Unit - 5
NoSQL Databases
A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
A distributed database system (DDBS) is a database that does not have all of its storage devices connected to the same CPU. It might be stored on numerous computers in the same physical place, or it could be spread throughout a network of connected computers. Simply said, it is a logically centralized yet physically dispersed database system. It's a database system and a computer network all rolled into one. Despite the fact that this is a major issue in database architecture, one of the most serious challenges in today's database systems is storage and query in distributed database systems.
Advantages
The advantages of distributed databases versus centralized databases are as follows.
Modular Development − In centralized database systems, if the system needs to be expanded to additional locations or units, the activity necessitates significant effort and disruption of current operations. In distributed databases, on the other hand, the process is merely moving new computers and local data to the new site and then connecting them to the distributed system, with no interruption in present operations.
More Reliable − When a database fails, the entire centralized database system comes to a halt. When a component fails in a distributed system, however, the system may continue to function but at a lower level of performance.
Better Response − If data is delivered efficiently, user requests can be fulfilled from local data, resulting in a speedier response. In centralized systems, on the other hand, all inquiries must transit through the central computer for processing, lengthening the response time.
Lower Communication Cost − When data is stored locally where it is most frequently utilized in distributed database systems, communication costs for data manipulation can be reduced. In centralized systems, this is not possible.
Disadvantages
● Performance is hampered since the data is accessible through a remote system.
● It is not possible to utilize static SQL.
● In a distributed database, network traffic increases.
● In a distributed database, database optimization is tough.
● In different systems, different data formats are employed.
● Different DBMS products are utilized in different systems, increasing the system's complexity.
● Keeping track of the system catalog is a demanding task.
● The DBMS must ensure that the recovered system is consistent with other systems when recovering a failed system.
● It's difficult to deal with distributed deadlock.
CAP Theorem
The CAP theorem, also known as the CAP principle, is a mathematical formula that can be used to describe some of the competing requirements in a distributed system with replication. It's a tool that helps system designers understand the trade-offs while creating networked shared-data systems.
The three letters in CAP stand for three desirable features of distributed systems with replicated data: consistency (among replicated copies), system availability (for read and write operations), and partition tolerance (in the event that the system's nodes are partitioned by a network failure).
The CAP theorem asserts that in a distributed system with data replication, all three desirable features – consistency, availability, and partition tolerance – cannot be guaranteed at the same time.
According to the theory, networked shared-data systems can only firmly support two of three properties:
- Consistency
For various transactions, consistency means that the nodes will have the same copies of a replicated data item visible. Each node in a distributed cluster must return the same, most recent, successful write. Every client has the same view of the data, which is referred to as consistency. Consistency models come in a variety of shapes and sizes. Sequential consistency, a particularly powerful form of consistency, is referred to in CAP.
2. Availability
Each read or write request for a data item will either be processed successfully or will receive an error message indicating that the operation cannot be performed. In a reasonable length of time, every non-failing node responds to all read and write requests. Every is the essential word here. Every node on (either side of a network partition) must be able to reply in an acceptable period of time in order to be available.
3. Partition tolerance
Partition tolerance means that the system can keep running even if the network connecting the nodes fails, resulting in two or more partitions, each with its own set of nodes that can only communicate with one another. That is, despite network partitions, the system continues to function and maintains its consistency promises. Network partitions are an unavoidable reality. Once a partition heals, distributed systems that ensure partition tolerance can gently recover.
Key takeaway
- A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers.
- A distributed database system is made up of multiple sites with no physical components in common.
- The CAP theorem, also known as the CAP principle, is a mathematical formula that can be used to describe some of the competing requirements in a distributed system with replication.
- It's a tool that helps system designers understand the trade-offs while creating networked shared-data systems.
Structured data has elements that can be addressed for effective analysis. It has been structured into a database, which is a formatted repository. It refers to all data that can be put in a table with rows and columns in a SQL database. They have relational keys and can be mapped into pre-designed fields with ease. Those data are now being processed the most in the development and simplest approach to manage information. Relational data is an example.
Unstructured data
Unstructured data is data that isn't arranged in a preset way or doesn't have an established data model, making it unsuitable for a traditional relational database. So there are other platforms for storing and managing unstructured data; it is becoming more common in IT systems and is utilized by businesses in a number of business intelligence and analytics applications. Word, PDF, Text, and Media logs are just a few examples.
Semi-structured data
Semi-structured data is data that is not stored in a relational database but has organizational qualities that make it easier to examine. Some processes can be stored in a relational database (though this may be difficult for semi-structured data), but semi-structured data exists to save space. Data in XML format is an example.
Difference between the structured, unstructured and semi-structured data
Properties | Structured data | Semi-structured data | Unstructured data |
Technology | It is based on Relational database table | It is based on XML/RDF(Resource Description Framework). | It is based on character and binary data |
Transaction management | Matured transaction and various concurrency techniques | Transaction is adapted from DBMS not matured | No transaction management and no concurrency |
Version management | Versioning over tuples, row, tables | Versioning over tuples or graph is possible | Versioned as a whole |
Flexibility | It is schema dependent and less flexible | It is more flexible than structured data but less flexible than unstructured data | It is more flexible and there is absence of schema |
Scalability | It is very difficult to scale DB schema | Its scaling is simpler than structured data | It is more scalable. |
Robustness | Very robust | New technology, not very spread | — |
Query performance | Structured query allow complex joining | Queries over anonymous nodes are possible | Only textual queries are possible |
Key takeaway
- Structured data has elements that can be addressed for effective analysis. It has been structured into a database, which is a formatted repository.
- Unstructured data is data that isn't arranged in a preset way or doesn't have an established data model, making it unsuitable for a traditional relational database.
- Semi-structured data is data that is not stored in a relational database but has organizational qualities that make it easier to examine.
A NoSQL database, which stands for "non SQL" or "non relational," is a database that allows for data storage and retrieval. This information is represented in ways other than tabular relationships found in relational databases. Such databases first appeared in the late 1960s, but it wasn't until the early twenty-first century that they were given the name NoSQL. NoSQL databases are increasingly being employed in real-time online applications and large data analytics. Not only SQL is a term used to stress the fact that NoSQL systems may support SQL-like query languages.
Design simplicity, horizontal scaling to clusters of machines, and tighter control over availability are all advantages of a NoSQL database. The data structures used by NoSQL databases differ from those used by relational databases by default, which allows NoSQL to perform some operations faster. The applicability of a NoSQL database is determined by the problem it is supposed to answer. NoSQL databases' data structures are sometimes seen to be more flexible than relational database tables.
Many NoSQL databases make trade-offs between consistency and availability, performance, and partition tolerance. The usage of low-level query languages, a lack of standardized interfaces, and large prior investments in relational databases are all barriers to wider adoption of NoSQL storage. Although most NoSQL databases lack true ACID transactions (atomicity, consistency, isolation, and durability), a few databases, including MarkLogic, Aerospike, FairCom c-treeACE, Google Spanner (though technically a NewSQL database), Symas LMDB, and OrientDB, have made them a central part of their designs.
Most NoSQL databases support eventual consistency, which means that database updates are propagated to all nodes over time. As a result, queries for data may not return updated data right away, or may result in reading data that is inaccurate, a problem known as stale reads. Some NoSQL systems may also experience lost writes and other data loss. To avoid data loss, certain NoSQL systems offer features like write-ahead logging. Data consistency is even more difficult to achieve when doing distributed transaction processing across many databases. Both NoSQL and relational databases struggle with this.
Advantages
● it is possible to use it as a primary or analytic data source.
● Capacity for Big Data.
● There isn't a single point of failure.
● Replication is simple.
● There is no requirement for a separate caching layer.
● It offers quick performance as well as horizontal scalability.
● Can effectively handle structured, semi-structured, and unstructured data.
● Object-oriented programming is a type of programming that is simple to use and adaptable.
● A dedicated high-performance server isn't required for NoSQL databases.
● Key Developer Languages and Platforms are supported.
● RDBMS is more difficult to implement.
● It has the potential to be the key data source for web-based applications.
● Manages large data, including the velocity, diversity, volume, and complexity of data.
Disadvantages
● There are no norms for standardization.
● Querying capabilities are limited.
● Databases and tools for Relational Database Management Systems (RDBMS) are relatively established.
● It lacks standard database features such as consistency when several transactions are carried out at the same time.
● As the volume of data grows, it becomes more difficult to preserve unique values as keys become more difficult to remember.
● With relational data, it doesn't work as well.
● For novice developers, the learning curve is steep.
● For businesses, open source choices are less common.
Need
● When you need to store and retrieve a large volume of data.
● The relationship between the data you keep isn't as significant as you might think.
● The data is unstructured and changes over time.
● At the database level, support for constraints and joins is not necessary.
● The data is always growing, and you'll need to scale the database on a regular basis to keep up with it.
Features
Non - relational
● The relational model is never followed by NoSQL databases.
● Tables with flat fixed-column records should never be used.
● Work with BLOBs or self-contained aggregates.
● Object-relational mapping and data standardization are not required.
● There are no advanced features such as query languages, planners, referential integrity joins, or ACID.
Schema -free
● NoSQL databases are either schema-free or contain schemas that are more loose.
● There is no requirement for the data schema to be defined.
● Provides data structures that are heterogeneous within the same domain.
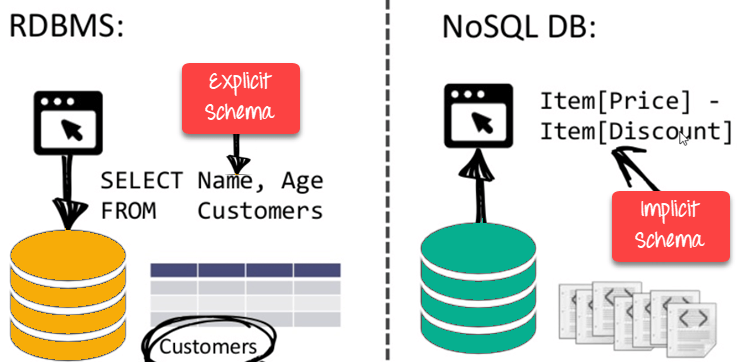
Fig 1: NoSQL is schema free
Simple API
● Provides simple user interfaces for storing and querying data.
● APIs make it possible to manipulate and choose data at a low level.
● HTTP REST with JSON is typically used with text-based protocols.
● The majority of queries were written in a NoSQL query language that was not based on any standard.
● Databases that are web-enabled and run as internet-facing services.
Distributed
● A distributed execution of many NoSQL databases is possible.
● Auto-scaling and fail-over capabilities are included.
● The ACID principle is frequently overlooked in favor of scalability and throughput.
● Asynchronous replication across remote nodes is almost non-existent. HDFS Replication, Asynchronous Multi-Master Replication, Peer-to-Peer.
● Only ensuring long-term consistency.
● Nothing is shared in the architecture. As a result, there is less coordination and more dispersal.
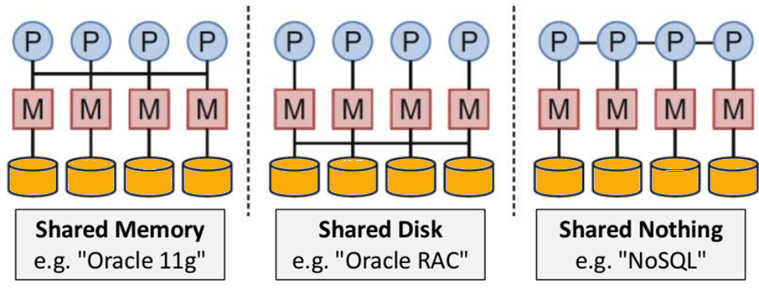
Fig 2: NoSQL is Shared Nothing
Key takeaway
- A NoSQL database, which stands for "non SQL" or "non relational," is a database that allows for data storage and retrieval.
- Many NoSQL databases make trade-offs between consistency and availability, performance, and partition tolerance.
- Most NoSQL databases support eventual consistency, which means that database updates are propagated to all nodes over time.
- NoSQL databases are increasingly being employed in real-time online applications and large data analytics.
- Not only SQL is a term used to stress the fact that NoSQL systems may support SQL-like query languages.
There are four types of NoSQL databases: key-value pair, column-oriented, graph-based, and document-oriented. Each category has its own set of characteristics and limits. None of the databases listed above is better at solving all of the difficulties. Users should choose a database that meets their product requirements.
NoSQL databases come in a variety of shapes and sizes:
● Key-value Pair Based
● Column-oriented Graph
● Graphs based
● Document-oriented
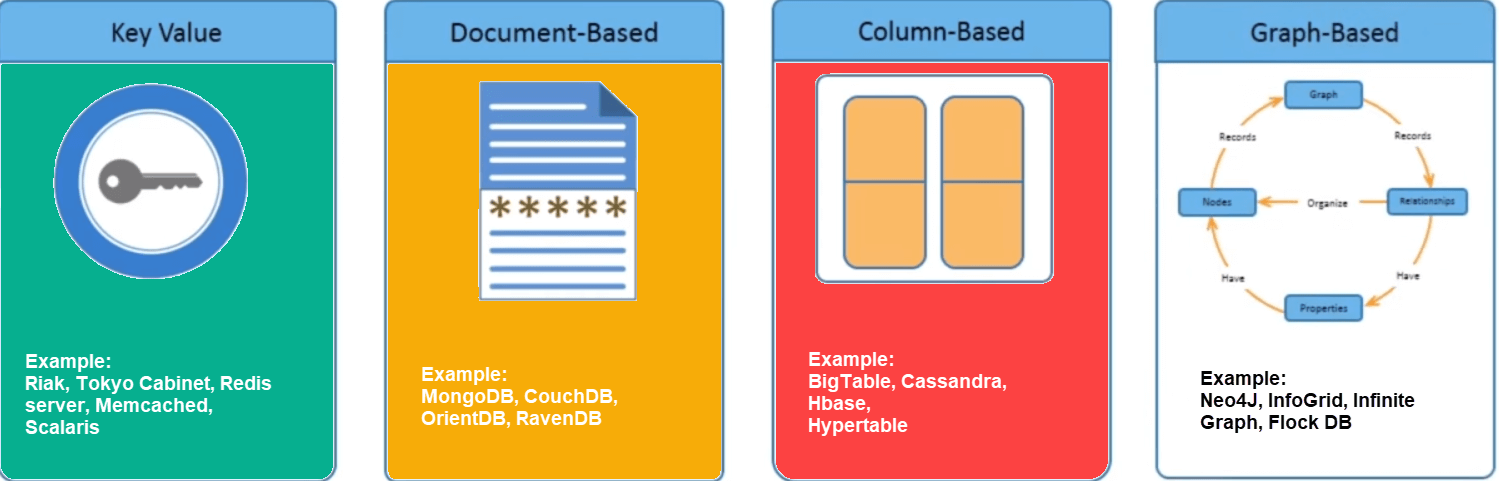
Fig 3: Types of data with example
Key value store
Key/value pairs are used to store data. It is built to handle large amounts of data and heavy loads. Data is stored in key-value pair storage databases as a hash table, with each key being unique and the value being a JSON, BLOB(Binary Large Objects), text, or other format.
A hash table is utilized in the Key Value store type, where a unique key points to an item. Keys can be grouped into logical groups, with the only requirement that each group's keys be unique. This enables the use of identical keys across logical groups.
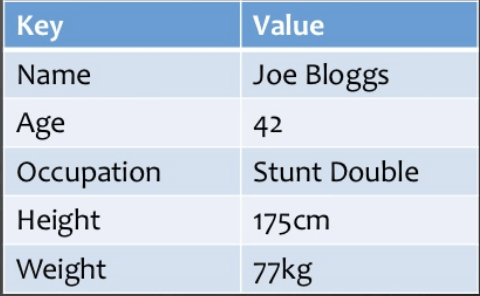
Fig 4: Example
It's one of the most fundamental NoSQL databases. This type of NoSQL database is utilized for things like collections, dictionaries, and associative arrays, among other things. Developers can use key value stores to store data that does not have a schema. They're great for items in shopping carts.
NoSQL key-value store DataBases include Redis, Dynamo, and Riak. They're all based on the Dynamo paper from Amazon.
Document store
Document-Oriented The value part of a NoSQL DB's data is kept as a document, while the key value pair is stored as a key value pair. JSON or XML formats are used to store the document. The database understands the value and can query it.
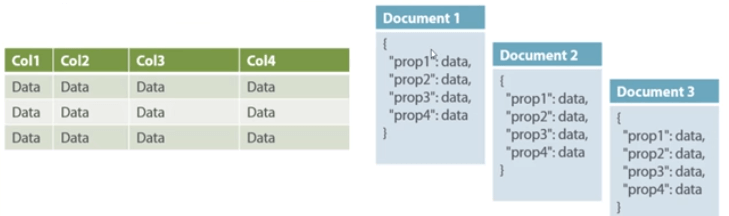
Fig 5: Relational Vs document
On the left, you can see rows and columns, and on the right, you can see a document database with a structure that is comparable to JSON. Now that you have a relational database, you must know what columns you have and how to use them. A document database, on the other hand, uses a data store such as a JSON object. You don't have to define anything, which makes it flexible.
CMS systems, blogging platforms, real-time analytics, and e-commerce apps all use this document type. It should not be used for complex transactions involving several operations or queries against different aggregate models.
Popular Document DBMS systems include Amazon SimpleDB, CouchDB, MongoDB, Riak, Lotus Notes, and MongoDB.
Graph
A graph database maintains both entities and the relationships between them. The entity is represented as a node, while the relationships are represented as edges. An edge establishes a connection between nodes. A unique identifier is assigned to each node and edge.
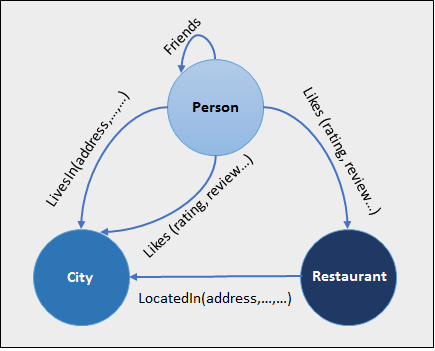
Fig 6: Example
A graph database is multi-relational in nature, as opposed to a relational database, which has loosely connected tables. Traversing relationships is quick because they are already stored in the database and don't need to be calculated.
Graph databases are commonly used for social networks, logistics, and geographic data.
Popular graph-based databases include Neo4J, Infinite Graph, OrientDB, and FlockDB.
Wide column stores
Column-oriented databases are based on Google's BigTable paper and function with columns. Each column is dealt with independently. The values of single-column databases are kept together.
Because the data is readily available in a column, they give good performance on aggregate queries like SUM, COUNT, AVG, MIN, and so on.
Data warehouses, business intelligence, CRM, library card catalogs, and other applications all use column-based NoSQL databases.
Column-based databases such as HBase, Cassandra, HBase, and Hypertable are instances of NoSQL queries.
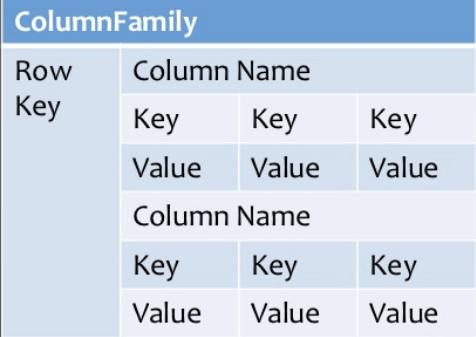
Fig 7: Column based NoSQL database
BASE properties
BASE is a term that refers to database processing in a NoSQL database, such as a data lake. According to DAMA DMBoK, the BASE philosophy was sparked by an increase in data volumes and variability. BASE has less confidence than ACID, but it scales effectively and reacts quickly to changes in data. The features of BASE construction are as follows:
Basically Availability - In the event of a failure, the system will remain operational.
Soft state - Due to eventual consistency, the status of the data could change without application intervention.
Eventually consistency - After the application input, the system will gradually become consistent. The data will be replicated over multiple nodes until it reaches a consistent state. But the consistency is not guaranteed at a transaction level.
BASE case example
● Putting together a value-based model for a health institution using a variety of data sources.
● On a website, using shopping cart software.
● Detecting fraud rings and con artists.
● Security of the network and IT infrastructure is being monitored.
● Organizing and repurposing content in documents.
Data consistency model
A database's consistency property means that if data is properly written to the database, subsequent queries will be able to access the data and obtain a consistent view of the data. In reality, this means that if you write a record to a database and then request it right away, you'll always get it. It comes in handy for things like Amazon orders and bank transfers, among other things.
Consistency, on the other hand, is a sliding scale that is far too complex to discuss here. In the world of NoSQL, however, consistency usually falls into one of two categories.
ACID Consistency (ACID stands for Atomicity, Consistency, Isolation, Durability): The term ACID refers to the fact that once data is written, it may be read with complete consistency.
Eventual Consistency (BASE): BASE denotes that data will eventually exist for reading after it has been written.
A battle has raged between individuals who believe that database consistency isn't necessary and others who believe it is (translate people to NoSQL firms' marketing teams!).
The truth is somewhere in the middle. Is it important that a Facebook post isn't visible by all of a person's friends for five minutes? No, most likely not. When you replace "Facebook post" with "billion-dollar financial transaction," your perspective shifts dramatically! Which consistency strategy you use is determined by the situation. Strong consistency, in my opinion, is always the best option in mission-critical business system settings.
ACID Vs BASE
An executed transaction is always consistent thanks to the ACID database transaction paradigm. This makes it a suitable fit for enterprises that deal with online transaction processing (for example, financial institutions) or online analytical processing (for example, consulting firms) (e.g., data warehousing). These businesses require database systems that can manage a large number of tiny transactions at the same time. Invalid states must be treated with zero tolerance.
It's easiest to understand the ACID model by breaking down the acronym in its name.

Fig 8: ACID
ACID is an acronym that stands for:
Atomic — Each transaction is either completed successfully or the process halts, causing the database to revert to its previous state. This ensures that the database's data is accurate.
Consistent - A completed transaction will never jeopardize the database's structural integrity.
Isolated — Transactions cannot interfere with the integrity of other transactions while they are still running.
Durable — In the event of a network or power failure, the data relating to the completed transaction will be preserved. If a transaction fails, the altered data is unaffected.
ACID Use Case Example
ACID databases will be used nearly exclusively by financial organizations. The atomic character of ACID is crucial for money transactions.
An interrupted transaction that isn't removed from the database right once can generate a slew of problems. Money could be deducted from one account and never credited to another owing to an error.
Which Databases are ACID compliant?
Choosing a relational database management system is a safe way to ensure that your database is ACID compliant. MySQL, PostgreSQL, Oracle, SQLite, and Microsoft SQL Server are among them.
Some NoSQL DBMSs, such as Apache CouchDB and IBM Db2, are also ACID compliant to some extent. The NoSQL approach to database management, on the other hand, goes against the stringent ACID requirements. As a result, NoSQL databases are not a good solution for individuals that need to work in a controlled environment.
BASE
With the rise of NoSQL databases, data manipulation became more flexible and fluid. As a result, a new database model matching these attributes was created.
BASE is a little more difficult to remember than ACID. The words underlying it, on the other hand, hint at how the BASE model differs.

Fig 9: BASE
The acronym BASE stands for:
Basically Available - BASE modelled NoSQL databases will maintain data availability by spreading and replicating it among the nodes of the database cluster, rather than enforcing immediate consistency.
Soft State - Data values may alter over time due to a lack of instant consistency. The BASE paradigm abandons the idea of a database that ensures its own consistency, instead entrusting that task to developers.
Eventually Consistent - BASE's failure to ensure instant consistency does not imply that it will never achieve it. However, data reads are still available until it does (even though they might not reflect reality).
BASE use Case example
When performing social network research, marketing and customer service organizations that deal with sentiment analysis will favor BASE's elasticity. Although social media feeds are not properly organized, they contain large amounts of data that a BASE-modeled database can easily handle.
Which Databases are Using the BASE Model?
NoSQL databases tend to follow BASE principles, similar to how SQL databases are almost always ACID compliant. MongoDB, Cassandra, and Redis, as well as Amazon DynamoDB and Couchbase, are among the most popular NoSQL systems.
Comparative study of RDBMS and NoSQL
Parameter | RDBMS | NoSQL |
Storage | RDBMS applications store data in the form of table structured manner. | NoSQL is a non-relational database system. It stores data in the form of unstructured. Manner. |
Number of users | RDBMS supports multiple users. | It also supports multiple users. |
Database structures | RDBMS uses tabular structures to store data. In table headers are the column names and the rows contains corresponding values. | NoSQL uses to store data in structured, semi-structured and unstructured forms. |
ACID | RDBMS are harder to construct and obey ACID (Atomicity, Consistency, Isolation, Durability). It helps to create consistency database. | NoSQL may support ACID to store data. |
Normalization | It supports the normalization and joining of tables. | It does have table form, so it does not support normalization. |
Open-source | Open-source application | Open-source program |
Integrity constraints | The relational database supports the integrity constraints at the schema level. Data values beyond a defined range cannot be stored in the particular RDBMS column. | NoSQL database supports integrity constraints. |
Development year | It was developed in the 1970s to deal with the issues of flat file storage. | It developed in the late 2000s to overcome the issues and limitations of the SQL database. |
Distributed database | It supports a distributed database. | It also supports a distributed database. |
Ideally suited for | This database system deals with a large quantity of data. | NoSQL database mainly designed for Big data and real-time web data. |
Client-server | RDBMS program support client-server architecture. | NoSQL storage system supports multi-server. It also supports client-server architecture. |
Data relationship | Data related to each other with the help of foreign keys | Data can be stored in a single document file. |
Hardware and software | High software and specialized DB hardware (Oracle Exadata, etc.) | Commodity hardware |
Data fetching | Data fetching is rapid because of its relational approach and database. | Data fetching is easy and flexible. |
Examples | MYSQL, Oracle, SQL Server, etc. | Apache HBase, IBM Domino,Oracle NoSQL Database,etc. |
Key takeaway
- Key value pairs are used to store data. It is built to handle large amounts of data and heavy loads.
- Document-Oriented The value part of a NoSQL DB's data is kept as a document, while the key value pair is stored as a key value pair.
- A graph database maintains both entities and the relationships between them. The entity is represented as a node, while the relationships are represented as edges.
- Column-oriented databases are based on Google's BigTable paper and function with columns.
- BASE is a term that refers to database processing in a NoSQL database, such as a data lake.
As we know, MongoDB can be used for a variety of purposes, including building applications (both web and mobile), data analysis, and database administration. In all of these cases, we must interact with the MongoDB server to perform operations such as entering new data into the application, updating data in the application, deleting data from the application, and reading data from the database.
The CRUD operations that MongoDB provides are a set of basic yet necessary activities that will enable you to interact with the MongoDB server quickly and simply.
Mongodb is a document-oriented database tool that is commonly referred to as a NoSQL database.
The CRUD operation in Mongodb relates to document creation, reading, updating, and deletion.
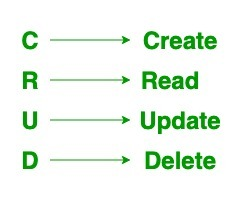
Fig 10: Curd
Create
To insert or add new documents to the collection, utilize the create or insert actions. If a collection does not already exist, it will be created in the database. MongoDB provides the following methods for performing and creating operations:
New documents are added to a collection using the Create operations.
New documents can be added to collections in two ways:
● db.collection.insertOne() - It's for adding a single document to a collection.
Example:
Using the db.collection.insertOne() method, we insert details of a single student in the form of a document into the student collection.
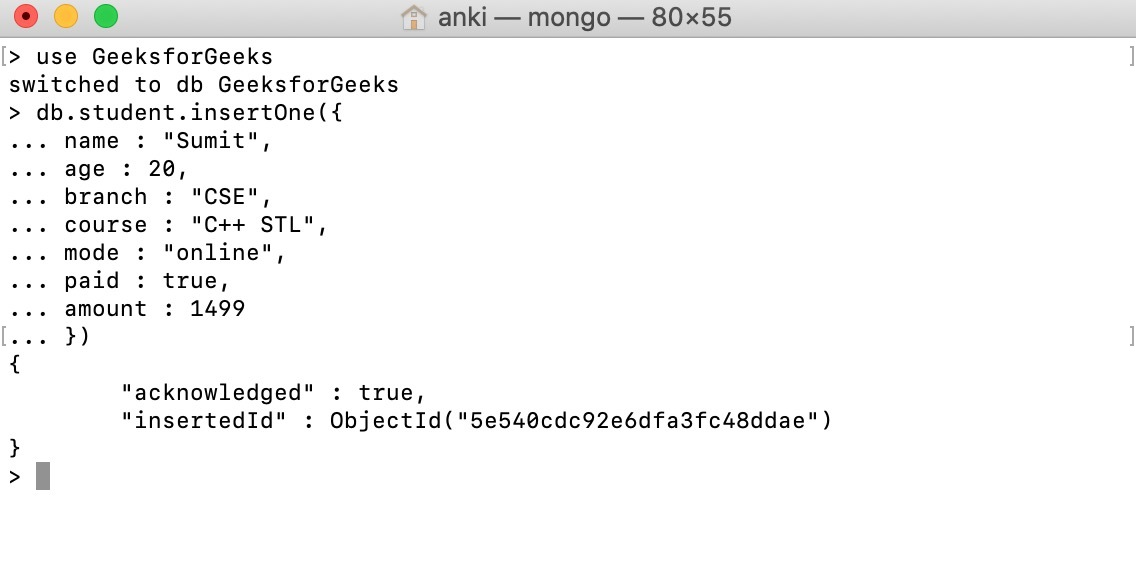
● db.collection.insertMany() - It's used to add a bunch of documents to a collection.
Example :
Using the db.collection.insertMany() method, we insert details of several students in the form of documents into the student collection in this example.
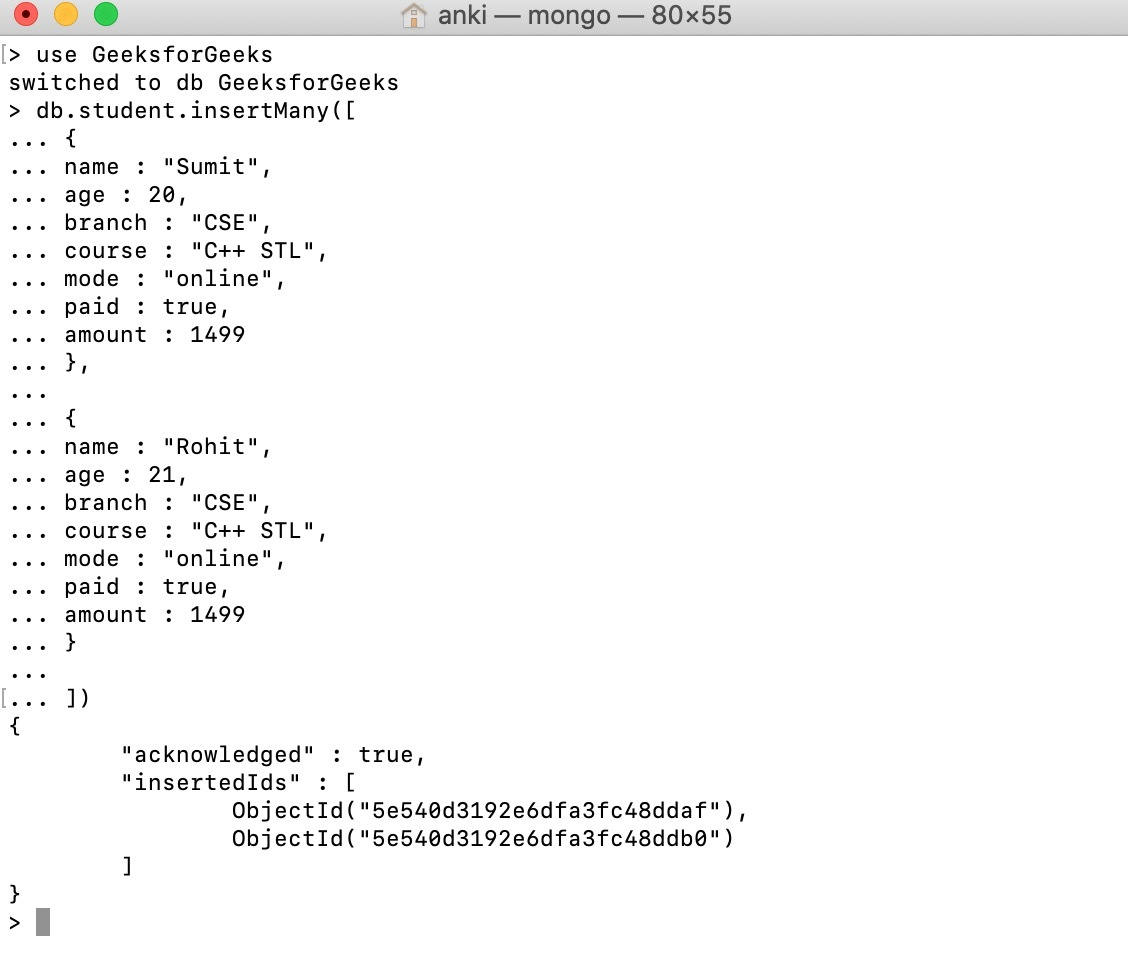
Read
Read operations are used to retrieve documents from a database. It will automatically create a new collection if one does not already present. In other words, read operations are used to search for a document in a collection. The following method given by MongoDB can be used to perform read operations:
● db.collection.find() - It's used to get papers out of a collection.
Example:
Using the db.collection.find() method, we are retrieving the details of students from the student collection in this example.
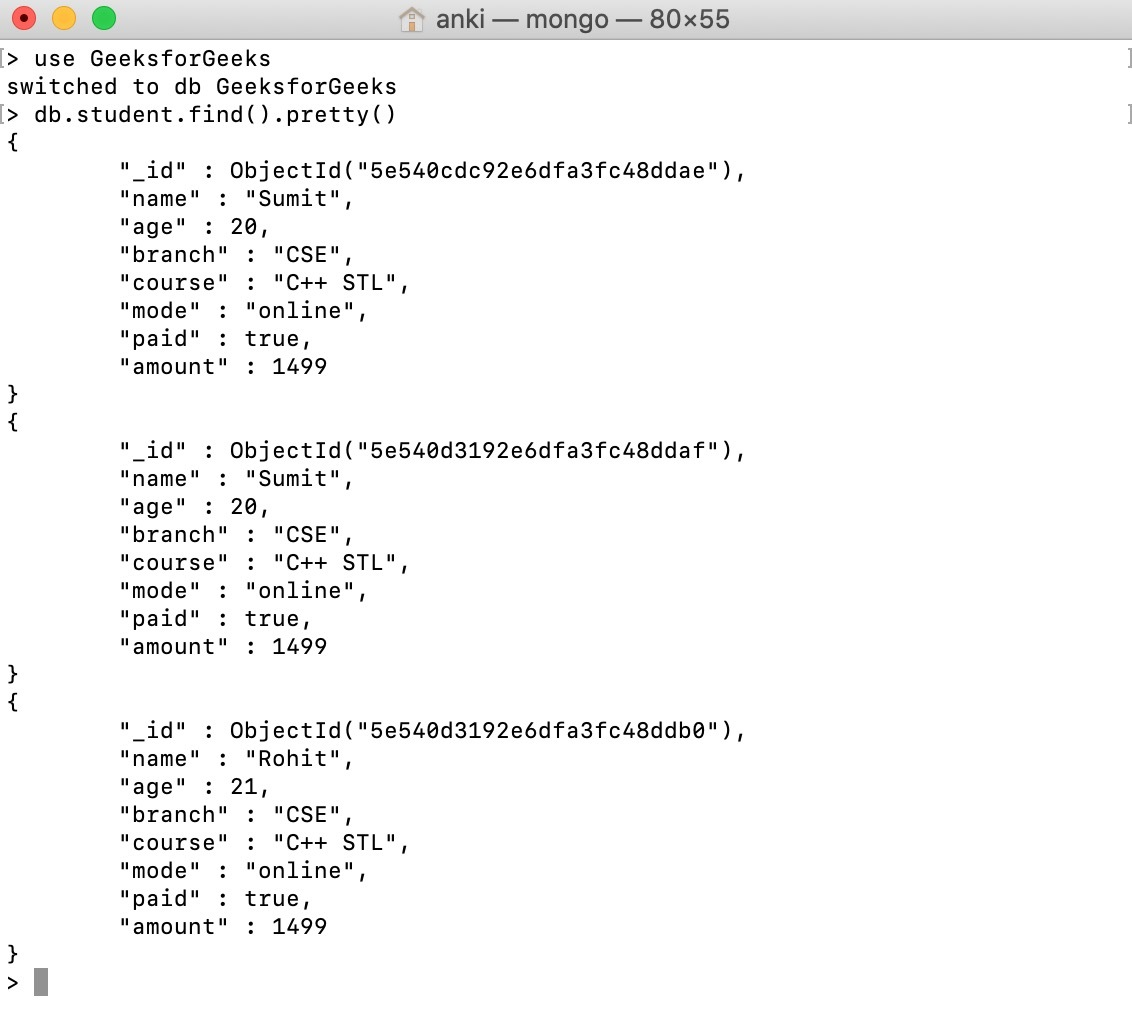
Update
The update operations are used to change or update a document in the collection. Update operations change the contents of a group of documents.
The following are the three methods for adding new documents to collections:
● db.collection.updateOne() - It's used to make changes to a single document in the collection that meets the specified criteria.
Example:
We're using the db.collection.updateOne() function to update Sumit's age in the student collection in this example.
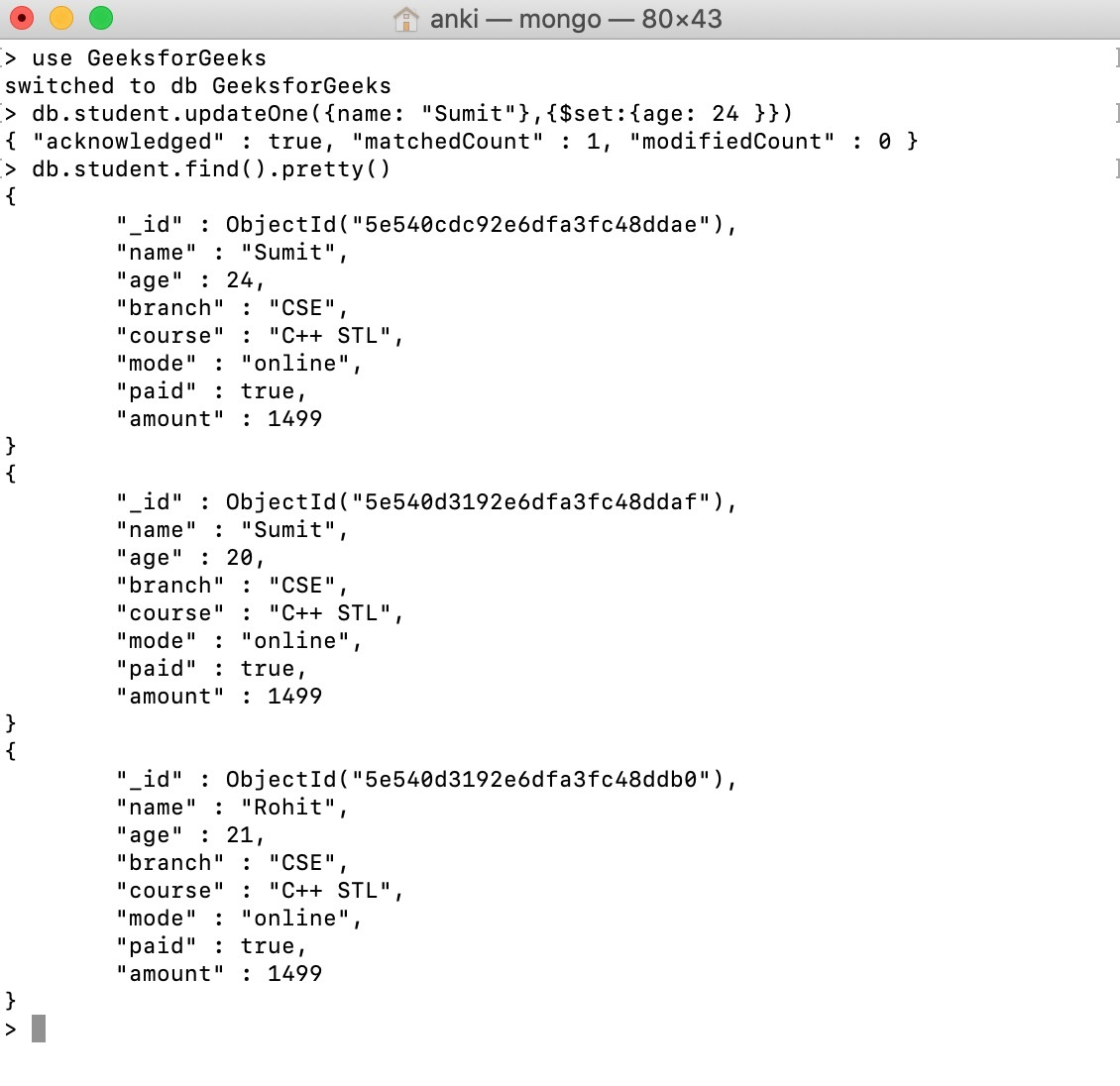
● db.collection.updateMany() - It's used to update a collection's worth of documents that meet the specified criteria.
Example:
Using the db.collection.updateMany() method, we update the year of course in all of the documents in the student collection.
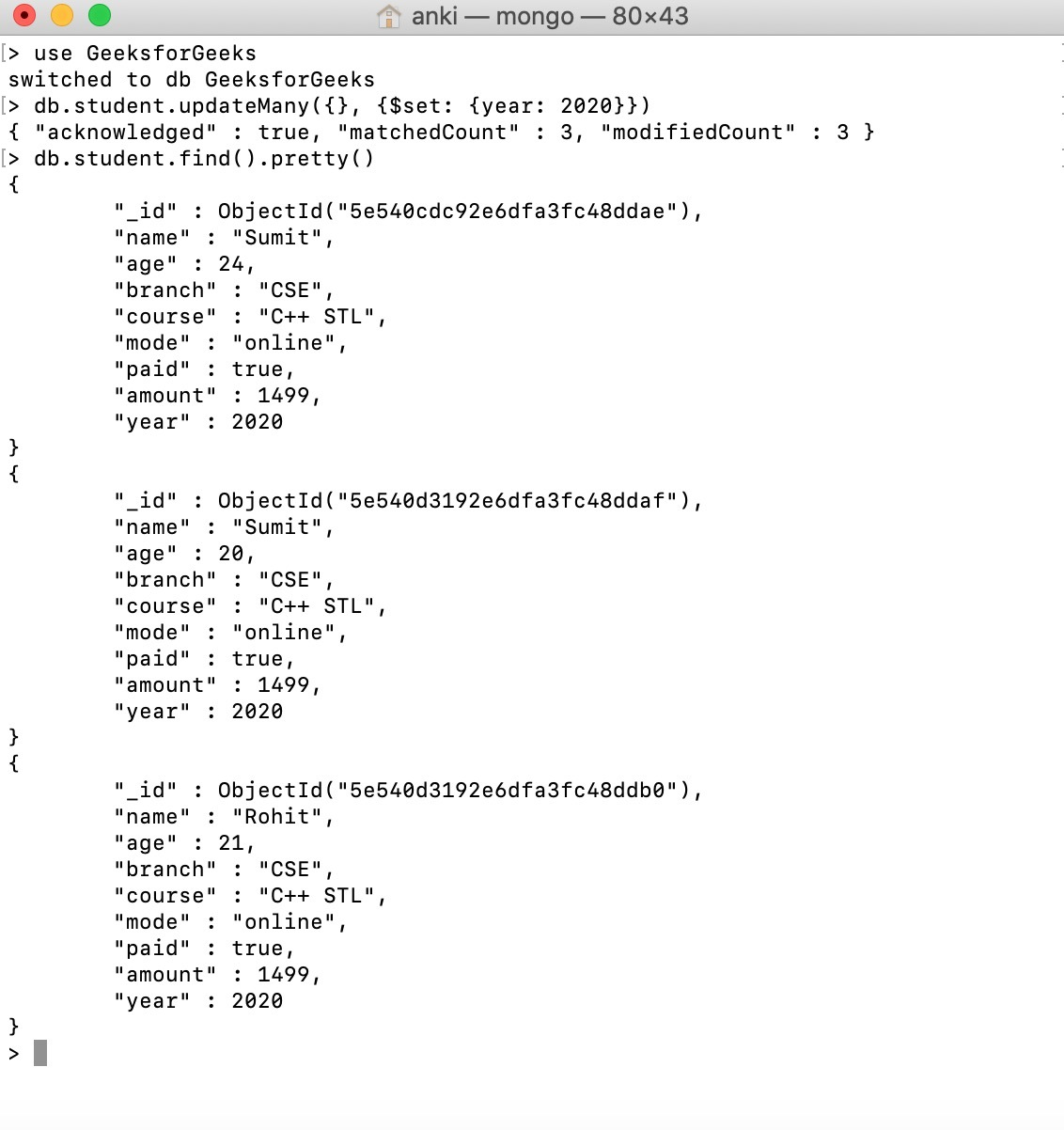
● db.collection.replaceOne() - It's used to replace individual documents in a collection that meet the specified criteria.
Delete
To delete or remove documents from a collection, perform the delete procedure.
New documents can be added to collections in two ways:
● db.collection.deleteOne() - It's used to remove a single document from a collection if it meets the specified conditions.
Example:
Using the db.collection.deleteOne() method, we delete a document from the student collection in our example.

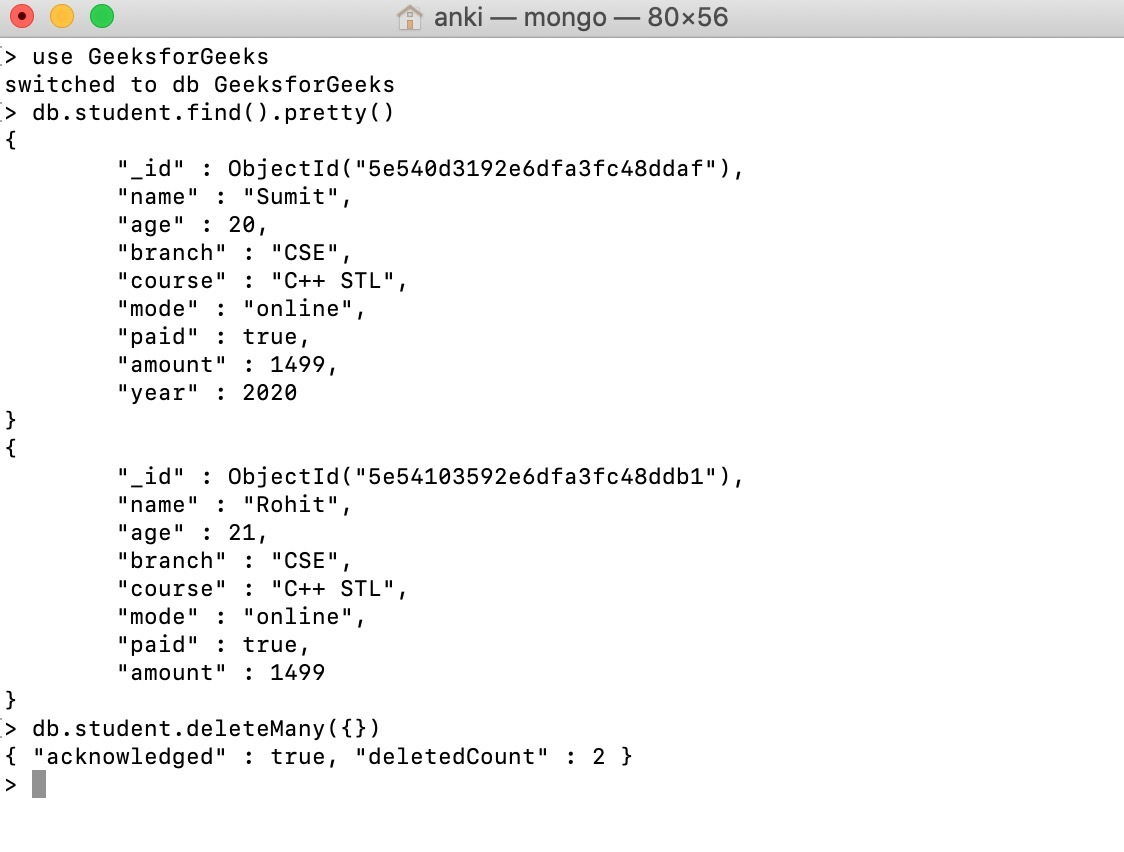
● db.collection.deleteMany() - It's used to remove a group of documents from a collection that meet the specified criteria.
Example:
Using the db.collection.deleteMany() method, we delete all of the documents from the student collection in our example.
Indexing
In SQL programming, an index is a particular data structure that allows you to quickly and conveniently discover a record in a database table without having to go through each and every entry in the table. Indexes can be readily created by employing one or more of a table's columns. A Binary Tree is the data structure that an index uses (B-Tree).
In MongoDB, indexes play a critical role in ensuring that queries are executed quickly. Basically, if MongoDB doesn't have any indexes specified, it has to scan every document in a given collection. As a result, MongoDB makes use of indexes to decrease the amount of documents that must be scanned in a collection. In truth, the index utilized by MongoDB is very similar to the indexes used by other relational databases.
MongoDB, on the other hand, defines indexes at the collection level and allows indexing on any MongoDB collection field.
The efficient resolution of queries is aided by indexes. MongoDB must scan every document in a collection without indexes to find those that match the query statement. This scan is inefficient and necessitates MongoDB processing a huge amount of data. Indexes are special data structures that store a tiny fraction of the data set in a format that is easy to navigate. The value of a specific field or collection of fields is stored in the index, which is ordered by the field's value as stated in the index.
The createIndex() Method
MongoDB's createIndex() method is used to create an index.
The createIndex() method's basic syntax is as follows: ().
>db.COLLECTION_NAME.createIndex({KEY:1})
The name of the field on which you want to establish an index is key, and 1 indicates ascending order. You must use -1 to construct an index in descending order.
Example
>db.mycol.createIndex({"title":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>
You can supply multiple fields to the createIndex() method to create an index on multiple fields.
>db.mycol.createIndex({"title":1,"description":-1})
>
Types of Indexes in MongoDB
Index Type | Description |
Single field index | Aside from the default _id index, this is used to construct an index on a single field that can be user defined. |
Compound index | User-defined indexes on multiple fields are supported by MongoDB. |
Multi key index | MongoDB stores arrays mostly using multi key indexes. Each element in an array gets its own index in MongoDB. If the index comprises elements from an array, MongoDB intelligently determines that a multi key index should be created. |
Geospatial index | Used to aid in the execution of geospatial coordinate data queries. |
Text index | This index is used to search a collection for string content. |
Hashed index | Sharding based on hashes. |
The dropIndexes() method
This function deletes a collection's numerous (specified) indexes.
Syntax
The following is the fundamental syntax for the DropIndexes() method:()
>db.COLLECTION_NAME.dropIndexes()
Example
Let's pretend we've built two indexes in the called mycol collection, as seen below.
> db.mycol.createIndex({"title":1,"description":-1})
The next example deletes the above-mentioned mycol indexes.
>db.mycol.dropIndexes({"title":1,"description":-1})
{ "nIndexesWas" : 2, "ok" : 1 }
>
Aggregation
Data records are processed and computed results are returned through aggregation processes. Aggregation operations combine values from several documents into a single result and can execute a number of functions on the gathered data. The equivalent of MongoDB aggregation in SQL is count(*) and group by.
The aggregate function groups entries in a collection and can be used to get a total number (sum), average, minimum, maximum, and other values from the group.
Aggregate () is the function to utilize in MongoDB to conduct the aggregate function. The aggregate syntax is as follows:
Db.collection_name.aggregate(aggregate_operation)
Let's have a look at how to use MongoDB's aggregate function. Consider the following data in a collection called books:
Create a book collection using the field names title, price, and type. To list the contents of the collection, use db.books.find().
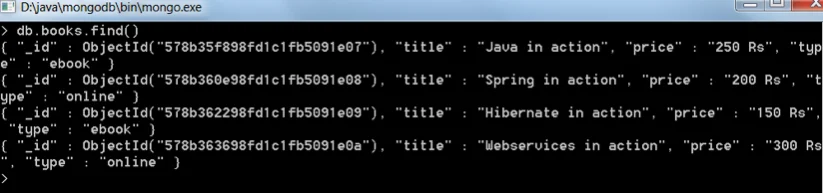
Let us now use the aggregate function to group the books that are of the type ebook and online from the above collection. The command that follows will be used.
Db.books.aggregate([{$group : {_id: "$type", category: {$sum : 1}}}])

The output of the above aggregate function is that there are two records of the type of ebook and two records of the type online. As a result of the aggregation command above, our collection data has been sorted by type.
Different expressions used by Aggregate function
Expression | Description |
$sum | Summarizes all of the documents in a collection's declared values. |
$avg | Calculates the average of all the values in a collection of documents. |
$min | Return the smallest of all document values in a collection. |
$max | Return the sum of all document values in a collection. |
$addToSet | There are no duplicates in the resultant document because values are inserted into an array. |
$push | In the generated document, adds values to an array. |
$first | The first document from the source document is returned. |
$last | The last document from the source document is returned. |
MapReduce
Map-reduce is a data processing methodology for condensing vast amounts of data into useful aggregated output, according to the MongoDB website. For map-reduce operations, MongoDB employs the mapReduce command. Large data sets are typically processed using MapReduce.
MapReduce Command
The basic mapReduce command's syntax is as follows:
>db.collection.mapReduce(
Function() {emit(key,value);}, //map function
Function(key,values) {return reduceFunction}, { //reduce function
Out: collection,
Query: document,
Sort: document,
Limit: number
}
)
The map-reduce function queries the collection first, then maps the results to produce key-value pairs, which are subsequently reduced based on keys with multiple values.
In the preceding syntax,
● A javascript function that maps a value to a key and returns a key-value pair is called map.
● Reduce is a javascript function that groups or reduces all documents that have the same key.
● The location of the map-reduce query result is specified by out.
● The query describes the document selection criteria that can be used.
● sort provides the sort criteria that can be used.
● limit defines the maximum number of documents to be returned, which is optional.
Using MapReduce
Consider the document structure below for storing user posts. The document saves the user's user name as well as the post's status.
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}
We'll now use a mapReduce function on our posts collection to select all current posts, group them by user name, and count the number of posts by each user using the code below.
>db.posts.mapReduce(
Function() { emit(this.user_id,1); },
Function(key, values) {return Array.sum(values)}, {
Query:{status:"active"},
Out:"post_total"
}
)
The mapReduce query above returns the following result:
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}
The map function generated 4 documents with key-value pairs, while the reduction function grouped mapped documents with the same keys into 2.
To see how this map turned out, click here. Use the find operator to simplify your query.
>db.posts.mapReduce(
Function() { emit(this.user_id,1); },
Function(key, values) {return Array.sum(values)}, {
Query:{status:"active"},
Out:"post_total"
}
).find()
The above query returns the following results, indicating that both Tom and Mark have two active postings.
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }
MapReduce queries can be used to build huge complicated aggregating queries in a similar way. MapReduce, which is incredibly versatile and powerful, is used with bespoke Javascript functions.
Replication
The practice of synchronizing data across several servers is known as replication. With numerous copies of data on separate database servers, replication provides redundancy and boosts data availability. Replication safeguards a database against the failure of a single server. You may also recover from hardware failures and service interruptions using replication. You can dedicate one copy of the data to disaster recovery, reporting, or backup if you have extra copies of the data.
Why Replication?
● To ensure the security of your data.
● Data is available 24 hours a day, seven days a week.
● Recovery from a disaster.
● There will be no downtime for maintenance (like backups, index rebuilds, compaction).
● Read about scalability (extra copies to read from).
● The program does not see the replica set.
How Replication Works in MongoDB
MongoDB uses replica sets to achieve replication. A replica set is a collection of mongod instances that all store the identical data. One node is the primary node in a replica, and it gets all write operations. All other instances, such as secondaries, use the primary's actions to ensure they have the same data set. There can only be one primary node in a replica set.
● A replica set is a collection of two or more nodes that are identical (generally minimum 3 nodes are required).
● One node in a replica set is the major node, while the others are secondary.
● From the primary to the secondary node, all data is replicated.
● Election for primary is established during automatic failover or maintenance, and a new primary node is elected.
● After a failed node is recovered, it rejoins the replica set and becomes a secondary node.
The client application constantly interacts with the primary node in a typical MongoDB replication diagram, and the primary node subsequently replicates the data to the subsidiary nodes.
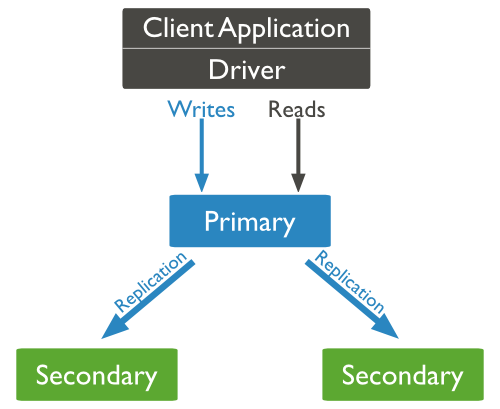
Fig 11: Replication
Replica Set Features
● There are N nodes in this cluster.
● A principal node can be any other node.
● All write operations are sent to the primary.
● Failover occurs automatically.
● Recovery is carried out automatically.
● Primary election by consensus.
Sharding
The process of storing data across numerous machines is known as sharding. The primary goal of this MongoDB feature is to accommodate the predicted data increase of any application. Because, at some point, the accessibility of any program will almost certainly result in an increase in data volume, which will be impossible to support.
Given the difficulty of managing data expansion in a single system, having a cluster holding a replica set of the data is a suitable solution. As a result, horizontal data scaling is essential, which MongoDB achieves through sharding. Sharding is simply the addition of new machines to support an application's sudden or quick expansion of data.
Sharding in MongoDB is Required:
● Vertical scaling is exaggerated.
● All data will be written to the master nodes throughout the data backup procedure.
● The amount of space on the local disk may not be sufficient to accommodate the data expansion.
The diagram below depicts how sharding in a mongodb context works conceptually.
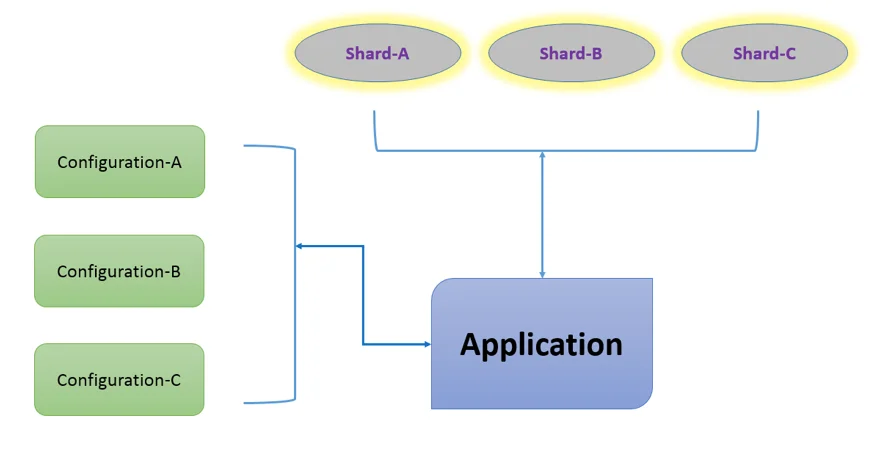
Fig 12: Sharding
Application
A mongodb-based application that requires data to be clustered over numerous servers.
Shards
The actual data is stored in shards. Each shard will be a separate replica set in any production environment.
Configuration
The configured MongoDB servers that store the cluster's metadata are referred to as configuration. The mapping of the cluster's data set to the shards is stored in these configuration servers. For any target operations, the query router will choose a certain shard depending on the metadata. There will be three configuration servers in any production scenario.
Key takeaway
- As we know, MongoDB can be used for a variety of purposes, including building applications (both web and mobile), data analysis, and database administration.
- The CRUD operations that MongoDB provides are a set of basic yet necessary activities that will enable you to interact with the MongoDB server quickly and simply.
- Data records are processed and computed results are returned through aggregation processes.
- Aggregation operations combine values from several documents into a single result and can execute a number of functions on the gathered data.
- Indexes can be readily created by employing one or more of a table's columns.
- Map-reduce is a data processing methodology for condensing vast amounts of data into useful aggregated output, according to the MongoDB website.
- MongoDB uses replica sets to achieve replication.
The evolution of NoSQL databases is inextricably linked to the Big Data phenomenon. This situation is linked to widespread requirements for the storage and administration of massive amounts of highly complex, dynamic, developing, distributed, and heterogeneous data originating from various sources and platforms. Due to the failure of relational databases to appropriately respond to Big Data issues, new databases – NoSQL – had to be developed.
The term "NoSQL" was first used in the modern sense in 2009 as the name of a meetup arranged by Johan Oskarsson. The phrase "NoSQL Meetup" was used to refer to open-source, distributed, non-relational databases. The original plan was to just name the meetup, but the term NoSQL exploded in popularity and was immediately accepted by the IT world as a phrase to describe the new trend in database development.
Despite the fact that the word NoSQL has gained widespread use, there is no globally agreed definition for it. NoSQL databases are “non-relational, distributed, open-source, and horizontally scalable,” according to the NoSQL archive (NoSQL, 2017). In essence, NoSQL is not about abandoning certain software and hardware database architectures; rather, it is about a specific technology since NoSQL solutions are based on a distinct set of objectives and hardware models than relational databases.
The SNSs (social network sites) such as Facebook, Twitter, and YouTube were among the first to be confronted with Big Data issues. SNSs are web-based systems that enable users to create a public or semi-public profile within a confined system, articulate a list of other users with whom they have a connection, and browse and navigate their list of connections as well as those produced by others. They're a type of special-purpose software (or social media tool) that makes it easier to create and maintain social relationships. Some of the most popular social networking sites include Facebook, Twitter, LinkedIn, and Google+.
Users can construct their own social network in a digital world using social networking sites. A social network is a collection of nodes and links generated by social entities, with nodes representing individuals and organizations. Friendships and business relationships, for example, are represented via links. In both the actual and virtual worlds, social networks can exist. Online social networks are the focus of this paper. Online social networks make developing, expanding, and maintaining social relationships simple and rapid, and they quickly attract a large number of people.
NoSQL database
The phrase "NoSQL" refers to a variety of databases. The architecture and purpose of NoSQL databases are distinct. It's natural for NoSQL proponents since they believe there isn't a universal solution that can handle all data types, volumes, and goals. Despite their variances, NoSQL databases share the following characteristics.
● Tables are not basic structures. NoSQL databases store and process data in a variety of formats (key-values, graphs, column family, documents, and tables).
● There are no joins. NoSQL databases eliminate the requirement for joins by allowing data to be processed using simple interfaces.
● They are schema-free. Data manipulation is possible with NoSQL databases without the need for prior modeling (e.g., entity-relational model).
● There are many processors. NoSQL databases allow data to be stored on several processors while maintaining excellent performance.
● They use shared-nothing commodity computers. The majority of NoSQL databases are built on low-cost commodity CPUs with separate random access memory (RAM) and disk storage.
● They support linear scalability. The addition of a larger number of processors results in a gain in performance that is consistent.
● Innovation SQL is one of the alternatives for storing and processing data in NoSQL databases. Supporters of NoSQL advocate for a multifaceted approach, recognizing that there is no single solution to each problem. NoSQL means "not merely SQL" to them.
Different NoSQL database designs are now being used to handle various Big Data concerns, with varying degrees of success. According to this classification, NoSQL databases can be divided into four categories, each of which addresses a distinct type of large data problem:
● Key-Value
● Column-Family
● Document
● Graph
The key-value type of NoSQL databases uses a key to locate a value (for example, traditional data, BLOBs – Binary Large Objects, and files) in simple, standalone tables called hash tables. In this situation, searches are limited to exact matches and are performed against keys rather than values. Amazon DynamoDB, Berkeley DB, Redis, and Riak are some of the most well-known key-value stores.
Column-family or column-oriented NoSQL databases are named for its design, which uses columns to store data. A row-oriented database (relational database), on the other hand, maintains information about a row together. Google BigTable, Apache Cassandra, HBase, Hypertable, and Amazon SimpleDB are some of the most well-known column-family stores.
Document NoSQL stores were created for the purpose of storing and managing documents. Standard data interchange formats such as XML, JSON (JavaScript Object Notation), and BSON are used to encode the documents (Binary JSON). MongoDB, CouchDB, Terrastore, and RavenDB are some of the most well-known document stores.
Graph NoSQL databases are particularly good at dealing with data that is heavily linked. Instead of statistics, they concentrate on relationships. Nodes and their relationships make up a graph storage. Property (or key-value pairs) are used to hold data in both nodes and relationships. Neo4J, Infinite Graph, and FlockDB are a few examples of well-known graph stores.
Social networks sites and data storage
Today, there are a variety of social networking sites (SNSs), but Facebook remains the most popular and has the most users worldwide. Table 1 shows the top five SNSs by estimated unique monthly visitor (eBizMBA, 2017), as well as data from http://www.internet livestats.com/ on active users and uploads on a daily basis, to better understand SNS data storage concerns.
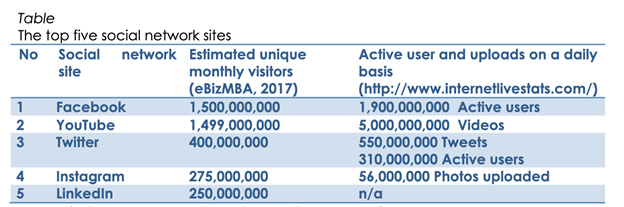
Mark Zuckerberg registered thefacebook.com domain in January of 2004 and thus began the Facebook era. Facebook quickly became a trending issue, and before the end of 2004, it had over one million registered users. Facebook has used a relational MySQL database for data storage since the beginning. However, Facebook's engineers developed Cassandra, a column-family store NoSQL database, after being inspired by Google's publication about the Google BigTable NoSQL database. Cassandra was open-sourced by Facebook in 2008, however it was never developed further.
Although Jawed Karim, one of the YouTube founders, posted the first video in April 2005, the YouTube era officially began in December 2005. However, in February 2006, YouTube had over 20,000 daily uploads (Telegraph, 2010). In terms of databases, YouTube, like Facebook, began with MySQL databases. In the following years, YouTube created Vitess, a bespoke tool built on top of a MySQL database. Since 2011, Vitess has been servicing all YouTube database traffic.
The first tweet on Twitter was posted by Jack Dorsey, one of the company's co-founders, in March 2006. However, in 2007, a massive increase in Twitter usage was seen (MacArthur, 2016). Twitter has made major contributions to a number of open-source databases throughout the years. However, the outcome was unsatisfactory. Firefighting production systems to match the performance demands of Twitter's many products took far too much time, and setting up new storage capacity for a use case required far too much manual work and process.
Instagram is a relatively new social media platform. It was the first photo social platform, and it debuted in October of 2010. Instagram has experienced rapid growth since its inception. It reached one million members barely two months after its introduction and has continued to expand since then.
In 2003, LinkedIn was founded. The introduction of address book uploads in late 2003 increased growth, which had been modest at first (LinkedIn, 2017). LinkedIn has been steadily improving its data architecture in order to support long-term development. LinkedIn uses the Espresso and Voldemort databases for data storage.
Discussion: NoSQL databases as SNSs storage system
The majority of the top five SNSs still employ relational databases, mostly MySQL, according to an analysis of their storage systems. However, all of the SNSs examined use NoSQL databases to some extent. The majority of them created their own NoSQL databases (Facebook, Twitter) and contributed heavily to the development of open-source NoSQL databases (HBase, Cassandra, Voldemort). But why haven't SNSs made full conversions to NoSQL databases, which were designed to address Big Data issues that large web sites faced? The solution to this query is most likely found in the following NoSQL properties –
- A large variety of different NoSQL databases are available. Although NoSQL databases have matured over the last 10 years, the majority of key functionalities have yet to be implemented or tested in a real-world setting.
- Standardization is lacking. Because NoSQL is a catch-all word for a wide range of products, the design, data store, query languages, and other elements of NoSQL databases differ significantly. As a result, the learning curve for NoSQL databases is longer, because a developer who is experienced with one type of NoSQL database may not always be ready to work with another. This is a significant impediment to greater NoSQL adoption.
- Provide a very rapid and efficient “insert-read-update-delete” cycle to meet the expectations of Web 2.0 applications. However, if business intelligence and analytics tools are required, a dilemma develops.
- On a worldwide basis, vendors provide assistance. Because most NoSQL databases are open source and only a few companies provide support, they lack the trustworthiness that established relational database manufacturers (Oracle, Microsoft, IBM) enjoy (Richards, 2015).
References:
- Silberschatz A., Korth H., Sudarshan S., "Database System Concepts", McGraw Hill Publishers, ISBN 0-07-120413-X, 6th edition
- Kristina Chodorow, Michael Dierolf, “MongoDB: The Definitive Guide”, O‘Reilly Publications, ISBN: 978-1-449-34468-9
- Adam Fowler, “NoSQL for Dummies”, John Wiley & Sons, ISBN-1118905628
- Kevin Roebuck, “Storing and Managing Big Data - NoSQL, HADOOP and More”, Emereopty Limited, ISBN: 1743045743, 9781743045749
- Joy A. Kreibich, “Using SQLite”, O'REILLY, ISBN: 13:978-93-5110-934-1




