Unit - 4
Database Transaction Management
Collection of operations that form a single logic unit of work is called as a transaction. It is viewed as a single database operation.
E.g., Money withdrawal from ATM.
This is one transaction consisting of operations like: -
i. Enter PIN.
Ii. Enter type of account.
Iii. Enter money, etc.
Database Operations: -
Transactions access data item by using two operations: -
Read(x) & write (x).
1. Read (x): - (Database to buffer).
It transfers data item X from the database to a local buffer belonging to the transaction that executes the Read operation.
2. Write(x): - (Buffer to Database)
IT transfers data item X from the local buffer to the transaction that execute write
Operation & data is written to the database.
E.g., Transfer $ 50 from account A to B.
T1: - Read(A);
A: = A-50;
Write(A);
T2: - Read (B);
B: = B + 50;
Write(B);
Transaction State
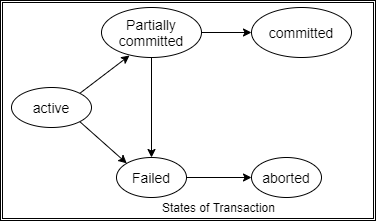
Fig 1: Transition state diagram
A transaction must be in one of the following status:
1. Active: -
It is the initial state the transaction stays in this state while it is executing.
2. Partially Committed: -
The transaction stays in this state after the final statement has been executed.
3. Failed: -
The transaction enters into failed state after active state/ partially committed state.
This is the state after the discovery that normal execution can no longer proceed.
4. Aborted: -
After failed state, the transaction must be rolled back & the database must be
Restored to its initial state.
5. Committed: -
The transaction enters in this state after successful completion.
Above figure shows the state diagram of a transaction. A transaction starts in the active state. When it finishes its final statement, it enters the partially committed state. When last statement of the actual output is written out in disk, the transaction enters the committed state.
A transaction enters the failed state after the system determines that transaction can no longer proceed with its normal execution. Such a transaction must be rolled back. Then, it enters the aborted state.
At this point, system has two options: -
i. Restart: -
It can restart the transaction if the transaction was aborted as a result of some
Hardware or software error that was created through internal logic of the transaction.
Ii. Kill: -
It can kill the program, if the transaction was aborted because of internal logical
Error that can be corrected only by rewriting the application program.
Key takeaway
- Collection of operations that form a single logic unit of work is called as a transaction.
- It is viewed as a single database operation.
- A transaction starts in the active state.
A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy,
Completeness, and data integrity.
● Atomicity
● Consistency
● Isolation
● Durability.
Atomicity: -
● A transaction is an atomic unit of processing.
● It is either performed in its entirely or not performed at all.
● It means either all operations are reflected in the database or none are.
● It is responsibility of the transaction recovery subsystem to ensure atomicity.
● If a transaction fails to complete for some reason, recovery technique must undo any effects of the transaction on the database.
Consistency: -
● A transaction is consistency preserving if its complete execution takes the database from one consistent state to other.
● It is responsibility of the programmer who writes database programs.
● Database programs should be written in such a way that, if database is in a consistent state before execution of transaction, it will be in a consistent state after execution of transaction.
Eg. Transaction is :- Transfer $50 from account A to account B.
If account A having amount $100 & account B having amount $ 200 initially then after execution of transaction, A must have $ 50 & B must have $ 250.
Isolation: -
● If multiple transactions execute concurrently, they should produce the result as if they are working serially.
● It is enforced by concurrency control subsystem.
● To avoid the problem of concurrent execution, transaction should be executed in isolation.
Durability: -
● The changes applied to the database, by a committed transaction must persist in a database.
● The changes must not be lost because of any failure.
● It is the responsibility of the recovery subsystem of the DBMS.
Key takeaway
- A transaction is an atomic unit of processing.
- To avoid the problem of concurrent execution, transaction should be executed in isolation.
- A transaction is consistency preserving if its complete execution takes the database from one consistent state to other.
A schedule S of n transactions T1, T2, Tn is an ordering of the operations of the
Transactions, subject to the constraint that, for each transaction Ti, appearing in S, th
Operations of Ti in they occur in original Ti. So, the execution of sequences which
Represents the chronological order in which instructions are executed in the system, are called schedules.
E.g.
T1 T2
Read(A)
A:= A+100;
Write(A);
Read(A)
A := A-200;
Write(A).
* Schedule S *
Schedule S is serial because T1 & T2 are executing serially, T2 followed by T1.
If initial value of A = 500, then after successful execution of T1 & T2, A should have value =400.
Now, consider above transactions T1 & T2 are running concurrently like: -
A = 500
T1 T2
Read(A)
Read(A)
(A=500) (A=500)
A: = A+100;
A: = A-200;
(A=600) (A=300)
Write(A); Write(A);
(A=600) (A=300)
*concurrent schedule S*
Here, instead of 400, schedule produces value of A=300. So, in this case database is in inconsistent state.
Conflict Operations: -
Two operations are said to be conflict if: -
i. They are from different transactions
Ii. They access same data item.
Iii. One of the operations is write operation.
Eg:
T1 T2
1. R(A)
2. W(A)
3. R(A)
4. W(A)
5. R(A)
6. R(B)
7.R(A)
8.W(B)
9. R(A)
Here, instructions: - 2 & 3, 4 & 5 ,6 & 8, 4& 9 are conflict instructions.
Instructions 8 & 9 are non-conflict because they are working on different data items.
Key takeaway
- A schedule is considered a sequential execution sequence of a transaction.
- There can be several transactions in a schedule, each containing a number of instructions/tasks.
In the Serial Schedule, a transaction is completely completed until another transaction begins to be executed. In other words, you might assume that a transaction does not start execution in the serial schedule until the currently running transaction is executed. A non-interleaved execution is also known as this form of transaction execution.
Take one example:
R here refers to the operation of reading and W to the operation of writing. In this case, the execution of transaction T2 does not start until the completion of transaction T1.
T1 T2
---- ----
R(A)
R(B)
W(A)
Commit
R(B)
R(A)
W(B)
Commit
Key takeaway
- A non-interleaved execution is also known as this form of transaction execution.
- In the Serial Schedule, a transaction is completely completed until another transaction begins to be executed.
A schedule that can be serialized often leaves the database in a consistent state. A serial schedule is often a serializable schedule since a transaction only begins after the other transaction has completed execution in the serial schedule. However, for serialization, a non-serial schedule needs to be tested.
A non-serial schedule of n transactions is known to be a serialized schedule, given that the serial schedule of n transactions is equal to that of n transactions. Only one transaction is executed at a time and the other begins when the already operating transaction is completed. A serial schedule does not allow choice.
A serializable schedule helps to maximize both the usage of resources and CPU throughput.
Types of serializability
There are 2 types of serializability:
Conflict serializability
If it can be converted into a serial schedule by exchanging non-conflicting operations, a schedule is called dispute serializable. If all conditions comply, two activities are said to be conflicting:
● They are part of numerous transactions.
● On the same data object, they run
● At least one of them is a writing procedure.
To understand this, let us see some examples:
Example
T1 T2
----- ------
R(A)
R(B)
R(A)
R(B)
W(B)
W(A)
We need to swap the R(A) operation of Transaction T2 with the W(A) operation of Transaction T1 to turn this schedule into a serial schedule. However, since they are competing operations, we cannot swap these two operations, so we can conclude that this given schedule is not Serializable to Conflict.
View serializability
If the view is equal to a serial schedule, a schedule is called view serializable (no overlapping transactions). A conflict schedule is a serializable view, but if blind writing is included in the serializability, the serializable view is not serializable conflict.
View equivalent
If they satisfy the following conditions, two timetables S1 and S2 are said to be considered equivalent:
- Initial Read
The initial reading of the two timetables must be the same. Suppose there are two S1 and S2 schedules. If a transaction T1 reads data item A in schedule S1, then in S2, transaction T1 can read A as well.
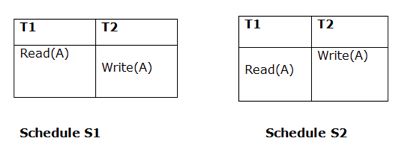
Fig 2: Two schedules (initial read)
The two schedules above are considered as similar since T1 performs the initial read operation in S1 and T1 also performs it in S2.
- Updated Read
If Ti reads A that is updated by Tj in schedule S1, then in S2 as well, Ti can read A that is updated by Tj.
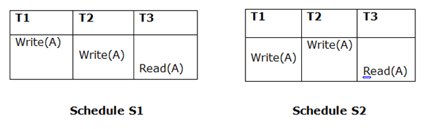
Fig 3: Two schedules(updated read)
The two schedules above are not considered equivalent since, in S1, T3 reads A updated by T2 and in S2, T3 reads A updated by T1.
2. Final Read
For the two schedules, the final writing must be the same. In Schedule S1, if a transaction T1 eventually updates A then in S2, T1 should also perform final writing operations.
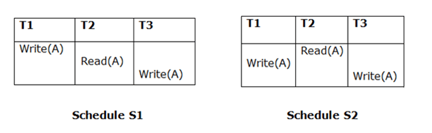
Fig 4: Two schedules(final read)
The view is identical to the above two schedules since T3 performs the final writing operation in S1 and T3 performs the final writing operation in S2.
Key takeaway
- If we are able to turn it into a serial schedule after swapping its non-conflicting activities, a schedule is called dispute serializable.
- View Serializability is a tool to assess whether or not a given schedule can be serialised as a view.
Cascaded aborts Recoverable and Non-recoverable Schedules
● Once a transaction T is committed, it should never be necessary to Roll back T.
● The schedules that theoretically meet this criterion are called recoverable schedules & those do not are called non-recoverable schedules.
● Recoverable schedule is one where, for each pair of transactions Ti & Tj, such that Tj reads a data item previously written by Ti, the commit operation of Ti appears before the commit operation of Tj.
E.g.
T1 T2
R(X)
W(X)
Commit;
R(X)
Commit
T2 reads the value of X, which has been written by T1. T1 commits & then T2. As per definition, commit of T1 must appear before commit of T2. So, the schedule is called as a recoverable schedule.
Cascading Rollback/Cascading Abort:
● In a recoverable schedule, no committed transaction ever needs to be rolled back.
● However, it is possible for a phenomenon known as cascading Rollback or cascading abort to occur, where an uncommitted transaction has to be rolled back because it read an item from a transaction that failed.
T1 T2 T3
R(X)
W(X)
R(X)
W(x)
R(X)
W(X)
*schedule S10*
● This is illustrated in schedule S10.
● T2 has to be rolled back in case of T1’s failure because it read the X, written by T1.
● Similarly, T3 has to be rolled back, because it read the value of X, written by T2.
Non-Recoverable Schedule:
T1 T2
R(A)
W(A)
R(X)
Commit
R(B)
● Here, T2 commits immediately after R(A).
● If after T2 commit, because of some reason suppose T1 fails before it commits.
● T1 must be restarted. As T2 reads the value of X, written by T1, T2 must be restarted to ensure the property of atomicity.
● But as T2 has committed, it is not possible to abort & restart.
● So, it is impossible to recover from the failure of T1.
So, the schedule is not recoverable i.e. T1 is non- recoverable schedule.
E.g.
T1 T2
r(x)
w(x)
r(X)
r(y)
w(x)
Commit;
Commit;
Schedule is non-recoverable because T2 reads X which is modified by T1. But T2 commits before T1 commits.
Key takeaway
- In a recoverable schedule, no committed transaction ever needs to be rolled back.
- It is necessary to commit transactions in order. There may be a Dirty Read issue and a Lost Update issue.
i. A lock is a variable associated with a data item which describes the status of the item with respect to possible operations that can be applied to it.
Ii. Generally, there is one lock for each data item in the database.
Iii. Locks are used as a means of synchronizing the access by concurrent transactions to the database items.
Locking Models: -
There are two models in which a data item may be locked: -
a. Shared (Read) Lock Mode &
b. Exclusive (write) Lock Mode
a. Shared-Lock Mode: -
● If a transaction Ti has obtained a shared mode lock on item Q, then Ti can read Q but cannot modify/write Q.
● Shared lock is also called as a Read-lock because other transactions are allowed to read the item.
● It is denoted by s.
Eg. T1 T2
Locks(A);
Locks(B);
T1 has locked A in shared mode & T2 also has locked B in shared lock mode.
b. Exclusive-Lock Mode: -
● If a transaction Ti has obtained a exclusive-lock mode on item Q, then Ti can read & write Q.
● Exclusive –lock is also called a write-lock because a single transaction exclusively holds the locks on the item
● It is denoted by X.
T1 T2
LockX(A)
LockX(B);
T1 has locked A in exclusive-mode & T2 has locked B in exclusive mode.
Lock-Compatibility Matrix: -
| S | X |
S | ✓ | X |
X | X | X |
● If a transaction Ti has locked Q in shared mode, then another transaction Tj can lock Q in shared mode only. This is called as composite mode.
● If a transaction Ti has locked Q in S mode, another transaction Tj can’t lock Q in X mode. This is called incompatible mode.
● Similarly, if a transaction Ti has locked Q in X mode, then other transaction Tj can’t lock Q in either S or X mode.
● To access, a data item, transaction Ti must first lock that item.
● If the data item is already locked by another transaction in an incompatible mode, the concurrency control manager will not grant the lock until lock has been released.
● Thus, Ti is mode to wait until all incompatible locks have been released.
● A transaction can unlock a data item by unlock (Q)instruction.
Eg.1. Transaction T1 displays total amount of money in accounts A & B.
Without-locking modes: -
T1
R(A)
R(B)
Display(A+B)
With-locking modes: -
T1
Locks(A)
R(A) unlock(A)
Locks(B)
R(B) unlock(B)
Display(A+B)
T1 locks A & B in shared mode because T1 uses A & B only for reading purpose.
Two-Phase Locking Protocol: -
● Each transaction in the system should follow a set of rules, called locking protocol.
● A transaction is said to follow the two-phase locking protocol, if all locking operation (shared, exclusive protocol) precede the first unlock operation.
● Such a transaction can be divided into two phases: Growing & shrinking phase.
● During Expanding / Growing phase, new locks on items can be acquired but no one can be released.
● During a shrinking phase, existing locks can be released but no new locks can be acquired.
● If every transaction in a schedule follows the two-phase locking protocol, the schedule is guaranteed to be serialization, obviating the need to test for Serializability.
● Consider, following schedules S11, S12. S11 does not follow two-phase locking &S12 follows two-phase locking protocol.
T1
Lock_S(Y) R(Y) Unlock(Y) Lock_X(Q) R(Q) Unlock(Q) Q: = Q + Y; W(Q); Unlock(Q)
|
This schedule does not follow two phase locking because 3 rd instruction lock-X(Q) appears after unlock(Y) instruction.
T1
Lock_S(Y) R(Y) Lock_X(Q) R(Q) Q: = Q + Y; W(Q); Unlock(Q); Unlock(Y); |
This schedule follows two-phase locking because all lock instructions appear before first unlock instruction.
Time stamping Methods
● Time stamp is a unique identifier created by the DBMS to identify a transaction.
● These values are assigned, in the order in which the transactions are submitted to the system, so timestamp can be thought of as the transaction start time.
● It is denoted as Ts(T).
● Note: - Concurrency control techniques based on timestamp ordering do not use locks, here deadlock cannot occur.
Generation of timestamp: -
Timestamps can be generated in several ways like: -
● Use a counter that is incremental each time its value is assigned to a transaction. Transaction timestamps are numbered 1,2, 3, in this scheme. The system must periodically reset the counter to zero when no transactions are executing for some short period of time.
● Another way is to use the current date/time of the system lock.
● Two timestamp values are associated with each database item X: -
1) Read-Ts(X): -
i. Read timestamp of X.
Ii.Read –Ts(X) = Ts(T)
Where T is the youngest transaction that has read X successfully.
2) Write-Ts(X): -
i. Write timestamp of X.
Ii.Write-Ts(X) = Ts(T),
Where T is the youngest transaction that has written X successfully.
These timestamps are updated whenever a new read(X) or write(X) instruction is executed.
Timestamp Ordering Algorithm: -
a. Whenever some transaction T issues a Read(X) or Write(X) operation, the algorithm compares Ts(T) with Read-Ts(X) & Write-Ts(X) to ensure that the timestamp order of execution is not violated.
b. If violate, transaction is aborted & resubmitted to system as a new transaction with new timestamp.
c. If T is aborted & rolled back, any transaction T1 that may have used a value written by T must also be rolled back.
d. Similarly, any transaction T2 that may have used a value written by T1 must also be rolled back & so on.
So, cascading rollback problems is associated with this algorithm.
Algorithm: -
1) If transaction T issues a written(X) operation: -
a) If Read-Ts(X) > Ts(T)
OR
Write-Ts(X) > Ts(T)
Then abort & rollback T & reject the operation.
This is done because some younger transaction with a timestamp greater than Ts(T) has already read/written the value of X before T had a chance to write(X), thus violating timestamp ordering.
b) If the condition in (a) does not occur then execute write (X) operation of T & set write-Ts(X) to Ts(T).
2) If a transaction T issues a read(X) operation.
a. If write-Ts(X) > Ts(T), then abort & Rollback T & reject the operation.
This should be done because some younger transaction with timestamp greater than Ts(T) has already written the value of X before T had a chance to read X.
b. If Write-Ts(X) ≤ Ts(T), then execute the read(X) operation of T & set read-Ts(X) to the larger of Ts(T) & current read-Ts(X).
Advantages: -
1. Timestamp ordering protocol ensures conflict serializability. This is because conflicting order.
2. The protocol ensures freedom from deadlock, since no transaction ever waits.
Disadvantages: -
1. There is a possibility of starvation of long transactions if a sequence of conflicting short transaction causes repeated restarting of long transaction.
2. The protocol can generate schedules that are not recoverable.
Shadow Paging is a method of recovery that is used for database recovery. In this recovery process, the database is considered to consist of fixed sizes of logical storage units referred to as pages. With the support of the page table, pages are mapped into physical storage blocks that allow for one entry for each logical database page. Two-page tables called the actual page table and a shadow page table are used for this process.
The entries in the current page table are used to refer to the most recent pages of the database on the disc. Another table, i.e., the Shadow Page Table, is used when the transaction that copies the current page table begins.
After that, the shadow page table is saved on the disc, and for transactions, the actual page table will be used. Entries present in the current page table can be updated during execution, but they are never changed in the shadow page table. Both tables become similar after transactions.
This technique is also known as Cut-of-Place updating.

Fig 5: Shadow paging
Consider the figure above. Writing operations on page 3 and 5 are done in this 2. The new page table points to the old page 3 before the start of the writing operation on page 3. The following steps are carried out when the writing operation starts:
● Firstly, start looking for a free block accessible in disc blocks.
● After the free block is located, page 3 is copied to the free block represented by Page 3 (New).
● Now the present page table points to Page 3 (New) on the disc, but since it is not updated, the shadow page table points to the old page 3.
● Changes are now propagated to Page 3 (New), where the existing page table points to.
Log Based Recovery
● Log is the most widely used structure for recording database modifications.
● The log is a sequence of log records.
● Various types of log records are represented as: -
● <Ti start>: Transaction Ti has started.
<Ti commit>: Transaction Ti has committed.
<Ti abort>: Transaction Ti has aborted.
Database write record: -
<Transaction Id, Data item Id, Old value, New value>
<Ti, X, V1, V2>: - Transaction Ti has performed write operation on X. Old value of x was V1 & the new value is V2.
● Whenever a transaction performs write, a log record for that write is created.
● Once a log exists, we can output the modification to the database if that is desirable.
Key takeaway
- Shadow Paging is a method of recovery that is used for database recovery.
- In this recovery process, the database is considered to consist of fixed sizes of logical storage units referred to as pages.
The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
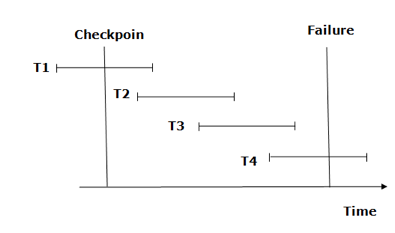
Fig 6: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example : <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Key takeaway
- The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
- The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Deferred Database Modification: -
● This ensures atomicity by recording all database modifications in the log, but deferring the execution of all write operations in a transaction until transaction partially commits.
● When a transaction partially commits, the information in the log associated with the transactions is used in executing deferred writes.
● If a system crashes before the transaction completes its execution, then the information on the log is simply ignored.
Consider transactions T1 & T2 as: -
A = 100, B = 200, C = 50
T1: - R(A) A: = A+100 W(A)
R(B) B: = B-100 W(B) T2: - R(C) C: = C+50 W(C)
|
Log for T1: - <T1, start>
<T1, A, 100, 200>
<T1, B, 200, 100>
<T1, commit>
Log for T2: - <T2, Start>
<T2, C, 50, 100>
<T2, commit>
Consider, the failure cases like: -
T1: = R(A)
A: = A+100
W(A)
R(B)
B: = B-100
W(B) → Case I
T2: = R(C) → Case II
C = C+50;
W(C) → Case III
Case I: - System comes back without taking any action because system fails before commit operation. So, database has not been modified. Therefore, only log records are deleted.
Case II: - <T1, start>
<T1, A, 100, 200>
<T1, B, 200, 100>
<T1, commit>
<T2, start> → System failure
In this case, when system failure occurs, T1 has been committed. So, the changes are
Recorded in the database. After this system fails, as database has been already modified, we require new values of items. For this, redo(T1) is executed.
Case III: -
<T1, start>
<T1, A, 100, 200>
<T1, B,200, 100>
<T1, commit>
<T2, start>
<T2, C,50, 100>
<T2, commit> → System failure
As T1 & T2 are committed log records are written to the database. So the database has been modified & then system failure occurs. So, to retrieve modified values of database items, redo(T1) & redo(T2) is executed.
Immediate database modification
● Database gets modifies immediately after write operation while the transaction is still in active state.
● It does not wait for commit operation. It is called as uncommitted modification
● First log records is created & then database gets modified.
● The recovery scheme uses two recovery procedures: -
I. Undo (Ti): - It restores the value of all data items updated by transaction, Ti to old values.
II. Redo (Ti): - IT sets the value of all data items updated by transaction, Ti to the new
Values.
Hints: -
1) After <T, start> & <T, commit> => Redo
2) After <T, start> & before <T, commit> => Redo
T1 T2 R(A) A: =A+100 W(A) R(B) B: = B-100 → Case I W(B)
R(C) → Case II C: = C+50 W(C) → Case III
|
Case I: - log record for case-I
<T1, start>
<T1, A, 100, 200>
<T1, B, 200, 100>
Log record contains start but not commit. But as it is immediate database modification, database has been modified before commit instruction. So, to maintain atomicity property, undo<T1> is executed. So that original value of A will be achieved.
Case II: - log record for case-II
<T1, start>
<T1, A, 100, 200>
<T1, B, 200, 100>
<T1, commit>
<T2, start>
Log record for T1 contains both start & commit modifications are done on database & T1has executed commit also. So, after failure, new values of A & B are required.
To get modified values of A & B, redo(T1) is issued.
For T2, start is recorded but not commit. It means modifications are reflected in the database before commit. As per property of atomicity, to get original value of C, undo(T2) is issued.
Case III: - In this case, log record contains (start & commit) for both T1 & T2. So the database has been modified & commit is executed for both T1 & T2. So, to get modified values of A, B, & C Redo(T1) & Redo(T2) is issued.
Key takeaway
- Database gets modifies immediately after write operation while the transaction is still in active state.
- When a transaction partially commits, the information in the log associated with the transactions is used in executing deferred writes.
- Log is the most widely used structure for recording database modifications.
- The log is a sequence of log records
References:
- Silberschatz A., Korth H., Sudarshan S., "Database System Concepts", McGraw Hill Publishers, ISBN 0-07-120413-X, 6th edition
- Connally T, Begg C., "Database Systems", Pearson Education, ISBN 81-7808-861-4
- Adam Fowler, “NoSQL For Dummies”, John Wiley & Sons, ISBN-1118905628
- Kevin Roebuck, “Storing and Managing Big Data - NoSQL, HADOOP and More”, Emereopty Limited, ISBN: 1743045743, 9781743045749
- Joy A. Kreibich, “Using SQLite”, O'REILLY, ISBN: 13:978-93-5110-934-1




