Unit - 5
File Systems
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
Objective of File management System
Here are the main objectives of the file management system:
- It provides I/O support for a variety of storage device types.
- Minimizes the chances of lost or destroyed data
- Helps OS to standardized I/O interface routines for user processes.
- It provides I/O support for multiple users in a multiuser systems environment.
Properties of a File System
Here, are important properties of a file system:
- Files are stored on disk or other storage and do not disappear when a user logs off.
- Files have names and are associated with access permission that permits controlled sharing.
- Files could be arranged or more complex structures to reflect the relationship between them.
File structure
A File Structure needs to be predefined format in such a way that an operating system understands. It has an exclusively defined structure, which is based on its type.
Three types of files structure in OS:
- A text file: It is a series of characters that is organized in lines.
- An object file: It is a series of bytes that is organized into blocks.
- A source file: It is a series of functions and processes.
File Attributes
A file has a name and data. Moreover, it also stores meta information like file creation date and time, current size, last modified date, etc. All this information is called the attributes of a file system.
Here, are some important File attributes used in OS:
- Name: It is the only information stored in a human-readable form.
- Identifier: Every file is identified by a unique tag number within a file system known as an identifier.
- Location: Points to file location on device.
- Type: This attribute is required for systems that support various types of files.
- Size. Attribute used to display the current file size.
- Protection. This attribute assigns and controls the access rights of reading, writing, and executing the file.
- Time, date and security: It is used for protection, security, and also used for monitoring
File Type
It refers to the ability of the operating system to differentiate various types of files like text files, binary, and source files. However, Operating systems like MS_DOS and UNIX has the following type of files:
Character Special File
It is a hardware file that reads or writes data character by character, like mouse, printer, and more.
Ordinary files
- These types of files stores user information.
- It may be text, executable programs, and databases.
- It allows the user to perform operations like add, delete, and modify.
Directory Files
- Directory contains files and other related information about those files. Its basically a folder to hold and organize multiple files.
Special Files
- These files are also called device files. It represents physical devices like printers, disks, networks, flash drive, etc.
Functions of File
- Create file, find space on disk, and make an entry in the directory.
- Write to file, requires positioning within the file
- Read from file involves positioning within the file
- Delete directory entry, regain disk space.
- Reposition: move read/write position.
Commonly used terms in File systems
Field:
This element stores a single value, which can be static or variable length.
DATABASE:
Collection of related data is called a database. Relationships among elements of data are explicit.
FILES:
Files is the collection of similar record which is treated as a single entity.
RECORD:
A Record type is a complex data type that allows the programmer to create a new data type with the desired column structure. Its groups one or more columns to form a new data type. These columns will have their own names and data type.
Key takeaway
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
Let's look at various ways to access files stored in secondary memory.
Sequential Access
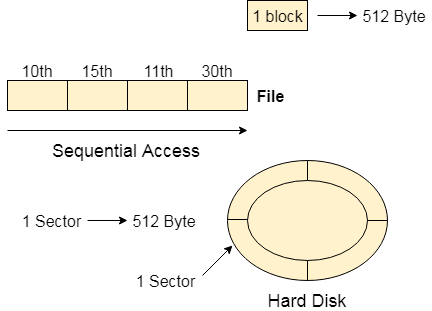
Fig 1: Sequential access
Most of the operating systems access the file sequentially. In other words, we can say that most of the files need to be accessed sequentially by the operating system.
In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
Modern word systems do provide the concept of direct access and indexed access but the most used method is sequential access due to the fact that most of the files such as text files, audio files, video files, etc need to be sequentially accessed.
Direct Access
The Direct Access is mostly required in the case of database systems. In most of the cases, we need filtered information from the database. The sequential access can be very slow and inefficient in such cases.
Suppose every block of the storage stores 4 records and we know that the record we needed is stored in 10th block. In that case, the sequential access will not be implemented because it will traverse all the blocks in order to access the needed record.
Direct access will give the required result despite of the fact that the operating system has to perform some complex tasks such as determining the desired block number. However, that is generally implemented in database applications.
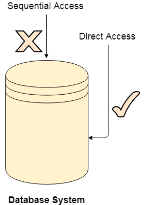
Fig 2: Database system
Indexed Access
If a file can be sorted on any of the filed, then an index can be assigned to a group of certain records. However, A particular record can be accessed by its index. The index is nothing but the address of a record in the file.
In index accessing, searching in a large database became very quick and easy but we need to have some extra space in the memory to store the index value.
Key takeaway
In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
File Directories
A single directory may or may not contain multiple files. It can also have subdirectories inside the main directory. Information about files is maintained by Directories. In Windows OS, it is called folders.
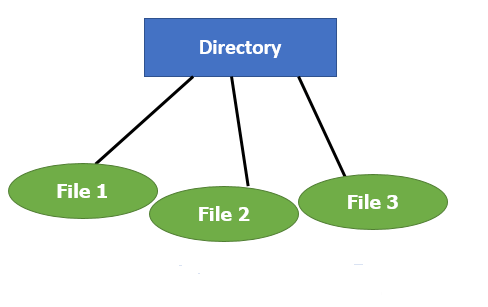
Fig 3: Single Level Directory
Following is the information which is maintained in a directory:
- Name The name which is displayed to the user.
- Type: Type of the directory.
- Position: Current next-read/write pointers.
- Location: Location on the device where the file header is stored.
- Size: Number of bytes, block, and words in the file.
- Protection: Access control on read/write/execute/delete.
- Usage: Time of creation, access, modification
File types- name, extension
File Type | Usual extension | Function |
Executable | Exe, com, bin or none | Ready-to-run machine- language program |
Object | Obj, o | Complied, machine language, not linked |
Source code | c. p, pas, 177, asm, a | Source code in various languages |
Batch | Bat, sh | Series of commands to be executed |
Text | Txt, doc | Textual data documents |
Word processor | Doc,docs, tex, rrf, etc. | Various word-processor formats |
Library | Lib, h | Libraries of routines |
Archive | Arc, zip, tar | Related files grouped into one file, sometimes compressed. |
Summary:
- A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes.
- It provides I/O support for a variety of storage device types.
- Files are stored on disk or other storage and do not disappear when a user logs off.
- A File Structure needs to be predefined format in such a way that an operating system understands it.
- File type refers to the ability of the operating system to differentiate different types of files like text files, binary, and source files.
- Create find space on disk and make an entry in the directory.
- Indexed Sequential Access method is based on simple sequential access
- In Sequential Access method records are accessed in a certain predefined sequence
- The random access method is also called direct random access
- Three types of space allocation methods are:
- Linked Allocation
- Indexed Allocation
- Contiguous Allocation
- Information about files is maintained by Directories
File directories
What is a directory?
The directory can be defined as the listing of the related files on the disk. The directory may store some or the entire file attributes.
To get the benefit of different file systems on the different operating systems, A hard disk can be divided into some partitions of different sizes. The partitions are also called volumes or minidisks.
Each partition must have at least one directory in which, all the files of the partition can be listed. A directory entry is maintained for each file in the directory which stores all the information related to that file.

Fig 4: Example
A directory can be viewed as a file that contains the Metadata of a bunch of files.
Every Directory supports many common operations on the file:
- File Creation
- Search for the file
- File deletion
- Renaming the file
- Traversing Files
- Listing of files
Single Level Directory
The simplest method is to have one big list of all the files on the disk. The entire system will contain only one directory which is supposed to mention all the files present in the file system. The directory contains one entry per each file present on the file system.

Fig 5: Single level directory
This type of directories can be used for a simple system.
Advantages
- Implementation is very simple.
- If the sizes of the files are very small then the searching becomes faster.
- File creation, searching, deletion is very simple since we have only one directory.
Disadvantages
- We cannot have two files with the same name.
- The directory may be very big therefore searching for a file may take so much time.
- Protection cannot be implemented for multiple users.
- There are no ways to group the same kind of files.
- Choosing the unique name for every file is a bit complex and limits the number of files in the system because most of the Operating System limits the number of characters used to construct the file name.
Two Level Directory
In two-level directory systems, we can create a separate directory for each user. There is one master directory that contains separate directories dedicated to each user. For each user, there is a different directory present at the second level, containing a group of user's files. The system doesn't let a user enter the other user's directory without permission.
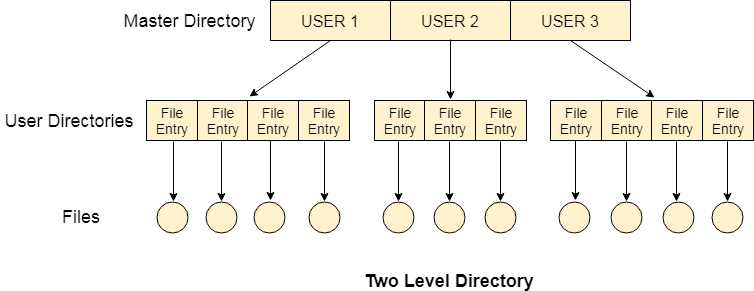
Fig 6: Two-Level Directory
Characteristics of the two-level directory system
- Each file has a pathname as /User-name/directory-name/
- Different users can have the same file name.
- Searching becomes more efficient as only one user's list needs to be traversed.
- The same kind of files cannot be grouped into a single directory for a particular user.
Every Operating System maintains a variable as PWD which contains the present directory name (present user name) so that the searching can be done appropriately.
Key takeaway
The directory can be defined as the listing of the related files on the disk. The directory may store some or the entire file attributes.
To get the benefit of different file systems on the different operating systems, A hard disk can be divided into some partitions of different sizes. The partitions are also called volumes or minidisks.
Every process needs some resources to complete its execution. However, the resource is granted in a sequential order.
The process requests for some resource.
OS grant the resource if it is available otherwise let the process waits.
The process uses it and release on the completion.
A Deadlock is a situation where each of the computer process waits for a resource which is being assigned to some another process. In this situation, none of the process gets executed since the resource it needs, is held by some other process which is also waiting for some other resource to be released.
Let us assume that there are three processes P1, P2 and P3. There are three different resources R1, R2 and R3. R1 is assigned to P1, R2 is assigned to P2 and R3 is assigned to P3.
After some time, P1 demands for R1 which is being used by P2. P1 halts its execution since it can't complete without R2. P2 also demands for R3 which is being used by P3. P2 also stops its execution because it can't continue without R3. P3 also demands for R1 which is being used by P1 therefore P3 also stops its execution.
In this scenario, a cycle is being formed among the three processes. None of the process is progressing and they are all waiting. The computer becomes unresponsive since all the processes got blocked.
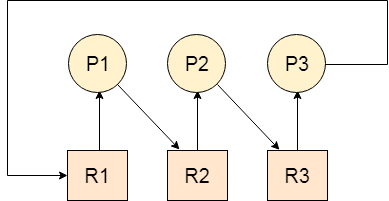
Fig 7 – Example
Difference between Starvation and Deadlock
Sr. | Deadlock | Starvation |
1 | Deadlock is a situation where no process got blocked and no process proceeds | Starvation is a situation where the low priority process got blocked and the high priority processes proceed. |
2 | Deadlock is an infinite waiting. | Starvation is a long waiting but not infinite. |
3 | Every Deadlock is always a starvation. | Every starvation need not be deadlock. |
4 | The requested resource is blocked by the other process. | The requested resource is continuously be used by the higher priority processes. |
5 | Deadlock happens when Mutual exclusion, hold and wait, No pre-emption and circular wait occurs simultaneously. | It occurs due to the uncontrolled priority and resource management. |
Necessary Conditions
- A deadlock occurs in operating system when at least two processes need some resource to finish their execution that is held by the different process.
- A deadlock happens if the four Coffman conditions prove to be true. But, these conditions are not totally related. They are describes as follows:
Mutual Exclusion
- There ought to be a resource that must be held by one process at once.
- In the figure below, there is a single instance of Resource 1 and it is held by Process 1 as it were.

Hold and Wait
- A process can hold numerous resources and still demand more resources from different processes which are holding them.
- In the graph given beneath, Process 2 holds Resource 2 and Resource 3 and is mentioning the Resource 1 which is held by Process 1.
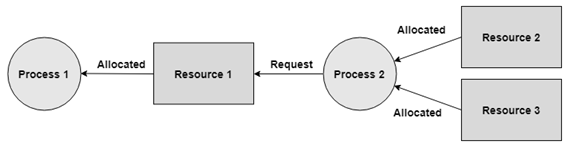
No Pre-emption
- A resource can't be pre-empted forcefully from a process. A process can just release a resource wishfully.
- In the graph underneath, Process 2 can't pre-empt Resource 1 from Process 1. It might be discharged when Process 1 gives up it intentionally after its execution is finished.

Circular Wait
- A process is waiting for the resource held continuously by other process, which is waiting for the resource held by the third process, etc, till the last process is waiting for a resource held by the first process. This structures a round chain.
- For instance: Process 1 is assigned Resource 2 and it is requesting Resource 1. Likewise, Process 2 is assigned Resource 1 and it is requesting Resource 2. This structures a circular wait loop.
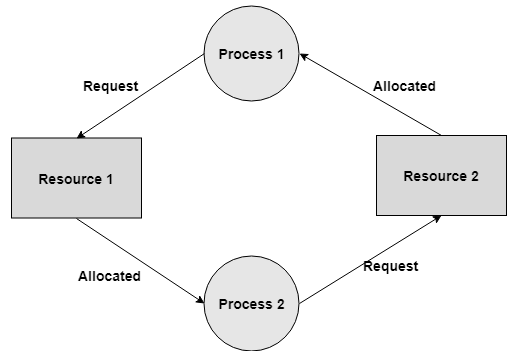
Key takeaway
Every process needs some resources to complete its execution. However, the resource is granted in a sequential order.
The process requests for some resource.
OS grant the resource if it is available otherwise let the process waits.
The process uses it and release on the completion.
A Deadlock is a situation where each of the computer process waits for a resource which is being assigned to some another process. In this situation, none of the process gets executed since the resource it needs, is held by some other process which is also waiting for some other resource to be released.
If we simulate deadlock with a table which is standing on its four legs then we can also simulate four legs with the four conditions which when occurs simultaneously, cause the deadlock.
However, if we break one of the legs of the table then the table will fall definitely. The same happens with deadlock, if we can be able to violate one of the four necessary conditions and don't let them occur together then we can prevent the deadlock.
Let's see how we can prevent each of the conditions.
1. Mutual Exclusion
Mutual section from the resource point of view is the fact that a resource can never be used by more than one process simultaneously which is fair enough but that is the main reason behind the deadlock. If a resource could have been used by more than one process at the same time then the process would have never been waiting for any resource.
However, if we can be able to violate resources behaving in the mutually exclusive manner then the deadlock can be prevented.
Spooling
For a device like printer, spooling can work. There is a memory associated with the printer which stores jobs from each of the process into it. Later, Printer collects all the jobs and print each one of them according to FCFS. By using this mechanism, the process doesn't have to wait for the printer and it can continue whatever it was doing. Later, it collects the output when it is produced.
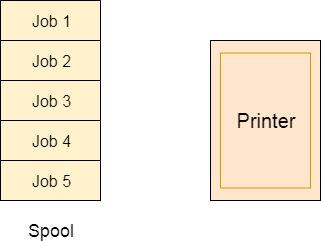
Fig 8 – Spooling
Although, Spooling can be an effective approach to violate mutual exclusion but it suffers from two kinds of problems.
This cannot be applied to every resource.
After some point of time, there may arise a race condition between the processes to get space in that spool.
We cannot force a resource to be used by more than one process at the same time since it will not be fair enough and some serious problems may arise in the performance. Therefore, we cannot violate mutual exclusion for a process practically.
2. Hold and Wait
Hold and wait condition lies when a process holds a resource and waiting for some other resource to complete its task. Deadlock occurs because there can be more than one process which are holding one resource and waiting for other in the cyclic order.
However, we have to find out some mechanism by which a process either doesn't hold any resource or doesn't wait. That means, a process must be assigned all the necessary resources before the execution starts. A process must not wait for any resource once the execution has been started.
!(Hold and wait) = !hold or !wait (negation of hold and wait is, either you don't hold or you don't wait)
This can be implemented practically if a process declares all the resources initially. However, this sounds very practical but can't be done in the computer system because a process can't determine necessary resources initially.
Process is the set of instructions which are executed by the CPU. Each of the instruction may demand multiple resources at the multiple times. The need cannot be fixed by the OS.
The problem with the approach is:
Practically not possible.
Possibility of getting starved will be increases due to the fact that some process may hold a resource for a very long time.
3. No Pre-emption
Deadlock arises due to the fact that a process can't be stopped once it starts. However, if we take the resource away from the process which is causing deadlock then we can prevent deadlock.
This is not a good approach at all since if we take a resource away which is being used by the process then all the work which it has done till now can become inconsistent.
Consider a printer is being used by any process. If we take the printer away from that process and assign it to some other process then all the data which has been printed can become inconsistent and ineffective and also the fact that the process can't start printing again from where it has left which causes performance inefficiency.
4. Circular Wait
To violate circular wait, we can assign a priority number to each of the resource. A process can't request for a lesser priority resource. This ensures that not a single process can request a resource which is being utilized by some other process and no cycle will be formed.
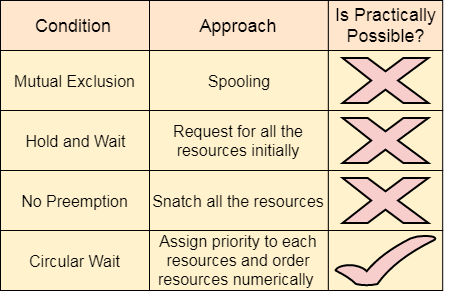
Fig 9 – Process state
Among all the methods, violating Circular wait is the only approach that can be implemented practically.
Key takeaway
If we simulate deadlock with a table which is standing on its four legs then we can also simulate four legs with the four conditions which when occurs simultaneously, cause the deadlock.
However, if we break one of the legs of the table then the table will fall definitely. The same happens with deadlock, if we can be able to violate one of the four necessary conditions and don't let them occur together then we can prevent the deadlock.
- Deadlock-prevention algorithm prevents the occurrence of deadlock by limiting how demands can be made. The restrictions guarantee that at any rate one of the vital conditions for deadlock can't happen and, thus, deadlock can't occur.
- Conceivable drawbacks of preventing deadlocks by this strategy, in any case, result in low device usage and decreased system throughput.
- An alternative strategy for staying away from deadlocks is to require extra data about how resources are requested.
- In this respect each request requires that system keeps record about the resources as of now available, the resources at present assigned to each process, and the future demands and releases of each process.
- The different algorithms that utilize this methodology vary in the sum and type of data required. The least complex and most valuable model necessitates that each process proclaim the most maximum number of resources of each instance that it might require.
- Given this as earlier data, it is conceivable to develop a algorithm that guarantees that the system will never enter a deadlock state. Such a calculation characterizes the deadlock avoidance approach.
- A deadlock avoidance approach powerfully looks at the resource-assignment state to guarantee that a circular wait condition can never exist.
- The resource-allocation state is characterized by the number of available and allotted resources and the most extreme requests of the processes.
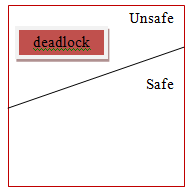
Safe State
- A state is safe if the system can assign resources to each process (up to its most extreme) in some sequence and still will be able maintain a deadlock free state.
- In other words, a system is in a safe state if there exists a safe sequence.
- An arrangement of processes <P1, P2, ... , Pn> is a safe arrangement for the present allocation state if, for each Pi, the resource requests that Pi make can be fulfilled by the currently accessible resources in addition to the resources held by all Pj, with j < i.
- In this circumstance, the resources that Pi needs are not quickly available, at that point then Pi can wait until all Pj have completed.
- When all Pj have completed, Pi can acquire the majority of its required resources, complete its assigned task, and return its allotted resources, and will terminate.
- At the point when Pi ends, Pi+l can get its required resources, and so on.
- In the event that no such sequence exists, at that point the system state is said to be unsafe.
- A safe state is definitely not a deadlock state. On the other hand, a deadlock state is a unsafe state. All the unsafe state are not deadlock.
- Consider a system with 10 magnetic tape drives and 3 processes P0, P1, and P2 respectively. The maximum requirement and current needs by each process is shown in table below.
Process | Maximum needs | Current allocated |
P0 | 8 | 4 |
P1 | 4 | 2 |
P2 | 8 | 2 |
- Process P0 is having 4 tape drives, P1 is having 2 tape drives and P2 is having 2 tape drives.
- For a safe sequence process P0 needs 4 more tape drives to completes its execution. Similarly process P1 needs 2 and P2 needs 6. Total available resources are 2.
- Since process P0 needs 5 tape drives, but available is only 2, so process P1 will wait till gets resources. Process P1 needs only 2 so its request will be fulfilled and as P1 will finish its execution it will return all resources.
- Now currently available resources are 4. Then process P2 will wait as available resources are 4 and P2 needs 6.
- The system will now fulfil the needs of P0. Process P0 will execute and release its all resources. Now available resources are 8. And in the last request of process P2 will be fulfilled.
- So, the safe sequence will be <P1, P0, P2>.
- There is one thing to be note here that any system can go from a safe state to unsafe state if any process requests more resources.
In this approach, The OS doesn't apply any mechanism to avoid or prevent the deadlocks. Therefore, the system considers that the deadlock will definitely occur. In order to get rid of deadlocks, The OS periodically checks the system for any deadlock. In case, it finds any of the deadlock then the OS will recover the system using some recovery techniques.
The main task of the OS is detecting the deadlocks. The OS can detect the deadlocks with the help of Resource allocation graph.
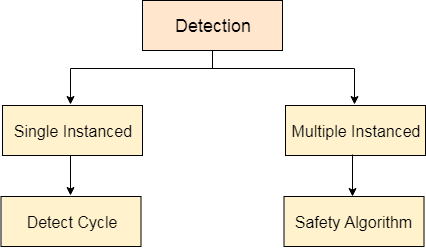
Fig 10 – Detection
In single instanced resource types, if a cycle is being formed in the system then there will definitely be a deadlock. On the other hand, in multiple instanced resource type graph, detecting a cycle is not just enough. We have to apply the safety algorithm on the system by converting the resource allocation graph into the allocation matrix and request matrix.
In order to recover the system from deadlocks, either OS considers resources or processes.
For Resource
Pre-empt the resource
We can snatch one of the resources from the owner of the resource (process) and give it to the other process with the expectation that it will complete the execution and will release this resource sooner. Well, choosing a resource which will be snatched is going to be a bit difficult.
Rollback to a safe state
System passes through various states to get into the deadlock state. The operating system can roll back the system to the previous safe state. For this purpose, OS needs to implement check pointing at every state.
The moment, we get into deadlock, we will rollback all the allocations to get into the previous safe state.
For Process
Kill a process
Killing a process can solve our problem but the bigger concern is to decide which process to kill. Generally, Operating system kills a process which has done least amount of work until now.
Kill all process
This is not a suggestible approach but can be implemented if the problem becomes very serious. Killing all process will lead to inefficiency in the system because all the processes will execute again from starting.
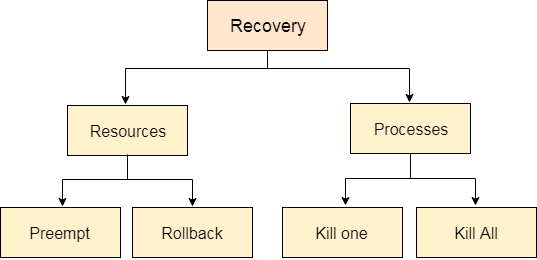
Fig 11 - Recovery
Key takeaway
In this approach, The OS doesn't apply any mechanism to avoid or prevent the deadlocks. Therefore, the system considers that the deadlock will definitely occur. In order to get rid of deadlocks, The OS periodically checks the system for any deadlock. In case, it finds any of the deadlock then the OS will recover the system using some recovery techniques.
The main task of the OS is detecting the deadlocks. The OS can detect the deadlocks with the help of Resource allocation graph.
References:
1. Operating Systems (5th Ed) - Internals and Design Principles by William Stallings, Prentice Hall India, 2000.
2. Operating System: Concepts and Design by Milan Milenkovik, McGraw Hill Higher Education.
3. Operating Systems - 3rd Edition by Gary Nutt, Pearson Education.
4. Operating Systems, 3rd Edition by P. Balakrishna Prasad, SciTech Publications.




