Unit 1
Introduction to Algorithm and Data structures
Problem
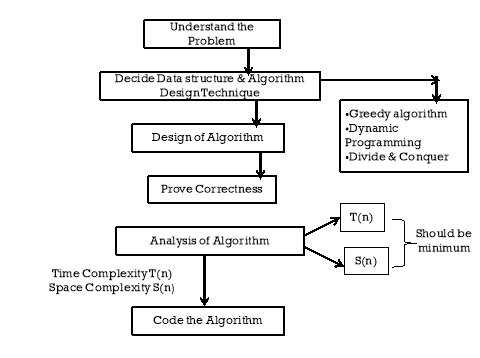
Analyzing algorithms: - analyzing algorithm has come to predicting the resources such as memory, communication bandwidth that the algorithm requires.
Goal of analysis: - Better utilization of memory, speed up the process (reduce the execution time) and reducethe development cost.
Running time of an algorithm: - Running time on a particular input is the numbers of basic operations that are perform.
Algorithm - An algorithm is any well defined computational procedure that takes some values or set of values as input and produces some values or set of values as output.
Logic: - Logic requires accurate identification of facts, elimination of cognitive error, and drawing of reasonable conclusions.
Data structure Data structure could also be a representation of the logical relationship existing between individual elements of knowledge.
Data: Raw information is called data.
Information: Processed data is called information.
Knowledge- Education or awareness or familiarity gained by experience of a fact or situation.
Ephemeral data structure- An ephemeral data structure is one for which only one version is available at a time: after an update operation, the structure as it existed before the update is lost.
Persistent Data Structure- A persistent structure is one where multiple versions are simultaneously accessible: after an update, both old and new versions are often used.
Abstract data types
• Abstract Data type (ADT) may be a type (or class) for objects whose behavior is defined by a group useful and a group of operations.
• The definition of ADT only mentions what operations are to be performed but not how these operations are going to be implemented.
• It doesn't specify how data are going to be organized in memory and what algorithms are going to be used for implementing the operations.
• It’s called “abstract” because it gives an implementation-independent view.
• The method of providing only the essentials and hiding the small print is understood as abstraction.
• The user of knowledge type doesn't got to skills that data type is implemented, for instance , we've been using Primitive values like int, float, char data types only with the knowledge that these data type can operate and be performed on with none idea of how they're implemented. So a user only must know what a knowledge type can do, but not how it'll be implemented. Consider
• ADT as a recorder which hides the inner structure and style of the info type.
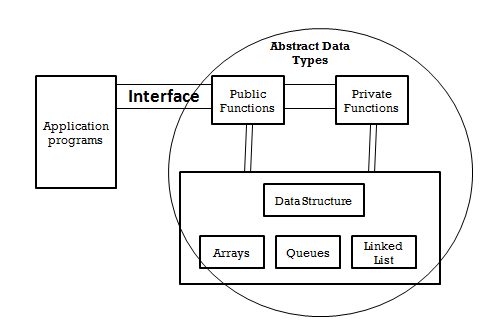
Data structures
• Data structure could also be a representation of the logical relationship existing between individual elements of knowledge.
• Data Structure may be a way of organizing all data items that considers not only the weather stored but also their relationship to every other.
• We also can define arrangement as a mathematical or logical model of a specific organization of knowledge items.
• The representation of particular arrangement within the main memory of a computer is named as storage structure.
• The storage structure representation in auxiliary memory is named as file structure.
• It is defined because the way of storing and manipulating data in organized form in order that it are often used efficiently.
• Data Structure mainly specifies the subsequent four things
• Algorithm + arrangement = Program
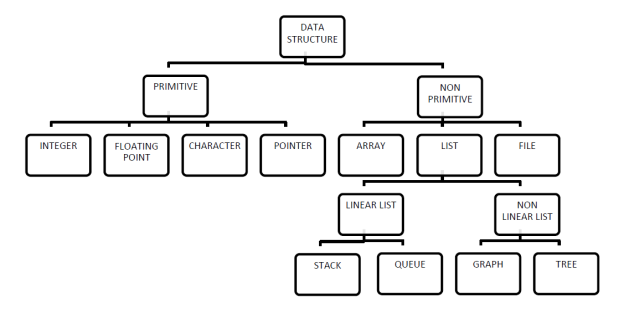
Classification of data types
- Integer
- Floating
- Character
- Pointer
- Linear list
- Stack
- Queue
- Non linear list
- Graph
- Tree
Data types a specific quite data item, as defined by the values it can take, the programming language used, or the operations which will be performed thereon.
1. Primitive arrangement
• Primitive data structures are basic structures and are directly operated upon by machine instructions.
• Primitive data structures are represented different in different computers.
• Integers, floats, character and pointers are samples of primitive data structures.
• These data types are available in most programming languages as inbuilt type.
Non primitive Data Type
• These are more sophisticated data structures.
• These are derived from primitive data structures.
• The non-primitive data structures emphasize on structuring of a gaggle of homogeneous or heterogeneous data items.
• Some of Non-primitive data types are Array, List, and File.
• A Non-primitive data type is further divided into Linear and Non-Linear arrangement
• Array: An array could also be a fixed-size sequenced collection of elements of the same data type.
• List: An ordered set containing variable number of elements is known as Lists.
• File: A file may be a collection of logically related information. It are often viewed as an outsized list of records consisting of varied fields.
Static data structure
Dynamic data structure
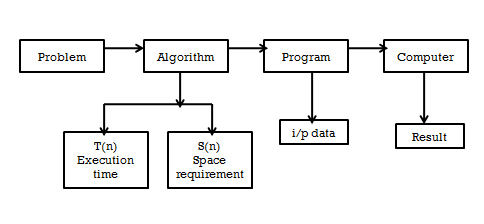
Algorithm
• An algorithm is any well defined computational procedure that takes some values or set of values as input and produces some values or set of values as output.
• An algorithm is a computational steps that transform the input into the output
• An algorithm is an abstraction of a program to be executed on a physical machine (model of computation).
• An essential aspect to data structures is algorithms.
• Data structures are implemented using algorithms.
• An algorithm may be a procedure that you simply can write as a C function or program, or the other language.
• An algorithm states explicitly how the info are going to be manipulated.
Algorithm Efficiency
• Some algorithms are more efficient than others. we might prefer to settle on an efficient algorithm, so it might be nice to possess metrics for comparing algorithm efficiency.
• The complexity of an algorithm may be a function describing the efficiency of the algorithm in terms of the quantity of knowledge the algorithm must process.
• Usually there are natural units for the domain and range of this function. The efficiency of algorithm is measured in two main complexity.
Properties of algorithm
• Finiteness – algorithm must complete after a finite number of instructions have been executed.
• Absence of ambiguity – every steps that are included in algorithm must be clearly defined having only one interpretation.
• Definition of sequence – each step must have a unique defined preceding and succeeding step. The first step (start step) and last step (halt step) must be clearly noted.
• Input/output – number and types of required inputs and results must be specified.
• Feasibility – every instruction should be performed.
Characteristics of an algorithm
Algorithm design tools
Flowcharts and Pseudocode
PSEUDOCODE
• Pseudo code is one among the tools which will be want to write a preliminary plan which will bedeveloped into a computer virus.
• Pseudo code may be a generic way of describing analgorithm without use of any specific programming language syntax.
• It is, because the namesuggests, pseudo code —it can't be executed on a true computer, but it models and resembles real programming code, and is written at roughly an equivalent level of detail.
Flowcharts
• Flowcharting may be a tool developed within the industry, for showing the stepsinvolved during a process.
• A flowchart may be a diagram made from boxes, diamonds and othershapes, connected by arrows - each shape represents a step within the process, and therefore the arrowsshow the order during which they occur.
• Flowcharting combines symbols and flow lines, toshow figuratively the operation of an algorithm.


Time complexity
• Time Complexity may be a function describing the quantity of your time an algorithm takes in terms of the quantity of input to the algorithm.
• "Time" can mean the quantity of memory accesses performed, the quantity of comparisons between integers, the quantity of times some inner loop is executed, or another natural unit related to the quantity of real time the algorithm will take.
Space complexity
• Space complexity may be a function describing the quantity of memory (space) an algorithm takes in terms of the quantity of input to the algorithm. We often speak of "extra" memory needed, not counting the memory needed to store the input itself.
• Space complexity is usually ignored because the space used is minimal and/or obvious, but sometimes it becomes as important a drag as time.
Asymptotic Notations
When it involves analyzing the complexity of any algorithm in terms of your time and space, we will never provide a particular number to define the time required and therefore the space required by the algorithm, instead we express it using some standard notations, also referred to as Asymptotic Notations.
When we analyze any algorithm, we generally get a formula to represent the quantity of your time required for execution or the time required by the pc to run the lines of code of the algorithm, number of memory accesses, number of comparisons, temporary variables occupying memory space etc. This formula often contains unimportant details that do not really tell us anything about the time period .
Types of Asymptotic Notations
We use three sorts of asymptotic notations to represent the expansion of any algorithm, as input increases:
1. Big Theta (Θ)
2. Big Oh(O)
3. Big Omega (Ω)
Tight Bounds: Theta
When we say tight bounds, we mean that the time compexity represented by the Big-Θ notation is just like the average value or range within which the particular time of execution of the algorithm are going to be.
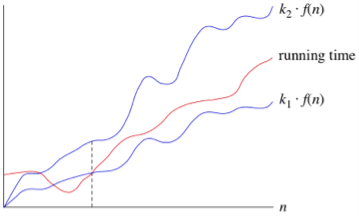
Upper Bounds: Big-O
This notation is understood because the boundary of the algorithm, or a Worst Case of an algorithm.
It tells us that a particular function will never exceed a specified time for any value of input n.
The question is why we'd like this representation once we have already got the big-Θ notation, which represents the tightly bound time period for any algorithm. Let's take a little example to know this.
Lower Bounds: Omega
Big Omega notation is employed to define the boundary of any algorithm or we will say the simplest case of any algorithm.
This always indicates the minimum time required for any algorithm for all input values, therefore the simplest case of any algorithm.
In simple words, once we represent a time complexity for any algorithm within the sort of big-Ω, we mean that the algorithm will take at least this much time to complete its execution. It can definitely take longer than this too.
Space Complexity of Algorithms
Instruction Space
Environmental Stack
Data Space
Finding complexity using step count method
Step-count Method and Asymptotic Notation
- { There is no count for f and g .
- { Each basic statement like 'assignment' and 'return' have a count of 1.
- { If a basic statement is iterated, then multiply by the amount of times the loop is run.
- { The loop statement is iterated n times, it's a count of (n + 1). Here the loop runs n times
- for truth case and a check is performed for the loop exit (the false condition),hence the additional 1 in the count.
Example
1. Sum of elements in an array
S. no. | Algorithm | Step count (time) | Step count (space) |
1 | Algorithm SUM(a,n) | 0 |
|
2 | sum = 0; | 1 | 1 word for sum |
3 | for i = 1 to n do | n+1 | 1 word each for i and n |
4 | sum = sum + a[i]; | n | n words for the array a[] |
5 | return sum | 1 |
|
6 | } | 0 |
|
Total: (2n+3) (n+3) words
2.Adding two matrices of order m and n
S no | Algorithm | Step count | Step count |
1 | Algorithm Add(a, b, c, m, n) | ------------ |
|
2 | { | ------------ |
|
3 | for i = 1 to m do | ------------ | m +1 |
4 | for j = 1 to n do | ------------ | m(n+1 |
5 | c[i,j] = a[i,j] + b[i,j] | ------------ | m.n |
6 | } | ------------ |
|
Total no of steps= 2mn + 2m + 2
Analysis of programming constructs
1. Constant-Time Algorithms - O(1)
2. Logarithmic-Time Algorithm - O(log n)
3. Linear-Time Algorithms - O(n)
4. Quadratic-Time Algorithms - O(n2)
5. Cubic-Time Algorithms - O(n3)
6. Exponential-Time Algorithms - O(2n)
S no | Constructs | Complexity |
1 | Constant | O(1) |
2 | Logarithmic | O(log n) |
3 | Linear | O(n) |
4 | Quadratic | O(n2) |
5 | Cubic | O(n3) |
6 | exponential | O(2n) |
Greedy algorithm
The main advantage of the greedy algorithm is:
Feasible Solution, A feasible solution is that the one that gives the optimal solution to the matter.
Greedy Algorithm
Problem: You have to make a change of an amount using the smallest possible number of coins.
Solution:
Greedy Algorithm Applications
Divide and Conquer Algorithm
A divide and conquer algorithm may be a strategy of solving an outsized problem bybreaking the matter into smaller sub-problems
solving the sub-problems, andcombining them to urge the specified output.
Here are the steps involved:
Complexity
Advantage of Divide and Conquer Algorithm
Divide and Conquer Application




