Unit 1
Foundations of Object Oriented Programming
Ernest Tello, A well-known writer in the field of artificial intelligence, compared the evolution of software technology to the growth of the tree. Like a tree, the software evolution has had distinct phases “layers” of growth. These layers were building up one by one over the last five decades as shown with each layer representing and improvement over the previous one. However, the analogy fails if we consider the life of these layers. In software system each of the layers continues to be functional, whereas in the case of trees, only the uppermost layer is functional
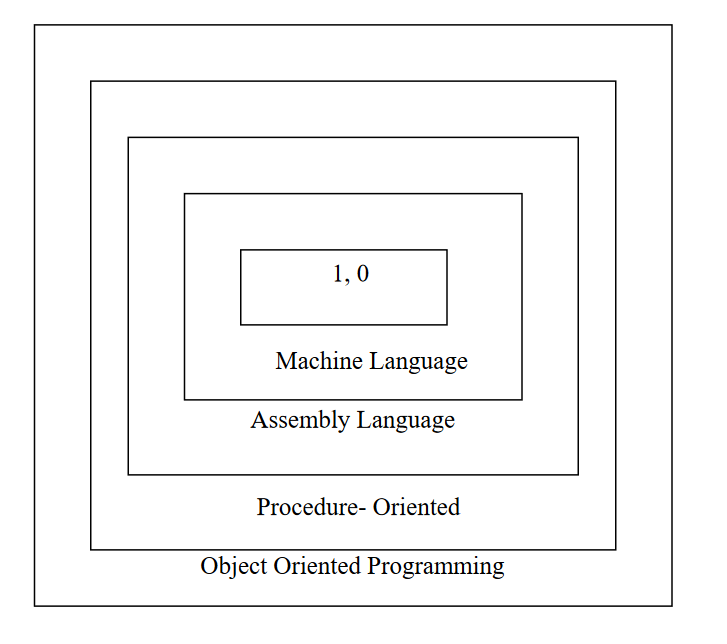
Alan Kay, one of the promoters of the object-oriented paradigm and the principal designer of Smalltalk, has said: “As complexity increases, architecture dominates the basic materials”. To build today’s complex software it is just not enough to put together a sequence of programming statements and sets of procedures and modules; we need to incorporate sound construction techniques and program structures that are easy to comprehend implement and modify.
With the advent of languages such as c, structured programming became very popular and was the main technique of the 1980’s. Structured programming was a powerful tool that enabled programmers to write moderately complex programs fairly easily. However, as the programs grew larger, even the structured approach failed to show the desired result in terms of bug-free, easy-to- maintain, and reusable programs.
Object Oriented Programming (OOP) is an approach to program organization and development that attempts to eliminate some of the pitfalls of conventional programming methods by incorporating the best of structured programming features with several powerful new concepts. It is a new way of organizing and developing programs and has nothing to do with any particular language. However, not all languages are suitable to implement the OOP concepts easily.
In the procedure-oriented approach, the problem is viewed as the sequence of things to be done such as reading, calculating and printing such as cobol, fortran and c. The primary focus is on functions. A typical structure for procedural programming is shown. The technique of hierarchical decomposition has been used to specify the tasks to be completed for solving a problem.
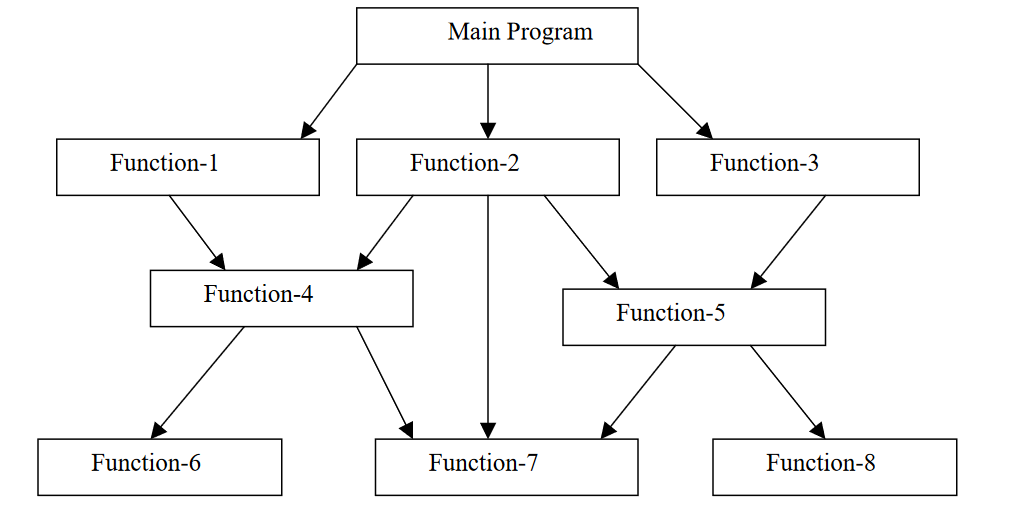
Procedure oriented programming basically consists of writing a list of instructions for the computer to follow, and organizing these instructions into groups known as functions. We normally use flowcharts to organize these actions and represent the flow of control from one action to another.
In a multi-function program, many important data items are placed as global so that they may be accessed by all the functions. Each function may have its own local data. Global data are more vulnerable to an inadvertent change by a function. In a large program it is very difficult to identify what data is used by which function. In case we need to revise an external data structure, we also need to revise all functions that access the data. This provides an opportunity for bugs to creep in.
Another serious drawback with the procedural approach is that we do not model real world problems very well. This is because functions are action-oriented and do not really corresponding to the element of the problem.
Some Characteristics exhibited by procedure-oriented programming are: • Emphasis is on doing things (algorithms).
• Large programs are divided into smaller programs known as functions.
• Most of the functions share global data.
• Data move openly around the system from function to function.
• Functions transform data from one form to another.
• Employs top-down approach in program design.
Principles of Object-Oriented Systems
The conceptual framework of object–oriented systems is based upon the object model. There are two categories of elements in an object-oriented system −
Major Elements−By major, it is meant that if a model does not have any one of these elements, it ceases to be object oriented. The four major elements are −
- Abstraction
- Encapsulation
- Modularity
- Hierarchy
Minor Elements−By minor, it is meant that these elements are useful, but not indispensable part of the object model. The three minor elements are −
- Typing
- Concurrency
- Persistence
Abstraction
Abstraction means to focus on the essential features of an element or object in OOP, ignoring its extraneous or accidental properties. The essential features are relative to the context in which the object is being used.
Grady Booch has defined abstraction as follows −
“An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of objects and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.”
Example− When a class Student is designed, the attributes enrolment_number, name, course, and address are included while characteristics like pulse_rate and size of_shoe are eliminated, since they are irrelevant in the perspective of the educational institution.
Encapsulation
Encapsulation is the process of binding both attributes and methods together within a class. Through encapsulation, the internal details of a class can be hidden from outside. The class has methods that provide user interfaces by which the services provided by the class may be used.
Modularity
Modularity is the process of decomposing a problem (program) into a set of modules so as to reduce the overall complexity of the problem. Booch has defined modularity as −
“Modularity is the property of a system that has been decomposed into a set of cohesive and loosely coupled modules.”
Modularity is intrinsically linked with encapsulation. Modularity can be visualized as a way of mapping encapsulated abstractions into real, physical modules having high cohesion within the modules and their inter–module interaction or coupling is low.
Hierarchy
In Grady Booch’s words, “Hierarchy is the ranking or ordering of abstraction”. Through hierarchy, a system can be made up of interrelated subsystems, which can have their own subsystems and so on until the smallest level components are reached. It uses the principle of “divide and conquer”. Hierarchy allows code reusability.
The two types of hierarchies in OOA are −
- “IS–A” hierarchy− It defines the hierarchical relationship in inheritance, whereby from a super-class, a number of subclasses may be derived which may again have subclasses and so on. For example, if we derive a class Rose from a class Flower, we can say that a rose “is–a” flower.
- “PART–OF” hierarchy− It defines the hierarchical relationship in aggregation by which a class may be composed of other classes. For example, a flower is composed of sepals, petals, stamens, and carpel. It can be said that a petal is a “part–of” flower.
Typing
According to the theories of abstract data type, a type is a characterization of a set of elements. In OOP, a class is visualized as a type having properties distinct from any other types. Typing is the enforcement of the notion that an object is an instance of a single class or type. It also enforces that objects of different types may not be generally interchanged; and can be interchanged only in a very restricted manner if absolutely required to do so.
The two types of typing are −
- Strong Typing− Here, the operation on an object is checked at the time of compilation, as in the programming language Eiffel.
- Weak Typing− Here, messages may be sent to any class. The operation is checked only at the time of execution, as in the programming language Smalltalk.
Concurrency
Concurrency in operating systems allows performing multiple tasks or processes simultaneously. When a single process exists in a system, it is said that there is a single thread of control. However, most systems have multiple threads, some active, some waiting for CPU, some suspended, and some terminated. Systems with multiple CPUs inherently permit concurrent threads of control; but systems running on a single CPU use appropriate algorithms to give equitable CPU time to the threads so as to enable concurrency.
In an object-oriented environment, there are active and inactive objects. The active objects have independent threads of control that can execute concurrently with threads of other objects. The active objects synchronize with one another as well as with purely sequential objects.
Persistence
An object occupies a memory space and exists for a particular period of time. In traditional programming, the lifespan of an object was typically the lifespan of the execution of the program that created it. In files or databases, the object lifespan is longer than the duration of the process creating the object. This property by which an object continues to exist even after its creator ceases to exist is known as persistence.
Object-oriented programming
Object-oriented programming is based on the three concepts encapsulation, inheritance, and polymorphism.
Encapsulation
An object encapsulates its attributes and methods and provides them via an interface to the outside world. This property that an object hides its implementation is often called data hiding.
Inheritance
A derived class get all characteristics from its base class. You can use an instance of a derived class as an instance of its base class. We often speak about code reuse because the derived class automatically gets all characteristics of the base class .
Polymorphism
Polymorphism is the ability to present the same interface for differing underlying data types. The term is from Greek and stands for many forms.
1 2 3 4 5 6 7 8 9 10 11 12 13 | Class HumanBeing{ Public: HumanBeing(std::stringn):name(n){} Virtual std::string getName() const{ Return name; } Private: Std::string name; };
Class Man: public HumanBeing{};
Class Woman: public HumanBeing{}; |
In the example you only get the name of HumanBeing by using the method getName in line 4 (encapsulation). In addition, getName is declared as virtual. Therefore, derived classes can change the behaviour of their methods and therefore change the behaviour of their objects (polymorphism). Man and Woman are derived from HumanBeing.
Generic programming
The key idea of generic programming or programming with templates is to define families of functions or classes. By providing the concrete type you get automatically a function or a class for this type. Generic programming provides similar abstraction like object-oriented programming. A big difference is that polymorphism of object-oriented programming will happen at runtime; that polymorphism of generic programming will happen in C++ at compile time. That the reason why polymorphism at runtime is often called dynamic polymorphism but polymorphism at compile is often called static polymorphism.
By using the function template I can exchange arbitrary objects.
1 2 3 4 5 6 7 8 9 10 11 12 | Template <typename T> void xchg(T& x, T& y){ T t= x; x= y; y= t; }; Inti= 10; Int j= 20; Man huber; Man maier;
Xchg(i,j); Xchg(huber,maier); |
It doesn't matter for the function template, if I exchange numbers or men (line 11 and 12). In addition, I have not to specify the type parameter (line) because the compiler can derived it from the function arguments (line 11 and 12).
The automatic type deduction of function templates will not hold for class templates. In the concrete case I have to specify the type parameter T and the non-type parameter N (line 1).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Template <typename T, int N> Class Array{ Public: IntgetSize() const{ Return N; } Private: T elem[N]; };
Array<double,10>doubleArray; Std::cout<<doubleArray.getSize() <<std::endl;
Array<Man,5>manArray; Std::cout<<manArray.getSize() <<std::endl; |
Accordingly, the application of the class template Array is independent of the fact, whether I use doubles or men.
Functional programming
A will only say a few words about functional programming because I will and can not explain the concept of functional programming in a short remark. Only that much. I use the code snippet the pendants in C++ to the typical functions in functional programming: map, filter, and reduce. These are the functions std::transform, std::remove_if, and std::accumulate.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Std::vector<int>vec{1,2,3,4,5,6,7,8,9}; Std::vector<std::string>str{"Programming","in","a","functional","style."};
Std::transform(vec.begin(),vec.end(),vec.begin(), [](inti){ return i*i; }); // {1,4,9,16,25,36,49,64,81}
Auto it= std::remove_if(vec.begin(),vec.end(), [](inti){ return ((i< 3) or (i> 8)) }); // {3,4,5,6,7,8} Auto it2= std::remove_if(str.begin(),str.end(), [](string s){ return (std::lower(s[0])); }); // "Programming"
Std::accumulate(vec.begin(),vec.end(),[](inta,int b){return a*b;}); // 362880 Std::accumulate(str.begin(),str.end(), [](std::string a,std::string b){return a + ":"+ b;}); // "Programming:in:a:functional:style." |
I apply in the code snippet two powerful features of functional programming. Both are now mainstream in modern C++: automatic type deduction with auto and lambda-functions.
- Well, although procedural-oriented programs are extremely powerful, they do have some limitations.
- Perhaps the most serious limitation is the tendency for large procedural-based programs to turn into "spaghetti-code".
- Spaghetti code is code that has been modified so many times that the logical flow shown in the figures above becomes so convoluted that any new programmer coming onto the project needs a two month prep-course in order to even begin to understand the software innards.
- Why does this happen?
- Well, in reality, a programmer's job has just begun when she finishes writing version 1.0 of her software application. Before she knows it, she'll be bombarded with dozens of modification requests and bug reports as users actually get to batter and bruise her poor piece of code.
- In order to meet the demands of the evil user, the programmer is forced to modify the code. This can mean introducing new sub loops, new eddies of flow control and new methods, libraries and variables altogether.
- Unfortunately, there are no great tools for abstraction and modularization in procedural languages...thus, it is hard to add new functionality or change the work flow without going back and modifying all other parts of the program.
- Now, instead of redesigning the workflow and starting from scratch, most programmers, under intense time restrictions will introduce hacks to fix the code.
- This gets us to the second problem with procedural-based programming. Not only does procedural code have a tendency to be difficult to understand, as it evolves, it becomes even harder to understand, and thus, harder to modify.
- Since everything is tied to everything else, nothing is independent. If you change one bit of code in a procedural-based program, it is likely that you will break three other pieces in some other section that might be stored in some remote library file you'd forgotten all about.
- A final problem with spaghetification is that the code you write today will not help you write the code you have to write tomorrow. Procedural-based code has a tenacious ability to resist being cut and pasted from one application to another. Thus, procedural programmers often find themselves reinventing the wheel on every new project.
For Example: Consider the Class of Cars. There may be many cars with different names and brand but all of them will share some common properties like all of them will have 4 wheels, Speed Limit, Mileage range etc. So here, Car is the class and wheels, speed limits, mileage are their properties.
- A Class is a user-defined data-type which has data members and member functions.
- Data members are the data variables and member functions are the functions used to manipulate these variables and together these data members and member functions define the properties and behaviour of the objects in a Class.
- In the above example of class Car, the data member will be speed limit, mileage etc and member functions can apply brakes, increase speed etc.
We can say that a Class in C++ is a blue-print representing a group of objects which shares some common properties and behaviours.
Object: An Object is an identifiable entity with some characteristics and behaviour. An Object is an instance of a Class. When a class is defined, no memory is allocated but when it is instantiated (i.e. an object is created) memory is allocated.
Classperson { Charname[20]; Intid; Public: Voidgetdetails(){} };
Intmain() { Person p1; // p1 is a object } |
Object take up space in memory and have an associated address like a record in pascal or structure or union in C.
When a program is executed the objects interact by sending messages to one another.
Each object contains data and code to manipulate the data. Objects can interact without having to know details of each other’s data or code, it is sufficient to know the type of message accepted and type of response returned by the objects.
Encapsulation: In normal terms, Encapsulation is defined as wrapping up of data and information under a single unit. In Object-Oriented Programming, Encapsulation is defined as binding together the data and the functions that manipulate them.
Consider a real-life example of encapsulation, in a company, there are different sections like the accounts section, finance section, sales section etc. The finance section handles all the financial transactions and keeps records of all the data related to finance. Similarly, the sales section handles all the sales-related activities and keeps records of all the sales. Now there may arise a situation when for some reason an official from the finance section needs all the data about sales in a particular month. In this case, he is not allowed to directly access the data of the sales section. He will first have to contact some other officer in the sales section and then request him to give the particular data. This is what encapsulation is. Here the data of the sales section and the employees that can manipulate them are wrapped under a single name “sales section”.

Encapsulation in C++
Encapsulation also leads to data abstraction or hiding. As using encapsulation also hides the data. In the above example, the data of any of the section like sales, finance or accounts are hidden from any other section.
Abstraction: Data abstraction is one of the most essential and important features of object-oriented programming in C++. Abstraction means displaying only essential information and hiding the details. Data abstraction refers to providing only essential information about the data to the outside world, hiding the background details or implementation.
Consider a real-life example of a man driving a car. The man only knows that pressing the accelerators will increase the speed of the car or applying brakes will stop the car but he does not know about how on pressing accelerator the speed is actually increasing, he does not know about the inner mechanism of the car or the implementation of accelerator, brakes etc in the car. This is what abstraction is.
- Abstraction using Classes: We can implement Abstraction in C++ using classes. The class helps us to group data members and member functions using available access specifiers. A Class can decide which data member will be visible to the outside world and which is not.
- Abstraction in Header files: One more type of abstraction in C++ can be header files. For example, consider the pow() method present in math.h header file. Whenever we need to calculate the power of a number, we simply call the function pow() present in the math.h header file and pass the numbers as arguments without knowing the underlying algorithm according to which the function is actually calculating the power of numbers.
Polymorphism: The word polymorphism means having many forms. In simple words, we can define polymorphism as the ability of a message to be displayed in more than one form.
A person at the same time can have different characteristic. Like a man at the same time is a father, a husband, an employee. So the same person possesses different behaviour in different situations. This is called polymorphism.
An operation may exhibit different behaviours in different instances. The behaviour depends upon the types of data used in the operation.
C++ supports operator overloading and function overloading.
- Operator Overloading: The process of making an operator to exhibit different behaviours in different instances is known as operator overloading.
- Function Overloading: Function overloading is using a single function name to perform different types of tasks.
Polymorphism is extensively used in implementing inheritance.
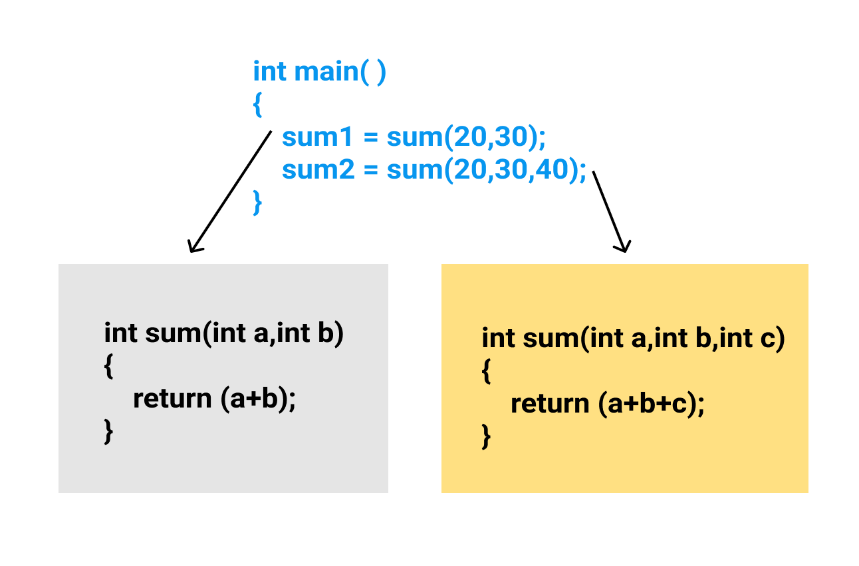
Example: Suppose we have to write a function to add some integers, some times there are 2 integers, sometimes there are 3 integers. We can write the Addition Method with the same name having different parameters; the concerned method will be called according to parameters.
Inheritance: The capability of a class to derive properties and characteristics from another class is called Inheritance. Inheritance is one of the most important features of Object-Oriented Programming.
- Sub Class: The class that inherits properties from another class is called Sub class or Derived Class.
- Super Class: The class whose properties are inherited by sub class is called Base Class or Super class.
- Reusability: Inheritance supports the concept of “reusability”, i.e. when we want to create a new class and there is already a class that includes some of the code that we want, we can derive our new class from the existing class. By doing this, we are reusing the fields and methods of the existing class.
Example: Dog, Cat, Cow can be Derived Class of Animal Base Class.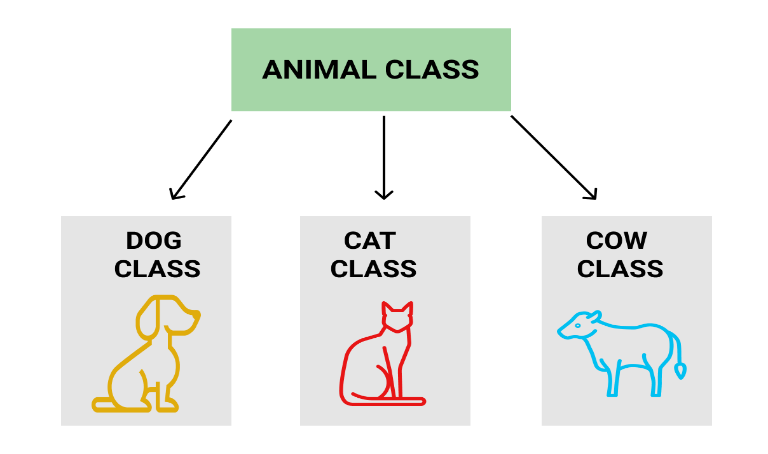
Dynamic Binding: In dynamic binding, the code to be executed in response to function call is decided at runtime. C++ has virtual function to support this.
Message Passing: Objects communicate with one another by sending and receiving information to each other. A message for an object is a request for execution of a procedure and therefore will invoke a function in the receiving object that generates the desired results. Message passing involves specifying the name of the object, the name of the function and the information to be sent.
Objects
Objects are the basic run time entities in an object-oriented system. They may represent a person, a place, a bank account, a table of data or any item that the program has to handle. They may also represent user-defined data such as vectors, time and lists. Programming problem is analyzed in term of objects and the nature of communication between them. Program objects should be chosen such that they match closely with the real-world objects. Objects take up space in the memory and have an associated address like a record in Pascal, or a structure in c.
When a program is executed, the objects interact by sending messages to one another. For example, if “customer” and “account” are to object in a program, then the customer object may send a message to the count object requesting for the bank balance. Each object contain data, and code to manipulate data. Objects can interact without having to know details of each other’s data or code. It is a sufficient to know the type of message accepted, and the type of response returned by the objects. Although different author represent them differently shows two notations that are popularly used in object-oriented analysis and design.

Classes
We just mentioned that objects contain data, and code to manipulate that data. The entire set of data and code of an object can be made a user-defined data type with the help of class. In fact, objects are variables of the type class. Once a class has been defined, we can create any number of objects belonging to that class. Each object is associated with the data of type class with which they are created. A class is thus a collection of objects similar types. For examples, Mango, Apple and orange members of class fruit. Classes are user-defined that types and behave like the built-in types of a programming language. The syntax used to create an object is not different then the syntax used to create an integer object in C. If fruit has been defines as a class, then the statement
Fruit Mango;
Will create an object mango belonging to the class fruit.
Data Members
"Data Member" and "Member Functions" are the new names/terms for the members of a class, which are introduced in C++ programming language.
The variables which are declared in any class by using any fundamental data types (like int, char, float etc) or derived data type (like class, structure, pointer etc.) are known as Data Members. And the functions which are declared either in private section of public section are known as Member functions.
There are two types of data members/member functions in C++:
- Private members
- Public members
1) Private members
The members which are declared in private section of the class (using private access modifier) are known as private members. Private members can also be accessible within the same class in which they are declared.
2) Public members
The members which are declared in public section of the class (using public access modifier) are known as public members. Public members can access within the class and outside of the class by using the object name of the class in which they are declared.
Consider the example:
Class Test
{
Private:
Int a;
Float b;
Char *name;
VoidgetA() { a=10; }
...;
Public:
Int count;
VoidgetB() { b=20; }
...;
};
Here, a, b, and name are the private data members and count is a public data member. While, getA() is a private member function and getB() is public member functions.
How to declare, define and access data members an member functions in a class?
#include <iostream>
#include <string.h>
Using namespace std;
#define MAX_CHAR 30
//class definition
Class person
{
//private data members
Private:
Char name [MAX_CHAR];
Int age;
//public member functions
Public:
//function to get name and age
Void get(char n[], int a)
{
Strcpy(name , n);
Age = a;
}
//function to print name and age
Void put()
{
Cout<< "Name: " << name <<endl;
Cout<< "Age: " <<age <<endl;
}
};
//main function
Int main()
{
//creating an object of person class
Person PER;
//calling member functions
PER.get("Manju Tomar", 23);
PER.put();
Return 0;
}
Output
Name: Manju Tomar
Age: 23
As we can see in the program, that private members are directly accessible within the member functions and member functions are accessible within in main() function (outside of the class) by using period (dot) operator like object_name.member_name;
Methods
A function is a group of statements that together perform a task. Every C++ program has at least one function, which is main(), and all the most trivial programs can define additional functions.
You can divide up your code into separate functions. How you divide up your code among different functions is up to you, but logically the division usually is such that each function performs a specific task.
A function declaration tells the compiler about a function's name, return type, and parameters. A function definition provides the actual body of the function.
The C++ standard library provides numerous built-in functions that your program can call. For example, function strcat() to concatenate two strings, function memcpy() to copy one memory location to another location and many more functions.
A function is known with various names like a method or a sub-routine or a procedure etc.
Defining a Function
The general form of a C++ function definition is as follows −
Return_typefunction_name( parameter list ) {
Body of the function
}
A C++ function definition consists of a function header and a function body. Here are all the parts of a function −
- Return Type − A function may return a value. The return_type is the data type of the value the function returns. Some functions perform the desired operations without returning a value. In this case, the return_type is the keyword void.
- Function Name − This is the actual name of the function. The function name and the parameter list together constitute the function signature.
- Parameters − A parameter is like a placeholder. When a function is invoked, you pass a value to the parameter. This value is referred to as actual parameter or argument. The parameter list refers to the type, order, and number of the parameters of a function. Parameters are optional; that is, a function may contain no parameters.
- Function Body − The function body contains a collection of statements that define what the function does.
Example
Following is the source code for a function called max(). This function takes two parameters num1 and num2 and return the biggest of both −
// function returning the max between two numbers
Int max(int num1, int num2) {
// local variable declaration
Int result;
If (num1 > num2)
Result = num1;
Else
Result = num2;
Return result;
}
Function Declarations
A function declaration tells the compiler about a function name and how to call the function. The actual body of the function can be defined separately.
A function declaration has the following parts −
Return_typefunction_name( parameter list );
For the above defined function max(), following is the function declaration −
Int max(int num1, int num2);
Parameter names are not important in function declaration only their type is required, so following is also valid declaration −
Int max(int, int);
Function declaration is required when you define a function in one source file and you call that function in another file. In such case, you should declare the function at the top of the file calling the function.
Calling a Function
While creating a C++ function, you give a definition of what the function has to do. To use a function, you will have to call or invoke that function.
When a program calls a function, program control is transferred to the called function. A called function performs defined task and when it’s return statement is executed or when its function-ending closing brace is reached, it returns program control back to the main program.
To call a function, you simply need to pass the required parameters along with function name, and if function returns a value, then you can store returned value. For example −
#include <iostream>
Using namespace std;
// function declaration
Int max(int num1, int num2);
Int main () {
// local variable declaration:
Int a = 100;
Int b = 200;
Int ret;
// calling a function to get max value.
Ret = max(a, b);
Cout<< "Max value is : " << ret <<endl;
Return 0;
}
// function returning the max between two numbers
Int max(int num1, int num2) {
// local variable declaration
Int result;
If (num1 > num2)
Result = num1;
Else
Result = num2;
Return result;
}
I kept max() function along with main() function and compiled the source code. While running final executable, it would produce the following result −
Max value is : 200
Function Arguments
If a function is to use arguments, it must declare variables that accept the values of the arguments. These variables are called the formal parameters of the function.
The formal parameters behave like other local variables inside the function and are created upon entry into the function and destroyed upon exit.
While calling a function, there are two ways that arguments can be passed to a function −
Sr.No | Call Type & Description |
1 | Call by Value This method copies the actual value of an argument into the formal parameter of the function. In this case, changes made to the parameter inside the function have no effect on the argument. |
2 | Call by Pointer This method copies the address of an argument into the formal parameter. Inside the function, the address is used to access the actual argument used in the call. This means that changes made to the parameter affect the argument. |
3 | Call by Reference This method copies the reference of an argument into the formal parameter. Inside the function, the reference is used to access the actual argument used in the call. This means that changes made to the parameter affect the argument. |
By default, C++ uses call by value to pass arguments. In general, this means that code within a function cannot alter the arguments used to call the function and above mentioned example while calling max() function used the same method.
Default Values for Parameters
When you define a function, you can specify a default value for each of the last parameters. This value will be used if the corresponding argument is left blank when calling to the function.
This is done by using the assignment operator and assigning values for the arguments in the function definition. If a value for that parameter is not passed when the function is called, the default given value is used, but if a value is specified, this default value is ignored and the passed value is used instead. Consider the following example −
#include <iostream>
Using namespace std;
Int sum(int a, int b = 20) {
Int result;
Result = a + b;
Return (result);
}
Int main () {
// local variable declaration:
Int a = 100;
Int b = 200;
Int result;
// calling a function to add the values.
Result = sum(a, b);
Cout<< "Total value is :" << result <<endl;
// calling a function again as follows.
Result = sum(a);
Cout<< "Total value is :" << result <<endl;
Return 0;
}
When the above code is compiled and executed, it produces the following result −
Total value is :300
Total value is :120
Messages
The messages standard facet is used to read individual strings from a message catalog.
The specifics on how messages are organized in a catalog depend on the library implementation.
The messages class template has a protected destructor: Programs shall only construct objects of derived classes, or use those installed in locale objects (through use_facet).
All standard locale objects support at least the following facet instantiations of the messages class template as part of the messages category:
Facets in locale objects | Description |
Messages<char> | Narrow characters |
Messages<wchar_t> | Wide characters |
Template parameters
CharT
Character type.
This is the type of characters for the returned messages.
Aliased as member char_type.
Member types
Member type | Definition | Description |
Char_type | The template parameter (charT) | Character type |
String_type | Basic_string<charT> | The basic_string instantiation for characters of type charT (such as string for char). |
The class also inherits the catalog type from messages_base. This type is a mere alias (typedef) of a signed integer type.
Member constants
The class contains a public static constant of type locale::id that uniquely identifies facets with money_put semantics.
Public member functions
(constructor)
Messages constructor (public member function)
Open
Open message catalog (public member function )
Get
Get message from catalog (public member function )
Close
Closse message catalog (public member function )
Virtual protected member functionss
The class defines the virtual protected members which implement the behavior by default of their respective public member functions:
Do_open
Open message catalog [virtual] (protected virtual member function )
Do_get
Get message from catalog [virtual] (protected virtual member function )
Do_close
Close message catalog (protected virtual member function )
Along with the class destructor:
(destructor)
Messages destructor (protected member function )
Specializations
At least the following specializations of this template are provided in all library implementations:
Specialization |
Messages<char> |
Messages<wchar_t> |
Data Encapsulation, Data Abstraction
Data Encapsulation
All C++ programs are composed of the following two fundamental elements −
- Program statements (code) − This is the part of a program that performs actions and they are called functions.
- Program data − The data is the information of the program which gets affected by the program functions.
Encapsulation is an Object Oriented Programming concept that binds together the data and functions that manipulate the data, and that keeps both safe from outside interference and misuse. Data encapsulation led to the important OOP concept of data hiding.
Data encapsulation is a mechanism of bundling the data, and the functions that use them and data abstraction is a mechanism of exposing only the interfaces and hiding the implementation details from the user.
C++ supports the properties of encapsulation and data hiding through the creation of user-defined types, called classes. We already have studied that a class can contain private, protected and public members. By default, all items defined in a class are private. For example −
Class Box {
Public:
DoublegetVolume(void) {
Return length * breadth * height;
}
Private:
Double length; // Length of a box
Double breadth; // Breadth of a box
Double height; // Height of a box
};
The variables length, breadth, and height are private. This means that they can be accessed only by other members of the Box class, and not by any other part of your program. This is one way encapsulation is achieved.
To make parts of a class public (i.e., accessible to other parts of your program), you must declare them after the public keyword. All variables or functions defined after the public specifier are accessible by all other functions in your program.
Making one class a friend of another exposes the implementation details and reduces encapsulation. The ideal is to keep as many of the details of each class hidden from all other classes as possible.
Data Encapsulation Example
Any C++ program where you implement a class with public and private members is an example of data encapsulation and data abstraction. Consider the following example −
#include <iostream>
Using namespace std;
Class Adder {
Public:
// constructor
Adder(inti = 0) {
Total = i;
}
// interface to outside world
VoidaddNum(int number) {
Total += number;
}
// interface to outside world
IntgetTotal() {
Return total;
};
Private:
// hidden data from outside world
Int total;
};
Int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
Cout<< "Total " <<a.getTotal() <<endl;
Return 0;
}
When the above code is compiled and executed, it produces the following result −
Total 60
Above class adds numbers together, and returns the sum. The public membersaddNum and getTotal are the interfaces to the outside world and a user needs to know them to use the class. The private member total is something that is hidden from the outside world, but is needed for the class to operate properly.
Designing Strategy
Most of us have learnt to make class members private by default unless we really need to expose them. That's just good encapsulation.
This is applied most frequently to data members, but it applies equally to all members, including virtual functions.
Data Abstraction
Data abstraction refers to providing only essential information to the outside world and hiding their background details, i.e., to represent the needed information in program without presenting the details.
Data abstraction is a programming (and design) technique that relies on the separation of interface and implementation.
Let's take one real life example of a TV, which you can turn on and off, change the channel, adjust the volume, and add external components such as speakers, VCRs, and DVD players, BUT you do not know its internal details, that is, you do not know how it receives signals over the air or through a cable, how it translates them, and finally displays them on the screen.
Thus, we can say a television clearly separates its internal implementation from its external interface and you can play with its interfaces like the power button, channel changer, and volume control without having any knowledge of its internals.
In C++, classes provides great level of data abstraction. They provide sufficient public methods to the outside world to play with the functionality of the object and to manipulate object data, i.e., state without actually knowing how class has been implemented internally.
For example, your program can make a call to the sort() function without knowing what algorithm the function actually uses to sort the given values. In fact, the underlying implementation of the sorting functionality could change between releases of the library, and as long as the interface stays the same, your function call will still work.
In C++, we use classes to define our own abstract data types (ADT). You can use the cout object of class ostream to stream data to standard output like this −
#include <iostream>
Using namespace std;
Int main() {
Cout<< "Hello C++" <<endl;
Return 0;
}
Here, you don't need to understand how cout displays the text on the user's screen. You need to only know the public interface and the underlying implementation of ‘cout’ is free to change.
Access Labels Enforce Abstraction
In C++, we use access labels to define the abstract interface to the class. A class may contain zero or more access labels −
- Members defined with a public label are accessible to all parts of the program. The data-abstraction view of a type is defined by its public members.
- Members defined with a private label are not accessible to code that uses the class. The private sections hide the implementation from code that uses the type.
There are no restrictions on how often an access label may appear. Each access label specifies the access level of the succeeding member definitions. The specified access level remains in effect until the next access label is encountered or the closing right brace of the class body is seen.
Benefits of Data Abstraction
Data abstraction provides two important advantages −
- Class internals are protected from inadvertent user-level errors, which might corrupt the state of the object.
- The class implementation may evolve over time in response to changing requirements or bug reports without requiring change in user-level code.
By defining data members only in the private section of the class, the class author is free to make changes in the data. If the implementation changes, only the class code needs to be examined to see what affect the change may have. If data is public, then any function that directly access the data members of the old representation might be broken.
Data Abstraction Example
Any C++ program where you implement a class with public and private members is an example of data abstraction. Consider the following example −
#include <iostream>
Using namespace std;
Class Adder {
Public:
// constructor
Adder(inti = 0) {
Total = i;
}
// interface to outside world
VoidaddNum(int number) {
Total += number;
}
// interface to outside world
IntgetTotal() {
Return total;
};
Private:
// hidden data from outside world
Int total;
};
Int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
Cout<< "Total " <<a.getTotal() <<endl;
Return 0;
}
When the above code is compiled and executed, it produces the following result −
Total 60
Above class adds numbers together, and returns the sum. The public members - addNum and getTotal are the interfaces to the outside world and a user needs to know them to use the class. The private member total is something that the user doesn't need to know about, but is needed for the class to operate properly.
Designing Strategy
Abstraction separates code into interface and implementation. So while designing your component, you must keep interface independent of the implementation so that if you change underlying implementation then interface would remain intact.
In this case whatever programs are using these interfaces; they would not be impacted and would just need a recompilation with the latest implementation.
Information Hiding
Information hiding is a principle of OOP, where a stable interface is open to the rest of the program while its implementation details are hidden. This is usually achieved in OO languages (such as C++ and Java) by controlling access over the methods and fields of a class.
The problem is that C has only structs and their fields are always public, so the rest of the program always has access to the struct fields. This introduces the danger of higher coupling between modules, by directly manipulating the fields of a foreign data structure.
Fortunately, we can solve this by utilizing type forward declaration. For example, we can simulate an immutable class using the following structure:
// person.h
// Type forward declaration
// #include "person.h" provides that the type exists, but never shows the internal structure
Struct _person_t;
Typedefstruct _person_tperson_t;
// Simulates class constructor
Person_t *person_create(const char *name, unsigned int age);
// Simulates field getters
Const char *person_get_name(person_t *person);
Unsignedintperson_get_age(person_t *person);
// Simulates class destructor
Voidperson_destroy(person_t *person);
// person.c
// By defining the internal structure here, we can prevent direct manipulation of
// the struct's fields.
Typedefstruct _person_t {
Const char *name;
Unsignedint age;
} person_t;
Person_t *person_create(const char *name, unsigned int age) {
// Create and initialize an instance using malloc()
// Or, you can use any other custom strategy,
// e.g. For limiting memory usage or number of instances
Returnnew_person;
}
Const char *person_get_name(person_t *person) {
Return person->name;
}
Unsignedintperson_get_age(person_t *person) {
Return person->age;
}
Voidperson_destroy(person_t *person) {
// Destroy the instance using free()
// Or, if you used an alternative strategy in person_create(), use custom cleanup routine here
}
In C++, inheritance is a process in which one object acquires all the properties and behaviors of its parent object automatically. In such way, you can reuse, extend or modify the attributes and behaviours which are defined in other class.
In C++, the class which inherits the members of another class is called derived class and the class whose members are inherited is called base class. The derived class is the specialized class for the base class.
Advantage of C++ Inheritance
Code reusability: Now you can reuse the members of your parent class. So, there is no need to define the member again. So less code is required in the class.
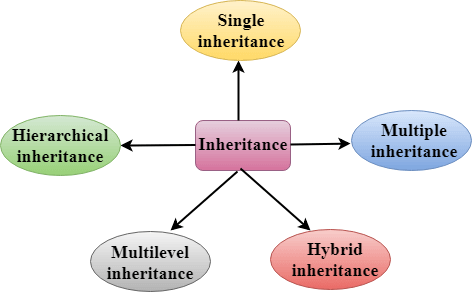
Types Of Inheritance
C++ supports five types of inheritance:
- Single inheritance
- Multiple inheritance
- Hierarchical inheritance
- Multilevel inheritance
- Hybrid inheritance
Derived Classes
A Derived class is defined as the class derived from the base class.
The Syntax of Derived class:
- Class derived_class_name :: visibility-mode base_class_name
- {
- // body of the derived class.
- }
Where,
Derived_class_name: It is the name of the derived class.
Visibility mode: The visibility mode specifies whether the features of the base class are publicly inherited or privately inherited. It can be public or private.
Base_class_name: It is the name of the base class.
- When the base class is privately inherited by the derived class, public members of the base class becomes the private members of the derived class. Therefore, the public members of the base class are not accessible by the objects of the derived class only by the member functions of the derived class.
- When the base class is publicly inherited by the derived class, public members of the base class also become the public members of the derived class. Therefore, the public members of the base class are accessible by the objects of the derived class as well as by the member functions of the base class.
Note:
- In C++, the default mode of visibility is private.
- The private members of the base class are never inherited.
C++ Single Inheritance
Single inheritance is defined as the inheritance in which a derived class is inherited from the only one base class.
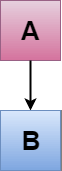
Where 'A' is the base class, and 'B' is the derived class.
C++ Single Level Inheritance Example: Inheriting Fields
When one class inherits another class, it is known as single level inheritance. Let's see the example of single level inheritance which inherits the fields only.
- #include <iostream>
- Using namespace std;
- Class Account {
- Public:
- Float salary = 60000;
- };
- Class Programmer: public Account {
- Public:
- Float bonus = 5000;
- };
- Int main(void) {
- Programmer p1;
- Cout<<"Salary: "<<p1.salary<<endl;
- Cout<<"Bonus: "<<p1.bonus<<endl;
- Return 0;
- }
Output:
Salary: 60000
Bonus: 5000
In the above example, Employee is the base class and Programmer is the derived class.
C++ Single Level Inheritance Example: Inheriting Methods
Let's see another example of inheritance in C++ which inherits methods only.
- #include <iostream>
- Using namespace std;
- Class Animal {
- Public:
- Void eat() {
- Cout<<"Eating..."<<endl;
- }
- };
- Class Dog: public Animal
- {
- Public:
- Void bark(){
- Cout<<"Barking...";
- }
- };
- Int main(void) {
- Dog d1;
- d1.eat();
- d1.bark();
- Return 0;
- }
Output:
Eating...
Barking...
Let's see a simple example.
- #include <iostream>
- Using namespace std;
- Class A
- {
- Int a = 4;
- Int b = 5;
- Public:
- Int mul()
- {
- Int c = a*b;
- Return c;
- }
- };
- Class B : private A
- {
- Public:
- Void display()
- {
- Int result = mul();
- Std::cout <<"Multiplication of a and b is : "<<result<< std::endl;
- }
- };
- Int main()
- {
- B b;
- b.display();
- Return 0;
- }
Output:
Multiplication of a and b is : 20
In the above example, class A is privately inherited. Therefore, the mul() function of class 'A' cannot be accessed by the object of class B. It can only be accessed by the member function of class B.
How to make a Private Member Inheritable
The private member is not inheritable. If we modify the visibility mode by making it public, but this takes away the advantage of data hiding.
C++ introduces a third visibility modifier, i.e., protected. The member which is declared as protected will be accessible to all the member functions within the class as well as the class immediately derived from it.
Visibility modes can be classified into three categories:
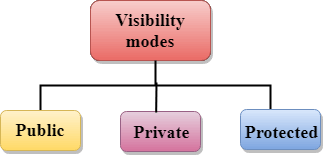
- Public: When the member is declared as public, it is accessible to all the functions of the program.
- Private: When the member is declared as private, it is accessible within the class only.
- Protected: When the member is declared as protected, it is accessible within its own class as well as the class immediately derived from it.
Visibility of Inherited Members
Base class visibility | Derived class visibility | ||
Public | Private | Protected | |
Private | Not Inherited | Not Inherited | Not Inherited |
Protected | Protected | Private | Protected |
Public | Public | Private | Protected |
C++ Multilevel Inheritance
Multilevel inheritance is a process of deriving a class from another derived class.

C++ Multi Level Inheritance Example
When one class inherits another class which is further inherited by another class, it is known as multi level inheritance in C++. Inheritance is transitive so the last derived class acquires all the members of all its base classes.
Let's see the example of multi level inheritance in C++.
- #include <iostream>
- Using namespace std;
- Class Animal {
- Public:
- Void eat() {
- Cout<<"Eating..."<<endl;
- }
- };
- Class Dog: public Animal
- {
- Public:
- Void bark(){
- Cout<<"Barking..."<<endl;
- }
- };
- Class BabyDog: public Dog
- {
- Public:
- Void weep() {
- Cout<<"Weeping...";
- }
- };
- Int main(void) {
- BabyDog d1;
- d1.eat();
- d1.bark();
- d1.weep();
- Return 0;
- }
Output:
Eating...
Barking...
Weeping...
C++ Multiple Inheritance
Multiple inheritance is the process of deriving a new class that inherits the attributes from two or more classes.
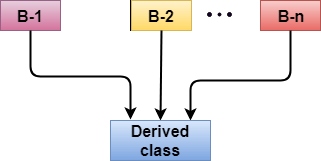
Syntax of the Derived class:
- Class D : visibility B-1, visibility B-2, ?
- {
- // Body of the class;
- }
Let's see a simple example of multiple inheritance.
- #include <iostream>
- Using namespace std;
- Class A
- {
- Protected:
- Int a;
- Public:
- Void get_a(int n)
- {
- a = n;
- }
- };
- Class B
- {
- Protected:
- Int b;
- Public:
- Void get_b(int n)
- {
- b = n;
- }
- };
- Class C : public A,public B
- {
- Public:
- Void display()
- {
- Std::cout << "The value of a is : " <<a<< std::endl;
- Std::cout << "The value of b is : " <<b<< std::endl;
- Cout<<"Addition of a and b is : "<<a+b;
- }
- };
- Int main()
- {
- C c;
- c.get_a(10);
- c.get_b(20);
- c.display();
- Return 0;
- }
Output:
The value of a is : 10
The value of b is : 20
Addition of a and b is : 30
In the above example, class 'C' inherits two base classes 'A' and 'B' in a public mode.
Ambiquity Resolution in Inheritance
Ambiguity can be occurred in using the multiple inheritance when a function with the same name occurs in more than one base class.
Let's understand this through an example:
- #include <iostream>
- Using namespace std;
- Class A
- {
- Public:
- Void display()
- {
- Std::cout << "Class A" << std::endl;
- }
- };
- Class B
- {
- Public:
- Void display()
- {
- Std::cout << "Class B" << std::endl;
- }
- };
- Class C : public A, public B
- {
- Void view()
- {
- Display();
- }
- };
- Int main()
- {
- C c;
- c.display();
- Return 0;
- }
Output:
Error: reference to 'display' is ambiguous
Display();
- The above issue can be resolved by using the class resolution operator with the function. In the above example, the derived class code can be rewritten as:
- Class C : public A, public B
- {
- Void view()
- {
- A :: display(); // Calling the display() function of class A.
- B :: display(); // Calling the display() function of class B.
- }
- };
An ambiguity can also occur in single inheritance.
Consider the following situation:
- Class A
- {
- Public:
- Void display()
- {
- Cout<<?Class A?;
- }
- } ;
- Class B
- {
- Public:
- Void display()
- {
- Cout<<?Class B?;
- }
- } ;
In the above case, the function of the derived class overrides the method of the base class. Therefore, call to the display() function will simply call the function defined in the derived class. If we want to invoke the base class function, we can use the class resolution operator.
- Int main()
- {
- B b;
- b.display(); // Calling the display() function of B class.
- b.B :: display(); // Calling the display() function defined in B class.
- }
C++ Hybrid Inheritance
Hybrid inheritance is a combination of more than one type of inheritance.
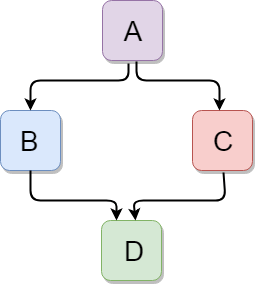
Let's see a simple example:
- #include <iostream>
- Using namespace std;
- Class A
- {
- Protected:
- Int a;
- Public:
- Void get_a()
- {
- Std::cout << "Enter the value of 'a' : " << std::endl;
- Cin>>a;
- }
- };
- Class B : public A
- {
- Protected:
- Int b;
- Public:
- Void get_b()
- {
- Std::cout << "Enter the value of 'b' : " << std::endl;
- Cin>>b;
- }
- };
- Class C
- {
- Protected:
- Int c;
- Public:
- Void get_c()
- {
- Std::cout << "Enter the value of c is : " << std::endl;
- Cin>>c;
- }
- };
- Class D : public B, public C
- {
- Protected:
- Int d;
- Public:
- Void mul()
- {
- Get_a();
- Get_b();
- Get_c();
- Std::cout << "Multiplication of a,b,c is : " <<a*b*c<< std::endl;
- }
- };
- Int main()
- {
- D d;
- d.mul();
- Return 0;
- }
Output:
Enter the value of 'a' :
10
Enter the value of 'b' :
20
Enter the value of c is :
30
Multiplication of a,b,c is : 6000
C++ Hierarchical Inheritance
Hierarchical inheritance is defined as the process of deriving more than one class from a base class.
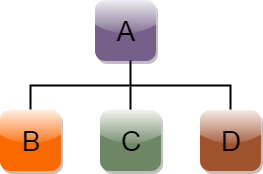
Syntax of Hierarchical inheritance:
- Class A
- {
- // body of the class A.
- }
- Class B : public A
- {
- // body of class B.
- }
- Class C : public A
- {
- // body of class C.
- }
- Class D : public A
- {
- // body of class D.
- }
Let's see a simple example:
- #include <iostream>
- Using namespace std;
- Class Shape // Declaration of base class.
- {
- Public:
- Int a;
- Int b;
- Void get_data(int n,int m)
- {
- a= n;
- b = m;
- }
- };
- Class Rectangle : public Shape // inheriting Shape class
- {
- Public:
- Int rect_area()
- {
- Int result = a*b;
- Return result;
- }
- };
- Class Triangle : public Shape // inheriting Shape class
- {
- Public:
- Int triangle_area()
- {
- Float result = 0.5*a*b;
- Return result;
- }
- };
- Int main()
- {
- Rectangle r;
- Triangle t;
- Int length,breadth,base,height;
- Std::cout << "Enter the length and breadth of a rectangle: " << std::endl;
- Cin>>length>>breadth;
- r.get_data(length,breadth);
- Int m = r.rect_area();
- Std::cout << "Area of the rectangle is : " <<m<< std::endl;
- Std::cout << "Enter the base and height of the triangle: " << std::endl;
- Cin>>base>>height;
- t.get_data(base,height);
- Float n = t.triangle_area();
- Std::cout <<"Area of the triangle is : " << n<<std::endl;
- Return 0;
- }
Output:
Enter the length and breadth of a rectangle:
23
20
Area of the rectangle is : 460
Enter the base and height of the triangle:
2
5
Area of the triangle is : 5
The term "Polymorphism" is the combination of "poly" + "morphs" which means many forms. It is a greek word. In object-oriented programming, we use 3 main concepts: inheritance, encapsulation, and polymorphism.
Real Life Example Of Polymorphism
Let's consider a real-life example of polymorphism. A lady behaves like a teacher in a classroom, mother or daughter in a home and customer in a market. Here, a single person is behaving differently according to the situations.
There are two types of polymorphism in C++:
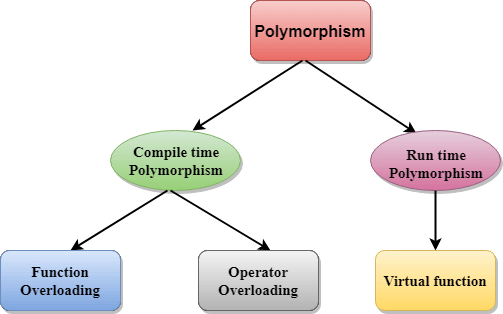
- Compile time polymorphism: The overloaded functions are invoked by matching the type and number of arguments. This information is available at the compile time and, therefore, compiler selects the appropriate function at the compile time. It is achieved by function overloading and operator overloading which is also known as static binding or early binding. Now, let's consider the case where function name and prototype is same.
- Class A // base class declaration.
- {
- Int a;
- Public:
- Void display()
- {
- Cout<< "Class A ";
- }
- };
- Class B : public A // derived class declaration.
- {
- Int b;
- Public:
- Void display()
- {
- Cout<<"Class B";
- }
- };
In the above case, the prototype of display() function is the same in both the base and derived class. Therefore, the static binding cannot be applied. It would be great if the appropriate function is selected at the run time. This is known as run time polymorphism.
- Run time polymorphism: Run time polymorphism is achieved when the object's method is invoked at the run time instead of compile time. It is achieved by method overriding which is also known as dynamic binding or late binding.
Differences b/w compile time and run time polymorphism.
Compile time polymorphism | Run time polymorphism |
The function to be invoked is known at the compile time. | The function to be invoked is known at the run time. |
It is also known as overloading, early binding and static binding. | It is also known as overriding, Dynamic binding and late binding. |
Overloading is a compile time polymorphism where more than one method is having the same name but with the different number of parameters or the type of the parameters. | Overriding is a run time polymorphism where more than one method is having the same name, number of parameters and the type of the parameters. |
It is achieved by function overloading and operator overloading. | It is achieved by virtual functions and pointers. |
It provides fast execution as it is known at the compile time. | It provides slow execution as it is known at the run time. |
It is less flexible as mainly all the things execute at the compile time. | It is more flexible as all the things execute at the run time. |
C++ Runtime Polymorphism Example
Let's see a simple example of run time polymorphism in C++.
// an example without the virtual keyword.
- #include <iostream>
- Using namespace std;
- Class Animal {
- Public:
- Void eat(){
- Cout<<"Eating...";
- }
- };
- Class Dog: public Animal
- {
- Public:
- Void eat()
- { cout<<"Eating bread...";
- }
- };
- Int main(void) {
- Dog d = Dog();
- d.eat();
- Return 0;
- }
Output:
Eating bread...
C++ Run time Polymorphism Example: By using two derived class
Let's see another example of run time polymorphism in C++ where we are having two derived classes.
// an example with virtual keyword.
- #include <iostream>
- Using namespace std;
- Class Shape { // base class
- Public:
- Virtual void draw(){ // virtual function
- Cout<<"drawing..."<<endl;
- }
- };
- Class Rectangle: public Shape // inheriting Shape class.
- {
- Public:
- Void draw()
- {
- Cout<<"drawing rectangle..."<<endl;
- }
- };
- Class Circle: public Shape // inheriting Shape class.
- {
- Public:
- Void draw()
- {
- Cout<<"drawing circle..."<<endl;
- }
- };
- Int main(void) {
- Shape *s; // base class pointer.
- Shape sh; // base class object.
- Rectangle rec;
- Circle cir;
- s=&sh;
- s->draw();
- s=&rec;
- s->draw();
- s=?
- s->draw();
- }
Output:
Drawing...
Drawing rectangle...
Drawing circle...
Runtime Polymorphism with Data Members
Runtime Polymorphism can be achieved by data members in C++. Let's see an example where we are accessing the field by reference variable which refers to the instance of derived class.
- #include <iostream>
- Using namespace std;
- Class Animal { // base class declaration.
- Public:
- String color = "Black";
- };
- Class Dog: public Animal // inheriting Animal class.
- {
- Public:
- String color = "Grey";
- };
- Int main(void) {
- Animal d= Dog();
- Cout<<d.color;
- }
Output:
Black
Association of method call to the method body is known as binding. There are two types of binding: Static Binding that happens at compile time and Dynamic Binding that happens at runtime. Before I explain static and dynamic binding in java, lets see few terms that will help you understand this concept better.
What is reference and object?
Class Human{
....
}
Class Boy extends Human{
Public static void main( String args[]) {
/*This statement simply creates an object of class
*Boy and assigns a reference of Boy to it*/
Boy obj1 = new Boy();
/* Since Boy extends Human class. The object creation
* can be done in this way. Parent class reference
* can have child class reference assigned to it
*/
Human obj2 = new Boy();
}
}
Static and Dynamic Binding in Java
As mentioned above, association of method definition to the method call is known as binding. There are two types of binding: Static binding and dynamic binding. Lets discuss them.
Static Binding or Early Binding
The binding which can be resolved at compile time by compiler is known as static or early binding. The binding of static, private and final methods is compile-time. Why? The reason is that the these method cannot be overridden and the type of the class is determined at the compile time. Lets see an example to understand this:
Static binding example
Here we have two classes Human and Boy. Both the classes have same method walk() but the method is static, which means it cannot be overriden so even though I have used the object of Boy class while creating object obj, the parent class method is called by it. Because the reference is of Human type (parent class). So whenever a binding of static, private and final methods happen, type of the class is determined by the compiler at compile time and the binding happens then and there.
Class Human{
Public static void walk()
{
System.out.println("Human walks");
}
}
Class Boy extends Human{
Public static void walk(){
System.out.println("Boy walks");
}
Public static void main( String args[]) {
/* Reference is of Human type and object is
* Boy type
*/
Human obj = new Boy();
/* Reference is of HUman type and object is
* of Human type.
*/
Human obj2 = new Human();
Obj.walk();
Obj2.walk();
}
}
Output:
Human walks
Human walks
Dynamic Binding or Late Binding
When compiler is not able to resolve the call/binding at compile time, such binding is known as Dynamic or late binding. Method Overriding is a perfect example of dynamic binding as in overriding both parent and child classes have same method and in this case the type of the object determines which method is to be executed. The type of object is determined at the run time so this is known as dynamic binding.
Dynamic binding example
This is the same example that we have seen above. The only difference here is that in this example, overriding is actually happening since these methods are not static, private and final. In case of overriding the call to the overriden method is determined at runtime by the type of object thus late binding happens. Lets see an example to understand this:
Class Human{
//Overridden Method
Public void walk()
{
System.out.println("Human walks");
}
}
Class Demo extends Human{
//Overriding Method
Public void walk(){
System.out.println("Boy walks");
}
Public static void main( String args[]) {
/* Reference is of Human type and object is
* Boy type
*/
Human obj = new Demo();
/* Reference is of HUman type and object is
* of Human type.
*/
Human obj2 = new Human();
Obj.walk();
Obj2.walk();
}
}
Output:
Boy walks
Human walks
As you can see that the output is different than what we saw in the static binding example, because in this case while creation of object obj the type of the object is determined as a Boy type so method of Boy class is called. Remember the type of the object is determined at the runtime.
Static Binding vs Dynamic Binding
Lets discuss the difference between static and dynamic binding in Java.
Static binding happens at compile-time while dynamic binding happens at runtime.
Binding of private, static and final methods always happen at compile time since these methods cannot be overridden. When the method overriding is actually happening and the reference of parent type is assigned to the object of child class type then such binding is resolved during runtime.
The binding of overloaded methods is static and the binding of overridden methods is dynamic.
Message Passing is nothing but sending and receving of information by the objects same as people exchange information. So this helps in building systems that simulate real life. Following are the basic steps in message passing.
- Creating classes that define objects and its behaviour.
- Creating objects from class definitions
- Establishing communication among objects
In OOPs, Message Passing involves specifying the name of objects, the name of the function, and the information to be sent.
References:
1. Object-Oriented Programming and Java by Danny Poo (Author), Derek Kiong (Author), Swarnalatha Ashok (Author)Springer; 2nd ed. 2008 edition (12 October 2007), ISBN-10: 1846289629, ISBN-13: 978-1846289620,2007
2. Java The complete reference, 9th edition, Herbert Schildt, McGraw Hill Education (India) Pvt. Ltd.
3. Object-Oriented Design Using Java, Dale Skrien, McGraw-Hill Publishing, 2008, ISBN - 0077423097, 9780077423094. 4. UML for Java Programmers by Robert C. Martin, Prentice Hall, ISBN 0131428489,2003.




