Unit - 5
Learning
Changes in the system that allow it to perform the same task more efficiently the next time around. Learning is the process of creating or changing representations of what one is experiencing. Learning causes beneficial mental changes. Learning enhances comprehension and productivity.
Find out about new objects or structures that you didn't know about before (data mining, scientific discovery). Fill in any observations or requirements regarding a domain that are skeletal or incomplete (this expands the domain of expertise and lessens the brittleness of the system). Create software agents that can learn from their users and other software agents. Replicate a key feature of intelligent behavior.
Arthur Samuel, an American pioneer in the fields of computer games and artificial intelligence, invented the phrase Machine Learning in 1959, stating that "it offers computers the ability to learn without being expressly taught."
"A computer programme is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, increases with experience E," Tom Mitchell wrote in 1997.
At a high-level, machine learning is simply the study of teaching a computer programme or algorithm how to gradually improve upon a set task that it is given. On the research-side of things, machine learning can be seen through the prism of theoretical and mathematical simulation of how this method works. However, more technically it is the study of how to construct applications that exhibit this iterative progress.
Machine Learning is an Application of Artificial Intelligence (AI) that gives machines the opportunity to learn from their experiences and develop themselves without doing any coding.
Machine Learning is a branch of Artificial Intelligence. Machine Learning is the study of making machines more human-like in their actions and decisions by allowing them the ability to learn and create their own programmes. This is achieved with minimal human interference, i.e., no explicit programming. The learning process is automated and enhanced based on the experiences of the machines in the process.
In the real world, we are surrounded by individuals who can learn anything from their experiences thanks to their ability to learn, and we have computers or machines that follow our commands. But, like a human, can a machine learn from past experiences or data? So here's where Machine Learning comes in.
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms that allow a computer to learn on its own from data and previous experiences. Arthur Samuel was the first to coin the term "machine learning" in 1959. In a nutshell, we can characterize it as follows:
“Machine learning enables a machine to automatically learn from data, improve performance from experiences, and predict things without being explicitly programmed.”
Machine learning algorithms create a mathematical model with the help of sample historical data, referred to as training data, that aids in making predictions or judgments without being explicitly programmed. In order to create predictive models, machine learning combines computer science and statistics. Machine learning is the process of creating or employing algorithms that learn from past data. The more information we supply, the better our performance will be.
If a system can enhance its performance by gaining new data, it has the potential to learn.
Steps
There are Seven Steps of Machine Learning
- Gathering Data
- Preparing that data
- Choosing a model
- Training
- Evaluation
- Hyperparameter Tuning
- Prediction
Features of ML
● Data is used by machine learning to find distinct patterns in a dataset.
● It can learn from previous data and improve on its own.
● It is a technology that is based on data.
● Data mining and machine learning are very similar in that they both deal with large amounts of data.
Key takeaway:
Machine Learning is an Application of Artificial Intelligence (AI) that gives machines the opportunity to learn from their experiences and develop themselves without doing any coding.
On the research-side of things, machine learning can be seen through the prism of theoretical and mathematical simulation of how this method works.
Learning is a process, whereas knowledge is the result, consequence, output, or effect of learning through experience, study, education, or training data.
"The process of obtaining new understanding, knowledge, behaviors, abilities, beliefs, attitudes, and preferences is known as learning."
Learning is a system/method/algorithm through which you acquire information from your parents, a peer, a street, a school or college or an institution, a book, or the internet. So learning is the process of acquiring skill or knowledge by trial and error in life or through study, observation, instruction, and other means.
Facts, information, data, truths, principles, beliefs, and harmful behaviors are all learned.
What we learn and learn to know is what we know.
Scientific activities such as theoretical, experimental, computational, or data analytic activities drive human and machine knowledge and learning. Science is the sum total of all known facts about reality, people, and technology. And only at the transdisciplinary level, where all barriers between and within knowledge areas and technical domains are transgressed by holistic, systematic, and transdisciplinary learning and knowledge, as shown above, could real-world learning and knowledge be achieved.
Once again, human knowledge is highly specialized and fragmented into small disciplines and fields, impeding our ability to address global change issues like as climate change, pandemics, and other planetary hazards and threats.
There is only one type of causal learning. However, in behavioristic psychology, learning is classified as either passive or active, non-associative, associative, or active (the process by which a person or animal or machine learns an association between two stimuli or events). Informal and formal education, e-learning, meaningful or rote learning, interactive or accidental or episodic learning, enculturation, and socialization are all factors to consider.
Learning, according to the ML/DL philosophy, is a change in behavior brought about by interacting with the environment in order to establish new patterns of reactions to stimuli/inputs, whether internal or external, conscious or subconscious, voluntary or involuntary.
All that a humanity, society, mind, or machine understands has been learned through experience or education. Intuition and experience, information and comprehension, values, attitudes and views, awareness and familiarity are all part of knowledge. Human minds, unlike robots, are capable of one-short learning, transfer learning, and relearning.
Learned behaviors could be demonstrated by humans, animals, plants, and machines.
When the program does not learn from advice, it can learn by generalizing from its own experiences.
● Learning by parameter adjustment
● Learning with macro-operators
● Learning by chunking
● The unity problem
Learning by parameter adjustment
● The learning system in this example uses an evaluation technique that combines data from various sources into a single static summary.
● For example, demand and production capacity might be combined into a single score to indicate the likelihood of increased output.
● However, defining how much weight each component should be given a priori is difficult.
● By guessing the correct settings and then letting the computer modify them based on its experience, the correct weight can be discovered.
● Features that appear to be strong indicators of overall performance will have their weights increased, while those that do not will have their weights reduced.
● This type of learning strategy is useful when there is a shortage of knowledge.
● In game programming, for example, factors such as piece advantage and mobility are combined into a single score to assess whether a particular board position is desired. This single score is nothing more than data that the algorithm has gathered through calculation.
● This is accomplished via programs' static evaluation functions, which combine several elements into a single score. This function's polynomial form is as follows:
● The t words represent the values of the traits that contribute to the evaluation. The c terms are the coefficients or weights that are allocated to each of these values.
● When it comes to creating programs, deciding on the right value to give each weight might be tricky. As a result, the most important rule in parameter adjustment is to:
● Begin by making an educated guess at the appropriate weight values.
● Adjust the program's weight based on your previous experience.
● Traits that appear to be good forecasters will have their weights increased, while features that look to be bad predictions will have their weights reduced.
● The following are significant factors that affect performance:
● When should the value of a coefficient be increased and when should it be decreased?
● The coefficients of good predictors should be increased, while the coefficients of undesirable predictors should be reduced.
● The difficulty of properly assigning blame to each of the phases that led to a single outcome is referred to as the credit assignment system.
● How much should the price change?
● Hill climbing is a type of learning technique.
● This strategy is particularly beneficial in situations when new knowledge is scarce or in programs where it is used in conjunction with more knowledge-intensive strategies.
Learning with Macro-Operators
● Macro-operators are collections of actions that can be handled together.
● The learning component saves the computed plan as a macro-operator once a problem is solved.
● The preconditions are the initial conditions of the just-solved problem, while the postconditions are the problem's outcomes.
● The problem solver makes good use of prior experience-based knowledge.
● By generalizing macro-operations, the issue solver can even tackle other challenges. To achieve generality, all constants in the macro-operators are substituted with variables.
● Despite the fact that the macro operator's multiple operators cause countless undesirable local changes, it can have a minimal global influence.
● Macro operators can help us develop domain-specific knowledge.
Learning by Chunking
● It's similar to chunking to learn with macro-operators. Problem-solving systems that use production systems are most likely to use it.
● A series of rules in the form of if-then statements makes up a production system. That is, what actions should be made in a specific situation. Bring an umbrella if it's raining, for example.
● Problem solvers employ rules to solve difficulties. Some of these rules may be more valuable than others, and the results are grouped together.
● Chunking can be used to gain a general understanding of search control.
● Chunks learned at the start of the problem-solving process can be employed at a later stage. The chunk is saved by the system to be used in future challenges.
The utility problem
● When knowledge is acquired in the hopes of improving a system's performance, it actually causes harm. In learning systems, this is referred to as the utility problem.
● The problem can be encountered in a wide range of AI systems, but it's particularly common in speedup learning. Speedup learning approaches are aimed to teach people control principles in order to assist them enhance their problem-solving skills. When these systems are given complete freedom to learn, they usually display the unwelcome attribute of actually slowing down.
● Although each control rule has a positive utility (improve performance), when combined, they have a negative utility (reduce performance) (degrade performance).
● The serial nature of modern hardware is one of the sources of the utility problem. The more control rules a system acquires, the longer it takes for the system to test them on each cycle.
● This type of utility analysis can be used to a wide range of learning challenges.
● Each control rule in the PRODIGY program has a utility measure. This metric considers the rule's average savings, the frequency with which it is used, and the cost of matching it.
● A proposed regulation is discarded or forgotten if it provides a negative utility.
Induction learning
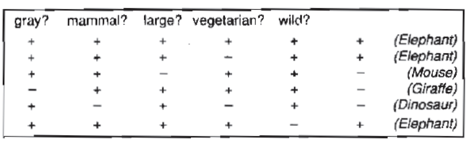
Learning through Induction We have a collection of xi, f (xi) for 1in in supervised learning, and our goal is to determine 'f' using an adaptive approach. It's a machine learning method for inferring rules from facts or data. In logic, conditional or antecedent reasoning is the process of reasoning from the specific to the general. Theoretical studies in machine learning mostly concern supervised learning, a sort of inductive learning. An algorithm is provided with samples that are labeled in a useful way in supervised learning.
Inductive learning techniques, such as artificial neural networks, allow the real robot to learn simply from data that has already been collected. Another way is to let the bot learn everything in his environment by inducing facts from it. Inductive learning is the term for this type of learning. Finally, you may train the bot to evolve across numerous generations and improve its performance.
f(x) is the target function
An example is a pair [x, f(x)]
Some practical examples of induction are:
● Credit risk assessment.
● The x is the property of the customer.
● The f(x) is credit approved or not.
● Disease diagnosis.
● The x are the properties of the patient.
● The f(x) is the disease they suffer from.
● Face recognition.
● The x are bitmaps of peoples faces.
● The f(x) is to assign a name to the face.
● Automatic steering.
● The x are bitmap images from a camera in front of the car.
● The f(x) is the degree the steering wheel should be turned.
Two perspectives on inductive learning:
● Learning is the removal of uncertainty. Data removes some of the uncertainty. We are removing more uncertainty by selecting a class of hypotheses.
● Learning is guessing a good and small hypothesis class. It necessitates speculation. Because we don't know the answer, we'll have to rely on trial and error. You don't need to learn if you're confident in your domain knowledge. But we're not making educated guesses.
In the fields of statistics and machine learning, probabilistic models—in which unobserved variables are seen as stochastic and dependencies between variables are recorded in joint probability distributions—are commonly utilized.
Many desirable properties of probabilistic models include the ability to reason about the uncertainties inherent in most data, the ability to build complex models from simple parts, a natural safeguard against overfitting, and the ability to infer fully coherent inferences over complex structures from data.
Probabilistic Models in Machine Learning is the application of statistical coding to data analysis. It was one of the first machine learning methods. To this day, it's still widely used. The Naive Bayes algorithm is one of the most well-known algorithms in this group.
Probabilistic modeling provides a framework for adopting the concept of learning. The probabilistic framework specifies how to express and deploy model reservations. In scientific data analysis, predictions play a significant role. Machine learning, automation, cognitive computing, and artificial intelligence all rely heavily on them.
The use of probabilistic models to define the world is portrayed as a common idiom. These were explained using random variables, such as building pieces that were thought to be connected by probabilistic linkages.
In machine learning, there are probabilistic and non-probabilistic models. Basic knowledge of probability concepts, such as random variables and probability distributions, would be beneficial in gaining a thorough understanding of probabilistic models.
Intelligent systems must be able to derive representations from noisy or ambiguous data. Bayes' theorem, in particular, is useful in probability theory as a systematic framework for mixing prior knowledge and empirical evidence.
Key takeaway
Probabilistic Models in Machine Learning is the application of statistical coding to data analysis. It was one of the first machine learning methods. To this day, it's still widely used.
A normative epistemology is mathematically embodied in formal learning theory. It considers how an agent should use observations about her surroundings to reach accurate and informative conclusions. Learning theory was established by philosophers such as Putnam, Glymour, and Kelly as a normative framework for scientific reasoning and inductive inference.
● Valiant's Theory of the Learnable categorizes situations according to how difficult they are to learn.
● Formally, a device can learn a concept if it can generate an algorithm that will correctly classify future cases with probability 1/h given positive and negative examples.
● Complexity of learning a function is decided by three factors:
● The error tolerance (h)
● The number of binary features present in the example (t)
● Size of rules necessary to make the discrimination (f)
● The system is considered to be trainable if the number of training examples is a polynomial in h, t, and f.
● Learning feature descriptions is an example.
● The usage of knowledge will be quantified using mathematical theory.
References:
- E.Rich and K. Knight, Artificial Intelligence, Tata McGraw Hill, 2008.
- Artificial intelligence and soft computing for beginners by Anandita Das Bhattachargee, Shroff Publishers
- Artificial Intelligence – A Practical Approach: Patterson , Tata McGraw Hill, 3rd Edition
Unit - 5
Learning
Changes in the system that allow it to perform the same task more efficiently the next time around. Learning is the process of creating or changing representations of what one is experiencing. Learning causes beneficial mental changes. Learning enhances comprehension and productivity.
Find out about new objects or structures that you didn't know about before (data mining, scientific discovery). Fill in any observations or requirements regarding a domain that are skeletal or incomplete (this expands the domain of expertise and lessens the brittleness of the system). Create software agents that can learn from their users and other software agents. Replicate a key feature of intelligent behavior.
Arthur Samuel, an American pioneer in the fields of computer games and artificial intelligence, invented the phrase Machine Learning in 1959, stating that "it offers computers the ability to learn without being expressly taught."
"A computer programme is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, increases with experience E," Tom Mitchell wrote in 1997.
At a high-level, machine learning is simply the study of teaching a computer programme or algorithm how to gradually improve upon a set task that it is given. On the research-side of things, machine learning can be seen through the prism of theoretical and mathematical simulation of how this method works. However, more technically it is the study of how to construct applications that exhibit this iterative progress.
Machine Learning is an Application of Artificial Intelligence (AI) that gives machines the opportunity to learn from their experiences and develop themselves without doing any coding.
Machine Learning is a branch of Artificial Intelligence. Machine Learning is the study of making machines more human-like in their actions and decisions by allowing them the ability to learn and create their own programmes. This is achieved with minimal human interference, i.e., no explicit programming. The learning process is automated and enhanced based on the experiences of the machines in the process.
In the real world, we are surrounded by individuals who can learn anything from their experiences thanks to their ability to learn, and we have computers or machines that follow our commands. But, like a human, can a machine learn from past experiences or data? So here's where Machine Learning comes in.
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms that allow a computer to learn on its own from data and previous experiences. Arthur Samuel was the first to coin the term "machine learning" in 1959. In a nutshell, we can characterize it as follows:
“Machine learning enables a machine to automatically learn from data, improve performance from experiences, and predict things without being explicitly programmed.”
Machine learning algorithms create a mathematical model with the help of sample historical data, referred to as training data, that aids in making predictions or judgments without being explicitly programmed. In order to create predictive models, machine learning combines computer science and statistics. Machine learning is the process of creating or employing algorithms that learn from past data. The more information we supply, the better our performance will be.
If a system can enhance its performance by gaining new data, it has the potential to learn.
Steps
There are Seven Steps of Machine Learning
- Gathering Data
- Preparing that data
- Choosing a model
- Training
- Evaluation
- Hyperparameter Tuning
- Prediction
Features of ML
● Data is used by machine learning to find distinct patterns in a dataset.
● It can learn from previous data and improve on its own.
● It is a technology that is based on data.
● Data mining and machine learning are very similar in that they both deal with large amounts of data.
Key takeaway:
Machine Learning is an Application of Artificial Intelligence (AI) that gives machines the opportunity to learn from their experiences and develop themselves without doing any coding.
On the research-side of things, machine learning can be seen through the prism of theoretical and mathematical simulation of how this method works.
Learning is a process, whereas knowledge is the result, consequence, output, or effect of learning through experience, study, education, or training data.
"The process of obtaining new understanding, knowledge, behaviors, abilities, beliefs, attitudes, and preferences is known as learning."
Learning is a system/method/algorithm through which you acquire information from your parents, a peer, a street, a school or college or an institution, a book, or the internet. So learning is the process of acquiring skill or knowledge by trial and error in life or through study, observation, instruction, and other means.
Facts, information, data, truths, principles, beliefs, and harmful behaviors are all learned.
What we learn and learn to know is what we know.
Scientific activities such as theoretical, experimental, computational, or data analytic activities drive human and machine knowledge and learning. Science is the sum total of all known facts about reality, people, and technology. And only at the transdisciplinary level, where all barriers between and within knowledge areas and technical domains are transgressed by holistic, systematic, and transdisciplinary learning and knowledge, as shown above, could real-world learning and knowledge be achieved.
Once again, human knowledge is highly specialized and fragmented into small disciplines and fields, impeding our ability to address global change issues like as climate change, pandemics, and other planetary hazards and threats.
There is only one type of causal learning. However, in behavioristic psychology, learning is classified as either passive or active, non-associative, associative, or active (the process by which a person or animal or machine learns an association between two stimuli or events). Informal and formal education, e-learning, meaningful or rote learning, interactive or accidental or episodic learning, enculturation, and socialization are all factors to consider.
Learning, according to the ML/DL philosophy, is a change in behavior brought about by interacting with the environment in order to establish new patterns of reactions to stimuli/inputs, whether internal or external, conscious or subconscious, voluntary or involuntary.
All that a humanity, society, mind, or machine understands has been learned through experience or education. Intuition and experience, information and comprehension, values, attitudes and views, awareness and familiarity are all part of knowledge. Human minds, unlike robots, are capable of one-short learning, transfer learning, and relearning.
Learned behaviors could be demonstrated by humans, animals, plants, and machines.
When the program does not learn from advice, it can learn by generalizing from its own experiences.
● Learning by parameter adjustment
● Learning with macro-operators
● Learning by chunking
● The unity problem
Learning by parameter adjustment
● The learning system in this example uses an evaluation technique that combines data from various sources into a single static summary.
● For example, demand and production capacity might be combined into a single score to indicate the likelihood of increased output.
● However, defining how much weight each component should be given a priori is difficult.
● By guessing the correct settings and then letting the computer modify them based on its experience, the correct weight can be discovered.
● Features that appear to be strong indicators of overall performance will have their weights increased, while those that do not will have their weights reduced.
● This type of learning strategy is useful when there is a shortage of knowledge.
● In game programming, for example, factors such as piece advantage and mobility are combined into a single score to assess whether a particular board position is desired. This single score is nothing more than data that the algorithm has gathered through calculation.
● This is accomplished via programs' static evaluation functions, which combine several elements into a single score. This function's polynomial form is as follows:
● The t words represent the values of the traits that contribute to the evaluation. The c terms are the coefficients or weights that are allocated to each of these values.
● When it comes to creating programs, deciding on the right value to give each weight might be tricky. As a result, the most important rule in parameter adjustment is to:
● Begin by making an educated guess at the appropriate weight values.
● Adjust the program's weight based on your previous experience.
● Traits that appear to be good forecasters will have their weights increased, while features that look to be bad predictions will have their weights reduced.
● The following are significant factors that affect performance:
● When should the value of a coefficient be increased and when should it be decreased?
● The coefficients of good predictors should be increased, while the coefficients of undesirable predictors should be reduced.
● The difficulty of properly assigning blame to each of the phases that led to a single outcome is referred to as the credit assignment system.
● How much should the price change?
● Hill climbing is a type of learning technique.
● This strategy is particularly beneficial in situations when new knowledge is scarce or in programs where it is used in conjunction with more knowledge-intensive strategies.
Learning with Macro-Operators
● Macro-operators are collections of actions that can be handled together.
● The learning component saves the computed plan as a macro-operator once a problem is solved.
● The preconditions are the initial conditions of the just-solved problem, while the postconditions are the problem's outcomes.
● The problem solver makes good use of prior experience-based knowledge.
● By generalizing macro-operations, the issue solver can even tackle other challenges. To achieve generality, all constants in the macro-operators are substituted with variables.
● Despite the fact that the macro operator's multiple operators cause countless undesirable local changes, it can have a minimal global influence.
● Macro operators can help us develop domain-specific knowledge.
Learning by Chunking
● It's similar to chunking to learn with macro-operators. Problem-solving systems that use production systems are most likely to use it.
● A series of rules in the form of if-then statements makes up a production system. That is, what actions should be made in a specific situation. Bring an umbrella if it's raining, for example.
● Problem solvers employ rules to solve difficulties. Some of these rules may be more valuable than others, and the results are grouped together.
● Chunking can be used to gain a general understanding of search control.
● Chunks learned at the start of the problem-solving process can be employed at a later stage. The chunk is saved by the system to be used in future challenges.
The utility problem
● When knowledge is acquired in the hopes of improving a system's performance, it actually causes harm. In learning systems, this is referred to as the utility problem.
● The problem can be encountered in a wide range of AI systems, but it's particularly common in speedup learning. Speedup learning approaches are aimed to teach people control principles in order to assist them enhance their problem-solving skills. When these systems are given complete freedom to learn, they usually display the unwelcome attribute of actually slowing down.
● Although each control rule has a positive utility (improve performance), when combined, they have a negative utility (reduce performance) (degrade performance).
● The serial nature of modern hardware is one of the sources of the utility problem. The more control rules a system acquires, the longer it takes for the system to test them on each cycle.
● This type of utility analysis can be used to a wide range of learning challenges.
● Each control rule in the PRODIGY program has a utility measure. This metric considers the rule's average savings, the frequency with which it is used, and the cost of matching it.
● A proposed regulation is discarded or forgotten if it provides a negative utility.
Induction learning
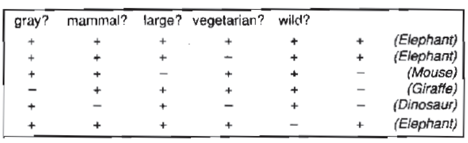
Learning through Induction We have a collection of xi, f (xi) for 1in in supervised learning, and our goal is to determine 'f' using an adaptive approach. It's a machine learning method for inferring rules from facts or data. In logic, conditional or antecedent reasoning is the process of reasoning from the specific to the general. Theoretical studies in machine learning mostly concern supervised learning, a sort of inductive learning. An algorithm is provided with samples that are labeled in a useful way in supervised learning.
Inductive learning techniques, such as artificial neural networks, allow the real robot to learn simply from data that has already been collected. Another way is to let the bot learn everything in his environment by inducing facts from it. Inductive learning is the term for this type of learning. Finally, you may train the bot to evolve across numerous generations and improve its performance.
f(x) is the target function
An example is a pair [x, f(x)]
Some practical examples of induction are:
● Credit risk assessment.
● The x is the property of the customer.
● The f(x) is credit approved or not.
● Disease diagnosis.
● The x are the properties of the patient.
● The f(x) is the disease they suffer from.
● Face recognition.
● The x are bitmaps of peoples faces.
● The f(x) is to assign a name to the face.
● Automatic steering.
● The x are bitmap images from a camera in front of the car.
● The f(x) is the degree the steering wheel should be turned.
Two perspectives on inductive learning:
● Learning is the removal of uncertainty. Data removes some of the uncertainty. We are removing more uncertainty by selecting a class of hypotheses.
● Learning is guessing a good and small hypothesis class. It necessitates speculation. Because we don't know the answer, we'll have to rely on trial and error. You don't need to learn if you're confident in your domain knowledge. But we're not making educated guesses.
In the fields of statistics and machine learning, probabilistic models—in which unobserved variables are seen as stochastic and dependencies between variables are recorded in joint probability distributions—are commonly utilized.
Many desirable properties of probabilistic models include the ability to reason about the uncertainties inherent in most data, the ability to build complex models from simple parts, a natural safeguard against overfitting, and the ability to infer fully coherent inferences over complex structures from data.
Probabilistic Models in Machine Learning is the application of statistical coding to data analysis. It was one of the first machine learning methods. To this day, it's still widely used. The Naive Bayes algorithm is one of the most well-known algorithms in this group.
Probabilistic modeling provides a framework for adopting the concept of learning. The probabilistic framework specifies how to express and deploy model reservations. In scientific data analysis, predictions play a significant role. Machine learning, automation, cognitive computing, and artificial intelligence all rely heavily on them.
The use of probabilistic models to define the world is portrayed as a common idiom. These were explained using random variables, such as building pieces that were thought to be connected by probabilistic linkages.
In machine learning, there are probabilistic and non-probabilistic models. Basic knowledge of probability concepts, such as random variables and probability distributions, would be beneficial in gaining a thorough understanding of probabilistic models.
Intelligent systems must be able to derive representations from noisy or ambiguous data. Bayes' theorem, in particular, is useful in probability theory as a systematic framework for mixing prior knowledge and empirical evidence.
Key takeaway
Probabilistic Models in Machine Learning is the application of statistical coding to data analysis. It was one of the first machine learning methods. To this day, it's still widely used.
A normative epistemology is mathematically embodied in formal learning theory. It considers how an agent should use observations about her surroundings to reach accurate and informative conclusions. Learning theory was established by philosophers such as Putnam, Glymour, and Kelly as a normative framework for scientific reasoning and inductive inference.
● Valiant's Theory of the Learnable categorizes situations according to how difficult they are to learn.
● Formally, a device can learn a concept if it can generate an algorithm that will correctly classify future cases with probability 1/h given positive and negative examples.
● Complexity of learning a function is decided by three factors:
● The error tolerance (h)
● The number of binary features present in the example (t)
● Size of rules necessary to make the discrimination (f)
● The system is considered to be trainable if the number of training examples is a polynomial in h, t, and f.
● Learning feature descriptions is an example.
● The usage of knowledge will be quantified using mathematical theory.
References:
- E.Rich and K. Knight, Artificial Intelligence, Tata McGraw Hill, 2008.
- Artificial intelligence and soft computing for beginners by Anandita Das Bhattachargee, Shroff Publishers
- Artificial Intelligence – A Practical Approach: Patterson , Tata McGraw Hill, 3rd Edition




