Unit - 5
Application Layer
An application layer protocol defines how application processes (clients and servers), running on different end systems, pass messages to each other. In particular, an application layer protocol defines:
• The types of messages, e.g., request messages and response messages.
• The syntax of the various message types, i.e., the fields in the message and how the fields are delineated.
• The semantics of the fields, i.e., the meaning of the information that the field is supposed to contain.
• Rules for determining when and how a process sends messages and responds to messages.
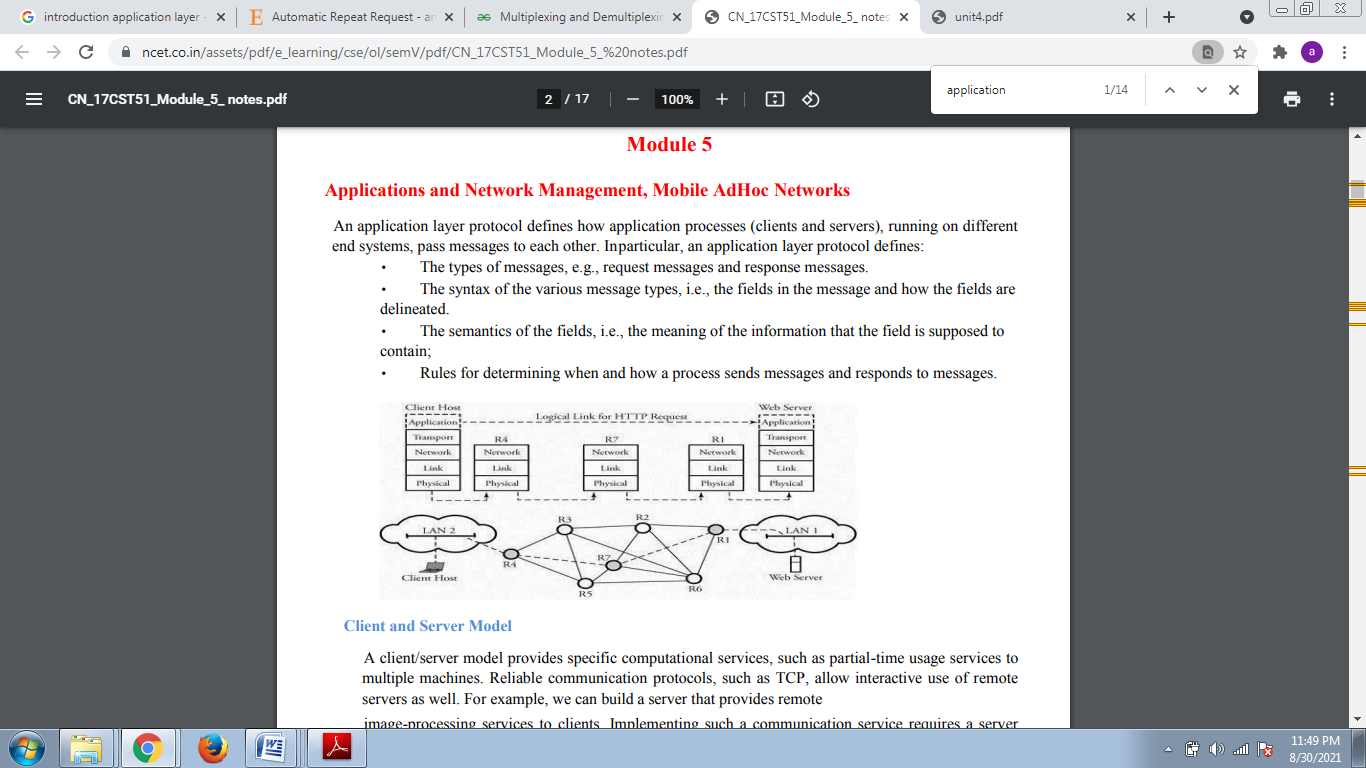
Fig- Hyper Text Transfer Protocol (Http)
HTTP protocol is used to access the data on World Wide Web. This protocol normally transfers the data in the form of plain text, hypertext, audio, video and so on.
It is called as Hypertext Transfer Protocol because it is used in an environment where there are rapid jumps from one document to another.
HTTP functions like a combination of FTP and SMTP.
It is said to be similar to FTP because it transfers files.
It is said to be similar to SMTP because the data transferred between the client and server are similar to the SMTP messages.
However, HTTP differs from SMTP in the way the messages are sent from client to server and from server to client. In case of SMTP, messages are only transferred from server to client.
How HTTP Works?
The working of HTTP is very simple. A client sends a request and server sends a reply (response) to the client. See Fig. HTTP uses the services of TCP on well-known port 80.
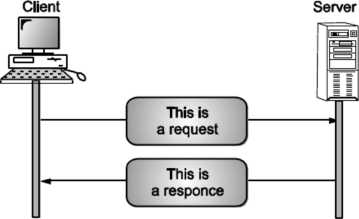
Fig: HTTP transaction
Although HTTP uses the services of TCP, HTTP itself is a “stateless protocol”. The client initializes the transaction by sending a request message. The server replies by sending a response.
Types of HTTP Messages
There are two types of HTTP messages
- Request Message
- Response Message
HTTP is a Stateless Protocol
In this protocol, the server does not store any information about the state of current transaction. So, when the client does a request for some files, server sends these files to client without storing any state information about the client.
If same client asks for the same information again and again to the server, so the server would not understand that it has already transferred this information to the same client, so server resends this information back to the client again and again as and when the client requests for those files.
As HTTP server does not maintain any information about the state of client, it is called as "stateless protocol".
HTTP Connections Types
HTTP connections are of two types
- Persistent Connections
- Non-Persistent Connections.
These are explained in detail as follows:
Persistent Connections
It is specified in HTTP version 1.1. In persistent connection the server leaves the connection open for more requests after sending a response. The server can close the connection at the request of a client or if timeout has been reached. The sender usually sends a length of the data with each response.
However, there are certain situations where the sender does not know the length of the data. In such situation the document is created dynamically. In such cases, the server informs the client that the length of the data is not known and closes the connection after sending the data so the client knows that the end of the data has been reached. HTTP version 1.1 by default specifies a persistent connection.
Non-persistent Connection
In this type one TCP connection is made for each request/response by using the following steps:
The client opens a TCP connection and sends a request.
The server sends a response and closes the connection.
The client reads the data until it encounters an end of file marker the client then closes the connection.
World Wide Web and Proxy Server (Web Caching)
Web server is a computer where the web content is stored. Basically, web server is used to host the web sites but there exist other web servers also such as gaming, storage, FTP, email etc.
Web Server Working Web server respond to the client request in either of the following two ways:
• Sending the file to the client associated with the requested URL.
• Generating response by invoking a script and communicating with database
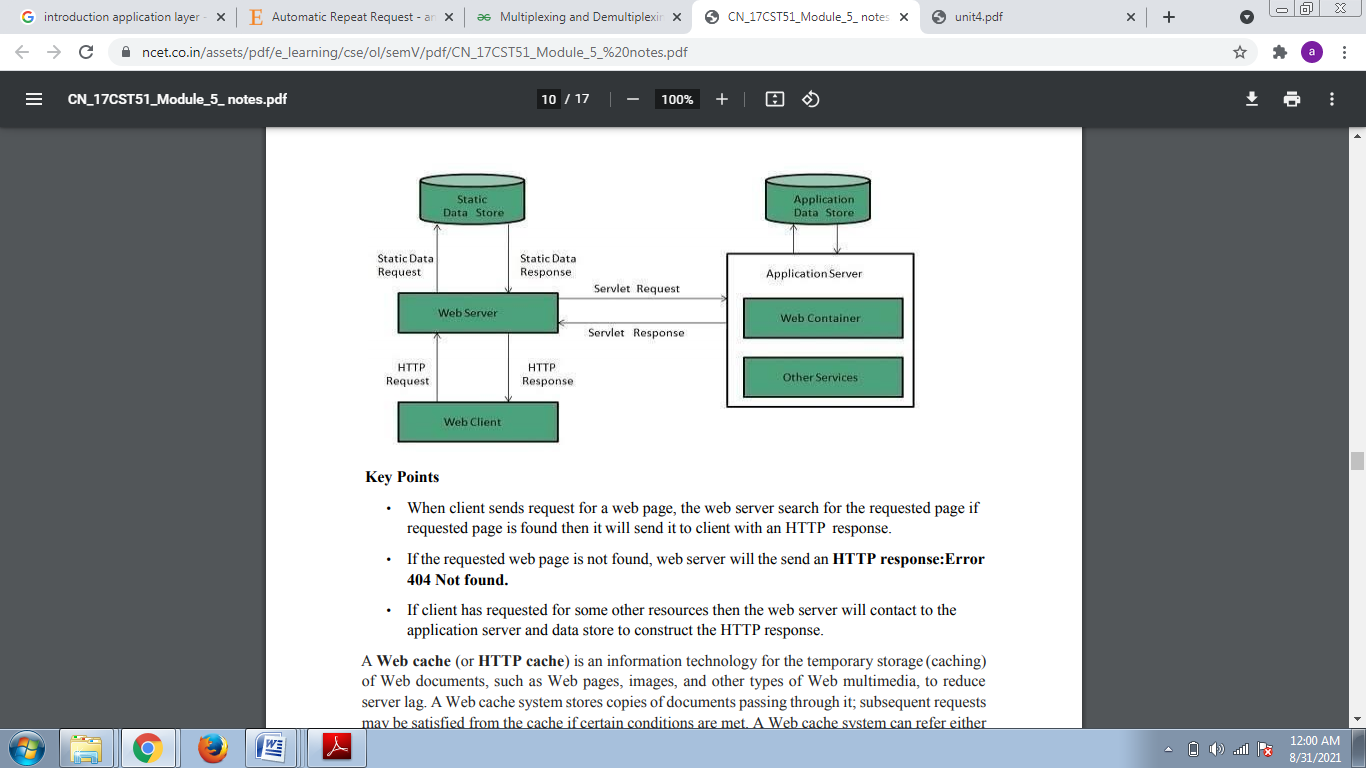
Key Points
• When client sends request for a web page, the web server search for the requested page if requested page is found then it will send it to client with an HTTP response.
• If the requested web page is not found, web server will the send an HTTP response: Error 404 Not found.
• If client has requested for some other resources then the web server will contact to the application server and data store to construct the HTTP response.
A Web cache (or HTTP cache) is an information technology for the temporary storage (caching) of Web documents, such as Web pages, images, and other types of Web multimedia, to reduce server lag.
A Web cache system stores copies of documents passing through it subsequent requests may be satisfied from the cache if certain conditions are met.
A Web cache system can refer either to an appliance or to a computer program.
What Is Caching?
Caching is the term for storing reusable responses in order to make subsequent requests faster. There are many different types of caching available, each of which has its own characteristics. Application caches and memory caches are both popular for their ability to speed up certain responses. Web caching, the focus of this guide, is a different type of cache.
Web caching is a core design feature of the HTTP protocol meant to minimize network traffic while improving the perceived responsiveness of the system as a whole. Caches are found at every level of a content’s journey from the original server to the browser. Web caching works by caching the HTTP responses for requests according to certain rules. Subsequent requests for cached content can then be fulfilled from a cache closer to the user instead of sending the request all the way back to the web server.
Benefits
Effective caching aids both content consumers and content providers. Some of the benefits that caching brings to content delivery are:
• Decreased network costs: Content can be cached at various points in the network path between the content consumer and content origin. When the content is cached closer to the consumer, requests will not cause much additional network activity beyond the cache.
• Improved responsiveness: Caching enables content to be retrieved faster because an entire network round trip is not necessary. Caches maintained close to the user, like the browser cache, can make this retrieval nearly instantaneous.
• Increased performance on the same hardware: For the server where the content originated, more performance can be squeezed from the same hardware by allowing aggressive caching. The content owner can leverage the powerful servers along the delivery path to take the brunt of certain content loads.
• Availability of content during network interruptions: With certain policies, caching can be used to serve content to end users even when it may be unavailable for short periods of time from the origin servers.
DNS
Domain name system (DNS)
DNS provides a protocol that allows client and servers to communicate with each other. To identify a computer on the internet, IP address is used by the TCP/IP protocol suit.
However, it is difficult to remember so many IP addresses, for that people used to prefer names (such as www.puneatoz.net) instead of the numeric IP addresses.
Therefore, we need a system that can map a name to an IP address or an IP address to a name. Domain Name System provides this facility.
Working of DNS
To map a URL name with IP address, the application program calls a library procedure called as ‘Resolver’. The URL name is passed to the Resolver as an argument. This Resolver sends a UDP packet to local DNS server which goes through its database, finds out the corresponding IP address associated with the URL name, and returns this IP address to the application program. After getting the actual IP address, the application program establishes the connection with the destination.
Domain Name Space
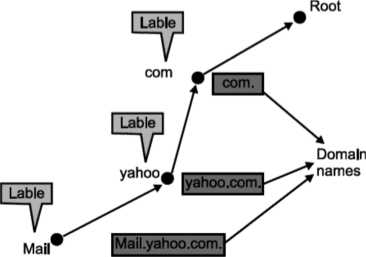
Domain name space is hierarchical, which is similar to Unix file system. In this design, names are defined in an inverted tree structure with the root at the top. Domain names are case insensitive (i.e., com and COM are same thing). Every node has a label of maximum 63 characters long. The root label is null string. A domain name that ends with a period is called as absolute domain name or fully qualified domain name.
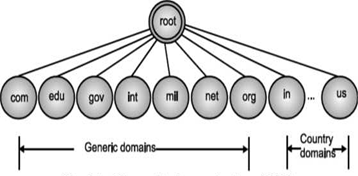
Fig: Hierarchical organization of DNS
- Top level domains are divided into two areas means generic and countries as shown in Fig. Above.
- Three-character domains are called as generic domains
- Two-character domains are called as country domains (e.g., in for India, us for United States, nz for New Zealand).
- The generic domains .GOV and .MIL are restricted to the United States only.
- Each domain is named by the path upward from it to the root. The components are separated by periods. This is called as hierarchical routing.
As we know that root label is null, this means that a full domain name always ends in null label; this means the last character is dot because the null string is nothing. Following Fig. below shows some domain names
Simple Mail Transfer Protocol (SMTP)
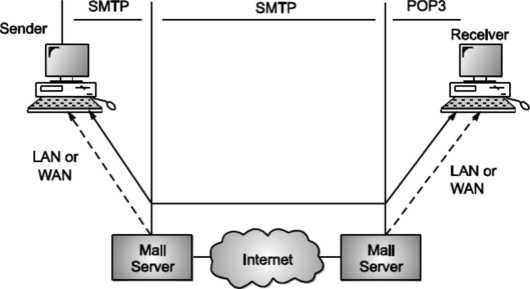
E-mail system is implemented with the help of Message Transfer Agents (MTA). There are normally two MTAs in each mailing system. One for sending e-mails and another for receiving e-mails. The formal protocol that defines the MTA client and server in the internet is called Simple Mail Transfer Protocol (SMTP).
Fig shows the range of SMTP protocol.
By referring the above diagram, we can say that SMTP is used two times. That is between the sender and sender’s mail server and between the sender’s mail server and receiver’s mail server. Another protocol is used between the receiver’s mail server and receiver.
SMTP simply defines how commands and responses must be sent back and forth.
SMTP is a simple ASCII protocol
It establishes a TCP connection between a sender and port number 25 of the receiver. No checksums are generally required because TCP provides a reliable byte stream. After exchanging all the e-mail, the connection is released.
Commands and Responses
SMTP uses commands and responses to transfer messages between an MTA client and MTA server.
Each command or reply is terminated by a two-character (carriage return and line feed) end-of-line token.

Fig. Commands and Responses
Commands
Client sends commands to the server. SMTP defines 14 commands. Out of that first 5 commands are mandatory; every implementation must support these commands.
The next three commands are often used and are highly recommended. Last six commands are hardly used.
Following table shows FTP commands.
Table:
Keyword | Description |
HELO | Used by the client to identify itself. The argument is domain name of the client host. The format is: HELO: mail.viit.ac.in |
MAIL FROM | Used by the client to identify the sender of the message. The argument is email address of the sender. The format is MAIL FROM: amol.dhumane@gmail.com |
RCPT TO | Used by the client to identify the intended recipient of the message. The argument is the email address of the recipient. The format is: RCPT TO: ashwini.dhumane@yahoo.co.in |
DATA | This command is used to send the actual message. The lines following DATA command are treated as mail message. The format is: DATA There is an important meeting on this Sunday. So please be present for it. Regards; Nitin Sakhare |
QUIT | It terminates the message. The format is: QUIT |
RSET | It aborts the current email transaction. The stored information of the sender and receiver is deleted after executing the command. The connection gets reset. The format is: RSET |
VRFY | This command is used to verify the address of the recipient. In this sender asks the receiver to confirm that a name identifies a valid recipient. Its format is: VRFY: sai@puneatoz.net |
NOOP | By using this command, the client checks the status of the recipient. It requires an answer from recipient. Its format is: NOOP |
TURN | It reverses the role of sender and receiver. |
EXPN | It asks the receiving host to expand the mailing list. |
HELP | It sends system specific documentation. The format is: HELP: mail
|
SEND FROM | This command specifies that the mail is to be delivered to the terminal of the recipient, and not the mailbox. If the recipient is not logged in, the mail is bounced back. The argument is the address of the sender. The format is: SEND FROM: amol.dhumane@gmail.com |
SMOL FROM | This command specifies to send the mail to the terminal if possible, otherwise to the mailbox. |
SMAL FROM
FROM | It sends mail to the terminal and mail box. |
SMTP Working
SMTP works in the following three stages:
a) Connection Establishment
b) Message Transfer
c) Connection Termination
These are explained below:
Connection Establishment
Once the TCP connection is made on port no. 25, SMTP server starts the connection phase. This phase involves following three steps which are explained in the Fig.
The server tells the client that it is ready to receive mail by using the code 220. If the server is not ready, it sends code 421 which tells that service is not available.
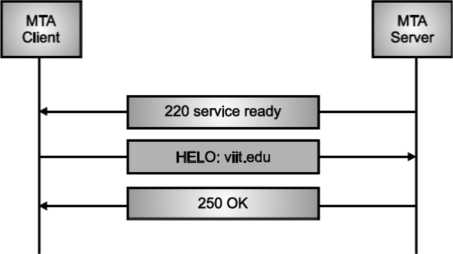
Fig. Connection Establishment
Once the server becomes ready to receive the mails, client sends HELO message to identify itself using the domain name address. This is important step which informs the server of the domain name of the client. Remember that during TCP connection establishment, the sender and receiver know each other through their IP addresses.
Server responds with code 250 which tells that the request command is completed. Message Transfer Once the connection has been established, SMTP server sends messages to SMTP receiver.
The messages are transferred in three stages
A MAIL command identifies the message originator.
RCPT command identifies the receiver of the message.
DATA command transfers the message text.
Connection Closing
After the message is transferred successfully, the client terminates the connection. The connection is terminated in two steps The client sends the quit command.
The server responds with code 221 or some other appropriate code. After the connection termination phase, the TCP connection must be closed.
MIME Short for Multipurpose Internet Mail Extensions, a specification for formatting non-ASCII messages so that they can be sent over the Internet.
Many e-mail clients now support MIME, which enables them to send and receive graphics, audio, and video files via the Internet mail system. In addition, MIME supports messages in character sets other than ASCII.
There are many predefined MIME types, such as GIF graphics files and PostScript files. It is also possible to define your own MIME types.
In addition to e-mail applications, Web browsers also support various MIME types. This enables the browser to display or output files that are not in HTML format.
MIME-Version
The presence of this header indicates the message is MIME-formatted. The value is typically ”1.0" so this header appears as MIME-Version: 1.0 Content-Type
This header indicates the media type of the message content, consisting of a type and subtype, for example
Content-Type: text/plain Through the use of the multipart type, MIME allows mail messages to have parts arranged in a tree structure where the leaf nodes are any non-multipart content type and the non-leaf nodes are any of a variety of multipart types. This mechanism supports:
Simple text messages using text/plain (the default value for "Content-Type: ")
Text plus attachments (multipart/mixed with a text/plain part and other non-text parts). A MIME message including an attached file generally indicates the file’s original name with the "Content-disposition:" header, so the type of file is indicated both by the MIME content-type and the (usually OS-specific) filename extension
Reply with original attached (multipart/mixed with a text/plain part and the original message as a message∕rfc822 part)
Alternative content, such as a message sent in both plain text and another format such as HTML (multipart/alternative with the same content in text/plain and text/html forms) Image, audio, video and application (for example, image/jpeg, audio∕mp3, video∕mp4, and application/msword and so on)
Many other message constructs POP 3 POP Stands for "Post Office Protocol." POP3, sometimes referred to as just "POP," is a simple, standardized method of delivering e-mail messages. A POP3 mail server receives e-mails and filters them into the appropriate user folders. When a user connects to the mail server to retrieve his mail, the messages are downloaded from mail server to the user's hard disk.
When you configure your e-mail client, such as Outlook (Windows) or Mail (Mac OS X), you will need to enter the type of mail server your e-mail account uses. This will typically be either a POP3 or IMAP server. IMAP mail servers are a bit more complex than POP3 servers and allow e-mail messages to be read and stored on the server. Many "webmail" interfaces use IMAP mail servers so that users can manage all their mail online.
Still, most mail servers use the POP3 mail protocol because it is simple and well- supported. You may have to check with your ISP or whoever manages your mail account to find out what settings to use for configuring your mail program. If your e- mail account is on a POP3 mail server, you will need to enter the correct POP3 server address in your e-mail program settings.
Typically, this is something like "mail.servemame.com" or "pop.servername.com." Of course, to successfully retrieve your mail, you will have to enter a valid username and password too.
POP3
POP, or Post Office Protocol, is a way of retrieving email information that dates back to a very different Internet than we use today. Computers only had limited, low bandwidth access to remote computers, so engineers created POP in an effort to create a dead simple way to download copies of emails for offline reading, then remove those mails from the remote server.
Mail Server Functionality
POP3 has become increasingly sophisticated so that some administrators can configure the protocol to "store" email on the server for a certain period of time, which would allow an individual to download it as many times as they wished within that given time frame. However, this method is not practical for the vast majority of email recipients.
While mail servers can use alternate protocol retrieval programs, such as IMAP, POP3 is extremely common among most mail servers because of its simplicity and high rate of success. Although the newer version of POP offers more "features," at its basic level, POP3 is preferred because it does the job with a minimum of errors.
Working With Email Applications
Because POP3 is a basic method of storing and retrieving email, it can work with virtually any email program, as long as the email program is configured to host the protocol. Many popular email programs, including Eudora and Microsoft Outlook, are automatically designed to work with POP3.
Each POP3 mail server has a different address, which is usually provided to an individual by their web hosting company.
This address must be entered into the email program in order for the program to connect effectively with the protocol. Generally, most email applications use the 110 port to connect to POP3.
Those individuals who are configuring their email program to receive POP3 email will also need to input their username and password in order to successfully receive email.
POP3 and IMAP are two different protocols (methods) used to access email. Both of the two, IMAP is the better option - and the recommended option - when you need to check your emails from multiple devices, such as a work laptop, a home computer, or a tablet, smartphone, or other mobile device. Tap into your synced (updated) account from any device with IMAP.
POP3 downloads email from a server to a single computer, then deletes it from the server. Because your messages get downloaded to a single computer or device and then deleted from the server, it can appear that mail is missing or disappearing from your Inbox if you try to check your mail from a different computer.
Here are the differences between POP3 and IMAP.
POP3 - Post Office Protocol | IMAP - Internet Messaging Access Protocol |
You can use only one computer to check your email (no other devices) | You can use multiple computers and devices to check your email |
Your mails are stored on the computer that you use | Your mails are stored on the server |
Sent mail is stored locally on your PC, not on a mail server | Sent mail stays on the server so you can see it from any device. |
Webmail
Webmail is a way of sending and receiving emails from a web browser, instead of from an email client.
All email travels over the internet, and is stored on servers. Those servers can belong to email providers (like Gmail), internet service providers, or web hosting providers. This server is where email is collected and stored, until you delete it.
To access your webmail provider's server, you connect to the internet, and log in to a site that connects to your email account. When you use webmail, you are directly accessing the email, from your provider's server. This lets you send and receive mail from anywhere in the world, from any device, as long as you have an internet- connected web browser.
Your mail always remains on your provider's server, so if you do not have an internet connection, or the provider's servers are down, you will not be able to access your email using webmail. Also, webmail interfaces may not provide as much functionality as a more robust email client.
Webmail accounts don't require you to install or use an email application software such as Microsoft Outlook on your computer. You can read, send, reply, forward, organize your email into folders and save attachments.
The webmail service stores of all of your email on their computers and storage systems, and gives you a web page to use for accessing your email account. You login to your webmail account from the webmail service's web page using your email address and password.
You might already have a webmail account, and common webmail providers include Google's Gmail, AOL Mail, Microsoft's Hotmail/Live/Outlook.com, Yahoo! Mail, and Apple's iCloud email. Many of the webmail services that are offered on the Internet are free but can include ads that display on the screen. An upgrade to a paid email plans will remove the ads.
Your Internet service provider may also provide you with access to webmail when you subscribe to their service so your existing email account may already be webmail capable. You might have to check with them to see if your account can be used as a webmail account, or, you may be able to change your account to a webmail account and keep the same email address.
One of the biggest advantages of webmail is that you can access it from anywhere with almost any device that can connect to the Internet. You don't need to carry your laptop with you just to check your email. Instead, you could check your webmail from your smart phone or even from an Internet cafe or public library. All your emails are stored on the providers' servers until you choose to delete them. For those who do not regularly check their email on the same computer, do not have a computer or who frequently travel, webmail is a good option to access their email on public computers. Most webmail systems so you only need you to go to the provider's website, and then enter your username and password to access your account.
Often webmail accounts are referred to as IMAP accounts, and while most webmail accounts use IMAP, not all IMAP accounts can be used with a Web browser. IMAP stands for Internet Message Access Protocol, which is a type of email account service. Many webmail accounts use this type of email protocol, which keeps a master copy of all email on the email service's computers. Webmail is the ability to access any email account using a Web browser, regardless of the type of software running the email service.
While webmail works with a Web browser, it's also possible to setup your email account with a smart phone using an app or on a computer using a local application. Why would you do this you might ask since the point of webmail is to use it on the Web, right? Sometimes the apps and applications included with smart phones and computers are designed to make using email easier and faster, and sometimes they add additional capabilities. For example, the Mail app provided on Apple iPhones, iPads, and the Mail app provided on Android phones are all designed to work with touch gestures.
While you could use your webmail account using the Web browser on your device, you would need to navigate around the screen using mouse clicks and keyboard commands designed for when you use a desktop or laptop. When you use your email account with the built-in apps on a smart phone or tablet, your email experience is optimized for a touch-screen device.
Whether it's a Microsoft Windows model or an Apple Mac, the built-in email application provides additional features and functions, and the built-in email applications usually work more like other applications on the computer, which can make them easier to use for many people.
For both smart phones and computers, using the built-in email application on the device with your webmail account lets you store a local copy of your email, so you can read and write emails while you're not connected to the Internet. When you connect to the Internet again, your new email messages will arrive in your Inbox, and your pending messages will be sent to their recipient.
One other advantage of using webmail with more than one device is that your email and folders stay up to date on all of your devices since a master copy is kept by the webmail service. Each device checks in and sends and receives updates whenever the device is connected to the Internet.
Web Mail Disadvantages
If you only use webmail using a Web browser, in order to access your email to view or create an email, you must be connected to the Internet. Your email will not be saved locally on your computer. This means would also be unable to review your email later unless you have access to the Internet. Since Internet access is available with smartphones almost everywhere, this might not be a disadvantage unless you travel to places where cellular reception or WiFi access is not available.
Webmail users may miss some of the features that may be in the local email application software used on smart phones and computers. Users may be subjected to ads that are included by the webmail service with their emails, in addition to having to deal with the service's spam-filters that may be too efficient and mark some emails from people you know as spam.
File Transfer Protocol (FTP)
The main purpose of computer networks is data and resource sharing. File transfer is a very common operation on the computer network.
We require two types of protocols for transferring the files on the network: (1) FTP and (2) TFTP
FTP is a standard mechanism provided by TCP/IP for copying a file from one host to another.
There are some problems associated with file transfer mechanism from one machine to another, which can be as follows: Two systems may have different ways to represent text and data.
These systems may have different directory structure.
It is necessary for the FTP to solve all such sort of problems for transferring a file.
For transferring a file, FTP establishes two connections between the hosts. One connection is used for data transfer, and other for control information (commands and responses). Separation of commands and data transfer makes FTP more efficient. Data connection uses very complex rules for transmission of data (due to variety of data types transferred); on the other hand, control connection uses very simple rules of communication.
Points to be Remembered
FTP uses the service of TCP.
It needs two TCP connections.
Port 21 is used for control connection.
Port 20 is used for data connection.
Following Fig. 6.20 explains the basic architecture of FTP. The server has two major components and the client has two major components as given in Fig. 6.20.
The control connection is made between the control processes at server and client side while the data connection is made between the data transfer processes.
One more thing that is very important about the control and data connection is that, the control connection remains open during the entire FTP interactive session, while the data connection is opened when the user wants to transmit a file and then it is closed after the file transfer. In short, the data connection is opened and closed for each file transferred.
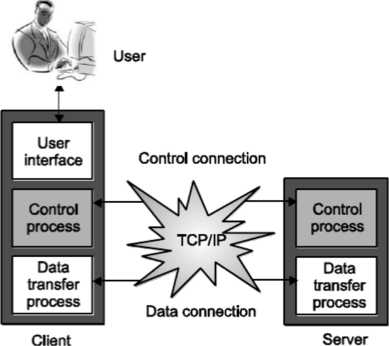
Fig. FTP
Control Connection
• The process of opening the control connection is shown in Fig.
There are two steps:
- The server issues a passive open on well known port 21 and waits for a client.
- The client uses a temporary (ephemeral) port and issues an active open.
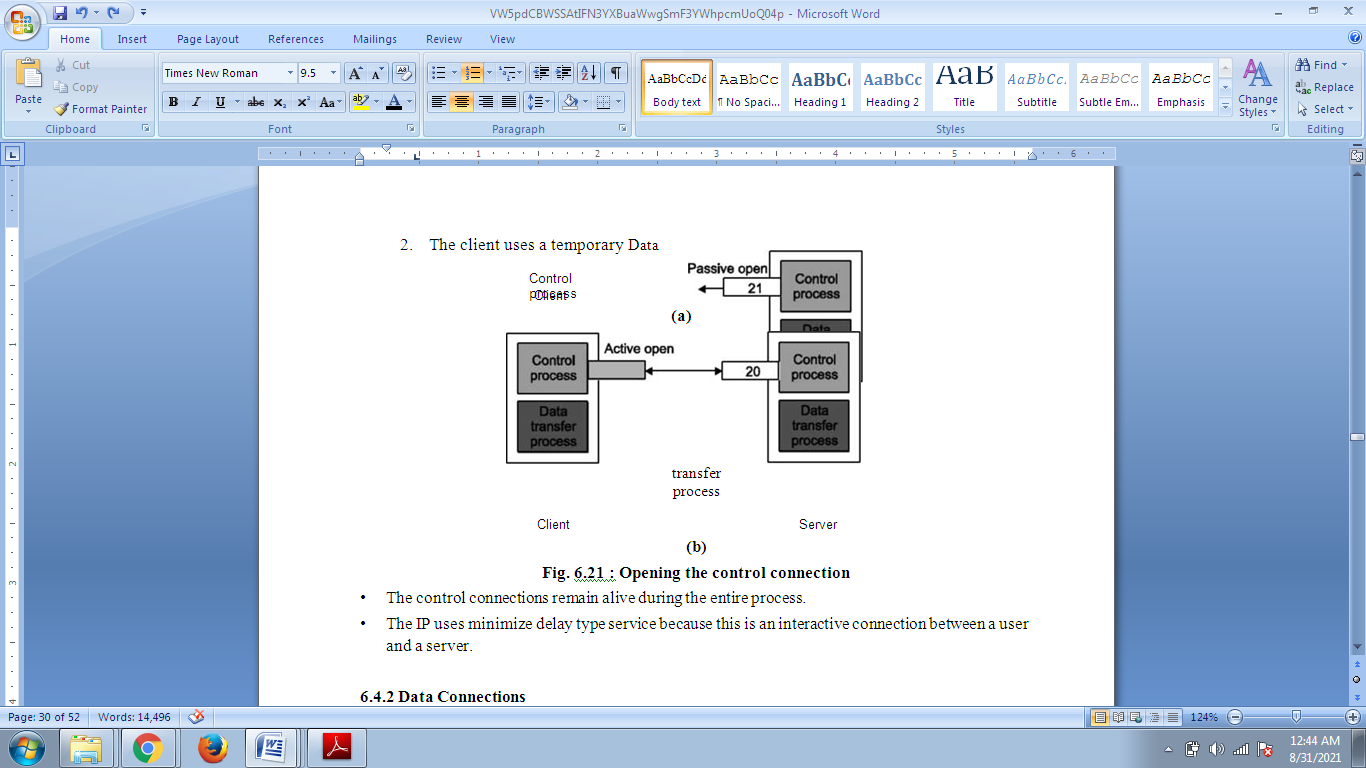
Fig. Opening the control connection
The control connections remain alive during the entire process. The IP uses minimize delay type service because this is an interactive connection between a user and a server.
Data Connections
Data connection uses port 20 at server side.
Following steps are required for creating data connections: The client issues a passive open using a temporary (ephemeral) port. The client sends this port number to the server using PORT command. The server receives the port number and issues an active open using port 20 and the received ephemeral port number.
These steps for creating the initial data connection are shown in Fig.
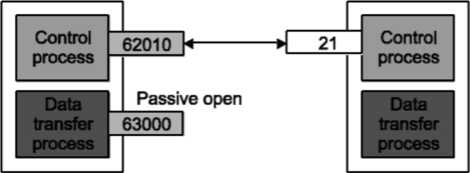
Client Server
(a)
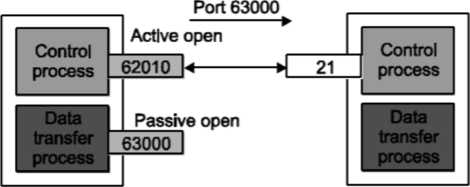
Client Server
(b)
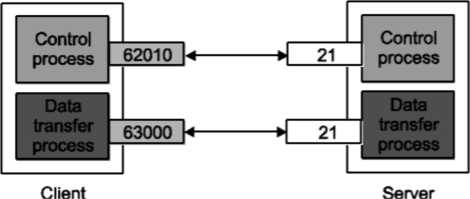
(c)
Fig. Creating data connections
Telnet
Where the TCP protocol makes it possible to connect the remote computers, the TELNET protocol makes it possible to use them. The TELNET protocol offers a user the possibility to connect and log on to any other hosts in the network from user’s own computer by offering a remote log on capability.
Historically, TELNET was the first TCP/IP application and still is widely used as a terminal emulator. Today, while the applications are more and more equipped with the graphical user interface, the terminal-based applications are becoming minority among the applications.
The TELNET has found its future as a tool kit lying below several client/server software. For example: FTP, SMTP, SNMP, NNTP and HTTP are more or less dependent on the TELNET protocol.
Telnet Model
For the connections, TELNET uses the TCP protocol. The TELNET service is offered in the host machine’s TCP port 23. The user at the terminal interacts with the local telnet client.
The TELNET client acts as a terminal accepting any keystrokes from the keyboard, interpreting them and displaying the output on the screen.
The client on the computer makes the TCP connection to the host machine’s port 23 where the TELNET server answers. The TELNET server interacts with applications in the host machine and assists in the terminal emulation.
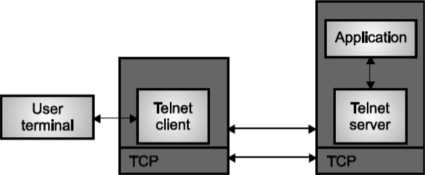
Fig. TELNET Protocol Model
- As the connection is setup, the both ends of the TELNET connection are assumed to be originated and terminated at the Network Virtual Terminal (NVT). The NVT is a network wide terminal which is host independent so that both the server and the client in the connection may not need to keep any information about each other’s terminal’s characteristics as both sees each other as a NVT terminal.
- As there are several types of terminals, which may be able to provide additional services from those provided by the NVT, the TELNET protocol contains a negotiation method for the user and the server to negotiate changes to the terminal provided in the NVT. Typically, the client and the server stay in the NVT just as long as it takes to negotiate some terminal type to be emulated.
Options
The TELNET has a set of options and these options can be negotiated through a simple protocol inside the TELNET. The negotiation protocol contains commands DO, WILL, WON’T and DON’T. Following examples present the accepted command sequences
DO (sender wants receiver to enable the option)
WILL (receiver acknowledges)
DO (sender wants receiver to enable the option)
WON’T (receiver will not acknowledge the request)
WILL (sender wants to enable the option)
DO (receiver gives permission)
WILL (sender wants to enable the option)
DON’T (receiver does not give permission to do so)
WON'T (sender wants to disable option)
DON’T (receiver has to answer OK)
DON’T (sender wants receiver to disable option)
WON’T (receiver must say OK)
Dynamic Host Configuration Protocol (DHCP) BOOTP is not a dynamic configuration protocol.
When client requests its IP address, BOOTP server consults a table that matches the physical address of the client with its IP address. This implies that the binding between the IP address and the physical address of the client already exists. The binding is predetermined.
As BOOTP is static configuration protocol, it cannot assign temporary IP address to the host; also it cannot handle the situation when the host moves from one physical network to the other.
To remove the limitations of BOOTP, DHCP protocol comes into existence, where DHCP provides static and dynamic address allocation that can be manual or automatic.
DHCP is backward compatible with BOOTP, which means a host running the BOOTP client can request a static address from a DHCP server.
Dynamic Address Allocation DHCP database contains a pool of available IP addresses. This database makes DHCP dynamic.
When a DHCP client requests a temporary IP address, DHCP server goes to the pool of available IP addresses and assigns an IP address for negotiable period of time.
When DHCP client send a request to a DHCP server, the server first checks its static database.
If an entry with the requested physical address exists in the static database, the permanent IP address of the client is returned.
On the other hand, if the entry does not exist in the static database, the server selects an IP address from the available pool, assigns the IP address to the client, and adds the entry to the dynamic database.
The dynamic aspect of DHCP is needed when the host moves from network to network or is connected and disconnected from the network.
DHCP provides temporary IP address for a limited period of time. The address assigned from the pool is temporary addresses. The DHCP server issues a lease for a specific period of time. When the lease is expired, the client must either stop using the IP address or renew the lease.
The server has a choice to agree or disagree with the renewal. If the server disagrees, the client stops using the address.
Packet Format
As discussed previously, we know that DHCP is backward compatible with BOOTP. To make it backward compatible, the designers of DHCP have decided to use almost the same packet format as that of BOOTP protocol.
They have only added one bit flag to the packet. However, for allowing different interaction with the server, extra options have been added to the option field
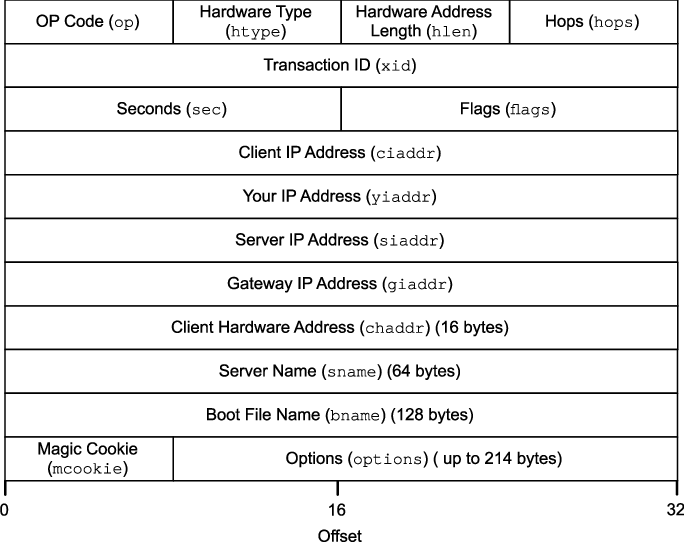
Fig –DHCP PACKET
The fields are described below:
Operation Code: This 8-bit field defines the type of BOOTP packet: 1) Request or 2) Reply.
Hardware Type: This 8-bit field defines the type of physical network. For Ethernet the value is 1.
Hardware Length: This 8-bit field defines the length of physical address in bytes. For example, for Ethernet the value is 6.
Hop Count: This 8-bit field defines the maximum number of hops the packet can travel.
Transaction ID: This is a 4-byte field carrying an integer. This is set by the client and used to match reply with the request.
Number of Seconds: This is a 16-bit field that indicates the number of seconds elapsed since the time the client started to boot.
Flag: Server uses this field to specify the client that it is a forced broadcast reply. For unicast reply to the client, the destination IP address of the IP packet is the address assigned to the client. If the client does not know its IP address, it discards the packet.
But if the IP datagram is broadcast, every host will receive and process the broadcast message.
Client IP Address: This is a 4-byte field that contains the client IP address. If client does not have this information, this field has a value of 0.
Your IP Address: This is a 4-byte field that contains the client IP address. It is filled by the server at the request of the client.
Server IP Address: This is a 4-byte field that contains the server IP address. It is filled by the server in a reply message.
Gateway IP Address: This is a 4-byte field that contains the router IP address. It is filled by the server in a reply message.
Client Hardware Address: This is the physical address of the client.
Server Name: This is an optional 64-byte field, filled by the server in reply packet.
Boot Filename: This is an optional 128-byte field that can be filled by the server in a reply packet. It contains the full pathname of the boot file. The client can use this path to retrieve other booting information.
Options: Several options have been added to the list of options.
Simple Network Management Protocol (SNMP)
SNMP stands for simple network management protocol. It is a way that servers can share information about their current state, and also a channel through which an administer can modify pre-defined values. While the protocol itself is very simple, the structure of programs that implement SNMP can be very complex.
In this guide, we will introduce you to the basics of the SNMP protocol. We will go over its uses, the way that the protocol is typically used in a network, the differences in its protocol versions, and more.
Basic Concepts
SNMP is a protocol that is implemented on the application layer of the networking stack (click here to learn about networking layers). The protocol was created as a way of gathering information from very different systems in a consistent manner. Although it can be used in connection to a diverse array of systems, the method of querying information and the paths to the relevant information are standardized.
There are multiple versions of the SNMP protocol, and many networked hardware devices implement some form of SNMP access. The most widely used version is SNMPvl, but it is in many ways insecure. Its popularity largely stems from its ubiquity and long time in the wild. Unless you have a strong reason not to, we recommend you use SNMPv3, which provides more advanced security features.
In general, a network being profiled by SNMP will mainly consist of devices containing SNMP agents. An agent is a program that can gather information about a piece of hardware, organize it into predefined entries, and respond to queries using the SNMP protocol.
The component of this model that queries agents for information is called an SNMP manager. These machines generally have data about all of the SNMP-enabled devices in their network and can issue requests to gather information and set certain properties.
SNMP Managers
An SNMP manager is a computer that is configured to poll SNMP agent for information. The management component, when only discussing its core functionality, is actually a lot less complex than the client configuration, because the management component simply requests data.
The manager can be any machine that can send query requests to SNMP agents with the correct credentials. Sometimes, this is implemented as part of a monitoring suite, while other times this is an administrator using some simple utilities to craft a quick request.
Almost all of the commands defined in the SNMP protocol (we will go over these in detail later) are designed to be sent by a manager component. These include Get Request, Get Next Request, Get Bulk Request, Set Request, Infonn Request, and Response. In addition to these, a manager is also designed to respond to Trap, and Response messages.
SNMP Agents
SNMP agents do the bulk of the work. They are responsible for gathering infoπnation about the local system and storing them in a format that can be queried. Updating a database called the "management information base", or MIB.
The MIB is a hierarchical, pre-defined structure that stores information that can be queried or set. This is available to well-formed SNMP requests originating from a host that has authenticated with the correct credentials (an SNMP manager). The agent computer configures which managers should have access to its information. It can also act as an intermediary to report information on devices it can connect to that are not configured for SNMP traffic. This provides a lot of flexibility in getting your components online and SNMP accessible.
SNMP agents respond to most of the commands defined by the protocol. These include GetRequest, GetNextRequest, GetBulkRequest, Set Request and InfonnRequest. In addition, an agent is designed to send Trap messages.
Use of application layer
In Application layer DNS (domain name specification) is used in various purposes in network security
- DNS provides a protocol that allows client and servers to communicate with each other.
- To identify a computer on the internet, IP address is used by the TCP/IP protocol suit.
- However, it is difficult to remember so many IP addresses, for that people used to prefer names (such as www.puneatoz.net) instead of the numeric IP addresses.
- Therefore, we need a system that can map a name to an IP address or an IP address to a name.
- Domain Name System provides this facility.
Working of DNS
- To map a URL name with IP address, the application program calls a library procedure called as ‘Resolver’.
- The URL name is passed to the Resolver as an argument.
- This Resolver sends a UDP packet to local DNS server which goes through its database, finds out the corresponding IP address associated with the URL name, and returns this IP address to the application program.
- After getting the actual IP address, the application program establishes the connection with the destination.
Application Analysis Tasks for the Network Analyst
Application analysis is the process of capturing and analyzing the traffic generated by a network application. Application analysis tasks that can be performed with Wireshark include, but are not limited to:
• Analyzing application bandwidth requirements
• Identifying application protocols and ports in use
• Validating secure application data traversal Understand Security
Issues Related to Network Analysis Network analysis can be used to improve network performance and security but it can also be used for malicious tasks. For example, an intruder who can access the network medium (wired or wireless) can listen in on traffic. Unencrypted communications (such as clear text user names and passwords) may be captured and thus enable a malicious user to compromise accounts.
An intruder can also learn network configuration information by listening to the traffic this information can then be used to exploit network vulnerabilities. Malicious programs may include network analysis capabilities to sniff the traffic.
Be Aware of Legal Issues of Listening to Network Traffic
We aren’t lawyers, so consult your legal counsel on this issue. In general, Wireshark provides the ability to eavesdrop on network communications have you heard the terms “wiretapping” or “electronic surveillance”?
Unauthorized use of Wireshark may be illegal. Certain exceptions are in place to cover government use of wiretapping methods in advance of a crime being perpetrated.
Review a Checklist of Analysis Tasks
The following lists some of the analysis tasks that can be performed using Wireshark:
a) Find the top talkers on the network
b) Identify the protocols and applications in use
c) Determine the average packets per second rate and bytes per second rate of an
d) Application or all network traffic on a link
e) List all hosts communicating
f) Learn the packet lengths used by a data transfer application
g) Recognize the most common connection problems
h) Spot delays between client requests due to slow processing
i) Locate misconfigured hosts
j) Detect network or host congestion that is slowing down file transfers
k) Identify asynchronous traffic prioritization
l) Graph HTTP flows to examine website referrals rates
m) Identify unusual scanning traffic on the network
n) Quickly identify HTTP error responses indicating client and server problems
o) Quickly identify VoIP error responses indicating client, server or global errors
p) Build graphs to compare traffic behavior
q) Graph application throughput and compare to overall link traffic seen
r) Identify applications that do not encrypt traffic
s) Play back VoIP conversations to hear the effects of various network problems on network traffic
t) Perform passive operating system and application use detection
Some points should also be considered.
1) Spot unusual protocols and unrecognized port number usage on the network
2) Examine the startup process of hosts and applications on the network
3) Identify average and unacceptable service response times (SRT)
4) Graph intervals of periodic packet generation applications or protocols
Working of Wireshark for network security
The Wireshark interface has five major components which is used for network security purpose.
The command menus are standard pulldown menus located at the top of the window. Of interest to us now is the File and Capture menus. The File menu allows you to save captured packet data or open a file containing previously captured packet data, and exit the Wireshark application.
The Capture menu allows you to begin packet capture. The packet-listing window displays a one-line summary for each packet captured, including the packet number (assigned by Wireshark; this is not a packet number contained in any protocol’s header), the time at which the packet was captured, the packet’s source and destination addresses, the protocol type, and protocol-specific information contained in the packet.
The packet listing can be sorted according to any of these categories by clicking on a column name. The protocol type field lists the highest-level protocol that sent or received this packet, i.e., the protocol that is the source or ultimate sink for this packet.
The packet-header details window provides details about the packet selected (highlighted) in the packet-listing window. (To select a packet in the packet-listing window, place the cursor over the packet’s one-line summary in the packet-listing window and click with the left mouse button.). These details include information about the Ethernet frame and IP datagram that contains this packet. The amount of Ethernet and IP-layer detail displayed can be expanded or minimized by clicking on the right pointing or down-pointing arrowhead to the left of the Ethernet frame or IP datagram line in the packet details window. If the packet has been carried over TCP or UDP, TCP or UDP details will also be displayed, which can similarly be expanded or minimized. Finally, details about the highest-level protocol that sent or received this packet are also provided.
The packet-contents window displays the entire contents of the captured frame, in both ASCII and hexadecimal format.
Towards the top of the Wireshark graphical user interface, is the packet display filter field, into which a protocol name or other information can be entered in order to filter the information displayed in the packet-listing window (and hence the packet-header and packet-contents windows). In the example below, we’ll use the packet-display filter field to have Wireshark hide (not display) packets except those that correspond to HTTP messages.
References:
1. Kurose, Ross, “Computer Networking a Top-Down Approach Featuring the Internet”, Pearson, ISBN-10: 0132856204
2. L. Peterson and B. Davie, “Computer Networks: A Systems Approach”, 5th Edition, Morgan-Kaufmann, 2012.
3. Douglas E. Comer & M.S Narayanan, “Computer Network & Internet”, Pearson Education
4. William Stallings, “Cryptography and Network Security: Principles and Practice”, 4th Edition
5. Pachghare V. K., “Cryptography and Information Security”, 3rd Edition, PHI




