Unit – 1
Introduction to database systems
Database
The database is a set of interrelated data used to efficiently retrieve, insert and remove data. It is also used in the form of a table, schema, views, and reports to organize the data, etc.
You can conveniently retrieve, attach, and delete information using the database.
Database management system (DBMS)
A DBMS is a programme that enables database creation, specification and manipulation, allowing users to easily store, process and analyse information.
DBMS provides one with an interface or a tool to conduct different operations, such as building databases, storing data in them, updating data, creating database tables, and much more.
The DBMS also provides databases with privacy and security. In the case of multiple users, it also ensures data consistency.
Some Example of DBMS:
● MySQL
● Oracle
● SQL Server
● IBM DB2
Advantages of DBMS
- Controls database redundancy: It can control data redundancy because it stores all the data in one single database file and that recorded data is placed in the database.
- Data sharing: In DBMS, the authorized users of an organization can share the data among multiple users.
- Easily Maintenance: It can be easily maintainable due to the centralized nature of the database system.
- Reduce time: It reduces development time and maintenance need.
- Backup: It provides backup and recovery subsystems which create automatic backup of data from hardware and software failures and restores the data if required.
- Multiple user interface: It provides different types of user interfaces like graphical user interfaces, application program interfaces
Disadvantages of DBMS
- Cost of Hardware and Software: It requires a high speed of data processor and large memory size to run DBMS software.
- Size: It occupies a large space of disks and large memory to run them efficiently.
- Complexity: Database system creates additional complexity and requirements.
- Higher impact of failure: Failure is highly impacted the database because in most of the organization, all the data stored in a single database and if the database is damaged due to electric failure or database corruption then the data may be lost forever.
Purpose of Database Systems
It is a set of tools that allows a user to construct and manage databases. In other words, it is general-purpose software that enables users to define, construct, and manipulate databases for a variety of applications.
Database systems are made to handle massive amounts of data. Data management entails both the creation of structures for storing data and the provision of methods for manipulating data. Furthermore, despite system crashes or efforts at illegal access, the database system must preserve the security of the information stored. If data is to be shared across multiple users, the system must avoid any unexpected outcomes.
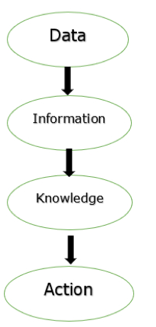
Fig 1: Process of transforming data
The figure above depicts the process of transforming data into information, knowledge, and action in a database management system.
The file system was used as the foundation for the database applications.
The goal of a database management system (DBMS) is to transform the following:
1. Data into information.
2. Information into knowledge.
3. Knowledge of the action.
Uses of DBMS
The main uses of DBMS are as follows −
● Data independence and efficient access of data.
● Application Development time reduces.
● Security and data integrity.
● Uniform data administration.
● Concurrent access and recovery from crashes.
Characteristics of DBMS
● It stores and manages information in a digital repository hosted on a server.
● It can provide a logical and transparent picture of the data manipulation process.
● Automatic backup and recovery mechanisms are included in the DBMS.
● It has ACID qualities, which keep data healthy in the event of a failure.
● It has the ability to simplify complex data relationships.
● It's utilized to help with data manipulation and processing.
● It is used to ensure data security.
● It can examine the database from several perspectives depending on the user's needs.
Key takeaway
DBMS provides one with an interface or a tool to conduct different operations, such as building databases, storing data in them, updating data, creating database tables, and much more.
The architecture of a database management system influences its design. When dealing with a large number of PCs, web servers, database servers, and other networked elements, the same client/server architecture is used.
A client/server architecture is made up of several PCs and a workstation that are all linked by a network.
The design of a database management system is determined by how users link to the database in order to complete their requests.
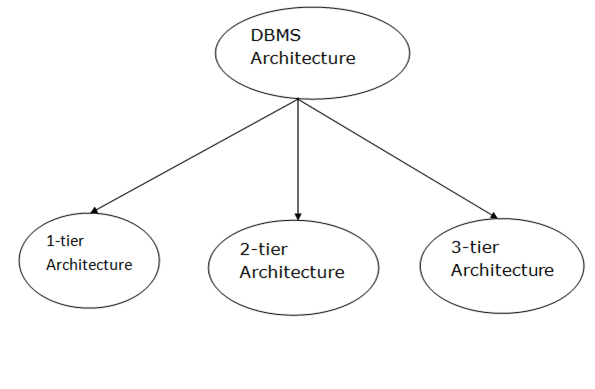
Fig 2: Types of architecture
A single tier or multi-tier database architecture can be seen. However, database design can be divided into two categories: 2-tier architecture and 3-tier architecture.
1-tier Architecture:
The database is directly accessible to the user in this architecture. It means that the user can sit on the DBMS and use it directly. Any modifications made here will be applied directly to the database. It does not provide end users with a useful tool.
For the creation of local applications, a 1-tier architecture is used, in which programmers can interact directly with the database for fast responses.
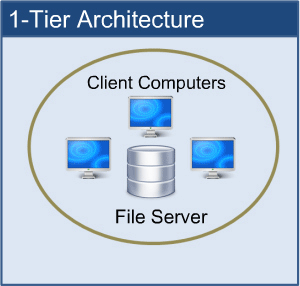
Fig 3: 1-tier architecture
2-tier Architecture:
The 2-tier architecture is similar to the basic client-server architecture. Client-side applications can interact directly with the database on the server side in a two-tier architecture. APIs such as ODBC and JDBC are used for this interaction.
The client-side runs the user interfaces and application programs. The server side is in charge of providing features such as query processing and transaction management. The client-side application creates a link with the server side in order to communicate with the DBMS.
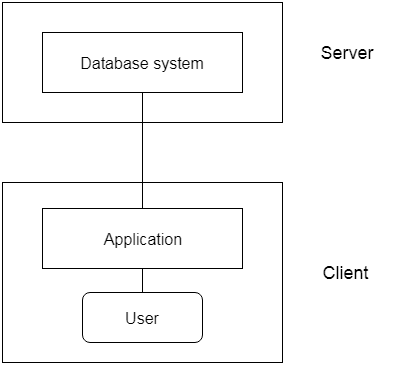
Fig 4: 2-tier architecture
3-tier Architecture:
Between the client and the server is another layer in the 3-tier architecture. The client cannot communicate directly with the server in this architecture. The client-side program communicates with an application server, which in turn communicates with the database system.
Beyond the application server, the end user is unaware of the database's presence. Aside from the submission, the database has no knowledge about any other users.
In the case of a wide web application, the 3-tier architecture is used.
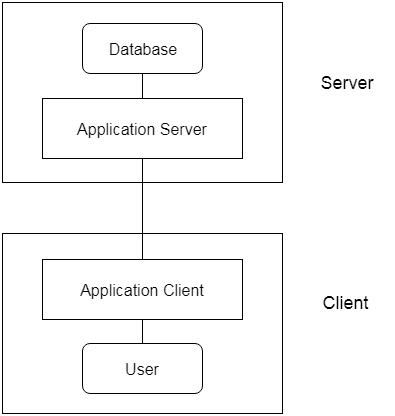
Fig 5: 3-tier architecture
Key takeaway
The architecture of a database management system influences its design. When dealing with a large number of PCs, web servers, database servers, and other networked elements, the same client/server architecture is used.
Conflicting goals, such as adherence to design standards (design elegance), processing speed, and information requirements, force database designers to make design tradeoffs.
Design standards
Design guidelines must be followed when creating a database. As a result of these standards, you've been able to create logical structures that reduce data redundancy and, as a result, the chance of destructive data anomalies. You've also learned how to avoid nulls as much as feasible according to standards. In a nutshell, design standards allow you to work with well-defined components and evaluate their interactions with precision. It is practically impossible to establish a suitable design process, analyse an existing design, or trace the expected logical consequence of design modifications without design standards.
Processing speed
High processing speeds are often a major priority in database architecture in many organisations, particularly those that generate huge quantities of transactions. Minimal access time is achieved by reducing the quantity and complexity of logically desirable relationships, which can be achieved by increasing processing speed. For example, a "ideal" design might eliminate nulls by utilising a 1:1 relationship, whereas a better transaction-speed design might combine the two tables to minimise the need for an additional relationship and avoid nulls by using dummy entries. If data retrieval speed is a priority, you may be required to include derived attributes in the design.
Information requirements
The desire of real-time data could be the goal of database design. Complex data requirements may necessitate data transformations, as well as an increase in the number of entities and characteristics in the design. To ensure maximal information creation, the database may have to trade some of its "clean" design structures and/or part of its high transaction performance.
An important goal is to create a design that fits all logical requirements and design norms. However, if this flawless design fails to match the customer's transaction speed and/or information needs, the designer will not have done a good job in the eyes of the end user. In the real world of database design, compromises are unavoidable.
Even as the designer concentrates on the entities, characteristics, relationships, and constraints, end-user requirements like as performance, security, shared access, and data integrity should be considered. The designer must take into account processing needs and ensure that all update, retrieval, and deletion options are available. Finally, a design is worthless unless the finished product can meet all of the required query and reporting criteria.
Last but not least, document, document, document! Make a list of all design activity. Then go over what you've written again. Documentation not only keeps you on track during the design process, but it also allows you (or anyone who follow you) to pick up where you left off when it's time to make changes. Despite the obvious need for documentation, one of the most frustrating aspects of database and systems analysis work is that the "put it in writing" criterion is not always followed throughout the design and implementation stages. The creation of organisational documentation standards is a critical component of assuring data compatibility and consistency.
You may split the database management system into five main components, which are
- Hardware
- Software
- Data
- Procedure
- Database Access Language
In order to see how they all work together to form a database management system, let's have a basic diagram.
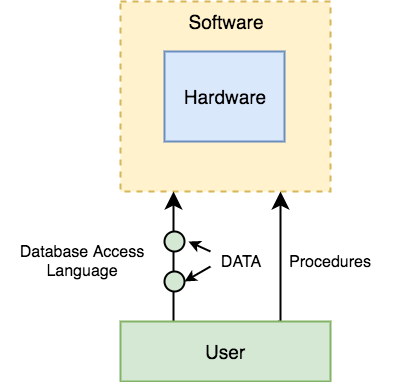
Fig 6: Component of DBMS
1. Hardware
When we say hardware, before any data is successfully stored in the memory, we mean computers, hard discs, I/O channels for data, and any other physical part involved.
When we run Oracle or MySQL on our personal computer, the hard disc of our computer, the keyboard we use to type all the commands, the RAM of our computer, the ROM, all become part of the hardware of the DBMS.
2. Software
As this is the software that governs everything, this is the key part. More like a wrapper around the physical database, the DBMS programme gives us an easy-to-use interface for storing, accessing and upgrading data.
The DBMS programme is able to understand and translate the Database Access Language into actual database commands in order to execute them on the DB.
3. Data
Data is the resource for which the DBMS is intended. The motive behind the creation of DBMS was to store and use information.
Data saved by the user is present in a standard database and meta data is stored.
Metadata is data about knowledge. To better understand the data contained in it, this is information stored by the DBMS.
4. Procedure
Procedures refer to general instructions for using a method to handle a database. This includes procedures for setting up and installing a DBMS, logging in and logging out of the DBMS programme, database maintenance, backups, report creation, etc.
5. Database Access language
Database Access Language is a basic language designed to access, attach, update and delete data stored in any database by writing commands.
In the Database Access Language, a user can write commands and send them to the DBMS for execution, which is then interpreted and executed by the DBMS.
The user can use the access language to build new databases, tables, insert data, fetch stored data, update data and remove data.
Key takeaway:
Hardware means computers, hard discs, I/O channels for data, and any other physical part involved.
Software that governs everything, this is the key part.
Data is the resource for which the DBMS is intended.
Procedures refer to general instructions for using a method to handle a database.
In the Database Access Language, a user can write commands and send them to the DBMS.
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Data models are used to describe the design of a database at the logical level.
Some of the data models are: -
1. Entity-Relationship Model
2. Relational Model
4. Network Model
5. Object Relational Model
1.5.1 Entity-relationship model
- The logical structure of a database can be expressed by an E-R diagram.
- Relationships are defined in this database model by dividing the object of interest into an entity and its characteristics into attributes.
- Using relationships, various entities are related.
- To make it easier for various stakeholders to understand, E-R models are established to represent relationships in pictorial form.
The Main Components of ER Diagram are: -
a) Rectangles - Entity Sets
b) Ellipses - Attributes
c) Diamond - Relation among entity sets
d) Lines - Connects attributes to entity sets and entity sets to relationships.
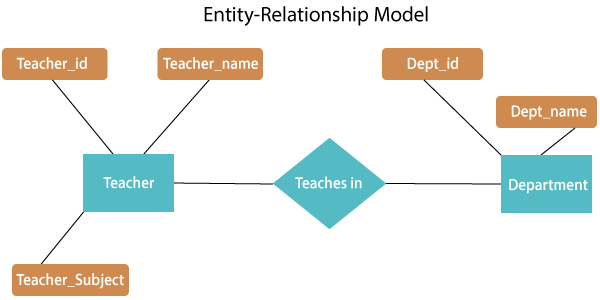
Fig 7: E-R relationship
The above E-R diagram has two entities: Teacher and Department
Teacher entity has three attributes:
Teacher_id
Teacher_name
Teacher_Subject
Department entity has two attributes: -
Dept_id
Dept_name
Relation Teaches in gives relationship between Teacher, Department.
Relationship can be of the type:
1:1 → One to one
1:M → One to many
M:1 → Many to one
M:M → Many to many
Key takeaway:
- The logical representation of data as objects and relations among them is an ER model.
- These objects are known as entities, and an interaction between these entities is an association.
1.5.2 Network model
- Network model uses two different data structures: -
a) A record type is used to represent as entity set.
b) A set type is used to represent a directed relationship between two record types.
- This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
- Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
- This was the most commonly used database architecture prior to the advent of the Relational Model.
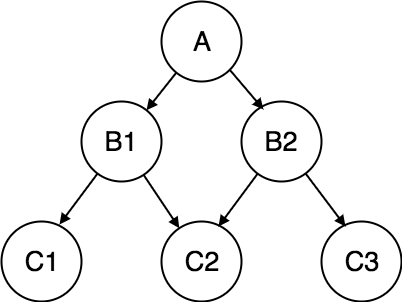
Fig 8: Network model
Key takeaway:
- Network model is the Hierarchical model's extension
- Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
1.5.3 Relational and object-oriented data models
Relational model
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- This model is useful for constructing a database that can then be converted into relational model tables.
- Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
- In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
A. Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
B. Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
C. Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Object oriented data model
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of the object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
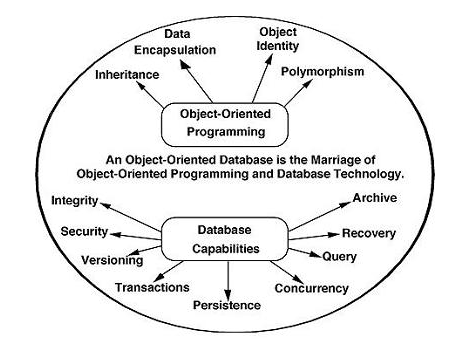
Fig 9: Object-oriented model
Object-oriented databases use small, recyclable separated of software called objects. The objects themselves are stored in the object-oriented database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with The data.
There are two types of ORM: -
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Key takeaway:
- The logical structure of a database can be expressed by an E-R diagram.
- Relational model uses a collection of tables to represent both data and the relationships among those data.
- Object-oriented databases use small, recyclable separated of software called objects.
References:
- Silberschatz A., Korth H., Sudarshan S. “Database System Concepts”, 6th edition, Tata McGraw Hill Publisher
- Ramkrishna R., Gehrke J. “Database Management Systems”, 3rd edition, McGraw Hill
- Rab P., Coronel C. “Database Systems Design, Implementation and Management”, 5th edition, Thomson Course Technology, 2002




