Unit - 4
Push Down Automata
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
Basically a pushdown automaton is -
“Finite state machine” + “a stack”
A pushdown automaton has three components −
● an input tape,
● a control unit, and
● a stack with infinite size.
The stack head scans the top symbol of the stack.
A stack does two operations −
● Push − a new symbol is added at the top.
● Pop − the top symbol is read and removed.
A PDA may or may not read an input symbol, but it has to read the top of the stack in every transition.
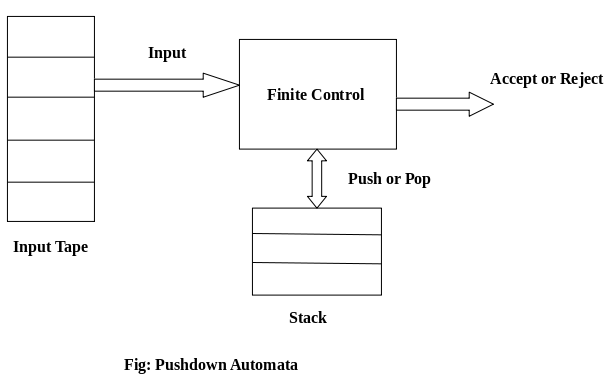
Fig1: Basic structure of PDA
A PDA can be formally described as a 7-tuple (Q, ∑, S, δ, q 0 , I, F) −
Where,
● Q is the finite number of states
● ∑ is input alphabet
● S is stack symbols
● δ is the transition function: Q × (∑ ∪ {ε}) × S × Q × S* )
● q 0 is the initial state (q 0 ∈ Q)
● I is the initial stack top symbol (I ∈ S)
● F is a set of accepting states (F ∈ Q)
The following diagram shows a transition in a PDA from a state q 1 to state q 2 , labeled as a,b → c −
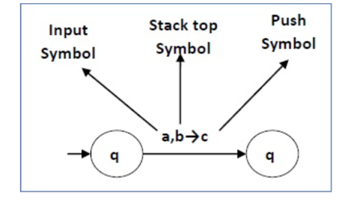
Fig 2: Example
This means at state q1, if we encounter an input string ‘a’ and the top symbol of the stack is ‘b’, then we pop ‘b’, push ‘c’ on top of the stack and move to state q2 .
Key takeaway
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Similarly, there are some CFGs which can be accepted only by NPDA and not by DPDA. Thus NPDA is more powerful than DPDA.
● Non-deterministic pushdown automata are quite similar to the NFA.
● Non-deterministic PDAs are also approved by the CFG that accepts deterministic PDAs.
● Similarly, there are several CFGs that only NPDA and not DPDA can consider. Therefore, NPDA is more efficient than DPDA.
● Non deterministic pushdown automata is basically a non finite automata (nfa) with a stack added to it.
Nondeterministic pushdown automaton or npda is a 7-tuple -
M = (Q, ∑, T, δ , q0, z, F)
Where
● Q is a finite set of states,
● ∑ is a the input alphabet,
● T is the stack alphabet,
● δ is a transition function,
● q0 ∈ Q is the initial state,
● z ∈ T is the stack start symbol, and
● F ⊆ Q is a set of final states.
Moves
The three groups of loop transitions in state q represent these respective functions:
● input a with no b’s on the stack: push a
● input b with no a’;s on the stack: push b
● input a with b’s on the stack: pop b; or, input b with a’s on the stack: pop a
For example if we have seen 5 b’s and 3 a’s in any order, then the stack should be “bbc”. The transition to the final state represents the only non-determinism in the PDA in that it must guess when the input is empty in order to pop off the stack bottom.
Example:
Design PDA for Palindrome strips.
Solution:
Suppose the language consists of string L = {aba, aa, bb, bab, bbabb, aabaa, ......].
The string can be odd palindrome or even palindrome. The logic for constructing PDA is that we will push a symbol onto the stack till half of the string then we will read each symbol and then perform the pop operation. We will compare to see whether the symbol which is popped is similar to the symbol which is read. Whether we reach the end of the input, we expect the stack to be empty.
This PDA is a non-deterministic PDA because finding the mid for the given string and reading the string from left and matching it with from right (reverse) direction leads to non-deterministic moves.
Here is the ID.
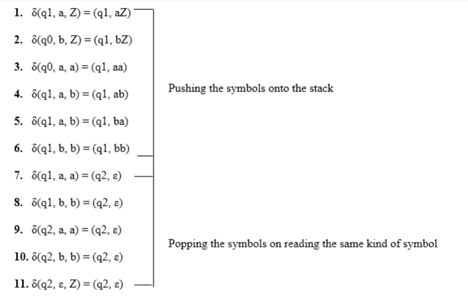
Simulation of abaaba
1. δ(q1, abaaba, Z) Apply rule 1
2. δ(q1, baaba, aZ) Apply rule 5
3. δ(q1, aaba, baZ) Apply rule 4
4. δ(q1, aba, abaZ) Apply rule 7
5. δ(q2, ba, baZ) Apply rule 8
6. δ(q2, a, aZ) Apply rule 7
7. δ(q2, ε, Z) Apply rule 11
8. δ(q2, ε) Accept
Key takeaway
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Acceptance by final state
When a PDA accepts a string in final state acceptability, the PDA is in a final state after reading the full string. We can make moves from the starting state to a final state with any stack values. As long as we end up in a final state, the stack values don't matter.
If the PDA enters any final state in zero or more moves after receiving the complete input, it is said to accept it by the final state.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by the final state can be defined as:
L(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ F}
Equivalence of Acceptance by Final State and Empty Stack
There is a PDA P2 such that L = L (P2) if L = N(P1) for some PDA P1. That is, the language supported by the empty stack PDA will be supported by the end state PDA as well.
If a language L = L (P1) exists for a PDA P1, then L = N (P2) exists for a PDA P2. That is, language supported by the end state PDA is also supported by the empty stack PDA.
Acceptance by empty stack
The stack of PDAs becomes empty after reading the input string from the initial setup for some PDA.
When a PDA has exhausted its stack after reading the entire string, it accepts a string.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by empty stack can be defined as:
N(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ Q}
Example
Construct a PDA that accepts L = {0n 1n | n ≥ 0}
Solution:
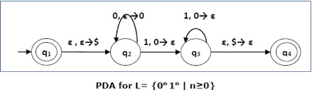
This language accepts L = {ε, 01, 0011, 000111, ............................. }
The number of ‘a' and ‘b' in this example must be the same.
● We began by inserting the special symbol ‘$' into the empty stack.
● If we encounter input 0 and top is Null at state q2, we push 0 into the stack. It's possible that this will happen again. We pop this 0 if we meet input 1 and top is 0.
● If we encounter input 1 at state q3 and the top is 0, we pop this 0. It's possible that this will continue to iterate. We pop the top element if we meet input 1 and top is 0.
● If the special symbol '$' appears at the top of the stack, it is popped out, and the stack eventually moves to the accepting state q4.
We can design a similar nondeterministic PDA that accepts the language produced by the context-free grammar G if it is context-free. For the grammar G, a parser can be created.
In addition, if P is a pushdown automaton, an analogous context-free grammar G can be built.
L(G) = L(P)
Algorithm to find PDA corresponding to a given CFG
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F)
Step1 - Convert the CFG's productions into GNF.
Step2 - There will be only one state q on the PDA.
Step3 - The CFG's start symbol will be the PDA's start sign.
Step4 - The PDA's stack symbols will be all of the CFG's non-terminals, and the PDA's input symbols will be all of the CFG's terminals.
Step5 - For each production in the form A → aX where a is terminal and A, X are a combination of terminal and non-terminals, make a transition δ (q, a, A).
Problem
Construct a PDA using the CFG below.
G = ({S, X}, {a, b}, P, S)
Where are the productions?
S → XS | ε , A → aXb | Ab | ab
Solution
Let's say you have a PDA that's equivalent to that.
P = ({q}, {a, b}, {a, b, X, S}, δ, q, S)
Where δ −
δ(q, ε , S) = {(q, XS), (q, ε )}
δ(q, ε , X) = {(q, aXb), (q, Xb), (q, ab)}
δ(q, a, a) = {(q, ε )}
δ(q, 1, 1) = {(q, ε )}
Algorithm to find CFG corresponding to a given PDA
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F) such that the non- terminals of the grammar G will be {Xwx | w,x ∈ Q} and the start state will be Aq0,F.
Step1 − For every w, x, y, z ∈ Q, m ∈ S and a, b ∈ ∑, if δ (w, a, ε) contains (y, m) and (z, b, m) contains (x, ε), add the production rule Xwx → a Xyzb in grammar G.
Step2 − For every w, x, y, z ∈ Q, add the production rule Xwx → XwyXyx in grammar G.
Step3 − For w ∈ Q, add the production rule Xww → ε in grammar G.
They are closed under −
● Union
● Concatenation
● Kleene Star operation
Union of the languages A1 and A2 , A = A1 A2 = { anbncmdm }
The additional development would have the corresponding grammar G, P: S → S1 S2
Union
Let A1 and A2 be two context free languages. Then A1 ∪ A2 is also context free.
Example
Let A1 = { xn yn , n ≥ 0}. Corresponding grammar G 1 will have P: S1 → aAb|ab
Let A2 = { cm dm , m ≥ 0}. Corresponding grammar G 2 will have P: S2 → cBb| ε
Union of A1 and A2 , A = A1 ∪ A2 = { xn yn } ∪ { cm dm }
The corresponding grammar G will have the additional production S → S1 | S2
Note - So under Union, CFLs are closed.
Concatenation
If A1 and A2 are context free languages, then A1 A2 is also context free.
Example
Union of the languages A 1 and A 2 , A = A 1 A 2 = { an bn cm dm }
The corresponding grammar G will have the additional production S → S1 S2
Note - So under Concatenation, CFL are locked.
Kleene Star
If A is a context free language, so that A* is context free as well .
Example
Let A = { xn yn , n ≥ 0}. G will have corresponding grammar P: S → aAb| ε
Kleene Star L 1 = { xn yn }*
The corresponding grammar G 1 will have additional productions S1 → SS 1 | ε
Note - So under Kleene Closure, CFL's are closed.
Context-free languages are not closed under −
● Intersection − If A1 and A2 are context free languages, then A1 ∩ A2 is not necessarily context free.
● Intersection with Regular Language − If A1 is a regular language and A2 is a context free language, then A1 ∩ A2 is a context free language.
● Complement − If A1 is a context free language, then A1’ may not be context free.
Decision property of CFL
● It is possible to determine whether or not a CFG G is empty.
● The following questions are undecidable?
● Testing the membership of a string w in a CFG G is also decidable.
1. Is there any ambiguity in a particular G?
2. Is a CFL by definition ambiguous?
3. Is the point where two CFLs meet empty?
4. Is there a difference between two CFLs?
References:
- John E. Hopcroft, Rajeev Motwani and Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- Introduction to Automata theory, Languages and Computation, J.E.Hopcraft, R.Motwani, and Ullman. 2nd edition, Pearson Education Asia
- Introduction to languages and the theory of computation, J Martin, 3rd Edition, Tata McGraw Hill
Unit - 4
Push Down Automata
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
Basically a pushdown automaton is -
“Finite state machine” + “a stack”
A pushdown automaton has three components −
● an input tape,
● a control unit, and
● a stack with infinite size.
The stack head scans the top symbol of the stack.
A stack does two operations −
● Push − a new symbol is added at the top.
● Pop − the top symbol is read and removed.
A PDA may or may not read an input symbol, but it has to read the top of the stack in every transition.
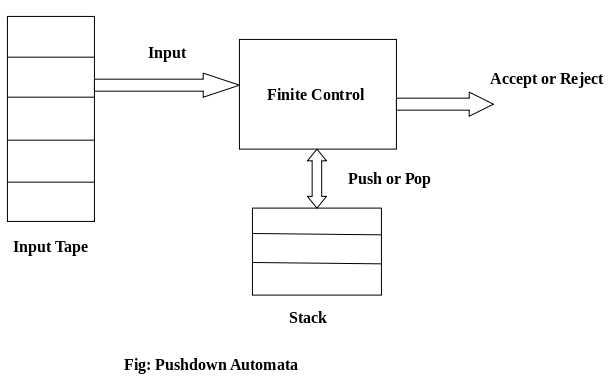
Fig1: Basic structure of PDA
A PDA can be formally described as a 7-tuple (Q, ∑, S, δ, q 0 , I, F) −
Where,
● Q is the finite number of states
● ∑ is input alphabet
● S is stack symbols
● δ is the transition function: Q × (∑ ∪ {ε}) × S × Q × S* )
● q 0 is the initial state (q 0 ∈ Q)
● I is the initial stack top symbol (I ∈ S)
● F is a set of accepting states (F ∈ Q)
The following diagram shows a transition in a PDA from a state q 1 to state q 2 , labeled as a,b → c −
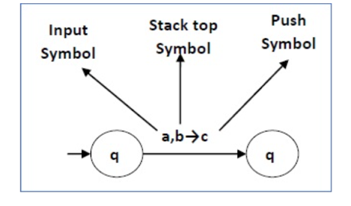
Fig 2: Example
This means at state q1, if we encounter an input string ‘a’ and the top symbol of the stack is ‘b’, then we pop ‘b’, push ‘c’ on top of the stack and move to state q2 .
Key takeaway
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Similarly, there are some CFGs which can be accepted only by NPDA and not by DPDA. Thus NPDA is more powerful than DPDA.
● Non-deterministic pushdown automata are quite similar to the NFA.
● Non-deterministic PDAs are also approved by the CFG that accepts deterministic PDAs.
● Similarly, there are several CFGs that only NPDA and not DPDA can consider. Therefore, NPDA is more efficient than DPDA.
● Non deterministic pushdown automata is basically a non finite automata (nfa) with a stack added to it.
Nondeterministic pushdown automaton or npda is a 7-tuple -
M = (Q, ∑, T, δ , q0, z, F)
Where
● Q is a finite set of states,
● ∑ is a the input alphabet,
● T is the stack alphabet,
● δ is a transition function,
● q0 ∈ Q is the initial state,
● z ∈ T is the stack start symbol, and
● F ⊆ Q is a set of final states.
Moves
The three groups of loop transitions in state q represent these respective functions:
● input a with no b’s on the stack: push a
● input b with no a’;s on the stack: push b
● input a with b’s on the stack: pop b; or, input b with a’s on the stack: pop a
For example if we have seen 5 b’s and 3 a’s in any order, then the stack should be “bbc”. The transition to the final state represents the only non-determinism in the PDA in that it must guess when the input is empty in order to pop off the stack bottom.
Example:
Design PDA for Palindrome strips.
Solution:
Suppose the language consists of string L = {aba, aa, bb, bab, bbabb, aabaa, ......].
The string can be odd palindrome or even palindrome. The logic for constructing PDA is that we will push a symbol onto the stack till half of the string then we will read each symbol and then perform the pop operation. We will compare to see whether the symbol which is popped is similar to the symbol which is read. Whether we reach the end of the input, we expect the stack to be empty.
This PDA is a non-deterministic PDA because finding the mid for the given string and reading the string from left and matching it with from right (reverse) direction leads to non-deterministic moves.
Here is the ID.
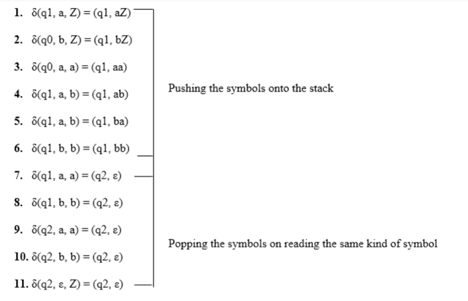
Simulation of abaaba
1. δ(q1, abaaba, Z) Apply rule 1
2. δ(q1, baaba, aZ) Apply rule 5
3. δ(q1, aaba, baZ) Apply rule 4
4. δ(q1, aba, abaZ) Apply rule 7
5. δ(q2, ba, baZ) Apply rule 8
6. δ(q2, a, aZ) Apply rule 7
7. δ(q2, ε, Z) Apply rule 11
8. δ(q2, ε) Accept
Key takeaway
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Acceptance by final state
When a PDA accepts a string in final state acceptability, the PDA is in a final state after reading the full string. We can make moves from the starting state to a final state with any stack values. As long as we end up in a final state, the stack values don't matter.
If the PDA enters any final state in zero or more moves after receiving the complete input, it is said to accept it by the final state.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by the final state can be defined as:
L(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ F}
Equivalence of Acceptance by Final State and Empty Stack
There is a PDA P2 such that L = L (P2) if L = N(P1) for some PDA P1. That is, the language supported by the empty stack PDA will be supported by the end state PDA as well.
If a language L = L (P1) exists for a PDA P1, then L = N (P2) exists for a PDA P2. That is, language supported by the end state PDA is also supported by the empty stack PDA.
Acceptance by empty stack
The stack of PDAs becomes empty after reading the input string from the initial setup for some PDA.
When a PDA has exhausted its stack after reading the entire string, it accepts a string.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by empty stack can be defined as:
N(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ Q}
Example
Construct a PDA that accepts L = {0n 1n | n ≥ 0}
Solution:
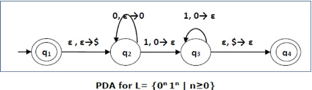
This language accepts L = {ε, 01, 0011, 000111, ............................. }
The number of ‘a' and ‘b' in this example must be the same.
● We began by inserting the special symbol ‘$' into the empty stack.
● If we encounter input 0 and top is Null at state q2, we push 0 into the stack. It's possible that this will happen again. We pop this 0 if we meet input 1 and top is 0.
● If we encounter input 1 at state q3 and the top is 0, we pop this 0. It's possible that this will continue to iterate. We pop the top element if we meet input 1 and top is 0.
● If the special symbol '$' appears at the top of the stack, it is popped out, and the stack eventually moves to the accepting state q4.
We can design a similar nondeterministic PDA that accepts the language produced by the context-free grammar G if it is context-free. For the grammar G, a parser can be created.
In addition, if P is a pushdown automaton, an analogous context-free grammar G can be built.
L(G) = L(P)
Algorithm to find PDA corresponding to a given CFG
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F)
Step1 - Convert the CFG's productions into GNF.
Step2 - There will be only one state q on the PDA.
Step3 - The CFG's start symbol will be the PDA's start sign.
Step4 - The PDA's stack symbols will be all of the CFG's non-terminals, and the PDA's input symbols will be all of the CFG's terminals.
Step5 - For each production in the form A → aX where a is terminal and A, X are a combination of terminal and non-terminals, make a transition δ (q, a, A).
Problem
Construct a PDA using the CFG below.
G = ({S, X}, {a, b}, P, S)
Where are the productions?
S → XS | ε , A → aXb | Ab | ab
Solution
Let's say you have a PDA that's equivalent to that.
P = ({q}, {a, b}, {a, b, X, S}, δ, q, S)
Where δ −
δ(q, ε , S) = {(q, XS), (q, ε )}
δ(q, ε , X) = {(q, aXb), (q, Xb), (q, ab)}
δ(q, a, a) = {(q, ε )}
δ(q, 1, 1) = {(q, ε )}
Algorithm to find CFG corresponding to a given PDA
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F) such that the non- terminals of the grammar G will be {Xwx | w,x ∈ Q} and the start state will be Aq0,F.
Step1 − For every w, x, y, z ∈ Q, m ∈ S and a, b ∈ ∑, if δ (w, a, ε) contains (y, m) and (z, b, m) contains (x, ε), add the production rule Xwx → a Xyzb in grammar G.
Step2 − For every w, x, y, z ∈ Q, add the production rule Xwx → XwyXyx in grammar G.
Step3 − For w ∈ Q, add the production rule Xww → ε in grammar G.
They are closed under −
● Union
● Concatenation
● Kleene Star operation
Union of the languages A1 and A2 , A = A1 A2 = { anbncmdm }
The additional development would have the corresponding grammar G, P: S → S1 S2
Union
Let A1 and A2 be two context free languages. Then A1 ∪ A2 is also context free.
Example
Let A1 = { xn yn , n ≥ 0}. Corresponding grammar G 1 will have P: S1 → aAb|ab
Let A2 = { cm dm , m ≥ 0}. Corresponding grammar G 2 will have P: S2 → cBb| ε
Union of A1 and A2 , A = A1 ∪ A2 = { xn yn } ∪ { cm dm }
The corresponding grammar G will have the additional production S → S1 | S2
Note - So under Union, CFLs are closed.
Concatenation
If A1 and A2 are context free languages, then A1 A2 is also context free.
Example
Union of the languages A 1 and A 2 , A = A 1 A 2 = { an bn cm dm }
The corresponding grammar G will have the additional production S → S1 S2
Note - So under Concatenation, CFL are locked.
Kleene Star
If A is a context free language, so that A* is context free as well .
Example
Let A = { xn yn , n ≥ 0}. G will have corresponding grammar P: S → aAb| ε
Kleene Star L 1 = { xn yn }*
The corresponding grammar G 1 will have additional productions S1 → SS 1 | ε
Note - So under Kleene Closure, CFL's are closed.
Context-free languages are not closed under −
● Intersection − If A1 and A2 are context free languages, then A1 ∩ A2 is not necessarily context free.
● Intersection with Regular Language − If A1 is a regular language and A2 is a context free language, then A1 ∩ A2 is a context free language.
● Complement − If A1 is a context free language, then A1’ may not be context free.
Decision property of CFL
● It is possible to determine whether or not a CFG G is empty.
● The following questions are undecidable?
● Testing the membership of a string w in a CFG G is also decidable.
1. Is there any ambiguity in a particular G?
2. Is a CFL by definition ambiguous?
3. Is the point where two CFLs meet empty?
4. Is there a difference between two CFLs?
References:
- John E. Hopcroft, Rajeev Motwani and Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- Introduction to Automata theory, Languages and Computation, J.E.Hopcraft, R.Motwani, and Ullman. 2nd edition, Pearson Education Asia
- Introduction to languages and the theory of computation, J Martin, 3rd Edition, Tata McGraw Hill
Unit - 4
Push Down Automata
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
Basically a pushdown automaton is -
“Finite state machine” + “a stack”
A pushdown automaton has three components −
● an input tape,
● a control unit, and
● a stack with infinite size.
The stack head scans the top symbol of the stack.
A stack does two operations −
● Push − a new symbol is added at the top.
● Pop − the top symbol is read and removed.
A PDA may or may not read an input symbol, but it has to read the top of the stack in every transition.
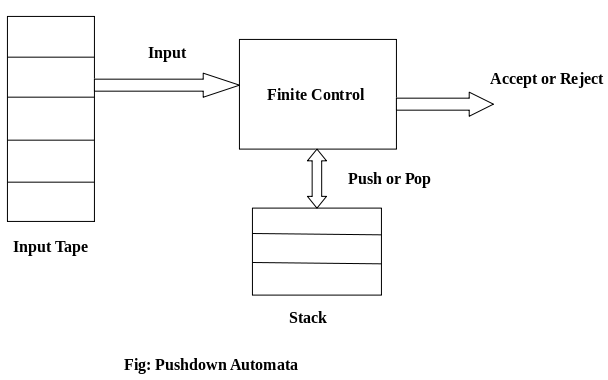
Fig1: Basic structure of PDA
A PDA can be formally described as a 7-tuple (Q, ∑, S, δ, q 0 , I, F) −
Where,
● Q is the finite number of states
● ∑ is input alphabet
● S is stack symbols
● δ is the transition function: Q × (∑ ∪ {ε}) × S × Q × S* )
● q 0 is the initial state (q 0 ∈ Q)
● I is the initial stack top symbol (I ∈ S)
● F is a set of accepting states (F ∈ Q)
The following diagram shows a transition in a PDA from a state q 1 to state q 2 , labeled as a,b → c −
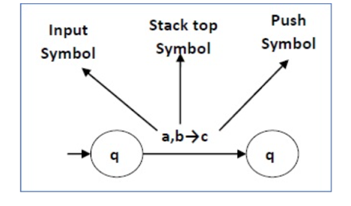
Fig 2: Example
This means at state q1, if we encounter an input string ‘a’ and the top symbol of the stack is ‘b’, then we pop ‘b’, push ‘c’ on top of the stack and move to state q2 .
Key takeaway
It is a way to implement a context-free grammar as we design DFA for a regular grammar. A DFA can remember a finite amount of information, but a PDA can remember an infinite amount of information.
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Similarly, there are some CFGs which can be accepted only by NPDA and not by DPDA. Thus NPDA is more powerful than DPDA.
● Non-deterministic pushdown automata are quite similar to the NFA.
● Non-deterministic PDAs are also approved by the CFG that accepts deterministic PDAs.
● Similarly, there are several CFGs that only NPDA and not DPDA can consider. Therefore, NPDA is more efficient than DPDA.
● Non deterministic pushdown automata is basically a non finite automata (nfa) with a stack added to it.
Nondeterministic pushdown automaton or npda is a 7-tuple -
M = (Q, ∑, T, δ , q0, z, F)
Where
● Q is a finite set of states,
● ∑ is a the input alphabet,
● T is the stack alphabet,
● δ is a transition function,
● q0 ∈ Q is the initial state,
● z ∈ T is the stack start symbol, and
● F ⊆ Q is a set of final states.
Moves
The three groups of loop transitions in state q represent these respective functions:
● input a with no b’s on the stack: push a
● input b with no a’;s on the stack: push b
● input a with b’s on the stack: pop b; or, input b with a’s on the stack: pop a
For example if we have seen 5 b’s and 3 a’s in any order, then the stack should be “bbc”. The transition to the final state represents the only non-determinism in the PDA in that it must guess when the input is empty in order to pop off the stack bottom.
Example:
Design PDA for Palindrome strips.
Solution:
Suppose the language consists of string L = {aba, aa, bb, bab, bbabb, aabaa, ......].
The string can be odd palindrome or even palindrome. The logic for constructing PDA is that we will push a symbol onto the stack till half of the string then we will read each symbol and then perform the pop operation. We will compare to see whether the symbol which is popped is similar to the symbol which is read. Whether we reach the end of the input, we expect the stack to be empty.
This PDA is a non-deterministic PDA because finding the mid for the given string and reading the string from left and matching it with from right (reverse) direction leads to non-deterministic moves.
Here is the ID.
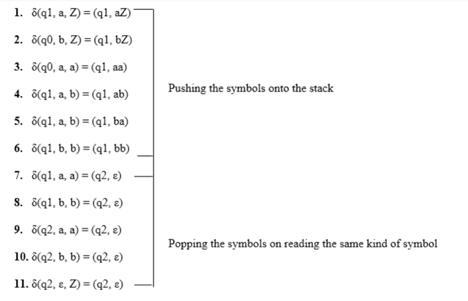
Simulation of abaaba
1. δ(q1, abaaba, Z) Apply rule 1
2. δ(q1, baaba, aZ) Apply rule 5
3. δ(q1, aaba, baZ) Apply rule 4
4. δ(q1, aba, abaZ) Apply rule 7
5. δ(q2, ba, baZ) Apply rule 8
6. δ(q2, a, aZ) Apply rule 7
7. δ(q2, ε, Z) Apply rule 11
8. δ(q2, ε) Accept
Key takeaway
The non-deterministic pushdown automata is very much similar to NFA. We will discuss some CFGs which accept NPDA.
The CFG which accepts deterministic PDA accepts non-deterministic PDAs as well.
Acceptance by final state
When a PDA accepts a string in final state acceptability, the PDA is in a final state after reading the full string. We can make moves from the starting state to a final state with any stack values. As long as we end up in a final state, the stack values don't matter.
If the PDA enters any final state in zero or more moves after receiving the complete input, it is said to accept it by the final state.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by the final state can be defined as:
L(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ F}
Equivalence of Acceptance by Final State and Empty Stack
There is a PDA P2 such that L = L (P2) if L = N(P1) for some PDA P1. That is, the language supported by the empty stack PDA will be supported by the end state PDA as well.
If a language L = L (P1) exists for a PDA P1, then L = N (P2) exists for a PDA P2. That is, language supported by the end state PDA is also supported by the empty stack PDA.
Acceptance by empty stack
The stack of PDAs becomes empty after reading the input string from the initial setup for some PDA.
When a PDA has exhausted its stack after reading the entire string, it accepts a string.
Let P =(Q, ∑, Γ, δ, q0, Z, F) be a PDA. The language acceptable by empty stack can be defined as:
N(PDA) = {w | (q0, w, Z) ⊢* (p, ε, ε), q ∈ Q}
Example
Construct a PDA that accepts L = {0n 1n | n ≥ 0}
Solution:
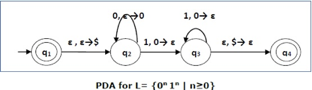
This language accepts L = {ε, 01, 0011, 000111, ............................. }
The number of ‘a' and ‘b' in this example must be the same.
● We began by inserting the special symbol ‘$' into the empty stack.
● If we encounter input 0 and top is Null at state q2, we push 0 into the stack. It's possible that this will happen again. We pop this 0 if we meet input 1 and top is 0.
● If we encounter input 1 at state q3 and the top is 0, we pop this 0. It's possible that this will continue to iterate. We pop the top element if we meet input 1 and top is 0.
● If the special symbol '$' appears at the top of the stack, it is popped out, and the stack eventually moves to the accepting state q4.
We can design a similar nondeterministic PDA that accepts the language produced by the context-free grammar G if it is context-free. For the grammar G, a parser can be created.
In addition, if P is a pushdown automaton, an analogous context-free grammar G can be built.
L(G) = L(P)
Algorithm to find PDA corresponding to a given CFG
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F)
Step1 - Convert the CFG's productions into GNF.
Step2 - There will be only one state q on the PDA.
Step3 - The CFG's start symbol will be the PDA's start sign.
Step4 - The PDA's stack symbols will be all of the CFG's non-terminals, and the PDA's input symbols will be all of the CFG's terminals.
Step5 - For each production in the form A → aX where a is terminal and A, X are a combination of terminal and non-terminals, make a transition δ (q, a, A).
Problem
Construct a PDA using the CFG below.
G = ({S, X}, {a, b}, P, S)
Where are the productions?
S → XS | ε , A → aXb | Ab | ab
Solution
Let's say you have a PDA that's equivalent to that.
P = ({q}, {a, b}, {a, b, X, S}, δ, q, S)
Where δ −
δ(q, ε , S) = {(q, XS), (q, ε )}
δ(q, ε , X) = {(q, aXb), (q, Xb), (q, ab)}
δ(q, a, a) = {(q, ε )}
δ(q, 1, 1) = {(q, ε )}
Algorithm to find CFG corresponding to a given PDA
Input − A CFG, G = (V, T, P, S)
Output − Equivalent PDA, P = (Q, ∑, S, δ, q0, I, F) such that the non- terminals of the grammar G will be {Xwx | w,x ∈ Q} and the start state will be Aq0,F.
Step1 − For every w, x, y, z ∈ Q, m ∈ S and a, b ∈ ∑, if δ (w, a, ε) contains (y, m) and (z, b, m) contains (x, ε), add the production rule Xwx → a Xyzb in grammar G.
Step2 − For every w, x, y, z ∈ Q, add the production rule Xwx → XwyXyx in grammar G.
Step3 − For w ∈ Q, add the production rule Xww → ε in grammar G.
They are closed under −
● Union
● Concatenation
● Kleene Star operation
Union of the languages A1 and A2 , A = A1 A2 = { anbncmdm }
The additional development would have the corresponding grammar G, P: S → S1 S2
Union
Let A1 and A2 be two context free languages. Then A1 ∪ A2 is also context free.
Example
Let A1 = { xn yn , n ≥ 0}. Corresponding grammar G 1 will have P: S1 → aAb|ab
Let A2 = { cm dm , m ≥ 0}. Corresponding grammar G 2 will have P: S2 → cBb| ε
Union of A1 and A2 , A = A1 ∪ A2 = { xn yn } ∪ { cm dm }
The corresponding grammar G will have the additional production S → S1 | S2
Note - So under Union, CFLs are closed.
Concatenation
If A1 and A2 are context free languages, then A1 A2 is also context free.
Example
Union of the languages A 1 and A 2 , A = A 1 A 2 = { an bn cm dm }
The corresponding grammar G will have the additional production S → S1 S2
Note - So under Concatenation, CFL are locked.
Kleene Star
If A is a context free language, so that A* is context free as well .
Example
Let A = { xn yn , n ≥ 0}. G will have corresponding grammar P: S → aAb| ε
Kleene Star L 1 = { xn yn }*
The corresponding grammar G 1 will have additional productions S1 → SS 1 | ε
Note - So under Kleene Closure, CFL's are closed.
Context-free languages are not closed under −
● Intersection − If A1 and A2 are context free languages, then A1 ∩ A2 is not necessarily context free.
● Intersection with Regular Language − If A1 is a regular language and A2 is a context free language, then A1 ∩ A2 is a context free language.
● Complement − If A1 is a context free language, then A1’ may not be context free.
Decision property of CFL
● It is possible to determine whether or not a CFG G is empty.
● The following questions are undecidable?
● Testing the membership of a string w in a CFG G is also decidable.
1. Is there any ambiguity in a particular G?
2. Is a CFL by definition ambiguous?
3. Is the point where two CFLs meet empty?
4. Is there a difference between two CFLs?
References:
- John E. Hopcroft, Rajeev Motwani and Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- Introduction to Automata theory, Languages and Computation, J.E.Hopcraft, R.Motwani, and Ullman. 2nd edition, Pearson Education Asia
- Introduction to languages and the theory of computation, J Martin, 3rd Edition, Tata McGraw Hill




