Unit - 5
Protocols
Address Resolution Protocol (ARP) is a communication protocol used to find the MAC (Media Access Control) address of a device from its IP address. This protocol is used when a device wants to communicate with another device on a Local Area Network or Ethernet.
Types of ARP
There are four types of Address Resolution Protocol, which is given below:
● Proxy ARP
● Gratuitous ARP
● Reverse ARP (RARP)
● Inverse ARP
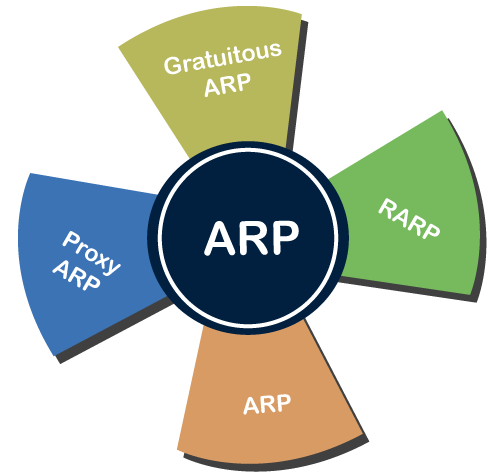
Fig 1: ARP
Proxy ARP - Proxy ARP is a method through which a Layer 3 device may respond to ARP requests for a target that is in a different network from the sender. The Proxy ARP configured router responds to the ARP and maps the MAC address of the router with the target IP address and fools the sender that it is reached at its destination.
At the backend, the proxy router sends its packets to the appropriate destination because the packets contain the necessary information.
Example - If Host A wants to transmit data to Host B, which is on the different network, then Host A sends an ARP request message to receive a MAC address for Host B. The router responds to Host A with its own MAC address pretending itself as a destination. When the data is transmitted to the destination by Host A, it will send to the gateway so that it sends to Host B. This is known as proxy ARP.
Gratuitous ARP - Gratuitous ARP is an ARP request of the host that helps to identify the duplicate IP address. It is a broadcast request for the IP address of the router. If an ARP request is sent by a switch or router to get its IP address and no ARP responses are received, so all other nodes cannot use the IP address allocated to that switch or router. Yet if a router or switch sends an ARP request for its IP address and receives an ARP response, another node uses the IP address allocated to the switch or router.
There are some primary use cases of gratuitous ARP that are given below:
● The gratuitous ARP is used to update the ARP table of other devices.
● It also checks whether the host is using the original IP address or a duplicate one.
Key takeaway
Address Resolution Protocol (ARP) is a communication protocol used to find the MAC (Media Access Control) address of a device from its IP address. This protocol is used when a device wants to communicate with another device on a Local Area Network or Ethernet.
Reverse ARP (RARP)
It is a networking protocol used by the client system in a local area network (LAN) to request its IPv4 address from the ARP gateway router table. A table is created by the network administrator in the gateway-router that is used to find out the MAC address to the corresponding IP address.
When a new system is set up or any machine that has no memory to store the IP address, then the user has to find the IP address of the device. The device sends a RARP broadcast packet, including its own MAC address in the address field of both the sender and the receiver hardware. A host installed inside of the local network called the RARP-server is prepared to respond to such type of broadcast packet. The RARP server is then trying to locate a mapping table entry in the IP to MAC address. If any entry matches the item in the table, then the RARP server sends the response packet along with the IP address to the requesting computer.
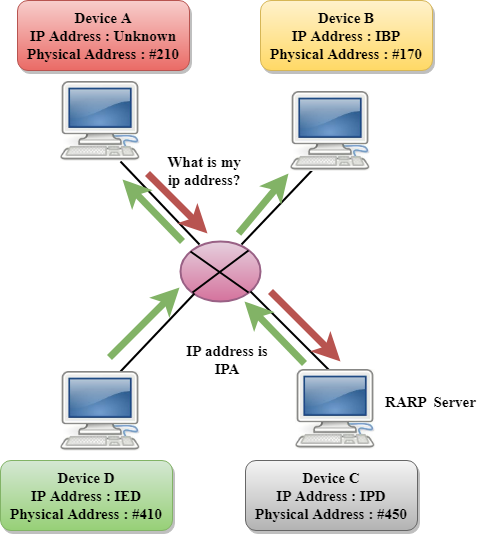
Fig 2: RARP
Inverse ARP (In ARP) - Inverse ARP is inverse of the ARP, and it is used to find the IP addresses of the nodes from the data link layer addresses. These are mainly used for the frame relays, and ATM networks, where Layer 2 virtual circuit addressing are often acquired from Layer 2 signaling. When using these virtual circuits, the relevant Layer 3 addresses are available.
ARP conversions Layer 3 addresses to Layer 2 addresses. However, its opposite address can be defined by In ARP. The In ARP has a similar packet format as ARP, but operational codes are different.
Key takeaway
It is a networking protocol used by the client system in a local area network (LAN) to request its IPv4 address from the ARP gateway router table. A table is created by the network administrator in the gateway-router that is used to find out the MAC address to the corresponding IP address.
An IP stands for internet protocol. An IP address is assigned to each device connected to a network. Each device uses an IP address for communication. It also behaves as an identifier as this address is used to identify the device on a network. It defines the technical format of the packets. Mainly, both the networks, i.e., IP and TCP, are combined together, so together, they are referred to as TCP/IP. It creates a virtual connection between the source and the destination.
We can also define an IP address as a numeric address assigned to each device on a network. An IP address is assigned to each device so that the device on a network can be identified uniquely. To facilitate the routing of packets, TCP/IP protocol uses a 32-bit logical address known as IPv4(Internet Protocol version 4).
Function:
The internet protocol's main purpose is to provide hosts with addresses, encapsulate data into packet structures, and route data from source to destination through one or more IP networks. The internet protocol provides two main items in order to achieve these functionalities, which are mentioned below.
● Format of IP packet
● IP Addressing system
IP packet
Until an IP packet is sent over the network, it contains two main components: a header and a payload.
Fig 3: IP packet
An IP header provides a lot of details about the IP packet, such as:
● The source IP address is that of the person who is sending the data.
● IP address of the destination: The destination is a host that collects data from the sender.
● Header length
● Packet length
● TTL (Time to Live) of a packet is the amount of hops that must occur before the packet is discarded.
● The internet protocol's transport protocol, which can be TCP or UDP, is known as the transport protocol.
The IP header contains a total of 14 fields, one of which is optional.
The data to be transported is known as the payload.
Key takeaway
An IP stands for internet protocol. An IP address is assigned to each device connected to a network. Each device uses an IP address for communication. It also behaves as an identifier as this address is used to identify the device on a network.
The ICMP stands for Internet Control Message Protocol. The ICMP protocol is a network layer protocol that hosts and routers use to notify the sender of IP datagram problems. The echo test/reply method is used by ICMP to determine if the destination is reachable and responding.
ICMP can handle both control and error messages, but its primary purpose is to record errors rather than to fix them. An IP datagram includes the source and destination addresses, but it does not know the address of the previous router it passed through.
As a result, ICMP can only send messages to the source, not to the routers in the immediate vicinity. The sender receives error messages via the ICMP protocol. The errors are returned to the user processes via ICMP messages.
ICMP messages are sent as part of an IP datagram.
Fig 4: ICMP
Format of ICMP

Fig 5: ICMP format
● The message's form is defined in the first sector.
● The reason for a particular message form is specified in the second sector.
● The checksum field is used to verify the integrity of the entire ICMP message.
Key takeaway
The ICMP stands for Internet Control Message Protocol. The ICMP protocol is a network layer protocol that hosts and routers use to notify the sender of IP datagram problems. The echo test/reply method is used by ICMP to determine if the destination is reachable and responding.
Internet Protocol version 6 (IPv6) is the latest revision of the Internet Protocol (IP) and the first version of the protocol to be widely deployed. IPv6 was developed by the Internet Engineering Task Force (IETF) to deal with the long-anticipated problem of IPv4 address exhaustion. The Internet has grown exponentially and the address space allowed by IPv4 is saturating.
There is a requirement of protocol which can satisfy the need of future Internet addresses which are expected to grow in an unexpected manner. Using features such as NAT, has made the Internet discontinuous i.e. one part which belongs to intranet, primarily uses private IP addresses; which has to go through a number of mechanisms to reach the other part, the Internet, which is on public IP addresses.
What is IPv6?
IPv4 produces 4 billion addresses, and the developers think that these addresses are enough, but they were wrong. IPv6 is the next generation of IP addresses. The main difference between IPv4 and IPv6 is the address size of IP addresses. The IPv4 is a 32-bit address, whereas IPv6 is a 128-bit hexadecimal address. IPv6 provides a large address space, and it contains a simple header as compared to IPv4.
It provides transition strategies that convert IPv4 into IPv6, and these strategies are as follows:
● Dual stacking: It allows us to have both the versions, i.e., IPv4 and IPv6, on the same device.
● Tunneling: In this approach, all the users have IPv6 and communicate with an IPv4 network to reach IPv6.
● Network Address Translation: The translation allows the communication between the hosts having a different version of IP.
This hexadecimal address contains both numbers and alphabets. Due to the usage of both the numbers and alphabets, IPv6 is capable of producing over 340 undecillion (3.4*1038) addresses.
IPv6 is a 128-bit hexadecimal address made up of 8 sets of 16 bits each, and these 8 sets are separated by a colon. In IPv6, each hexadecimal character represents 4 bits. So, we need to convert 4 bits to a hexadecimal number at a time
The address format of IPv6:

Fig 6: Address format of IPV6
The above diagram shows the address format of IPv4 and IPv6. An IPv4 is a 32-bit decimal address. It contains 4 octets or fields separated by 'dot', and each field is 8-bit in size. The number that each field contains should be in the range of 0-255. Whereas an IPv6 is a 128-bit hexadecimal address. It contains 8 fields separated by a colon, and each field is 16-bit in size.
Differences between IPv4 and IPv6
| Ipv4 | Ipv6 |
Address length | IPv4 is a 32-bit address. | IPv6 is a 128-bit address. |
Fields | IPv4 is a numeric address that consists of 4 fields which are separated by dot (.). | IPv6 is an alphanumeric address that consists of 8 fields, which are separated by colon. |
Classes | IPv4 has 5 different classes of IP address that includes Class A, Class B, Class C, Class D, and Class E. | IPv6 does not contain classes of IP addresses. |
Number of IP address | IPv4 has a limited number of IP addresses. | IPv6 has a large number of IP addresses. |
VLSM | It supports VLSM (Virtual Length Subnet Mask). Here, VLSM means that Ipv4 converts IP addresses into a subnet of different sizes. | It does not support VLSM. |
Address configuration | It supports manual and DHCP configuration. | It supports manual, DHCP, auto-configuration, and renumbering. |
Encryption and Authentication | It does not provide encryption and authentication. | It provides encryption and authentication. |
Address representation | In IPv4, the IP address is represented in decimal. | In IPv6, the representation of the IP address is hexadecimal. |
Packet flow identification | It does not provide any mechanism for packet flow identification. | It uses a flow label field in the header for the packet flow identification. |
Key takeaway:
- Network layer manages options pertaining to host and network addressing, managing sub-networks, and internet working.
- IPv6 is the next generation of IP addresses.
- IPv6 is the latest revision of the Internet Protocol and the first version of the protocol to be widely deployed.
The majority of internet and intranet traffic, also known as unicast data or unicast traffic, is routed to a specific destination. Unicast routing is the process of sending unicast data via the internet. Because the destination is already known, it is the simplest form of routing. As a result, all the router has to do is check the routing table and forward the packet to the next step.
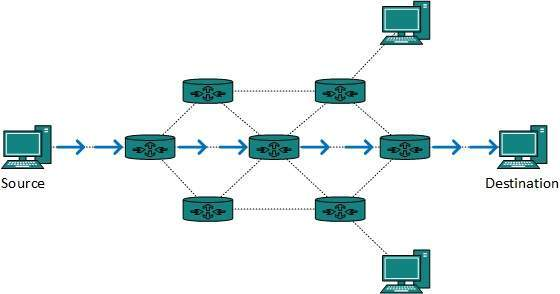
Fig 7: Unicast routing
Unicast packets can be routed using one of two routing protocols:
Distance Vector Routing Protocol
Distance Vector is a straightforward routing technique that bases its decisions on the number of hops between the source and the destination. The best route is one that has the fewest amount of hops. To other routers, each router presents its collection of optimal routes. Finally, all routers construct their network topologies based on peer router ads.
Routing Information Protocol, for example (RIP).
Link State Routing Protocol
The Link State protocol is a little more sophisticated than the Distance Vector protocol. It considers the states of all the routers in a network's links. This technique aids in the creation of a network-wide shared graph. The optimum path for routing is then calculated by all routers. Open Shortest Path First (OSPF) and Intermediate System to Intermediate System (IS-IS) are two examples (ISIS).
Multicast routing protocol
Multicast routing is a subset of broadcast routing, with unique characteristics and challenges. Packets are sent to all nodes via broadcast routing, even if they do not want them. However, in Multicast routing, data is only sent to nodes that desire to receive packets.
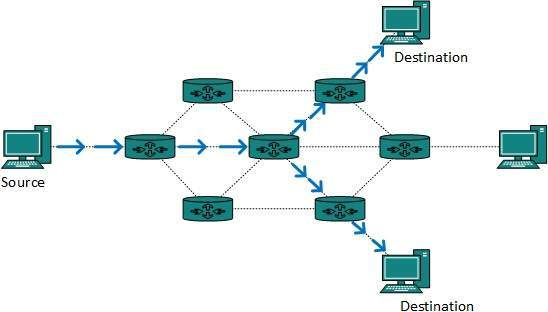
Fig 8: Multicast routing
Multicast routing methods employ trees, i.e. spanning tree, to eliminate loops, whereas Unicast routing protocols use graphs. The shortest path spanning tree is the best tree.
● DVMRP - Distance Vector Multicast Routing Protocol
● MOSPF - Multicast Open Shortest Path First
● CBT - Core Based Tree
● PIM - Protocol independent Multicast
Protocol Independent Multicast (PIM) is currently widely utilised. It comes in two different flavors:
PIM Dense Mode -
Source-based trees are used in this mode. It's employed in high-density environments like LANs.
PIM Sparse Mode -
Shared trees are used in this manner. In a sparse setting, such as a WAN, it is employed.
Key takeaway
Unicast routing is the process of sending unicast data via the internet. Because the destination is already known, it is the simplest form of routing.
Multicast routing is a subset of broadcast routing, with unique characteristics and challenges. Packets are sent to all nodes via broadcast routing, even if they do not want them.
Let's have a look at how the Leaky Bucket Algorithm works.
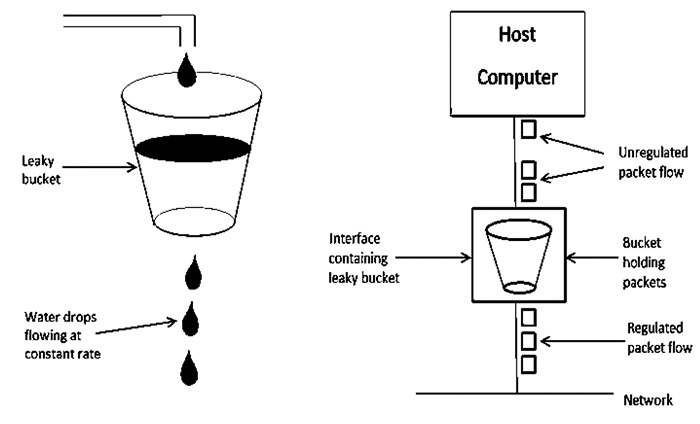
Fig 9: Leaky bucket algorithm
The Leaky Bucket Algorithm is primarily responsible for controlling the total volume and rate of traffic supplied to the network.
Step 1: Consider a bucket with a small hole at the bottom into which water is poured at a variable pace, but which leaks at a constant rate.
Step 2 So (as long as there is water in the bucket), the rate at which water leaks is unaffected by the pace at which water is poured into the bucket.
Step 3: If the bucket is full, any more water that enters will pour over the edges and be lost.
Step 4: The same technique was applied to network packets. Consider the fact that data is arriving at varying speeds from the source. Assume a source transmits data at 10 Mbps for 4 seconds. For the next three seconds, there is no data. For 2 seconds, the source transfers data at an 8 Mbps pace. Thus, 68 Mb of data was sent in less than 8 seconds.
As a result, if you employ a leaky bucket technique, the data flow will be 8 Mbps for 9 seconds. As a result, the steady flow is maintained.
Token bucket algorithm
One of the strategies for congestion management algorithms is the token bucket algorithm. When there are too many packets in the network, it causes packet delay and packet loss, lowering the system's performance. Congestion is the term for this circumstance.
Congestion management is shared between the network layer and the transport layer. Trying to lessen the burden that the transport layer places on the network is one of the most effective strategies to control congestion. To keep this network running, the network and transport layers must collaborate.
The Token Bucket Algorithm is illustrated graphically as follows:
When there is too much traffic, performance suffers significantly.
Token Bucket Algorithm
No matter how busy the network is, the leaky bucket algorithm enforces output patterns at the average rate. To deal with the increased traffic, we'll need a flexible algorithm that won't lose data. The token bucket algorithm is one such method.
Let's take a look at this method one step at a time, as shown below.
Step 1: Tokens are thrown into the bucket f at regular intervals.
Step 2: The bucket can hold a maximum of f.
Step 3: If the packet is ready, a token from the bucket is taken, and the packet is sent.
Step 4 Assume that the packet cannot be forwarded if there is no token in the bucket.
Example
Let's look at an example of the Token Bucket Algorithm.
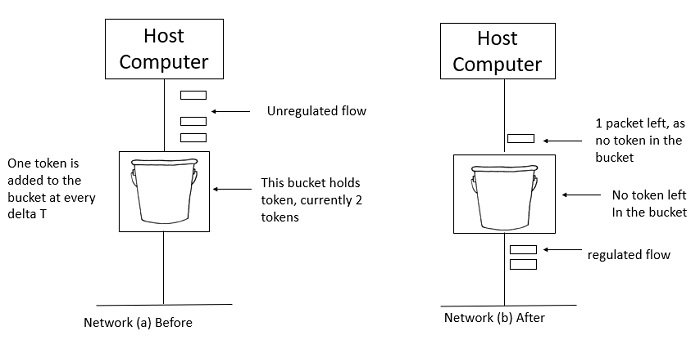
Two tokens are in the bucket in figure (a), and three packets are waiting to be transmitted out of the interface.
Figure (b) shows that two packets have been sent out after two tokens have been consumed, and one packet remains.
The token bucket method is less limiting than the Leaky bucket algorithm, allowing for more traffic. The amount of tokens accessible in the bucket at any given time determines the maximum amount of bustle.
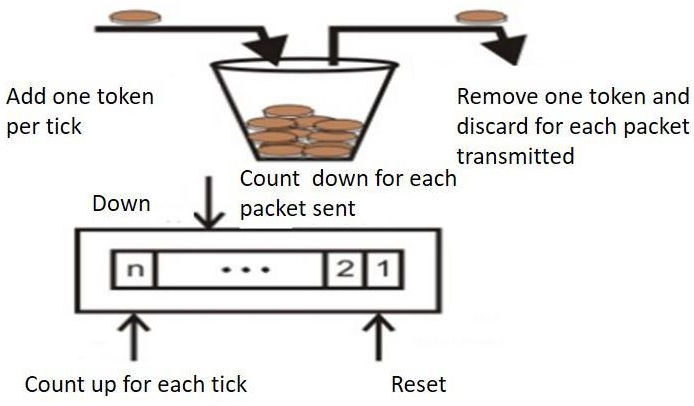
The token bucket technique is simple to construct because the tokens are counted using a variable. The counter is incremented every t seconds and then decremented whenever a packet is sent. When the counter reaches zero, no further packet is sent out.
This is shown in below given diagram −
Some advantage of token Bucket over leaky bucket –
● If the token bucket is full, tokens are discarded rather than packets. Packets are discarded while in a leaky bucket.
● Token Bucket may deliver large bursts at a quicker pace, but a leaky bucket sends packets at the same rate every time.
Difference between leaky bucket and token bucket
Leaky Bucket | Token Bucket |
When the host has to send a packet , packet is thrown in bucket. | In this leaky bucket holds tokens generated at regular intervals of time. |
Bucket leaks at constant rate | Bucket has maximum capacity. |
Bursty traffic is converted into uniform traffic by leaky bucket. | If there is a ready packet , a token is removed from Bucket and packet is send. |
In practice bucket is a finite queue outputs at finite rate | If there is a no token in bucket, packet can not be send.
|
Both virtual networks and datagram subnets can benefit from the choke packet strategy. A choke packet is a message delivered by a node to the source informing it that the network is congested. Each router keeps track of its resources and how many of its output lines are in use. The router sends a choke packet to the source anytime resource use exceeds the threshold value defined by the administrator, giving it feedback to minimize traffic. Congestion is not reported to the intermediate nodes via which the packets passed.
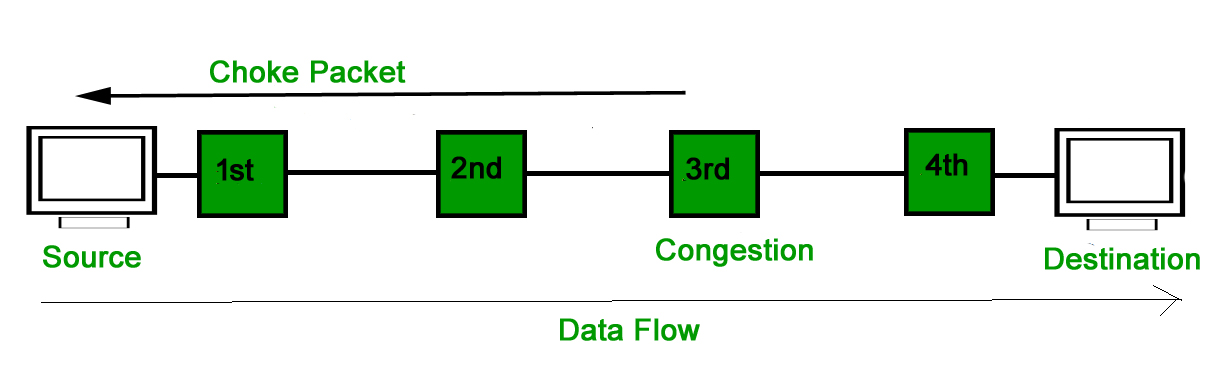
In network maintenance and quality management, a choke packet is used to notify a specific node or transmitter that its broadcast traffic is causing network congestion. As a result, the node or transmitter is forced to lower its output rate.
Choke packets are used to control network congestion and flow. The router addresses the source node directly, forcing it to reduce its transmission rate. The source node responds by lowering the sending rate by a certain percentage.
A source quench packet for the Internet Control Message Protocol (ICMP) is a form of choke packet commonly used by routers.
Routers are used in a choke packet's congestion control and recovery approach. Routers often scan the network for anomalies by looking at things like line use, queuing, and buffer length. Routers transmit choke packets to all related segments in the event of congestion to reduce data throughput. Depending on variables such as the size of the congestions, available bandwidth, and buffer size, the source node congesting the network must reduce throughput by a particular factor.
Key takeaway
Choke packets are used to control network congestion and flow. The router addresses the source node directly, forcing it to reduce its transmission rate. The source node responds by lowering the sending rate by a certain percentage.
Open loop
Policies are used in open-loop congestion control to prevent congestion before it occurs. Congestion control is performed by either the source or the destination in these systems.
a. Retransmission Policy
Sometimes retransmission is unavoidable. If the sender believes a packet has been lost or corrupted, the packet must be resent. In general, retransmission may cause network congestion. A good retransmission policy, on the other hand, can prevent congestion. The retransmission strategy and timers must be configured in such a way that they maximize efficiency while avoiding congestion. TCP's retransmission strategy, for example (described below), is meant to avoid or alleviate congestion.
b. Window Policy
Congestion may be influenced by the type of window used by the sender. For congestion control, the Selective Repeat window outperforms the Go-Back-N window. When the timer for a packet times out in the Go-Back-N window, numerous packets may be resent, even if some may have arrived safely at the recipient. This duplication could exacerbate the bottleneck. The Selective Repeat window, on the other hand, attempts to send only the lost or damaged packets.
c. Acknowledgment Policy
Congestion may be influenced by the receiver's acknowledgment policy. If the receiver does not acknowledge every packet it gets, the sender will be slowed and congestion will be avoided. In this scenario, several ways are applied. Only when a packet needs to be sent or when a particular timer expires can a receiver send an acknowledgment. Only N packets may be acknowledged at a time by a receiver. We need to understand that acknowledgements are part of a network's burden. Sending fewer acknowledgements reduces the amount of traffic on the network.
d. Discarding Policy
Routers with a good discarding policy can prevent congestion while not jeopardising the integrity of the transmission. In audio transmission, for example, if the policy is to discard less sensitive packets when congestion is expected, the sound quality is kept while congestion is avoided or alleviated.
e. Admission Policy
In virtual-circuit networks, an admission policy, which is a quality-of-service mechanism, can also reduce congestion. Before admitting a flow to the network, switches in a flow verify its resource requirements. If the network is congested or there is a chance of future congestion, a router can refuse to make a virtual circuit connection.
Closed loop
Closed-loop congestion control systems aim to reduce traffic congestion after it has occurred. Different methods have used a variety of mechanisms.
a. Backpressure
Backpressure is a congestion control technique in which a congested node stops receiving data from the upstream node or nodes it is connected to. As a result, the upstream node or nodes may become overburdened, and they may reject data from their upstream node or nodes. And so forth. Backpressure is a type of node-to-node congestion control that begins at a node and spreads to the source in the reverse direction of data flow. Only virtual circuit networks with each node knowing the upstream node from which a data flow is emanating can use the backpressure technique. Backpressure is depicted in the diagram.
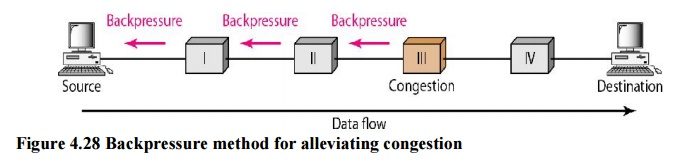
Fig 10: Backpressure method
The incoming data for Node III in the diagram is greater than it can manage. It discards a few packets from its input buffer and tells node II to slow down. Node II, in turn, may be congested as a result of the data output flow being slowed. When node II becomes crowded, it signals node I to slow down, which may cause congestion. If this is the case, node I will advise the data source to slow down. This, in turn, relieves congestion over time. This, in turn, relieves congestion over time. To clear the congestion, the pressure on node III is shifted backwards to the source.
b. Choke Packet
A choke packet is a message delivered by a node to the source informing it that the network is congested. The backpressure and choke packet approaches differ from one another. The alert is sent from one node to its upstream node under backpressure, albeit it may finally reach the source station. The choke packet approach sends a direct warning to the source station from the router that has encountered congestion. The intermediary nodes that the packet passed through are not notified. In ICMP, we've seen an example of this form of control. When an Internet router receives a large number of IP datagrams, it may discard some of them, but it notifies the source host via an ICMP source quench message. The warning message is sent directly to the source station, bypassing the intermediate routers, with no action taken. A choke packet is seen in the diagram.
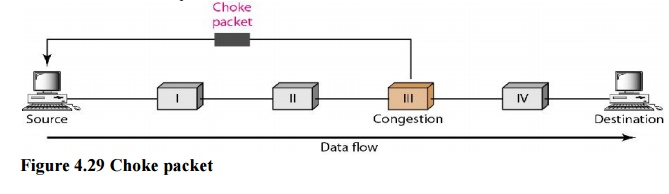
Fig 11: Choke packet
c. Implicit Signaling
There is no communication between the congested node or nodes and the source in implicit signaling. Other signs lead the source to believe that there is congestion somewhere in the network. One assumption is that the network is congested when a source sends multiple packets and receives no acknowledgement for a long time. The lack of an acknowledgement is viewed as network congestion, and the source should slow down.
d. Explicit Signaling
When a node encounters congestion, it can transmit an explicit signal to the source or destination. The explicit signaling approach, on the other hand, is not the same as the choke packet method. A separate packet is used for this purpose in the choke packet approach; in the explicit signaling method, the signal is included in the data packets. Explicit signaling can occur in either the forward or backward direction, as we'll see in Frame Relay congestion control.
i. Backward Signaling
In a packet going in the opposite direction of the congestion, a bit can be set. This bit can alert the source that there is a bottleneck and that it should slow down to minimize packet loss.
Ii. Forward Signaling
In a packet traveling in the direction of congestion, a bit can be set. This bit can alert the destination to the fact that there is a traffic jam. In this instance, the receiver can utilize measures to reduce congestion, such as slowing down acknowledgments.
References:
- Peterson and Davie, “Computer Networks: A Systems Approach”, Morgan Kaufmann
- W. A. Shay, “Understanding Communications and Networks”, Cengage Learning.
- D. Comer, “Computer Networks and Internets”, Pearson.
- Behrouz Forouzan, “TCP/IP Protocol Suite”, McGraw Hill.
Unit - 5
Protocols
Address Resolution Protocol (ARP) is a communication protocol used to find the MAC (Media Access Control) address of a device from its IP address. This protocol is used when a device wants to communicate with another device on a Local Area Network or Ethernet.
Types of ARP
There are four types of Address Resolution Protocol, which is given below:
● Proxy ARP
● Gratuitous ARP
● Reverse ARP (RARP)
● Inverse ARP
Fig 1: ARP
Proxy ARP - Proxy ARP is a method through which a Layer 3 device may respond to ARP requests for a target that is in a different network from the sender. The Proxy ARP configured router responds to the ARP and maps the MAC address of the router with the target IP address and fools the sender that it is reached at its destination.
At the backend, the proxy router sends its packets to the appropriate destination because the packets contain the necessary information.
Example - If Host A wants to transmit data to Host B, which is on the different network, then Host A sends an ARP request message to receive a MAC address for Host B. The router responds to Host A with its own MAC address pretending itself as a destination. When the data is transmitted to the destination by Host A, it will send to the gateway so that it sends to Host B. This is known as proxy ARP.
Gratuitous ARP - Gratuitous ARP is an ARP request of the host that helps to identify the duplicate IP address. It is a broadcast request for the IP address of the router. If an ARP request is sent by a switch or router to get its IP address and no ARP responses are received, so all other nodes cannot use the IP address allocated to that switch or router. Yet if a router or switch sends an ARP request for its IP address and receives an ARP response, another node uses the IP address allocated to the switch or router.
There are some primary use cases of gratuitous ARP that are given below:
● The gratuitous ARP is used to update the ARP table of other devices.
● It also checks whether the host is using the original IP address or a duplicate one.
Key takeaway
Address Resolution Protocol (ARP) is a communication protocol used to find the MAC (Media Access Control) address of a device from its IP address. This protocol is used when a device wants to communicate with another device on a Local Area Network or Ethernet.
Reverse ARP (RARP)
It is a networking protocol used by the client system in a local area network (LAN) to request its IPv4 address from the ARP gateway router table. A table is created by the network administrator in the gateway-router that is used to find out the MAC address to the corresponding IP address.
When a new system is set up or any machine that has no memory to store the IP address, then the user has to find the IP address of the device. The device sends a RARP broadcast packet, including its own MAC address in the address field of both the sender and the receiver hardware. A host installed inside of the local network called the RARP-server is prepared to respond to such type of broadcast packet. The RARP server is then trying to locate a mapping table entry in the IP to MAC address. If any entry matches the item in the table, then the RARP server sends the response packet along with the IP address to the requesting computer.
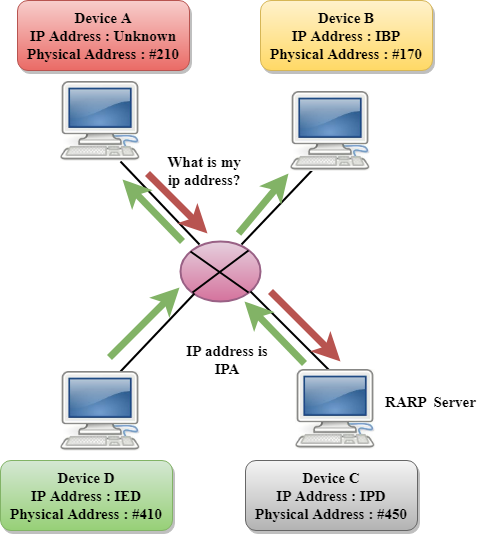
Fig 2: RARP
Inverse ARP (In ARP) - Inverse ARP is inverse of the ARP, and it is used to find the IP addresses of the nodes from the data link layer addresses. These are mainly used for the frame relays, and ATM networks, where Layer 2 virtual circuit addressing are often acquired from Layer 2 signaling. When using these virtual circuits, the relevant Layer 3 addresses are available.
ARP conversions Layer 3 addresses to Layer 2 addresses. However, its opposite address can be defined by In ARP. The In ARP has a similar packet format as ARP, but operational codes are different.
Key takeaway
It is a networking protocol used by the client system in a local area network (LAN) to request its IPv4 address from the ARP gateway router table. A table is created by the network administrator in the gateway-router that is used to find out the MAC address to the corresponding IP address.
An IP stands for internet protocol. An IP address is assigned to each device connected to a network. Each device uses an IP address for communication. It also behaves as an identifier as this address is used to identify the device on a network. It defines the technical format of the packets. Mainly, both the networks, i.e., IP and TCP, are combined together, so together, they are referred to as TCP/IP. It creates a virtual connection between the source and the destination.
We can also define an IP address as a numeric address assigned to each device on a network. An IP address is assigned to each device so that the device on a network can be identified uniquely. To facilitate the routing of packets, TCP/IP protocol uses a 32-bit logical address known as IPv4(Internet Protocol version 4).
Function:
The internet protocol's main purpose is to provide hosts with addresses, encapsulate data into packet structures, and route data from source to destination through one or more IP networks. The internet protocol provides two main items in order to achieve these functionalities, which are mentioned below.
● Format of IP packet
● IP Addressing system
IP packet
Until an IP packet is sent over the network, it contains two main components: a header and a payload.
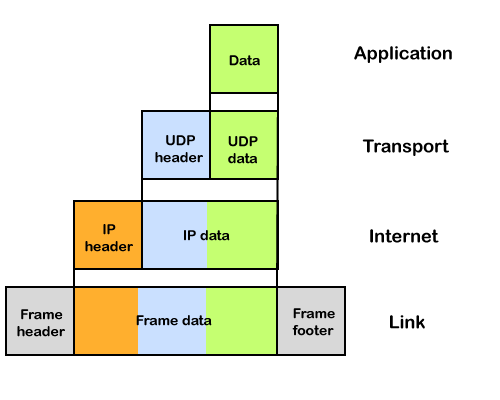
Fig 3: IP packet
An IP header provides a lot of details about the IP packet, such as:
● The source IP address is that of the person who is sending the data.
● IP address of the destination: The destination is a host that collects data from the sender.
● Header length
● Packet length
● TTL (Time to Live) of a packet is the amount of hops that must occur before the packet is discarded.
● The internet protocol's transport protocol, which can be TCP or UDP, is known as the transport protocol.
The IP header contains a total of 14 fields, one of which is optional.
The data to be transported is known as the payload.
Key takeaway
An IP stands for internet protocol. An IP address is assigned to each device connected to a network. Each device uses an IP address for communication. It also behaves as an identifier as this address is used to identify the device on a network.
The ICMP stands for Internet Control Message Protocol. The ICMP protocol is a network layer protocol that hosts and routers use to notify the sender of IP datagram problems. The echo test/reply method is used by ICMP to determine if the destination is reachable and responding.
ICMP can handle both control and error messages, but its primary purpose is to record errors rather than to fix them. An IP datagram includes the source and destination addresses, but it does not know the address of the previous router it passed through.
As a result, ICMP can only send messages to the source, not to the routers in the immediate vicinity. The sender receives error messages via the ICMP protocol. The errors are returned to the user processes via ICMP messages.
ICMP messages are sent as part of an IP datagram.
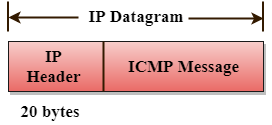
Fig 4: ICMP
Format of ICMP

Fig 5: ICMP format
● The message's form is defined in the first sector.
● The reason for a particular message form is specified in the second sector.
● The checksum field is used to verify the integrity of the entire ICMP message.
Key takeaway
The ICMP stands for Internet Control Message Protocol. The ICMP protocol is a network layer protocol that hosts and routers use to notify the sender of IP datagram problems. The echo test/reply method is used by ICMP to determine if the destination is reachable and responding.
Internet Protocol version 6 (IPv6) is the latest revision of the Internet Protocol (IP) and the first version of the protocol to be widely deployed. IPv6 was developed by the Internet Engineering Task Force (IETF) to deal with the long-anticipated problem of IPv4 address exhaustion. The Internet has grown exponentially and the address space allowed by IPv4 is saturating.
There is a requirement of protocol which can satisfy the need of future Internet addresses which are expected to grow in an unexpected manner. Using features such as NAT, has made the Internet discontinuous i.e. one part which belongs to intranet, primarily uses private IP addresses; which has to go through a number of mechanisms to reach the other part, the Internet, which is on public IP addresses.
What is IPv6?
IPv4 produces 4 billion addresses, and the developers think that these addresses are enough, but they were wrong. IPv6 is the next generation of IP addresses. The main difference between IPv4 and IPv6 is the address size of IP addresses. The IPv4 is a 32-bit address, whereas IPv6 is a 128-bit hexadecimal address. IPv6 provides a large address space, and it contains a simple header as compared to IPv4.
It provides transition strategies that convert IPv4 into IPv6, and these strategies are as follows:
● Dual stacking: It allows us to have both the versions, i.e., IPv4 and IPv6, on the same device.
● Tunneling: In this approach, all the users have IPv6 and communicate with an IPv4 network to reach IPv6.
● Network Address Translation: The translation allows the communication between the hosts having a different version of IP.
This hexadecimal address contains both numbers and alphabets. Due to the usage of both the numbers and alphabets, IPv6 is capable of producing over 340 undecillion (3.4*1038) addresses.
IPv6 is a 128-bit hexadecimal address made up of 8 sets of 16 bits each, and these 8 sets are separated by a colon. In IPv6, each hexadecimal character represents 4 bits. So, we need to convert 4 bits to a hexadecimal number at a time
The address format of IPv6:

Fig 6: Address format of IPV6
The above diagram shows the address format of IPv4 and IPv6. An IPv4 is a 32-bit decimal address. It contains 4 octets or fields separated by 'dot', and each field is 8-bit in size. The number that each field contains should be in the range of 0-255. Whereas an IPv6 is a 128-bit hexadecimal address. It contains 8 fields separated by a colon, and each field is 16-bit in size.
Differences between IPv4 and IPv6
| Ipv4 | Ipv6 |
Address length | IPv4 is a 32-bit address. | IPv6 is a 128-bit address. |
Fields | IPv4 is a numeric address that consists of 4 fields which are separated by dot (.). | IPv6 is an alphanumeric address that consists of 8 fields, which are separated by colon. |
Classes | IPv4 has 5 different classes of IP address that includes Class A, Class B, Class C, Class D, and Class E. | IPv6 does not contain classes of IP addresses. |
Number of IP address | IPv4 has a limited number of IP addresses. | IPv6 has a large number of IP addresses. |
VLSM | It supports VLSM (Virtual Length Subnet Mask). Here, VLSM means that Ipv4 converts IP addresses into a subnet of different sizes. | It does not support VLSM. |
Address configuration | It supports manual and DHCP configuration. | It supports manual, DHCP, auto-configuration, and renumbering. |
Encryption and Authentication | It does not provide encryption and authentication. | It provides encryption and authentication. |
Address representation | In IPv4, the IP address is represented in decimal. | In IPv6, the representation of the IP address is hexadecimal. |
Packet flow identification | It does not provide any mechanism for packet flow identification. | It uses a flow label field in the header for the packet flow identification. |
Key takeaway:
- Network layer manages options pertaining to host and network addressing, managing sub-networks, and internet working.
- IPv6 is the next generation of IP addresses.
- IPv6 is the latest revision of the Internet Protocol and the first version of the protocol to be widely deployed.
The majority of internet and intranet traffic, also known as unicast data or unicast traffic, is routed to a specific destination. Unicast routing is the process of sending unicast data via the internet. Because the destination is already known, it is the simplest form of routing. As a result, all the router has to do is check the routing table and forward the packet to the next step.
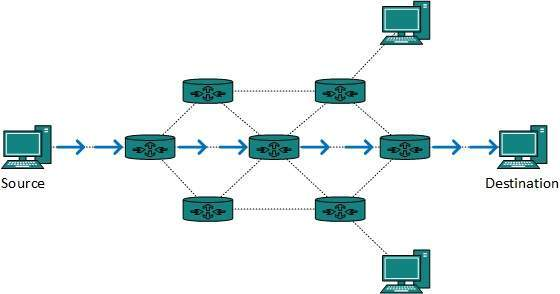
Fig 7: Unicast routing
Unicast packets can be routed using one of two routing protocols:
Distance Vector Routing Protocol
Distance Vector is a straightforward routing technique that bases its decisions on the number of hops between the source and the destination. The best route is one that has the fewest amount of hops. To other routers, each router presents its collection of optimal routes. Finally, all routers construct their network topologies based on peer router ads.
Routing Information Protocol, for example (RIP).
Link State Routing Protocol
The Link State protocol is a little more sophisticated than the Distance Vector protocol. It considers the states of all the routers in a network's links. This technique aids in the creation of a network-wide shared graph. The optimum path for routing is then calculated by all routers. Open Shortest Path First (OSPF) and Intermediate System to Intermediate System (IS-IS) are two examples (ISIS).
Multicast routing protocol
Multicast routing is a subset of broadcast routing, with unique characteristics and challenges. Packets are sent to all nodes via broadcast routing, even if they do not want them. However, in Multicast routing, data is only sent to nodes that desire to receive packets.
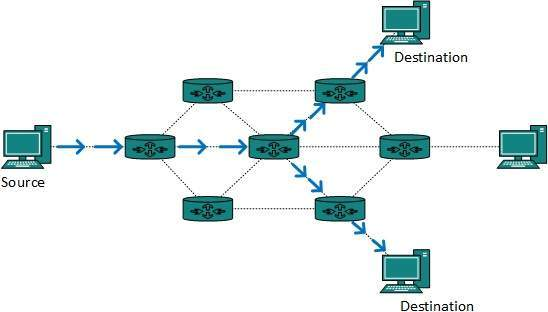
Fig 8: Multicast routing
Multicast routing methods employ trees, i.e. spanning tree, to eliminate loops, whereas Unicast routing protocols use graphs. The shortest path spanning tree is the best tree.
● DVMRP - Distance Vector Multicast Routing Protocol
● MOSPF - Multicast Open Shortest Path First
● CBT - Core Based Tree
● PIM - Protocol independent Multicast
Protocol Independent Multicast (PIM) is currently widely utilised. It comes in two different flavors:
PIM Dense Mode -
Source-based trees are used in this mode. It's employed in high-density environments like LANs.
PIM Sparse Mode -
Shared trees are used in this manner. In a sparse setting, such as a WAN, it is employed.
Key takeaway
Unicast routing is the process of sending unicast data via the internet. Because the destination is already known, it is the simplest form of routing.
Multicast routing is a subset of broadcast routing, with unique characteristics and challenges. Packets are sent to all nodes via broadcast routing, even if they do not want them.
Let's have a look at how the Leaky Bucket Algorithm works.
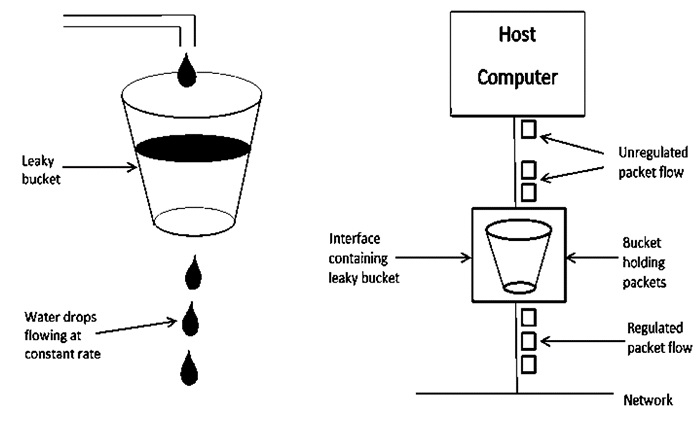
Fig 9: Leaky bucket algorithm
The Leaky Bucket Algorithm is primarily responsible for controlling the total volume and rate of traffic supplied to the network.
Step 1: Consider a bucket with a small hole at the bottom into which water is poured at a variable pace, but which leaks at a constant rate.
Step 2 So (as long as there is water in the bucket), the rate at which water leaks is unaffected by the pace at which water is poured into the bucket.
Step 3: If the bucket is full, any more water that enters will pour over the edges and be lost.
Step 4: The same technique was applied to network packets. Consider the fact that data is arriving at varying speeds from the source. Assume a source transmits data at 10 Mbps for 4 seconds. For the next three seconds, there is no data. For 2 seconds, the source transfers data at an 8 Mbps pace. Thus, 68 Mb of data was sent in less than 8 seconds.
As a result, if you employ a leaky bucket technique, the data flow will be 8 Mbps for 9 seconds. As a result, the steady flow is maintained.
Token bucket algorithm
One of the strategies for congestion management algorithms is the token bucket algorithm. When there are too many packets in the network, it causes packet delay and packet loss, lowering the system's performance. Congestion is the term for this circumstance.
Congestion management is shared between the network layer and the transport layer. Trying to lessen the burden that the transport layer places on the network is one of the most effective strategies to control congestion. To keep this network running, the network and transport layers must collaborate.
The Token Bucket Algorithm is illustrated graphically as follows:
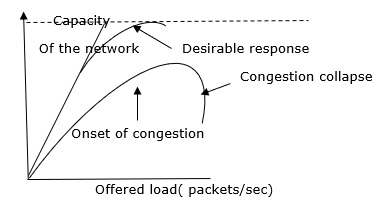
When there is too much traffic, performance suffers significantly.
Token Bucket Algorithm
No matter how busy the network is, the leaky bucket algorithm enforces output patterns at the average rate. To deal with the increased traffic, we'll need a flexible algorithm that won't lose data. The token bucket algorithm is one such method.
Let's take a look at this method one step at a time, as shown below.
Step 1: Tokens are thrown into the bucket f at regular intervals.
Step 2: The bucket can hold a maximum of f.
Step 3: If the packet is ready, a token from the bucket is taken, and the packet is sent.
Step 4 Assume that the packet cannot be forwarded if there is no token in the bucket.
Example
Let's look at an example of the Token Bucket Algorithm.
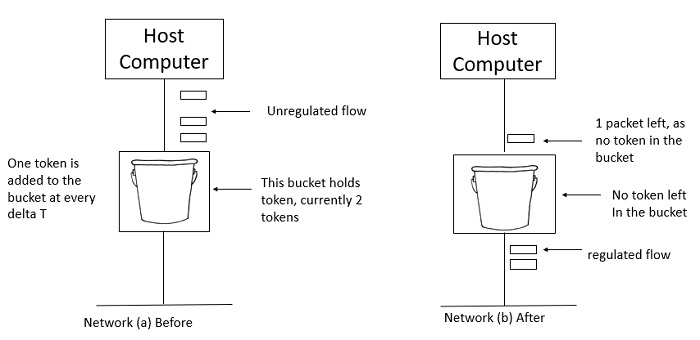
Two tokens are in the bucket in figure (a), and three packets are waiting to be transmitted out of the interface.
Figure (b) shows that two packets have been sent out after two tokens have been consumed, and one packet remains.
The token bucket method is less limiting than the Leaky bucket algorithm, allowing for more traffic. The amount of tokens accessible in the bucket at any given time determines the maximum amount of bustle.
The token bucket technique is simple to construct because the tokens are counted using a variable. The counter is incremented every t seconds and then decremented whenever a packet is sent. When the counter reaches zero, no further packet is sent out.
This is shown in below given diagram −
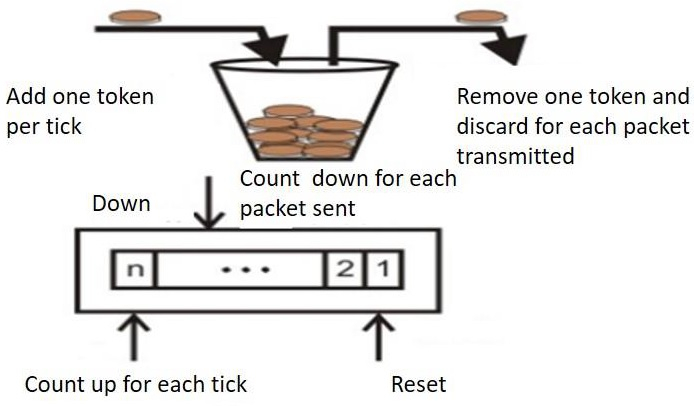
Some advantage of token Bucket over leaky bucket –
● If the token bucket is full, tokens are discarded rather than packets. Packets are discarded while in a leaky bucket.
● Token Bucket may deliver large bursts at a quicker pace, but a leaky bucket sends packets at the same rate every time.
Difference between leaky bucket and token bucket
Leaky Bucket | Token Bucket |
When the host has to send a packet , packet is thrown in bucket. | In this leaky bucket holds tokens generated at regular intervals of time. |
Bucket leaks at constant rate | Bucket has maximum capacity. |
Bursty traffic is converted into uniform traffic by leaky bucket. | If there is a ready packet , a token is removed from Bucket and packet is send. |
In practice bucket is a finite queue outputs at finite rate | If there is a no token in bucket, packet can not be send.
|
Both virtual networks and datagram subnets can benefit from the choke packet strategy. A choke packet is a message delivered by a node to the source informing it that the network is congested. Each router keeps track of its resources and how many of its output lines are in use. The router sends a choke packet to the source anytime resource use exceeds the threshold value defined by the administrator, giving it feedback to minimize traffic. Congestion is not reported to the intermediate nodes via which the packets passed.
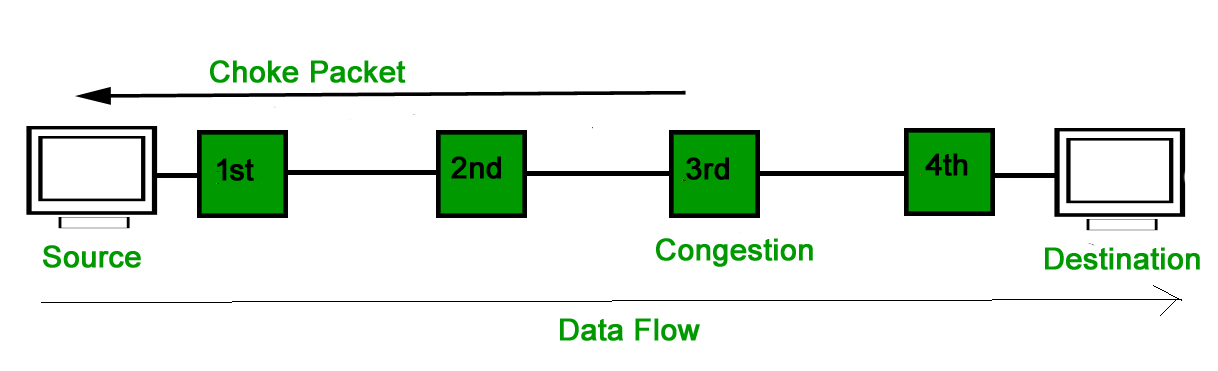
In network maintenance and quality management, a choke packet is used to notify a specific node or transmitter that its broadcast traffic is causing network congestion. As a result, the node or transmitter is forced to lower its output rate.
Choke packets are used to control network congestion and flow. The router addresses the source node directly, forcing it to reduce its transmission rate. The source node responds by lowering the sending rate by a certain percentage.
A source quench packet for the Internet Control Message Protocol (ICMP) is a form of choke packet commonly used by routers.
Routers are used in a choke packet's congestion control and recovery approach. Routers often scan the network for anomalies by looking at things like line use, queuing, and buffer length. Routers transmit choke packets to all related segments in the event of congestion to reduce data throughput. Depending on variables such as the size of the congestions, available bandwidth, and buffer size, the source node congesting the network must reduce throughput by a particular factor.
Key takeaway
Choke packets are used to control network congestion and flow. The router addresses the source node directly, forcing it to reduce its transmission rate. The source node responds by lowering the sending rate by a certain percentage.
Open loop
Policies are used in open-loop congestion control to prevent congestion before it occurs. Congestion control is performed by either the source or the destination in these systems.
a. Retransmission Policy
Sometimes retransmission is unavoidable. If the sender believes a packet has been lost or corrupted, the packet must be resent. In general, retransmission may cause network congestion. A good retransmission policy, on the other hand, can prevent congestion. The retransmission strategy and timers must be configured in such a way that they maximize efficiency while avoiding congestion. TCP's retransmission strategy, for example (described below), is meant to avoid or alleviate congestion.
b. Window Policy
Congestion may be influenced by the type of window used by the sender. For congestion control, the Selective Repeat window outperforms the Go-Back-N window. When the timer for a packet times out in the Go-Back-N window, numerous packets may be resent, even if some may have arrived safely at the recipient. This duplication could exacerbate the bottleneck. The Selective Repeat window, on the other hand, attempts to send only the lost or damaged packets.
c. Acknowledgment Policy
Congestion may be influenced by the receiver's acknowledgment policy. If the receiver does not acknowledge every packet it gets, the sender will be slowed and congestion will be avoided. In this scenario, several ways are applied. Only when a packet needs to be sent or when a particular timer expires can a receiver send an acknowledgment. Only N packets may be acknowledged at a time by a receiver. We need to understand that acknowledgements are part of a network's burden. Sending fewer acknowledgements reduces the amount of traffic on the network.
d. Discarding Policy
Routers with a good discarding policy can prevent congestion while not jeopardising the integrity of the transmission. In audio transmission, for example, if the policy is to discard less sensitive packets when congestion is expected, the sound quality is kept while congestion is avoided or alleviated.
e. Admission Policy
In virtual-circuit networks, an admission policy, which is a quality-of-service mechanism, can also reduce congestion. Before admitting a flow to the network, switches in a flow verify its resource requirements. If the network is congested or there is a chance of future congestion, a router can refuse to make a virtual circuit connection.
Closed loop
Closed-loop congestion control systems aim to reduce traffic congestion after it has occurred. Different methods have used a variety of mechanisms.
a. Backpressure
Backpressure is a congestion control technique in which a congested node stops receiving data from the upstream node or nodes it is connected to. As a result, the upstream node or nodes may become overburdened, and they may reject data from their upstream node or nodes. And so forth. Backpressure is a type of node-to-node congestion control that begins at a node and spreads to the source in the reverse direction of data flow. Only virtual circuit networks with each node knowing the upstream node from which a data flow is emanating can use the backpressure technique. Backpressure is depicted in the diagram.
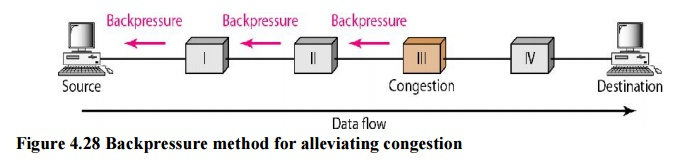
Fig 10: Backpressure method
The incoming data for Node III in the diagram is greater than it can manage. It discards a few packets from its input buffer and tells node II to slow down. Node II, in turn, may be congested as a result of the data output flow being slowed. When node II becomes crowded, it signals node I to slow down, which may cause congestion. If this is the case, node I will advise the data source to slow down. This, in turn, relieves congestion over time. This, in turn, relieves congestion over time. To clear the congestion, the pressure on node III is shifted backwards to the source.
b. Choke Packet
A choke packet is a message delivered by a node to the source informing it that the network is congested. The backpressure and choke packet approaches differ from one another. The alert is sent from one node to its upstream node under backpressure, albeit it may finally reach the source station. The choke packet approach sends a direct warning to the source station from the router that has encountered congestion. The intermediary nodes that the packet passed through are not notified. In ICMP, we've seen an example of this form of control. When an Internet router receives a large number of IP datagrams, it may discard some of them, but it notifies the source host via an ICMP source quench message. The warning message is sent directly to the source station, bypassing the intermediate routers, with no action taken. A choke packet is seen in the diagram.
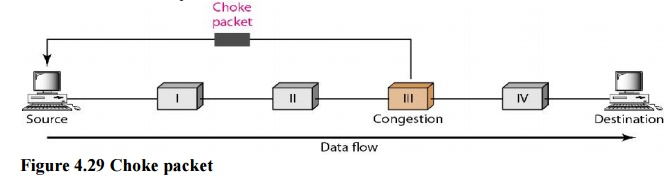
Fig 11: Choke packet
c. Implicit Signaling
There is no communication between the congested node or nodes and the source in implicit signaling. Other signs lead the source to believe that there is congestion somewhere in the network. One assumption is that the network is congested when a source sends multiple packets and receives no acknowledgement for a long time. The lack of an acknowledgement is viewed as network congestion, and the source should slow down.
d. Explicit Signaling
When a node encounters congestion, it can transmit an explicit signal to the source or destination. The explicit signaling approach, on the other hand, is not the same as the choke packet method. A separate packet is used for this purpose in the choke packet approach; in the explicit signaling method, the signal is included in the data packets. Explicit signaling can occur in either the forward or backward direction, as we'll see in Frame Relay congestion control.
i. Backward Signaling
In a packet going in the opposite direction of the congestion, a bit can be set. This bit can alert the source that there is a bottleneck and that it should slow down to minimize packet loss.
Ii. Forward Signaling
In a packet traveling in the direction of congestion, a bit can be set. This bit can alert the destination to the fact that there is a traffic jam. In this instance, the receiver can utilize measures to reduce congestion, such as slowing down acknowledgments.
References:
- Peterson and Davie, “Computer Networks: A Systems Approach”, Morgan Kaufmann
- W. A. Shay, “Understanding Communications and Networks”, Cengage Learning.
- D. Comer, “Computer Networks and Internets”, Pearson.
- Behrouz Forouzan, “TCP/IP Protocol Suite”, McGraw Hill.




