Unit V
Applied Statistics
Method of Least Squares
Let 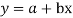 Be the straight line to be fitted to the given data points 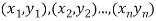 Let  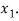 Then, 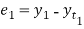 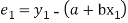 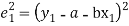 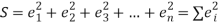  For S to be minimum 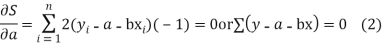 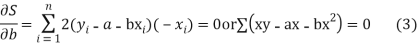 On simplification equation (2) and (3) becomes  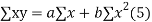 The equation (3) and (4) are known as Normal equations. On solving ( 3) and (4) we get the values of a and b (b)To fit the parabola 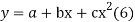 The normal equations are 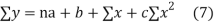   On solving three normal equations we get the values of a,b and c.
|
Example. Find the best values of a and b so that y = a + bx fits the data given in the table
x | 0 | 1 | 2 | 3 | 4 |
y | 1.0 | 2.9 | 4.8 | 6.7 | 8.6 |
Solution.
y = a + bx
x | y | Xy | 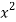 |
0 | 1.0 | 0 | 0 |
1 | 2.9 | 2.0 | 1 |
2 | 4.8 | 9.6 | 4 |
3 | 6.7 | 20.1 | 9 |
4 | 8.6 | 13.4 | 16 |
 | 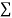 | 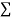 | 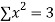 |
Normal equations,  y= na+ b
y= na+ b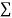 x (2)
x (2)

On putting the values of 

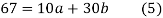
On solving (4) and (5) we get,
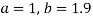
On substituting the values of a and b in (1) we get

Example. By the method of least squares, find the straight line that best fits the following data :
x | 1 | 2 | 3 | 4 | 5 |
y | 14 | 27 | 40 | 55 | 68 |
Solution. Let the equation of the straight line best fit be y = a + bx. (1)
x | y | x y |  |
1 | 14 | 14 | 1 |
2 | 27 | 54 | 4 |
3 | 40 | 120 | 9 |
4 | 55 | 220 | 16 |
5 | 68 | 340 | 25 |
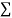 |  |  |  |
Normal equations are 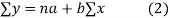
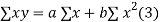
On putting the values of  x,
x, 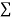 y,
y,  xy and
xy and 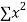 in (2) and (3) we have
in (2) and (3) we have


On solving equations (4) and (5) we get
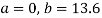
On substituting the values of (a) and (b) in (1) we get,

Example. Find the least squares approximation of second degree for the discrete data
x | 2 | -1 | 0 | 1 | 2 |
y | 15 | 1 | 1 | 3 | 19 |
Solution. Let the equation of second degree polynomial be 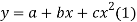
x | y | Xy | 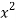 | 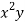 |  |  |
-2 | 15 | -30 | 4 | 60 | -8 | 16 |
-1 | 1 | -1 | 1 | 1 | -1 | 1 |
0 | 1 | 0 | 0 | 0 | 0 | 0 |
1 | 3 | 3 | 1 | 3 | 1 | 1 |
2 | 19 | 38 | 4 | 76 | 8 | 16 |
 | 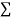 | 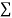 |  |  |  |  |
Normal equations are 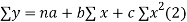
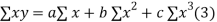
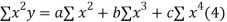
On putting the values of 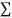 x,
x, 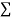 y,
y, xy,
xy, 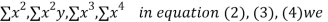 have
have
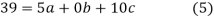
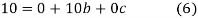

On solving (5),(6),(7), we get, 
The required polynomial of second degree is
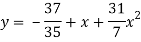
Key takeaways-
 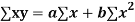  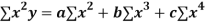 |
Change of scale
If the data is of equal interval in large numbers then we change the scale as 
Example. Fit a second degree parabola to the following data by least square method:
x | 1929 | 1930 | 1931 | 1932 | 1933 | 1934 | 1935 | 1936 | 1937 |
y | 352 | 356 | 357 | 358 | 360 | 361 | 365 | 360 | 359 |
Solution. Taking 
Taking 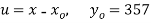
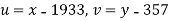
The equation 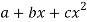 is transformed to
is transformed to 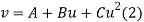
x |  | y |  | Uv | 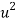 | 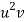 | 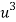 | 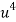 |
1929 | -4 | 352 | -5 | 20 | 16 | -80 | -64 | 256 |
1930 | -3 | 360 | -1 | 3 | 9 | -9 | -27 | 81 |
1931 | -2 | 357 | 0 | 0 | 4 | 0 | -8 | 16 |
1932 | -1 | 358 | 1 | -1 | 1 | 1 | -1 | 1 |
1933 | 0 | 360 | 3 | 0 | 0 | 0 | 0 | 0 |
1934 | 1 | 361 | 4 | 4 | 1 | 4 | 1 | 1 |
1935 | 2 | 361 | 4 | 8 | 4 | 16 | 8 | 16 |
1936 | 3 | 360 | 3 | 9 | 9 | 27 | 27 | 81 |
1937 | 4 | 350 | 2 | 8 | 16 | 32 | 64 | 256 |
Total | 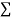 |
| 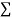 | 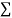 | 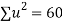 | 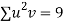 | 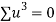 | 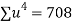 |
Normal equations are
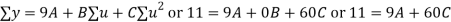 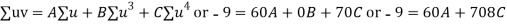 On solving these equations we get  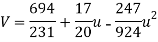 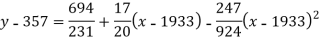  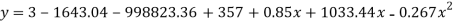 
|
Example. Fit a second degree parabola to the following data.
x=1.0 | 1.5 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 |
y=1.1 | 1.3 | 1.6 | 2.0 | 2.7 | 3.4 | 4.1 |
Solution. We shift the origin to (2.5, 0) antique 0.5 as the new unit. This amounts to changing the variable x to X, by the relation X = 2x – 5.
Let the parabola of fit be y = a + bX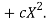 The values of
The values of  X etc. Are calculated as below:
X etc. Are calculated as below:
x | X | y | Xy |  | 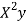 |  |  |
1.0 | -3 | 1.1 | -3.3 | 9 | 9.9 | -27 | 81 |
1.5 | -2 | 1.3 | -2.6 | 4 | 5.2 | -5 | 16 |
2.0 | -1 | 1.6 | -1.6 | 1 | 1.6 | -1 | 1 |
2.5 | 0 | 2.0 | 0.0 | 0 | 0.0 | 0 | 0 |
3.0 | 1 | 2.7 | 2.7 | 1 | 2.7 | 1 | 1 |
3.5 | 2 | 3.4 | 6.8 | 4 | 13.6 | 8 | 16 |
4.0 | 3 | 4.1 | 12.3 | 9 | 36.9 | 27 | 81 |
Total | 0 | 16.2 | 14.3 | 28 | 69.9 | 0 | 196 |
The normal equations are
7a + 28c =16.2; 28b =14.3;. 28a +196c=69.9
Solving these as simultaneous equations we get
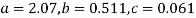

Replacing X bye 2x – 5 in the above equation we get
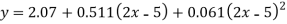
Which simplifies to y =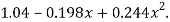 This is the required parabola of the best fit
This is the required parabola of the best fit
Significance test of a sample mean
Given a random small sample  from a normal population we have to test the hypothesis that mean of the population is μ. For this we first calculate
from a normal population we have to test the hypothesis that mean of the population is μ. For this we first calculate 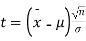
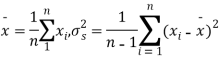 |
Then find the value of P for the given df from the table.
If the calculated value of  the difference between
the difference between  and μ is said to be significant at 5% level of significance.
and μ is said to be significant at 5% level of significance.
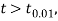 the difference is said to be significant at 1% level of significance.
the difference is said to be significant at 1% level of significance.
If 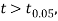 the data is said to be the consistent with the hypothesis that μ is the mean of the population.
the data is said to be the consistent with the hypothesis that μ is the mean of the population.
Example. A certain stimulus administered to each of 12 patients resulted in the following increases off blood pressure: 5, 2, 8, -1, 3, 0, -2, 1, 5, 0, 4, 6. Can it be concluded that the stimulus will in general be accompanied by an increase in blood pressure.
Solution. Let us assume that the stimulus administered to all the 12 patients will increases the blood pressure. Taking the population to be normal with mean μ = 0 and S.D. 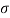
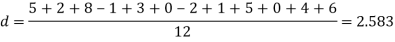 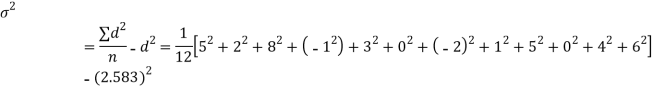 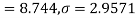 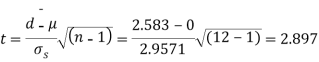 Here 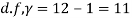 For 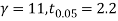 |
Since the  our assumptions is rejected i.e. the stimulus does not increase the B.P.
our assumptions is rejected i.e. the stimulus does not increase the B.P.
Example. The 9 items of a sample have the following values : 45, 47, , 50, 52, 48, 47, 49, 53, 51. Does the mean of these differ significantly from the assumed mean of 47.5?
Solution. We find the mean and the standard deviation of the sample as follows
X | 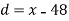 | 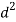 |
45 | -3 | 9 |
47 | -1 | 1 |
50 | 2 | 4 |
52 | 2 | 4 |
48 | 0 | 0 |
47 | -1 | 1 |
49 | 1 | 1 |
53 | 5 | 25 |
51 | 3 | 9 |
Total | 10 | 66 |


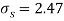
Hence, 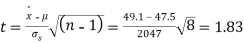
Here, 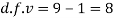
For v = 8, we get from table IV 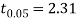
As calculated value of 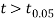 the value of t is not significant at 5% level of significance which implies that there is no significant difference between
the value of t is not significant at 5% level of significance which implies that there is no significant difference between 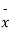 and μ. Thus the test provides no evidence against the population mean being 47.5.
and μ. Thus the test provides no evidence against the population mean being 47.5.
Example. A mechanism is making engine parts with axle diameter of 0.7 inch. A random sample of 10 parts shows mean diameter 0.742 inches with a standard deviation of 0.04 inch. On the basis of this sample would you say that the work is inferior?
Solution. Here we have,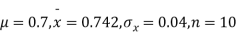
Taking the hypothesis that the product is not inferior that is there is no significant difference between  and μ.
and μ.
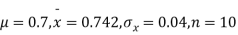 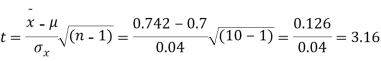
|
Degree of freedom 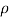 = 10-1=9
= 10-1=9
For  we get from table IV,
we get from table IV, 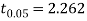
As the calculated value of  the value of t is significant at 5% level of significance. This implies that
the value of t is significant at 5% level of significance. This implies that  differs significantly from μ and the hypothesis is rejected. Hence the work is inferior. In fact the work is inferior even at 2% level of significance.
differs significantly from μ and the hypothesis is rejected. Hence the work is inferior. In fact the work is inferior even at 2% level of significance.
Key takeaways-
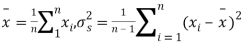
- If the calculated value of
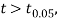 the difference between
the difference between 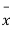 and μ is said to be significant at 5% level of significance.
and μ is said to be significant at 5% level of significance. 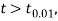 the difference is said to be significant at 1% level of significance.
the difference is said to be significant at 1% level of significance.- If
 the data is said to be the consistent with the hypothesis that μ is the mean of the population.
the data is said to be the consistent with the hypothesis that μ is the mean of the population.
Comparison of large samples
Two large samples of sizes 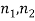 are taken from two populations giving proportions of attributes A's are
are taken from two populations giving proportions of attributes A's are 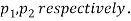
(a) On the hypothesis that the populations are similar as regards the attribute A, we combine the two samples to find an estimate of the common value of proportion of A’s in the populations which is given by

If 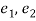 be the standard errors in the two samples then
be the standard errors in the two samples then

If e with the standard error of the difference between 
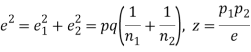
If z>3, the difference between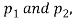 is real one.
is real one.
If z<2, the difference may be due to fluctuations of simple sampling.
But if z lies between 2 and 3, then the difference is significant at 5% level of significance.
(b)If the proportions of A's are not the same in the two populations from which the samples are drawn but  are the True values of proportions then S.E., e off the difference
are the True values of proportions then S.E., e off the difference  is given by
is given by
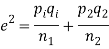
If 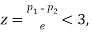 the difference could have rising due to fluctuations of simple sampling.
the difference could have rising due to fluctuations of simple sampling.
Example. In two large populations there are 30% and 25% respectively of fair haired people. Is this difference likely to be hidden in samples of 1200 and 900 respectively from the two populations?
Solution. Here 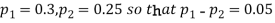
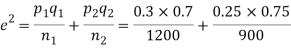
So that,. 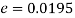

Hence it is unlikely that the real difference will be hidden.
Example. One type of aircraft is found to be develop engine trouble in 5 flights out of a total of hundred and another type in 7 flights out of a total of 200 flights. Is there a significant difference in the two types of aircraft so as far as engine defects are concerned?
Solution. 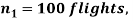 number of troubled flights =5
number of troubled flights =5

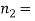 200 flights, number of troubled flights
200 flights, number of troubled flights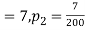
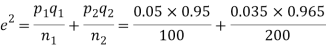
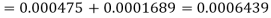
e=0.0254
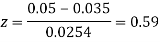
z<1, difference is not significant.
Example. In a sample of 600 men from a certain City 450 are found smokers. In another sample of 900 men from another City, 450 are smokers. Do the data indicate that the cities are significantly different with respect to the habit of smoking among men?
Solution. 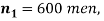 number of smokers = 450,
number of smokers = 450, 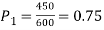
 900 men, number of smokers = 450,
900 men, number of smokers = 450, 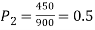
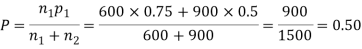
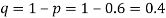
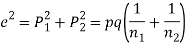

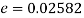
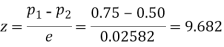
z>3 so that the difference is significant.
The single mean (or one-sample) t-test is used to compare the mean of a variable in a sample of data to a (hypothesized) mean in the population from which our sample data are drawn. This is important because we seldom have access to data for an entire population. The hypothesized value in the population is specified in the Comparison value box.
We can perform either a one-sided test (i.e., less than or greater than) or a two-sided test (see the Alternative hypothesis dropdown). We use one-sided tests to evaluate if the available data provide evidence that the sample mean is larger (or smaller) than the comparison value (i.e., the population value in the null-hypothesis)
Significance test of difference between sample mean
Given two independent samples,  which means
which means 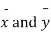 and standard deviations from a normal population with the same variance, we have to test the hypothesis that the population means
and standard deviations from a normal population with the same variance, we have to test the hypothesis that the population means  are the same
are the same
For this, we calculate,
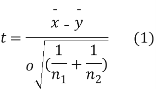 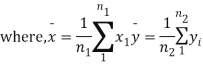 
|
It can be shown that the variate t defined by (1) follows the t distribution with  degree of freedom.
degree of freedom.
If the calculated value of 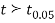 the difference between the sample means is said to be significant at 5% level of significance.
the difference between the sample means is said to be significant at 5% level of significance.
If 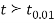 , the difference is said to be significant at 1% level of significance.
, the difference is said to be significant at 1% level of significance.
If  , the data is said to be consistent with the hypothesis, that
, the data is said to be consistent with the hypothesis, that 
Cor. If the two samples are of the same size and the data are paired, then t is defined by
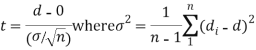
|
Example:
Eleven students were given a test in statistics. They were given a month’s further tuition and the second test of equal difficulty was held at the end of this. Do the marks give evidence that the students have benefitted by extra coaching?
Boys | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Marks I test | 23 | 20 | 19 | 21 | 18 | 20 | 18 | 17 | 23 | 16 | 19 |
Marks II test | 24 | 19 | 22 | 18 | 20 | 22 | 20 | 20 | 23 | 20 | 17 |
Sol. We compute the mean and the S.D. Of the difference between the marks of the two tests as under:
 |
Assuming that the students have not been benefitted by extra coaching, it implies that the mean of the difference between the marks of the two tests is zero i.e.
Then,  nearly and df v=11-1=10
nearly and df v=11-1=10
Students |  | 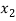 | 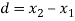 | 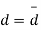 | 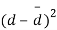 |
1 | 23 | 24 | 1 | 0 | 0 |
2 | 20 | 19 | -1 | -2 | 4 |
3 | 19 | 22 | 3 | 2 | 4 |
4 | 21 | 18 | -3 | -4 | 16 |
5 | 18 | 20 | 2 | 1 | 1 |
6 | 20 | 22 | 2 | 1 | 1 |
7 | 18 | 20 | 2 | 1 | 1 |
8 | 17 | 20 | 3 | 2 | 4 |
9 | 23 | 23 | - | -1 | 1 |
10 | 16 | 20 | 4 | 3 | 9 |
11 | 19 | 17 | -2 | -3 | 9 |
|
|
| 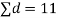 |
|  |
From table IV, we find that 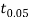 (for v=10) =2.228. As the calculated value of
(for v=10) =2.228. As the calculated value of 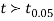 , the value of t is not significant at 5% level of significance i.e. the test provides no evidence that the students have benefitted by extra coaching.
, the value of t is not significant at 5% level of significance i.e. the test provides no evidence that the students have benefitted by extra coaching.
Example
From a random sample of 10 pigs fed on diet A. The increase in weight in a certain period were 10, 6, 16, 17, 13, 12, 8, 14, 15, 9 lbs. For another random sample of 12 pig’s fat on diet B, the increases in the same period were 7, 13, 22, 15, 12, 14, 18, 8, 21, 23, 10, 17 lbs. Test whether diets A and B differ significantly as regards their effects on increases in weight?
Solution. We calculate the means and standard deviation of the samples as follows
| Diet A |
|
| Diet B |
|
 | 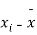 | 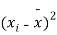 |  | 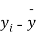 | 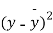 |
10 | -2 | 4 | 7 | -8 | 64 |
6 | -6 | 36 | 18 | -2 | 4 |
16 | 4 | 16 | 22 | 7 | 49 |
17 | 5 | 25 | 15 | 0 | 0 |
13 | 1 | 1 | 12 | -3 | 9 |
12 | 0 | 0 | 14 | -1 | 1 |
8 | -4 | 16 | 18 | 3 | 9 |
14 | 2 | 4 | 8 | -7 | 49 |
15 | 3 | 9 | 21 | 6 | 36 |
9 | -3 | 9 | 23 | 8 | 64 |
|
|
| 10 | -5 | 25 |
|
|
| 23 | 2 | 4 |
120 | 0 | 120 | 10 | 0 | 314 |
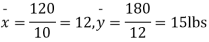 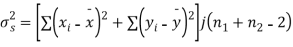 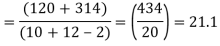 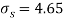
|
Assuming that the samples do not differ in weight so far as two diets are concerned i.e. 
Hence, 
Here, 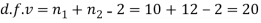
For 
The calculated value of 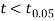
Hence the difference between the sample means is not significant that is the two diets do not differ significantly as regards their effects on increase in weight.
Key takeaways-
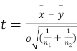
- If the two samples are of the same size and the data are paired, then t is defined by

References:
1. E. Kreyszig, “Advanced Engineering Mathematics”, John Wiley & Sons, 2006.
2. P. G. Hoel, S. C. Port and C. J. Stone, “Introduction to Probability Theory”, Universal Book Stall, 2003.
3. S. Ross, “A First Course in Probability”, Pearson Education India, 2002.
4. W. Feller, “An Introduction to Probability Theory and its Applications”, Vol. 1, Wiley, 1968.
5. N.P. Bali and M. Goyal, “A text book of Engineering Mathematics”, Laxmi Publications, 2010.
6. B.S. Grewal, “Higher Engineering Mathematics”, Khanna Publishers, 2000.
7. T. Veerarajan, “Engineering Mathematics”, Tata McGraw-Hill, New Delhi, 2010.




