Unit - 4
Overview
Query processing is nothing but steps involved in retrieving data from database. These activities include translation of queries written high level database language into expressions that can be understood at the physical level of the file system. It also includes a variety of query optimizing transformations and actual evaluations of queries.
Query processing procedure
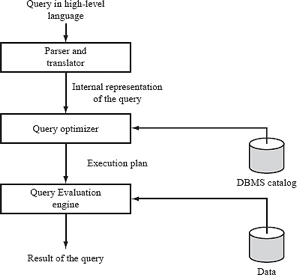
Fig 1: Query processing steps
Basic steps in query processing are:
1. Parsing and translation
2. Optimization
3. Evaluation
At the beginning of query processing, the queries must be translated into a form which could be understood at the physical level of the system. A language like SQL is not suitable for the internal representation of a query. Relational algebra is the good option for internal representation of query.
So, the first step in query processing is to translate a given query into its internal
Representation. In generating internal form of a query, parser checks the syntax of the query written by user, verifies that the relation names appearing in the query really exists in the database and so on.
The system constructs a parse-tree of the query. Then this tree is translated into relational- algebra expressions. If the query was expressed in terms of a view, the translation phase replaces all uses of the view by the relational-algebra expression that defines the view.
One query can be answered in different ways. Relational-algebra representation of a query specifies only partially how to evaluate a query. There are different ways to evaluate relational-algebra expressions. Consider the query:
Select acc_balance from account where acc_balance<5000
This query can be translated into one of the following relational-algebra expressions:
1. σ acc_balance<5000 (Π acc_balance (account))
2. Πacc_balance (σ acc_balance <5000 (account))
Different algorithms are available to execute relational-algebra operation. To solve the above query, we can search every tuple in account to find the tuples having balance less than 5000. If a B + tree index is available on the balance attribute, we can use this index instead to search for the required tuples.
To specify how to evaluate a query, we need not only to provide the relational-algebra expression, but also to explain it with instructions specifying the procedure for evaluation of each operation.
Account_id | Cust_id | Acc_Balance |
Account Relation
Cust_id | Cust_Name |
Customer Relation

Fig 2: Procedure for evaluation
A relational-algebra operation along with instructions on how to evaluate it is called an evaluation primitive. A sequence of primitive operations that can be used in the evaluation of a query is called a query execution plan or query evaluation plan. Above figure illustrates an evaluation plan for our example query, in which a particular index is specified for the selection operation from database. The query execution engine takes a query evaluation plan, executes that plan, and returns the answer to the query.
Different evaluation plans have different costs. It is the responsibility of the system to
Construct a query evaluation plan that minimizes the cost of query evaluation; this task is called Query Optimization. Once the query plan with minimum cost is chosen, the query is evaluated with the plan, and the result of the query is the output. In order to optimize a query, a query optimizer must know the cost of each operation.
Although the exact cost is hard to compute, it is possible to get a rough estimate of
Execution cost for each operation. Exact cost is hard for computation because it depends on many parameters such as actual memory available to execute the operation.
Optimization process
A single query can be executed using different algorithms or re-written in different forms and structures. Hence, the question of query optimization comes into the picture. The query optimizer helps to determine the most efficient way to execute a given query by considering the possible query plans.
The optimizer tries to generate the most optimal execution plan for a SQL statement. It selects the plan with lowest execution cost among all other available plans. The optimizer uses available statistics to calculate cost. For a specific query in a given environment, the most computation accounts for factors of query execution such as I/O, CPU, and communication.
For example, consider table storing information about employees who are managers. If the optimizer statistics indicate that 80% of employees are managers, then the optimizer may decide that a full table scan is most efficient. However, if statistics indicate that very few employees are managers, then reading an index followed by a table access by row id may be more efficient than full table scan.
Because the database has many internal statistics and tools at its disposal, the optimizer is usually in a better position than the user to determine the optimal method of statement execution. For this reason, all SQL statements use the optimizer.
There are broadly two ways a query can be optimized:
1. Analyze and transform equivalent relational expressions: Try to minimize the tuple and column counts of the intermediate and final query processes.
2. Using different algorithms for each operation: These underlying algorithms determine how tuples are accessed from the data structures they are stored in, indexing, hashing, data retrieval and hence influence the number of disk and block accesses.
Advantages of Query Optimization as:
● First, it provides the user with faster results, which makes the application seem faster to the user.
● Secondly, it allows the system to service more queries in the same amount of time, because each request takes less time than un-optimized queries.
● Thirdly, query optimization ultimately reduces the amount of wear on the hardware (e.g., disk drives), and allows the server to run more efficiently (e.g. Lower power consumption, less memory usage).
Cost estimation:
● The cost must be calculated for every strategy considered:
○ Costs of each operation must be calculated in the plan tree.
■ It depends on the cardinal inputs.
■ Operations expense (sequential scan, index scan, joins, etc.)
● The result size must also be calculated for each operation in the tree!
○ Using data about input relationships.
○ Assume freedom of predicates for choices and entries.
Estimating result size:
● Reduction factor
○ The ratio of the size of the (expected) result to the size of the input, considering Just the selection that the word reflects.
● How to estimate factors for reduction:
● Column = value
1/Nkeys(I) – I:
- index on column
1/10: random
● Column1 = column2
1/Max (Nkeys(I1), Nkeys(I2)): both columns have indexes
1/Nkeys(I): either column1 or column 2 has index I
1/10: no index
Size Estimation:
● How to estimate factors for reduction:
○ Column>value
■ (High(I)-value)/(High(I)-Low(I)): with index
■ Less than half: no index
● Column IN (list of values)
○ RF (column=value) * number of items
○ At most half
● Reduction factor for projection
Key takeaway:
Query processing is nothing but steps involved in retrieving data from database.
It also includes a variety of query optimizing transformations and actual evaluations of queries.
The first step in query processing is to translate a given query into its internal representation.
The query optimizer helps to determine the most efficient way to execute a given query by considering the possible query plans.
The cost of query evaluation can be measured in terms of number of different resources used, including disk accesses, CPU time to execute given query, and, in a distributed database or parallel database system. In large database systems, however, the cost to access data from disk is usually the most important cost, since disk accesses are slow compared to in-memory operations.
Moreover, CPU speeds have been improving much faster than have disk speeds. The CPU time taken for a task is harder to estimate since it depends on low-level details of the execution.
The time taken by CPU is negligible in most systems when compared with the number of disk accesses.
If we consider the number of block transfers as the main component in calculating the cost of a query, it would include more sub-components. Those are as below:
Rotational latency – time taken to bring and turn the required data under the read-write head of the disk.
Seek time – It is the time taken to position the read-write head over the required track or cylinder.
Sequential I/O – reading data that are stored in contiguous blocks of the disk
Random I/O – reading data that are stored in different blocks of the disk that are not
Contiguous.
From these sub-components, we would list the components of a more accurate measure as follows;
● The number of seek operations performed
● The number of block read operations performed
● The number of blocks written operations performed
Hence, the total query cost can be written as follows;
Query cost = (Number of seek operations X average seek time) +
(Number of blocks read X average transfer time for reading a block) +
(Number of blocks written X average transfer time for writing a block).
The query tree is regarded and evaluated as a data structure that contains a series of basic operations that are linked in order to complete the query in order to assess the cost of several potential execution plans or execution strategies. The cost of the operations in the query is determined by how the operation is chosen, such as the proportion of select operations that make up the result. It's also crucial to understand the cardinality of an operation's projected output. The output's cardinality is critical because it serves as the input for the next operation.
The cost of query optimization is determined by the following factors:
● Cardinality- The number of rows returned by performing the actions indicated by the query execution plan is known as Cardinality. The cardinality estimates must be accurate because they have a significant impact on the execution plan's possibilities.
● Selectivity- The number of rows selected is referred to as selectivity. The criterion almost completely determines the selectivity of any entry from the table or any table from the database. The selectivity of that specific row is determined by the satisfaction of the criteria. Depending on the situation, the condition that must be met can be anything.
● Cost- The amount of money spent on the system to optimise it is referred to as the cost. The amount of money spent is entirely determined by the amount of work done or the number of resources utilised.
Key takeaway:
Cost is normally calculated as the total time spent responding to a question.
We only use the number of block transfers from the disc as the cost measure for simplicity.
● The system must create a query evaluation plan in order to completely evaluate a query.
● The annotations in the evaluation plan could refer to the algorithms that will be utilised for the specific index or actions.
● Evaluation Primitives are a type of relational algebra with annotations. The instructions for evaluating the operation are stored in the evaluation primitives.
● As a result, a query evaluation plan specifies a set of primitive operations that are utilised to evaluate a query. The query evaluation plan, also known as the query execution plan, is used to evaluate queries.
● A query execution engine is in charge of generating the results of a query. It accepts the query execution plan, performs it, and then generates the user query output.
An evaluation plan specifies which algorithm should be utilised for each operation as well as how the operations' execution should be coordinated. So far, we've covered (a) heuristic optimization and (b) cost-based optimization as two basic ways to selecting an execution (action) plan. The majority of query optimizers integrate aspects of both of these approaches. One of the possible evaluation plans is depicted in Fig.
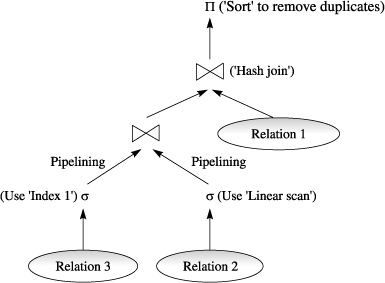
Fig 4: Evaluation plan
Key takeaway
An evaluation plan specifies which algorithm should be utilised for each operation as well as how the operations' execution should be coordinated. So far, we've covered (a) heuristic optimization and (b) cost-based optimization as two basic ways to selecting an execution (action) plan.
References:
- Korth, Silbertz, Sudarshan,” Database Concepts”, McGraw Hill
- Date C J, “An Introduction to Database Systems”, Addision Wesley
- Elmasri, Navathe, “Fundamentals of Database Systems”, Addision Wesley
- O’Neil, Databases, Elsevier Pub.




