 (page 0 of task D) is stored in frame addressed 001.
Lesson Summary
The ability of systems to multitask is key, and memory is at the core of it all. Programs need to be loaded into memory for execution, but sometimes these programs are too large to be held in memory all at once. The OS therefore implements a paging system. Tasks are split into fixed sizes called pages and loaded into memory as and when needed.
Paged memory allocation is a memory management technique in which the OS controls the way memory is shared among different processes or tasks.
Memory is partitioned into frames that hold the different pages of executing tasks while the remainder of the program is kept in secondary memory until needed. The process of swapping pages from main memory to secondary memory and back is called demand page memory allocation.
The OS keeps track of what's stored where through the use of page tables, which show the mapping of physical address locations with virtual address locations.
Key takeaway
Consider Tasks A, B, and C that need to be loaded into memory for execution. We have a total memory space sized at 32Mb. Memory frames have been partitioned into 4Mb compartments. An area is reserved exclusively for the operating system.
Task A requires 8Mb of memory for execution. This means that task A will have to be allocated two 4Mb frames. This is indicated by pages A0 and A1 in main memory.
Task B requires 11Mb of memory for execution. This means Task B will have to be allocated three 4Mb frames denoted by pages B0, B1, and B2, to accommodate its size.
Paging is a memory-management technique that provides the non-contiguous address space in main memory. Paging avoids external fragmentation. In this technique physical memory is broken into fixed-sized blocks called frames and logical memory is divided into blocks of the same size called pages. When a process is to be executed, its pages are loaded into any available memory frames from the backing store.
The address generated by CPU is called logical address and it is divided into two parts a page number (p) and a page offset (d). The page number is used as an index into a page table. The page table contains the base address of each page in physical memory. The combination of base address and page offset is used to map the page in physical memory address. Hardware decides the page size.
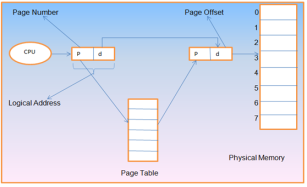
Fig 8 – hardware support
Key takeaway
Paging is a memory-management technique that provides the non-contiguous address space in main memory. Paging avoids external fragmentation. In this technique physical memory is broken into fixed-sized blocks called frames and logical memory is divided into blocks of the same size called pages. When a process is to be executed, its pages are loaded into any available memory frames from the backing store.
Security refers to providing a protection system to computer system resources such as CPU, memory, disk, software programs and most importantly data/information stored in the computer system. If a computer program is run by an unauthorized user, then he/she may cause severe damage to computer or data stored in it. So, a computer system must be protected against unauthorized access, malicious access to system memory, viruses, worms etc. We're going to discuss following topics in this chapter.
Authentication
One Time passwords
Program Threats
System Threats
Computer Security Classifications
Authentication
Authentication refers to identifying each user of the system and associating the executing programs with those users. It is the responsibility of the Operating System to create a protection system which ensures that a user who is running a particular program is authentic. Operating Systems generally identifies/authenticates users using following three ways −
Username / Password − User need to enter a registered username and password with Operating system to login into the system.
User card/key − User need to punch card in card slot, or enter key generated by key generator in option provided by operating system to login into the system.
User attribute - fingerprint/ eye retina pattern/ signature − User need to pass his/her attribute via designated input device used by operating system to login into the system.
One Time passwords
One-time passwords provide additional security along with normal authentication. In One-Time Password system, a unique password is required every time user tries to login into the system. Once a one-time password is used, then it cannot be used again. One-time password are implemented in various ways.
Random numbers − Users are provided cards having numbers printed along with corresponding alphabets. System asks for numbers corresponding to few alphabets randomly chosen.
Secret key − User are provided a hardware device which can create a secret id mapped with user id. System asks for such secret id which is to be generated every time prior to login.
Network password − Some commercial applications send one-time passwords to user on registered mobile/ email which is required to be entered prior to login.
Program Threats
Operating system's processes and kernel do the designated task as instructed. If a user program made these process do malicious tasks, then it is known as Program Threats. One of the common examples of program threat is a program installed in a computer which can store and send user credentials via network to some hacker. Following is the list of some well-known program threats.
Trojan Horse − Such program traps user login credentials and stores them to send to malicious user who can later on login to computer and can access system resources.
Trap Door − If a program which is designed to work as required, have a security hole in its code and perform illegal action without knowledge of user then it is called to have a trap door.
Logic Bomb − Logic bomb is a situation when a program misbehaves only when certain conditions met otherwise it works as a genuine program. It is harder to detect.
Virus − Virus as name suggest can replicate themselves on computer system. They are highly dangerous and can modify/delete user files, crash systems. A virus is generally a small code embedded in a program. As user accesses the program, the virus starts getting embedded in other files/ programs and can make system unusable for user
System Threats
System threats refers to misuse of system services and network connections to put user in trouble. System threats can be used to launch program threats on a complete network called as program attack. System threats creates such an environment that operating system resources/ user files are misused. Following is the list of some well-known system threats.
Worm − Worm is a process which can choked down a system performance by using system resources to extreme levels. A Worm process generates its multiple copies where each copy uses system resources, prevents all other processes to get required resources. Worms processes can even shut down an entire network.
Port Scanning − Port scanning is a mechanism or means by which a hacker can detects system vulnerabilities to make an attack on the system.
Denial of Service − Denial of service attacks normally prevent user to make legitimate use of the system. For example, a user may not be able to use internet if denial of service attacks browser's content settings.
Computer Security Classifications
As per the U.S. Department of Defence Trusted Computer System's Evaluation Criteria there are four security classifications in computer systems: A, B, C, and D. This is widely used specifications to determine and model the security of systems and of security solutions. Following is the brief description of each classification.
S.N. | Classification Type & Description |
1 | Type A Highest Level. Uses formal design specifications and verification techniques. Grants a high degree of assurance of process security. |
2 | Type B Provides mandatory protection system. Have all the properties of a class C2 system. Attaches a sensitivity label to each object. It is of three types. B1 − Maintains the security label of each object in the system. Label is used for making decisions to access control. B2 − Extends the sensitivity labels to each system resource, such as storage objects, supports covert channels and auditing of events. B3 − Allows creating lists or user groups for access-control to grant access or revoke access to a given named object. |
3 | Type C Provides protection and user accountability using audit capabilities. It is of two types. C1 − Incorporates controls so that users can protect their private information and keep other users from accidentally reading / deleting their data. UNIX versions are mostly Cl class. C2 − Adds an individual-level access control to the capabilities of a Cl level system. |
4 | Type D Lowest level. Minimum protection. MS-DOS, Window 3.1 fall in this category. |
Key takeaway
Security refers to providing a protection system to computer system resources such as CPU, memory, disk, software programs and most importantly data/information stored in the computer system. If a computer program is run by an unauthorized user, then he/she may cause severe damage to computer or data stored in it. So, a computer system must be protected against unauthorized access, malicious access to system memory, viruses, worms etc.
Advantages of Paging
Here, are advantages of using Paging method:
1. Easy to use memory management algorithm
2. No need for external Fragmentation
3. Swapping is easy between equal-sized pages and page frames.
Disadvantages of Paging
Here, are drawback/ cons of Paging:
1. May cause Internal fragmentation
2. Complex memory management algorithm
3. Page tables consume additonal memory.
4. Multi-level paging may lead to memory reference overhead.
Advantages of a Segmentation method
Here, are pros/benefits of Segmentation
1. Offer protection within the segments
2. You can achieve sharing by segments referencing multiple processes.
3. Not offers internal fragmentation
4. Segment tables use lesser memory than paging
Disadvantages of Segmentation
Here are cons/drawback of Segmentation
1. In segmentation method, processes are loaded/ removed from the main memory. Therefore, the free memory space is separated into small pieces which may create a problem of external fragmentation
2. Costly memory management algorithm
Summary:
Paging is a storage mechanism that allows OS to retrieve processes from the secondary storage into the main memory in the form of pages.
The paging process should be protected by using the concept of insertion of an additional bit called Valid/Invalid bit.
The biggest advantage of paging is that it is easy to use memory management algorithm
Paging may cause Internal fragmentation
Segmentation method works almost similarly to paging, only difference between the two is that segments are of variable-length whereas, in the paging method, pages are always of fixed size.
You can achieve sharing by segments referencing multiple processes.
Segmentation is costly memory management algorithm
Key takeaway
Easy to use memory management algorithm
No need for external Fragmentation
Swapping is easy between equal-sized pages and page frames.
A computer can address more memory than the amount physically installed on the system. This extra memory is actually called virtual memory and it is a section of a hard disk that's set up to emulate the computer's RAM.
The main visible advantage of this scheme is that programs can be larger than physical memory. Virtual memory serves two purposes. First, it allows us to extend the use of physical memory by using disk. Second, it allows us to have memory protection, because each virtual address is translated to a physical address.
Following are the situations, when entire program is not required to be loaded fully in main memory.
User written error handling routines are used only when an error occurred in the data or computation.
Certain options and features of a program may be used rarely.
Many tables are assigned a fixed amount of address space even though only a small amount of the table is actually used.
The ability to execute a program that is only partially in memory would counter many benefits.
Less number of I/O would be needed to load or swap each user program into memory.
A program would no longer be constrained by the amount of physical memory that is available.
Each user program could take less physical memory, more programs could be run the same time, with a corresponding increase in CPU utilization and throughput.
Modern microprocessors intended for general-purpose use, a memory management unit, or MMU, is built into the hardware. The MMU's job is to translate virtual addresses into physical addresses. A basic example is given below −
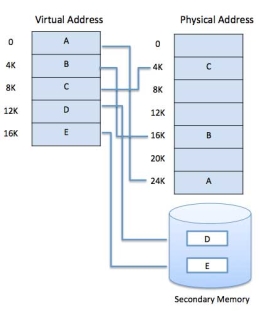
Fig 9 - example
Virtual memory is commonly implemented by demand paging. It can also be implemented in a segmentation system. Demand segmentation can also be used to provide virtual memory.
Demand Paging
A demand paging system is quite similar to a paging system with swapping where processes reside in secondary memory and pages are loaded only on demand, not in advance. When a context switch occurs, the operating system does not copy any of the old program’s pages out to the disk or any of the new program’s pages into the main memory Instead, it just begins executing the new program after loading the first page and fetches that program’s pages as they are referenced.
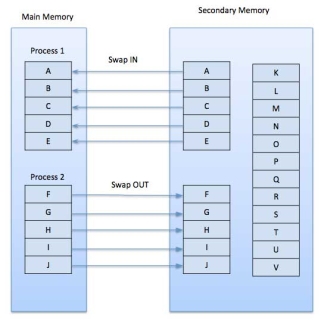
Fig 10 - swapping
While executing a program, if the program references a page which is not available in the main memory because it was swapped out a little ago, the processor treats this invalid memory reference as a page fault and transfers control from the program to the operating system to demand the page back into the memory.
Advantages
Following are the advantages of Demand Paging −
1. Large virtual memory.
2. More efficient use of memory.
3. There is no limit on degree of multiprogramming.
Disadvantages
Number of tables and the amount of processor overhead for handling page interrupts are greater than in the case of the simple paged management techniques.
Page Replacement Algorithm
Page replacement algorithms are the techniques using which an Operating System decides which memory pages to swap out, write to disk when a page of memory needs to be allocated. Paging happens whenever a page fault occurs and a free page cannot be used for allocation purpose accounting to reason that pages are not available or the number of free pages is lower than required pages.
When the page that was selected for replacement and was paged out, is referenced again, it has to read in from disk, and this requires for I/O completion. This process determines the quality of the page replacement algorithm: the lesser the time waiting for page-ins, the better is the algorithm.
A page replacement algorithm looks at the limited information about accessing the pages provided by hardware, and tries to select which pages should be replaced to minimize the total number of page misses, while balancing it with the costs of primary storage and processor time of the algorithm itself. There are many different page replacement algorithms. We evaluate an algorithm by running it on a particular string of memory reference and computing the number of page faults,
Reference String
The string of memory references is called reference string. Reference strings are generated artificially or by tracing a given system and recording the address of each memory reference. The latter choice produces a large number of data, where we note two things.
For a given page size, we need to consider only the page number, not the entire address.
If we have a reference to a page p, then any immediately following references to page p will never cause a page fault. Page p will be in memory after the first reference; the immediately following references will not fault.
For example, consider the following sequence of addresses − 123,215,600,1234,76,96
If page size is 100, then the reference string is 1,2,6,12,0,0
First In First Out (FIFO) algorithm
Oldest page in main memory is the one which will be selected for replacement.
Easy to implement, keep a list, replace pages from the tail and add new pages at the head.
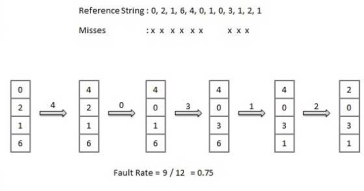
Optimal Page algorithm
An optimal page-replacement algorithm has the lowest page-fault rate of all algorithms. An optimal page-replacement algorithm exists, and has been called OPT or MIN.
Replace the page that will not be used for the longest period of time. Use the time when a page is to be used.
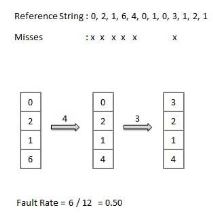
Least Recently Used (LRU) algorithm
Page which has not been used for the longest time in main memory is the one which will be selected for replacement.
Easy to implement, keep a list, replace pages by looking back into time.
Page Buffering algorithm
To get a process start quickly, keep a pool of free frames.
On page fault, select a page to be replaced.
Write the new page in the frame of free pool, mark the page table and restart the process.
Now write the dirty page out of disk and place the frame holding replaced page in free pool.
Least frequently Used (LFU) algorithm
The page with the smallest count is the one which will be selected for replacement.
This algorithm suffers from the situation in which a page is used heavily during the initial phase of a process, but then is never used again.
Most frequently Used (MFU) algorithm
This algorithm is based on the argument that the page with the smallest count was probably just brought in and has yet to be used.
Key takeaway
A computer can address more memory than the amount physically installed on the system. This extra memory is actually called virtual memory and it is a section of a hard disk that's set up to emulate the computer's RAM.
The main visible advantage of this scheme is that programs can be larger than physical memory. Virtual memory serves two purposes. First, it allows us to extend the use of physical memory by using disk. Second, it allows us to have memory protection, because each virtual address is translated to a physical address.
On comparing simple paging and simple segmentation on the one hand, with fixed and dynamic partitioning on the other creates foundation for a fundamental breakthrough in memory management. Two characteristics of paging and segmentation are the keys to this breakthrough.
All memory references within a process are logical addresses that are dynamically translated into physical addresses at run time. This means that a process may be swapped in an out of main memory such that it occupies different regions of main memory at different times during the course of execution.
A process may be broken up into a number of pieces and these pieces need not be contiguously located in main memory during the execution. The combination of dynamic run time address translation and the use of a page or segment table permit this.
If these two characteristics are present, then it is not necessary that all pages or all the segments of a process be in memory during execution. If a piece that holds the next instruction to be fetched and the piece that holds the next data location to be accessed are in main memory, then at least for a time execution may proceed.
There are two implications, the second more startling than the first, and both lead to improved system utility. More process may be maintained in main memory. Because we are going to load some of the pieces of any particular process, there is room for more processes. This leads to more efficient use of the processor because it is more likely that at least one of the more numerous processes will be in a Ready state at any particular state.
It is possible for a process to be larger than all the main memory. One of the most fundamental restrictions in programming is lifted. A programmer must be acutely aware of how much memory is available. If the program being written is too large, the programmer must devise ways to structure the program into pieces that can be loaded separately in some sort of overlay strategy. With virtual memory based on paging or segmentation, that job is left to the operating system and the hardware. As far as the programmer is concerned, they are dealing with a huge memory associated with disk storage. The operating system automatically loads pieces into main memory as required.
Quick Note: Taking the Nonsense out of looking for the right spyware remover
If you really want to take the work out of looking for that right Spyware Protection from a go to the Internet and get a or a Free Download, In order to prevent your vital information from being ripped from your computer get your Remover Today.
A process executes only in main memory that memory is referred to as real memory.
Key takeaway
On comparing simple paging and simple segmentation on the one hand, with fixed and dynamic partitioning on the other creates foundation for a fundamental breakthrough in memory management. Two characteristics of paging and segmentation are the keys to this breakthrough.
All memory references within a process are logical addresses that are dynamically translated into physical addresses at run time. This means that a process may be swapped in an out of main memory such that it occupies different regions of main memory at different times during the course of execution.
Locality of reference refers to a phenomenon in which a computer program tends to access same set of memory locations for a particular time period. In other words, Locality of Reference refers to the tendency of the computer program to access instructions whose addresses are near one another. The property of locality of reference is mainly shown by loops and subroutine calls in a program.
Fig 11 – locality of reference
In case of loops in program control processing unit repeatedly refers to the set of instructions that constitute the loop.
In case of subroutine calls, every time the set of instructions are fetched from memory.
References to data items also get localized that means same data item is referenced again and again.

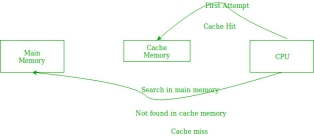
Fig 12 - example
In the above figure, you can see that the CPU wants to read or fetch the data or instruction. First, it will access the cache memory as it is near to it and provides very fast access. If the required data or instruction is found, it will be fetched. This situation is known as a cache hit. But if the required data or instruction is not found in the cache memory then this situation is known as a cache miss. Now the main memory will be searched for the required data or instruction that was being searched and if found will go through one of the two ways:
First way is that the CPU should fetch the required data or instruction and use it and that’s it but what, when the same data or instruction is required again. CPU again has to access the same main memory location for it and we already know that main memory is the slowest to access.
The second way is to store the data or instruction in the cache memory so that if it is needed soon again in the near future it could be fetched in a much faster way.
Cache Operation:
It is based on the principle of locality of reference. There are two ways with which data or instruction is fetched from main memory and get stored in cache memory. These two ways are the following:
Temporal Locality –
Temporal locality means current data or instruction that is being fetched may be needed soon. So, we should store that data or instruction in the cache memory so that we can avoid again searching in main memory for the same data.
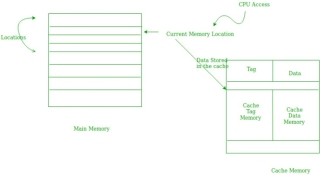
Fig 13 – temporal locality
When CPU accesses the current main memory location for reading required data or instruction, it also gets stored in the cache memory which is based on the fact that same data or instruction may be needed in near future. This is known as temporal locality. If some data is referenced, then there is a high probability that it will be referenced again in the near future.
Spatial Locality –
Spatial locality means instruction or data near to the current memory location that is being fetched, may be needed soon in the near future. This is slightly different from the temporal locality. Here we are talking about nearly located memory locations while in temporal locality we were talking about the actual memory location that was being fetched.
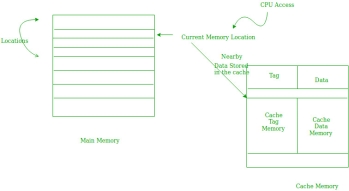
Fig 14 – Spatial locality
Cache Performance:
The performance of the cache is measured in terms of hit ratio. When CPU refers to memory and find the data or instruction within the cache memory, it is known as cache hit. If the desired data or instruction is not found in the cache memory and CPU refers to the main memory to find that data or instruction, it is known as a cache miss.
Hit + Miss = Total CPU Reference
Hit Ratio(h) = Hit / (Hit+Miss)
Average access time of any memory system consists of two levels: Cache and Main Memory. If Tc is time to access cache memory and Tm is the time to access main memory then we can write:
Tavg = Average time to access memory
Tavg = h * Tc + (1-h)*(Tm + Tc)
Key takeaway
Locality of reference refers to a phenomenon in which a computer program tends to access same set of memory locations for a particular time period. In other words, Locality of Reference refers to the tendency of the computer program to access instructions whose addresses are near one another. The property of locality of reference is mainly shown by loops and subroutine calls in a program.
A page fault occurs when a program attempts to access data or code that is in its address space, but is not currently located in the system RAM. So when page fault occurs then following sequence of events happens:
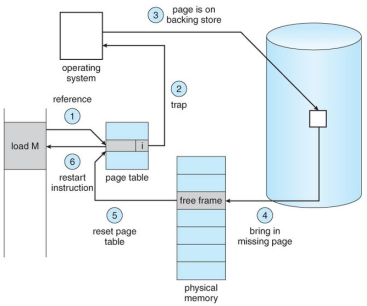
Fig 15 – Page fault
The computer hardware traps to the kernel and program counter (PC) is saved on the stack. Current instruction state information is saved in CPU registers.
An assembly program is started to save the general registers and other volatile information to keep the OS from destroying it.
Operating system finds that a page fault has occurred and tries to find out which virtual page is needed. Sometimes hardware register contains this required information. If not, the operating system must retrieve PC, fetch instruction and find out what it was doing when the fault occurred.
Once virtual address caused page fault is known, system checks to see if address is valid and checks if there is no protection access problem.
If the virtual address is valid, the system checks to see if a page frame is free. If no frames are free, the page replacement algorithm is run to remove a page.
If frame selected is dirty, page is scheduled for transfer to disk, context switch takes place, fault process is suspended and another process is made to run until disk transfer is completed.
As soon as page frame is clean, operating system looks up disk address where needed page is, schedules disk operation to bring it in.
When disk interrupt indicates page has arrived, page tables are updated to reflect its position, and frame marked as being in normal state.
Faulting instruction is backed up to state it had when it began and PC is reset. Faulting is scheduled, operating system returns to routine that called it.
Assembly Routine reloads register and other state information, returns to user space to continue execution.
Key takeaway
A page fault occurs when a program attempts to access data or code that is in its address space, but is not currently located in the system RAM. So, when page fault occurs then following sequence of events happens:
Working Set Model –
This model is based on the above-stated concept of the Locality Model.
The basic principle states that if we allocate enough frames to a process to accommodate its current locality, it will only fault whenever it moves to some new locality. But if the allocated frames are lesser than the size of the current locality, the process is bound to thrash.
According to this model, based on a parameter A, the working set is defined as the set of pages in the most recent ‘A’ page references. Hence, all the actively used pages would always end up being a part of the working set.
The accuracy of the working set is dependent on the value of parameter A. If A is too large, then working sets may overlap. On the other hand, for smaller values of A, the locality might not be covered entirely.
If D is the total demand for frames and is the working set size for a process i,
Now, if ‘m’ is the number of frames available in the memory, there are 2 possibilities:
(i) D>m i.e. total demand exceeds the number of frames, then thrashing will occur as some processes would not get enough frames.
(ii) D<=m, then there would be no thrashing.
If there are enough extra frames, then some more processes can be loaded in the memory. On the other hand, if the summation of working set sizes exceeds the availability of frames, then some of the processes have to be suspended (swapped out of memory).
This technique prevents thrashing along with ensuring the highest degree of multiprogramming possible. Thus, it optimizes CPU utilisation.
Key takeaway
This model is based on the above-stated concept of the Locality Model.
The basic principle states that if we allocate enough frames to a process to accommodate its current locality, it will only fault whenever it moves to some new locality. But if the allocated frames are lesser than the size of the current locality, the process is bound to thrash.
Modified bit says whether the page has been modified or not. Modified means sometimes you might try to write something on to the page. If a page is modified, then whenever you should replace that page with some other page, then the modified information should be kept on the hard disk or it has to be written back or it has to be saved back. It is set to 1 by hardware on write-access to page which is used to avoid writing when swapped out. Sometimes this modified bit is also called as the Dirty bit.
Dirty bit for a page in a page table helps avoid unnecessary writes on a paging device.
A dirty bit is a bit that is associated with a block of computer memory and indicates whether or not the corresponding block of memory has been modified. The dirty bit is set when the processor writes to this memory.
Use of dirty bit:
When a block of memory is to be replaced, its corresponding dirty bit is checked to see if the block needs to be written back to secondary memory before being replaced or if it can simply be removed. Dirty bits are used by the CPU cache and in the page replacement algorithms of an operating system.
Key takeaway
Modified bit says whether the page has been modified or not. Modified means sometimes you might try to write something on to the page. If a page is modified, then whenever you should replace that page with some other page, then the modified information should be kept on the hard disk or it has to be written back or it has to be saved back. It is set to 1 by hardware on write-access to page which is used to avoid writing when swapped out. Sometimes this modified bit is also called as the Dirty bit.
According to the concept of Virtual Memory, in order to execute some process, only a part of the process needs to be present in the main memory which means that only a few pages will only be present in the main memory at any time.
However, deciding, which pages need to be kept in the main memory and which need to be kept in the secondary memory, is going to be difficult because we cannot say in advance that a process will require a particular page at particular time.
Therefore, to overcome this problem, there is a concept called Demand Paging is introduced. It suggests keeping all pages of the frames in the secondary memory until they are required. In other words, it says that do not load any page in the main memory until it is required.
Whenever any page is referred for the first time in the main memory, then that page will be found in the secondary memory.
After that, it may or may not be present in the main memory depending upon the page replacement algorithm which will be covered later in this tutorial.
What is a Page Fault?
If the referred page is not present in the main memory then there will be a miss and the concept is called Page miss or page fault.
The CPU has to access the missed page from the secondary memory. If the number of page fault is very high then the effective access time of the system will become very high.
What is thrashing?
If the number of page faults is equal to the number of referred pages or the number of page faults are so high so that the CPU remains busy in just reading the pages from the secondary memory then the effective access time will be the time taken by the CPU to read one word from the secondary memory and it will be so high. The concept is called thrashing.
If the page fault rate is PF %, the time taken in getting a page from the secondary memory and again restarting is S (service time) and the memory access time is ma then the effective access time can be given as;
EAT = PF X S + (1 - PF) X (ma)
Key takeaway
According to the concept of Virtual Memory, in order to execute some process, only a part of the process needs to be present in the main memory which means that only a few pages will only be present in the main memory at any time.
However, deciding, which pages need to be kept in the main memory and which need to be kept in the secondary memory, is going to be difficult because we cannot say in advance that a process will require a particular page at particular time.
In an operating system that uses paging for memory management, a page replacement algorithm is needed to decide which page needs to be replaced when new page comes in.
Page Fault – A page fault happens when a running program accesses a memory page that is mapped into the virtual address space, but not loaded in physical memory.
Since actual physical memory is much smaller than virtual memory, page faults happen. In case of page fault, Operating System might have to replace one of the existing pages with the newly needed page. Different page replacement algorithms suggest different ways to decide which page to replace. The target for all algorithms is to reduce the number of page faults.
Page Replacement Algorithms:
First In First Out (FIFO) –
This is the simplest page replacement algorithm. In this algorithm, the operating system keeps track of all pages in the memory in a queue, the oldest page is in the front of the queue. When a page needs to be replaced page in the front of the queue is selected for removal.
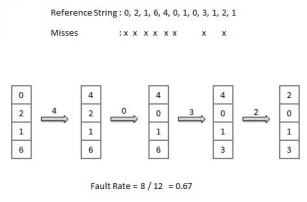
Example-1Consider page reference string 1, 3, 0, 3, 5, 6 with 3 page frames. Find number of page faults.
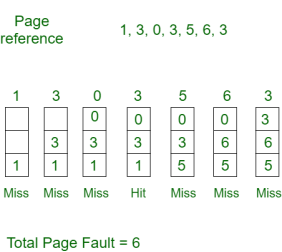
Initially all slots are empty, so when 1, 3, 0 came they are allocated to the empty slots —> 3 Page Faults.
when 3 comes, it is already in memory so —> 0 Page Faults.
Then 5 comes, it is not available in memory so it replaces the oldest page slot i.e. 1. —>1 Page Fault.
6 comes, it is also not available in memory so it replaces the oldest page slot i.e. 3 —>1 Page Fault.
Finally, when 3 come it is not available so it replaces 0 1 page fault
Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm. For example, if we consider reference string 3, 2, 1, 0, 3, 2, 4, 3, 2, 1, 0, 4 and 3 slots, we get 9 total page faults, but if we increase slots to 4, we get 10-page faults.
Optimal Page replacement –
In this algorithm, pages are replaced which would not be used for the longest duration of time in the future.
Example-2: Consider the page references 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, with 4 page frame. Find number of page fault.
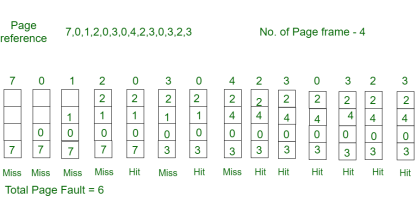
Initially all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults
0 is already there so —> 0 Page fault.
when 3 came it will take the place of 7 because it is not used for the longest duration of time in the future —>1 Page fault.
0 is already there so —> 0 Page fault.
4 will takes place of 1 —> 1 Page Fault.
Now for the further page reference string —> 0 Page fault because they are already available in the memory.
Optimal page replacement is perfect, but not possible in practice as the operating system cannot know future requests. The use of Optimal Page replacement is to set up a benchmark so that other replacement algorithms can be analysed against it.
Least Recently Used –
In this algorithm page will be replaced which is least recently used.
Example-3 Consider the page reference string 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2 with 4 page frames. Find number of page faults.

Initially all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults
0 is already there so —> 0 Page fault.
when 3 came it will take the place of 7 because it is least recently used —>1 Page
fault
0 is already in memory so —> 0 Page fault.
4 will takes place of 1 —> 1 Page Fault
Now for the further page reference string —> 0 Page fault because they are already available in the memory.
Key takeaway
A page fault happens when a running program accesses a memory page that is mapped into the virtual address space, but not loaded in physical memory.
Since actual physical memory is much smaller than virtual memory, page faults happen. In case of page fault, Operating System might have to replace one of the existing pages with the newly needed page. Different page replacement algorithms suggest different ways to decide which page to replace. The target for all algorithms is to reduce the number of page faults.
References




