Unit - 5
Application Layer
An application layer protocol defines how the application processes running on different systems, pass the messages to each other.
- DNS stands for Domain Name System.
- DNS is a directory service that provides a mapping between the name of a host on the network and its numerical address.
- DNS is required for the functioning of the internet.
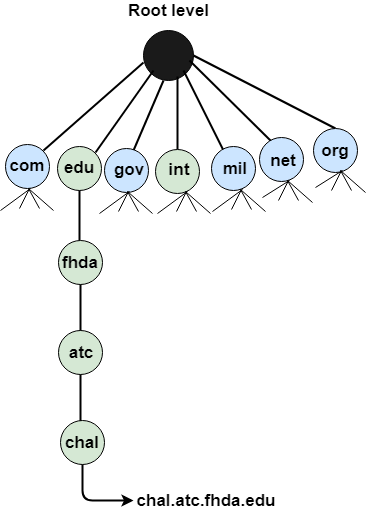
- Each node in a tree has a domain name, and a full domain name is a sequence of symbols specified by dots.
- DNS is a service that translates the domain name into IP addresses. This allows the users of networks to utilize user-friendly names when looking for other hosts instead of remembering the IP addresses.
- For example, suppose the FTP site at EduSoft had an IP address of 132.147.165.50, most people would reach this site by specifying ftp.EduSoft.com. Therefore, the domain name is more reliable than IP address.
DNS is a TCP/IP protocol used on different platforms. The domain name space is divided into three different sections: generic domains, country domains, and inverse domain.
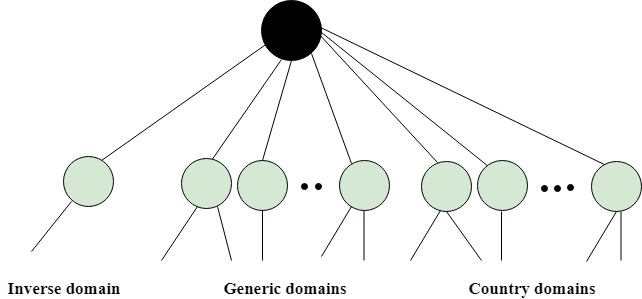
Fig 1 – DNS
Generic Domains
- It defines the registered hosts according to their generic behavior.
- Each node in a tree defines the domain name, which is an index to the DNS database.
- It uses three-character labels, and these labels describe the organization type.
Label | Description |
Aero | Airlines and aerospace companies |
Biz | Businesses or firms |
Com | Commercial Organizations |
Coop | Cooperative business Organizations |
Edu | Educational institutions |
Gov | Government institutions |
Info | Information service providers |
Int | International Organizations |
Mil | Military groups |
Museum | Museum & other nonprofit organizations |
Name | Personal names |
Net | Network Support centers |
Org | Nonprofit Organizations |
Pro | Professional individual Organizations |
Country Domain
The format of country domain is same as a generic domain, but it uses two-character country abbreviations (e.g., us for the United States) in place of three character organizational abbreviations.
Inverse Domain
The inverse domain is used for mapping an address to a name. When the server has received a request from the client, and the server contains the files of only authorized clients. To determine whether the client is on the authorized list or not, it sends a query to the DNS server and ask for mapping an address to the name.
Working of DNS
- DNS is a client/server network communication protocol. DNS clients send requests to the. Server while DNS servers send responses to the client.
- Client requests contain a name which is converted into an IP address known as a forward DNS lookups while requests containing an IP address which is converted into a name known as reverse DNS lookups.
- DNS implements a distributed database to store the name of all the hosts available on the internet.
- If a client like a web browser sends a request containing a hostname, then a piece of software such as DNS resolver sends a request to the DNS server to obtain the IP address of a hostname. If DNS server does not contain the IP address associated with a hostname, then it forwards the request to another DNS server. If IP address has arrived at the resolver, which in turn completes the request over the internet protocol.
Key takeaways
- DNS stands for Domain Name System.
- DNS is a directory service that provides a mapping between the name of a host on the network and its numerical address.
- DNS is required for the functioning of the internet.
- Each node in a tree has a domain name, and a full domain name is a sequence of symbols specified by dots.
- DNS is a service that translates the domain name into IP addresses. This allows the users of networks to utilize user-friendly names when looking for other hosts instead of remembering the IP addresses.
- For example, suppose the FTP site at EduSoft had an IP address of 132.147.165.50, most people would reach this site by specifying ftp.EduSoft.com. Therefore, the domain name is more reliable than IP address.
Dynamic Domain Name System (DDNS) in Application Layer
When DNS (Domain Name System) was designed, nobody expected that there would be so many address changes such as adding a new host, removing a host, or changing an IP address. When there is a change, the change must be made to the DNS master file which needs a lot of manual updating and it must be updated dynamically.
Dynamic Domain Name System (DDNS):
It is a method of automatically updating a name server in the Domain Name Server (DNS), often in real-time, with the active DDNS configuration of its configured hostnames, addresses, or other information. In DDNS, when a binding between a name and an address is determined, the information is sent, usually by DHCP (Dynamic Host Configuration Protocol) to a primary DNS server.
The primary server updates the zone. The secondary servers are notified either actively or passively. Inactive notification, the primary server sends a message to secondary servers, whereas, in the passive notification, the secondary servers periodically check for any changes. In either case, after being notified about the change, the secondary requests information about the entire zone (zone transfer).
DDNS can use an authentication mechanism to provide security and prevent unauthorized changes in DNS records.
Advantages:
- It saves time required by static addresses updates manually when network configuration changes.
- It saves space as the number of addresses are used as required at one time rather than using one for all the possible users of the IP address.
- It is very comfortable for users point of view as any IP address changes will not affect any of their activities.
- It does not affect accessibility as changed IP addresses are configured automatically against URL’s.
Disadvantages:
- It is less reliable due to lack of static IP addresses and domain name mappings.
- Dynamic DNS services alone can not make any guarantee about the device you are attempting to connect is actually your own.
Uses:
- It is used for Internet access devices such as routers.
- It is used for security appliance manufacturers and even required for IP-based security appliances like DVRs.
Telnet
- The main task of the internet is to provide services to users. For example, users want to run different application programs at the remote site and transfers a result to the local site. This requires a client-server program such as FTP, SMTP. But this would not allow us to create a specific program for each demand.
- The better solution is to provide a general client-server program that lets the user access any application program on a remote computer. Therefore, a program that allows a user to log on to a remote computer. A popular client-server program Telnet is used to meet such demands. Telnet is an abbreviation for Terminal Network.
- Telnet provides a connection to the remote computer in such a way that a local terminal appears to be at the remote side.
There are two types of login:
Local Login
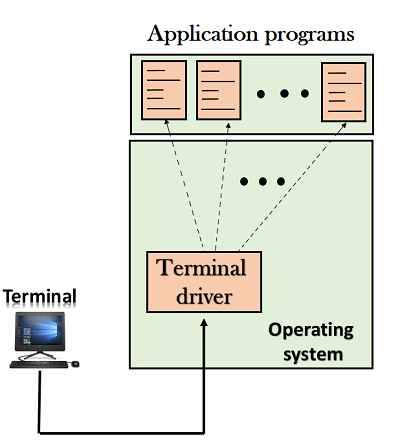
Fig 2 – Local login
When a user logs into a local computer, then it is known as local login.
When the workstation running terminal emulator, the keystrokes entered by the user are accepted by the terminal driver. The terminal driver then passes these characters to the operating system which in turn, invokes the desired application program.
However, the operating system has special meaning to special characters. For example, in UNIX some combination of characters have special meanings such as control character with "z" means suspend. Such situations do not create any problem as the terminal driver knows the meaning of such characters. But, it can cause the problems in remote login.
Remote login
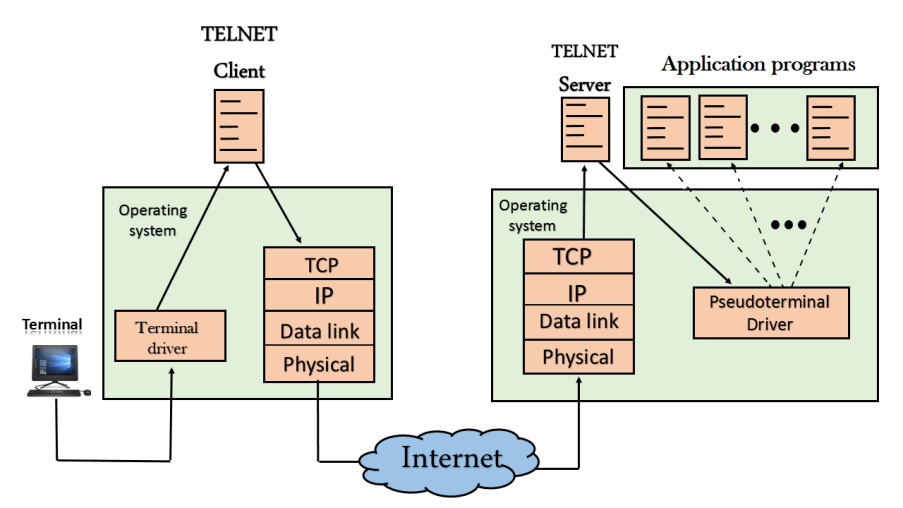
Fig 3 – Remote login
- When the user wants to access an application program on a remote computer, then the user must perform remote login.
How remote login occurs
At the local site
The user sends the keystrokes to the terminal driver, the characters are then sent to the TELNET client. The TELNET client which in turn, transforms the characters to a universal character set known as network virtual terminal characters and delivers them to the local TCP/IP stack
At the remote site
The commands in NVT forms are transmitted to the TCP/IP at the remote machine. Here, the characters are delivered to the operating system and then pass to the TELNET server. The TELNET server transforms the characters which can be understandable by a remote computer. However, the characters cannot be directly passed to the operating system as a remote operating system does not receive the characters from the TELNET server. Therefore it requires some piece of software that can accept the characters from the TELNET server. The operating system then passes these characters to the appropriate application program.
Network Virtual Terminal (NVT)
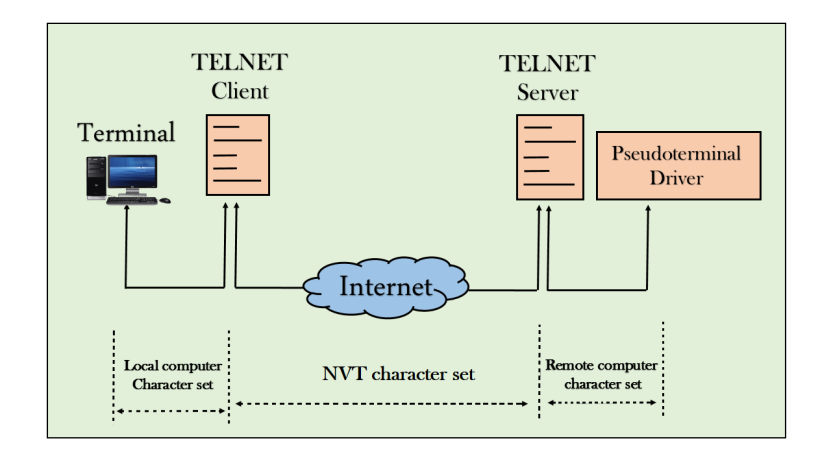
Fig 4 – NVT
- The network virtual terminal is an interface that defines how data and commands are sent across the network.
- In today's world, systems are heterogeneous. For example, the operating system accepts a special combination of characters such as end-of-file token running a DOS operating system ctrl+z while the token running a UNIX operating system is ctrl+d.
- TELNET solves this issue by defining a universal interface known as network virtual interface.
- The TELNET client translates the characters that come from the local terminal into NVT form and then delivers them to the network. The Telnet server then translates the data from NVT form into a form which can be understandable by a remote computer.
What is E-mail?
E-mail is defined as the transmission of messages on the Internet. It is one of the most commonly used features over communications networks that may contain text, files, images, or other attachments. Generally, it is information that is stored on a computer sent through a network to a specified individual or group of individuals.
Email messages are conveyed through email servers; it uses multiple protocols within the TCP/IP suite. For example, SMTP is a protocol, stands for simple mail transfer protocol and used to send messages whereas other protocols IMAP or POP are used to retrieve messages from a mail server. If you want to login to your mail account, you just need to enter a valid email address, password, and the mail servers used to send and receive messages.
Although most of the webmail servers automatically configure your mail account, therefore, you only required to enter your email address and password. However, you may need to manually configure each account if you use an email client like Microsoft Outlook or Apple Mail. In addition, to enter the email address and password, you may also need to enter incoming and outgoing mail servers and the correct port numbers for each one.
Email messages include three components, which are as follows:
- Message envelope: It depicts the email's electronic format.
- Message header: It contains email subject line and sender/recipient information.
- Message body: It comprises images, text, and other file attachments.
The email was developed to support rich text with custom formatting, and the original email standard is only capable of supporting plain text messages. In modern times, email supports HTML (Hypertext markup language), which makes it capable of emails to support the same formatting as websites. The email that supports HTML can contain links, images, CSS layouts, and also can send files or "email attachments" along with messages. Most of the mail servers enable users to send several attachments with each message. The attachments were typically limited to one megabyte in the early days of email. Still, nowadays, many mail servers are able to support email attachments of 20 megabytes or more in size.
In 1971, as a test e-mail message, Ray Tomlinson sent the first e-mail to himself. This email was contained the text "something like QWERTYUIOP." However, the e-mail message was still transmitted through ARPANET, despite sending the e-mail to himself. Most of the electronic mail was being sent as compared to postal mail till 1996.
Differences between email and webmail
The term email is commonly used to describe both browser-based electronic mail and non-browser-based electronic mail today. The AOL and Gmail are browser-based electronic mails, whereas Outlook for Office 365 is non-browser-based electronic mail. However, to define email, a difference was earlier made as a non-browser program that needed a dedicated client and email server. The non-browser emails offered some advantages, which are enhanced security, integration with corporate software platforms, and lack of advertisements.
Uses of email
Email can be used in different ways: it can be used to communicate either within an organization or personally, including between two people or a large group of people. Most people get benefit from communicating by email with colleagues or friends or individuals or small groups. It allows you to communicate with others around the world and send and receive images, documents, links, and other attachments. Additionally, it offers benefit users to communicate with the flexibility on their own schedule.
There is another benefit of using email; if you use it to communicate between two people or small groups that will beneficial to remind participants of approaching due dates and time-sensitive activities and send professional follow-up emails after appointments. Users can also use the email to quickly remind all upcoming events or inform the group of a time change. Furthermore, it can be used by companies or organizations to convey information to large numbers of employees or customers. Mainly, email is used for newsletters, where mailing list subscribers are sent email marketing campaigns directly and promoted content from a company.
Email can also be used to move a latent sale into a completed purchase or turn leads into paying customers. For example, a company may create an email that is used to send emails automatically to online customers who contain products in their shopping cart. This email can help to remind consumers that they have items in their cart and stimulate them to purchase those items before the items run out of stock. Also, emails are used to get reviews by customers after making a purchase. They can survey by including a question to review the quality of service.
History of E-mail
As compared to ARPANet or the Internet, email is much older. The early email was just a small advance, which is known as a file directory in nowadays. It was used to just put a message in other user's directory in the place where they were able to see the message by logging in. For example, the same as leaving a note on someone's desk. Possibly MAILBOX was used at Massachusetts Institute of Technology, which was the first email system of this type from 1965. For sending messages on the same computer, another early program was SNDMSG.
Users were only able to send messages to several users of the same computer through email when the internetworking was not beginning. And, the problem became a little more complex when computers began to talk to each other over networks, we required to put a message in an envelope and address it for the destination.
Later in 1972, Ray Tomlinson invented email to remove some difficulties. Tomlinson worked (Like many of the Internet inventors) for Newman and Bolt Beranek as an ARPANET contractor. To denote sending messages from one computer to another, he picked up the @ symbol from the keyboard. Then, it became easy to send a message to another with the help of Internet standards; they were only required to propose name-of-the-user@name-of-the-computer. One of the first users of the new system was Internet pioneer Jon Postel. Also, describing as a "nice hack," credited goes to Jon Postel.
Although the World Wide Web offers many services, email is the most widely used facility and remains the most important application of the Internet. On the international level, over 600 million people use email. There were hundreds of email users by 1974, as ARPANET ultimately encouraged it. Furthermore, email caused a radical shift in Arpa's purpose, as it became the savior of Arpanet.
From there were rapid developments in the field of the email system. A big enhancement was to sort emails; some email folders for his boss were invented by Larry Roberts. To organize an email, John Vittal developed some software in 1976. By 1976 commercial packages began to appear, and email had really taken off. The email had changed people and took them from Arpanet to the Internet. Here was appeared some interesting features that ordinary people all over the world wanted to use.
Some years later, Ray Tomlinson observed about email. As compared to the previous one, any single development is stepping rapidly and nearly followed by the next. I think that all the developments would take a big revolution.
When personal computers came on the scene, the offline reader was one of the first new developments. Then, email users became able to store their email on their own personal computers with the help of offline reader and read it. Also, without actually being connected to the network, they were able to prepare replies like Microsoft Outlook can do today. In parts of the world, this was specifically useful for people where the telephone was expensive as compared to the email system.
Without being connected to a telephone, it was able to prepare a reply with connection charges of many dollars a minute and then get on the network to send it. Also, it was useful as the offline mode allowed for more simple user interfaces. In this modern time of very few standards being connected directly to the host email system often resulted in no capacity for text to wrap around on the screen of the user's computer, and backspace keys and delete keys may not work and other such annoyances. Offline readers helped out more to overcome these kinds of difficulties.
The SMTP (simple mail transfer protocol) was the first important email standard. It was a fairly naïve protocol that is still in use. And, it was made in terms of no attempt to find the person who sent a message that was the right or not what they claimed to be. In the email addresses, fraudulent was very easy and is still available. Later, these basic flaws were used in the protocol by security frauds, worms and viruses, and spammers forging identities. From 2004, some of these problems are still being processed for a solution.
But as developed email system offered some important features that helped out people to understand easily about email. In 1988, Steve Dorner developed Eudora that was one of the first good commercial systems. But it did not appear for a long time after Pegasus mail come. Servers began to appear as a standard when Internet standards POP (Post office protocol) for email began to mature. Each server was a little different before standard post office protocol (POP). POP was an important standard that allowed users to work together.
Individual dialup users were required to charges for an email per-minute in those days. Also, on the Internet, email and email discussion groups were the main uses for most people. There were several issues on a wide variety of subjects; they became USENET as a body of newsgroups.
With the World Wide Web (WWW), email became available with a simple user interface that was offered by providers like Hotmail and Yahoo. And, users did not require to pay any charges on these platforms. Now everyone wanted at least one email address as it is much simple and affordable, and the medium was adopted by millions of people.
Internet Service Providers (ISPs) started to connect people with each other all over the world by the 1980s. Also, by 1993 the use of the Internet was becoming widespread, and the word electronic mail was replaced by email.
Today, email has become a primary platform to communicate with people all over the world. There are continuing updates to the system with so many people using email for communication. Although email has some security issues, there have been laws passed to prevent the spread of junk email over the years.
Advantages of Email
There are many advantages of email, which are as follows:
- Cost-effective: Email is a very cost-effective service to communicate with others as there are several email services available to individuals and organizations for free of cost. Once a user is online, it does not include any additional charge for the services.
- Email offers users the benefit of accessing email from anywhere at any time if they have an Internet connection.
- Email offers you an incurable communication process, which enables you to send a response at a convenient time. Also, it offers users a better option to communicate easily regardless of different schedules users.
- Speed and simplicity: Email can be composed very easily with the correct information and contacts. Also, minimum lag time, it can be exchanged quickly.
- Mass sending: You can send a message easily to large numbers of people through email.
- Email exchanges can be saved for future retrieval, which allows users to keep important conversations or confirmations in their records and can be searched and retrieved when they needed quickly.
- Email provides a simple user interface and enables users to categorize and filter their messages. This can help you recognize unwanted emails like junk and spam mail. Also, users can find specific messages easily when they are needed.
- As compared to traditional posts, emails are delivered extremely fast.
- Email is beneficial for the planet, as it is paperless. It reduces the cost of paper and helps to save the environment by reducing paper usage.
- It also offers a benefit to attaching the original message at the time you reply to an email. This is beneficial when you get hundreds of emails a day, and the recipient knows what you are talking about.
- Furthermore, emails are beneficial for advertising products. As email is a form of communication, organizations or companies can interact with a lot of people and inform them in a short time.
Disadvantages of Email
- Impersonal: As compared to other forms of communication, emails are less personal. For example, when you talk to anyone over the phone or meeting face to face is more appropriate for communicating than email.
- Misunderstandings: As email includes only text, and there is no tone of voice or body language to provide context. Therefore, misunderstandings can occur easily with email. If someone sends a joke on email, it can be taken seriously. Also, well-meaning information can be quickly typed as rude or aggressive that can impact wrong. Additionally, if someone types with short abbreviations and descriptions to send content on the email, it can easily be misinterpreted.
- Malicious Use: As email can be sent by anyone if they have an only email address. Sometimes, an unauthorized person can send you mail, which can be harmful in terms of stealing your personal information. Thus, they can also use email to spread gossip or false information.
- Accidents Will Happen: With email, you can make fatal mistakes by clicking the wrong button in a hurry. For instance, instead of sending it to a single person, you can accidentally send sensitive information to a large group of people. Thus, the information can be disclosed, when you have clicked the wrong name in an address list. Therefore, it can be harmful and generate big trouble in the workplace.
- Spam: Although in recent days, the features of email have been improved, there are still big issues with unsolicited advertising arriving and spam through email. It can easily become overwhelming and takes time and energy to control.
- Information Overload: As it is very easy to send email to many people at a time, which can create information overload. In many modern workplaces, it is a major problem where it is required to move a lot of information and impossible to tell if an email is important. And, email needs organization and upkeep. The bad feeling is one of the other problems with email when you returned from vacation and found hundreds of unopened emails in your inbox.
- Viruses: Although there are many ways to travel viruses in the devices, email is one of the common ways to enter viruses and infect devices. Sometimes when you get a mail, it might be the virus come with an attached document. And, the virus can infect the system when you click on the email and open the attached link. Furthermore, an anonymous person or a trusted friend or contact can send infected emails.
- Pressure to Respond: If you get emails and you do not answer them, the sender can get annoyed and think you are ignoring them. Thus, this can be a reason to make pressure on your put to keep opening emails and then respond in some way.
- Time Consuming: When you get an email and read, write, and respond to emails that can take up vast amounts of time and energy. Many modern workers spend their most time with emails, which may be caused to take more time to complete work.
- Overlong Messages: Generally, email is a source of communication with the intention of brief messages. There are some people who write overlong messages that can take much time than required.
- Insecure: There are many hackers available that want to gain your important information, so email is a common source to seek sensitive data, such as political, financial, documents, or personal messages. In recent times, there have various high-profile cases occurred that shown how email is insecure about information theft.
Different types of Email
There are many types of email; such are as follows:
Newsletters: It is studying by Clutch, the newsletter is the most common type of email that are routinely sent to all mailing list subscribers, either daily, weekly, or monthly. These emails often contain from the blog or website, links curated from other sources, and selected content that the company has recently published. Typically, Newsletter emails are sent on a consistent schedule, and they offer businesses the option to convey important information to their client through a single source. Newsletters might also incorporate upcoming events or new, webinars from the company, or other updates.
Lead Nurturing: Lead-nurturing emails are a series of related emails that marketers use to take users on a journey that may impact their buying behavior. These emails are typically sent over a period of several days or weeks. Lead-nurturing emails are also known as trigger campaigns, which are used for solutions in an attempt to move any prospective sale into a completed purchase and educate potential buyers on the services. These emails are not only helpful for converting emails but also drive engagement. Furthermore, lead-nurturing emails are initiated by a potential buyer taking initial action, such as clicking links on a promotional email or downloading a free sample.
Promotional emails: It is the most common type of B2B (Business to Business) email, which is used to inform the email list of your new or existing products or services. These types of emails contain creating new or repeat customers, speeding up the buying process, or encouraging contacts to take some type of action. It provides some critical benefits to buyers, such as a free month of service, reduced or omitted fees for managed services, or percentage off the purchase price.
Standalone Emails: These emails are popular like newsletters emails, but they contain a limitation. If you want to send an email with multiple links or blurbs, your main call-to-action can weaken. Your subscriber may skip your email and move on, as they may click on the first link or two in your email but may not come back to the others.
Onboarding emails: An onboarding email is a message that is used to strengthen customer loyalty, also known as post-sale emails. These emails receive users right after subscription. The onboarding emails are sent to buyers to familiarize and educate them about how to use a product effectively. Additionally, when clients faced with large-scale service deployments, these emails help them facilitate user adoption.
Transactional: These emails are related to account activity or a commercial transaction and sent from one sender to one recipient. Some examples of transactional email are purchase confirmations, password reminder emails, and personalized product notifications. These emails are used when you have any kind of e-commerce component to your business. As compared to any other type of email, the transactional email messages have 8x the opens and clicks.
Plain-Text Emails: It is a simple email that does not include images or graphics and no formatting; it only contains the text. These types of emails may worth it if you try to only ever send fancy formatted emails, text-only messages. According to HubSpot, although people prefer fully designed emails with various images, plain text emails with less HTML won out in every A/B test. In fact, HTML emails contain lower open and click-through rates, and plain text emails can be great for blog content, event invitations, and survey or feedback requests. Even if you do not send plainer emails, but you can boost your open and click through rates by simplifying your emails and including fewer images.
Welcome emails: It is a type of B2B email and common parts of onboarding emails that help users get acquainted with the brand. These emails can improve subscriber constancy as they include additional information, which helps to the new subscriber in terms of a business objective. Generally, welcome emails are sent buyers who got a subscription to a business's opt-in activities, such as a blog, mailing list, or webinar. Also, these emails can help businesses to build a better relationship between customers.
Examples of email attacks
Although there are many ways to travel viruses in the devices, email is one of the most common vectors for cyberattacks. The methods include spoofing, spamming, spear-phishing, phishing, ransomware, and business email compromise (BEC).
There are many organizations (around 7710) hit by a BEC attack every month, as one out of every 412 emails contains a malware attack. According to the Symantec Internet Threat Security Report, spear-phishing is the most widely used infection vector. Below is given a complete description of these types of attacks:
- Phishing: A form of fraud in which the attacks are the practice of sending fraudulent communications that appear to come from a reputable entity or person in email or other communication channels. Usually, it is done through the email; phishing emails are used by attackers to steal sensitive data like credit card and login information or to install malware on the victim's machine. Additionally, everyone should learn about a phishing attack in order to protect themselves, as it is a common type of cyberattack. The common features of phishing emails are Sense of urgency, Hyperlinks, Too Good to Be True, Unusual sender, Attachments.
- Spamming: Spam email is unsolicited bulk messages sent without explicit consent from the recipient, which is also known as junk email. Since the 1990s, spam is a problem faced by most email users and has been increasing in popularity. Obtained by spambots, spam mail recipients have had their email addresses (automated programs), which crawl the Internet to find email addresses. This is the dark side of email marketing in which spammers use spambots to create email distribution lists. Typically, an email is sent by a spammer to millions of email addresses with the expectation that only a few numbers of an email address will respond or interact with the message.
- Spoofing: Email spoofing is an email message that could be obtained from someone or somewhere other than the intended source. It is a popular strategy that is used in spam and phishing campaigns as core email protocols do not have a built-in method of authentication. And, when people think the email has been sent by a legitimate or familiar source, they are more likely to open an email. Thus, it is a common tactic used for spam and phishing emails. The email spoofing is used with the purpose of getting mail recipients to open emails and possibly respond to a solicitation.
- Business email compromise (BEC): A BEC is an exploit in which an authorized person or attacker hacks to a business email account and spoofs the owner's identity to defraud the company, its customers, partners of money. Often, an attacker simply creates an account with an email address that is almost identical to one on the corporate network, which creates trust between the victim and their email account. Sometimes, a BEC is also known as a man-in-the-email attack. Some samples of BEC email messages that contain the word in subject, such as urgent, transfer, request, payment, and more. There are five types of BEC scams on the basis of the FBI, which are False Invoice Scheme, CEO Fraud, Data Theft, Attorney Impersonation, Account Compromise.
- Spear-phishing: Email spoofing is an attack where hackers target an individual or specific organization to gain sensitive information through unauthorized access. Spear phishing is not initiated by random hackers but attempted by perpetrators to gain financial benefits or secrets information. It is an attack in which attackers send emails to specific and well-researched targets while purporting to be a trusted sender. The main objective of spear phishing is to convince victims to hand over information or money and infect devices with malware.
- Ransomware: It is a subset of malware that is used to encrypt a victim's files. Typically, it locks data by encryption on the victim's system. Typically, it locks data by encryption on the victim's system, and attackers demand payments before the ransomed data is decrypted. Unlike other types of attacks, the primary goal of ransomware attacks is just about always monetary. Usually, when the exploit occurs, a victim is notified about the attack and is given instructions for how to recover from the attack.
Popular email sites
There are some free email website examples include the following:
- AOL
- Zoho
- Gmail
- ProtonMail
- Com
- Microsoft Outlook
- Yahoo Mail
Email is a platform that allows users to communicate with people or groups of people around the world. As email security is more important but consequent, it is not inherently secure.
There are many techniques that can be used by individuals, organizations, and service providers. These techniques provide how to protect sensitive information with email communication and accounts from unauthorized access, loss, or destruction.
Individuals can protect their account with the help of creating strong passwords and changing them frequently. They can use alphabetical, numerical, special symbols to make a strong password that helps to protect your account. Users can also install and run an antivirus and antimalware software on their computer, as well as create spam filters and folders to separate potentially malicious emails and junk mail.
Also, there are some techniques the helps organizations to secure email include implementing an email security gateway, training employees on deploying automated email encryption solutions, and proper email usage. By processing and scanning all received emails, email gateways check emails for threats, and analyze that should be allowed into the system or not. A multilayered gateway is a powerful technique since attacks are increasing rapidly and becoming complicated and sophisticated. Some emails that cannot be caught by the gateway, training employees on how to differentiate malicious messages, and properly use email are the best approach, which helps users avoid threatening mails.
For potentially sensitive information, the automated email encryption solutions are used that scans all outgoing messages; it will encrypt the sensitive information before it is sent to the intended recipient. This process helps to send email securely and prevent hackers from gaining access to the secret information, even if they stop it. The only intended recipient can view the original information with permission.
Email service providers can also help to enhance security with the help of accessing control standards and mechanisms and establishing a strong password. Additionally, providers should also offer digital signatures and encryption solutions to secure emails in transit and in users' inboxes. Finally, to protect users from malicious, unrecognized, and untrustworthy messages, service providers should implement firewalls and spam-filtering software applications.
E-mail address breakdown
Let's take an example of Help@javatpoint.com to describe the breakdown of an email.
In the email address, before the part of the @ symbol, contains the department of an organization, alias, user, or group. As shown in the above example, help is the support department at our company javatpoint.
Next, the @ (at sign) is required for all SMTP (Simple Mail Transfer Protocol) email address that is a divider in the email address, since the first message was sent by Ray Tomlinson.
Finally, users belong to the domain name, javatpoint.com. For the domain, the .com is the top-level domain (TLD).
What can be sent in an e-mail?
An email is a platform that enables users to communicate with each other. It allows users to send text messages, including a file or other data on the e-mail all over the world. It is also possible to attach a picture, word processor document, PDF, program, movie, or any file stored on your computer in an e-mail. However, due to some security issues, it may not be possible to send certain types of files on the email; they need some additional steps. For example, the .exe file can be blocked by many companies from being sent over the email, and you will need to compress the file into a .zip file format. Additionally, you may be unable to send any large files or programs from being sent over e-mail as most e-mail providers have file size restrictions.
What should be write e-mail or email?
You can use any word email or e-mail according to the style guide you are following as both are valid and have the same meaning. However, the e-mail word has a hyphen and is a compound noun that describes "electronic" and "mail."
How to send and receive e-mail
E-mail program
You can use an email program to send and receive an email. An email program is also known as an e-mail client. There are many email programs available to send and receive an email, including Mozilla Thunderbird and Microsoft Outlook. A server is used to store and deliver your messages while you use an email client. Often, your ISP (Internet service provider) host this server but can be another Internet company to host this server. To download the new emails, an email client requires connecting a server, whereas online stored emails are always available on Internet-connected devices.
Online e-mail
An online e-mail service or webmail is an alternative way and the popular solution for most people in sending and receiving e-mail. Examples of online emails are Yahoo Mail, Gmail, and Hotmail (now Outlook.com).
Some of the popular e-mail clients?
Today, there are different software-based e-mail clients available for users, but these are not online. Below is given a list that contains the most popular clients.
- Microsoft Outlookv
- Mail for Windows 10
- DreamMail
- Mozilla Thunderbird
- EM Client
- Mailbird
What makes a valid e-mail address?
Users need to follow the various rule that is given below to make valid email address:
- A username followed by @ (the at sign) is most important for an email address, which is followed by the domain name with a domain suffix. Hence, an e-mail must have a username.
- The domain name cannot be longer than 254 characters, and the username cannot be longer than 64 characters long.
- An email must have only one @ sign.
- An email should not have space and special characters like \ [ ] ( ) , : ; < >. Sometimes, few symbols such as backslash, space, and quotation mark work must be preceded with a forward slash. But these characters are not allowed by some email providers.
- In the email, the email address and username cannot start or end with a period.
- The two or more successive periods are not allowed in the email.
Key takeaways
- It is a method of automatically updating a name server in the Domain Name Server (DNS), often in real-time, with the active DDNS configuration of its configured hostnames, addresses, or other information. In DDNS, when a binding between a name and an address is determined, the information is sent, usually by DHCP (Dynamic Host Configuration Protocol) to a primary DNS server.
- The primary server updates the zone. The secondary servers are notified either actively or passively. Inactive notification, the primary server sends a message to secondary servers, whereas, in the passive notification, the secondary servers periodically check for any changes. In either case, after being notified about the change, the secondary requests information about the entire zone (zone transfer).
- DDNS can use an authentication mechanism to provide security and prevent unauthorized changes in DNS records.
FTP
- FTP stands for File transfer protocol.
- FTP is a standard internet protocol provided by TCP/IP used for transmitting the files from one host to another.
- It is mainly used for transferring the web page files from their creator to the computer that acts as a server for other computers on the internet.
- It is also used for downloading the files to computer from other servers.
Objectives of FTP
- It provides the sharing of files.
- It is used to encourage the use of remote computers.
- It transfers the data more reliably and efficiently.
Why FTP?
Although transferring files from one system to another is very simple and straightforward, but sometimes it can cause problems. For example, two systems may have different file conventions. Two systems may have different ways to represent text and data. Two systems may have different directory structures. FTP protocol overcomes these problems by establishing two connections between hosts. One connection is used for data transfer, and another connection is used for the control connection.
Mechanism of FTP
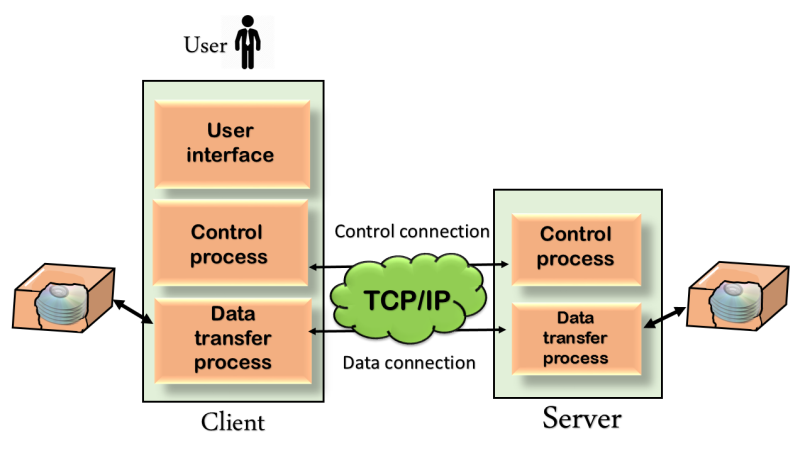
Fig 5 – Mechanism of FTP
The above figure shows the basic model of the FTP. The FTP client has three components: the user interface, control process, and data transfer process. The server has two components: the server control process and the server data transfer process.
There are two types of connections in FTP:
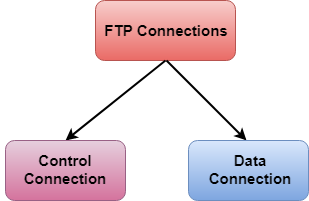
Fig 6 – FTP Connections
- Control Connection: The control connection uses very simple rules for communication. Through control connection, we can transfer a line of command or line of response at a time. The control connection is made between the control processes. The control connection remains connected during the entire interactive FTP session.
- Data Connection: The Data Connection uses very complex rules as data types may vary. The data connection is made between data transfer processes. The data connection opens when a command comes for transferring the files and closes when the file is transferred.
FTP Clients
- FTP client is a program that implements a file transfer protocol which allows you to transfer files between two hosts on the internet.
- It allows a user to connect to a remote host and upload or download the files.
- It has a set of commands that we can use to connect to a host, transfer the files between you and your host and close the connection.
- The FTP program is also available as a built-in component in a Web browser. This GUI based FTP client makes the file transfer very easy and also does not require to remember the FTP commands.
Advantages of FTP:
- Speed: One of the biggest advantages of FTP is speed. The FTP is one of the fastest way to transfer the files from one computer to another computer.
- Efficient: It is more efficient as we do not need to complete all the operations to get the entire file.
- Security: To access the FTP server, we need to login with the username and password. Therefore, we can say that FTP is more secure.
- Back & forth movement: FTP allows us to transfer the files back and forth. Suppose you are a manager of the company, you send some information to all the employees, and they all send information back on the same server.
Disadvantages of FTP:
- The standard requirement of the industry is that all the FTP transmissions should be encrypted. However, not all the FTP providers are equal and not all the providers offer encryption. So, we will have to look out for the FTP providers that provides encryption.
- FTP serves two operations, i.e., to send and receive large files on a network. However, the size limit of the file is 2GB that can be sent. It also doesn't allow you to run simultaneous transfers to multiple receivers.
- Passwords and file contents are sent in clear text that allows unwanted eavesdropping. So, it is quite possible that attackers can carry out the brute force attack by trying to guess the FTP password.
- It is not compatible with every system.
What is World Wide Web?
World Wide Web, which is also known as a Web, is a collection of websites or web pages stored in web servers and connected to local computers through the internet. These websites contain text pages, digital images, audios, videos, etc. Users can access the content of these sites from any part of the world over the internet using their devices such as computers, laptops, cell phones, etc. The WWW, along with internet, enables the retrieval and display of text and media to your device.
Fig 7 – WWW
The building blocks of the Web are web pages which are formatted in HTML and connected by links called "hypertext" or hyperlinks and accessed by HTTP. These links are electronic connections that link related pieces of information so that users can access the desired information quickly. Hypertext offers the advantage to select a word or phrase from text and thus to access other pages that provide additional information related to that word or phrase.
A web page is given an online address called a Uniform Resource Locator (URL). A particular collection of web pages that belong to a specific URL is called a website, e.g., www.facebook.com, www.google.com, etc. So, the World Wide Web is like a huge electronic book whose pages are stored on multiple servers across the world.
Small websites store all of their WebPages on a single server, but big websites or organizations place their WebPages on different servers in different countries so that when users of a country search their site they could get the information quickly from the nearest server.
So, the web provides a communication platform for users to retrieve and exchange information over the internet. Unlike a book, where we move from one page to another in a sequence, on World Wide Web we follow a web of hypertext links to visit a web page and from that web page to move to other web pages. You need a browser, which is installed on your computer, to access the Web.
Difference between World Wide Web and Internet:
Some people use the terms 'internet' and 'World Wide Web' interchangeably. They think they are the same thing, but it is not so. Internet is entirely different from WWW. It is a worldwide network of devices like computers, laptops, tablets, etc. It enables users to send emails to other users and chat with them online. For example, when you send an email or chatting with someone online, you are using the internet.
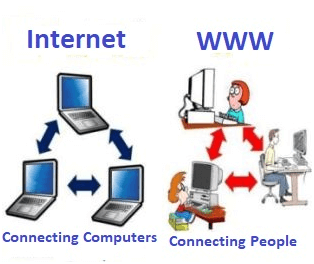
Fig 8 – Internet and WWW
But, when you have opened a website like google.com for information, you are using the World Wide Web; a network of servers over the internet. You request a webpage from your computer using a browser, and the server renders that page to your browser. Your computer is called a client who runs a program (web browser), and asks the other computer (server) for the information it needs.
History of the World Wide Web:
The World Wide Web was invented by a British scientist, Tim Berners-Lee in 1989. He was working at CERN at that time. Originally, it was developed by him to fulfill the need of automated information sharing between scientists across the world, so that they could easily share the data and results of their experiments and studies with each other.
CERN, where Tim Berners worked, is a community of more than 1700 scientists from more than 100 countries. These scientists spend some time on CERN site, and rest of the time they work at their universities and national laboratories in their home countries, so there was a need for reliable communication tools so that they can exchange information.
Internet and Hypertext were available at this time, but no one thought how to use the internet to link or share one document to another. Tim focused on three main technologies that could make computers understand each other, HTML, URL, and HTTP. So, the objective behind the invention of WWW was to combine recent computer technologies, data networks, and hypertext into a user-friendly and effective global information system.
How the Invention Started:
In March 1989, Tim Berners-Lee took the initiative towards the invention of WWW and wrote the first proposal for the World Wide Web. Later, he wrote another proposal in May 1990. After a few months, in November 1990, along with Robert Cailliau, it was formalized as a management proposal. This proposal had outlined the key concepts and defined terminology related to the Web. In this document, there was a description of "hypertext project" called World Wide Web in which a web of hypertext documents could be viewed by browsers. His proposal included the three main technologies (HTML, URL, and HTTP).
In 1990, Tim Berners-Lee was able to run the first Web server and browser at CERN to demonstrate his ideas. He used a NeXT computer to develop the code for his Web server and put a note on the computer "The machine is a server. Do Not Power It DOWN!!" So that it was not switched off accidentally by someone.
In 1991, Tim created the world's first website and Web Server. Its address was info.cern.ch, and it was running at CERN on the NeXT computer. Furthermore, the first web page address was http://info.cern.ch/hypertext/WWW/TheProject.html.
This page had links to the information related to the WWW project, and also about the Web servers, hypertext description, and information for creating a Web server.
The Web Grows:
NeXT computer platform was accessible by a few users. Later, the development of 'line-mode' browser, which could run on any system, started. In 1991, Berners-Lee introduced his WWW software with 'line-mode' browser, Web server software and a library for developers.
In March 1991, it was available to colleagues who were using CERN computers. After a few months, in August 1991, he introduced the WWW software on internet newsgroups, and it generated interest in the project across the world. Graphic interface for the internet, first introduced to the public on 6 August 1991 by Tim Berners-Lee. On 23 August 1991, it was available to everyone.
Becoming Global:
The first Web server came online in December 1991 in the United States. At this time, there were only two types of browsers; the original development version which was available only on NeXT machines and the 'line-mode' browser which was easy to install and run on any platform but was less user-friendly and had limited power.
For further improvement, Berners-Lee asked other developers via the internet to contribute to its development. Many developers wrote browsers for the X-Window System. The first web server, outside Europe, was introduced at Standard University in the United States in 1991. In the same year, there were only ten known web servers across the world.
Later at the beginning of 1993, the National Center for Supercomputing Applications (NCSA) introduced the first version of its Mosaic browser. It ran in the X Window System environment. Later, the NCSA released versions for the PC and Macintosh environments. With the introduction of user-friendly browsers on these computers, the WWW started spreading tremendously across the world.
Eventually, the European Commission approved its first web project in the same year with CERN as one of its partners. In April 1993, CERN made the source code of WWW available on a royalty-free basis and thus made it free software. Royalty-free means one has the right to use copyright material or intellectual property without paying any royalty or license fee. Thus, CERN allowed people to use the code and web protocol for free. The technologies that were developed to make the WWW became an open source to allow people to use them for free. Eventually, people started creating websites for online businesses, to provide information and other similar purposes.
At the end of 1993, there were more than 500 web servers, and the WWW has 1% of the total internet traffic. In May 1994, the First International World Wide Web conference was held at CERN and was attended by around 400 users and developers and popularly known as the "Woodstock of the Web." In the same year, the telecommunication companies started providing internet access, and people have access to WWW available at their homes.
In the same year, one more conference was held in the United States, which was attended by over 1000 people. It was organized by the NCSA and the newly-formed International WWW Conference Committee (IW3C2). At the end of this year (1994), the World Wide Web had around 10000 servers and 10 million users. The technology was continuously improved to fulfill growing needs and security, and e-commerce tools were decided to be added soon.
Open standards:
The main objective was to keep the Web an open standard for all rather than a proprietary system. Accordingly, CERN sent a proposal to the Commission of the European Union under the ESPRIT program "WebCore." This project's objective was to form an international consortium in collaboration with Massachusetts Institute of Technology (MIT), the US. In 1994, Berners-Lee left CERN and joined MIT and established the International World Wide Web Consortium (W3C) and a new European partner was needed for W3C.
The European Commission approached the French National Institute for Research in Computer Science and Controls (INRIA), to substitute the CERN's role. Eventually, in April 1995, INRIA became the first European W3C host and in 1996 Keio University of Japan became another host in Asia.
In 2003, ERCIM (European Research Consortium in Informatics and Mathematics) replaced INRIA for the role of European W3C Host. Beihang University was announced as the fourth Host by W3C in 2013. In September 2018, there were over 400 member organizations around the world.
Since its inception, the Web has changed a lot and is still changing today. Search engines have become more advanced at reading, understanding, and processing information. They can easily find the information requested by users and can even provide other relevant information that might interest users.
How the World Wide Web Works?
Now, we have understood that WWW is a collection of websites connected to the internet so that people can search and share information. Now, let us understand how it works!
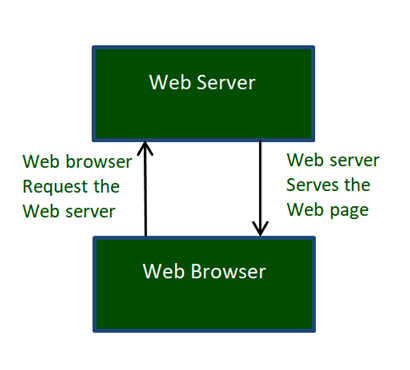
Fig 9 – World Wide Web Works
The Web works as per the internet's basic client-server format as shown in the following image. The servers store and transfer web pages or information to user's computers on the network when requested by the users. A web server is a software program which serves the web pages requested by web users using a browser. The computer of a user who requests documents from a server is known as a client. Browser, which is installed on the user' computer, allows users to view the retrieved documents.
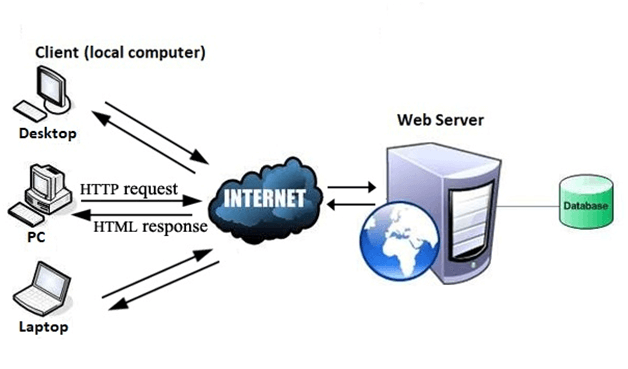
Fig 10 – Internet
All the websites are stored in web servers. Just as someone lives on rent in a house, a website occupies a space in a server and remains stored in it. The server hosts the website whenever a user requests its WebPages, and the website owner has to pay the hosting price for the same.
The moment you open the browser and type a URL in the address bar or search something on Google, the WWW starts working. There are three main technologies involved in transferring information (web pages) from servers to clients (computers of users). These technologies include Hypertext Markup Language (HTML), Hypertext Transfer Protocol (HTTP) and Web browsers.
Hypertext Markup Language (HTML):

Fig 11 - HTML
HTML is a standard markup language which is used for creating web pages. It describes the structure of web pages through HTML elements or tags. These tags are used to organize the pieces of content such as 'heading,' 'paragraph,' 'table,' 'Image,' and more. You don't see HTML tags when you open a webpage as browsers don't display the tags and use them only to render the content of a web page. In simple words, HTML is used to display text, images, and other resources through a Web browser.
Web Browser:

Fig 12 – Web Browser
A web browser, which is commonly known as a browser, is a program that displays text, data, pictures, videos, animation, and more. It provides a software interface that allows you to click hyperlinked resources on the World Wide Web. When you double click the Browser icon installed on your computer to launch it, you get connected to the World Wide Web and can search Google or type a URL into the address bar.
In the beginning, browsers were used only for browsing due to their limited potential. Today, they are more advanced; along with browsing you can use them for e-mailing, transferring multimedia files, using social media sites, and participating in online discussion groups and more. Some of the commonly used browsers include Google Chrome, Mozilla Firefox, Internet Explorer, Safari, and more.
Hypertext Transfer Protocol (HTTP):
Hyper Text Transfer Protocol (HTTP) is an application layer protocol which enables WWW to work smoothly and effectively. It is based on a client-server model. The client is a web browser which communicates with the web server which hosts the website. This protocol defines how messages are formatted and transmitted and what actions the Web Server and browser should take in response to different commands. When you enter a URL in the browser, an HTTP command is sent to the Web server, and it transmits the requested Web Page.
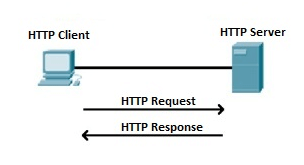
Fig 13 – HTTP Request and Response
When we open a website using a browser, a connection to the web server is opened, and the browser communicates with the server through HTTP and sends a request. HTTP is carried over TCP/IP to communicate with the server. The server processes the browser's request and sends a response, and then the connection is closed. Thus, the browser retrieves content from the server for the user.
HTTP
- HTTP stands for HyperText Transfer Protocol.
- It is a protocol used to access the data on the World Wide Web (www).
- The HTTP protocol can be used to transfer the data in the form of plain text, hypertext, audio, video, and so on.
- This protocol is known as HyperText Transfer Protocol because of its efficiency that allows us to use in a hypertext environment where there are rapid jumps from one document to another document.
- HTTP is similar to the FTP as it also transfers the files from one host to another host. But, HTTP is simpler than FTP as HTTP uses only one connection, i.e., no control connection to transfer the files.
- HTTP is used to carry the data in the form of MIME-like format.
- HTTP is similar to SMTP as the data is transferred between client and server. The HTTP differs from the SMTP in the way the messages are sent from the client to the server and from server to the client. SMTP messages are stored and forwarded while HTTP messages are delivered immediately.
Features of HTTP:
- Connectionless protocol: HTTP is a connectionless protocol. HTTP client initiates a request and waits for a response from the server. When the server receives the request, the server processes the request and sends back the response to the HTTP client after which the client disconnects the connection. The connection between client and server exist only during the current request and response time only.
- Media independent: HTTP protocol is a media independent as data can be sent as long as both the client and server know how to handle the data content. It is required for both the client and server to specify the content type in MIME-type header.
- Stateless: HTTP is a stateless protocol as both the client and server know each other only during the current request. Due to this nature of the protocol, both the client and server do not retain the information between various requests of the web pages.
HTTP Transactions
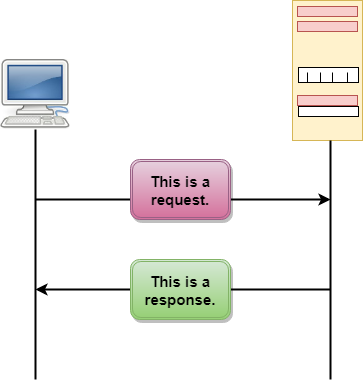
Fig 14 – HTTP Transaction
The above figure shows the HTTP transaction between client and server. The client initiates a transaction by sending a request message to the server. The server replies to the request message by sending a response message.
Messages
HTTP messages are of two types: request and response. Both the message types follow the same message format.
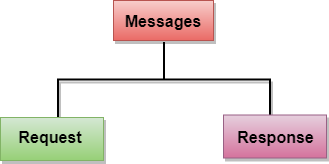
Fig 15 – Message
Request Message: The request message is sent by the client that consists of a request line, headers, and sometimes a body.
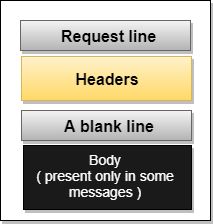
Fig 16 – Request Message
Response Message: The response message is sent by the server to the client that consists of a status line, headers, and sometimes a body.
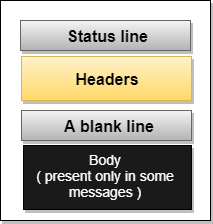
Fig 17 – Response Message
Uniform Resource Locator (URL)
- A client that wants to access the document in an internet needs an address and to facilitate the access of documents, the HTTP uses the concept of Uniform Resource Locator (URL).
- The Uniform Resource Locator (URL) is a standard way of specifying any kind of information on the internet.
- The URL defines four parts: method, host computer, port, and path.

Fig 18 – URL
- Method: The method is the protocol used to retrieve the document from a server. For example, HTTP.
- Host: The host is the computer where the information is stored, and the computer is given an alias name. Web pages are mainly stored in the computers and the computers are given an alias name that begins with the characters "www". This field is not mandatory.
- Port: The URL can also contain the port number of the server, but it's an optional field. If the port number is included, then it must come between the host and path and it should be separated from the host by a colon.
- Path: Path is the pathname of the file where the information is stored. The path itself contain slashes that separate the directories from the subdirectories and files.
SNMP
- SNMP stands for Simple Network Management Protocol.
- SNMP is a framework used for managing devices on the internet.
- It provides a set of operations for monitoring and managing the internet.
SNMP Concept
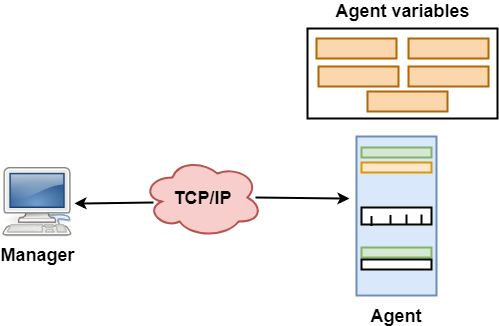
Fig 19 – SNMP Concept
- SNMP has two components Manager and agent.
- The manager is a host that controls and monitors a set of agents such as routers.
- It is an application layer protocol in which a few manager stations can handle a set of agents.
- The protocol designed at the application level can monitor the devices made by different manufacturers and installed on different physical networks.
- It is used in a heterogeneous network made of different LANs and WANs connected by routers or gateways.
Managers & Agents
- A manager is a host that runs the SNMP client program while the agent is a router that runs the SNMP server program.
- Management of the internet is achieved through simple interaction between a manager and agent.
- The agent is used to keep the information in a database while the manager is used to access the values in the database. For example, a router can store the appropriate variables such as a number of packets received and forwarded while the manager can compare these variables to determine whether the router is congested or not.
- Agents can also contribute to the management process. A server program on the agent checks the environment, if something goes wrong, the agent sends a warning message to the manager.
Management with SNMP has three basic ideas:
- A manager checks the agent by requesting the information that reflects the behavior of the agent.
- A manager also forces the agent to perform a certain function by resetting values in the agent database.
- An agent also contributes to the management process by warning the manager regarding an unusual condition.
Management Components
- Management is not achieved only through the SNMP protocol but also the use of other protocols that can cooperate with the SNMP protocol. Management is achieved through the use of the other two protocols: SMI (Structure of management information) and MIB(management information base).
- Management is a combination of SMI, MIB, and SNMP. All these three protocols such as abstract syntax notation 1 (ASN.1) and basic encoding rules (BER).
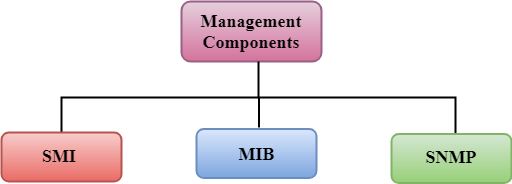
Fig 20 – Management Components
SMI
The SMI (Structure of management information) is a component used in network management. Its main function is to define the type of data that can be stored in an object and to show how to encode the data for the transmission over a network.
MIB
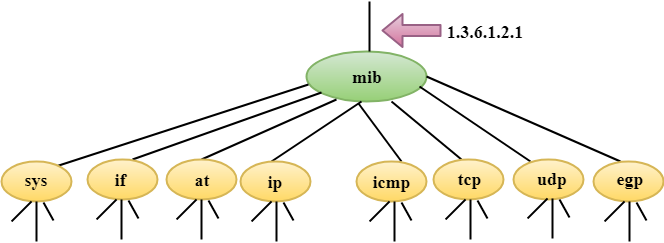
- The MIB (Management information base) is a second component for the network management.
- Each agent has its own MIB, which is a collection of all the objects that the manager can manage. MIB is categorized into eight groups: system, interface, address translation, ip, icmp, tcp, udp, and egp. These groups are under the mib object.
SNMP
SNMP defines five types of messages: GetRequest, GetNextRequest, SetRequest, GetResponse, and Trap.
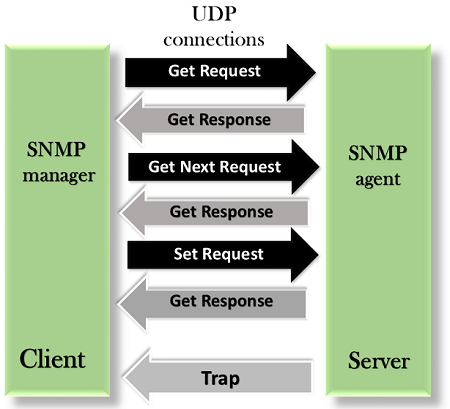
Fig 21 – SNMP
GetRequest: The GetRequest message is sent from a manager (client) to the agent (server) to retrieve the value of a variable.
GetNextRequest: The GetNextRequest message is sent from the manager to agent to retrieve the value of a variable. This type of message is used to retrieve the values of the entries in a table. If the manager does not know the indexes of the entries, then it will not be able to retrieve the values. In such situations, GetNextRequest message is used to define an object.
GetResponse: The GetResponse message is sent from an agent to the manager in response to the GetRequest and GetNextRequest message. This message contains the value of a variable requested by the manager.
SetRequest: The SetRequest message is sent from a manager to the agent to set a value in a variable.
Trap: The Trap message is sent from an agent to the manager to report an event. For example, if the agent is rebooted, then it informs the manager as well as sends the time of rebooting.
Bluetooth Technology in Mobile Computing
Bluetooth technology is a high speed and low powered wireless technology designed to connect phones or other portable equipment for communication or file transmissions. This is based on mobile computing technology. Following is a list of some prominent features of Bluetooth technology:
- Bluetooth is also known as IEEE 802.15 standard or specification that uses low power radio communications to link phones, computers and other network devices over a short distance without using any type of connecting wires.
- As Bluetooth is an open wireless technology standard so, it is used to send or receive data to connected devices present across a certain distance using a band of 2.4 to 2.485 GHz.
- In Bluetooth technology, the wireless signals transmit data and files over a short distance, typically up to 30 feet or 10 meters.
- Bluetooth technology was developed by a group of 5 companies known as Special Interest Group formed in 1998. The companies are Ericsson, Intel, Nokia, IBM, and Toshiba.
- The range of Bluetooth technology for data exchange was up to 10 meters in older versions of devices, but the latest version of Bluetooth technology i.e., Bluetooth 5.0, can exchange data in the range of about 40-400 meters.
- The average speed of data transmission in Bluetooth technology was around 1 Mbps in the very first version. The second version was 2.0+ EDR, which provided the data rate speed of 3Mbps. The third was 3.0+HS, which provided the speed of 24 Mbps. The latest version of this technology is 5.0.
History of Bluetooth
There is an amazing story behind the history of Bluetooth technology. The Bluetooth wireless technology was named after a Danish King named Harald Blatand. His last name means "Bluetooth" in English. The name "Bluetooth" was awarded to this technology because the Danish King named Harald Blatand was united the Denmark and Norway, same as Bluetooth wireless technology is used to unite two disparate devices for communication or data transmission.
Ericsson Mobile Communications started the development of Bluetooth technology in 1994. The main motive behind the development of this amazing technology was to find an alternative to the use of cables for communication between mobile phones and other devices. In 1998, 4 big companies of that time named Ericsson, IBM, Nokia and Toshiba formed the Bluetooth Special Interest Group (SIG), which published the 1st version of Bluetooth technology in 1999. After that, four versions have been released. The latest version of this technology is Bluetooth 5.0.
The Architecture of Bluetooth Technology
- In Bluetooth technology, the network of Bluetooth consists of a Personal Area Network or a
- Bluetooth's architecture is also called a "Piconet" because it is made of multiple networks.
- It contains a minimum of 2 to a maximum of 8 Bluetooth peer devices.
- It usually contains a single master and up to 7 slaves.
- Piconet provides the technology which facilitates data transmission based on its nodes, i.e., Master node and Slave Nodes.
- The master node is responsible for sending the data while the slave nodes are used to receive the data.
- In Bluetooth technology, data transmission occurs through Ultra-High frequency and short-wavelength radio waves.
- The Piconet uses the concept of multiplexing and spread spectrum. It is a combination of code division multiple access (CDMA) and frequency hopping spread spectrum (FHSS) technique.
How does Bluetooth work?
As we stated that there is one master and up to 7 slaves may exist for a Bluetooth connection. The master is the device that initiates communication with other devices. The master device handles the communications link and traffic between itself and the slave devices associated with it. The slave devices have to respond to the master device and synchronize their transmit/receive timing with the master device's specified time.
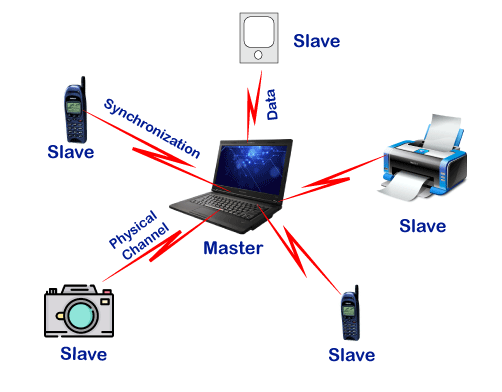
Fig 22 – Master and Slave
Conditions for Successful Data transmission
Following is a list of some conditions that must be satisfied for a successful data transmission in Bluetooth technology:
- Maximum number of Master Node - 1
- Maximum number of Slave Nodes - 7
- Maximum number of Nodes in a Piconet - 8
- Maximum number of devices that can be paired - 28 - 1 = 255
- Number of devices that can be parked → Infinite (∞)
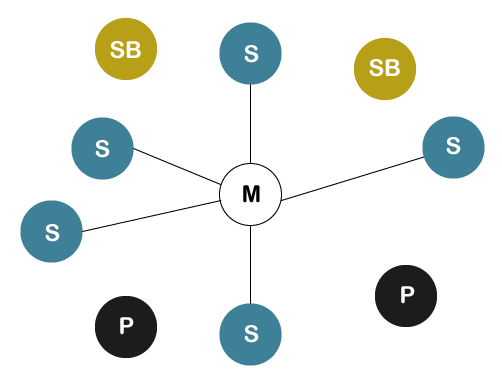
Explanation
- The parked node is a type of node that is ready to be connected and stand by node is a type of node that can either become a slave or parked node or remains idle or disconnected.
- In Bluetooth technology, the data transmission can only occur between master and slave nodes. It cannot be done between slave and slave nodes. However, two master nodes can be connected.
- If the connection from the master node gets disconnected, the whole Piconet gets disconnected.
- If there is a connection between two master nodes, then that network is called as Scatter-net.
- It means scatter-nets are created when a device becomes an active member of more than one Piconet and the adjoining device shares its time slots among the different piconets.
- If the number of slaves or devices is increased in a Piconet, then the data transmission speed will be decreased, and if the number of slaves or devices is decreased in number, then the data transmission speed will be increased.
Specifications of Bluetooth Technology
Bluetooth technology can be specified in two types:
- The Core Specification
- The problems Specification
The Core Specifications
The core specification is used to define the Bluetooth protocol stack and the requirements for the testing and qualification process of the Bluetooth-based products.
The core specification of Bluetooth Technology contains 5 layers:
- Radio: It is used to specify the requirements for radio transmission such as frequency, modulation, and power characteristics for a Bluetooth transceiver.
- Baseband Layer: It is used to define physical and logical channels, voice or data link types, various packet formats, transmit and receive timing, channel control, and the mechanism for frequency hopping and device addressing. It also specifies point to point or point to multipoint links. The length range of a packet can vary from 68 bits to a maximum of 3071 bits.
- Link Manager Protocol (LMP): The Link manager protocol is used to de?ne the procedures for link set up and ongoing link management.
- Logical Link Control and Adaptation Protocol (L2CAP): It is used for adapting upper-layer protocols to the baseband layer.
- Service Discovery Protocol (SDP): It facilitates the Bluetooth device to query other Bluetooth devices for device information, provided services, and the characteristics of those services.
Here, the first three layers denote the Bluetooth module, whereas the last two layers make up the host. The interface between these two logical groups is called the Host Controller Interface.
The Problems Specification
It provides usage models to show detailed information about using the Bluetooth protocol for various types of applications.
Advantages of Bluetooth Technology
Following is a list of some advantages of the Bluetooth technology:
- Bluetooth Technology is based on Wireless technology. That's why it is cheap because it doesn't need any transmission wire that reduces the cost.
- It is very simple to form a Piconet in Bluetooth technology.
- It removes the problem of radio interference by using the Speed Frequency Hopping technique.
- The energy or power consumption is very low, about 0.3mW. It makes it possible for the least utilization of battery life.
- It is robust because it guarantees security at a bit level. The authentication is controlled using a 128bit key.
- You can use it for transferring the data, and verbal communication as Bluetooth can support data channels of up to 3 similar voice channels.
- It doesn't require line of sight and one to one communication as used in other modes of wireless communications such as infrared.
Disadvantages of Bluetooth Technology
Following is a list of some disadvantages of the Bluetooth technology:
- In Bluetooth technology, the bandwidth is low.
- The data transmission range may also be an issue because it is also less.
Applications of Bluetooth Technology
Bluetooth technology is used in many communicational and entertainment devices. The following are some most used applications of the Bluetooth technology:
- Bluetooth technology is used in cordless desktop. It means the peripheral devices such as a mouse, keyboard, printer, speakers, etc. are connected to the desktop without a wire.
- It is used in the multimedia transfer, such as exchanging multimedia data like songs, videos, pictures etc. that can be transferred among devices using Bluetooth.
- This technology is also used in the following devices: i.e.
- Bluetooth Speakers.
- Bluetooth Headphones.
- Bluetooth Headsets for calling purposes.
- Bluetooth gaming consoles etc.
Firewall
Nowadays, it is a big challenge to protect our sensitive data from unwanted and unauthorized sources. There are various tools and devices that can provide different security levels and help keep our private data secure. One such tool is a 'firewall' that prevents unauthorized access and keeps our computers and data safe and secure.
In this article, we have talked about firewalls as well as other related topics, such as why we need firewalls, functions of firewalls, limitations of firewalls, working of firewalls, etc.
What is a Firewall?
A firewall can be defined as a special type of network security device or a software program that monitors and filters incoming and outgoing network traffic based on a defined set of security rules. It acts as a barrier between internal private networks and external sources (such as the public Internet).
The primary purpose of a firewall is to allow non-threatening traffic and prevent malicious or unwanted data traffic for protecting the computer from viruses and attacks. A firewall is a cybersecurity tool that filters network traffic and helps users block malicious software from accessing the Internet in infected computers.
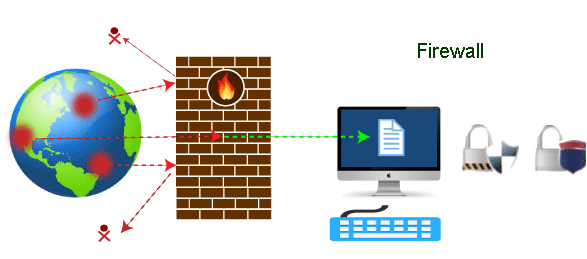
Fig 23 – Firewall
Firewall: Hardware or Software
This is one of the most problematic questions whether a firewall is a hardware or software. As stated above, a firewall can be a network security device or a software program on a computer. This means that the firewall comes at both levels, i.e., hardware and software, though it's best to have both.
Each format (a firewall implemented as hardware or software) has different functionality but the same purpose. A hardware firewall is a physical device that attaches between a computer network and a gateway. For example, a broadband router. On the other hand, a software firewall is a simple program installed on a computer that works through port numbers and other installed software.
Apart from that, there are cloud-based firewalls. They are commonly referred to as FaaS (firewall as a service). A primary advantage of using cloud-based firewalls is that they can be managed centrally. Like hardware firewalls, cloud-based firewalls are best known for providing perimeter security.
Why Firewall
Firewalls are primarily used to prevent malware and network-based attacks. Additionally, they can help in blocking application-layer attacks. These firewalls act as a gatekeeper or a barrier. They monitor every attempt between our computer and another network. They do not allow data packets to be transferred through them unless the data is coming or going from a user-specified trusted source.
Firewalls are designed in such a way that they can react quickly to detect and counter-attacks throughout the network. They can work with rules configured to protect the network and perform quick assessments to find any suspicious activity. In short, we can point to the firewall as a traffic controller.
Some of the important risks of not having a firewall are:
Open Access
If a computer is running without a firewall, it is giving open access to other networks. This means that it is accepting every kind of connection that comes through someone. In this case, it is not possible to detect threats or attacks coming through our network. Without a firewall, we make our devices vulnerable to malicious users and other unwanted sources.
Lost or Comprised Data
Without a firewall, we are leaving our devices accessible to everyone. This means that anyone can access our device and have complete control over it, including the network. In this case, cybercriminals can easily delete our data or use our personal information for their benefit.
Network Crashes
In the absence of a firewall, anyone could access our network and shut it down. It may lead us to invest our valuable time and money to get our network working again.
Therefore, it is essential to use firewalls and keep our network, computer, and data safe and secure from unwanted sources.
Brief History of Firewall
Firewalls have been the first and most reliable component of defense in network security for over 30 years. Firewalls first came into existence in the late 1980s. They were initially designed as packet filters. These packet filters were nothing but a setup of networks between computers. The primary function of these packet filtering firewalls was to check for packets or bytes transferred between different computers.
Firewalls have become more advanced due to continuous development, although such packet filtering firewalls are still in use in legacy systems.
As the technology emerged, Gil Shwed from Check Point Technologies introduced the first stateful inspection firewall in 1993. It was named as FireWall-1. Back in 2000, Netscreen came up with its purpose-built firewall 'Appliance'. It gained popularity and fast adoption within enterprises because of increased internet speed, less latency, and high throughput at a lower cost.
The turn of the century saw a new approach to firewall implementation during the mid-2010. The 'Next-Generation Firewalls' were introduced by the Palo Alto Networks. These firewalls came up with a variety of built-in functions and capabilities, such as Hybrid Cloud Support, Network Threat Prevention, Application and Identity-Based Control, and Scalable Performance, etc. Firewalls are still getting new features as part of continuous development. They are considered the first line of defense when it comes to network security.
How does a firewall work?
A firewall system analyzes network traffic based on pre-defined rules. It then filters the traffic and prevents any such traffic coming from unreliable or suspicious sources. It only allows incoming traffic that is configured to accept.
Typically, firewalls intercept network traffic at a computer's entry point, known as a port. Firewalls perform this task by allowing or blocking specific data packets (units of communication transferred over a digital network) based on pre-defined security rules. Incoming traffic is allowed only through trusted IP addresses, or sources.
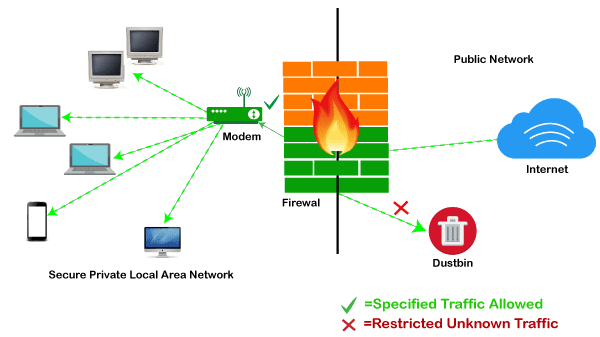
Fig 24 – Example Firewall
Functions of Firewall
As stated above, the firewall works as a gatekeeper. It analyzes every attempt coming to gain access to our operating system and prevents traffic from unwanted or non-recognized sources.
Since the firewall acts as a barrier or filter between the computer system and other networks (i.e., the public Internet), we can consider it as a traffic controller. Therefore, a firewall's primary function is to secure our network and information by controlling network traffic, preventing unwanted incoming network traffic, and validating access by assessing network traffic for malicious things such as hackers and malware.
Generally, most operating systems (for example - Windows OS) and security software come with built-in firewall support. Therefore, it is a good idea to ensure that those options are turned on. Additionally, we can configure the security settings of the system to be automatically updated whenever available.
Firewalls have become so powerful, and include a variety of functions and capabilities with built-in features:
- Network Threat Prevention
- Application and Identity-Based Control
- Hybrid Cloud Support
- Scalable Performance
- Network Traffic Management and Control
- Access Validation
- Record and Report on Events
Limitations of Firewall
When it comes to network security, firewalls are considered the first line of defense. But the question is whether these firewalls are strong enough to make our devices safe from cyber-attacks. The answer may be "no". The best practice is to use a firewall system when using the Internet. However, it is important to use other defense systems to help protect the network and data stored on the computer. Because cyber threats are continually evolving, a firewall should not be the only consideration for protecting the home network.
The importance of using firewalls as a security system is obvious; however, firewalls have some limitations:
- Firewalls cannot stop users from accessing malicious websites, making it vulnerable to internal threats or attacks.
- Firewalls cannot protect against the transfer of virus-infected files or software.
- Firewalls cannot prevent misuse of passwords.
- Firewalls cannot protect if security rules are misconfigured.
- Firewalls cannot protect against non-technical security risks, such as social engineering.
- Firewalls cannot stop or prevent attackers with modems from dialing in to or out of the internal network.
- Firewalls cannot secure the system which is already infected.
Therefore, it is recommended to keep all Internet-enabled devices updated. This includes the latest operating systems, web browsers, applications, and other security software (such as anti-virus). Besides, the security of wireless routers should be another practice. The process of protecting a router may include options such as repeatedly changing the router's name and password, reviewing security settings, and creating a guest network for visitors.
Types of Firewall
Depending on their structure and functionality, there are different types of firewalls. The following is a list of some common types of firewalls:
- Proxy Firewall
- Packet-filtering firewalls
- Stateful Multi-layer Inspection (SMLI) Firewall
- Unified threat management (UTM) firewall
- Next-generation firewall (NGFW)
- Network address translation (NAT) firewalls
Difference between a Firewall and Anti-virus
Firewalls and anti-viruses are systems to protect devices from viruses and other types of Trojans, but there are significant differences between them. Based on the vulnerabilities, the main differences between firewalls and anti-viruses are tabulated below:
Attributes | Firewall | Anti-virus |
Definition | A firewall is defined as the system which analyzes and filters incoming or outgoing data packets based on pre-defined rules. | Anti-virus is defined as the special type of software that acts as a cyber-security mechanism. The primary function of Anti-virus is to monitor, detect, and remove any apprehensive or distrustful file or software from the device. |
Structure | Firewalls can be hardware and software both. The router is an example of a physical firewall, and a simple firewall program on the system is an example of a software firewall. | Anti-virus can only be used as software. Anti-virus is a program that is installed on the device, just like the other programs. |
Implementation | Because firewalls come in the form of hardware and software, a firewall can be implemented either way. | Because Anti-virus comes in the form of software, therefore, Anti-virus can be implemented only at the software level. There is no possibility of implementing Anti-virus at the hardware level. |
Responsibility | A firewall is usually defined as a network controlling system. It means that firewalls are primarily responsible for monitoring and filtering network traffic. | Anti-viruses are primarily responsible for detecting and removing viruses from computer systems or other devices. These viruses can be in the form of infected files or software. |
Scalability | Because the firewall supports both types of implementations, hardware, and software, therefore, it is more scalable than anti-virus. | Anti-viruses are generally considered less-scalable than firewalls. This is because anti-virus can only be implemented at the software level. They don't support hardware-level implementation. |
Threats | A firewall is mainly used to prevent network related attacks. It mainly includes external network threats?for example- Routing attacks and IP Spoofing. | Anti-virus is mainly used to scan, find, and remove viruses, malware, and Trojans, which can harm system files and software and share personal information (such as login credentials, credit card details, etc.) with hackers. |
Types of Firewall
There are mainly three types of firewalls, such as software firewalls, hardware firewalls, or both, depending on their structure. Each type of firewall has different functionality but the same purpose. However, it is best practice to have both to achieve maximum possible protection.
A hardware firewall is a physical device that attaches between a computer network and a gateway. For example- a broadband router. A hardware firewall is sometimes referred to as an Appliance Firewall. On the other hand, a software firewall is a simple program installed on a computer that works through port numbers and other installed software. This type of firewall is also called a Host Firewall.
Besides, there are many other types of firewalls depending on their features and the level of security they provide. The following are types of firewall techniques that can be implemented as software or hardware:
- Packet-filtering Firewalls
- Circuit-level Gateways
- Application-level Gateways (Proxy Firewalls)
- Stateful Multi-layer Inspection (SMLI) Firewalls
- Next-generation Firewalls (NGFW)
- Threat-focused NGFW
- Network Address Translation (NAT) Firewalls
- Cloud Firewalls
- Unified Threat Management (UTM) Firewalls
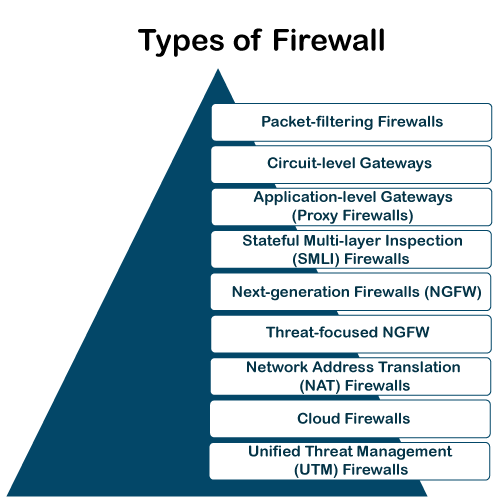
Fig 25 – Types of Firewall
Packet-filtering Firewalls
A packet filtering firewall is the most basic type of firewall. It acts like a management program that monitors network traffic and filters incoming packets based on configured security rules. These firewalls are designed to block network traffic IP protocols, an IP address, and a port number if a data packet does not match the established rule-set.
While packet-filtering firewalls can be considered a fast solution without many resource requirements, they also have some limitations. Because these types of firewalls do not prevent web-based attacks, they are not the safest.
Circuit-level Gateways
Circuit-level gateways are another simplified type of firewall that can be easily configured to allow or block traffic without consuming significant computing resources. These types of firewalls typically operate at the session-level of the OSI model by verifying TCP connections and sessions. Circuit-level gateways are designed to ensure that the established sessions are protected.
Typically, circuit-level firewalls are implemented as security software or pre-existing firewalls. Like packet-filtering firewalls, these firewalls do not check for actual data, although they inspect information about transactions. Therefore, if a data contains malware, but follows the correct TCP connection, it will pass through the gateway. That is why circuit-level gateways are not considered safe enough to protect our systems.
Application-level Gateways (Proxy Firewalls)
Proxy firewalls operate at the application layer as an intermediate device to filter incoming traffic between two end systems (e.g., network and traffic systems). That is why these firewalls are called 'Application-level Gateways'.
Unlike basic firewalls, these firewalls transfer requests from clients pretending to be original clients on the web-server. This protects the client's identity and other suspicious information, keeping the network safe from potential attacks. Once the connection is established, the proxy firewall inspects data packets coming from the source. If the contents of the incoming data packet are protected, the proxy firewall transfers it to the client. This approach creates an additional layer of security between the client and many different sources on the network.
Stateful Multi-layer Inspection (SMLI) Firewalls
Stateful multi-layer inspection firewalls include both packet inspection technology and TCP handshake verification, making SMLI firewalls superior to packet-filtering firewalls or circuit-level gateways. Additionally, these types of firewalls keep track of the status of established connections.
In simple words, when a user establishes a connection and requests data, the SMLI firewall creates a database (state table). The database is used to store session information such as source IP address, port number, destination IP address, destination port number, etc. Connection information is stored for each session in the state table. Using stateful inspection technology, these firewalls create security rules to allow anticipated traffic.
In most cases, SMLI firewalls are implemented as additional security levels. These types of firewalls implement more checks and are considered more secure than stateless firewalls. This is why stateful packet inspection is implemented along with many other firewalls to track statistics for all internal traffic. Doing so increases the load and puts more pressure on computing resources. This can give rise to a slower transfer rate for data packets than other solutions.
Next-generation Firewalls (NGFW)
Many of the latest released firewalls are usually defined as 'next-generation firewalls'. However, there is no specific definition for next-generation firewalls. This type of firewall is usually defined as a security device combining the features and functionalities of other firewalls. These firewalls include deep-packet inspection (DPI), surface-level packet inspection, and TCP handshake testing, etc.
NGFW includes higher levels of security than packet-filtering and stateful inspection firewalls. Unlike traditional firewalls, NGFW monitors the entire transaction of data, including packet headers, packet contents, and sources. NGFWs are designed in such a way that they can prevent more sophisticated and evolving security threats such as malware attacks, external threats, and advance intrusion.
Threat-focused NGFW
Threat-focused NGFW includes all the features of a traditional NGFW. Additionally, they also provide advanced threat detection and remediation. These types of firewalls are capable of reacting against attacks quickly. With intelligent security automation, threat-focused NGFW set security rules and policies, further increasing the security of the overall defense system.
In addition, these firewalls use retrospective security systems to monitor suspicious activities continuously. They keep analyzing the behavior of every activity even after the initial inspection. Due to this functionality, threat-focus NGFW dramatically reduces the overall time taken from threat detection to cleanup.
Network Address Translation (NAT) Firewalls
Network address translation or NAT firewalls are primarily designed to access Internet traffic and block all unwanted connections. These types of firewalls usually hide the IP addresses of our devices, making it safe from attackers.
When multiple devices are used to connect to the Internet, NAT firewalls create a unique IP address and hide individual devices' IP addresses. As a result, a single IP address is used for all devices. By doing this, NAT firewalls secure independent network addresses from attackers scanning a network for accessing IP addresses. This results in enhanced protection against suspicious activities and attacks.
In general, NAT firewalls works similarly to proxy firewalls. Like proxy firewalls, NAT firewalls also work as an intermediate device between a group of computers and external traffic.
Cloud Firewalls
Whenever a firewall is designed using a cloud solution, it is known as a cloud firewall or FaaS (firewall-as-service). Cloud firewalls are typically maintained and run on the Internet by third-party vendors. This type of firewall is considered similar to a proxy firewall. The reason for this is the use of cloud firewalls as proxy servers. However, they are configured based on requirements.
The most significant advantage of cloud firewalls is scalability. Because cloud firewalls have no physical resources, they are easy to scale according to the organization's demand or traffic-load. If demand increases, additional capacity can be added to the cloud server to filter out the additional traffic load. Most organizations use cloud firewalls to secure their internal networks or entire cloud infrastructure.
Unified Threat Management (UTM) Firewalls
UTM firewalls are a special type of device that includes features of a stateful inspection firewall with anti-virus and intrusion prevention support. Such firewalls are designed to provide simplicity and ease of use. These firewalls can also add many other services, such as cloud management, etc.
Which firewall architecture is best?
When it comes to selecting the best firewall architecture, there is no need to be explicit. It is always better to use a combination of different firewalls to add multiple layers of protection. For example, one can implement a hardware or cloud firewall at the perimeter of the network, and then further add individual software firewall with every network asset.
Besides, the selection usually depends on the requirements of any organization. However, the following factors can be considered for the right selection of firewall:
Size of the organization
If an organization is large and maintains a large internal network, it is better to implement such firewall architecture, which can monitor the entire internal network.
Availability of resources
If an organization has the resources and can afford a separate firewall for each hardware piece, this is a good option. Besides, a cloud firewall may be another consideration.
Requirement of multi-level protection
The number and type of firewalls typically depend on the security measures that an internal network requires. This means, if an organization maintains sensitive data, it is better to implement multi-level protection of firewalls. This will ensure data security from hackers.
Key takeaways
- FTP stands for File transfer protocol.
- FTP is a standard internet protocol provided by TCP/IP used for transmitting the files from one host to another.
- It is mainly used for transferring the web page files from their creator to the computer that acts as a server for other computers on the internet.
- It is also used for downloading the files to computer from other servers.
- It provides the sharing of files.
- It is used to encourage the use of remote computers.
- It transfers the data more reliably and efficiently.
Origin of Cryptography
Human being from ages had two inherent needs − (a) to communicate and share information and (b) to communicate selectively. These two needs gave rise to the art of coding the messages in such a way that only the intended people could have access to the information. Unauthorized people could not extract any information, even if the scrambled messages fell in their hand.
The art and science of concealing the messages to introduce secrecy in information security is recognized as cryptography.
The word ‘cryptography’ was coined by combining two Greek words, ‘Krypto’ meaning hidden and ‘graphene’ meaning writing.
History of Cryptography
The art of cryptography is considered to be born along with the art of writing. As civilizations evolved, human beings got organized in tribes, groups, and kingdoms. This led to the emergence of ideas such as power, battles, supremacy, and politics. These ideas further fueled the natural need of people to communicate secretly with selective recipient which in turn ensured the continuous evolution of cryptography as well.
The roots of cryptography are found in Roman and Egyptian civilizations.
Hieroglyph − The Oldest Cryptographic Technique
The first known evidence of cryptography can be traced to the use of ‘hieroglyph’. Some 4000 years ago, the Egyptians used to communicate by messages written in hieroglyph. This code was the secret known only to the scribes who used to transmit messages on behalf of the kings. One such hieroglyph is shown below.

Later, the scholars moved on to using simple mono-alphabetic substitution ciphers during 500 to 600 BC. This involved replacing alphabets of message with other alphabets with some secret rule. This rule became a key to retrieve the message back from the garbled message.
The earlier Roman method of cryptography, popularly known as the Caesar Shift Cipher, relies on shifting the letters of a message by an agreed number (three was a common choice), the recipient of this message would then shift the letters back by the same number and obtain the original message.
Steganography
Steganography is similar but adds another dimension to Cryptography. In this method, people not only want to protect the secrecy of an information by concealing it, but they also want to make sure any unauthorized person gets no evidence that the information even exists. For example, invisible watermarking.
In steganography, an unintended recipient or an intruder is unaware of the fact that observed data contains hidden information. In cryptography, an intruder is normally aware that data is being communicated, because they can see the coded/scrambled message.

Evolution of Cryptography
It is during and after the European Renaissance, various Italian and Papal states led the rapid proliferation of cryptographic techniques. Various analysis and attack techniques were researched in this era to break the secret codes.
- Improved coding techniques such as Vigenere Coding came into existence in the 15th century, which offered moving letters in the message with a number of variable places instead of moving them the same number of places.
- Only after the 19th century, cryptography evolved from the ad hoc approaches to encryption to the more sophisticated art and science of information security.
- In the early 20th century, the invention of mechanical and electromechanical machines, such as the Enigma rotor machine, provided more advanced and efficient means of coding the information.
- During the period of World War II, both cryptography and cryptanalysis became excessively mathematical.
With the advances taking place in this field, government organizations, military units, and some corporate houses started adopting the applications of cryptography. They used cryptography to guard their secrets from others. Now, the arrival of computers and the Internet has brought effective cryptography within the reach of common people.
Modern Cryptography
Modern cryptography is the cornerstone of computer and communications security. Its foundation is based on various concepts of mathematics such as number theory, computational-complexity theory, and probability theory.
Characteristics of Modern Cryptography
There are three major characteristics that separate modern cryptography from the classical approach.
Classic Cryptography | Modern Cryptography |
It manipulates traditional characters, i.e., letters and digits directly. | It operates on binary bit sequences. |
It is mainly based on ‘security through obscurity’. The techniques employed for coding were kept secret and only the parties involved in communication knew about them. | It relies on publicly known mathematical algorithms for coding the information. Secrecy is obtained through a secrete key which is used as the seed for the algorithms. The computational difficulty of algorithms, absence of secret key, etc., make it impossible for an attacker to obtain the original information even if he knows the algorithm used for coding. |
It requires the entire cryptosystem for communicating confidentially. | Modern cryptography requires parties interested in secure communication to possess the secret key only. |
Context of Cryptography
Cryptology, the study of cryptosystems, can be subdivided into two branches −
- Cryptography
- Cryptanalysis
What is Cryptography?
Cryptography is the art and science of making a cryptosystem that is capable of providing information security.
Cryptography deals with the actual securing of digital data. It refers to the design of mechanisms based on mathematical algorithms that provide fundamental information security services. You can think of cryptography as the establishment of a large toolkit containing different techniques in security applications.
What is Cryptanalysis?
The art and science of breaking the cipher text is known as cryptanalysis.
Cryptanalysis is the sister branch of cryptography and they both co-exist. The cryptographic process results in the cipher text for transmission or storage. It involves the study of cryptographic mechanism with the intention to break them. Cryptanalysis is also used during the design of the new cryptographic techniques to test their security strengths.
Note − Cryptography concerns with the design of cryptosystems, while cryptanalysis studies the breaking of cryptosystems.
Security Services of Cryptography
The primary objective of using cryptography is to provide the following four fundamental information security services. Let us now see the possible goals intended to be fulfilled by cryptography.
Confidentiality
Confidentiality is the fundamental security service provided by cryptography. It is a security service that keeps the information from an unauthorized person. It is sometimes referred to as privacy or secrecy.
Confidentiality can be achieved through numerous means starting from physical securing to the use of mathematical algorithms for data encryption.
Data Integrity
It is security service that deals with identifying any alteration to the data. The data may get modified by an unauthorized entity intentionally or accidently. Integrity service confirms that whether data is intact or not since it was last created, transmitted, or stored by an authorized user.
Data integrity cannot prevent the alteration of data, but provides a means for detecting whether data has been manipulated in an unauthorized manner.
Authentication
Authentication provides the identification of the originator. It confirms to the receiver that the data received has been sent only by an identified and verified sender.
Authentication service has two variants −
- Message authentication identifies the originator of the message without any regard router or system that has sent the message.
- Entity authentication is assurance that data has been received from a specific entity, say a particular website.
Apart from the originator, authentication may also provide assurance about other parameters related to data such as the date and time of creation/transmission.
Non-repudiation
It is a security service that ensures that an entity cannot refuse the ownership of a previous commitment or an action. It is an assurance that the original creator of the data cannot deny the creation or transmission of the said data to a recipient or third party.
Non-repudiation is a property that is most desirable in situations where there are chances of a dispute over the exchange of data. For example, once an order is placed electronically, a purchaser cannot deny the purchase order, if non-repudiation service was enabled in this transaction.
Cryptography Primitives
Cryptography primitives are nothing but the tools and techniques in Cryptography that can be selectively used to provide a set of desired security services −
- Encryption
- Hash functions
- Message Authentication codes (MAC)
- Digital Signatures
The following table shows the primitives that can achieve a particular security service on their own.
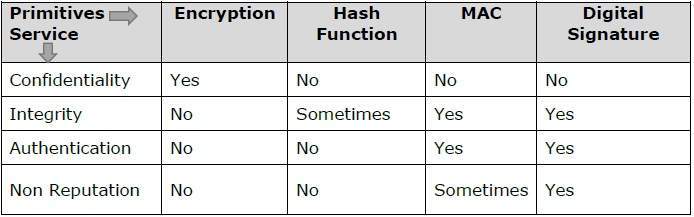
Note − Cryptographic primitives are intricately related and they are often combined to achieve a set of desired security services from a cryptosystem.
Cryptosystems
A cryptosystem is an implementation of cryptographic techniques and their accompanying infrastructure to provide information security services. A cryptosystem is also referred to as a cipher system.
Let us discuss a simple model of a cryptosystem that provides confidentiality to the information being transmitted. This basic model is depicted in the illustration below −
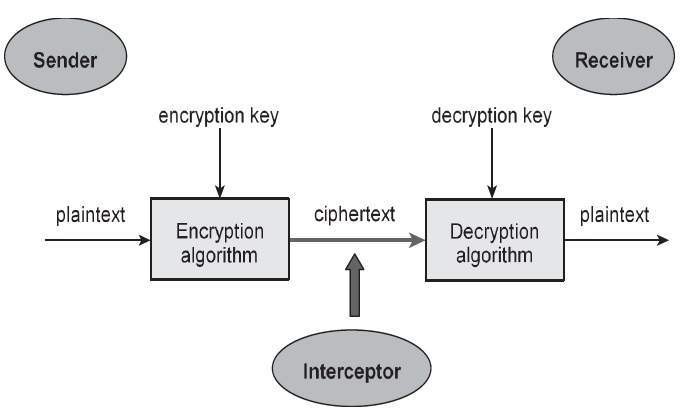
Fig 25 – Cryptosystems
The illustration shows a sender who wants to transfer some sensitive data to a receiver in such a way that any party intercepting or eavesdropping on the communication channel cannot extract the data.
The objective of this simple cryptosystem is that at the end of the process, only the sender and the receiver will know the plaintext.
Components of a Cryptosystem
The various components of a basic cryptosystem are as follows −
- Plaintext. It is the data to be protected during transmission.
- Encryption Algorithm. It is a mathematical process that produces a ciphertext for any given plaintext and encryption key. It is a cryptographic algorithm that takes plaintext and an encryption key as input and produces a ciphertext.
- Ciphertext. It is the scrambled version of the plaintext produced by the encryption algorithm using a specific the encryption key. The ciphertext is not guarded. It flows on public channel. It can be intercepted or compromised by anyone who has access to the communication channel.
- Decryption Algorithm, It is a mathematical process, that produces a unique plaintext for any given ciphertext and decryption key. It is a cryptographic algorithm that takes a ciphertext and a decryption key as input, and outputs a plaintext. The decryption algorithm essentially reverses the encryption algorithm and is thus closely related to it.
- Encryption Key. It is a value that is known to the sender. The sender inputs the encryption key into the encryption algorithm along with the plaintext in order to compute the ciphertext.
- Decryption Key. It is a value that is known to the receiver. The decryption key is related to the encryption key, but is not always identical to it. The receiver inputs the decryption key into the decryption algorithm along with the ciphertext in order to compute the plaintext.
For a given cryptosystem, a collection of all possible decryption keys is called a key space.
An interceptor (an attacker) is an unauthorized entity who attempts to determine the plaintext. He can see the ciphertext and may know the decryption algorithm. He, however, must never know the decryption key.
Types of Cryptosystems
Fundamentally, there are two types of cryptosystems based on the manner in which encryption-decryption is carried out in the system −
- Symmetric Key Encryption
- Asymmetric Key Encryption
The main difference between these cryptosystems is the relationship between the encryption and the decryption key. Logically, in any cryptosystem, both the keys are closely associated. It is practically impossible to decrypt the ciphertext with the key that is unrelated to the encryption key.
Symmetric Key Encryption
The encryption process where same keys are used for encrypting and decrypting the information is known as Symmetric Key Encryption.
The study of symmetric cryptosystems is referred to as symmetric cryptography. Symmetric cryptosystems are also sometimes referred to as secret key cryptosystems.
A few well-known examples of symmetric key encryption methods are − Digital Encryption Standard (DES), Triple-DES (3DES), IDEA, and BLOWFISH.
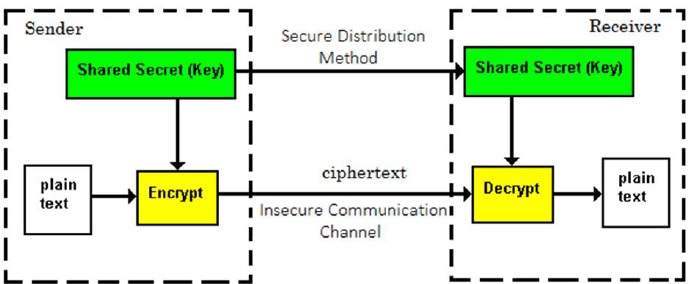
Prior to 1970, all cryptosystems employed symmetric key encryption. Even today, its relevance is very high and it is being used extensively in many cryptosystems. It is very unlikely that this encryption will fade away, as it has certain advantages over asymmetric key encryption.
The salient features of cryptosystem based on symmetric key encryption are −
- Persons using symmetric key encryption must share a common key prior to exchange of information.
- Keys are recommended to be changed regularly to prevent any attack on the system.
- A robust mechanism needs to exist to exchange the key between the communicating parties. As keys are required to be changed regularly, this mechanism becomes expensive and cumbersome.
- In a group of n people, to enable two-party communication between any two persons, the number of keys required for group is n × (n – 1)/2.
- Length of Key (number of bits) in this encryption is smaller and hence, process of encryption-decryption is faster than asymmetric key encryption.
- Processing power of computer system required to run symmetric algorithm is less.
Challenge of Symmetric Key Cryptosystem
There are two restrictive challenges of employing symmetric key cryptography.
- Key establishment − Before any communication, both the sender and the receiver need to agree on a secret symmetric key. It requires a secure key establishment mechanism in place.
- Trust Issue − Since the sender and the receiver use the same symmetric key, there is an implicit requirement that the sender and the receiver ‘trust’ each other. For example, it may happen that the receiver has lost the key to an attacker and the sender is not informed.
These two challenges are highly restraining for modern day communication. Today, people need to exchange information with non-familiar and non-trusted parties. For example, a communication between online seller and customer. These limitations of symmetric key encryption gave rise to asymmetric key encryption schemes.
Asymmetric Key Encryption
The encryption process where different keys are used for encrypting and decrypting the information is known as Asymmetric Key Encryption. Though the keys are different, they are mathematically related and hence, retrieving the plaintext by decrypting ciphertext is feasible. The process is depicted in the following illustration −
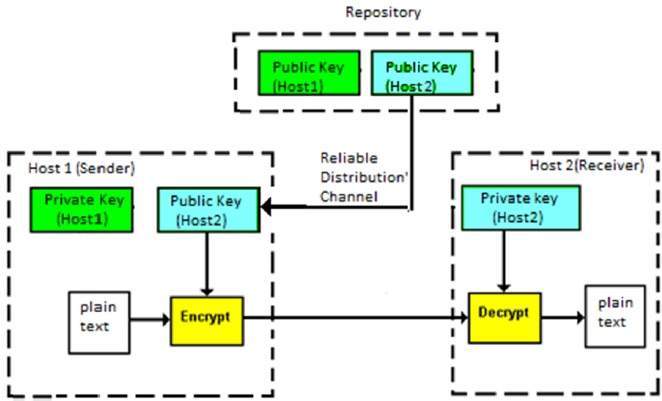
Asymmetric Key Encryption was invented in the 20th century to come over the necessity of pre-shared secret key between communicating persons. The salient features of this encryption scheme are as follows −
- Every user in this system needs to have a pair of dissimilar keys, private key and public key. These keys are mathematically related − when one key is used for encryption, the other can decrypt the ciphertext back to the original plaintext.
- It requires to put the public key in public repository and the private key as a well-guarded secret. Hence, this scheme of encryption is also called Public Key Encryption.
- Though public and private keys of the user are related, it is computationally not feasible to find one from another. This is a strength of this scheme.
- When Host1 needs to send data to Host2, he obtains the public key of Host2 from repository, encrypts the data, and transmits.
- Host2 uses his private key to extract the plaintext.
- Length of Keys (number of bits) in this encryption is large and hence, the process of encryption-decryption is slower than symmetric key encryption.
- Processing power of computer system required to run asymmetric algorithm is higher.
Symmetric cryptosystems are a natural concept. In contrast, public-key cryptosystems are quite difficult to comprehend.
You may think, how can the encryption key and the decryption key are ‘related’, and yet it is impossible to determine the decryption key from the encryption key? The answer lies in the mathematical concepts. It is possible to design a cryptosystem whose keys have this property. The concept of public-key cryptography is relatively new. There are fewer public-key algorithms known than symmetric algorithms.
Challenge of Public Key Cryptosystem
Public-key cryptosystems have one significant challenge − the user needs to trust that the public key that he is using in communications with a person really is the public key of that person and has not been spoofed by a malicious third party.
This is usually accomplished through a Public Key Infrastructure (PKI) consisting a trusted third party. The third party securely manages and attests to the authenticity of public keys. When the third party is requested to provide the public key for any communicating person X, they are trusted to provide the correct public key.
The third party satisfies itself about user identity by the process of attestation, notarization, or some other process − that X is the one and only, or globally unique, X. The most common method of making the verified public keys available is to embed them in a certificate which is digitally signed by the trusted third party.
Relation between Encryption Schemes
A summary of basic key properties of two types of cryptosystems is given below−
| Symmetric Cryptosystems | Public Key Cryptosystems |
Relation between Keys | Same | Different, but mathematically related |
Encryption Key | Symmetric | Public |
Decryption Key | Symmetric | Private |
Due to the advantages and disadvantage of both the systems, symmetric key and public-key cryptosystems are often used together in the practical information security systems.
Kerckhoff’s Principle for Cryptosystem
In the 19th century, a Dutch cryptographer A. Kerckhoff furnished the requirements of a good cryptosystem. Kerckhoff stated that a cryptographic system should be secure even if everything about the system, except the key, is public knowledge. The six design principles defined by Kerckhoff for cryptosystem are −
- The cryptosystem should be unbreakable practically, if not mathematically.
- Falling of the cryptosystem in the hands of an intruder should not lead to any compromise of the system, preventing any inconvenience to the user.
- The key should be easily communicable, memorable, and changeable.
- The ciphertext should be transmissible by telegraph, an unsecure channel.
- The encryption apparatus and documents should be portable and operable by a single person.
- Finally, it is necessary that the system be easy to use, requiring neither mental strain nor the knowledge of a long series of rules to observe.
The second rule is currently known as Kerckhoff principle. It is applied in virtually all the contemporary encryption algorithms such as DES, AES, etc. These public algorithms are considered to be thoroughly secure. The security of the encrypted message depends solely on the security of the secret encryption key.
Keeping the algorithms secret may act as a significant barrier to cryptanalysis. However, keeping the algorithms secret is possible only when they are used in a strictly limited circle.
In modern era, cryptography needs to cater to users who are connected to the Internet. In such cases, using a secret algorithm is not feasible, hence Kerckhoff principles became essential guidelines for designing algorithms in modern cryptography.
Key takeaways
- Human being from ages had two inherent needs − (a) to communicate and share information and (b) to communicate selectively. These two needs gave rise to the art of coding the messages in such a way that only the intended people could have access to the information. Unauthorized people could not extract any information, even if the scrambled messages fell in their hand.
- The art and science of concealing the messages to introduce secrecy in information security is recognized as cryptography.
- The word ‘cryptography’ was coined by combining two Greek words, ‘Krypto’ meaning hidden and ‘graphene’ meaning writing.
References:
1. Computer Networks, 8th Edition, Andrew S. Tanenbaum, Pearson New International Edition.
2. Internetworking with TCP/IP, Volume 1, 6th Edition Douglas Comer, Prentice Hall of India.
3. TCP/IP Illustrated, Volume 1, W. Richard Stevens, Addison-Wesley, United States of America.




