Unit - 6
Computability and Complexity Theory
If we can always create a comparable algorithm that can correctly answer the problem, the problem is said to be Decidable. By considering a basic example, we may immediately comprehend Decidable problems. Let's say we're asked to find all the prime numbers between 1000 and 2000. We can easily build an algorithm to enumerate all the prime numbers in this range in order to solve this challenge.
In terms of a Turing machine, a problem is said to be Decidable if there is a matching Turing machine that halts on every input with a yes or no answer. It's also worth noting that these issues are referred to as Turing Decidable since a Turing machine always comes to a halt on every input, accepting or rejecting it.
Example
We'll take a look at a couple key Decidable issues now:
● Is it possible to compare two regular languages, L and M?
Using the Set Difference technique, we can quickly verify this.
L-M =Null and M-L =Null.
Hence (L-M) U (M-L) = Null, then L, M are equivalent.
● Are you a CFL member?
Using a dynamic programming approach, we can always determine whether a string occurs in a particular CFL.
● A CFL's emptiness
By examining the CFL's production rules, we can quickly determine whether or not the language generates any strings.
Undecidable problem
Undecidable Problems are those for which we can't come up with an algorithm that can solve the problem correctly in a finite amount of time. These issues may be partially solvable, but they will never be completely solved. That is to say, there will always be a condition that causes the Turing Machine to go into an infinite loop without giving a response.
Consider Fermat's Theorem, a well-known Undecidable Problem that claims that no three positive numbers a, b, and c for any n>2 can ever meet the equation: a^n + b^n = c^n.
If we submit this problem to a Turing machine to discover a solution that produces a contradiction, the Turing machine could run indefinitely to find the appropriate values for n, a, b, and c. However, we are never clear whether a contradiction occurs, hence we call this problem an Undecidable Problem.
Example
Here are a few significant Undecided Issues:
● Is it true that a CFG generates all of the strings?
We can never reach the last string because a CFG generates infinite strings, hence it is undecidable.
● Is there a difference between two CFG L and M?
We can forecast if two CFGs are equal or not since we cannot determine all of the strings of any CFG.
● CFG's ambiguity?
There is no algorithm that can determine whether a CFL is ambiguous. We can only determine whether the CFL is ambiguous if any given string yields two separate parse trees.
● Is it possible to convert an ambiguous CFG into its non-ambiguous counterpart?
It's also an Insolvable Problem because there's no solution for converting ambiguous CFLs to non-ambiguous CFLs.
● Is it possible to learn a language that is a CFL on a regular basis?
This is an undecidable problem since we can't tell whether the CFL is regular or not from the production rules.
Key takeaway
- If there is no Turing machine that will always cease in a finite amount of time to deliver a yes or no answer, the problem is undecidable.
- There is no technique for determining the answer to an undecidable problem for a given input.
In 1936, a technique named as lambda-calculus was created by Alonzo Church
Within which the Church numerals area unit well outlined, i.e., the encryption of
Natural numbers. Additionally in 1936, mathematician machines (earlier known as
Theoretical model for machines) was created by mathematician, that’s used for
Manipulating the symbols of string with the assistance of tape.
Church - Turing Thesis:
Turing machine is outlined as associate degree abstract illustration of a computer
Like hardware in computers. Mathematician planned Logical Computing Machines
(LCMs), i.e., mathematician’s expressions for Turing Machines. This was done to
Outline algorithms properly. So, Church created a mechanical methodology named
As ‘M’ for manipulation of strings by mistreatment logic and arithmetic.
This methodology M should pass the subsequent statements:
• Number of directions in M should be finite.
• Output ought to be made when playing a finite variety of steps.
• It mustn’t be imagined, i.e., is created in the world.
• It doesn't need any complicated understanding.
Using these statements Church planned a hypothesis known as Church’s
Mathematician thesis that may be expressed as: “The assumption that the intuitive
The notion of estimable functions is known with partial algorithmic functions.”
In 1930, this statement was initially developed by Alonzo Church and is typically
Brought up as Church’s thesis, or the Church-Turing thesis. However, this hypothesis
Cannot be proved.
The algorithmic functions are estimable when taking the following assumptions:
1. Every and each operate should be estimable.
2. Let ‘F’ be the estimable operation and when playing some elementary operations to ‘F’, it’ll rework a replacement operation ‘G’ then this operates ‘G’ mechanically becomes the estimable operation.
3. If any operates that follow on top of 2 assumptions should be states as
Estimable function.
What Justifies the Church-Turing Thesis?
Stephen Kleene who coined the term “Church-Turing thesis” catalogued four sorts of argument for CTT-O:
Initial, the argument from non-refutation points out the thesis has ne’er been refuted, despite sustained (and ongoing) makes an attempt to search out a disproof (such because the makes an attempt by László Kalmár and, additional recently, by Doukas Kapantais).
Second, the argument from confluence points to the very fact that the assorted characterizations of computability, whereas differing in their approaches and formal details, end up to comprehend the exact same category of estimable functions. Four such characterizations were bestowed (independently) in 1936 and like a shot proved to be extensionally equivalent: mathematician computability, Church’s -definability, Kleene’s algorithmic functions, and Post’s finitary combinatory processes.
Third is associate degree argument typically brought up today as “Turing’s analysis.” mathematician known as it merely argument “I”; stating 5 terribly general and intuitive constraints or axioms the human pc is also assumed to satisfy: “The behavior of the pc at any moment is set by the symbols that he’s perceptive, associate degreed his “state of mind” at that moment”.
The second part of mathematician’s argument I may be a demonstration that every operate computed by any human pc subject to those constraints is additionally estimable by a computing machine; it’s not tough to visualize that every of the computer’s steps are mimicked by the Turing machine, either during a single step or by means of a series of steps.
Fourth during this catalog of issues supporting CTT-O area unit arguments from first order logic. They’re typified by a 1936 argument of Church’s and by Turing’s argument II, from Section nine of Turing’s 1936 paper. In 2013, Saul Kripke bestowed a reconstruction of Turing’s argument II, which works as follows:
Computation may be a special variety of mathematical deduction; each|and each} mathematical deduction and thus every computation can be formalized as a legitimate deduction within the language of first-order predicate logic with identity (a step Kripke brought up as “Hilbert’s thesis”); following Gödel’s completeness theorem, every computation is so formalized by an obvious formula of first-order logic; and each computation will thus be disbursed by the universal computing machine. This last step concerning the universal computing machine is secured by a theorem proved by Turing: each obvious formula of first-order logic is proved by the universal computing machine.
The third and fourth of those arguments offer justification for CTT-O however not for CTT-A. As Robin Gandy found out, the third argument Turing’s contains “crucial steps wherever he [Turing] appeals to the very fact that the calculation is being disbursed by a person’s being.” as an example, mathematician assumed “a soul will solely write one image at a time,” associate degreed Gandy noted this assumption cannot be carried over to a parallel machine that “prints a discretionary variety of symbols at the same time.” In Conway’s Game of Life, for example, there’s no edge on the amount of cells that conjure the grid, nevertheless the symbols altogether the cells area unit updated at the same time. Likewise, the fourth argument (Turing’s II) involves the claim that computation may be a special variety of formal proof, however the notion of proof is in and of itself associated with what a person’s mathematicians and not some oracle can prove.
It is thus perhaps not too surprising that the third and fourth arguments in this catalog seldom if ever appear in logic and computer science textbooks. The two arguments that are always given for the Church-Turing thesis (in, for example, Lewis and Papadimitriou are confluence and non-refutation. Yet both those arguments are merely inductive, whereas the third and fourth arguments are deductive in nature.
However, a number of attempts have sought to extend Turing’s axiomatic analysis to machine computation; for example, Gandy broadened Turing’s analysis in such a way that parallel computation is included, while Dershowitz and Gurevich gave a more general analysis in terms of abstract state machines. We return to the topic of extending the analysis to machine computation later in this article but first address the important question of whether CTT-O is mathematically provable.
Key takeaway:
- Turing machine is outlined as associate degree abstract illustration of a computer like hardware in computers.
- A common one is that a Turing machine can perform any good computation.
- The Church-Turing thesis is often misunderstood, especially in the philosophy of mind in recent writing.
If (1) L is not recursively enumerable or (2) L is recursively enumerable but not recursive, then L is undecidable.
The diagonal language Ld is not recursively enumerable, while the universal language Lu is recursively enumerable but not recursive, as we have proved. We may utilize the undecidability of these two languages to demonstrate that a number of Turing machine issues are unsolvable:
● Define Le to be {M | L(M) = ∅}. We can show that Le is not recursively enumerable.
● Define Lne to be {M | L (M) ≠ ∅}. Lne is the complement of Le. We can show that Lne is recursively enumerable but not recursive.
● It's worth noting that we just stated that Lne isn't recursive. Because Le and Lne are complements of each other, if Le were recursively enumerable, both it and Lne would be recursive. This is why Le cannot be enumerated in a recursive manner.
● The Halting Problem
○ Acceptance of Turing machines in Alan Turing's original conception was simply by halting, not necessarily by halting in a final state.
○ For a Turing machine, we can define H(M). M is the set of input strings w for which M comes to a halt in either a final or non-final state on w.
○ The set of pairings {(M, w) | w is in H(M)} is a well-known halting problem. The halting problem can be shown to be recursively enumerable but not recursive.
Any nontrivial attribute of Turing machines that depends exclusively on the language that the TM accepts must be undecidable, according to "Rice's Theorem." The recursively enumerable languages have the attribute of being a collection of recursively enumerable languages.
If a property is either the empty language or the set of all recursively enumerable languages, it is said to be trivial; otherwise, it is said to be nontrivial. The fact that a language is context free is an example of a nontrivial quality. As a result of Rice's Theorem, determining whether a Turing machine's recognized language is context free is impossible.
In this segment, we'll go over all of the Turing machine's unsolved issues. The reduction is used to demonstrate whether or not a given language is desirable. We will first learn about the concept of reduction in this section, and then we will look at a key theorem in this area.
Reduction
If a problem P1 is reduced to a problem P2, then any solution to P2 solves P1. In general, a P1 reduced P2 algorithm is one that converts an instance of a problem P1 to an instance of a problem P2 that has the same answer. As a result, if P1 is not recursive, neither is P2. Similarly, if P1 is not recursively enumerable, then neither is P2.
Theorem: When P1 is decreased to P2, the result is -
1. If P1 is inconclusive, then P2 is equally inconclusive.
2. If P1 isn't RE, then P2 isn't either.
Proof:
- Consider the case w of P1. Then create an algorithm that accepts instance w as an input and changes it to instance x of P2. After that, use that algorithm to see if x is in P2. If the algorithm returns 'yes,' then x is in P2. We may also state that w is in P1 if the algorithm returns 'yes.' P2 has been obtained after P1 has been reduced. Similarly, if the algorithm returns 'no,' then x is not in P2 and w is not in P1. This demonstrates that if P1 is undecidable, then P1 is undecidable as well.
- P1 is assumed to be non-RE, while P2 is assumed to be RE. Create an algorithm to decrease P1 to P2, however only P2 will be recognized by this algorithm. That means a Turing machine will say 'yes' if the input is in P2, but may or may not halt if the input is not in P2. We know that an instance of w in P1 can be converted to an instance of x in P2. After then, use a TM to see if x is in P2. If x is approved, then w must likewise be accepted. This procedure explains a TM that speaks the P1 language. If w is in P1, then x is in P2, and vice versa. If w is not in P1, then x is not in P2. This establishes that if P1 is non-RE, then P2 must be non-RE as well.
A complexity class is often described by (1) a computation model, (2) a resource (or set of resources), and (3) a function called the complexity bound for each resource.
Machine-based models and circuit-based models are the two basic types of models used to establish complexity classes. The two most common machine models are Turing machines (TMs) and random-access machines (RAMs).
Deterministic machines and circuits are our closest links to reality when modeling real computations. Then why think about other types of machines? There are two major causes for this.
The most compelling rationale stems from the computational challenges we're attempting to comprehend. Hundreds of natural NP-complete problems are the most well-known instances. It is thanks to the paradigm of nondeterministic Turing computers that we have any understanding of the intricacy of these challenges.
Nondeterministic machines don't represent physical compute devices, but they do represent real-world challenges. There are numerous such instances in which a specific model of computing has been proposed to capture a well-known computational problem in a complexity class.
The second reason is interconnected with the first. Our desire to comprehend real-world computational challenges has compelled us to develop a repertory of computation models and resource limitations. We combine and mix various models and boundaries in an attempt to uncover their relative power in order to better grasp their interactions.
Consider, for example, nondeterminism. Researchers were naturally led to the concept of alternating machines by analyzing the complements of languages allowed by nondeterministic computers. When alternating and deterministic machines were compared, it was discovered that deterministic space and alternating time have a startling virtual identity.
For deterministic and nondeterministic Turing computers, we begin by highlighting the fundamental resources of time and space. We focus on resource limitations between logarithmic and exponential since these constraints have proven to be the most beneficial in understanding real-world challenges.
The following fundamental time and space classes are given by the functions t(n) and s(n):
DTIME[t(n)] - is the language class determined by deterministic Turing machines with time complexity t (n).
NTIME[t(n)] - is the language category determined by nondeterministic Turing computers with time complexity t (n).
DSPACE[s(n)] - is the language category determined by deterministic Turing computers with space complexity s (n).
NSPACE[s(n) - is the language category determined by nondeterministic Turing computers with space complexity s (n).
● The P class solves the problem of deterministic computation.
● P class is used to solve the problems that are solvable in polynomial run time.
● The problem belongs to class P if it’s easy to find a solution for the problem.
● This problem can be solved by the worst case in O(nK) where k is constant.
● The problems which are solved by P class are known as tractable problems and others are known as intractable or super polynomial.
● If the polynomial time is P(n) then the algorithm can solve in time O (P(n)) with input size n.
● The advantage of the class of polynomial time algorithms is that all reasonable deterministic single processor models of computation can be simulated on each other with at most polynomial slow-d.
Example of problems in P
We saw before that the problem of palindrome recognition may be solved in linear time, which is definitely polynomial time.
A palindrome is a string that has the same length as its reversal. A palindrome is, for example, aabcbaa. Let's start with the basics.
PALINDROME = {x | x ∈ {a, b, c}* and x is a palindrome}
The fact that PALINDROME is in P is obvious. Simply reverse x and see if the reversal of x equals x to see if it's a palindrome.
String matching
The problem with string matching is as follows:
Input. Two strings, p and t.
Question. Does p occur as a contiguous substring of t?
If p = rocket and t = The rocketry specialist is in the room, the answer is yes.
One approach simply checks each point in t for the presence of p. It keeps running until it finds a match or the positions it can try are exhausted.
The rocketry expert is here.
Rocket
Rocket
Rocket
Rocket
Rocket
Assume p has a length of u and t has a length of v. There is v − u + 1 positions to experiment with. Each position can be checked in as few as u steps. As a result, the entire amount of time is proportional to u (v − u + 1).
Because n ≈ u + v, the cost is largest when v is around 2u, implying that u ≈ n/3. The time is then approximately (n/3) (n/3), which is O(n2).
Class NP
● The NP class solves the problem of non-deterministic computation.
● The problem belongs to NP, if it’s easy to check a solution that may have been very tedious to find.
● It solves the problem which is verifiable by polynomial time.
● It is a class of decision problems.
● For using this class, it is easy to check the correctness of the claimed answer even if it has extra information added in it.
● Hence it is used to verify the solution is correct, not for finding the solution.
● If there is a problem in this class then it can be solved by exhaustive search in exponential time.
Problems that can be verified in polynomial time are classified as NP. With the use of a little extra knowledge, it is possible to check the accuracy of a claimed answer in the NP class of decision problems. As a result, we're not looking for a technique to find a solution; rather, we're looking for a way to verify that an asserted solution is right.
Using exhaustive search, every problem in this class may be solved in exponential time.
Example of problem in NP
NP problem - Assume you're given a DECISION-BASED challenge in which you can get a high output from a collection of high inputs.
NP-hard or NP-complete criteria are available.
- The important point to remember here is that the output has already been provided, and you may verify the output/solution in polynomial time but not make one.
- We need the notion of reduction here because if you can't produce an output of the problem based on the given input, you'll need to rely on the concept of reduction, which allows you to turn one problem into another.
As a result, you can make a yes or no decision based on the given decision-based NP problem. If you answered yes, you must validate and turn the problem into a new one using the reduction principle. Both decision-based NP problems and NP compete if you are being performed.
We'll focus on NPC in this portion.
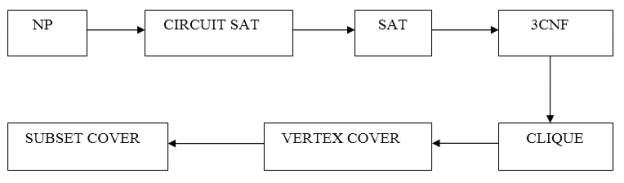
NP Completeness
● NP complete class is used to solve the problems of no polynomial time algorithm.
● If a polynomial time algorithm exists for any of these problems, all problems in NP would be polynomial time solvable. These problems are called NP-complete.
● The phenomenon of NP-completeness is important for both theoretical and practical reasons.
● Following are the no polynomial run time algorithm:
- Hamiltonian cycles
- Optimal graph coloring
- Travelling salesman problem
- Finding the longest path in graph, etc.
Application of NP complete class
- Clique
● A clique is a complete subgraph which is made by a given undirected graph.
● All the vertices are connected to each other i.e.one vertex of an undirected graph is connected to all other vertices in the graph.
● There is the computational problem in clique where we can find the maximum clique of graph, this known as max clique.
● Max clique is used in many real-world problems and in many applications.
● Assume a social networking where peoples are the vertices and they all are connected to each other via mutual acquaintance that becomes edges in graph.
● In the above example clique represents a subset of people who know each other.
● We can find max clique by taking one system which inspect all subsets.
● But the brute force search is too time consuming for a network which has more than a few dozen vertices present in the graph.
Example:
● Let's take an example where 1, 2, 3, 4, 5, 6 are the vertices that are connected to each other in an undirected graph.
● Here the subgraph contains 2,3,4,6 vertices which form a complete graph.
● Therefore, the subgraph is a clique.
● As this is a complete subgraph of a given graph. So, it’s a 4-clique.
Analysis of Clique Algorithm
● Non-deterministic algorithms use max clique algorithms to solve problems.
● In this algorithm we first find all the vertices in the given graph.
● Then we check if the graph is complete or not i.e., all vertices should form a complete graph.
● The no polynomial time deterministic algorithm is used to solve this problem, which is known as NP complete.
2. Vertex Cover
● A vertex-cover of an undirected graph G = (V, E) is a subset of vertices V' ⊆ V such that if edge (u, v) is an edge of G, then either u in V or v in V' or both.
● In a given undirected graph we need to find the maximum size of vertex cover.
● It is the optimization version of NP complete problems.
● It is easy to find vertex cover.
Example:
Given graph with set of edges are
{(1,6), (1,2), (1,4), (2,3), (2,4), (6,7), (4,7), (7,8), (3,8), (3,5), (8,5)}
Now, start by selecting an edge (1, 6).
Eliminate all the edges, which are either incident to vertex 1 or 6 and add edge (1, 6) to cover.
In the next step, we have chosen another edge (2, 3) at random
Now we select another edge (4, 7).
We select another edge (8, 5).
Hence, the vertex cover of this graph is {1, 2, 4, 5}.
Analysis of Vertex Cover Algorithm
● In this algorithm, by using an adjacency list to represent E it is easy to see the running time of this algorithm is O (V+E).
P problem Versus NP problem
A polynomial time non-deterministic algorithm can solve any decision issue that can be solved by a deterministic polynomial time algorithm.
In P, all problems can be solved with polynomial time techniques, whereas in NP - P, all issues are intractable.
It's unclear whether P Equals NP. Many issues in NP, on the other hand, have the property that if they belong to P, then P = NP may be proven.
If P ≠ NP, there are issues in NP that do not exist in either P or NP-Complete.
If finding a solution to the problem is simple, the problem belongs to class P. If it's simple to check a solution that may have taken a long time to find, the problem is NP.
NP completeness and NP hard problems
● A problem is in the class NPC if it is in NP and is as hard as any problem in NP.
● A problem is NP-hard if all problems in NP are polynomial time reducible to it, even though it may not be in NP itself.
● The problem in NP-Hard cannot be solved in polynomial time, until P = NP.
● If a problem is proved to be NPC, there is no need to waste time on trying to find an efficient algorithm for it.
● Instead, we can focus on design approximation algorithms.
● Following are the NP hard class problems:
- Circuit satisfiability problem
- Set cover
- Vertex cover
- Travelling salesman problem
● The following are some NP-Complete issues for which there is no polynomial-time solution.
- Identifying whether or not a graph contains a Hamiltonian cycle.
- Whether a Boolean formula is satisfiable, and so on.
Key takeaway
- The P class solves the problem of deterministic computation.
- The problem belongs to NP, if it’s easy to check a solution that may have been very tedious to find.
- NP complete class is used to solve the problems of no polynomial time algorithm.
- A problem is in the class NPC if it is in NP and is as hard as any problem in NP.
Introduction
NP-Hard issues (say X) can only be solved if and only if an NP-Complete solution exists. The Traveling Salesman Problem (TSP) is a classic combinatorial optimization problem that is straightforward to formulate but extremely complex to solve. The goal is to discover the shortest path through a set of N vertices while visiting each vertex precisely once. Because the number of alternative routes grows factorial with the number of cities, this problem is known to be NP-complete and cannot be solved exactly in polynomial time. In other words, there are 5! (120) possible routes for 5 cities, and 6! (120) routes for 6 cities (720).
In this case, a salesman visiting the 15 European capitals would have 1,307,674,368,000 (nearly 1.3 trillion) alternative routes to consider. Due to computer memory and speed limits, the old approach has become impractical. As a result, several scholars use heuristic, meta heuristic, and optimum methods such as dynamic programming and linear programming to solve this problem. In this work, the traveling salesman problem is addressed using a linear programming approach, just like an assignment problem. Due to the limits, the salesman is only allowed to enter and exit each city once. The assignment model, unfortunately, might lead to infeasible solutions.
The TSP (traveling salesman problem) is one of the most well-known problems in all of computer science. It's a problem that's simple to state but impossible to solve. In fact, whether or not it is possible to solve all TSP instances efficiently remains an unresolved subject.
Review
The Traveling Salesman Problem (TSP) is an interesting topic that has received a lot of attention from mathematicians and computer scientists. To tackle the TSP problem, many ways have been tried. Polynomial-sized linear programming formulation, Genetic Algorithm, a mixed integer linear programming formulation and dynamic programming, NP–complete problem, and Neural Network are just a few of them. The multiple traveling salesman problem (mTSP) is a generalization of the well-known traveling salesman problem (TSP), in which the solution might include more than one salesperson.
Researchers have proposed a variety of heuristic methods, including genetic algorithms (GAs), for solving TSP in the past. Knowledge-based multiple inversion and knowledge-based neighbourhood swapping GA algorithms, hybridized GA for integrated TSP and quadratic assignment problem, two-level GA for clustered TSP and large-scale TSP, and parallel GA program implementation on multicomputer clusters are some of the recently studied approaches to solve TSP.
The issue is as follows. Assume you're a traveling salesman with a list of cities you'd want to visit. You intend to visit each city only once. Naturally, you want to visit all of the cities in the sequence that needs the least amount of travel time.
Assume you're visiting the following four cities:
0 1
2 3
You always start, and end, at 0, your home city. We assume the following distances between cities:
Dist(0, 1) = 10
Dist(0, 2) = 10
Dist(0, 3) = 14
Dist(1, 2) = 14
Dist(1, 3) = 10
Dist(2, 3) = 10
The distances are symmetric in this example, so dist(a, b) is always the same as dist(a, b) (b, a). So, for example, we know that dist(3, 2) = 10 because dist(2, 3) = 10.
Here are some city excursions to choose from:
0 to 1 to 3 to 2 (and back to 0); total distance = 10 + 10 + 10 + 10 = 40
Or:
0 to 2 to 3 to 1 (and back to 0); total distance = 10 + 10 + 10 + 10 = 40
Or:
0 to 3 to 1 to 2 (and back to 0); total distance = 14 + 10 + 14 10 = 48
Or:
0 to 2 to 1 to 3 (and back to 0); total distance = 10 + 14 + 10 + 14 = 48
Some excursions are clearly shorter than others. It's easy to see that the quickest method to visit all four cities is to go around the perimeter and avoid the long diagonals in this modest four-city example.
However, not all TSP instances are as basic or as small. Let's say you wish to visit every one of Canada's 4600+ cities. It's not clear how you'd go about finding the shortest tour feasible of so many cities.
Planning our program
Let's take a look at our program's overall structure and organization.
To begin, we'll assume that the cities have names ranging from 0 to n -1, and that a tour of these n cities is a permutation of the integers 0 to n -1. We assume that 0 is the starting point for all excursions, and that all tours begin with 0.
Second, we require a method for storing the cities. Because our cities are on a two-dimensional map, we can use the Point class from previous notes to store them as (x, y) points. The cities will be stored as a vector, with each city's name equaling its index number in the vector, i.e. the city at index location 0 will be named 0, the city at index location 1 will be named 1, and so on.
A function to compute the distance between two cities, as well as a method to determine the total length of a city tour, will be required. So, let's create a class named Tsp map whose sole purpose is to handle such details. A Tsp map object will store a list of cities, as well as distance-calculating functions and possibly other auxiliary functions.
Distance between the points (x, y) and (a, b) is given by this formula:
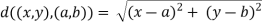
Third, let's agree that a tour (i.e. a permutation of city names) should be represented as a vectorint>. The numbers in it indicate the names of the cities in a specific Tsp map, and the sequence in which the cities are visited is determined by the numbers.
References:
- Daniel Cohen, “Introduction to Computer Theory”, Wiley & Sons, ISBN 97881265133454
- Sanjeev Arora and Boaz Barak, “Computational Complexity: A Modern Approach”, Cambridge University Press, ISBN: 0521424267 97805214242643
- John Martin, “Introduction to Languages and The Theory of Computation”, 2nd Edition, McGraw-Hill Education, ISBN-13: 978-1-25-900558-9, ISBN-10: 1-25-900558-5
- J.Carroll & D Long, “Theory of Finite Automata”, Prentice Hall, ISBN 0-13-913708-45
- Http://www.cs.ecu.edu/karl/6420/spr16/Notes/P/examples.html




