Unit - 2
SQL and PL/SQL
Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database. SQL comes in different versions and forms. All of these versions are based upon the ANSI SQL.
Currently, MySQL is the most common programme for database management systems used for relational database management. It is open-source, Oracle Company - supported database programme. In comparison to Microsoft SQL Server and Oracle Database, the database management system is fast, scalable, and easy to use. It is widely used for building efficient and interactive server-side or web-based business applications in combination with PHP scripts.
Characteristics of SQL
● It is quick to learn SQL.
● For accessing data from relational database management systems, SQL is used.
● SQL will perform database queries against it.
● To describe data, SQL is used.
● SQL is used in the database to describe the data and manipulate it when appropriate.
● To build and drop the database and the table, SQL is used.
● SQL is used in a database to construct a view, a stored procedure, a function.
● SQL allows users to set tables, procedures, and display permissions.
Advantages of SQL
● SQL is easy to learn and use.
● SQL is a non-procedural language. It means we have to specify only what to retrieve and not the procedure for retrieving data.
● SQL can be embedded within other languages using SQL modules, pre-compilers.
● Allows creating procedures, functions, and views using PL-SQL.
● Allows users to drop databases, tables, views, procedures and cursors.
● Allows users to set access permissions on tables, views and procedures.
Key takeaway:
- MySQL is the most common programme for database management systems used for relational database management.
- Structured Query Language (SQL) is a database query language which is used to store, retrieve and modify data in the relational database.
- SQL comes in different versions and forms.
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
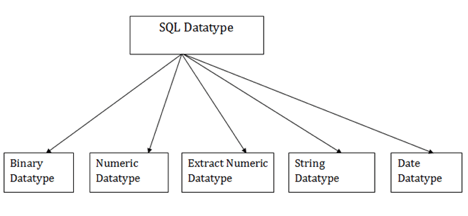
Fig 1: Sql data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Literals
Literals are notes or the concept of representing/expressing a meaning that does not change. Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
We will explain the various forms of literal statements in this section and how they can be used in MySQL statements.
The following are the literal forms:
S.no |
Literal type & example |
1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
Key takeaway:
- Literals are equivalent to constants in MySQL. When declaring a variable or executing queries, we may use a literal one.
- Literals are notes or the concept of representing/expressing a meaning that does not change
DDL (Data Definition Language)
DDL queries are used to define and manipulate the structure of tables. These commands will primarily be used by database administrators during the setup and removal phases of a database project.
DDL contains:
1. CREATE command to create a new table
2. ALTER command to modify a existing table
3. DROP command to delete a table
S .No | Command and description |
1. | CREATE Creates a new table, a view of a table, or other object in the database. Syntax: CREATE TABLE table_name ( column_name1 data_type(size), Column_name2 data_type(size),...... )
Example 1 This example demonstrates how you can create a table named “Account” with four columns. The column names will be “Acc_no” “Acct_hold_name”, “Address”, and “Mobile no”:
Mysql> CREATE TABLE Account (Acc_no int, Acct_hold_name varchar, Address varchar, mobil_no float )
|
2. | ALTER The ALTER command is used to change the structure of a existing table without deleting and recreating it.
Let’s begin with creation of a table called testalter_tbl. Mysql> create table customer ( cust_id int, cust_name varchar,cust_addr Varchar(10),acc_no int); Dropping, Adding or Changing size of a Column: Suppose you want to drop an existing column acc_no from above table then DROP clause along with ALTER command is used as follows:
Mysql> ALTER TABLE customer DROP acc_no; A DROP will not work if the mentioned column is the only one left in the table.
To add a column, use ADD and specify the column definition. The following statement Restores the acc_no column to customer table:
Mysql> ALTER TABLE customer ADD COLUMN acc_no int;
Changing a Column Definition or Name: To change a column’s definition, use MODIFY or CHANGE clause along with ALTER command. For example, to change column cust_addr from varchar(10) to Varchar(15), do this:
Mysql> ALTER TABLE customer MODIFY cust_addr varchar(15);
|
3. | DROP Deletes an entire table, a view of a table or other objects in the database. Syntax
DROP TABLE table_name;
For example, if we want to permanently remove the Employee table that we created, we use the following command:
DROP TABLE Employee;
|
Key takeaway:
- DDL queries are used to define and manipulate the structure of tables.
- These commands will primarily be used by database administrators during the setup and removal phases of a database project.
DML (Data Manipulation Language)
DML queries are used to manipulate the data stored in table. Data Manipulation Language commands are used to insert, retrieve and modify the data contained within it.
S . No | Command & description |
1. | SELECT Retrieves certain records from one or more tables. Syntax SELECT * FROM tablename.
OR
SELECT columnname,columnname,….. FROM tablename ;
|
2. | INSERT Creates a record in tables.
Example 1: Inserting a single row of data into a table Syntax INSERT INTO table_name [(columnname,columnname)] VALUES (expression,expression); To add a new employee to the personal_info table Example INSERT INTO customer values(1,’Ram’,’Pune’,3333444488)
Example 2 : Inserting data into a table from another table Syntax INSERT INTO tablename SELECT columnname,columnname FROM tablename
|
3. | UPDATE Modifies record stored in table. The UPDATE command can be used to modify information contained within a table.
Syntax
UPDATE customer SET cust_Address=’mumbai’ where cust_id=1; |
4. | DELETE Deletes records stored in table. The DELETE command can be used to delete information contained within a table.
Syntax
DELETE FROM tablename WHERE search condition The DELETE command with a WHERE clause can be used to remove his record from The customer table: Example
DELETE FROM customer WHERE cust_id=12; The following command deletes all the rows from the table Example DELETE FROM customer;
|
Key takeaway:
- DML queries are used to manipulate the data stored in table.
- DML commands are used to insert, retrieve and modify the data contained within it.
DCL (Data Control Language)
GRANT and REVOKE are commands in the DCL (Data Control Language) that can be used to grant "rights and permissions." The database system's parameters are controlled by other permissions.
DCL commands include the following:
- Grant
- Revoke
Grant
This command is used to grant a user database access capabilities.
Syntax
GRANT SELECT, UPDATE ON MY_TABLE TO SOME_USER, ANOTHER_USER;
Example
GRANT SELECT ON Users TO'Tom'@'localhost;
Revoke
It's a good idea to back up the user's permissions.
Syntax
REVOKE privilege_nameON object_nameFROM {user_name |PUBLIC |role_name}
Example
REVOKE SELECT, UPDATE ON student FROM Btech, Mtech;
TCL (Transaction Control Language)
TCL commands, or transaction control language, deal with database transactions.
Commit
All transactions are saved to the database with this command.
Syntax
Commit;
Example
DELETE FROM Students
WHERE RollNo =25;
COMMIT;
Rollback
You can use the rollback command to undo transactions that haven't yet been stored to the database.
Syntax
ROLLBACK;
Example
DELETE FROM Students
WHERE RollNo =25;
SAVEPOINT
This command allows you to save a transaction at a certain point.
Syntax
SAVEPOINT SAVEPOINT_NAME;
Example
SAVEPOINT RollNo;
Key takeaway:
- GRANT and REVOKE are commands in the DCL (Data Control Language) that can be used to grant "rights and permissions."
- TCL commands, or transaction control language, deal with database transactions.
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to conduct operations like comparisons and arithmetic computations. These Operators are used to express conditions in SQL statements and to act as conjunctions for numerous conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
Arithmetic operators
If 'variable a' has a value of 10 and 'variable b' has a value of 20, then
Operator | Description | Example |
+ (Addition) | Values are added on both sides of the operator.
| a + b will give 30 |
- (Subtraction) | Takes the right hand operand and subtracts it from the left hand operand. | a - b will give -10 |
* (Multiplication) | Values on both sides of the operator are multiplied. | a * b will give 200 |
/ (Division) | Divides the left and right hand operands. | b / a will give 2 |
% (Modulus) | Returns the remainder after dividing the left hand operand by the right hand operand. | b % a will give 0 |
Comparison operators
If 'variable a' has a value of 10 and 'variable b' has a value of 20, then
Operator | Description | Example |
= | Checks whether the values of two operands are equal, and if they are, the condition is true. | (a = b) is not true. |
!= | Checks whether the values of two operands are equivalent; if they aren't, the condition is true. | (a != b) is true. |
<> | Checks whether the values of two operands are equivalent; if they aren't, the condition is true. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is true. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is true. | (a < b) is true. |
>= | If the left operand's value is larger than or equal to the right operand's value, then the condition is true. | (a >= b) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is true. | (a <= b) is true. |
!< | If the value of the left operand is greater than the value of the right operand, the condition is true. | (a !< b) is false. |
!> | If the value of the left operand is less than the value of the right operand, then the condition is true. | (a !> b) is true. |
Logical operator
The following is a list of all the logical operators in SQL.
SrNo | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows many conditions to exist in the WHERE clause of a SQL query. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the criteria. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a specified table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been supplied, the IN operator is utilized. |
7 | LIKE The LIKE operator compares a value to other values that are comparable using wildcard operators. |
8 | NOT The NOT operator flips the meaning of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL query to combine multiple conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is employed. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
Key takeaway:
- An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to conduct operations like comparisons and arithmetic computations.
- These Operators are used to express conditions in SQL statements and to act as conjunctions for numerous conditions in a single statement.
It is just as important to design and maintain your tables as to ask about them. Creating, editing and deleting (dropping) tables requires designing and handling the tables. Table architecture governs much of the performance of your database and defines the consistency, stability and scalability of data.
Creating
The Build TABLE statement is used in a database to create a new table. In that table, use the syntax below if you want to add several columns.
Syntax for creating table
CREATE TABLE table_name(
Column1 datatype,
Column2 datatype,
Column3 datatype,
.....
ColumnN datatype,
PRIMARY KEY( one or more columns )
);
The column parameters define the names of the table's columns.
The parameter of the data type determines the type of data that the column can contain (e.g. Varchar, integer, date, etc.).
Create Table example
CREATE TABLE Employee(
EmpId int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
Modifying
In SQL, a SQL ALTER table statement is used to delete, add or even change an existing table's columns. It is often used to implement the table's constraints.
To adjust the data type of a column in a table, we use this order.
The syntax of Alter Table Change SQL Server column-
ALTER TABLE table_name
ALTER COLUMN column_name datatype;
Deleting
The DELETE statement is used to delete current records from a given record table.
Syntax
DELETE FROM table_name WHERE condition;
Example
DELETE FROM Employee WHERE EmpId=1;
EmpId = 1 record in the Employee table is removed.
Key takeaway:
- Creating, editing and deleting (dropping) tables requires designing and handling the tables.
- Table architecture governs much of the performance of your database and defines the consistency, stability and scalability of data.
The SELECT statement is used in the database to select / retrieve data from a table. The most frequently used statement is the SQL Pick Statement.
The SELECT Statement question retrieves data from the table as a whole or from some particular columns.
We need to write SELECT statement queries in SQL if we want to retrieve any data from a table.
We retrieve the data by columns in SELECT Statement wise.
Syntax
The SQL SELECT Syntax categorises into two sections, first we get complete table data from all columns, second we get some unique columns from a table.
SELECT all Columns data from a table
SELECT * FROM table_name ;
* = indicate the retrieve all the columns from a table.
Table_name = is the name of table from which the data is retrieved.
SELECT some columns data from a table
SELECT Col1, Col2, Col3 FROM table_name
Col1, Col2, Col3 = is the column name from which data is retrieved.
Table_name = is the name of table from which the data is retrieved.
A SELECT command has number of clauses :
● WHERE clause : Any output row from the FROM stage applies a criterion, further reducing the number of rows.
● GROUP BY clause : Class sets of rows with values balanced by columns in a group.
● HAVING clause : Criteria for each group of rows are added. Criteria can only be extended to columns within a category that have constant values (those in the grouping columns or aggregate functions applied across the group).
● ORDER BY clause : The rows returned from the SELECT stage are sorted as desired. Supports sorting, ascending or descending on multiple columns in a specified order. The output columns will be similar and have the same name as the columns returned from the SELECT point.
● INTO clause : Logically, the INTO clause is last used in processing.
Key takeaway:
- The SELECT statement is used in the database to select / retrieve data from a table.
- We retrieve the data by columns in SELECT Statement wise.
- The SELECT Statement question retrieves data from the table as a whole or from some particular columns.
Unique and non-unique indexes
Unique indexes ensure that no two rows in a table have the same key column value (or columns).
Oracle suggests explicitly creating unique indexes rather than enabling a unique requirement on a table for performance reasons. (Unique integrity constraints are enforced by defining an index automatically.)
You can construct several indexes for a table as long as each index has a different combination of columns.
CREATE INDEX emp_idx1 ON emp (ename, job);
CREATE INDEX emp_idx2 ON emp (job, ename);
The presence or absence of an index does not necessitate any changes to the SQL statement's language. An index is nothing more than a shortcut to the data.
An existing index can be used by the query optimizer to create a new index. As a result, index creation is substantially faster.
Index multiple index
A composite index is a table index that is made up of many columns.
If the SQL WHERE clause refers to all (or the leading portion) of the index columns, this can speed up data retrieval. As a result, the order in which the columns are defined in the definition is critical: the most often accessed or selective columns come first.
Rebuilding indexes
Although indexes can be updated with ALTER INDEX abc REBUILD, it is a common misconception that rebuilding indexes will increase performance.
Redesigning an index to meet the SQL queries being run, on the other hand, will yield measurable results.
Function-Based Indexes
You can make indexes on functions and expressions that reference columns in the table.
The value of a function or expression is precomputed and stored in a function-based index (B-tree or bitmap).
Case-insensitive searches can be aided by function-based indexes created on UPPER(column name) or LOWER(column name). Consider the following index:
CREATE INDEX uppercase_idx ON emp (UPPER(empname));
Can facilitate processing queries such as this:
SELECT * FROM emp WHERE UPPER(empname) = 'RICHARD';
You'll need optimizer statistics to use function-based indexing.
(Not compatible with optimization based on rules.)
Any modifications to the function specification, whether it's a PL/SQL function or a package function, will result in the index being disabled.
Sequence
The sequence generator generates a series of integers in a specific order. The sequence generator comes in handy when you need to create unique sequential ID numbers.
Individual sequence numbers that were generated and utilized in a transaction that was subsequently rolled back can be skipped.
For numeric columns in database tables, a sequence generates a serial list of unique numbers. Sequences make application programming easier by producing unique integer values for each row of a single table or several tables automatically.
Assume that two users are putting new employee entries into the EMP database at the same time. Neither user has to wait for the other to enter the next available employee number when utilizing a sequence to generate unique employee numbers for the EMPNO column. The sequence creates the correct values for each user automatically.
Tables are unrelated to sequence numbers, so the same sequence can be used for one or multiple tables. A sequence can be accessed by several people to generate actual sequence numbers once it is created.
A sequence is a set of integers, such as 1, 2, 3, and so on, that are generated and supported by some database systems in order to produce unique values on demand.
● A sequence is a schema-bound user-defined object that generates a list of numeric values.
● Many databases employ sequences because many applications need that each row in a table include a unique value, and sequences give an easy way to do so.
● The sequence of numeric numbers is generated at defined intervals in ascending or descending order, and it can be adjusted to resume when max value is exceeded.
Syntax
CREATE SEQUENCE sequence_name
START WITH initial_value
INCREMENT BY increment_value
MINVALUE minimum value
MAXVALUE maximum value
CYCLE|NOCYCLE ;
Sequence_name: Name of the sequence.
Initial_value: starting value from where the sequence starts.
Initial_value should be greater than or equal
To minimum value and less than equal to maximum value.
Increment_value: Value by which sequence will increment itself.
Increment_value can be positive or negative.
Minimum_value: Minimum value of the sequence.
Maximum_value: Maximum value of the sequence.
Cycle: When sequence reaches its set_limit
It starts from the beginning.
Nocycle: An exception will be thrown
If the sequence exceeds its max_value.
Example
Make a table called students, with the columns id and name.
CREATE TABLE students
(
ID number(10),
NAME char(20)
);
Insert values into the table now.
INSERT into students VALUES(sequence_1.nextval,'Ramesh');
INSERT into students VALUES(sequence_1.nextval,'Suresh');
Where sequence_1.nextval will insert id’s in id column in a sequence as defined in sequence_1.
Output
______________________
| ID | NAME |
------------------------
| 1 | Ramesh |
| 2 | Suresh |
----------------------
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create a view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
Mysql> create database set1;
Query OK, 1 row affected (0.00 sec)
Mysql> use set1;
Database changed
CREATING FIRST TABLE:
Mysql> create table A (x int (2), y varchar(2));
Query OK, 0 rows affected (0.19 sec)
Mysql> select * from A;
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
4 rows in set (0.00 sec)
CREATING SECOND TABLE:
Mysql> create table B (x int (2), y varchar(2));
Query OK, 0 rows affected (0.22 sec)
Mysql> select * from B;
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
2 rows in set (0.00 sec)
● INTERSECTION OPERATOR:
Mysql> select A.x,A.y from A join B using (x,y);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
Mysql> select * from A where (x,y) in (select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
2 rows in set (0.00 sec)
● UNION OPERATOR:
Mysql> select * from A union (select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
4 rows in set (0.00 sec)
Mysql> select * from A union all(select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 1 | a |
| 3 | c |
+------+------+
6 rows in set (0.00 sec)
● DIFFERENCE OPERATOR:
Mysql> select * from A where not exists (select * from B where A.x =B.x and A.y=B.y);
+------+------+
| x | y |
+------+------+
| 2 | b |
| 4 | d |
+------+------+
2 rows in set (0.11 sec)
● SYMMETRIC DIFFERENCE OPERATOR:
Mysql> (select * from A where not exists (select * from B where A.x =B.x and A.y=B.y))
Union( select * from B where not exists (select * from A where A.x =B.x and A.y=B.y));
+------+------+
| x | y |
+------+------+
| 2 | b |
| 4 | d |
+------+------+
Keywords that describe a relationship between two expressions are called predicates. A predicate is a logical condition that is applied to table rows. The SQL language adds a third value to the conventional logical conditions with two values (true, false) (unknown). In current query statements, SQL Predicates are located at the end of clauses, functions, and SQL expressions. So let's look at a real-world application of predicates in SQL Server 2012. The SQL Server Management Studio was used to create the example on SQL Server 2012.
The following predicates are supported by the Transact-SQL language:
● In Operator
● Exists function
● Between Operator
● Like Operator
● All and any Operator
IN operator
The IN operator allows you to specify two or more expressions to use in a query search. If the value of the corresponding column equals one of the phrases indicated by the IN predicate, the condition is true.
Exists function
The exists function takes a subquery as an input and returns true if the subquery produces one or more rows, false otherwise.
The EXISTS operator operates on a subquery and returns either TRUE or FALSE as a Boolean value.
● If the subquery produces at least one row, it returns TRUE.
● If the subquery returns no rows, it returns FALSE.
Between operator
The BETWEEN operator gives a range that sets the qualifying values' bottom and upper bounds. This operator combines the and and operators. A range of values larger than or equal to 5000 and less than or equal to 20000 has been chosen as the data. Numeric, text, and date data types can all be used with the Between operator.
LIKE operator
LIKE is a comparison operator that compares column values to a pattern. Regular characters must match the characters supplied in the character string exactly during pattern matching. Any character or date data type can be used in the column. Wildcard characters are characters that can be used anywhere in the pattern. I utilized four different forms of wildcards:
● Percent sign (%): It is used to represent or search any string of zero or more characters.
● Underscore (_): It is used to represent or search a single character.
● Bracket ([]): It is used to represent or search any single character within the specified range.
● Caret (^): It is used to represent or search any single character not within the specified range.
ANY and ALL operator
Comparison operators are always used in conjunction with the operators ANY and ALL.
ANY operator
Both operators have the same general syntax: column operator[ ANY | ALL ] query.
A comparison operator is represented by Operator.
If the result of an inner query has at least one row that meets the comparison, the any operator evaluates to true.
ALL operator
If the assessment of a table column in an inner query returns all values of the column, the ALL Operator evaluates to true.
Comparison predicate
The following is the syntax for comparison predicates:
Expression_1 comparison_operator expression_2
Expression2 can be a subquery in a comparison predicate. The comparison predicate evaluates to false if expression2 is a subquery that returns no rows. See Subqueries in the WHERE Clause for more information on subqueries. See Comparison Operators for additional information on comparison operators.
Pattern matching predicate
Pattern-matching predicates (the LIKE family) are used to find a specific pattern in text, an expression, or a column. The following are some of the predicates:
● LIKE
● BEGINNING, ENDING, CONTAINING
The type of predicate to utilize is determined by the pattern's complexity. The LIKE family of predicates all have the same SQL syntax, work with the same data types, and can control case sensitivity when matching.
Pattern matching is performed by the LIKE family of predicates for character data types (char, varchar) and Unicode data types (nchar, nvarchar).
The LIKE predicate family has the following syntax:
Expression [NOT] [LIKE|BEGINNING|CONTAINING|ENDING] pattern
[WITH CASE | WITHOUT CASE]
[ESCAPE escape_character]
Where
Expression
Is a string expression or a column name.
Pattern
The pattern to be matched is specified here. The pattern is usually a string literal, but it can also be a string expression of any length.
The patterns that are supported are determined by the predicate that is utilized.
WITH CASE | WITHOUT CASE
Indicates whether the pattern's case should be matched. The ESCAPE clause can be used before, after, or instead of this option.
If no collation type is supplied, the expression's collation type is utilized, which is usually WITH CASE.
ESCAPE escape_character
Specifies the character to use to escape another character or enable the special meaning of a character in a pattern.
Joins
To get data from various tables, SQL JOINS are needed. When two or more tables are listed in a SQL statement, a SQL JOIN is done.
SQL joins can be divided into four categories:
● SQL INNER JOIN (sometimes called simple join)
● SQL LEFT OUTER JOIN (sometimes called LEFT JOIN)
● SQL RIGHT OUTER JOIN (sometimes called RIGHT JOIN)
● SQL FULL OUTER JOIN (sometimes called FULL JOIN)
INNER JOIN
As long as the condition is met, the INNER JOIN keyword selects all rows from both tables. This keyword will generate a result-set by combining all rows from both tables that satisfy the requirement, i.e. the common field's value will be the same.
Syntax
SELECT columns
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
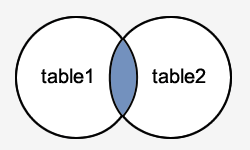
Fig 2: Inner join
LEFT OUTER JOIN
This join retrieves all rows from the table on the left side of the join, as well as matching rows from the table on the right. The result-set will include null for the rows for which there is no matching row on the right side. LEFT OUTER JOIN is another name for LEFT JOIN.
Syntax
SELECT columns
FROM table1
LEFT [OUTER] JOIN table2
ON table1.column = table2.column;
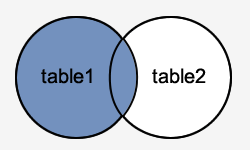
Fig 3: Left outer join
RIGHT OUTER JOIN
The RIGHT JOIN function is analogous to the LEFT JOIN function. This join retrieves all rows from the table on the right side of the join, as well as matching rows from the table on the left. The result-set will include null for the rows for which there is no matching row on the left side. RIGHT OUTER JOIN is another name for RIGHT JOIN.
Syntax
SELECT columns
FROM table1
RIGHT [OUTER] JOIN table2
ON table1.column = table2.column;
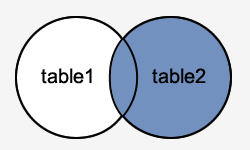
Fig 4: Right outer join
FULL OUTER JOIN
The result-set of FULL JOIN is created by combining the results of both LEFT JOIN and RIGHT JOIN. All of the rows from both tables will be included in the result-set. The result-set will contain NULL values for the rows for which there is no match.
Syntax
SELECT columns
FROM table1
FULL [OUTER] JOIN table2
ON table1.column = table2.column;
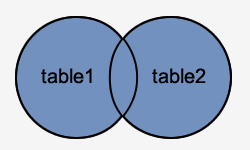
Fig 5: Full outer join
- For set membership, we employ the in and not in operations.
Select distinct cname
From borrower
Where cname in
(select cname from account
Where bname=SFU'')
2. It's worth noting that the identical query can be written in SQL in a variety of ways.
3. We can also test for many attributes at the same time:
Select distinct cname
From borrower, loan
Where borrower.loan# = loan.loan#
And bname=SFU''
And (bname, cname) in
(select bname, cname
From account, depositor where depositor.account# = account.account#)
In yet another manner, this locates all consumers with a loan and an account at the SFU branch.
4. We can use the not in operation field to find all clients that have a loan but no account.
In the from clause, tuple variables are described using the use of the Only as a clause.
Find the names of your customers and their loan numbers for all Customers at a certain branch have a deposit.
Select customer-name, T.loan-number, S.amount
From borrower as T, loan as S
Where T.loan-number = S.loan-number
Find the names of all branches with larger assets than those of The branch is in mumbai.
Select distinct T.branch-name
From branch as T, branch as S
Where T.assets > S.assets and S.branch-city = ‘mumbai’
Find all branches with greater assets than those branches It's situated in mumbai.
Select distinct T.branch-name
From branch as T, branch as S
Where T.assets > S.assets and S.branch-city = ‘mumbai’
Query the same with > any clause
Select branch-name
From branch
Where assets > some
(select assets
From branch
Where branch-city = ‘mumbai’)
SQL provides the user with some control over the order of the tuples in a relationship. The order by clause causes the tuples in the result of a query to appear in sorted order. To list in alphabetic order all instructors in the Physics department, we write :
Select name
From instructor
Where dept_name = ’Physics’
Order by name;
By default, the order by clause lists items in ascending order. To specify the
Sort order, we may specify desc for descending order or asc for ascending orderFurthermore, ordering can be performed on multiple attributes. Suppose that we wish to list the entire instructor relation in descending order of salary. If several instructors have the same salary, we order them in ascending order by name. We express this query in SQL as follows :
Select *
From instructor
Order by salary desc, name asc;
Key takeaway:
- SQL provides the user with some control over the order of the tuples in a relationship.
- To specify the sort order, we may specify desc for descending order or asc for ascending order.
The data that you need is not always stored in the tables. However, you can get it by
Performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from the orderdetails table because the orderdetails table stores only the quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Sql contains several built-in functions for working with data, which are divided into two groups and then further into seven functions under each category. The following are the categories:
- Aggregate function
These functions are used to perform operations on the column's values and return a single value.
● AVG()
● COUNT()
● FIRST()
● LAST()
● MAX()
● MIN()
● SUM()
2. Scalar function
These functions, like the others, are based on user input and return a single value.
● UCASE()
● LCASE()
● MID()
● LEN()
● ROUND()
● NOW()
● FORMAT()
Student - table
ID | NAME | MARKS | AGE |
1 | Harsh | 90 | 19 |
2 | Suresh | 50 | 20 |
3 | Pratik | 80 | 19 |
4 | Dhanraj | 95 | 21 |
5 | Ram | 85 | 18 |
Aggregate function
AVG() - After calculating from values in a numeric column, it returns the average value.
Syntax
SELECT AVG(column_name) FROM table_name;
Queries -
- Calculating students' average grades.
SELECT AVG(MARKS) AS AvgMarks FROM Students;
Output
AvgMarks
80
2. Calculating the average student age.
SELECT AVG(AGE) AS AvgAge FROM Students;
Output
AvgAge
19.4
COUNT() - It's used to count how many rows a SELECT command returns. It isn't compatible with MS ACCESS.
Syntax
SELECT COUNT(column_name) FROM table_name;
Queries
- The total number of students is calculated.
SELECT COUNT(*) AS NumStudents FROM Students;
Output:
NumStudents
5
2. Counting the number of students who are of a specific age.
SELECT COUNT(DISTINCT AGE) AS NumStudents FROM Students;
Output
NumStudents
4
FIRST() - The FIRST() function returns the selected column's first value.
Syntax
SELECT FIRST(column_name) FROM table_name;
Queries
- Taking the first student's marks from the Students table.
SELECT FIRST(MARKS) AS MarksFirst FROM Students;
Output:
MarksFirst
90
2. The first student's age is retrieved from the Students table.
SELECT FIRST(AGE) AS AgeFirst FROM Students;
Output:
AgeFirst
19
LAST() - The LAST() function returns the chosen column's last value. It can only be used in MS ACCESS.
Syntax
SELECT LAST(column_name) FROM table_name;
Queries
- Taking the final student's grades from the Students table.
SELECT LAST(MARKS) AS MarksLast FROM Students;
Output:
MarksLast
82
2. Obtaining the age of the most recent student from the Students table.
SELECT LAST(AGE) AS AgeLast FROM Students;
Output:
AgeLast
18
MAX() - The MAX() method returns the selected column's maximum value.
Syntax
SELECT MAX(column_name) FROM table_name;
Queries
- Obtaining the highest possible grade among students from the Students table.
SELECT MAX(MARKS) AS MaxMarks FROM Students;
Output:
MaxMarks
95
2. The maximum age among students is retrieved from the Students table.
SELECT MAX(AGE) AS MaxAge FROM Students;
Output:
MaxAge
21
MIN() - The MIN() method returns the selected column's minimal value.
Syntax
SELECT MIN(column_name) FROM table_name;
Queries
- Obtaining the lowest possible grade among students from the Students table.
SELECT MIN(MARKS) AS MinMarks FROM Students;
Output:
MinMarks
50
2. Obtaining the student's minimum age from the Students table.
SELECT MIN(AGE) AS MinAge FROM Students;
Output:
MinAge
18
SUM() - SUM() returns the total of all the values in the chosen column.
Syntax
SELECT SUM(column_name) FROM table_name;
Queries
- Obtaining the overall score of all students from the Students table.
SELECT SUM(MARKS) AS TotalMarks FROM Students;
Output:
TotalMarks
400
2. Obtaining the total age of all students from the Students table.
SELECT SUM(AGE) AS TotalAge FROM Students;
Output:
TotalAge
97
Scalar function
UCASE() - It transforms a field's value to uppercase.
Syntax
SELECT UCASE(column_name) FROM table_name;
Queries
- Students' names are being converted from lowercase to uppercase in the table Students.
SELECT UCASE(NAME) FROM Students;
Output:
NAME
HARSH
SURESH
PRATIK
DHANRAJ
RAM
LCASE() - It changes a field's value to lowercase.
Syntax
SELECT LCASE(column_name) FROM table_name;
Queries
- Students' names from the table Students are being converted to lowercase.
SELECT LCASE(NAME) FROM Students;
Output:
NAME
Harsh
Suresh
Pratik
Dhanraj
Ram
MID() - The MID() function takes text from a text field and extracts it.
Syntax
SELECT MID(column_name,start,length) AS some_name FROM table_name;
Specifying length is optional here, and start signifies start position ( starting from 1 )
Queries
- Getting the first four letters of student names from the Students table.
SELECT MID(NAME,1,4) FROM Students;
Output
NAME
HARS
SURE
PRAT
DHAN
RAM
LEN() - The LEN() function returns the length of a text field's value.
Syntax
SELECT LENGTH(column_name) FROM table_name;
Queries
- Getting the length of student names from the Students table.
Syntax
SELECT LENGTH(NAME) FROM Students;
Output:
NAME
5
6
6
7
3
ROUND() - The ROUND() function rounds a numeric field to the supplied number of decimals.
NOTE: For mathematical operations, several database systems have followed the IEEE 754 standard, which states that any numeric.5 is rounded to the next even integer, i.e., 5.5 and 6.5 are both rounded to 6.
Syntax
SELECT ROUND(column_name,decimals) FROM table_name;
Decimals- number of decimals to be fetched.
Queries
- Obtaining the highest possible grade among students from the Students table.
SELECT ROUND(MARKS,0) FROM table_name;
Output:
MARKS
90
50
80
95
85
FORMAT() - The FORMAT() function is used to format the appearance of a field.
Syntax
SELECT FORMAT(column_name,format) FROM table_name;
Queries
- The current date is formatted as ‘YYYY-MM-DD'.
Syntax
SELECT NAME, FORMAT(Now(),'YYYY-MM-DD') AS Date FROM Students;
Output:
NAME Date
HARSH 2017-01-13
SURESH 2017-01-13
PRATIK 2017-01-13
DHANRAJ 2017-01-13
RAM 2017-01-13
A MySQL subquery is a query nested within another query such as select, insert, update or delete. In addition, a MySQL subquery can be nested inside another subquery.
A MySQL subquery is called an inner query while the query that contains the subquery is called an outer query. A subquery can be used anywhere that expression is used and must be closed in parentheses.
A subquery is also known as a nested query. It is a SELECT query embedded within the WHERE or HAVING clause of another SQL query. The data returned by the subquery is used by the outer statement in the same way a literal value would be used.
Subqueries provide an easy and efficient way to handle the queries that depend on the results from another query. They are almost identical to the normal SELECT statements, but there are few restrictions.
The most important ones are listed below:
● A subquery must always appear within parentheses.
● A subquery must return only one column. This means you cannot use SELECT * in a subquery unless the table you are referring has only one column. You may use a subquery that returns multiple columns, if the purpose is row comparison.
● You can only use subqueries that return more than one row with multiple value operators, such as the IN or NOT IN operator.
● A subquery cannot be a UNION. Only a single SELECT statement is allowed.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who had placed order worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- MySQL subquery can be nested inside another subquery.
- A subquery is also known as a nested query.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
In PL/SQL, a Procedure is a subprogram unit made up of a collection of PL/SQL statements that can be invoked by name. Each procedure in PL/SQL has its own distinct name that can be used to refer to and invoke it. The Oracle database stores this subprogram unit as a database object.
A subprogram is nothing more than a process that must be manually constructed according to the requirements. They will be saved as database objects once they have been generated.
In PL/SQL, the following are the features of the Procedure subprogram unit:
● Procedures are individual software blocks that can be saved in a database.
● To execute the PL/SQL statements, call these PL/SQL procedures by referring to their names.
● In PL/SQL, it's mostly used to run a process.
● It can be defined and nested inside other blocks or packages, or it can have nested blocks.
● It consists of three parts: declaration (optional), execution, and exception handling (optional).
● The values can be supplied into or retrieved from an Oracle process using parameters.
● The calling statement should include these parameters.
● In SQL, a procedure can have a RETURN statement to return control to the caller block, but the RETURN statement cannot return any values.
● SELECT statements cannot directly invoke procedures. They can be accessed via the EXEC keyword or from another block.
Syntax
CREATE OR REPLACE PROCEDURE
<procedure_name>
(
<parameterl IN/OUT <datatype>
..
.
)
[ IS | AS ]
<declaration_part>
BEGIN
<execution part>
EXCEPTION
<exception handling part>
END;
● Construct PROCEDURE tells the compiler to create a new Oracle procedure. The keyword 'OR REPLACE' tells the compiler to replace any existing procedures with this one.
● The name of the procedure should be unique.
● When a stored procedure in Oracle is nested inside other blocks, the keyword 'IS' will be used. 'AS' will be used if the procedure is solo. Both have the same meaning aside from the coding standard.
Functions
Functions is a PL/SQL subprogram that runs on its own. Functions, like PL/SQL procedures, have a unique name by which they can be identified. These are saved as database objects in PL/SQL. Some of the qualities of functions are listed below.
● Functions are a type of standalone block that is mostly used to do calculations.
● The value is returned using the RETURN keyword, and the datatype is defined at the time of creation.
● Return is required in functions since they must either return a value or raise an exception.
● Functions that do not require DML statements can be called directly from SELECT queries, whereas functions that require DML operations can only be invoked from other PL/SQL blocks.
● It can be defined and nested inside other blocks or packages, or it can have nested blocks.
● It consists of three parts: declaration (optional), execution, and exception handling (optional).
● The parameters can be used to pass values into the function or to retrieve values from the process.
● The calling statement should include these parameters.
● In addition to utilizing RETURN, a PLSQL function can return the value using OUT parameters.
● Because it always returns the value, it is always used in conjunction with the assignment operator to populate the variables in the calling statement.
Syntax
CREATE OR REPLACE FUNCTION
<procedure_name>
(
<parameterl IN/OUT <datatype>
)
RETURN <datatype>
[ IS | AS ]
<declaration_part>
BEGIN
<execution part>
EXCEPTION
<exception handling part>
END;
● The command CREATE FUNCTION tells the compiler to construct a new function. The keyword 'OR REPLACE' tells the compiler to replace any existing functions with the new one.
● The name of the function should be unique.
● It's important to mention the RETURN datatype.
● When the method is nested inside other blocks, the keyword 'IS' will be utilized. 'AS' will be used if the procedure is solo. Both have the same meaning aside from the coding standard.
Oracle produces a memory space called the context area when a SQL statement is processed. The context region is shown by a cursor. It includes all of the data required to process the statement. Cursor in PL/SQL is in charge of the context area. A cursor keeps track of the rows of data accessed by a select statement.
A cursor is a software that fetches and processes each row returned by a SQL statement one by one. Cursors come in two varieties:
● Implicit Cursors
● Explicit Cursors
Implicit cursors
When a SQL statement is executed and there is no explicit cursor for the statement, Oracle automatically creates implicit cursors. Programmers have no control over implicit cursors or the data they contain.
When a DML statement (INSERT, UPDATE, or DELETE) is issued, it is accompanied by an implicit cursor. The cursor holds the data that needs to be inserted for INSERT operations. The cursor identifies the rows that will be affected by UPDATE and DELETE actions.
The most recent implicit cursor is known as the SQL cursor in PL/SQL, and it always has attributes like %FOUND, % ISOPEN, %NOTFOUND, and %ROWCOUNT. For use with the FORALL statement, the SQL cursor has two additional attributes: %BULK ROWCOUNT and % BULK EXCEPTIONS. The most commonly used properties are described in the table below.
Attribute | Description |
%FOUND | If DML actions like INSERT, DELETE, and UPDATE change at least one row or more rows, or if a SELECT INTO statement returned one or more rows, the return value is TRUE. Otherwise, FALSE is returned. |
%NOTFOUND | If DML statements like INSERT, DELETE, and UPDATE have no effect on any rows, or if a SELECT INTO statement returns no rows, it returns TRUE. Otherwise, FALSE is returned. It's the polar opposite of % FOUND. |
%ISOPEN | Because the SQL cursor is automatically closed after processing its related SQL statements, it always returns FALSE for implicit cursors.
|
%ROWCOUNT | It calculates the number of rows affected by DML statements such as INSERT, DELETE, and UPDATE, as well as the number of rows returned by a SELECT INTO command. |
Example
Create a customers table with the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 20000 |
2 | Suresh | 22 | Kanpur | 22000 |
3 | Mahesh | 24 | Ghaziabad | 24000 |
4 | Chandan | 25 | Noida | 26000 |
5 | Alex | 21 | Paris | 28000 |
6 | Sunita | 20 | Delhi | 30000 |
To update the table and boost each customer's salary by 5000, run the following software. The number of rows affected is determined using the SQL % ROWCOUNT attribute:
Create procedure:
DECLARE
Total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 5000;
IF sql%notfound THEN
Dbms_output.put_line('no customers updated');
ELSIF sql%found THEN
Total_rows := sql%rowcount;
Dbms_output.put_line( total_rows || ' customers updated ');
END IF;
END;
/
Output:
6 customers updated
PL/SQL procedure successfully completed.
If you look at the records in the customer table now, you'll notice that the rows have been changed.
Select * from customers;
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 25000 |
2 | Suresh | 22 | Kanpur | 27000 |
3 | Mahesh | 24 | Ghaziabad | 29000 |
4 | Chandan | 25 | Noida | 31000 |
5 | Alex | 21 | Paris | 33000 |
6 | Sunita | 20 | Delhi | 35000 |
Explicit cursors
Explicit cursors are cursors that have been programmed to give the user more control over the context area. In the PL/SQL Block's declaration section, an explicit cursor should be defined. It's based on a SELECT statement that returns multiple rows.
Creating an explicit cursor has the following syntax.
CURSOR cursor_name IS select_statement;
The steps for working with an explicit cursor are as follows:
● Declaring the cursor for memory initialization.
● Opening the cursor for allocating the memory.
● Fetching the cursor for retrieving the data.
● Closing the cursor to release the allocated memory.
Declaring the cursors
Declaring the cursor gives it a name and the SELECT statement that goes with it. For instance,
CURSOR c_customers IS
SELECT id, name, address FROM customers;
Opening the cursors
The cursor's memory is allocated when it is opened, and it is ready to receive the rows produced by the SQL statement. For instance, let's open the above-mentioned cursor as follows:
OPEN c_customers;
Fetching the cursors
The cursor is retrieved by accessing one row at a time. For instance, we can get rows from the above-opened cursor by doing the following:
FETCH c_customers INTO c_id, c_name, c_addr;
Closing the cursors
The allocated memory is released when the cursor is closed. For example, the above-opened cursor will be closed as follows:
CLOSE c_customers;
Example
Programmers define explicit cursors to have additional control over the context area. It's defined in the PL/SQL block's declaration section. It's based on a SELECT statement that returns multiple rows.
Let's look at an example of how to use explicit cursor. In this example, we'll use the CUSTOMERS table, which has already been established.
Create a customers table with the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 20000 |
2 | Suresh | 22 | Kanpur | 22000 |
3 | Mahesh | 24 | Ghaziabad | 24000 |
4 | Chandan | 25 | Noida | 26000 |
5 | Alex | 21 | Paris | 28000 |
6 | Sunita | 20 | Delhi | 30000 |
Create procedure:
To get the customer's name and address, run the following software.
DECLARE
c_id customers.id%type;
c_name customers.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
Dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/
Output
1 Ramesh Allahabad
2 Suresh Kanpur
3 Mahesh Ghaziabad
4 Chandan Noida
5 Alex Paris
6 Sunita Delhi
PL/SQL procedure successfully completed.
When a defined event occurs, the Oracle engine immediately calls the trigger. Triggers are stored in databases and are called repeatedly when certain conditions are met.
Triggers are stored programs that are executed or fired automatically when a certain event happens.
Triggers can be written to respond to any of the events listed below.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE).
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
Triggers can be set on the table, view, schema, or database connected with the event.
Advantages
The following are some of the benefits of Triggers:
Trigger automatically creates some derived column values.
Referential integrity is enforced.
Information on table access is logged and stored in an event log.
Auditing.
Tables are replicated in a synchronous manner.
Putting in place security authorizations.
Preventing transactions that aren't valid.
Creating a trigger
Syntax for creating trigger:
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;
Where,
CREATE [OR REPLACE] TRIGGER trigger_name: With the trigger name, it creates or replaces an existing trigger.
{BEFORE | AFTER | INSTEAD OF} : This determines when the trigger will be activated.
The INSTEAD OF clause is used to make a view trigger.
{INSERT [OR] | UPDATE [OR] | DELETE}: The DML operation is specified here.
[OF col_name]: This is the name of the column that will be modified.
[ON table_name]: The name of the table linked with the trigger is specified here.
[REFERENCING OLD AS o NEW AS n]: This allows you to refer to new and old values for INSERT, UPDATE, and DELETE DML statements.
[FOR EACH ROW]: This is a row-level trigger, which means it will be executed for each row that is affected. Otherwise, the trigger, which is known as a table level trigger, will only activate once when the SQL query is executed.
WHEN (condition): This provides a condition for rows for which the trigger would fire. This clause is valid only for row level triggers.
Example
We'll begin by looking at the CUSTOMERS table -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+
The following application sets a row-level trigger for the customers table that fires when the CUSTOMERS table is INSERTED, UPDATED, or DELETED. This trigger will show the difference in salary between the old and new values.
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
Sal_diff number;
BEGIN
Sal_diff := :NEW.salary - :OLD.salary;
Dbms_output.put_line('Old salary: ' || :OLD.salary);
Dbms_output.put_line('New salary: ' || :NEW.salary);
Dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/
When the preceding code is run at the SQL prompt, the following is the result:
Trigger created.
The following considerations must be made in this case:
● For table-level triggers, OLD and NEW references are not available; however, record-level triggers can use them.
● If you want to query the table within the same trigger, use the AFTER keyword, because triggers can only query or alter the table after the original modifications have been implemented and the table has returned to a consistent state.
● The above trigger will fire before every DELETE, INSERT, or UPDATE action on the table, but you may create your trigger to fire before a single or many operations, such as BEFORE DELETE, which will fire whenever a record is deleted on the table using the DELETE operation.
Triggering a Trigger
Let's use the CUSTOMERS table to conduct some DML operations. Here's an example of an INSERT statement that will add a new record to the table:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Kriti', 22, 'HP', 7500.00 );
When a record in the CUSTOMERS database is generated, the above create trigger, display salary changes, is triggered, and the following result is displayed:
Old salary:
New salary: 7500
Salary difference:
Because this is a new record, the previous salary is unavailable, hence the result above is nil. Let's do another DML transaction on the CUSTOMERS table now. The UPDATE statement will update a table record that already exists.
UPDATE customers
SET salary = salary + 500
WHERE id = 2;
When a record in the CUSTOMERS database is updated, the aforementioned create trigger, display salary changes, is triggered, and the following result is displayed:
Old salary: 1500
New salary: 2000
Salary difference: 500
When there are two (or more) tables in a constraint, the table constraint technique can be difficult to use, and the outcomes may not be as expected. To deal with this, SQL allows you to create assertions, which are limitations that aren't tied to a single table. Furthermore, an assertion statement should guarantee that a specific condition will always be present in the database. When changes are made to the corresponding table, the DBMS always checks the assertion.
Syntax
CREATE ASSERTION [ assertion_name ]
CHECK ( [ condition ] );
Example –
CREATE TABLE sailors (sid int,sname varchar(20), rating int,primary key(sid),
CHECK(rating >= 1 AND rating <=10)
CHECK((select count(s.sid) from sailors s) + (select count(b.bid)from boa
We're enforcing the CHECK constraint that the number of boats and sailors should be less than 100 in the example above. As a result, we can CHECK restrictions on two tablets at the same time.
A privilege is the ability to run a specific SQL statement or access another user's object. The following are some instances of privileges:
● the ability to access the database (create a session).
● the ability to make a table
● the ability to choose rows from a table created by another individual
● the ability to run a stored procedure created by another user
You give users privileges so that they may complete tasks that are necessary for their jobs. You should only give a privilege to a user who absolutely needs it to complete critical tasks. Excessive provision of needless rights might result in security breaches. A privilege can be granted to a user in two ways:
● Users can be given specific privileges. For example, you can specifically grant the user SCOTT the ability to insert records into the EMP table.
● You can also assign privileges to a role (a defined set of privileges) and then assign the role to one or more users. For example, you can give the role CLERK the ability to select, insert, edit, and delete data from the EMP table, which you can then provide to the users SCOTT and BRIAN.
Because roles make managing rights easier and more efficient, you should usually provide privileges to roles rather than specific users.
Privileges are divided into two categories:
● System privileges
● Object privileges
System privileges
A system privilege is the ability to perform a certain action or a specific action on a specific type of object. System privileges, for example, include the ability to create tablespaces and delete rows from any table in a database. There are approximately 60 different system privileges to choose from.
● Granting and Revoking System Privileges
Users and roles can have system privileges granted or revoked. If roles are given system privileges, the benefits of roles can be used to manage system privileges (for example, roles permit privileges to be made selectively available).
Users and roles can be granted or revoked system privileges using one of the following methods:
● Server Manager's Users or Roles directories are good places to start.
● GRANT and REVOKE are SQL commands.
Note: Typically, system rights should only be granted to administrative workers and application developers, as end users do not require the accompanying skills.
Object privileges
A privilege or right to do a certain action on a specific table, view, sequence, procedure, function, or package is known as an object privilege. The privilege to delete rows from the table DEPT, for example, is an object privilege. There are various types of object rights depending on the type of object.
Some schema objects (such as clusters, indexes, triggers, and database connections) don't have associated object privileges; instead, system privileges are used to regulate their use. To change a cluster, for example, a user must own it or have the ALTER ANY CLUSTER system privilege.
Whether accessing the underlying object by name or via a synonym, the object privileges allowed for a table, view, sequence, procedure, function, or package apply. Consider the table JWARD.EMP, which has a synonym named JWARD.EMPLOYEE. JWARD makes the following announcement:
GRANT SELECT ON emp TO swilliams;
SWILLIAMS can query JWARD.EMP by using the synonym JWARD.EMPLOYEE or by addressing the table by name:
SELECT * FROM jward.emp;
SELECT * FROM jward.employee;
When you give a synonym for an object privileges on a table, view, sequence, procedure, function, or package, the result is the same as if no synonym was given. For instance, if JWARD wished to provide SWILLIAMS the SELECT privilege for the EMP table, he may use one of the following statements.
GRANT SELECT ON emp TO swilliams;
GRANT SELECT ON employee TO swilliams;
Roles
Users or other roles are given roles, which are designated collections of related privileges. Roles were created to make managing end-user system and object privileges easier. Application developers, on the other hand, should not employ roles because the privileges to access objects within stored programmatic constructs must be granted explicitly. For additional information on procedure limits, see the section "Data Definition Language Statements and Roles" [*].
These aspects of roles make privilege management in a database easier:
● Administration with fewer privileges Rather than granting the same set of privileges to several users, you can assign the privileges for a group of related users to a role, and then each member of the group simply needs to be granted the role.
● Privilege management that changes over time. If a group's privileges need to be changed, only the role's privileges need to be changed. The security domains of all users who have been awarded the group's role instantly reflect the role's changes.
● Privileges are available on a case-by-case basis. You can enable or disable a user's roles on a per-user basis. This gives you complete control over a user's privileges in any situation.
● Awareness of the application Because the data dictionary keeps track of which roles exist, database applications can query the dictionary and automatically enable (or disable) specific roles when a user tries to run the application with a specific username.
Common uses for Roles
In general, you construct a role for one of two purposes: managing database application rights or managing user group capabilities. The two responsibilities are described in the figure and the sections that follow.
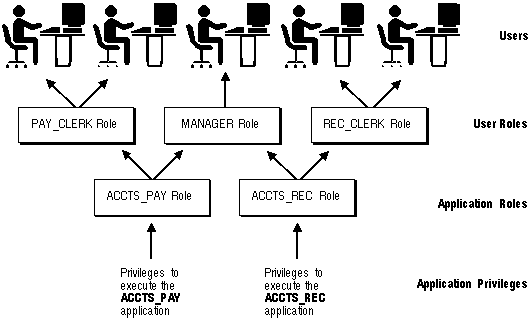
Fig 6: Common uses for roles
Application Roles
You provide an application role with all the permissions it needs to execute a database application. Then you can assign an application role to other roles or users. An application can have multiple roles, each with its own set of rights that grant more or less data access when using the app.
User Roles
You create a user role for a group of database users with common privilege requirements. You manage user privileges by granting application roles and privileges to the user role and then granting the user role to appropriate users.
Mechanisms of Roles
The following are some of the features of database roles:
● System or object privileges can be granted to a role.
● Other roles can be assigned to a position. A role, on the other hand, cannot be granted to itself or in a circular manner (for example, role A cannot be granted to role B if role B has previously been granted to role A).
● Any database user can be assigned any role.
● Each role assigned to a user is either enabled or disabled at any one time. The privileges of all roles currently enabled for the user are included in the user's security domain. The privileges of any roles that are now disabled for the user are not included in the user's security domain.
● A user can expressly enable or disable an indirectly granted role (a role granted to a role). Enabling a position that incorporates other roles, on the other hand, automatically enables all indirectly granted roles of the directly provided role.
References:
- Silberschatz A., Korth H., Sudarshan S., "Database System Concepts", McGraw Hill Publishers, ISBN 0-07-120413-X, 6th edition
- Joy A. Kreibich, “Using SQLite”, O'REILLY, ISBN: 13:978-93-5110-934-1
- Ivan Bayross, “SQL, PL/SQL the Programming Language of Oracle”, BPB Publications ISBN: 9788176569644, 9788176569644
- Seema Acharya, “Demystifying NoSQL”, Wiley Publications, ISBN: 9788126579969




