Unit - 3
Memory Management
If the blocks are allocated to the file in such a way that all the logical blocks of the file get the contiguous physical block in the hard disk then such allocation scheme is known as contiguous allocation.
In the image shown below, there are three files in the directory. The starting block and the length of each file are mentioned in the table. We can check in the table that the contiguous blocks are assigned to each file as per its need.
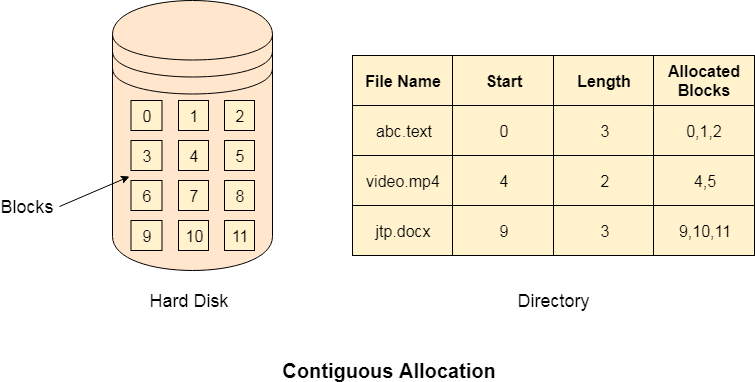
Fig 1: Contiguous allocation
Advantages
- It is simple to implement.
- We will get Excellent read performance.
- Supports Random Access into files.
Disadvantages
- The disk will become fragmented.
- It may be difficult to have a file grow.
- Program relocation: in that of the program instruction and that of the data use of some of the address. Program assumes its instructions and that of the data to occupy memory words with that of the specific address.
- Such a program is known as address sensitive program. It contains one or more of the following:
1. An address sensitive instruction: which is that of an instruction which uses an address.
2. An address constant: which is that of a data word which contains an address?
- Definition: program relocation is the process of modifying the address used in the address sensitive instructions of a program such that the program can execute correctly from the designated area of memory.
- In complete process translation origin and linking are always different. But linking origin and loading origin may be same or different.
- If loading origin and linking origin are different this means relocation must be performed by the loader.
- Linker always performs that of the relocation. But some loaders do not do this.
- If loaders do not perform relocation this means load origin and link origin are equal, and this loader is called absolute loader.
- If loaders perform relocation then loaders are called relocation loaders.
- Performing relocation: we can calculate the relocation factor by linking origin and translate origin. Suppose translated origin and linked origin of program ist_originand l_origin respectively. Consider a symbol symb in program P. Its translation time address be tsymb and link time address be 1symb
- The relocation factor of that of the program is defined as
Relocation_factor =l_orgin – t_origin
- Relocation factor can be positive, negative or 0.
- Here symb is working as an operand. The translator puts the address tsymb in the instruction for it.
Tsymb = t_origin + dsymb
Where dsymb is the offset of symb in program.
lsymb = l_origin + dsymb
lsymb = t_origin +relocation_faction +dsymb
= t_origin + dsymb + relocation_factior
= tsymb + relocation_factor
- In Operating Systems, Paging is a storage component used to recover processes from the secondary storage into the main memory as pages.
- The primary thought behind the concept of paging is to isolate each process as pages. The main memory will likewise be partitioned as frames.
- One page of the process is to be fitted in one of the frames of the memory. The pages are supposed to be store at the various locations of the memory however the need is consistently to locate the contiguous frames or holes.
- In this design, the operating system recovers data from secondary storage in same-size blocks called pages. Paging is a significant piece of virtual memory usage in current operating systems, utilizing secondary storage to give programs a chance to surpass the size of accessible physical memory.
- Support for paging has been taken care of by hardware. Nonetheless, ongoing structures have actualized paging by intently coordinating the hardware what's more, operating system, and particularly on 64-bit microprocessors.
Basic Method
- The fundamental technique for actualizing paging includes breaking physical memory into fixed-sized blocks called frames and breaking logical memory into blocks of a similar size known as pages.
- When a process needs to be executed, its pages are stacked into any accessible memory frames from their source (a file system or the support store).
- The backing store is partitioned into fixed-sized blocks that are of a similar size as the memory frames.
- The hardware support for paging is represented in the figure below. Each address created by the CPU is partitioned into two sections: a page number (p) and a page offset (d).
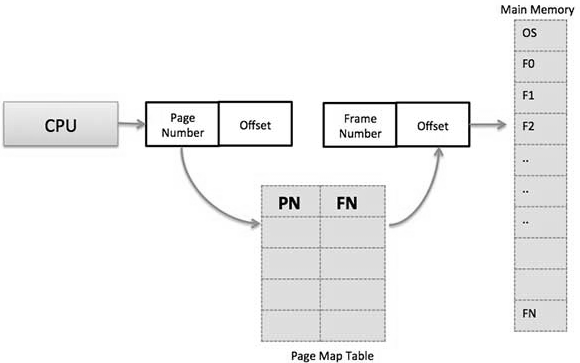
Fig 2 - Paging Hardware
Paging Hardware
- The page number is utilized as a list into a page table. The page table contains the base location of each page in physical memory.
- This base location is joined with the page offset to characterize the physical memory address that is sent to the memory unit. The paging model of memory has appeared in the figure below.
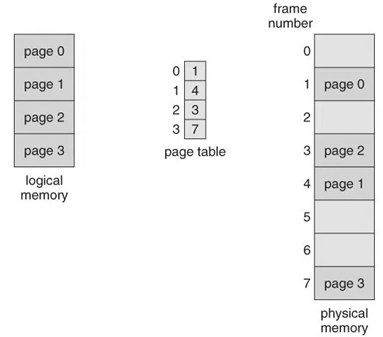
Fig 3 - Paging model of logical and physical memory
- The page size (like the frame size) is characterized by the hardware. The size of a page is regularly a power of 2, differing between 512 bytes and 16 MB for every page, contingent upon the computer architecture.
- The choice of a power of 2 as a page size makes the interpretation of a logical address into a page number and a page offset especially simple.
- If the size of the logical address space is 2m, and page size is 2n addressing units (bytes or words) then the high-request m - n bits of a logical address assign the page number, and the n low-request bits assign the page offset.
- Along these lines, the logical address is as per the following:
Page number | Page offset |
p | d |
m - n | m |
Where p is an index into the page table and d is the displacement inside the page.
- Since the operating system is overseeing physical memory, it must know of the assignment subtleties of physical memory-which frames are allotted, which frames are accessible, what number of total frames there are, etc.
- This data is commonly kept in a data structure considered a frame table. The frame table has one section for each physical page frame, demonstrating whether the last mentioned is free or designated and, on the off chance that it is allotted, to which page of which process or processes.
Hardware Support
- The hardware usage of the page table should be possible by utilizing committed registers. Be that as it may, the use or register for the page table is agreeable just if the page table is small.
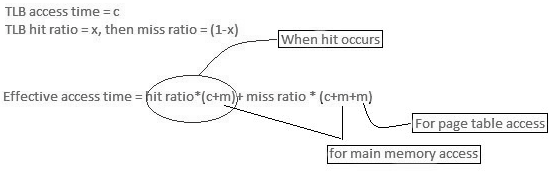
- On the off chance that the page table contains an enormous number of sections, at that point, we can utilize TLB (translation Look-aside cushion), an extraordinary, little, quick look into hardware cache.
- The TLB is acquainted with fast memory.
- Every passage in TLB comprises of two sections: a tag and a value.
- At the point when this memory is utilized, an item is compared with all tags at the same time. If the item is discovered, at that point comparing value is returned.

Main memory access time = m
If the page table is kept in main memory,
Successful Access time = m(for page table) + n(for specific page in page table)
Key Takeaway
- In Operating Systems, Paging is a storage component used to recover processes from the secondary storage into the main memory as pages.
- The primary thought behind the concept of paging is to isolate each process as pages. The main memory will likewise be partitioned as frames.
- One page of the process is to be fitted in one of the frames of the memory. The pages are supposed to be store at the various locations of the memory however the need is consistently to locate the contiguous frames or holes.
- Memory segmentation is a computer (primary) memory management method of division of a PC's primary memory into segments or sections.
- In a computer system utilizing segmentation, a reference to a memory area incorporates a value that distinguishes a segment and an offset (memory area) inside that segment.
- Segments or sections are likewise utilized in object files of compiled programs when they are connected into a program image and when the image is stacked into memory.
- A process is isolated into Segments. The chunks that a program is partitioned into which are not the majority of similar sizes are called segments.
- Segmentation gives the user's perspective on the process which paging does not give.
- Here the user's view is mapped to physical memory.
- There are kinds of segmentation:
0. Virtual memory segmentation – Each process is partitioned into various segments, not which are all inhabitants at any one point in time.
- Simple Segmentation – Each process is partitioned into various segments, which are all stacked into memory at run time, however not continuously.
- There is no straightforward connection between logical addresses and physical addresses in segmentation. A table is maintained to stores the data about all such segments and is called Segment Table.
- Segment Table – It maps two-dimensional Logical address into one-dimensional Physical address. It's each table entry has:
0. Base Address: It contains the beginning physical address where the fragments reside in memory.
- Limit: It determines the length of the fragment.
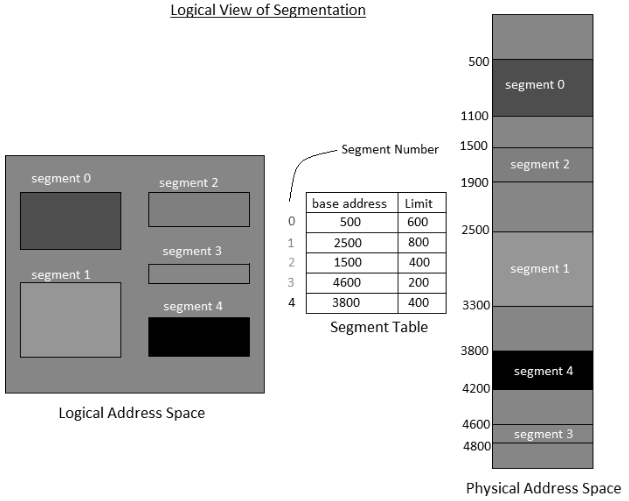
Fig 4 – Logical view of segmentation
- Segments, as a rule, compare to regular divisions of a program, for example, singular schedules or data tables so division is commonly more noticeable to the programmer than paging alone.
- Different segments might be made for various program modules, or various classes of memory utilization, for example, code and data portions. Certain segments might be shared between programs.
Why Segmentation is required?
- Till now, we were utilizing Paging as our main memory management system. Paging is more near to the operating system instead of the User.
- It isolates all the processes into the type of pages regardless of the way that a process can have some overall parts of functions which should be stacked on a similar page.
- The operating system couldn't care less about the User's perspective on the process. It might separate a similar function into various pages and those pages could conceivably be stacked simultaneously into the memory. It diminishes the productivity of the system.
- It is smarter to have segmentation which partitions the process into segments. Each segment contains the same sort of capacities, for example, the main function can be incorporated into one segment and the library capacities can be incorporated into the other segment.
Translation of Logical Address into Physical Address
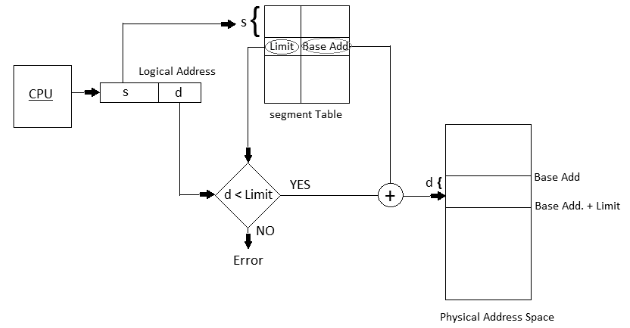
Fig 5 – Logical and physical address
- The address generated by the CPU is partitioned into:
- Segment number (s): Number of bits required to speak to the portion.
- Segment balance (d): Number of bits required to speak to the size of the fragment.
Advantages-
- No Internal fragmentation.
- Segment Table consumes less space in contrast with the Page table in paging.
Disadvantages-
- As processes are stacked and expelled from the memory, the free memory space is broken into little pieces, causing External fragmentation.
Key Takeaway
- Memory segmentation is a computer (primary) memory management method of division of a PC's primary memory into segments or sections.
- In a computer system utilizing segmentation, a reference to a memory area incorporates a value that distinguishes a segment and an offset (memory area) inside that segment.
- Segments or sections are likewise utilized in object files of compiled programs when they are connected into a program image and when the image is stacked into memory.
Pure segmentation is not very popular and not being used in many of the operating systems. However, Segmentation can be combined with Paging to get the best features out of both the techniques.
In Segmented Paging, the main memory is divided into variable size segments which are further divided into fixed-size pages.
- Pages are smaller than segments.
- Each Segment has a page table which means every program has multiple page tables.
- The logical address is represented as Segment Number (base address), Page number, and page offset.
Segment Number → It points to the appropriate Segment Number.
Page Number → It Points to the exact page within the segment
Page Offset → Used as an offset within the page frame
Each Page table contains various information about every page of the segment. The Segment Table contains information about every segment. Each segment table entry points to a page table entry and every page table entry is mapped to one of the pages within a segment.
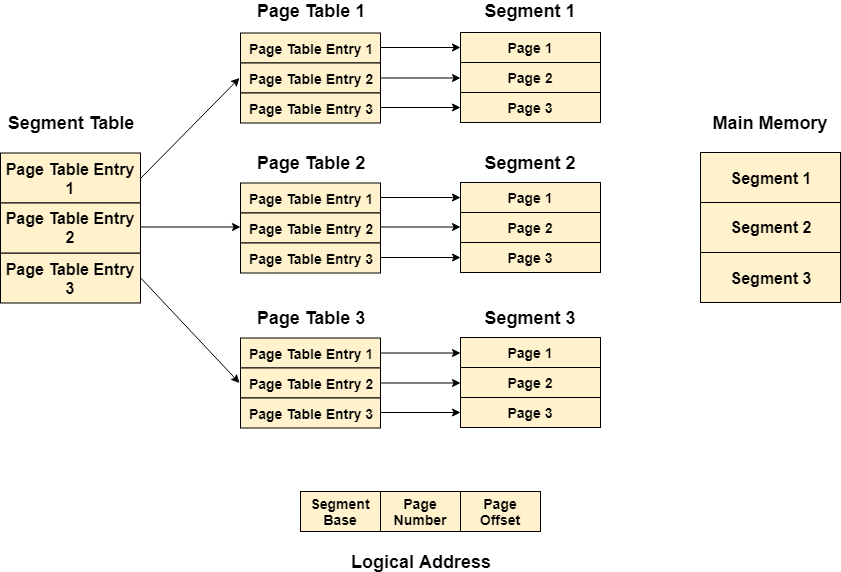
Fig 6 – Logical address
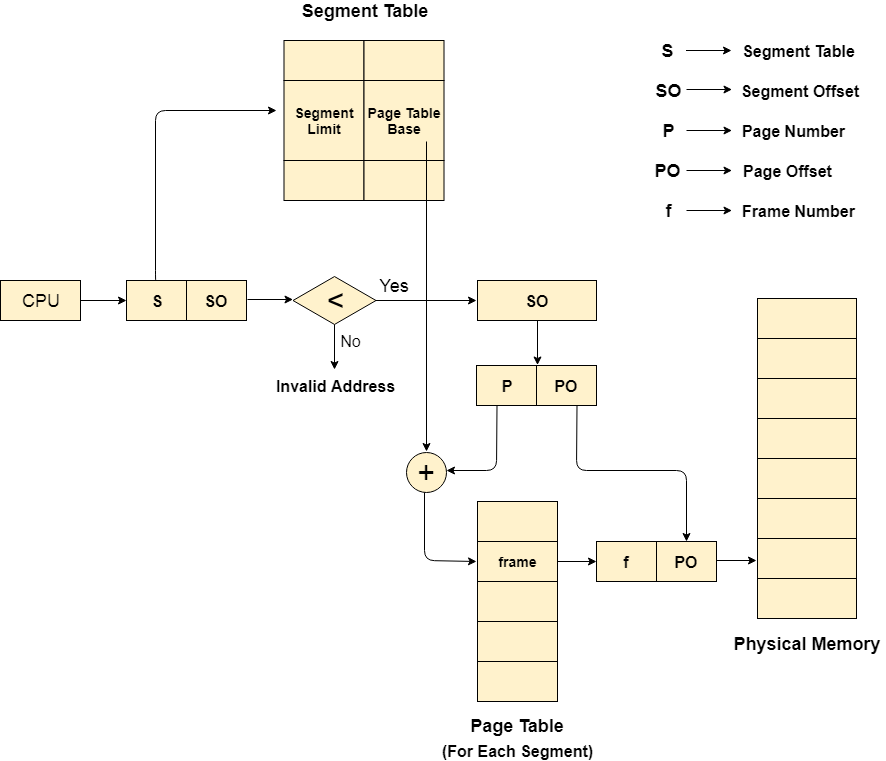
Translation of logical address to a physical address
The CPU generates a logical address which is divided into two parts: Segment Number and Segment Offset. The Segment Offset must be less than the segment limit. Offset is further divided into a Page number and Page Offset. To map the exact page number in the page table, the page number is added to the page table base.
The actual frame number with the page offset is mapped to the main memory to get the desired word on the page of a certain segment of the process.
Advantages of Segmented Paging
- It reduces memory usage.
- Page table size is limited by the segment size.
- The segment table has only one entry corresponding to one actual segment.
- External Fragmentation is not there.
- It simplifies memory allocation.
Disadvantages of Segmented Paging
- Internal Fragmentation will be there.
- The complexity level will be much higher as compare to paging.
- Page Tables need to be continuously stored in the memory.
Key takeaway
Pure segmentation is not very popular and not being used in many of the operating systems. However, Segmentation can be combined with Paging to get the best features out of both the techniques.
In Segmented Paging, the main memory is divided into variable size segments which are further divided into fixed-size pages.
- As per the idea of Virtual Memory, to execute some process, just a piece of the process should be available in the main memory which implies that a couple of pages may be available in the main memory whenever.
- The difficult task is to decide which pages should be kept in the main memory and which should be kept in the secondary memory because we can't state ahead of time that a process will require a specific page at a specific time.
- Subsequently, to beat this issue, there is an idea called Demand Paging is presented. It proposes keeping all pages of the frames in the secondary memory until they are required. That means, it says that don't stack any page in the main memory until it is required.
- Demand paging says that pages should possibly be brought into memory if the executing process requests them. This is frequently known as lazy evaluation as just those pages requested by the process are swapped from secondary storage to main memory.
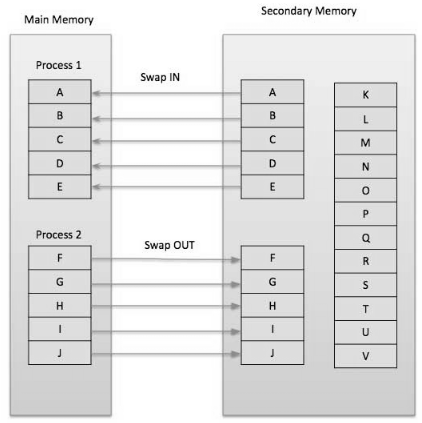
Fig 7 – Swapping memory
- On the other hand in pure swapping, where all memory for a process is swapped from secondary storage to main memory during the process start execution.
- To implement this process needs a page table is utilized. The page table maps logical memory to physical memory.
- The page table uses a bitwise administrator to stamp if a page is valid or invalid. A valid page is one that is present in the main memory. An invalid page is one that is present in secondary memory.
- At the point when a process attempts to get to a page, the following steps are followed as shown in the figure below:

- If the CPU attempts to call a page that is as of now not accessible in the main memory, it creates an interrupt showing memory access fault.
- The OS places the interrupted process in a blocking state. For the execution to continue the OS must call the required page into the memory.
- The OS will scan for the required page in the logical address space.
- The required page will be brought from logical address space to physical address space. The page replacement algorithms are utilized for deciding which page is to be replaced with the new page in the physical address space.
- Updates will be made to the page table accordingly.
- The sign will be sent to the CPU to proceed with the program execution and it will put the process again into a ready state.
Henceforth at whatever point a page fault happens these steps are performed by the operating system and the required page is brought into memory.
Advantages
- Demand paging, instead of loading all pages right away:
- Just loads pages that are requested by the executing process.
- As there is more space in the main memory, more processes can be stacked, decreasing the context switching time, which uses a lot of resources.
- Less loading latency happens at program startup, as less data is gotten from secondary storage and less data is brought into main memory.
- As main memory is costly contrasted with secondary memory, this method helps altogether decrease the bill of material (BOM) cost in advanced cells for instance. Symbian OS had this element.
Disadvantage
- Individual programs face additional latency when they access the page for the first time.
- Minimal effort, low-control implanted systems might not have a memory management unit that supports page replacement.
- Memory management with page replacement algorithms turns out to be somewhat increasingly intricate.
- Conceivable security dangers, including weakness to timing attacks.
- Thrashing may happen because of repeated page faults.
Key takeaway
As per the idea of Virtual Memory, to execute some process, just a piece of the process should be available in the main memory which implies that a couple of pages may be available in the main memory whenever.
The difficult task is to decide which pages should be kept in the main memory and which should be kept in the secondary memory because we can't state ahead of time that a process will require a specific page at a specific time.
A page fault occurs when a program attempts to access data or code that is in its address space, but is not currently located in the system RAM. So when page fault occurs then following sequence of events happens:
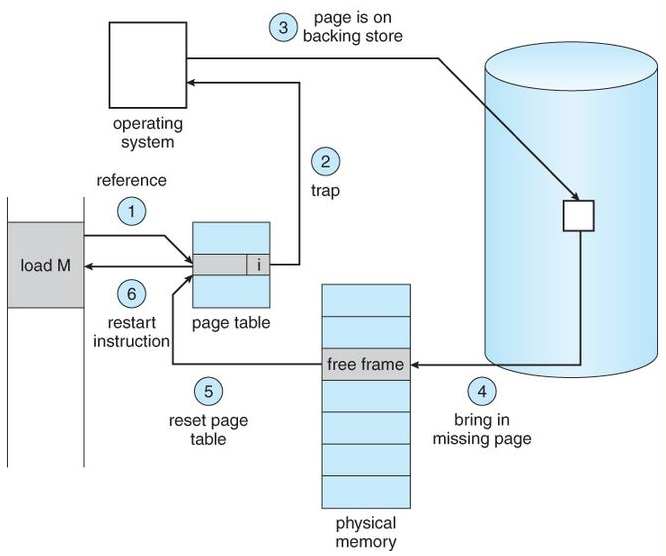
Fig 8 – Page fault
The computer hardware traps to the kernel and program counter (PC) is saved on the stack. Current instruction state information is saved in CPU registers.
An assembly program is started to save the general registers and other volatile information to keep the OS from destroying it.
Operating system finds that a page fault has occurred and tries to find out which virtual page is needed. Sometimes hardware register contains this required information. If not, the operating system must retrieve PC, fetch instruction and find out what it was doing when the fault occurred.
Once virtual address caused page fault is known, system checks to see if address is valid and checks if there is no protection access problem.
If the virtual address is valid, the system checks to see if a page frame is free. If no frames are free, the page replacement algorithm is run to remove a page.
If frame selected is dirty, page is scheduled for transfer to disk, context switch takes place, fault process is suspended and another process is made to run until disk transfer is completed.
As soon as page frame is clean, operating system looks up disk address where needed page is, schedules disk operation to bring it in.
When disk interrupt indicates page has arrived, page tables are updated to reflect its position, and frame marked as being in normal state.
Faulting instruction is backed up to state it had when it began and PC is reset. Faulting is scheduled, operating system returns to routine that called it.
Assembly Routine reloads register and other state information, returns to user space to continue execution.
Key takeaway
A page fault occurs when a program attempts to access data or code that is in its address space, but is not currently located in the system RAM. So, when page fault occurs then following sequence of events happens:
- Page replacement algorithms are the procedures utilizing which an Operating System chooses which memory pages to swap out, write to disk when a page of memory should be allocated.
- Paging happens at whatever point a page fault happens and a free page can't be utilized for allocation reason accounting to reason that pages are not available or the quantity of free pages is lower than required pages.
- At the point when the page that was chosen for replacement and was paged out, is referenced once more, it needs to read in from disk, and this requires I/O completion.
- This process decides the nature of the page replacement algorithm: the lesser the time waiting for page-ins, the better is the algorithm.
- A page replacement algorithm takes a gander at the restricted data about getting to the pages given by hardware and attempts to choose which pages ought to be replaced to limit the complete number of page misses while offsetting it with the expenses of primary storage and processor time of the algorithm itself.
- There is a wide range of page replacement algorithms. We assess an algorithm by running them on a specific string of memory reference and registering the number of page issues,
- There are two main parts of virtual memory, Frame allocation, and Page Replacement. It is imperative to have the ideal frame allocation and page replacement algorithm. Frame allocation is about what number of frames are to be designated to the process while the page replacement is tied in with deciding the page number which should be supplanted to make space for the mentioned page.
What if the algorithm is not optimal?
1. If the quantity of frames which are dispensed to a process isn't adequate or exact at that point, there can be an issue of thrashing. Because of the absence of frames, a large portion of the pages will reside in the main memory and consequently, more page faults will happen.
Nonetheless, on the off chance that OS allots more frames to the process, at that point there can be an internal discontinuity.
2. On the off chance that the page replacement orithm algorithm isn't ideal, at that point, there will likewise be the issue of thrashing. On the off chance that the number of pages that are supplanted by the mentioned pages will be referred sooner rather than later at that point, there will be a progressively some swap-in and swap-out and along these lines, the OS needs to perform more replacements then common which causes execution inadequacy.
3. In this manner, the assignment of an ideal page replacement calculation is to pick the page which can restrict the thrashing.
Types of Page Replacement Algorithm
There are different page replacement algorithms. Every algorithm has an alternate strategy by which the pages can be replaced.
First in First out (FIFO) –
This is the least difficult page replacement algorithm. In this algorithm, the operating system monitors all pages in the memory in a queue, the oldest page is in the front of the line. At the point when a page should be replaced page in the front of the queue is chosen for removal.
Example Consider page reference string 1, 3, 0, 3, 5, 6 with 3-page frames. Find several page faults.
At first, all slots are vacant, so when 1, 3, 0 came they are distributed to the unfilled spaces — > 3 Page Faults.
At the point when 3 comes, it is in memory so — > 0 Page Faults.
At that point 5 comes, it isn't available in memory so it replaces the oldest page space i.e 1. — >1 Page Fault.
6 comes, it is likewise not available in memory so it replaces the most established page space i.e 3 — >1 Page Fault.
At long last when 3 come it isn't available so it replaces 0 — > 1-page fault
Belady's anomaly – Belady's anomaly demonstrates that it is conceivable to have more page faults when expanding the number of page frames while utilizing the First in First Out (FIFO) page replacement algorithm. For instance, on the off chance that we consider reference string 3, 2, 1, 0, 3, 2, 4, 3, 2, 1, 0, 4 and 3 slots, we get 9 all-out page faults, however, on the off chance that we increment spaces to 4, we get 10-page faults.
Optimal Page replacement
This algorithm replaces the page which won't be alluded to for such a long time in the future. Although it cannot be implementable however it very well may be utilized as a benchmark. Different algorithms are contrasted with this regarding optimality.
Example: Consider the page references 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, with 4 page frame. Discover number of page faults.
At first, all openings are vacant, so when 7 0 1 2 are assigned to the unfilled spaces — > 4 Page faults
0 is as of now there so — > 0 Page fault.
At the point when 3 came it will replace 7 since it isn't utilized for the longest length of time in the future— >1 Page fault.
0 is as of now there so — > 0 Page fault.
4 will replace 1 — > 1 Page Fault.
Presently for the further page reference string — > 0 Page fault since they are as of now accessible in the memory.
Optimal page replacement is flawless, yet unrealistic by and by as the operating system can't know future requests. The utilization of Optimal Page replacement is to set up a benchmark with the goal that other replacement calculations can be examined against it.
Least Recently Used
This algorithm replaces the page which has not been alluded to for quite a while. This algorithm is only inverse to the optimal page replacement algorithm. In this, we take a look at the past as opposed to gazing at the future.
Example- Consider the page reference string 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2 with 4 page frames. Find number of page faults.
At first, all openings are vacant, so when 7 0 1 2 are apportioned to the vacant spaces — > 4 Page fault
0 is now their so — > 0 Page fault.
At the point when 3 came it will replace 7 since it is least as of late utilized — >1 Page fault.
0 is now in memory so — > 0 Page fault.
4 will happens of 1 — > 1 Page Fault
Presently for the further page reference string — > 0 Page fault since they are as of now accessible in the memory.
Key takeaway
- Page replacement algorithms are the procedures utilizing which an Operating System chooses which memory pages to swap out, write to disk when a page of memory should be allocated.
- Paging happens at whatever point a page fault happens and a free page can't be utilized for allocation reason accounting to reason that pages are not available or the quantity of free pages is lower than required pages.
- At the point when the page that was chosen for replacement and was paged out, is referenced once more, it needs to read in from disk, and this requires I/O completion.
Working Set Model –
This model is based on the above-stated concept of the Locality Model.
The basic principle states that if we allocate enough frames to a process to accommodate its current locality, it will only fault whenever it moves to some new locality. But if the allocated frames are lesser than the size of the current locality, the process is bound to thrash.
According to this model, based on a parameter A, the working set is defined as the set of pages in the most recent ‘A’ page references. Hence, all the actively used pages would always end up being a part of the working set.
The accuracy of the working set is dependent on the value of parameter A. If A is too large, then working sets may overlap. On the other hand, for smaller values of A, the locality might not be covered entirely.
If D is the total demand for frames and is the working set size for a process i,
Now, if ‘m’ is the number of frames available in the memory, there are 2 possibilities:
(i) D>m i.e. total demand exceeds the number of frames, then thrashing will occur as some processes would not get enough frames.
(ii) D<=m, then there would be no thrashing.
If there are enough extra frames, then some more processes can be loaded in the memory. On the other hand, if the summation of working set sizes exceeds the availability of frames, then some of the processes have to be suspended (swapped out of memory).
This technique prevents thrashing along with ensuring the highest degree of multiprogramming possible. Thus, it optimizes CPU utilisation.
Key takeaway
This model is based on the above-stated concept of the Locality Model.
The basic principle states that if we allocate enough frames to a process to accommodate its current locality, it will only fault whenever it moves to some new locality. But if the allocated frames are lesser than the size of the current locality, the process is bound to thrash.
Locality of reference refers to a phenomenon in which a computer program tends to access same set of memory locations for a particular time period. In other words, Locality of Reference refers to the tendency of the computer program to access instructions whose addresses are near one another. The property of locality of reference is mainly shown by loops and subroutine calls in a program.
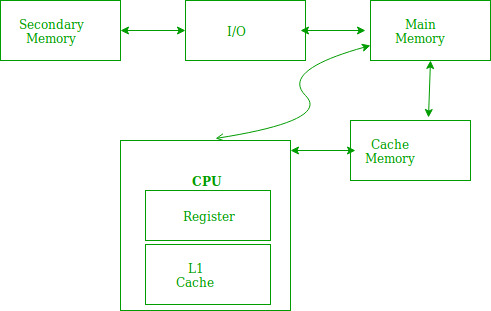
Fig 9 – Locality of reference
In case of loops in program control processing unit repeatedly refers to the set of instructions that constitute the loop.
In case of subroutine calls, every time the set of instructions are fetched from memory.
References to data items also get localized that means same data item is referenced again and again.


Fig 10 – Example
In the above figure, you can see that the CPU wants to read or fetch the data or instruction. First, it will access the cache memory as it is near to it and provides very fast access. If the required data or instruction is found, it will be fetched. This situation is known as a cache hit. But if the required data or instruction is not found in the cache memory then this situation is known as a cache miss. Now the main memory will be searched for the required data or instruction that was being searched and if found will go through one of the two ways:
First way is that the CPU should fetch the required data or instruction and use it and that’s it but what, when the same data or instruction is required again. CPU again has to access the same main memory location for it and we already know that main memory is the slowest to access.
The second way is to store the data or instruction in the cache memory so that if it is needed soon again in the near future it could be fetched in a much faster way.
Cache Operation:
It is based on the principle of locality of reference. There are two ways with which data or instruction is fetched from main memory and get stored in cache memory. These two ways are the following:
Temporal Locality –
Temporal locality means current data or instruction that is being fetched may be needed soon. So, we should store that data or instruction in the cache memory so that we can avoid again searching in main memory for the same data.

Fig 11 – Temporal locality
When CPU accesses the current main memory location for reading required data or instruction, it also gets stored in the cache memory which is based on the fact that same data or instruction may be needed in near future. This is known as temporal locality. If some data is referenced, then there is a high probability that it will be referenced again in the near future.
Spatial Locality –
Spatial locality means instruction or data near to the current memory location that is being fetched, may be needed soon in the near future. This is slightly different from the temporal locality. Here we are talking about nearly located memory locations while in temporal locality we were talking about the actual memory location that was being fetched.
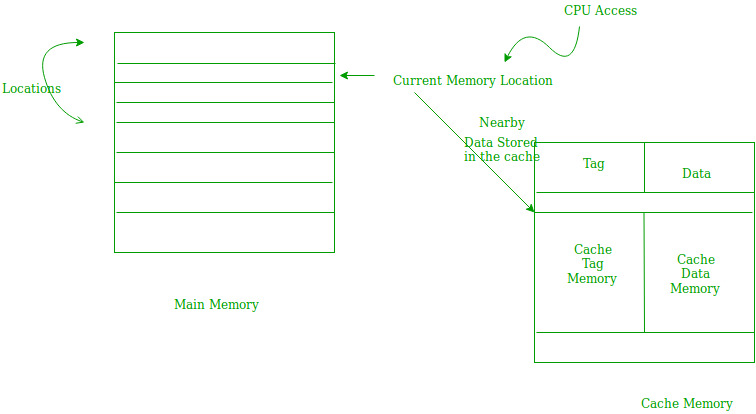
Fig 12 – Spatial locality
Cache Performance:
The performance of the cache is measured in terms of hit ratio. When CPU refers to memory and find the data or instruction within the cache memory, it is known as cache hit. If the desired data or instruction is not found in the cache memory and CPU refers to the main memory to find that data or instruction, it is known as a cache miss.
Hit + Miss = Total CPU Reference
Hit Ratio(h) = Hit / (Hit+Miss)
Average access time of any memory system consists of two levels: Cache and Main Memory. If Tc is time to access cache memory and Tm is the time to access main memory then we can write:
Tavg = Average time to access memory
Tavg = h * Tc + (1-h)*(Tm + Tc)
Key takeaway
Locality of reference refers to a phenomenon in which a computer program tends to access same set of memory locations for a particular time period. In other words, Locality of Reference refers to the tendency of the computer program to access instructions whose addresses are near one another. The property of locality of reference is mainly shown by loops and subroutine calls in a program.
- Thrashing is computer action that allows little or no progress, as memory or different resources have turned out to be depleted or too limited to even perform required functions.
- At this point, a pattern normally creates in which a request is made to the operating system by a process or program, then the operating system attempts to find resources by taking them from some different process, which in turn makes new demands that can't be fulfilled.
- In a virtual storage system (an operating system that deals with its local storage or memory in units called pages), thrashing is a condition wherein extreme paging operations are occurring.
- A system that is thrashing can be seen as either an exceptionally moderate system or one that has stopped.
- Thrashing is a condition or a circumstance when the system is spending a noteworthy segment of its time adjusting the page faults; however, the genuine processing done is truly insignificant.
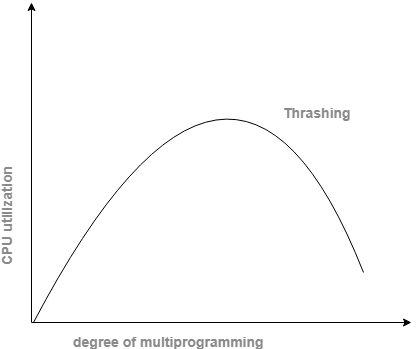
- The fundamental idea included is that if a process is assigned too few frames, at that point, there will be an excess of and too successive page faults.
- Thus, no work would be finished by the CPU and the CPU use would fall definitely.
- The long-term scheduler would then attempt to improve the CPU usage by loading some more processes into the memory in this way expanding the level of multiprogramming.
- This would bring about a further decline in the CPU usage setting off a chained response of higher page faults followed by an expansion in the level of multiprogramming, called Thrashing.
Reasons for Thrashing
It brings about extreme performance issues.
- If CPU use is too low then we increase the level of multiprogramming by acquainting another process with the system. A global page replacement algorithm is utilized. The CPU scheduler sees the diminishing CPU utilization and builds the level of multiprogramming.
- CPU use is plotted against the level of multiprogramming.
- As the level of multiprogramming expands, CPU use likewise increases.
- If the level of multiprogramming is expanded further, thrashing sets in, and CPU use drops sharply.
- So, now, to expand CPU usage and to quit thrashing, we should diminish the level of multiprogramming.
Methods to Handle Thrashing
We previously observed Local replacement is superior to Global replacement to abstain from thrashing. Be that as it may, it likewise has drawbacks and not suggestible. Some more strategies are
Working Set Model
- This model depends on the locality. What region is stating, the page utilized as of recently can be utilized again, and the pages which are adjacent to this page will likewise be utilized.
- Working set methods state that set of pages in the latest D time.
- The page which finished its D amount of time in working set naturally dropped from it.
- So the precision of the working set relies upon the D we have picked.
- This working set model abstains from thrashing while at the same time keeping the level of multiprogramming as high as could be expected under the circumstances.
Page Fault Frequency
- It is some immediate methodology than the working set model.
- When thrashing happens we realize that it has a few frames. Also, on the off chance that it isn't thrashing, that implies it has an excessive number of frames.
- In light of this property, we allocate an upper and lower bound for the ideal page fault rate.
- As indicated by the page fault rate we assign or remove pages.
- On the off chance that the page fault rate becomes less than the limit, frames can be expelled from the process.
- So, if the page fault rate becomes more than the limit, a progressive number of frames can be distributed to the process.
Furthermore, if no frames are available because of the high page fault rate, we will simply suspend the processes and will restart them again when frames will be available.
Key takeaway
- Thrashing is computer action that allows little or no progress, as memory or different resources have turned out to be depleted or too limited to even perform required functions.
- At this point, a pattern normally creates in which a request is made to the operating system by a process or program, then the operating system attempts to find resources by taking them from some different process, which in turn makes new demands that can't be fulfilled.
- In a virtual storage system (an operating system that deals with its local storage or memory in units called pages), thrashing is a condition wherein extreme paging operations are occurring.
References:
1. Operating Systems (5th Ed) - Internals and Design Principles by William Stallings, Prentice Hall India, 2000.
2. Operating System: Concepts and Design by Milan Milenkovik, McGraw Hill Higher Education.
3. Operating Systems - 3rd Edition by Gary Nutt, Pearson Education.
4. Operating Systems, 3rd Edition by P. Balakrishna Prasad, SciTech Publications.




