Unit - 5
Recovery System and advanced databases
To find where the problem has occurred, we generalize a failure into the following categories:
- Transaction failure
- System crash
- Disk failure
1. Transaction failure
The transaction failure occurs when it fails to execute or when it reaches a point from where it can't go any further. If a few transaction or process is hurt, then this is called as transaction failure.
Reasons for a transaction failure could be -
- Logical errors: If a transaction cannot complete due to some code error or an internal error condition, then the logical error occurs.
- Syntax error: It occurs where the DBMS itself terminates an active transaction because the database system is not able to execute it. For example, The system aborts an active transaction, in case of deadlock or resource unavailability.
2. System Crash
- System failure can occur due to power failure or other hardware or software failure. Example: Operating system error.
- Fail-stop assumption: In the system crash, non-volatile storage is assumed not to be corrupted.
3. Disk Failure
- It occurs where hard-disk drives or storage drives used to fail frequently. It was a common problem in the early days of technology evolution.
- Disk failure occurs due to the formation of bad sectors, disk head crash, and unreachability to the disk or any other failure, which destroy all or part of disk storage.
Key takeaway
To find that where the problem has occurred, we generalize a failure into the following categories:
- Transaction failure
- System crash
- Disk failure
Crash Recovery
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
Failure Classification
To see where the problem has occurred, we generalize a failure into various categories, as follows −
Transaction failure
A transaction has to abort when it fails to execute or when it reaches a point from where it can’t go any further. This is called transaction failure where only a few transactions or processes are hurt.
Reasons for a transaction failure could be −
- Logical errors− Where a transaction cannot complete because it has some code error or any internal error condition.
- System errors− Where the database system itself terminates an active transaction because the DBMS is not able to execute it, or it has to stop because of some system condition. For example, in case of deadlock or resource unavailability, the system aborts an active transaction.
System Crash
There are problems − external to the system − that may cause the system to stop abruptly and cause the system to crash. For example, interruptions in power supply may cause the failure of underlying hardware or software failure.
Examples may include operating system errors.
Disk Failure
In early days of technology evolution, it was a common problem where hard-disk drives or storage drives used to fail frequently.
Disk failures include formation of bad sectors, unreachability to the disk, disk head crash or any other failure, which destroys all or a part of disk storage.
Storage Structure
We have already described the storage system. In brief, the storage structure can be divided into two categories −
- Volatile storage−As the name suggests, a volatile storage cannot survive system crashes. Volatile storage devices are placed very close to the CPU; normally they are embedded onto the chipset itself. For example, main memory and cache memory are examples of volatile storage. They are fast but can store only a small amount of information.
- Non-volatile storage−These memories are made to survive system crashes. They are huge in data storage capacity, but slower in accessibility. Examples may include hard-disks, magnetic tapes, flash memory, and non-volatile (battery backed up) RAM.
Recovery and Atomicity
When a system crashes, it may have several transactions being executed and various files opened for them to modify the data items. Transactions are made of various operations, which are atomic in nature. But according to ACID properties of DBMS, atomicity of transactions as a whole must be maintained, that is, either all the operations are executed or none.
When a DBMS recovers from a crash, it should maintain the following −
- It should check the states of all the transactions, which were being executed.
- A transaction may be in the middle of some operation; the DBMS must ensure the atomicity of the transaction in this case.
- It should check whether the transaction can be completed now or it needs to be rolled back.
- No transactions would be allowed to leave the DBMS in an inconsistent state.
There are two types of techniques, which can help a DBMS in recovering as well as maintaining the atomicity of a transaction −
- Maintaining the logs of each transaction, and writing them onto some stable storage before actually modifying the database.
- Maintaining shadow paging, where the changes are done on a volatile memory, and later, the actual database is updated.
Log-based Recovery
Log is a sequence of records, which maintains the records of actions performed by a transaction. It is important that the logs are written prior to the actual modification and stored on a stable storage media, which is failsafe.
Log-based recovery works as follows −
- The log file is kept on a stable storage media.
- When a transaction enters the system and starts execution, it writes a log about it.
<Tn, Start>
- When the transaction modifies an item X, it write logs as follows −
<Tn, X, V1, V2>
It reads Tn has changed the value of X, from V1 to V2.
- When the transaction finishes, it logs −
<Tn, commit>
The database can be modified using two approaches −
- Deferred database modification− All logs are written on to the stable storage and the database is updated when a transaction commits.
- Immediate database modification−Each log follows an actual database modification. That is, the database is modified immediately after every operation.
Recovery with Concurrent Transactions
When more than one transaction are being executed in parallel, the logs are interleaved. At the time of recovery, it would become hard for the recovery system to backtrack all logs, and then start recovering. To ease this situation, most modern DBMS use the concept of 'checkpoints'.
Checkpoint
Keeping and maintaining logs in real time and in real environment may fill out all the memory space available in the system. As time passes, the log file may grow too big to be handled at all. Checkpoint is a mechanism where all the previous logs are removed from the system and stored permanently in a storage disk. Checkpoint declares a point before which the DBMS was in consistent state, and all the transactions were committed.
Recovery
When a system with concurrent transactions crashes and recovers, it behaves in the following manner −

Fig 1: Recovery
- The recovery system reads the logs backwards from the end to the last checkpoint.
- It maintains two lists, an undo-list and a redo-list.
- If the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, it puts the transaction in the redo-list.
- If the recovery system sees a log with <Tn, Start> but no commit or abort log found, it puts the transaction in undo-list.
All the transactions in the undo-list are then undone and their logs are removed. All the transactions in the redo-list and their previous logs are removed and then redone before saving their logs.
Key takeaway
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
- When a transaction is started, the start' log is written.
<Tn, Start>
- Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
- When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
- The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
- If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Key takeaway
- The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
- Any operation that is performed on the database is documented in the log.
The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
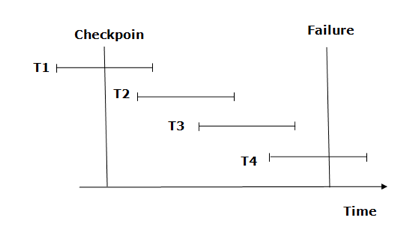
Fig 2: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example: <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Key takeaway
- The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
- The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
- In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
- In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
- Transactions which are in active list and failed list are undone and written on the abort list.
- Transactions which are in before-commit list are redone.
- No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions−
- Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
- Transactions which are in before-commit list are redone.
- No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
- The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
- The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A “checkpoint” record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
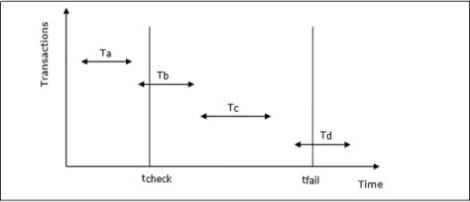
Fig 3: Transaction
The actions that are taken by the recovery manager are −
Nothing is done with Ta.
Transaction redo is performed for Tb and Tc.
Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
Key takeaway
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
- In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
- In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
There are a variety of other logging strategies that are more efficient than the ones listed above. Let's have a look at a few of them:
Logical Undo Logging
In normal types of executions, logging and checkpoints will operate well. However, we face difficulties when records are entered and deleted in a B+ tree format. The locks will be released early due to the B+ tree structure. As soon as such records are released, they will be locked by other transactions in the tree. As a result, undoing those record values using the above procedures is difficult, if not impossible.
As a result, we'll need a different way to undo these kinds of insertions and deletions. Logic undo techniques, rather than physical undo procedures, are required. The record value will be updated to the old value or re-executed in the physical undo procedure, which will look at the logs for earlier values or commit.
We can't undo operations if locks are released early since we can't just write back the old value of the data items. Consider transaction T, which inserts an entry into a B+-tree and, in accordance with the B+-tree concurrency-control protocol, releases some locks after the insertion operation but before the transaction commits. Other transactions may make additional insertions or deletions after the locks are freed, producing further changes to the B+-tree nodes.
Even if some locks are released early, the operation must keep enough locks to ensure that no other transaction can perform a conflicting operation (such as reading the inserted value or deleting the inserted value).
A second undo log file is created along with the log file in the logical undo approach. Any insertion action will have a corresponding deletion operation in the undo file to unwind the changes. The insertion operation will be detailed in the same way as the deletion operation. Logical undo logging is the name given to this method.
Following the log file – physical log can be used to undo the transaction. We will not keep a logical log in case the transaction needs to be redone. This is because by the time the system is restored, the state of the record will have changed. Other transactions may have already completed, causing the logical redo log to be incorrect. As a result, the physical log is re-executed in order to perform the procedures.
Transaction Rollback
Consider transaction rollback in the normal course of business (that is, not during recovery from system failure). To restore the old values of data items, the system scans the log backwards and uses log records related to the transaction. Rollback under our advanced recovery scheme, on the other hand, writes down special redo-only log records of the form Ti, Xj, V > containing the value V being restored to data item Xj during the rollback, unlike in regular operation. These log books are also known as compensatory log books. We will never need to undo such an undo operation, hence such records do not require undo information.
When a system crashes and the system tries to recover by rolling back, it scans the logs in reverse order and updates the log entries as follows:
● Enter the undo log as if there is a log entry. This type of undo log entry is referred to as a redo-only log entry. If it detects a redo-only record during recovery, it ignores it.
● If it detects something while traversing the log, use logical undo to undo the operation. This logical undo operation is also logged into the log file as a normal operation, but instead of, is logged at the end. Then skip all of the processes until you get to the end. i.e., it handles all logical undo actions as if they were regular activities, and its logs are saved in a log file, while all physical undo operations are disregarded.
Crash Recovery
When a system crashes, the transactions that were in the middle of execution must be recovered, and the database must be restored back to a consistent state. To perform redo and undo procedures, log files are reviewed. It is divided into two parts.
Redo Phase
Despite the fact that transactions and operations are rolled back in the reverse order of log file entries, the recovery system keeps a recovery log list for undoing and redoing operations by scanning the logs from the last checkpoint to the end of the file.
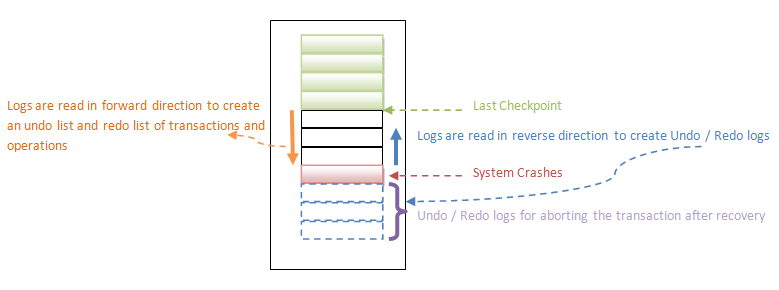
That is, undo / redo logs will contain a list of operations and how to perform them, which will be stored in the log file. A separate list of entries will be formed to keep track of the transactions/operations that need to be undone throughout the recovery process. This will be done by searching the log files from the most recent checkpoint to the end (forward direction). All other operations that are not part of the undo list are redone while constructing the undo list.
It checks if the forward scan to generate the undo list, L, is complete.
<Ti, Start> found, then adds Ti to undo list L
<Ti, Commit> or <Ti, Abort> is found, then it deletes Ti entry from undo list, L
As a result, the undo list will contain all partially completed transactions, while all other committed transactions will be re-done (redoing the transaction is not exactly as re-executing them. This forward scanning assumes that those transactions are already performed and committed, and lists only those transactions that are not committed yet and in partial execution state.)
Undo Phase
The log files are examined backward for transactions in the undo list in this step. Undoing transactions is done in the same way that transaction rollback is done. It looks for the end log for each operation and executes logical undo if one is discovered, or physical undo if the logs are entered into log files.
This is how a transaction is redone and undone in order to keep the transaction's consistency and atomicity.
Checkpoints
The procedure for checkpointing is outlined in Section 17.6. The system briefly pauses database updates and performs the following tasks:
1. It writes all log records now in main memory to stable storage.
2. It saves all modified buffer blocks to disc.
3. It writes a log entry called checkpoint L> to stable storage, where L is a list of all ongoing transactions.
Fuzzy Checkpointing
While the checkpoint is being performed, all database updates must be temporarily paused. A checkpoint may take a long time to complete if the amount of pages in the buffer is enormous, resulting in an unacceptable stoppage in transaction processing.
To minimise such disruptions, the checkpointing mechanism can be modified to allow updates to begin after the checkpoint record is created but before the modified buffer blocks are sent to disc. The resulting checkpoint is a fuzzy checkpoint.
Because pages are only written to disc after the checkpoint record has been recorded, the system may crash before all pages have been written. As a result, a disc checkpoint may be incomplete. This is one technique to cope with missing checkpoints: The last-checkpoint location in the log of the checkpoint record is saved in a fixed position on disc, last-checkpoint. When the system writes the checkpoint record, it does not update this information. Instead, it builds a list of all modified buffer blocks before writing the checkpoint record. Only when all buffer blocks in the list of modified buffer blocks have been exported to disc is the last-checkpoint information updated.
Even if fuzzy checkpointing is used, a buffer block must not be modified while being written to the disc, while other buffer blocks may be updated at the same time. Before a block is printed, the write-ahead log protocol must be followed to ensure that (undo) log records relevant to the block are on stable storage.
A web database is basically a database that can be accessed instead of one that has its data stored on a desktop or its connected storage, from a local network or the internet. Used both for technical and personal use, they are hosted on websites and are products of Software as a Service (SaaS), which means that access is made accessible via a web browser.
A relational database is one of the kinds of online databases that you might be more familiar with. Relational databases, through their ability to connect records together, allow you to store data in groups (known as tables). To find information fields stored in the database, it uses indexes and keys which are applied to the data, allowing you to quickly retrieve information.
A web database is a general concept used to manage data online. Without being a database guru or even a technical person, a web database gives you the opportunity to create your own databases / data storage.
Instances: banks, reservations for airlines and rental vehicles, enrollment for university courses, etc.
● The Web is a hypertext-based online information system.
● The bulk of Web documents are HTML-formatted hypertext documents.
● Contain HTML Documents
● Text along with font details, and other guidelines for formatting
● Hypertext connects to other documents that can be connected with the text field.
Web Database Includes:
- Save Money: One of the benefits of software for online databases is that it can save money for your business. Overall, if you don't need to purchase a software programme for your business, this might result in considerable savings. In most cases, for each computer that uses it, corporations pay for a software programme and then pay for a licence fee.
- Flexible use: Another advantage of using an online database programme is that it provides versatility for your business. You're paying just for the amount of room you need. When they are no longer needed, you do not need to think about buying servers as you go or eliminating them.
- Technical support: Another benefit of using a Web-based database programme is that the technical support responsibility can be transferred to someone else. Technical support is included in paying an organisation for access to an online database. If there are issues with the database, you simply contact the organisation and it is addressed by the workers.
- Access: Another big benefit of this type of database is providing access to the database at all times from different locations. For an online database, from any machine, you could potentially access the information in the database. The details are also available 24 hours a day, seven days a week.
- Typically, web database systems come with their own technical support team so that staff from the IT department can concentrate on more pressing business issues.
- It's easy: web databases allow users to update data, so all you have to do is build simple web forms.
- The data is accessible from nearly any computer. Getting stuff stored in a cloud ensures that one machine is not stuck with it. You can theoretically get a hold of the data from just about any compatible computer as long as you are given access.
Key takeaway:
A web database is a general concept used to manage data online.
A web database is basically a database that can be accessed instead of one that has its data stored on a desktop or its connected storage, from a local network or the internet.
A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
A distributed database system (DDBS) is a database that does not have all of its storage devices connected to the same CPU. It might be stored on numerous computers in the same physical place, or it could be spread throughout a network of connected computers. Simply said, it is a logically centralized yet physically dispersed database system. It's a database system and a computer network all rolled into one. Despite the fact that this is a major issue in database architecture, one of the most serious challenges in today's database systems is storage and query in distributed database systems.
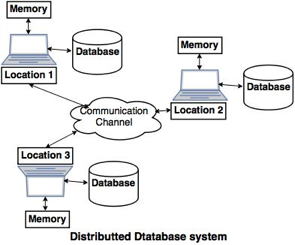
Fig 4: Distributed database
A centralized software system that manages a distributed database as if it were all kept in a single location is known as a distributed database management system (DDBMS).
Features
- It's used to create, retrieve, update, and destroy databases that are distributed.
- It synchronizes the database on a regular basis and provides access mechanisms, making the distribution transparent to the users.
- It ensures that data modified on any site is updated across the board.
- It's utilized in applications where a lot of data is processed and accessible by a lot of people at the same time.
- It's made to work with a variety of database platforms.
- It protects the databases' confidentiality and data integrity.
Advantages of Distributed Databases
The advantages of distributed databases versus centralized databases are as follows.
- Modular Development − In centralized database systems, if the system needs to be expanded to additional locations or units, the activity necessitates significant effort and disruption of current operations. In distributed databases, on the other hand, the process is merely moving new computers and local data to the new site and then connecting them to the distributed system, with no interruption in present operations.
- More Reliable − When a database fails, the entire centralized database system comes to a halt. When a component fails in a distributed system, however, the system may continue to function but at a lower level of performance.
- Better Response − If data is delivered efficiently, user requests can be fulfilled from local data, resulting in a speedier response. In centralized systems, on the other hand, all inquiries must transit through the central computer for processing, lengthening the response time.
- Lower Communication Cost − When data is stored locally where it is most frequently utilized in distributed database systems, communication costs for data manipulation can be reduced. In centralized systems, this is not possible.
Key takeaway
- A distributed database system is made up of multiple sites with no physical components in common.
- A distributed database system (DDBS) is a database that does not have all of its storage devices connected to the same CPU.
In order to provide useful business insights, a Data Warehousing (DW) method is used to collect and handle data from different sources. A data warehouse is usually used for linking and analysing heterogeneous sources of business data. The data warehouse is the cornerstone of the data collection and reporting framework developed for the BI system.
It is a blend of technologies and elements that promotes the strategic use of information. Instead of transaction processing, it is electronic storage of a vast volume of information by an organisation that is intended for question and review. It is a method of converting data into data and making it accessible to users to make a difference in a timely manner.
A Data Warehouse with the following attributes can be described as a data system:
- It is a database, using data from different applications, developed for investigative tasks.
- It serves a relatively limited number of clients with relatively long interactions.
- In order to have a historical view of knowledge, it requires current and historical data.
- Its application is read-intensive.
- It involves a few large tables.
"Data Warehouse is a subject-oriented, integrated, and time-variant store of information in support of management's decisions."
Types
Three main types of data warehouse are as follow:
- Enterprise Data Warehouse (EDW)
- Operational data store
- Data Mart
Characteristics of data warehouse
❏ Subject oriented
❏ Integrated
❏ Time variant
❏ Non volatile
Components of data warehouse
Four components of DW
- Load manger
- Warehouse manager
- Query manager
- End user access tool
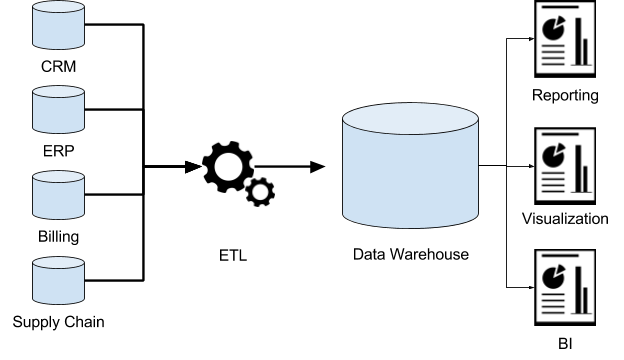
Fig 5: Data warehouse
Key takeaway:
- Data warehousing is a corporation or organization's electronic storage of a vast volume of information.
- A data warehouse is intended to conduct queries and analyses for business intelligence and data mining purposes on historical data obtained from transactional sources.
- By comparing data consolidated from several heterogeneous sources, data warehousing is used to provide greater insight into a company's results.
Data mining, in simple terms, is defined as a method used to extract useful data from a larger collection of raw data. It means analysing data patterns using one or more tools in large batches of data. In many areas, including science and analysis, data mining has applications.
As a data mining application, organisations can learn more about their clients and develop more efficient strategies related to different business functions and, in turn, exploit resources in a more optimal and informative way. This helps organisations get closer to their targets and make better choices. Successful data collection and warehousing as well as information processing include data mining.
Data mining uses advanced mathematical algorithms for segmenting the data and determining the likelihood of future events. Often known as Knowledge Exploration in Data Mining, data mining (KDD).
Main data mining features:
- Automatic forecasts of patterns based on study of trends and behaviours.
- Prediction on the basis of probable results.
- Creation of knowledge that is decision-oriented.
- Focus on broad data sets and research databases.
- Clustering centred on identifying groups of facts not previously recognised and visually registered.
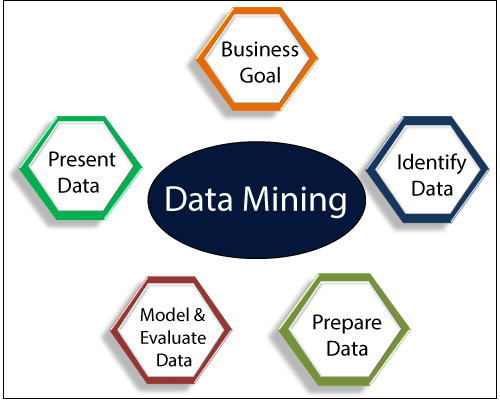
Fig 6: Data mining
Data mining technique:
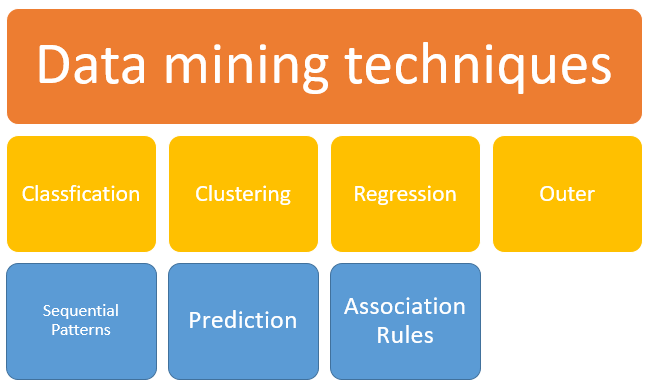
Fig 7: Data mining technique
● Classification: This research is used to gather information about data and metadata that is significant and relevant. This method of data mining helps to classify data into various groups.
● Clustering: Analysis of clustering is a technique of data mining to classify data that is like each other. The variations and similarities between the data help to explain this method.
● Regression: The data mining method of defining and evaluating the relationship between variables is regression analysis. It is used, given the existence of other variables, to classify the probability of a particular variable.
● Association rules: This method of data mining helps to find the connection between two or more objects. In the data set, it discovers a secret pattern.
● Outer prediction: This type of technique for data mining refers to the discovery of data items in the dataset that do not conform to an anticipated pattern or actions. In a number of domains, such as intrusion, tracking, fraud or fault detection, etc., this approach may be used. Outer identification is also referred to as Outlier Analysis or mining Outlier.
● Sequential patterns: For some times, this data mining technique helps to discover or recognise similar patterns or trends in transaction data.
● Prediction: A variation of other data mining strategies such as trends, temporal patterns, clustering, grouping, etc. has been used by Prediction. To predict a future occurrence, it analyses previous events or instances in the correct sequence.
Types of data mining
It is possible to conduct data mining on the following data types:
- Relational database
- Data warehouse
- Data repositories
- Object relational database
- Transactional database
Fig 8: Application of data mining
Key takeaway:
- The method of processing a large batch of information to discern trends and patterns is data mining.
- Corporations may use data mining for anything from knowing about what clients are interested in or want to purchase to detecting fraud and filtering spam.
- Based on what information users request or provide, data mining programmes break down trends and associations in data.
The term "database security" refers to a set of tools, policies, and procedures for ensuring and maintaining database confidentiality, integrity, and availability. Because confidentiality is the factor that is violated in the majority of data breaches, this article will concentrate on it.
The following must be addressed and protected by database security:
● The data in the database
● The database management system (DBMS)
● Any associated applications
● The physical database server and/or the virtual database server and the underlying hardware
● The computing and/or network infrastructure used to access the database
Database security is a complicated and difficult task that encompasses all areas of information security technology and procedures. It is also incompatible with database usability. The database becomes more exposed to security threats as it becomes more accessible and usable; the database becomes more invulnerable to attacks as it becomes more difficult to access and use.
Database security refers to the safeguarding of sensitive information and the prevention of data loss. The Database Administrator is in charge of the database's security (DBA).
Why is it important
A data breach is defined as a failure to keep the confidentiality of data in a database. The amount of damage a data breach causes your company is determined by a number of repercussions or factors:
● Compromised intellectual property: Your intellectual property—trade secrets, inventions, and private practices—could be crucial to maintaining a competitive advantage in your industry. If your intellectual property is stolen or revealed, it may be difficult or impossible to preserve or restore your competitive edge.
● Damage to brand reputation: Customers or partners may be hesitant to acquire your products or services (or do business with you) if they don't trust you to protect their or their data.
● Business continuity (or lack thereof): Some businesses are unable to continue operating until the breach has been fixed.
● Fines or penalties for non-compliance: Failure to comply with global regulations such as the Sarbanes-Oxley Act (SAO) or the Payment Card Industry Data Security Standard (PCI DSS), industry-specific data privacy regulations like HIPAA, or regional data privacy regulations like Europe's General Data Protection Regulation (GDPR) can have devastating financial consequences, with fines exceeding several million dollars per violation in the worst cases.
● Costs of repairing breaches and notifying customers: A violated organisation must spend for forensic and investigation efforts, crisis management, triage, system repair, and more, in addition to the cost of disclosing a breach to customers.
Common threats and challenges
Any database system must have data security as a top priority. Because of the enormous number of users, fragmented and replicated data, different sites, and dispersed control, it is especially important in distributed systems.
Threats in a Database
● Availability loss − The term "availability loss" refers to the inability of legitimate users to access database items.
● Integrity loss − When unacceptable activities are done on the database, either mistakenly or purposefully, integrity is lost. This can happen when you're putting data in, updating it, or deleting it. It leads to tainted data, which leads to erroneous decisions.
● Confidentiality loss − Unauthorized or inadvertent disclosure of confidential information causes confidentiality loss. It could lead to unlawful activities, security threats, and a loss of public trust.
Key takeaway
Database security is a complicated and difficult task that encompasses all areas of information security technology and procedures. It is also incompatible with database usability.
A NoSQL database, which stands for "non SQL" or "non relational," is a database that allows for data storage and retrieval. This information is represented in ways other than tabular relationships found in relational databases. Such databases first appeared in the late 1960s, but it wasn't until the early twenty-first century that they were given the name NoSQL. NoSQL databases are increasingly being employed in real-time online applications and large data analytics. Not only SQL is a term used to stress the fact that NoSQL systems may support SQL-like query languages.
Design simplicity, horizontal scaling to clusters of machines, and tighter control over availability are all advantages of a NoSQL database. The data structures used by NoSQL databases differ from those used by relational databases by default, which allows NoSQL to perform some operations faster. The applicability of a NoSQL database is determined by the problem it is supposed to answer. NoSQL databases' data structures are sometimes seen to be more flexible than relational database tables.
Many NoSQL databases make trade-offs between consistency and availability, performance, and partition tolerance. The usage of low-level query languages, a lack of standardized interfaces, and large prior investments in relational databases are all barriers to wider adoption of NoSQL storage. Although most NoSQL databases lack true ACID transactions (atomicity, consistency, isolation, and durability), a few databases, including MarkLogic, Aerospike, FairCom c-treeACE, Google Spanner (though technically a NewSQL database), Symas LMDB, and OrientDB, have made them a central part of their designs.
Most NoSQL databases support eventual consistency, which means that database updates are propagated to all nodes over time. As a result, queries for data may not return updated data right away, or may result in reading data that is inaccurate, a problem known as stale reads. Some NoSQL systems may also experience lost writes and other data loss. To avoid data loss, certain NoSQL systems offer features like write-ahead logging. Data consistency is even more difficult to achieve when doing distributed transaction processing across many databases. Both NoSQL and relational databases struggle with this.
Advantages
- It is possible to use it as a primary or analytic data source.
- Capacity for Big Data.
- There isn't a single point of failure.
- Replication is simple.
- There is no requirement for a separate caching layer.
- It offers quick performance as well as horizontal scalability.
- Can effectively handle structured, semi-structured, and unstructured data.
- Object-oriented programming is a type of programming that is simple to use and adaptable.
- A dedicated high-performance server isn't required for NoSQL databases.
- Key Developer Languages and Platforms are supported.
- RDBMS is more difficult to implement.
- It has the potential to be the key data source for web-based applications.
- Manages large data, including the velocity, diversity, volume, and complexity of data.
Disadvantages
● There are no norms for standardization.
● Querying capabilities are limited.
● Databases and tools for Relational Database Management Systems (RDBMS) are relatively established.
● It lacks standard database features such as consistency when several transactions are carried out at the same time.
● As the volume of data grows, it becomes more difficult to preserve unique values as keys become more difficult to remember.
● With relational data, it doesn't work as well.
● For novice developers, the learning curve is steep.
● For businesses, open source choices are less common.
Need
● When you need to store and retrieve a large volume of data.
● The relationship between the data you keep isn't as significant as you might think.
● The data is unstructured and changes over time.
● At the database level, support for constraints and joins is not necessary.
● The data is always growing, and you'll need to scale the database on a regular basis to keep up with it.
Features
Non - relational
● The relational model is never followed by NoSQL databases.
● Tables with flat fixed-column records should never be used.
● Work with BLOBs or self-contained aggregates.
● Object-relational mapping and data standardization are not required.
● There are no advanced features such as query languages, planners, referential integrity joins, or ACID.
Schema -free
● NoSQL databases are either schema-free or contain schemas that are more loose.
● There is no requirement for the data schema to be defined.
● Provides data structures that are heterogeneous within the same domain.
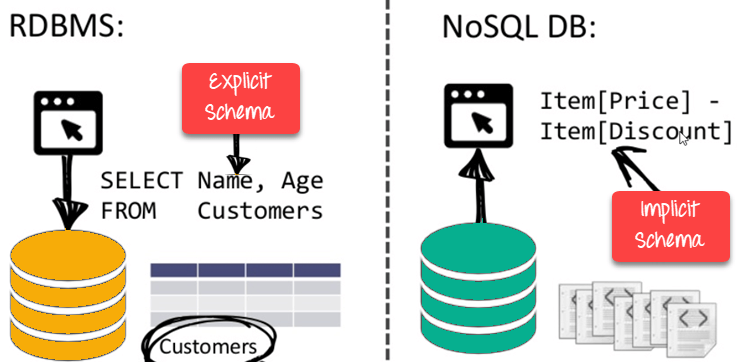
Fig 9: NoSQL is schema free
Simple API
● Provides simple user interfaces for storing and querying data.
● APIs make it possible to manipulate and choose data at a low level.
● HTTP REST with JSON is typically used with text-based protocols.
● The majority of queries were written in a NoSQL query language that was not based on any standard.
● Databases that are web-enabled and run as internet-facing services.
Distributed
● A distributed execution of many NoSQL databases is possible.
● Auto-scaling and fail-over capabilities are included.
● The ACID principle is frequently overlooked in favor of scalability and throughput.
● Asynchronous replication across remote nodes is almost non-existent. HDFS Replication, Asynchronous Multi-Master Replication, Peer-to-Peer.
● Only ensuring long-term consistency.
● Nothing is shared in the architecture. As a result, there is less coordination and more dispersal.
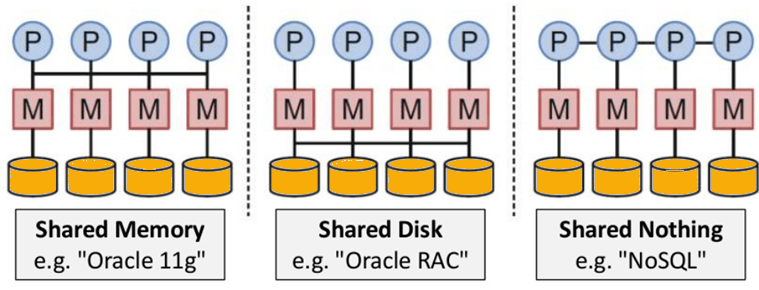
Fig 10: NoSQL is Shared Nothing
Key takeaway
- A NoSQL database, which stands for "non SQL" or "non relational," is a database that allows for data storage and retrieval.
- Many NoSQL databases make trade-offs between consistency and availability, performance, and partition tolerance.
- Most NoSQL databases support eventual consistency, which means that database updates are propagated to all nodes over time.
- NoSQL databases are increasingly being employed in real-time online applications and large data analytics.
- Not only SQL is a term used to stress the fact that NoSQL systems may support SQL-like query languages.
References:
- G. K. Gupta “Database Management Systems”, Tata McGraw Hill
- Rab P., Coronel C. “Database Systems Design, Implementation and Management”, 5th edition, Thomson Course Technology, 2002
- Elmasri R., Navathe S. “Fundamentals of Database Systems”, 4th edition, Pearson Education, 2003




